Immagine dell'autore
In questo post esploreremo il nuovo modello open source all'avanguardia chiamato Mixtral 8x7b. Impareremo anche come accedervi utilizzando la libreria LLaMA C++ e come eseguire modelli linguistici di grandi dimensioni con elaborazione e memoria ridotte.
Mixtral 8x7b è un modello di miscela sparsa di esperti (SMoE) di alta qualità con pesi aperti, creato da Mistral AI. È concesso in licenza con Apache 2.0 e supera Llama 2 70B sulla maggior parte dei benchmark pur avendo un'inferenza 6 volte più veloce. Mixtral eguaglia o batte GPT3.5 sulla maggior parte dei benchmark standard ed è il miglior modello open-weight in termini di costo/prestazioni.
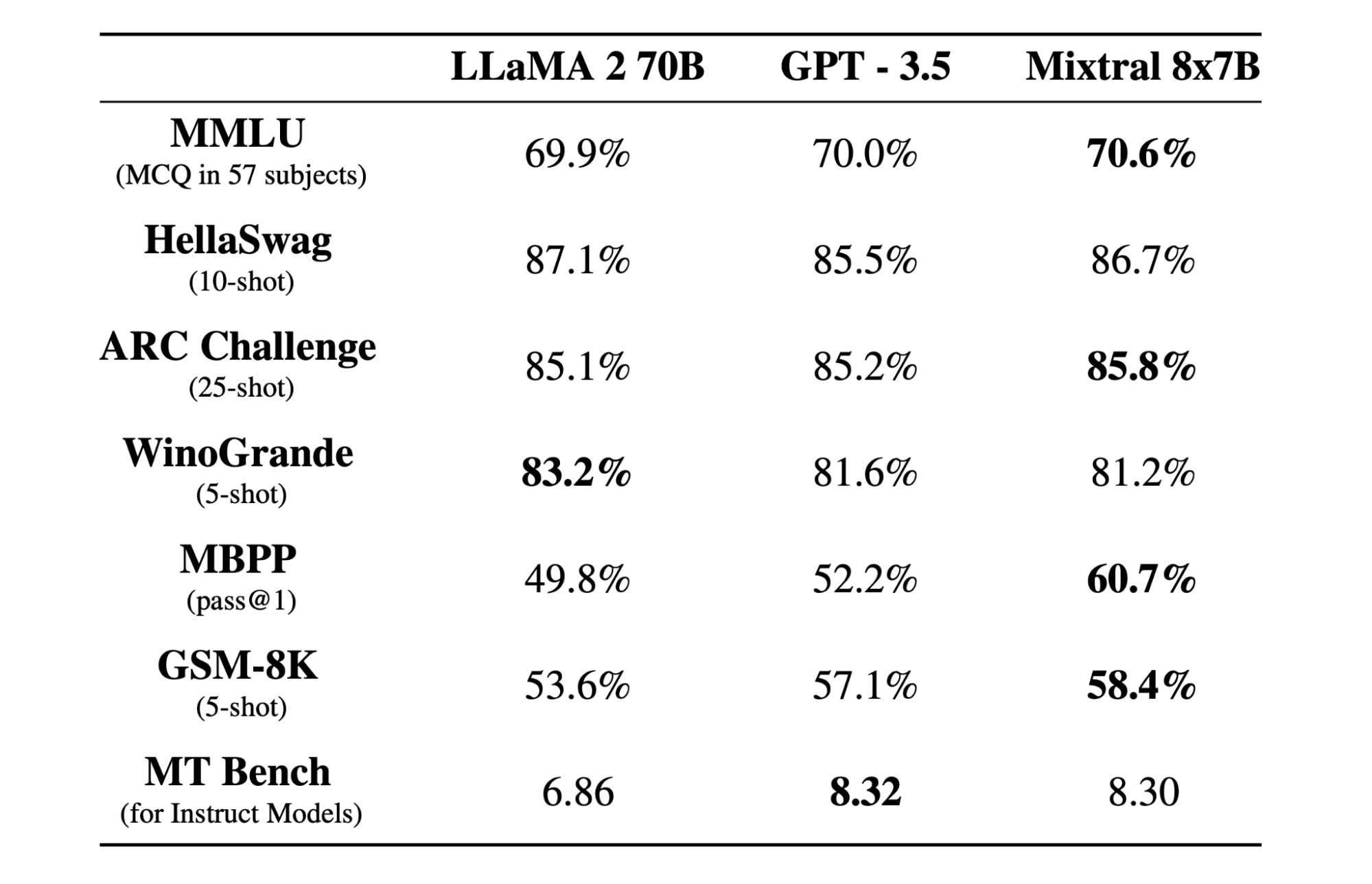
Immagine da Mixtral di esperti
Mixtral 8x7B utilizza una rete sparsa di esperti composta solo da decoder. Ciò comporta un blocco feedforward che seleziona tra 8 gruppi di parametri, con una rete di router che sceglie due di questi gruppi per ciascun token, combinando i loro output in modo additivo. Questo metodo migliora il conteggio dei parametri del modello gestendo al tempo stesso costi e latenza, rendendolo efficiente quanto un modello da 12.9 miliardi, nonostante abbia 46.7 miliardi di parametri totali.
Il modello Mixtral 8x7B eccelle nella gestione di un ampio contesto di token da 32 e supporta più lingue, tra cui inglese, francese, italiano, tedesco e spagnolo. Dimostra ottime prestazioni nella generazione di codice e può essere ottimizzato in un modello che segue le istruzioni, ottenendo punteggi elevati su benchmark come MT-Bench.
LLaMA.cpp è una libreria C/C++ che fornisce un'interfaccia ad alte prestazioni per modelli linguistici di grandi dimensioni (LLM) basati sull'architettura LLM di Facebook. È una libreria leggera ed efficiente che può essere utilizzata per una varietà di attività, tra cui la generazione di testo, la traduzione e la risposta a domande. LLaMA.cpp supporta un'ampia gamma di LLM, tra cui LLaMA, LLaMA 2, Falcon, Alpaca, Mistral 7B, Mixtral 8x7B e GPT4ALL. È compatibile con tutti i sistemi operativi e può funzionare sia su CPU che su GPU.
In questa sezione eseguiremo l'applicazione web llama.cpp su Colab. Scrivendo poche righe di codice potrai sperimentare le prestazioni del nuovo modello all'avanguardia sul tuo PC o su Google Colab.
Iniziamo
Innanzitutto, scaricheremo il repository GitHub llama.cpp utilizzando la riga di comando seguente:
!git clone --depth 1 https://github.com/ggerganov/llama.cpp.gitSuccessivamente, cambieremo la directory nel repository e installeremo llama.cpp utilizzando il comando `make`. Stiamo installando llama.cpp per la GPU NVidia con CUDA installato.
%cd llama.cpp
!make LLAMA_CUBLAS=1Scarica il modello
Possiamo scaricare il modello da Hugging Face Hub selezionando la versione appropriata del file del modello `.gguf`. Maggiori informazioni sulle varie versioni sono disponibili in TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF.
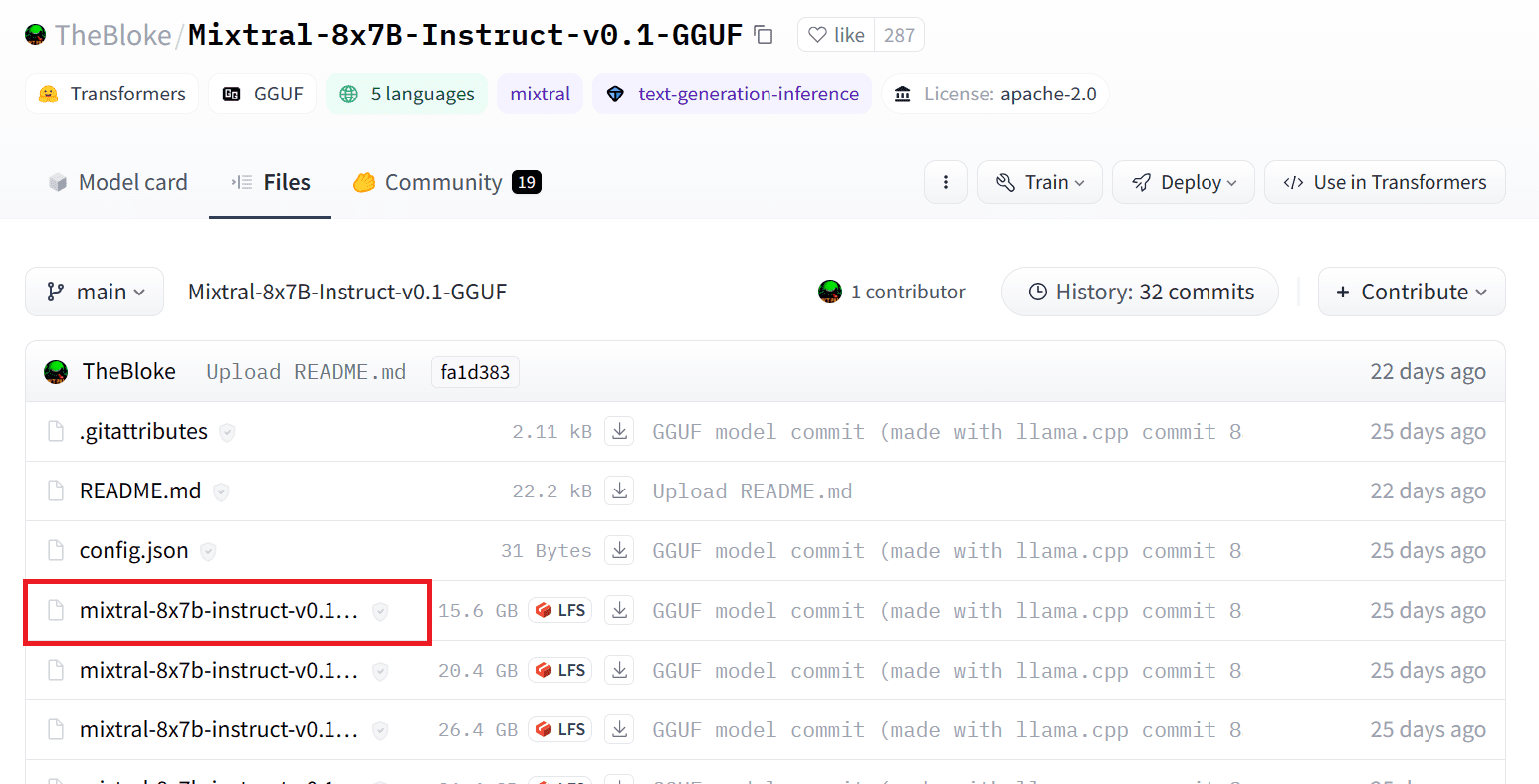
Immagine da TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF
Puoi utilizzare il comando "wget" per scaricare il modello nella directory corrente.
!wget https://huggingface.co/TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF/resolve/main/mixtral-8x7b-instruct-v0.1.Q2_K.ggufIndirizzo esterno per il server LLaMA
Quando eseguiamo il server LLaMA ci fornirà un IP localhost che è inutile per noi su Colab. Abbiamo bisogno della connessione al proxy localhost utilizzando la porta proxy del kernel Colab.
Dopo aver eseguito il codice seguente, otterrai il collegamento ipertestuale globale. Utilizzeremo questo collegamento per accedere alla nostra webapp in un secondo momento.
from google.colab.output import eval_js
print(eval_js("google.colab.kernel.proxyPort(6589)"))
https://8fx1nbkv1c8-496ff2e9c6d22116-6589-colab.googleusercontent.com/Esecuzione del server
Per eseguire il server LLaMA C++, è necessario fornire al comando del server il percorso del file del modello e il numero di porta corretto. È importante assicurarsi che il numero di porta corrisponda a quello che abbiamo avviato nel passaggio precedente per la porta proxy.
%cd /content/llama.cpp
!./server -m mixtral-8x7b-instruct-v0.1.Q2_K.gguf -ngl 27 -c 2048 --port 6589
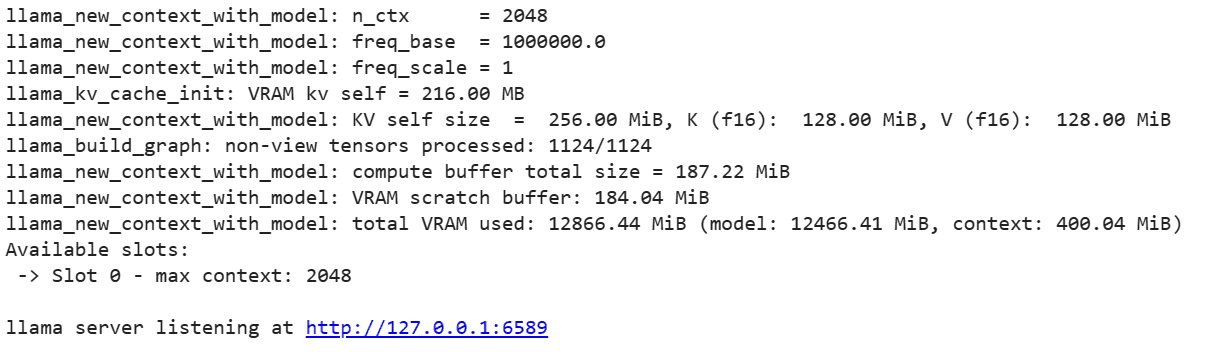
È possibile accedere alla webapp di chat facendo clic sul collegamento ipertestuale della porta proxy nel passaggio precedente poiché il server non è in esecuzione localmente.
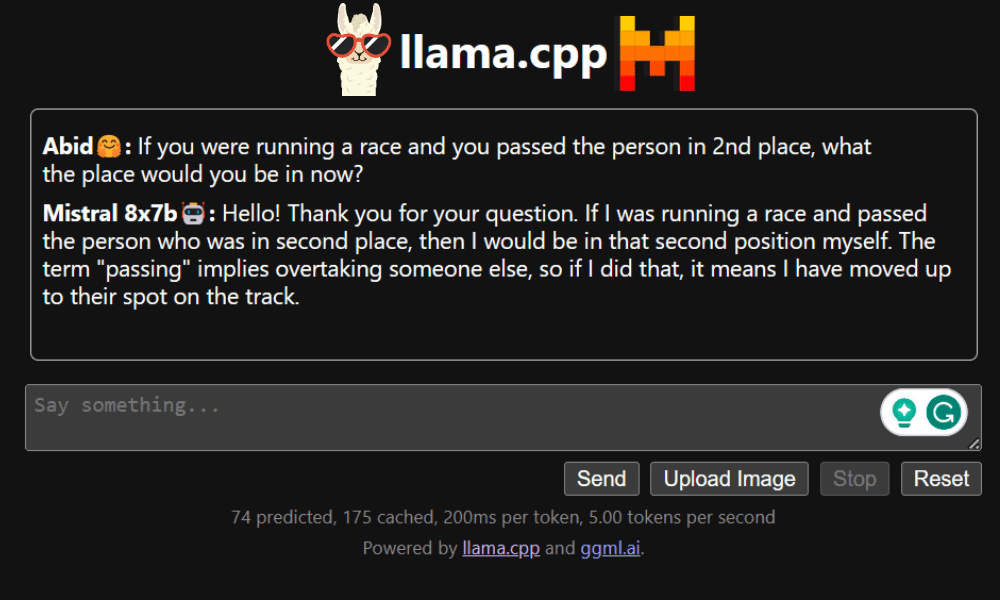
Applicazione Web LLaMA C++
Prima di iniziare a utilizzare il chatbot, dobbiamo personalizzarlo. Sostituisci "LLaMA" con il nome del tuo modello nella sezione prompt. Inoltre, modifica il nome utente e il nome del bot per distinguere tra le risposte generate.
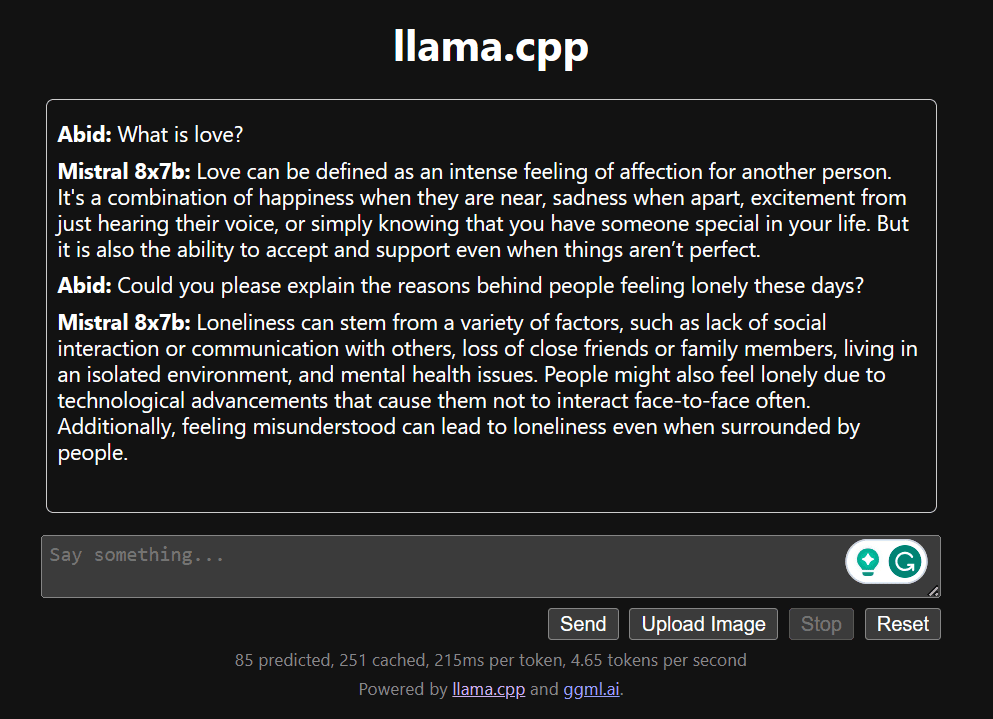
Inizia a chattare scorrendo verso il basso e digitando nella sezione chat. Sentiti libero di porre domande tecniche a cui altri modelli open source non sono riusciti a rispondere adeguatamente.
Se riscontri problemi con l'app, puoi provare a eseguirla da solo utilizzando il mio Google Colab: https://colab.research.google.com/drive/1gQ1lpSH-BhbKN-DdBmq5r8-8Rw8q1p9r?usp=sharing
Questo tutorial fornisce una guida completa su come eseguire il modello open source avanzato, Mixtral 8x7b, su Google Colab utilizzando la libreria LLaMA C++. Rispetto ad altri modelli, Mixtral 8x7b offre prestazioni ed efficienza superiori, rendendolo un'ottima soluzione per coloro che desiderano sperimentare modelli linguistici di grandi dimensioni ma non dispongono di ampie risorse computazionali. Puoi eseguirlo facilmente sul tuo laptop o su un cloud computing gratuito. È facile da usare e puoi persino distribuire la tua app di chat affinché altri possano utilizzarla e sperimentarla.
Spero che tu abbia trovato utile questa semplice soluzione per eseguire il modello di grandi dimensioni. Sono sempre alla ricerca di opzioni semplici e migliori. Se hai una soluzione ancora migliore, faccelo sapere e ne parlerò la prossima volta.
Abid Ali Awan (@1abidaliawan) è un professionista di data scientist certificato che ama creare modelli di machine learning. Attualmente si sta concentrando sulla creazione di contenuti e sulla scrittura di blog tecnici sulle tecnologie di apprendimento automatico e scienza dei dati. Abid ha conseguito un Master in Technology Management e una laurea in Ingegneria delle Telecomunicazioni. La sua visione è quella di costruire un prodotto di intelligenza artificiale utilizzando una rete neurale grafica per studenti alle prese con malattie mentali.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/running-mixtral-8x7b-on-google-colab-for-free?utm_source=rss&utm_medium=rss&utm_campaign=running-mixtral-8x7b-on-google-colab-for-free
- :È
- :non
- 1
- 12
- 27
- 46
- 7
- 8
- a
- capace
- accesso
- accessibile
- il raggiungimento
- Inoltre
- indirizzo
- Avanzate
- AI
- Tutti
- anche
- sempre
- am
- an
- ed
- rispondere
- Apache
- App
- Applicazioni
- opportuno
- architettura
- SONO
- AS
- chiedere
- basato
- BE
- iniziare
- sotto
- parametri di riferimento
- MIGLIORE
- Meglio
- fra
- Bloccare
- blog
- Bot
- entrambi
- costruire
- Costruzione
- ma
- by
- C++
- detto
- Materiale
- Certificato
- il cambiamento
- chiacchierare
- chatbot
- chat
- la scelta
- Cloud
- codice
- combinando
- rispetto
- compatibile
- globale
- computazionale
- Calcolare
- informatica
- veloce
- contenuto
- creazione di contenuti
- contesto
- correggere
- Costo
- coprire
- creato
- creazione
- Corrente
- Attualmente
- personalizzare
- dati
- scienza dei dati
- scienziato di dati
- Laurea
- fornisce un monitoraggio
- dimostra
- schierare
- Nonostante
- distinguere
- do
- giù
- scaricare
- ogni
- facilmente
- efficienza
- efficiente
- incontrare
- Ingegneria
- Inglese
- Migliora
- Anche
- eccellente
- esperienza
- esperimento
- esperti
- esplora
- estensivo
- Faccia
- fallito
- falco
- più veloce
- sentire
- pochi
- Compila il
- messa a fuoco
- Nel
- essere trovato
- Gratis
- Francese
- da
- function
- generato
- ELETTRICA
- Tedesco
- ottenere
- GitHub
- Dare
- globali
- GPU
- GPU
- grafico
- Grafico rete neurale
- Gruppo
- guida
- Manovrabilità
- Avere
- avendo
- he
- utile
- Alta
- Alte prestazioni
- alta qualità
- il suo
- detiene
- speranza
- Come
- Tutorial
- HTTPS
- Hub
- i
- if
- malattia
- importare
- importante
- in
- Compreso
- informazioni
- avviato
- install
- installazione
- Interfaccia
- ai miglioramenti
- comporta
- IP
- sicurezza
- IT
- Italiano
- KDnuggets
- Sapere
- Lingua
- Le Lingue
- laptop
- grandi
- Latenza
- dopo
- IMPARARE
- apprendimento
- lasciare
- Biblioteca
- Autorizzato
- leggero
- piace
- linea
- Linee
- LINK
- Lama
- a livello locale
- località
- cerca
- ama
- macchina
- machine learning
- make
- Fare
- gestione
- gestione
- Mastercard
- fiammiferi
- me
- Memorie
- mentale
- Malattia mentale
- metodo
- miscela
- modello
- modelli
- modificare
- Scopri di più
- maggior parte
- multiplo
- my
- Nome
- Bisogno
- Rete
- Neurale
- rete neurale
- New
- GENERAZIONE
- numero
- Nvidia
- of
- on
- ONE
- aprire
- open source
- operativo
- sistemi operativi
- Opzioni
- or
- Altro
- Altri
- nostro
- Sorpassa
- produzione
- uscite
- proprio
- parametro
- parametri
- PC
- performance
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- Post
- precedente
- Prodotto
- professionale
- propriamente
- fornire
- fornisce
- delega
- domanda
- Domande
- gamma
- Ridotto
- per quanto riguarda
- sostituire
- deposito
- riparazioni
- Risorse
- risposte
- router
- Correre
- running
- s
- Scienze
- Scienziato
- punteggi
- scrolling
- Sezione
- Selezione
- server
- Un'espansione
- da
- soluzione
- Fonte
- Spagnolo
- Standard
- state-of-the-art
- step
- forte
- Lottando
- Gli studenti
- superiore
- supporti
- sicuro
- SISTEMI DI TRATTAMENTO
- task
- Consulenza
- Tecnologie
- Tecnologia
- telecomunicazione
- testo
- generazione di testo
- che
- Il
- loro
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- quelli
- tempo
- a
- token
- Tokens
- Totale
- Traduzione
- prova
- lezione
- seconda
- per
- us
- uso
- utilizzato
- Utente
- user-friendly
- usa
- utilizzando
- varietà
- vario
- versione
- visione
- volere
- we
- sito web
- applicazione web
- quale
- while
- OMS
- largo
- Vasta gamma
- volere
- con
- scrittura
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro