Immagine dell'editore
La funzione sigmoidea è una delle funzioni di attivazione più popolari utilizzate per lo sviluppo di reti neurali profonde. L'uso della funzione sigmoidea ha limitato l'allenamento delle reti neurali profonde perché ha causato il problema del gradiente di scomparsa. Ciò ha causato l'apprendimento della rete neurale a un ritmo più lento o, in alcuni casi, nessun apprendimento. Questo post sul blog ha lo scopo di descrivere il problema del gradiente di scomparsa e spiegare come l'uso della funzione sigmoide ne abbia prodotto.
Le funzioni sigmoidi sono usate frequentemente nelle reti neurali per attivare i neuroni. È una funzione logaritmica con una caratteristica forma a S. Il valore di uscita della funzione è compreso tra 0 e 1. La funzione sigmoide viene utilizzata per attivare i livelli di uscita nei problemi di classificazione binaria. Si calcola come segue:
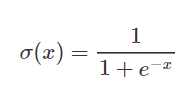
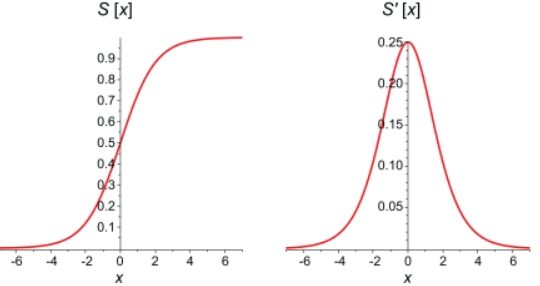
Nel grafico sottostante puoi vedere un confronto tra la funzione sigmoidea stessa e la sua derivata. Le derivate prime delle funzioni sigmoidi sono curve a campana con valori compresi tra 0 e 0.25.
La nostra conoscenza di come le reti neurali si comportano in avanti e indietro è essenziale per comprendere il problema del gradiente di fuga.
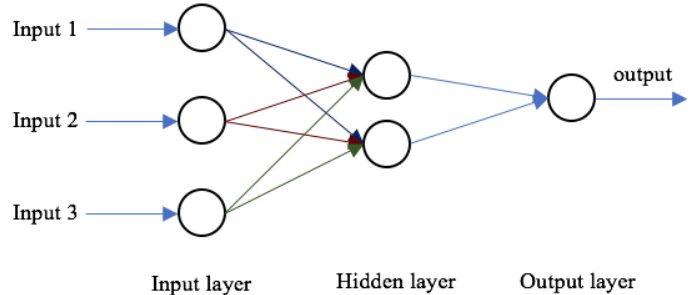
La struttura di base di una rete neurale è un livello di input, uno o più livelli nascosti e un singolo livello di output. I pesi della rete vengono inizializzati casualmente durante la propagazione in avanti. Le caratteristiche di input vengono moltiplicate per i pesi corrispondenti su ciascun nodo del livello nascosto e viene aggiunta una distorsione alla somma netta su ciascun nodo. Questo valore viene quindi trasformato nell'output del nodo tramite una funzione di attivazione. Per generare l'output della rete neurale, l'output del livello nascosto viene moltiplicato per i pesi più i valori di bias e il totale viene trasformato utilizzando un'altra funzione di attivazione. Questo sarà il valore previsto della rete neurale per un dato valore di input.
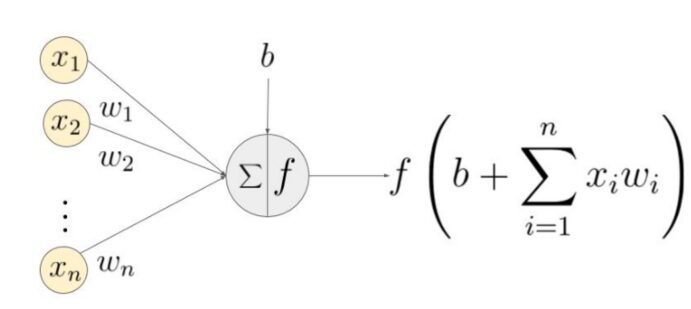
Quando la rete genera un output, la funzione di perdita (C) indica quanto bene ha previsto l'output. La rete esegue la propagazione all'indietro per ridurre al minimo la perdita. Un metodo di propagazione all'indietro riduce al minimo la funzione di perdita regolando i pesi e le distorsioni della rete neurale. In questo metodo si calcola il gradiente della funzione di perdita rispetto a ciascun peso nella rete.
Nella propagazione posteriore, il nuovo peso (wnuovi) di un nodo viene calcolato utilizzando il vecchio peso(wvecchio) e prodotto del tasso di apprendimento(ƞ) e del gradiente della funzione di perdita ![]()
![]() .
.
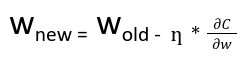
Con la regola della catena delle derivate parziali, possiamo rappresentare il gradiente della funzione di perdita come prodotto dei gradienti di tutte le funzioni di attivazione dei nodi rispetto ai loro pesi. Pertanto, i pesi aggiornati dei nodi nella rete dipendono dai gradienti di le funzioni di attivazione di ciascun nodo.
Per i nodi con funzioni di attivazione sigmoidea, sappiamo che la derivata parziale della funzione sigmoidea raggiunge un valore massimo di 0.25. Quando ci sono più strati nella rete, il valore del prodotto della derivata diminuisce fino a quando a un certo punto la derivata parziale della funzione di perdita si avvicina a un valore prossimo allo zero e la derivata parziale svanisce. Lo chiamiamo il problema del gradiente di fuga.
Con reti poco profonde, la funzione sigmoide può essere utilizzata poiché il piccolo valore del gradiente non diventa un problema. Quando si tratta di reti profonde, il gradiente di fuga potrebbe avere un impatto significativo sulle prestazioni. I pesi della rete rimangono invariati man mano che la derivata svanisce. Durante la propagazione posteriore, una rete neurale apprende aggiornando i suoi pesi e le sue distorsioni per ridurre la funzione di perdita. In una rete con gradiente evanescente, i pesi non possono essere aggiornati, quindi la rete non può apprendere. Di conseguenza, le prestazioni della rete diminuiranno.
Il problema del gradiente di fuga è causato dalla derivata della funzione di attivazione utilizzata per creare la rete neurale. La soluzione più semplice al problema è sostituire la funzione di attivazione della rete. Invece di sigmoid, usa una funzione di attivazione come ReLU.
Le unità lineari rettificate (ReLU) sono funzioni di attivazione che generano un'uscita lineare positiva quando vengono applicate a valori di ingresso positivi. Se l'input è negativo, la funzione restituirà zero.
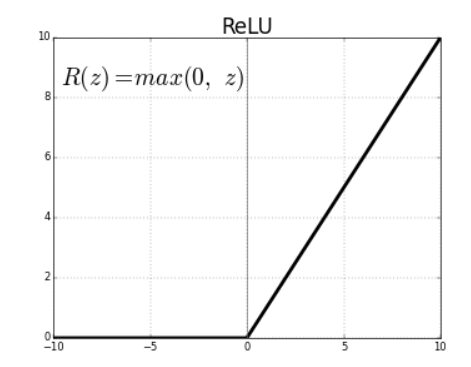
La derivata di una funzione ReLU è definita come 1 per input maggiori di zero e 0 per input negativi. Il grafico condiviso di seguito indica la derivata di una funzione ReLU
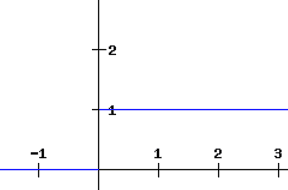
Se la funzione ReLU viene utilizzata per l'attivazione in una rete neurale al posto di una funzione sigmoidea, il valore della derivata parziale della funzione di perdita avrà valori di 0 o 1 che impediscono al gradiente di svanire. L'uso della funzione ReLU impedisce quindi che il gradiente svanisca. Il problema con l'uso di ReLU è quando il gradiente ha un valore di 0. In questi casi, il nodo è considerato un nodo morto poiché il vecchio e il nuovo valore dei pesi rimangono gli stessi. Questa situazione può essere evitata mediante l'uso di una funzione ReLU che perde che impedisce al gradiente di scendere al valore zero.
Un'altra tecnica per evitare il problema del gradiente evanescente è l'inizializzazione del peso. Questo è il processo di assegnazione dei valori iniziali ai pesi nella rete neurale in modo che durante la propagazione all'indietro i pesi non scompaiano mai.
In conclusione, il problema del gradiente di fuga nasce dalla natura della derivata parziale della funzione di attivazione utilizzata per creare la rete neurale. Il problema può essere peggio nelle reti neurali profonde che utilizzano la funzione di attivazione del Sigmoide. Può essere notevolmente ridotto utilizzando funzioni di attivazione come ReLU e ReLU che perde.
Tina Giacobbe è appassionato di scienza dei dati e crede che la vita riguardi l'apprendimento e la crescita, indipendentemente da ciò che porta.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2022/02/vanishing-gradient-problem.html?utm_source=rss&utm_medium=rss&utm_campaign=vanishing-gradient-problem-explained
- :ha
- :È
- :non
- 1
- 102
- 25
- 60
- a
- WRI
- attivazione
- Attivazione
- attivazioni
- aggiunto
- mira
- Tutti
- an
- ed
- Un altro
- applicato
- approcci
- SONO
- AS
- At
- evitare
- evitato
- precedente
- basic
- BE
- perché
- diventare
- crede
- Campana
- sotto
- fra
- pregiudizio
- pregiudizi
- Blog
- Porta
- by
- calcolato
- chiamata
- Materiale
- non può
- casi
- ha causato
- cause
- catena
- caratteristica
- classificazione
- Chiudi
- viene
- confronto
- conclusione
- Conseguenze
- considerato
- Corrispondente
- potuto
- creare
- dati
- scienza dei dati
- morto
- diminuire
- diminuisce
- deep
- reti neurali profonde
- definito
- derivato
- Derivati
- descrivere
- in via di sviluppo
- effettua
- durante
- ogni
- essential
- Spiegare
- ha spiegato
- Caduta
- Caratteristiche
- Nome
- segue
- Nel
- Avanti
- frequentemente
- da
- function
- funzioni
- generare
- genera
- dato
- gradienti
- grafico
- maggiore
- Crescita
- Avere
- avendo
- nascosto
- Come
- HTTPS
- if
- Impact
- in
- indica
- inizialmente
- ingresso
- Ingressi
- invece
- ai miglioramenti
- problema
- IT
- SUO
- stessa
- jpg
- KDnuggets
- Sapere
- conoscenze
- strato
- galline ovaiole
- IMPARARE
- apprendimento
- Vita
- piace
- spento
- Importanza
- massimo
- metodo
- Scopri di più
- maggior parte
- Più popolare
- moltiplicato
- Natura
- negativo.
- rete
- Rete
- reti
- Neurale
- rete neurale
- reti neurali
- neuroni
- mai
- New
- no
- nodo
- nodi
- of
- Vecchio
- on
- ONE
- or
- produzione
- Pace
- appassionato
- eseguire
- performance
- esegue
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- più
- punto
- Popolare
- positivo
- Post
- previsto
- impedisce
- Problema
- problemi
- processi
- Prodotto
- propagazione
- che vanno
- raggiunge
- ridurre
- Ridotto
- rimanere
- sostituire
- rappresentare
- rispetto
- limitato
- colpevole
- risultato
- ritorno
- Regola
- s
- stesso
- Scienze
- vedere
- superficiale
- Forma
- condiviso
- significativa
- significativamente
- da
- singolo
- situazione
- piccole
- So
- soluzione
- Soluzioni
- alcuni
- La struttura
- tale
- di
- che
- Il
- Il grafo
- loro
- poi
- Là.
- perciò
- di
- questo
- a
- Totale
- Training
- trasformato
- e una comprensione reciproca
- unità
- fino a quando
- aggiornato
- aggiornamento
- uso
- utilizzato
- utilizzando
- APPREZZIAMO
- Valori
- we
- peso
- WELL
- Che
- quando
- quale
- volere
- con
- Tu
- zefiro
- zero