Con quale frequenza i progetti di machine learning raggiungono un'implementazione di successo? Non abbastanza spesso. C'è abbondanza of industria riparazioni mostra che i progetti ML comunemente non riescono a fornire rendimenti, ma pochi preziosi hanno valutato il rapporto tra fallimento e successo dal punto di vista dei data scientist, le persone che sviluppano gli stessi modelli che questi progetti dovrebbero implementare.
Seguito su un sondaggio di data scientist che ho condotto con KDnuggets l'anno scorso, il sondaggio sulla scienza dei dati leader del settore di quest'anno gestito dalla società di consulenza ML Rexer Analytics ha affrontato la questione, in parte perché Karl Rexer, fondatore e presidente dell'azienda, ha consentito al sottoscritto di partecipare, favorendo l'inclusione di domande sul successo dell'implementazione (parte del mio lavoro durante una cattedra di analisi di un anno che ho tenuto all'UVA Darden).
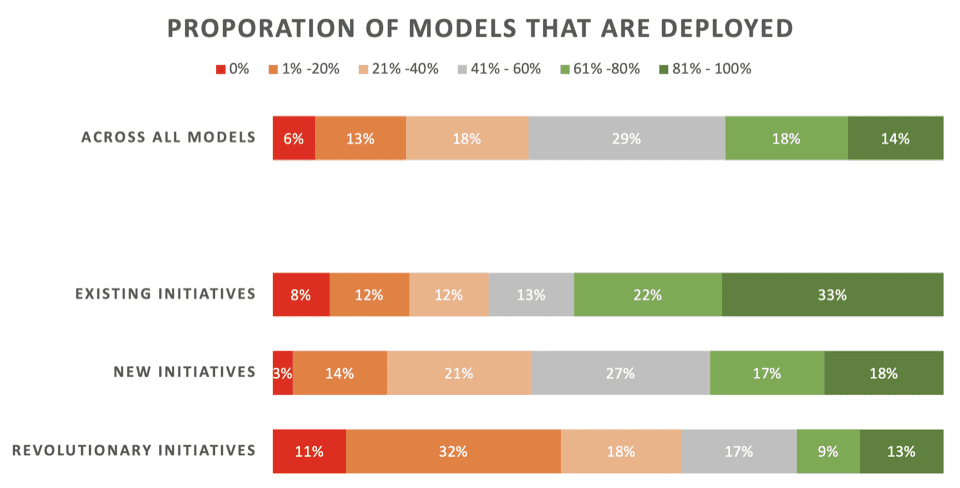
Le notizie non sono grandiose. Solo il 22% dei data scientist afferma che le proprie iniziative “rivoluzionarie” – modelli sviluppati per abilitare un nuovo processo o capacità – di solito vengono implementati. Il 43% afferma che l'80% o più non riesce a implementarlo.
Attraverso contro tutti i tipi di progetti ML, compresi i modelli di aggiornamento per le implementazioni esistenti, solo il 32% afferma che i propri modelli vengono solitamente implementati.
Ecco i risultati dettagliati di quella parte del sondaggio, presentati da Rexer Analytics, suddividendo i tassi di implementazione in tre tipi di iniziative ML:
Chiave:
- Iniziative esistenti: Modelli sviluppati per aggiornare/rinfrescare un modello esistente che è già stato distribuito con successo
- Nuove iniziative: Modelli sviluppati per migliorare un processo esistente per il quale non era già stato implementato alcun modello
- Iniziative rivoluzionarie: Modelli sviluppati per abilitare un nuovo processo o capacità
A mio avviso, questa lotta per l’implementazione deriva da due principali fattori che contribuiscono: la sottopianificazione endemica e le parti interessate del business prive di visibilità concreta. Molti professionisti dei dati e leader aziendali non sono arrivati a riconoscere che l’operatività prevista del machine learning deve essere pianificata in grande dettaglio e perseguita in modo aggressivo fin dall’inizio di ogni progetto di machine learning.
In effetti, ho scritto un nuovo libro proprio su questo: Il manuale dell'intelligenza artificiale: padroneggiare la rara arte dell'implementazione del machine learning. In questo libro presento una pratica in sei passaggi incentrata sulla distribuzione per accompagnare i progetti di machine learning dall'ideazione alla distribuzione che chiamo bizML (preordina la copertina rigida o l'e-book e ricevere una copia avanzata gratuita della versione dell'audiolibro al momento).
Lo stakeholder chiave di un progetto ML, ovvero la persona responsabile dell'efficacia operativa mirata al miglioramento, ad esempio un manager line-of-business, ha bisogno di visibilità su come il ML migliorerà le proprie operazioni e sul valore che si prevede che il miglioramento fornirà. Ne hanno bisogno per dare il via libera all’implementazione di un modello e, prima ancora, per valutare l’esecuzione del progetto durante le fasi precedenti l’implementazione.
Ma le prestazioni del machine learning spesso non vengono misurate! Quando il sondaggio Rexer chiedeva: "Con quale frequenza la tua azienda/organizzazione misura le prestazioni dei progetti analitici?" solo il 48% dei data scientist ha affermato “Sempre” o “La maggior parte delle volte”. È piuttosto strano. Dovrebbe essere più simile al 99% o al 100%.
E quando le prestazioni vengono misurate, lo fanno in termini di parametri tecnici che sono arcani e per lo più irrilevanti per gli stakeholder aziendali. I data scientist lo sanno meglio, ma generalmente non si attengono, in parte perché gli strumenti ML generalmente forniscono solo metriche tecniche. Secondo il sondaggio, i data scientist classificano i KPI aziendali come il ROI e le entrate come i parametri più importanti, ma elencano i parametri tecnici come incremento e AUC come quelli più comunemente misurati.
Secondo Revisione della scienza dei dati di Harvard. Ecco perché: ti dicono solo il parente prestazioni di un modello, ad esempio come si confronta con le ipotesi o con un'altra linea di base. Le metriche aziendali te lo dicono assoluto valore di business che il modello dovrebbe fornire o, in fase di valutazione dopo l'implementazione, che ha dimostrato di fornire. Tali parametri sono essenziali per i progetti ML incentrati sulla distribuzione.
Oltre all’accesso alle metriche aziendali, anche gli stakeholder aziendali devono accelerare. Quando il sondaggio Rexer ha chiesto: "I manager e i decisori della vostra organizzazione che devono approvare l'implementazione del modello sono generalmente sufficientemente informati per prendere tali decisioni in modo ben informato?" solo il 49% degli intervistati ha risposto “La maggior parte delle volte” o “Sempre”.
Ecco cosa credo stia accadendo. Il “cliente” del data scientist, lo stakeholder aziendale, spesso si spaventa quando si tratta di autorizzare l’implementazione, poiché ciò significherebbe apportare un cambiamento operativo significativo al pane quotidiano dell’azienda, ai suoi processi su larga scala. Non hanno il quadro contestuale. Ad esempio, si chiedono: “Come posso capire quanto questo modello, che funziona molto lontano dalla perfezione della sfera di cristallo, sarà effettivamente d’aiuto?” Così il progetto muore. Quindi, dare in modo creativo una sorta di svolta positiva alle “intuizioni acquisite” serve a nascondere chiaramente il fallimento sotto il tappeto. L’entusiasmo per l’IA rimane intatto anche se il valore potenziale, lo scopo del progetto, viene perso.
Su questo argomento – stimolare gli stakeholder – inserirò il mio nuovo libro, Il manuale dell'intelligenza artificiale, ancora una volta sola. Oltre a coprire la pratica bizML, il libro migliora anche le competenze dei professionisti aziendali fornendo una dose vitale ma amichevole di conoscenze di base semi-tecniche di cui tutte le parti interessate hanno bisogno per guidare o partecipare a progetti di machine learning, dall'inizio alla fine. Ciò mette i professionisti aziendali e dei dati sulla stessa lunghezza d'onda in modo che possano collaborare profondamente, stabilendo insieme con precisione cosa è chiamato a prevedere il machine learning, quanto bene lo prevede e come le sue previsioni vengono utilizzate per migliorare le operazioni. Questi elementi essenziali creano o distruggono ogni iniziativa: realizzarli correttamente apre la strada all’implementazione basata sul valore del machine learning.
Si può dire con certezza che la situazione è difficile là fuori, soprattutto per le nuove iniziative di ML di primo tentativo. Poiché la pura forza dell’hype sull’intelligenza artificiale perde la sua capacità di compensare continuamente
meno valore realizzato di quello promesso, ci sarà sempre più pressione per dimostrare il valore operativo del ML.? Quindi ti dico: vai avanti adesso: inizia a instillare una cultura più efficace di collaborazione interaziendale e leadership di progetto orientata all'implementazione!
Per risultati più dettagliati da Sondaggio sulla scienza dei dati di Rexer Analytics del 2023, fare clic su qui. Si tratta del più ampio sondaggio tra professionisti di data science e analisi del settore. Si compone di circa 35 domande a scelta multipla e a risposta aperta che coprono molto più delle semplici percentuali di successo dell'implementazione: sette aree generali della scienza e della pratica del data mining: (1) Campo e obiettivi, (2) Algoritmi, (3) Modelli, ( 4) Strumenti (pacchetti software utilizzati), (5) Tecnologia, (6) Sfide e (7) Futuro. È condotto come un servizio (senza sponsorizzazione aziendale) alla comunità della scienza dei dati e i risultati vengono solitamente annunciati all'indirizzo la conferenza della Machine Learning Week e condivisi tramite report di sintesi liberamente disponibili.
Questo articolo è il prodotto del lavoro dell'autore mentre ha ricoperto per un anno l'incarico di Professore di Analisi del Bicentenario Bodily presso la UVA Darden School of Business, incarico che alla fine è culminato con la pubblicazione di Il manuale dell'intelligenza artificiale: padroneggiare la rara arte dell'implementazione del machine learning (offerta di audiolibri gratuiti).
Eric Sigel, Ph.D., è un consulente leader ed ex professore della Columbia University che rende l'apprendimento automatico comprensibile e accattivante. È il fondatore della Mondo analitico predittivo e la Mondo del deep learning serie di conferenze, che hanno servito più di 17,000 partecipanti dal 2009, l'istruttore dell'acclamato corso Leadership e pratica dell'apprendimento automatico: padronanza end-to-end, un oratore popolare per il quale è stato incaricato Oltre 100 discorsi principalie direttore esecutivo di I tempi dell'apprendimento automatico. È l'autore del bestseller Analisi predittiva: il potere di prevedere chi farà clic, acquisterà, mentirà o morirà, che è stato utilizzato nei corsi di più di 35 università, e ha vinto premi per l'insegnamento quando era professore alla Columbia University, dove ha cantato canti educativi ai suoi studenti. Eric pubblica anche editoriali su analisi e giustizia sociale. Seguilo su @predictanalytic.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 17
- 35%
- 7
- a
- capacità
- WRI
- accesso
- acclamato
- Secondo
- operanti in
- effettivamente
- indirizzata
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- aggressivo
- avanti
- AI
- Algoritmi
- Tutti
- permesso
- già
- anche
- sempre
- am
- an
- Analitico
- analitica
- ed
- ha annunciato
- Un altro
- approvare
- circa
- Arcane
- SONO
- aree
- Arte
- articolo
- AS
- At
- i partecipanti
- nessuno
- Authored
- disponibile
- premi
- lontano
- sfondo
- Linea di base
- BE
- perché
- stato
- prima
- CREDIAMO
- bestseller
- Meglio
- libro
- Pane
- Rompere
- Rottura
- affari
- Dirigenti d'impresa
- ma
- Acquistare
- by
- chiamata
- detto
- Materiale
- capacità
- travolgente
- sfide
- il cambiamento
- carica
- scegliere
- clicca
- cliente
- freddo
- collaboreranno
- collaborazione
- Columbia
- COM
- Venire
- viene
- comunemente
- comunità
- azienda
- Società
- concezione
- calcestruzzo
- condotto
- Convegno
- consiste
- consulenza
- consulente
- contestuale
- continuamente
- contribuendo
- Aziende
- corso
- Corsi
- coprire
- copertura
- Creativamente
- cs
- Cultura
- dati
- data mining
- scienza dei dati
- scienziato di dati
- decisori
- decisioni
- profondamente
- consegnare
- consegna
- schierare
- schierato
- deployment
- implementazioni
- dettaglio
- dettagliati
- sviluppare
- sviluppato
- scollegato
- do
- effettua
- don
- Dont
- dose
- giù
- guida
- durante
- ogni
- editore
- Efficace
- efficacia
- enable
- fine
- da un capo all'altro
- endemico
- accrescere
- abbastanza
- eric
- particolarmente
- essential
- essenziali
- stabilire
- Etere (ETH)
- la valutazione
- Anche
- Ogni
- esempio
- esecuzione
- esecutivo
- esistente
- previsto
- fatto
- Fattori
- FAIL
- Fallimento
- lontano
- Piedi
- pochi
- campo
- seguire
- Nel
- forza
- Ex
- fondatore
- Contesto
- Gratis
- liberamente
- amichevole
- da
- futuro
- guadagnato
- Generale
- generalmente
- ottenere
- ottenere
- Obiettivi
- grande
- Happening
- Avere
- he
- Eroe
- Aiuto
- lui
- il suo
- Come
- HTML
- http
- HTTPS
- Montatura
- i
- IBM
- importante
- competenze
- miglioramento
- in
- inizio
- Compreso
- inclusione
- industria
- leader del settore
- iniziativa
- iniziative
- intuizioni
- destinato
- ai miglioramenti
- introdurre
- ISN
- IT
- SUO
- ad appena
- solo uno
- karl
- KDnuggets
- Le
- Nota fondamentale
- Genere
- Sapere
- conoscenze
- carente
- maggiore
- Cognome
- L'anno scorso
- portare
- capi
- Leadership
- principale
- apprendimento
- Bugia
- piace
- Lista
- ll
- Perde
- perso
- macchina
- machine learning
- Principale
- make
- FA
- Fare
- direttore
- I gestori
- modo
- molti
- La padronanza della
- significare
- significava
- misurare
- misurato
- Metrica
- Siti di estrazione mineraria
- CON
- ML
- modello
- modelli
- Scopri di più
- maggior parte
- soprattutto
- molti
- multiplo
- devono obbligatoriamente:
- my
- Bisogno
- esigenze
- New
- notizie
- no
- adesso
- of
- di frequente
- on
- ONE
- quelli
- esclusivamente
- operativa
- Operazioni
- or
- minimo
- organizzazione
- su
- Packages
- pagina
- parte
- partecipare
- Paves
- perfezione
- performance
- esegue
- persona
- prospettiva
- previsto
- Platone
- Platone Data Intelligence
- PlatoneDati
- spina
- Popolare
- posizione
- positivo
- potenziale
- energia
- pratica
- pre-ordine
- Prezioso
- precisamente
- predire
- Previsioni
- predice
- presentata
- Presidente
- pressione
- piuttosto
- processi
- i processi
- Prodotto
- Scelto dai professionisti
- Insegnante
- progetto
- progetti
- promesso
- Dimostra
- comprovata
- Pubblicazione
- Pubblica
- scopo
- mette
- Mettendo
- domanda
- Domande
- Rampa
- rampante
- classifica
- RARO
- rapporto
- raggiungere
- realizzato
- riconoscere
- resti
- Report
- intervistati
- Risultati
- problemi
- Le vendite
- rivoluzionario
- destra
- Roccioso
- ROI
- di routine
- Correre
- s
- sicura
- Suddetto
- stesso
- dire
- Scala
- di moto
- Scienze
- Scienziato
- scienziati
- Serie
- servire
- servito
- serve
- servizio
- Sette
- condiviso
- significativa
- da
- So
- Social
- Software
- alcuni
- Speaker
- Spin
- sponsorizzazione
- tappe
- delle parti interessate
- stakeholder
- inizia a
- deriva
- Ancora
- Lotta
- Gli studenti
- il successo
- di successo
- Con successo
- tale
- SOMMARIO
- Indagine
- Sweep
- T
- mirata
- Insegnamento
- Consulenza
- Tecnologia
- dire
- condizioni
- di
- che
- Il
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tre
- per tutto
- così
- tempo
- a
- strumenti
- argomento
- veramente
- seconda
- in definitiva
- per
- capire
- comprensibile
- Università
- Università
- su
- utilizzato
- inaugurando
- generalmente
- APPREZZIAMO
- Ve
- molto
- via
- Visualizza
- visibilità
- importantissima
- Prima
- Modo..
- settimana
- pesare
- WELL
- Che
- quando
- quale
- while
- OMS
- perché
- Selvaggio
- volere
- con
- senza
- Ha vinto
- meraviglia
- Lavora
- sarebbe
- scritto
- anno
- ancora
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro