Migliorare il modo in cui gli utenti scoprono nuovi contenuti è fondamentale per aumentare il coinvolgimento e la soddisfazione degli utenti sulle piattaforme multimediali. La sola ricerca per parole chiave presenta difficoltà nel catturare la semantica e l’intento dell’utente, portando a risultati privi di contesto pertinente; ad esempio, trovare appuntamenti serali o film a tema natalizio. Ciò può ridurre i tassi di fidelizzazione se gli utenti non riescono a trovare in modo affidabile il contenuto che desiderano. Tuttavia, con modelli linguistici di grandi dimensioni (LLM), esiste l'opportunità di risolvere queste sfide semantiche e di intenti dell'utente. Combinando incastri che catturano la semantica con una tecnica chiamata Recupero della generazione aumentata (RAG), puoi generare risposte più pertinenti in base al contesto recuperato dalle tue origini dati.
In questo post, ti mostriamo come creare in modo sicuro un chatbot cinematografico implementando RAG con i tuoi dati Basi di conoscenza per Roccia Amazzonica. Utilizziamo il set di dati IMDb e Box Office Mojo per simulare un catalogo per i clienti dei media e dell'intrattenimento e mostrare come creare la propria soluzione RAG in un paio di passaggi.
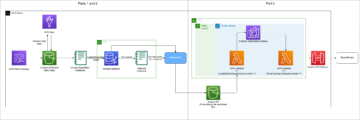
Panoramica della soluzione
I IMDb e Box Office Mojo Film/TV/OTT il pacchetto di dati con licenza fornisce un'ampia gamma di metadati di intrattenimento, tra cui oltre 1.6 miliardo di valutazioni degli utenti; crediti per oltre 13 milioni di membri del cast e della troupe; 10 milioni di titoli cinematografici, televisivi e di intrattenimento; e dati di reporting al botteghino globale di oltre 60 paesi. Molti clienti AWS nel settore dei media e dell'intrattenimento concedono in licenza i dati di IMDb Scambio di dati AWS per migliorare la scoperta dei contenuti e aumentare il coinvolgimento e la fidelizzazione dei clienti.
Introduzione alle basi di conoscenza per Amazon Bedrock
Per dotare un LLM di informazioni proprietarie aggiornate, le organizzazioni utilizzano RAG, una tecnica che prevede il recupero di dati da fonti di dati aziendali e l'arricchimento del prompt con tali dati per fornire risposte più pertinenti e accurate. Le basi di conoscenza per Amazon Bedrock abilitano una funzionalità RAG completamente gestita che consente di personalizzare le risposte LLM con dati aziendali contestuali e pertinenti. Le basi di conoscenza automatizzano il flusso di lavoro RAG end-to-end, inclusi inserimento, recupero, ampliamento tempestivo e citazioni, eliminando la necessità di scrivere codice personalizzato per integrare origini dati e gestire query. Le basi di conoscenza per Amazon Bedrock consentono inoltre conversazioni a più turni in modo che LLM possa rispondere alle domande complesse degli utenti con la risposta corretta.
Utilizziamo i seguenti servizi come parte di questa soluzione:
Esaminiamo i seguenti passaggi di alto livello:
- Preelaborare i dati IMDb per creare documenti da ogni record di film e caricare i dati in un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio.
- Creare una base di conoscenza.
- Sincronizza la tua knowledge base con la tua origine dati.
- Utilizza la knowledge base per rispondere a domande semantiche sul catalogo dei film.
Prerequisiti
I dati IMDb utilizzati in questo post richiedono una licenza per contenuti commerciali e un abbonamento a pagamento a IMDb e al pacchetto di licenze Box Office Mojo Movies/TV/OTT su AWS Data Exchange. Per richiedere informazioni su una licenza e accedere a dati di esempio, visitare sviluppatore.imdb.com. Per accedere al set di dati, fare riferimento a Raccomandazione e ricerca di potenza utilizzando un grafico della conoscenza di IMDb - Parte 1 e seguire la Accedi ai dati di IMDb .
Preelaborare i dati IMDb
Prima di creare una knowledge base, dobbiamo preelaborare il set di dati IMDb in file di testo e caricarli in un bucket S3. In questo post, simuliamo un catalogo clienti utilizzando il set di dati IMDb. Prendiamo 10,000 film popolari dal set di dati IMDb per il catalogo e costruiamo il set di dati.
Utilizza il seguente taccuino per creare il set di dati con informazioni aggiuntive come attori, regista e nomi di produttori. Usiamo il seguente codice per creare un singolo file per un film con tutte le informazioni memorizzate nel file in un testo non strutturato che possa essere compreso dai LLM:
Dopo aver ottenuto i dati in formato .txt, puoi caricarli in Amazon S3 utilizzando il comando seguente:
Crea la base di conoscenza di IMDb
Completa i seguenti passaggi per creare la tua knowledge base:
- Sulla console Amazon Bedrock, scegli Knowledge Base nel pannello di navigazione.
- Scegli Crea una base di conoscenza.
- Nel Nome della base di conoscenza, accedere
imdb. - Nel Descrizione della base di conoscenza, inserisci una descrizione facoltativa, ad esempio Base di conoscenza per l'inserimento e l'archiviazione dei dati imdb.
- Nel Autorizzazioni IAM, selezionare Crea e utilizza un nuovo ruolo del servizio, quindi inserisci un nome per il tuo nuovo ruolo di servizio.
- Scegli Avanti.
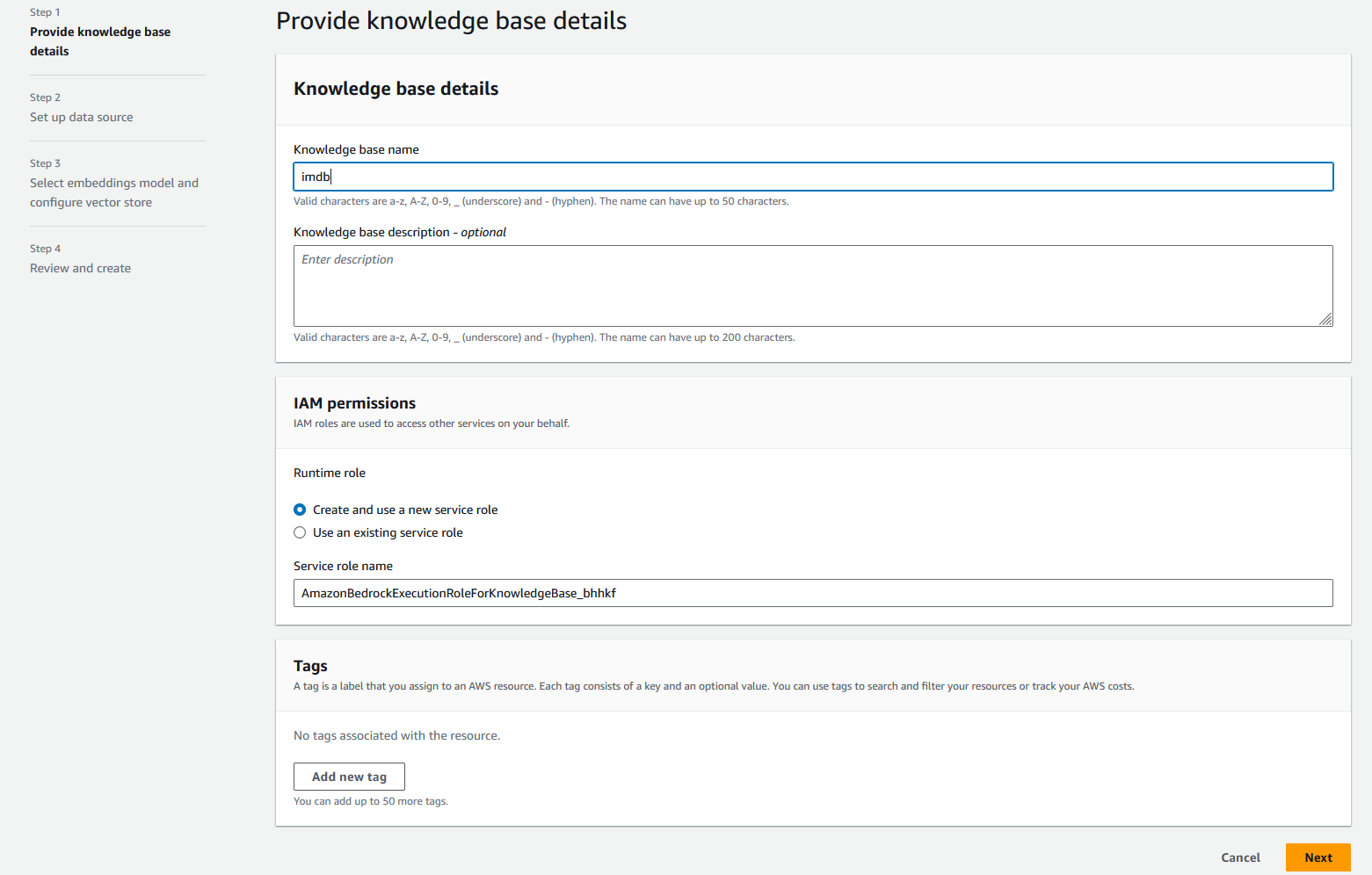
- Nel Nome dell'origine dati, accedere
imdb-s3. - Nel URI S3, inserisci l'URI S3 in cui hai caricato i dati.
- Nel Impostazioni avanzate – facoltativo sezione, per Strategia di suddivisione in blocchiscegli Nessun spezzettamento.
- Scegli Avanti.
Le basi di conoscenza ti consentono di suddividere i tuoi documenti in segmenti più piccoli per semplificare l'elaborazione di documenti di grandi dimensioni. Nel nostro caso, abbiamo già suddiviso i dati in un documento di dimensioni più piccole (uno per film).
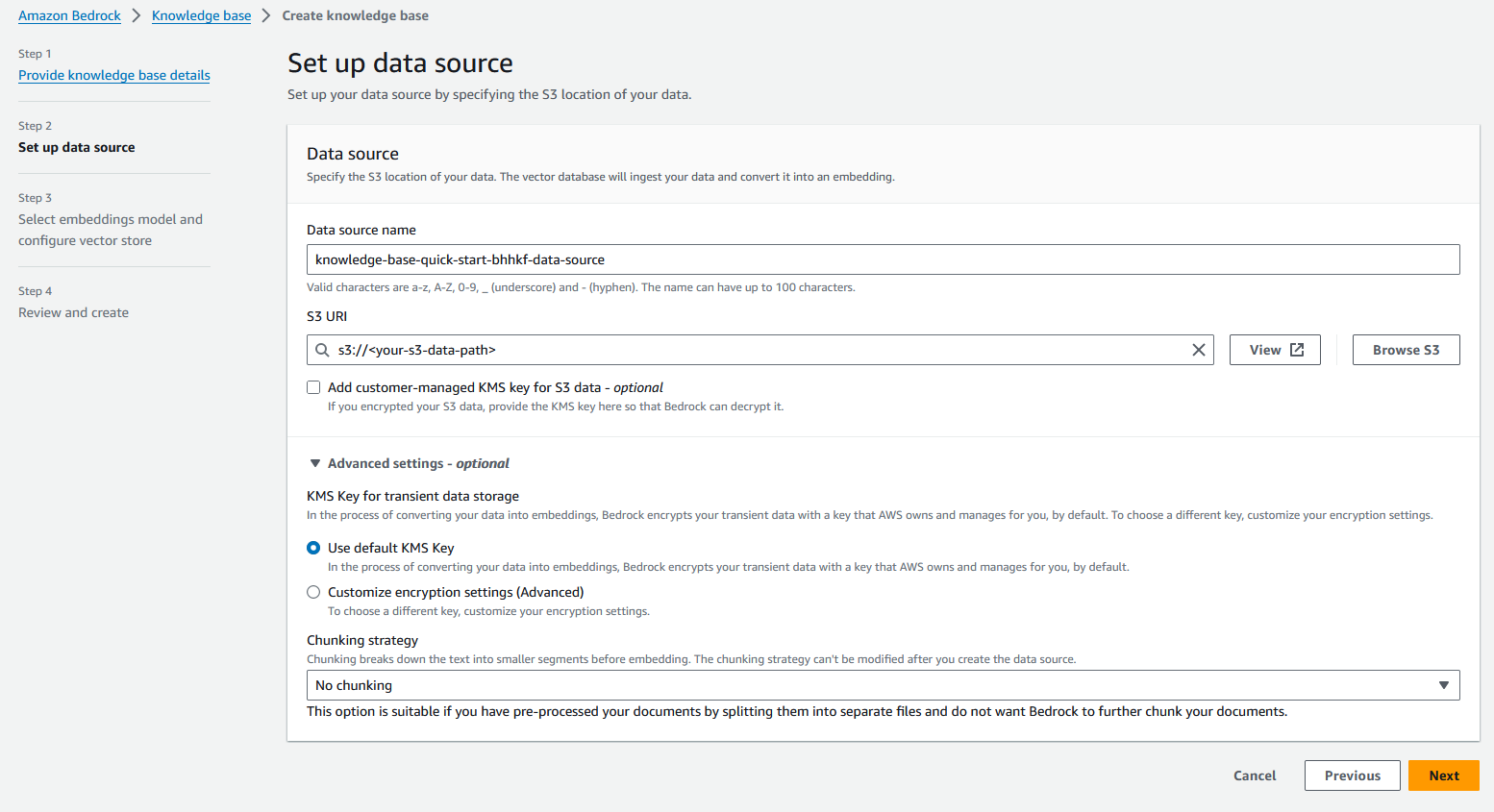
- Nel Banca dati vettoriale sezione, selezionare Crea rapidamente un nuovo archivio vettoriale.
Amazon Bedrock creerà automaticamente una raccolta di ricerca vettoriale OpenSearch Serverless completamente gestita e configurerà le impostazioni per incorporare le origini dati utilizzando il modello di incorporamento del testo Titan Embedding G1 scelto.
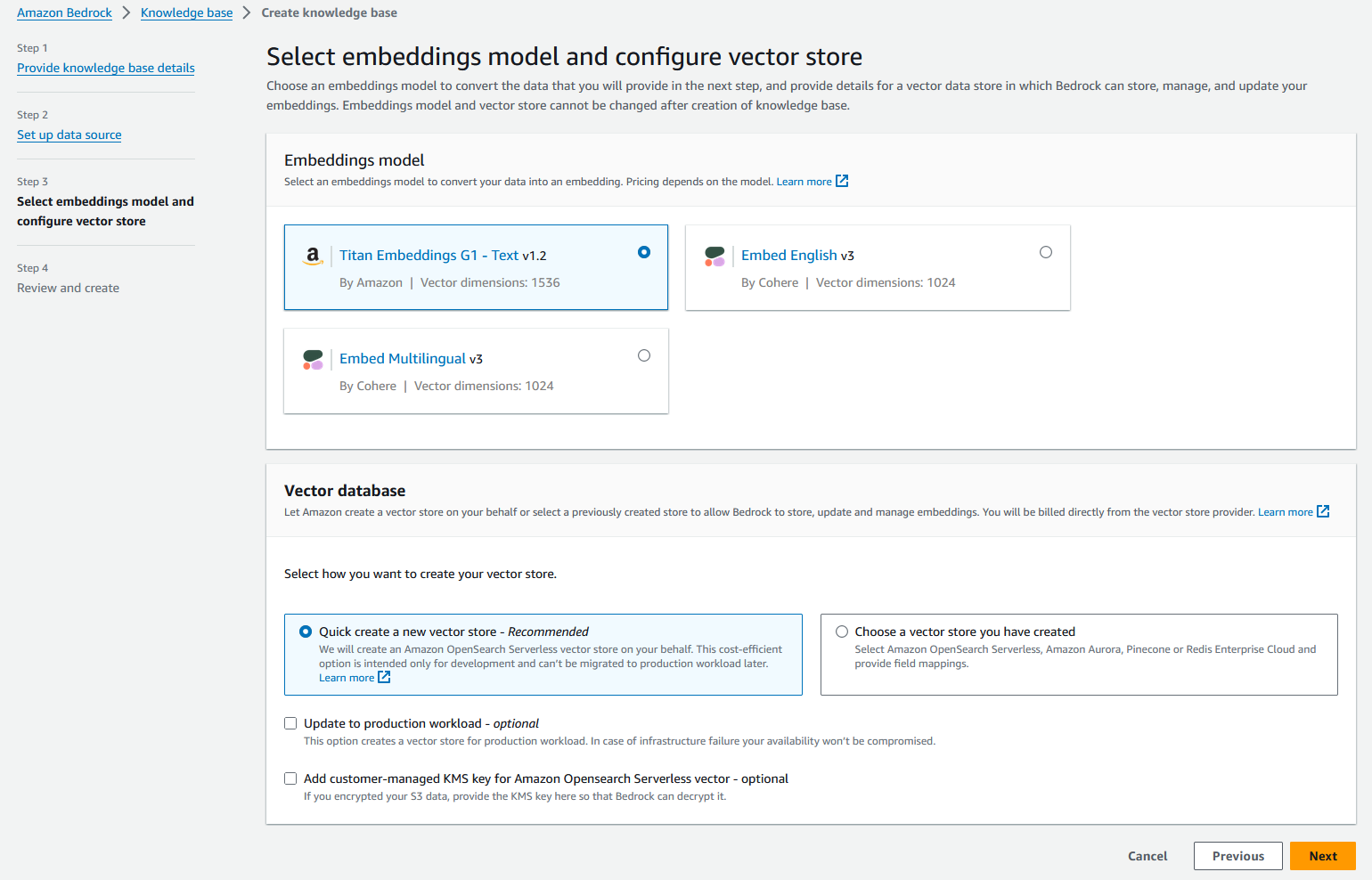
- Scegli Avanti.
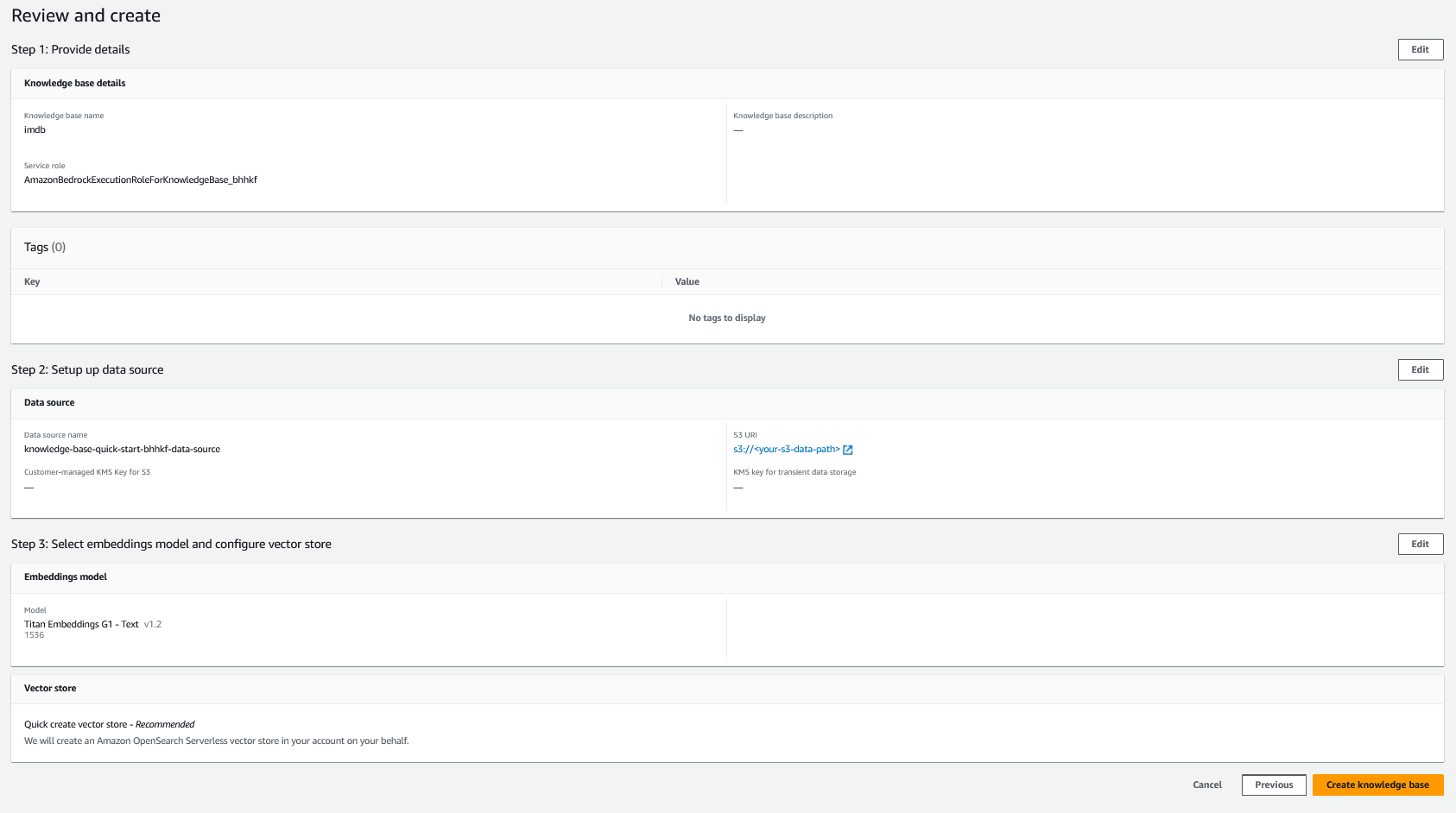
- Rivedi le tue impostazioni e scegli Crea una base di conoscenza.
Sincronizza i tuoi dati con la knowledge base
Ora che hai creato la tua knowledge base, puoi sincronizzarla con i tuoi dati.
- Nella console Amazon Bedrock, accedi alla tua knowledge base.
- Nel Fonte di dati sezione, scegliere Sincronizza.

Una volta sincronizzata l'origine dati, sei pronto per eseguire query sui dati.
Migliora la ricerca utilizzando risultati semantici
Completa i seguenti passaggi per testare la soluzione e migliorare la tua ricerca utilizzando risultati semantici:
- Nella console Amazon Bedrock, accedi alla tua knowledge base.
- Seleziona la tua knowledge base e scegli Testare la base di conoscenza.
- Scegli Seleziona il modelloe scegli Claude antropico v2.1.
- Scegli APPLICA.
Ora sei pronto per interrogare i dati.
Possiamo porre alcune domande semantiche, come “Consigliami alcuni film a tema natalizio”.
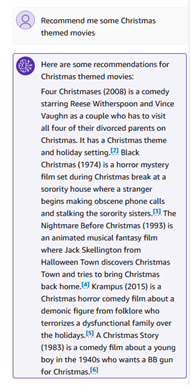
Le risposte della Knowledge Base contengono citazioni che puoi esplorare per verificarne la correttezza e la fattualità.
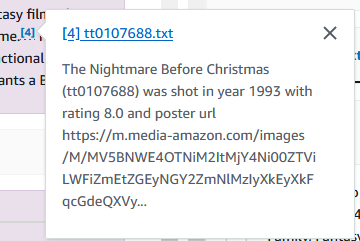
Puoi anche approfondire tutte le informazioni di cui hai bisogno da questi film. Nell’esempio seguente, chiediamo “chi ha diretto Nightmare Before Christmas?”

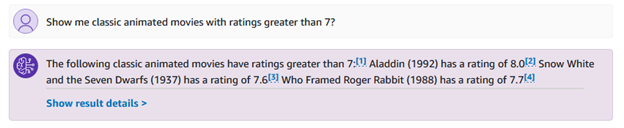
Puoi anche porre domande più specifiche relative ai generi e alle valutazioni, ad esempio "mostrami film d'animazione classici con valutazioni superiori a 7?"
Aumenta la tua base di conoscenza con gli agenti
Agenti per Amazon Bedrock aiutarti ad automatizzare attività complesse. Gli agenti possono suddividere la query dell'utente in attività più piccole e richiamare API personalizzate o basi di conoscenza per integrare le informazioni per l'esecuzione delle azioni. Con Agenti per Amazon Bedrock, gli sviluppatori possono integrare agenti intelligenti nelle loro app, accelerando la distribuzione di applicazioni basate sull'intelligenza artificiale e risparmiando settimane di tempo di sviluppo. Con gli agenti, puoi ampliare la tua knowledge base aggiungendo ulteriori funzionalità come i consigli da Amazon Personalizza per consigli specifici dell'utente o per eseguire azioni come filtrare i film in base alle esigenze dell'utente.
Conclusione
In questo post, abbiamo mostrato come creare un chatbot conversazionale per film utilizzando Amazon Bedrock in pochi passaggi per rispondere alla ricerca semantica e alle esperienze di conversazione basate sui tuoi dati e sul set di dati con licenza IMDb e Box Office Mojo Movies/TV/OTT. Nel prossimo post esamineremo il processo di aggiunta di ulteriori funzionalità alla tua soluzione utilizzando gli agenti per Amazon Bedrock. Per iniziare con le basi di conoscenza su Amazon Bedrock, fare riferimento a Basi di conoscenza per Amazon Bedrock.
Informazioni sugli autori
 Gaurav Relé è Senior Data Scientist presso il Generative AI Innovation Center, dove lavora con i clienti AWS di diversi settori verticali per accelerare il loro utilizzo dell'intelligenza artificiale generativa e dei servizi cloud AWS per risolvere le loro sfide aziendali.
Gaurav Relé è Senior Data Scientist presso il Generative AI Innovation Center, dove lavora con i clienti AWS di diversi settori verticali per accelerare il loro utilizzo dell'intelligenza artificiale generativa e dei servizi cloud AWS per risolvere le loro sfide aziendali.
 Divya Bhargavi è Senior Applied Scientist Lead presso il Generative AI Innovation Center, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando metodi di intelligenza artificiale generativa. Lavora sulla comprensione e sul recupero di immagini/video, modelli linguistici di grandi dimensioni con knowledge graph e casi d'uso di pubblicità personalizzata.
Divya Bhargavi è Senior Applied Scientist Lead presso il Generative AI Innovation Center, dove risolve problemi aziendali di alto valore per i clienti AWS utilizzando metodi di intelligenza artificiale generativa. Lavora sulla comprensione e sul recupero di immagini/video, modelli linguistici di grandi dimensioni con knowledge graph e casi d'uso di pubblicità personalizzata.
 Suren Gunturu è un Data Scientist che lavora nel Generative AI Innovation Center, dove collabora con vari clienti AWS per risolvere problemi aziendali di alto valore. È specializzato nella creazione di pipeline ML utilizzando modelli linguistici di grandi dimensioni, principalmente tramite Amazon Bedrock e altri servizi cloud AWS.
Suren Gunturu è un Data Scientist che lavora nel Generative AI Innovation Center, dove collabora con vari clienti AWS per risolvere problemi aziendali di alto valore. È specializzato nella creazione di pipeline ML utilizzando modelli linguistici di grandi dimensioni, principalmente tramite Amazon Bedrock e altri servizi cloud AWS.
 Vidya Sagar Ravipati è Science Manager presso il Generative AI Innovation Center, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'intelligenza artificiale e del cloud.
Vidya Sagar Ravipati è Science Manager presso il Generative AI Innovation Center, dove sfrutta la sua vasta esperienza nei sistemi distribuiti su larga scala e la sua passione per l'apprendimento automatico per aiutare i clienti AWS in diversi settori verticali ad accelerare l'adozione dell'intelligenza artificiale e del cloud.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- :ha
- :È
- :Dove
- $10 milioni
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- Chi siamo
- accelerare
- accelerando
- accesso
- preciso
- operanti in
- azioni
- attori
- l'aggiunta di
- aggiuntivo
- Adozione
- Pubblicità
- agenti
- AI
- AI-alimentato
- Tutti
- consente
- da solo
- già
- anche
- Amazon
- Amazon Web Services
- an
- ed
- rispondere
- risposte
- in qualsiasi
- API
- applicazioni
- applicato
- applicazioni
- SONO
- AS
- chiedere
- At
- aumentare
- aumentata
- automatizzare
- automaticamente
- AWS
- base
- basato
- BE
- prima
- Miliardo
- Scatola
- botteghino
- Rompere
- costruire
- Costruzione
- affari
- by
- chiamata
- detto
- Materiale
- capacità
- catturare
- Catturare
- Custodie
- casi
- catalogo
- centro
- sfide
- chatbot
- Scegli
- scelto
- Natale
- classico
- Cloud
- adozione del cloud
- servizi cloud
- codice
- collezione
- combinando
- azienda
- complesso
- consolle
- contenere
- contenuto
- contesto
- contestuale
- discorsivo
- Conversazioni
- correggere
- paesi
- Coppia
- creare
- creato
- Crediti
- equipaggio
- critico
- costume
- cliente
- Il coinvolgimento del cliente
- Clienti
- personalizzare
- dati
- Scambio di dati
- scienziato di dati
- Data
- consegnare
- consegna
- descrizione
- dettagli
- sviluppatori
- Mercato
- diverso
- indirizzato
- Direttore
- Amministrazione
- scopri
- scoperta
- distribuito
- sistemi distribuiti
- documento
- documenti
- giù
- guidare
- eliminando
- incorporamento
- enable
- da un capo all'altro
- Fidanzamento
- arricchendo
- entrare
- Intrattenimento
- Etere (ETH)
- Ogni
- esempio
- exchange
- esperienza
- Esperienze
- esplora
- pochi
- Compila il
- File
- filtraggio
- Trovare
- ricerca
- seguire
- i seguenti
- Nel
- formato
- da
- completamente
- funzionalità
- g1
- generare
- ELETTRICA
- generativo
- AI generativa
- generi
- ottenere
- globali
- Go
- grafico
- maggiore
- Avere
- he
- Aiuto
- alto livello
- il suo
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- if
- Implementazione
- competenze
- in
- Compreso
- Aumento
- industria
- info
- informazioni
- Innovazione
- chiedere informazioni
- integrare
- Intelligente
- intento
- ai miglioramenti
- comporta
- IT
- jpg
- ad appena
- conoscenze
- Dipingere
- Lingua
- grandi
- larga scala
- portare
- principale
- apprendimento
- leveraggi
- Licenza
- Autorizzato
- Licenze
- piace
- lm
- locale
- località
- inferiore
- macchina
- machine learning
- make
- gestire
- gestito
- direttore
- molti
- me
- Media
- Utenti
- Metadati
- metodi
- milione
- ML
- modello
- modelli
- mojo
- Scopri di più
- film
- Film
- Nome
- nomi
- Navigare
- Navigazione
- Bisogno
- esigenze
- New
- GENERAZIONE
- notte
- of
- Office
- on
- ONE
- Opportunità
- or
- organizzazioni
- Altro
- nostro
- ancora
- proprio
- pacchetto
- pagina
- pagato
- vetro
- parte
- passione
- sentiero
- per
- esecuzione
- Personalizzata
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- trama
- Popolare
- Post
- poster
- principalmente
- problemi
- processi
- produttore
- Produttori
- proprio
- fornisce
- query
- domanda
- Domande
- straccio
- gamma
- valutazione
- valutazioni
- pronto
- raccomandare
- Consigli
- raccomandazioni
- record
- riferimento
- relazionato
- pertinente
- Reportistica
- richiede
- risposta
- risposte
- Risultati
- ritenzione
- richiamo
- ritorno
- Ruolo
- RIGA
- running
- soddisfazione
- risparmio
- Scienze
- Scienziato
- Cerca
- Sezione
- in modo sicuro
- segmenti
- select
- semantico
- semantica
- anziano
- serverless
- servizio
- Servizi
- impostazioni
- lei
- tiro
- mostrare attraverso le sue creazioni
- vetrina
- ha mostrato
- Un'espansione
- simulare
- singolo
- Taglia
- inferiore
- So
- soluzione
- RISOLVERE
- risolve
- alcuni
- Fonte
- fonti
- specializzata
- specifico
- iniziato
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- lineare
- sottoscrizione
- tale
- integrare
- sync.
- SISTEMI DI TRATTAMENTO
- Fai
- task
- per l'esame
- test
- testo
- di
- che
- I
- le informazioni
- loro
- Li
- a tema
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- Attraverso
- tempo
- titano
- titoli
- a
- tv
- e una comprensione reciproca
- inteso
- non strutturati
- up-to-date
- caricato
- URI
- URL
- uso
- utilizzato
- Utente
- utenti
- utilizzando
- vario
- Fisso
- verticali
- Visita
- W
- camminare
- volere
- Prima
- we
- sito web
- servizi web
- Settimane
- largo
- Vasta gamma
- volere
- con
- flusso di lavoro
- lavoro
- lavori
- scrivere
- X
- anno
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro