Introduzione
Nel panorama in rapida evoluzione dell’intelligenza artificiale generativa, il ruolo centrale dei database vettoriali è diventato sempre più evidente. Questo articolo approfondisce la sinergia dinamica tra database vettoriali e soluzioni di intelligenza artificiale generativa, esplorando come questi fondamenti tecnologici stanno plasmando il futuro della creatività dell'intelligenza artificiale. Unisciti a noi in un viaggio attraverso le complessità di questa potente alleanza, svelando approfondimenti sull'impatto trasformativo che i database vettoriali portano in prima linea nelle soluzioni IA innovative.
obiettivi formativi
Questo articolo ti aiuta a comprendere gli aspetti del database vettoriale di seguito.
- Importanza dei database vettoriali e dei suoi componenti chiave
- Studio dettagliato del confronto del database Vettoriale con il database Tradizionale
- Esplorazione dei Vector Embedding da un punto di vista applicativo
- Creazione di database vettoriali utilizzando Pincone
- Implementazione del database Pinecone Vector utilizzando il modello langchain LLM
Questo articolo è stato pubblicato come parte di Blogathon sulla scienza dei dati.
Sommario
Cos'è il database vettoriale?
Un database vettoriale è una forma di raccolta dati archiviata nello spazio. Tuttavia, qui, sono archiviati in rappresentazioni matematiche poiché il formato archiviato nei database rende più semplice per i modelli di intelligenza artificiale aperta memorizzare gli input e consente alla nostra applicazione di intelligenza artificiale aperta di utilizzare la ricerca cognitiva, i consigli e la generazione di testo per vari casi d'uso in le industrie trasformate digitalmente. La memorizzazione e il recupero dei dati è chiamato "Embedding vettoriali" o "Embedding". Inoltre, questo è rappresentato in un formato di matrice numerica. La ricerca è molto più semplice rispetto ai database tradizionali utilizzati per le prospettive dell'intelligenza artificiale con enormi capacità indicizzate.
Caratteristiche dei database vettoriali
- Sfrutta la potenza di questi incorporamenti di vettori, portando all'indicizzazione e alla ricerca in un enorme set di dati.
- Compattabile con tutti i formati di dati (immagini, testo o dati).
- Poiché adatta tecniche di incorporamento e funzionalità altamente indicizzate, può offrire una soluzione completa per la gestione dei dati e degli input per un determinato problema.
- Un database vettoriale organizza i dati attraverso vettori ad alta dimensionalità contenenti centinaia di dimensioni. Possiamo configurarli molto rapidamente.
- Ciascuna dimensione corrisponde a una caratteristica o proprietà specifica dell'oggetto dati che rappresenta.
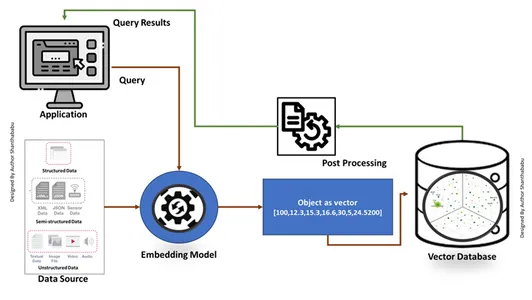
Tradizionale vs. Banca dati vettoriale
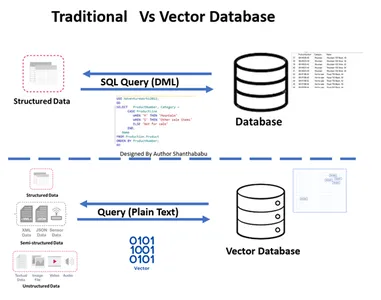
- L'immagine mostra il flusso di lavoro di alto livello del database tradizionale e vettoriale
- Le interazioni formali del database avvengono attraverso SQL istruzioni e dati archiviati in formato riga e tabellare.
- Nel database Vector, le interazioni avvengono tramite testo semplice (ad esempio, inglese) e dati archiviati in rappresentazioni matematiche.
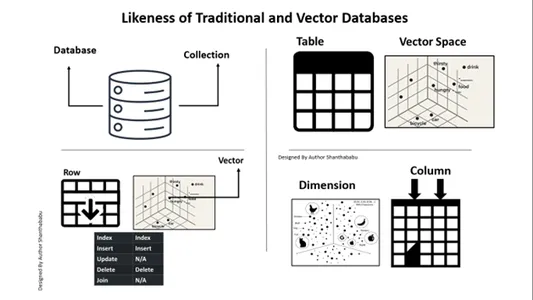
Somiglianza tra database tradizionali e vettoriali
Dobbiamo considerare come i database vettoriali differiscono da quelli tradizionali. Discutiamone qui. Una rapida differenza che posso fornire è quella dei database convenzionali. I dati vengono archiviati esattamente così come sono; potremmo aggiungere una logica aziendale per ottimizzare i dati e unirli o suddividerli in base ai requisiti o alle richieste aziendali. Tuttavia, il database vettoriale subisce una trasformazione massiccia e i dati diventano una rappresentazione vettoriale complessa.
Ecco una mappa per la tua comprensione e prospettiva di chiarezza database relazionali contro i database vettoriali. L'immagine seguente è autoesplicativa per comprendere i database vettoriali con i database tradizionali. In breve, possiamo eseguire inserimenti ed eliminazioni in database vettoriali, non istruzioni di aggiornamento.
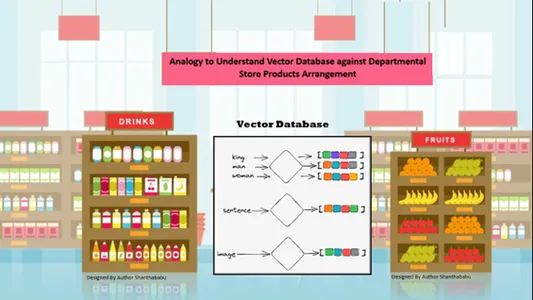
Semplice analogia per comprendere i database vettoriali
I dati vengono automaticamente organizzati spazialmente in base alla somiglianza del contenuto nelle informazioni archiviate. Quindi, consideriamo il negozio dipartimentale per l'analogia del database vettoriale; tutti i prodotti sono disposti sullo scaffale in base alla natura, allo scopo, alla produzione, all'utilizzo e alla quantità base. In un comportamento simile, i dati sono
disposti automaticamente nel database vettoriale in modo simile, anche se il genere non era ben definito durante la memorizzazione o l'accesso ai dati.
I database vettoriali consentono una granularità e dimensioni prominenti sulle somiglianze specifiche, quindi il cliente cerca il prodotto, il produttore e la quantità desiderati e mantiene l'articolo nel carrello. Il database vettoriale memorizza tutti i dati in una struttura di archiviazione perfetta; qui, gli ingegneri di machine learning e intelligenza artificiale non hanno bisogno di etichettare o taggare manualmente il contenuto archiviato.
Teorie essenziali dietro i database vettoriali
- Incorporamenti di vettori e loro ambito
- Requisiti di indicizzazione
- Comprendere la ricerca semantica e per somiglianza
Incorporamento dei vettori e relativo ambito
Un incorporamento vettoriale è una rappresentazione vettoriale in termini di valori numerici. In un formato compresso, gli incorporamenti catturano le proprietà intrinseche e le associazioni dei dati originali, rendendoli un punto fermo nei casi d'uso di intelligenza artificiale e machine learning. La progettazione di incorporamenti per codificare informazioni pertinenti sui dati originali in uno spazio a dimensione inferiore garantisce un'elevata velocità di recupero, efficienza computazionale e archiviazione efficiente.
Catturare l'essenza dei dati in un modo strutturato in modo più identico è il processo di incorporamento dei vettori, formando un "modello di incorporamento". In definitiva, questi modelli considerano tutti gli oggetti di dati, estraggono modelli e relazioni significativi all'interno dell'origine dati e li trasformano in incorporamenti di vettori. . Successivamente, gli algoritmi sfruttano questi incorporamenti di vettori per eseguire varie attività. Numerosi modelli di incorporamento altamente sviluppati, disponibili online gratuitamente o con pagamento in base al consumo, facilitano la realizzazione dell'incorporamento dei vettori.
Ambito dei Vector Embedding dal punto di vista applicativo
Questi incorporamenti sono compatti, contengono informazioni complesse, ereditano le relazioni tra i dati archiviati in un database vettoriale, consentono un'analisi efficiente dell'elaborazione dei dati per facilitare la comprensione e il processo decisionale e creano dinamicamente vari prodotti di dati innovativi in qualsiasi organizzazione.
Le tecniche di incorporamento dei vettori sono essenziali per colmare il divario tra dati leggibili e algoritmi complessi. Poiché i tipi di dati sono vettori numerici, siamo stati in grado di sbloccare il potenziale per un'ampia varietà di applicazioni di intelligenza artificiale generativa insieme ai modelli di intelligenza artificiale aperta disponibili.
Lavori multipli con incorporamento di vettori
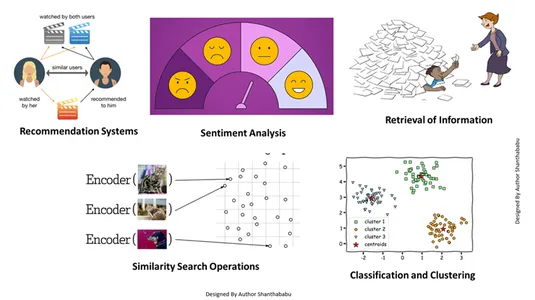
Questo incorporamento di vettori ci aiuta a svolgere più lavori:
- Recupero delle informazioni: Con l'aiuto di queste potenti tecniche, possiamo creare motori di ricerca influenti che possono aiutarci a trovare risposte basate sulle query degli utenti da file, documenti o contenuti multimediali archiviati
- Operazioni di ricerca per somiglianza: Questo è ben organizzato e indicizzato; ci aiuta a trovare la somiglianza tra diverse occorrenze nei dati vettoriali.
- Classificazione e clustering: Utilizzando queste tecniche di incorporamento, possiamo eseguire questi modelli per addestrare algoritmi di apprendimento automatico rilevanti e raggrupparli e classificarli.
- Sistemi di raccomandazione: Poiché le tecniche di incorporamento sono organizzate correttamente, si ottengono sistemi di raccomandazione che mettono in relazione accuratamente prodotti, media e articoli sulla base di dati storici.
- Analisi del sentimento: Questo modello di incorporamento ci aiuta a classificare e ricavare soluzioni di sentiment.
Requisiti di indicizzazione
Come sappiamo, l'indice migliorerà i dati di ricerca dalla tabella nei database tradizionali, simili ai database vettoriali, e fornirà le funzionalità di indicizzazione.
I database vettoriali forniscono "indici piatti", che sono la rappresentazione diretta dell'incorporamento dei vettori. La funzionalità di ricerca è completa e non utilizza cluster preaddestrati. Esegue la query del vettore su ogni singolo incorporamento del vettore e vengono calcolate le K distanze per ciascuna coppia.
- Data la semplicità di questo indice, per creare i nuovi indici è necessario un calcolo minimo.
- In effetti, un indice piatto può gestire le query in modo efficace e fornire tempi di recupero rapidi.
Comprendere la ricerca semantica e per somiglianza
Eseguiamo due diverse ricerche nei database vettoriali: ricerche semantiche e ricerche di somiglianza.
- Ricerca semantica: Durante la ricerca di informazioni, invece di cercare per parole chiave, puoi trovarle in base a una metodologia di conversazione significativa. La tempestiva progettazione svolge un ruolo fondamentale nel passaggio dell'input al sistema. Questa ricerca consente senza dubbio ricerche e risultati di qualità superiore che possono essere alimentati per applicazioni innovative, SEO, generazione di testo e riepilogo.
- Ricerca per somiglianza: Sempre nell'analisi dei dati, la ricerca per similarità consente set di dati non strutturati e con dati molto migliori. Per quanto riguarda i database vettoriali, dobbiamo accertare la vicinanza di due vettori e il modo in cui si assomigliano: tabelle, testo, documenti, immagini, parole e file audio. Nel processo di comprensione, la somiglianza tra i vettori si rivela come la somiglianza tra gli oggetti dati nel set di dati dato. Questo esercizio ci aiuta a comprendere l'interazione, identificare modelli, estrarre approfondimenti e prendere decisioni dal punto di vista dell'applicazione. La ricerca semantica e di somiglianza ci aiuterebbe a creare le applicazioni di seguito per vantaggi per il settore.
- Recupero delle informazioni: Utilizzando Open AI e database vettoriali, costruiremmo motori di ricerca per il recupero di informazioni utilizzando le query degli utenti aziendali o finali e i documenti indicizzati all'interno del DB vettoriale.
- Classificazione e clustering:Classificare o raggruppare punti dati o gruppi di oggetti simili implica assegnarli a più categorie in base a caratteristiche condivise.
- Rilevamento di anomalie: Scoprire anomalie rispetto a modelli abituali misurando la somiglianza dei punti dati e individuando le irregolarità.
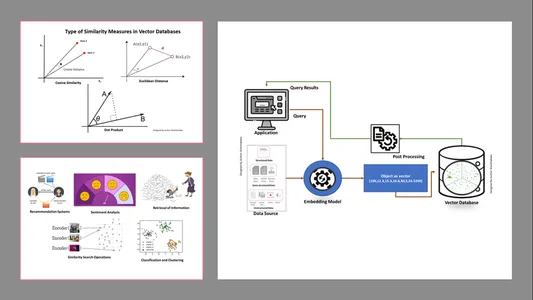
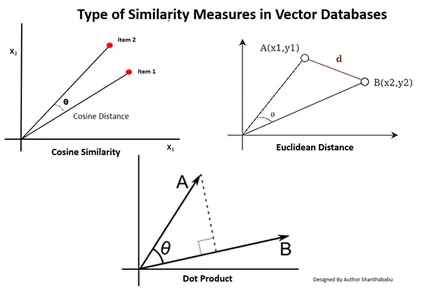
Tipi di misure di somiglianza nei database vettoriali
I metodi di misurazione dipendono dalla natura dei dati e dalle specifiche dell'applicazione. Comunemente, vengono utilizzati tre metodi per misurare la somiglianza e la familiarità con il Machine Learning.
Distanza euclidea
In termini semplici, la distanza tra i due vettori è la distanza in linea retta tra i due punti vettoriali che misurano la m.
Prodotto a punti
Questo ci aiuta a comprendere l'allineamento tra due vettori, indicando se puntano nella stessa direzione, in direzioni opposte o sono perpendicolari tra loro.
Somiglianza del coseno
Valuta la somiglianza di due vettori utilizzando l'angolo tra loro, come mostrato in figura. In questo caso i valori e la grandezza dei vettori sono insignificanti e non influenzano i risultati; nel calcolo viene considerato solo l'angolo.
Database tradizionali Cerca corrispondenze esatte di istruzioni SQL e recupera i dati in formato tabellare. Allo stesso tempo, ci occupiamo di database vettoriali ricercando il vettore più simile alla query di input in inglese semplice utilizzando tecniche di Prompt Engineering. Il database utilizza l'algoritmo di ricerca Approssimate Nearest Neighbour (ANN) per trovare dati simili. Fornire sempre risultati ragionevolmente accurati con prestazioni, accuratezza e tempi di risposta elevati.
Meccanismo di lavoro
- I database vettoriali convertono innanzitutto i dati in vettori di incorporamento, li archiviano in database vettoriali e creano indicizzazioni per una ricerca più rapida.
- Una query dall'applicazione interagirà con il vettore di incorporamento, cercando il vicino più vicino o dati simili nel database dei vettori utilizzando un indice e recuperando i risultati passati all'applicazione.
- In base ai requisiti aziendali, i dati recuperati verranno ottimizzati, formattati e visualizzati sul lato utente finale o sul feed di query o azioni.
Creazione di un database vettoriale
Connettiamoci con Pigna.
Puoi connetterti a Pinecone utilizzando Google, GitHub o Microsoft ID.
Crea un nuovo accesso utente per il tuo utilizzo.
Dopo aver effettuato con successo l'accesso, arriverai alla pagina Indice; puoi creare un indice per gli scopi del tuo database vettoriale. Fare clic sul pulsante Crea indice.
Crea il tuo nuovo indice fornendo il nome e le dimensioni.
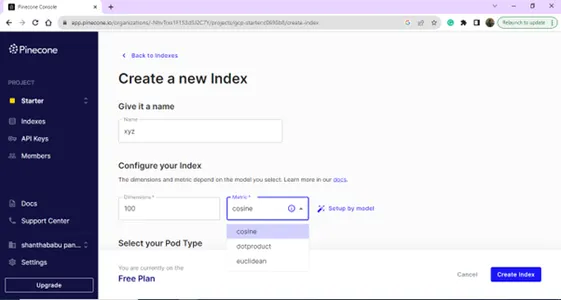
Pagina dell'elenco degli indici,
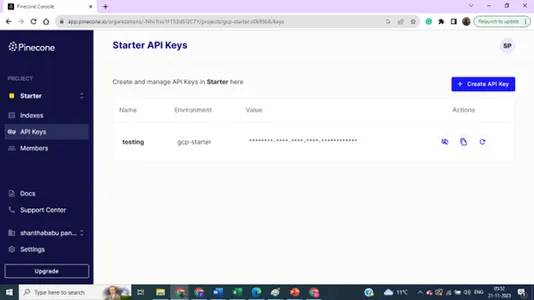
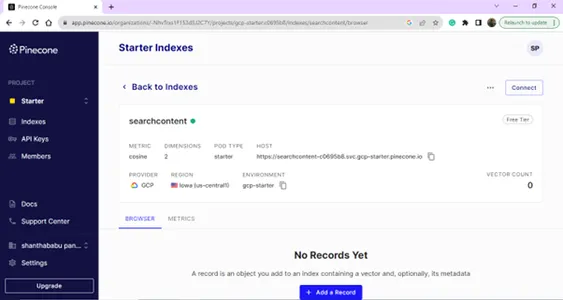
Dettagli indice – Nome, regione e ambiente – Abbiamo bisogno di tutti questi dettagli per collegare il nostro database vettoriale dal codice di costruzione del modello.
Dettagli sulle impostazioni del progetto,
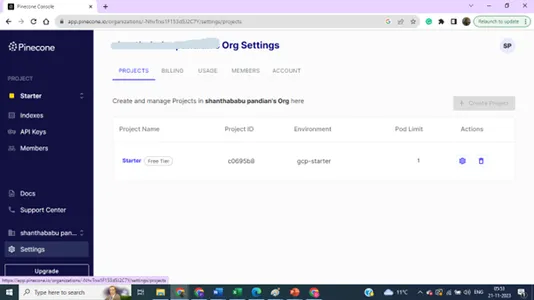
Puoi aggiornare le tue preferenze per più indici e chiavi per scopi di progetto.
Finora abbiamo discusso della creazione dell'indice e delle impostazioni del database vettoriale in Pinecone.
Implementazione del database vettoriale utilizzando Python
Facciamo un po' di codifica adesso.
Importazione di librerie
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIFornitura della chiave API per OpenAI e database Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Avvio del LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Inizio Pigna
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Caricamento del file .csv per la creazione del database vettoriale
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Dividi il testo in blocchi
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Trovare il testo in text_chunk
text_chunksUscita
[Document(page_content='name: 100% Brannmfr: Nntipo: Ccalorie: 70nproteine: 4ngrassi: 1nsodio: 130nfibre: 10ncarbo: 5nszuccheri: 6npotassio: 280nvitamine: 25nscaffale: 3npeso: 1ntazze: 0.33nvoto: 68.402973nrecom modifica: Kids', metadati={ 'fonte': '100% crusca', 'riga': 0}), , …..
Incorporamento dell'edificio
embeddings = OpenAIEmbeddings()Crea un'istanza Pinecone per il database vettoriale da "dati"
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Creare un retriever per interrogare il database vettoriale.
retriever = vectordb.as_retriever(score_threshold = 0.7)Recupero dei dati dal database vettoriale
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsUtilizzando Prompt e recuperare i dati
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Interroghiamo i dati.
chain('Can you please provide cereal recommendation for Kids?')Output dalla query
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Conclusione
Spero che tu possa comprendere come funzionano i database vettoriali, i loro componenti, l'architettura e le caratteristiche dei database vettoriali nelle soluzioni di intelligenza artificiale generativa. Comprendere le differenze tra il database vettoriale e il database tradizionale e confronto con gli elementi del database convenzionale. In effetti, l'analogia aiuta a comprendere meglio il database dei vettori. Il database vettoriale Pinecone e i passaggi di indicizzazione ti aiuteranno a creare un database vettoriale e a fornire la chiave per la seguente implementazione del codice.
Punti chiave
- Compattabile con dati strutturati, non strutturati e semistrutturati.
- Adatta tecniche di incorporamento e funzionalità altamente indicizzate.
- Le interazioni avvengono tramite testo semplice utilizzando un prompt (ad esempio, inglese). E dati memorizzati in rappresentazioni matematiche.
- La somiglianza si calibra nei database vettoriali tramite: Distanza euclidea, Somiglianza coseno e Prodotto scalare.
Domande frequenti
R. Un database vettoriale memorizza una raccolta di dati nello spazio. Mantiene i dati in rappresentazioni matematiche. poiché il formato archiviato nei database rende più semplice per i modelli di intelligenza artificiale aperta memorizzare gli input precedenti e consente alla nostra applicazione di intelligenza artificiale aperta di utilizzare ricerca cognitiva, raccomandazioni e generazione di testo precisa per vari casi d'uso nelle industrie trasformate digitalmente.
R. Alcune delle caratteristiche sono: 1. Sfrutta la potenza di questi incorporamenti di vettori, portando all'indicizzazione e alla ricerca in un enorme set di dati. 2. Compattabile con dati strutturati, non strutturati e semistrutturati. 3. Un database vettoriale organizza i dati attraverso vettori ad alta dimensione contenenti centinaia di dimensioni
A. Database ==> Raccolte
Tabella==> Spazio vettoriale
Riga==>Cettore
Colonna==>Dimensione
Nei database Vettoriali è possibile inserire e cancellare, proprio come in un database tradizionale.
Aggiorna e Partecipa non rientrano nell'ambito.
– Recupero di informazioni per una raccolta massiccia di dati in tempi rapidi.
– Operazioni di ricerca semantica e per similarità da documenti di grandi dimensioni.
– Applicazione di classificazione e clustering.
– Sistemi di raccomandazione e analisi del sentiment.
A5: Di seguito sono riportati i tre metodi per misurare la somiglianza:
– Distanza euclidea
– Somiglianza del coseno
– Prodotto scalare
I media mostrati in questo articolo non sono di proprietà di Analytics Vidhya e vengono utilizzati a discrezione dell'autore.
Leggi Anche
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :ha
- :È
- :non
- $ SU
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- capace
- WRI
- Accedendo
- precisione
- preciso
- con precisione
- operanti in
- adatta
- aggiungere
- influenzare
- AI
- Modelli AI
- algoritmo
- Algoritmi
- allineamento
- Tutti
- alleanza
- consentire
- consente
- lungo
- sempre
- tra
- an
- .
- analitica
- Analisi Vidhya
- ed
- rispondere
- in qualsiasi
- api
- apparente
- Applicazioni
- specifico dell'applicazione
- applicazioni
- approssimativo
- architettura
- SONO
- disposte
- Italia
- articolo
- news
- artificiale
- intelligenza artificiale
- Intelligenza artificiale e apprendimento automatico
- AS
- aspetti
- valuta il
- associazioni
- At
- Audio
- automaticamente
- disponibile
- basato
- BE
- diventare
- diventa
- comportamento
- dietro
- essendo
- sotto
- vantaggi
- Meglio
- fra
- blogathon
- portare
- costruire
- Costruzione
- affari
- pulsante
- by
- calcolato
- calcolo
- detto
- Materiale
- funzionalità
- capacità
- catturare
- Custodie
- casi
- categoria
- catena
- Catene
- caratteristiche
- chiarezza
- classificazione
- classificare
- clicca
- il clustering
- codice
- codifica
- conoscitivo
- collezione
- comunemente
- compatto
- confrontare
- confronto
- completamento di una
- complesso
- componenti
- globale
- calcolo
- computazionale
- Connettiti
- Collegamento
- Prendere in considerazione
- considerato
- contenere
- contenuto
- contesto
- convenzionale
- Conversazione
- convertire
- corrisponde
- potuto
- creare
- Creazione
- la creatività
- cliente
- dati
- analisi dei dati
- punti dati
- elaborazione dati
- Banca Dati
- banche dati
- dataset
- affare
- Decision Making
- decisioni
- richieste
- derivare
- progettazione
- desiderato
- dettagli
- rivelazione
- sviluppato
- differire
- differenza
- diverso
- digitalmente
- Dimensioni
- dimensioni
- dirette
- direzione
- itinerario
- scoprire
- discrezione
- discutere
- discusso
- visualizzati
- distanza
- do
- documenti
- effettua
- don
- DOT
- dinamico
- dinamicamente
- e
- ogni
- alleviare
- più facile
- in maniera efficace
- efficienza
- efficiente
- o
- elementi
- incorporamento
- enable
- fine
- Ingegneria
- Ingegneri
- Motori
- Inglese
- assicura
- Ambiente
- essenza
- essential
- Etere (ETH)
- Anche
- evoluzione
- eseguire
- Esercitare
- Esplorare
- estratto
- facilitare
- Familiarità
- lontano
- caratteristica
- Caratteristiche
- Federale
- figura
- Compila il
- File
- Trovate
- Nome
- piatto
- i seguenti
- Nel
- prima linea
- modulo
- formato
- Gratis
- da
- futuro
- divario
- generare
- ELETTRICA
- generativo
- AI generativa
- genere
- GitHub
- Dare
- dato
- Gruppo
- Gruppo
- maniglia
- accadere
- Avere
- Aiuto
- aiuta
- qui
- Alta
- alto livello
- vivamente
- storico
- Come
- Tuttavia
- HTTPS
- Enorme
- centinaia
- i
- ID
- identificare
- if
- immagini
- Impact
- implementazione
- importare
- competenze
- in
- sempre più
- Index
- indicizzati
- indici
- indicando
- Indici
- industrie
- industria
- Influente
- informazioni
- inerente
- creativi e originali
- ingresso
- Ingressi
- Inserti
- interno
- intuizioni
- esempio
- invece
- Intelligence
- interagire
- interazione
- interazioni
- ai miglioramenti
- complessità
- comporta
- IT
- SUO
- Offerte di lavoro
- join
- Unisciti a noi
- viaggio
- ad appena
- Le
- Tasti
- parole chiave
- bambini
- Sapere
- Discografica
- Paese
- paesaggio
- grandi
- principale
- Leads
- apprendimento
- Leva
- leveraggi
- piace
- Lista
- caricatore
- logica
- accesso
- macchina
- machine learning
- maggiore
- make
- FA
- Fare
- gestione
- modo
- manualmente
- Costruttore
- carta geografica
- massiccio
- fiammiferi
- matematico
- significativo
- misurare
- analisi
- di misura
- meccanismo
- Media
- Unire
- Metodologia
- metodi
- Microsoft
- minimo
- modello
- modelli
- Scopri di più
- Inoltre
- maggior parte
- molti
- multiplo
- devono obbligatoriamente:
- Nome
- Natura
- Bisogno
- New
- adesso
- numerose
- oggetto
- oggetti
- of
- offrire
- on
- ONE
- quelli
- online
- esclusivamente
- aprire
- OpenAI
- Operazioni
- di fronte
- or
- organizzazione
- Organizzato
- organizza
- i
- OS
- Altro
- nostro
- Di proprietà
- pagina
- coppia
- parte
- Passato
- Di passaggio
- modelli
- perfetta
- eseguire
- performance
- eseguita
- esegue
- prospettiva
- prospettive
- immagine
- centrale
- pianura
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioca
- per favore
- punto
- punti
- possibile
- potenziale
- energia
- potente
- Pratico
- Applicazioni pratiche
- bisogno
- precisamente
- preferenze
- precedente
- Problema
- processi
- Prodotto
- Prodotti
- progetto
- prominente
- istruzioni
- propriamente
- proprietà
- proprietà
- fornire
- fornitura
- fornitura
- pubblicato
- Puffs
- scopo
- fini
- quantità
- query
- domanda
- Presto
- più veloce
- rapidamente
- rapidamente
- Consigli
- raccomandazioni
- per quanto riguarda
- regione
- relazioni
- Relazioni
- pertinente
- rappresentazione
- rappresentato
- rappresenta
- necessario
- Requisiti
- risposta
- risposte
- colpevole
- Risultati
- Rivelato
- Ruolo
- RIGA
- s
- stesso
- Scienze
- portata
- Cerca
- Motori di ricerca
- Ricerche
- ricerca
- sentimento
- SEO
- impostazioni
- Forma
- sagomatura
- condiviso
- Lo scaffale
- Corti
- mostrato
- Spettacoli
- lato
- simile
- somiglianze
- Un'espansione
- da
- singolo
- Taglia
- So
- soluzione
- Soluzioni
- alcuni
- Fonte
- lo spazio
- specifico
- velocità
- dividere
- smacchiatura
- SQL
- Regione / Stato
- dichiarazione
- dichiarazioni
- Passi
- Ancora
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- La struttura
- strutturato
- Studio
- Successivamente
- di successo
- sinergia
- sistema
- SISTEMI DI TRATTAMENTO
- T
- tavolo
- TAG
- task
- tecniche
- tecnologico
- condizioni
- testo
- generazione di testo
- di
- che
- Il
- Il futuro
- loro
- Li
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tre
- Attraverso
- tempo
- volte
- a
- tradizionale
- Treni
- Trasformare
- Trasformazione
- trasformativa
- trasformato
- prova
- seconda
- Tipi di
- in definitiva
- capire
- e una comprensione reciproca
- indubbiamente
- sbloccare
- sblocco
- Aggiornanento
- upgrade
- us
- Impiego
- uso
- utilizzato
- Utente
- usa
- utilizzando
- solito
- Valori
- varietà
- vario
- molto
- importantissima
- vs
- Prima
- we
- WebP
- ben definita
- sono stati
- Che
- Che cosa è l'
- se
- quale
- while
- volere
- con
- entro
- parole
- Lavora
- lavoro
- sarebbe
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro