Nella posta Presentazione dello strumento TCO del kit di distribuzione della migrazione Hadoop di AWS ProServe, abbiamo introdotto lo strumento TCO AWS ProServe Hadoop Migration Delivery Kit (HMDK) e i vantaggi della migrazione dei carichi di lavoro Hadoop locali a Amazon EMR. In questo post, approfondiamo lo strumento, esaminando tutti i passaggi dall'importazione dei log, trasformazione, visualizzazione e progettazione dell'architettura per calcolare il TCO.
Panoramica della soluzione
Esaminiamo brevemente le caratteristiche principali dello strumento TCO HMDK. Lo strumento fornisce un raccoglitore di log YARN per connettere Hadoop Resource Manager per raccogliere i log YARN. Un analizzatore del carico di lavoro Hadoop basato su Python, chiamato analizzatore di log YARN, esamina le applicazioni Hadoop. Amazon QuickSight i dashboard mostrano i risultati dell'analizzatore. Gli stessi risultati accelerano anche la progettazione di future istanze EMR. Inoltre, un calcolatore del TCO genera la stima del TCO di un cluster EMR ottimizzato per facilitare la migrazione.
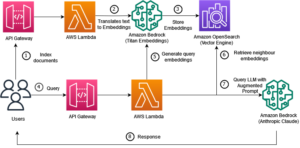
Ora diamo un'occhiata a come funziona lo strumento. Il diagramma seguente illustra il flusso di lavoro end-to-end.

Nelle sezioni successive, esaminiamo i cinque passaggi principali dello strumento:
- Raccogli i registri della cronologia dei lavori di YARN.
- Trasforma i registri della cronologia dei lavori da JSON a CSV.
- Analizzare i registri della cronologia dei lavori.
- Progetta un cluster EMR per la migrazione.
- Calcola il TCO.
Prerequisiti
Prima di iniziare, assicurati di completare i seguenti prerequisiti:
- Clona il file repository hadoop-migrazione-valutazione-tco.
- Installa Python 3 sul tuo computer locale.
- Avere un account AWS con autorizzazione attiva AWS Lambda, QuickSight (edizione Enterprise) e AWS CloudFormazione.
Raccogli i registri della cronologia dei lavori di YARN
Innanzitutto, esegui a Raccoglitore di tronchi YARN, start-collector.sh, sul tuo computer locale. Questo passaggio raccoglie i log di Hadoop YARN e li inserisce nel computer locale. Lo script connette il computer locale al nodo primario Hadoop e comunica con Resource Manager. Quindi recupera le informazioni sulla cronologia dei processi (registri YARN dai gestori delle applicazioni) chiamando l'API dell'applicazione YARN ResourceManager.
Prima di eseguire il raccoglitore di log YARN, è necessario configurare e stabilire la connessione (HTTP: 8088 o HTTPS: 8090; quest'ultimo è consigliato) per verificare l'accessibilità di YARN ResourceManager e di YARN Timeline Server abilitato (sono supportati Timeline Server v1 o successivo ). Potrebbe essere necessario definire l'intervallo di raccolta e la politica di conservazione dei log di YARN. Per assicurarti di raccogliere log YARN consecutivi, puoi utilizzare un cron job per pianificare il raccoglitore di log in un intervallo di tempo adeguato. Ad esempio, per un cluster Hadoop con 2,000 applicazioni giornaliere e l'impostazione yarn.resourcemanager.max-completed-applications impostata su 1,000, in teoria, devi eseguire il raccoglitore di log almeno due volte per ottenere tutti i log YARN. Inoltre, consigliamo di raccogliere almeno 7 giorni di log YARN per l'analisi dei carichi di lavoro olistici.
Per ulteriori dettagli su come configurare e pianificare il raccoglitore di log, fare riferimento a repository GitHub del raccoglitore di file di log.
Trasforma i log della cronologia dei lavori YARN da JSON a CSV
Dopo aver ottenuto i log YARN, esegui un organizzatore di log YARN, yarn-log-organizer.py, che è un parser per trasformare i log basati su JSON in file CSV. Questi file CSV di output sono gli input per l'analizzatore di log YARN. Il parser ha anche altre funzionalità, tra cui l'ordinamento degli eventi in base all'ora, la rimozione delle dediche e l'unione di più registri.
Per ulteriori informazioni su come utilizzare l'organizzatore di log YARN, fare riferimento a repository GitHub del file-log-organizer.
Analizza i registri della cronologia dei lavori di YARN
Successivamente, avvii l'analizzatore di log YARN per analizzare i log YARN in formato CSV.
Con QuickSight, puoi visualizzare i dati di registro YARN e condurre analisi rispetto ai set di dati generati da modelli di dashboard predefiniti e un widget. Il widget crea automaticamente dashboard QuickSight nell'account AWS di destinazione, configurato in un modello CloudFormation.
Il seguente diagramma illustra l'architettura TCO di HMDK.

L'analizzatore di log YARN fornisce quattro funzionalità chiave:
- Carica i registri della cronologia dei lavori YARN trasformati in formato CSV (ad esempio,
cluster_yarn_logs_*.csv) A Servizio di archiviazione semplice Amazon (Amazon S3) secchi. Questi file CSV sono gli output dell'organizzatore di log YARN. - Crea un file JSON manifest (ad esempio,
yarn-log-manifest.json) per QuickSight e caricalo nel bucket S3: - Distribuisci i dashboard QuickSight utilizzando un modello CloudFormation, che è in formato YAML. Dopo la distribuzione, scegli l'icona di aggiornamento finché non visualizzi lo stato dello stack come
CREATE_COMPLETE. Questa fase crea set di dati sui dashboard QuickSight nel tuo account di destinazione AWS.
- Nella dashboard di QuickSight, puoi trovare approfondimenti sui carichi di lavoro Hadoop analizzati da vari grafici. Queste informazioni ti aiutano a progettare future istanze EMR per l'accelerazione della migrazione, come dimostrato nel passaggio successivo.

Progetta un cluster EMR per la migrazione
I risultati dell'analizzatore di log YARN ti aiutano a comprendere i carichi di lavoro Hadoop effettivi sul sistema esistente. Questo passaggio accelera la progettazione di future istanze EMR per la migrazione utilizzando un Modello di Excel. Il modello contiene un elenco di controllo per condurre l'analisi del carico di lavoro e la pianificazione della capacità:
- Le applicazioni in esecuzione sul cluster vengono utilizzate in modo appropriato con la loro capacità attuale?
- Il cluster è sotto carico in un determinato momento o no? Se sì, quando è il momento?
- Quali tipi di applicazioni e motori (come MR, TEZ o Spark) sono in esecuzione nel cluster e qual è l'utilizzo delle risorse per ciascun tipo?
- I diversi cicli di esecuzione dei lavori (in tempo reale, batch, ad hoc) sono in esecuzione in un cluster?
- Ci sono lavori in esecuzione in batch regolari e, in caso affermativo, quali sono questi intervalli di pianificazione? (Ad esempio, ogni 10 minuti, 1 ora, 1 giorno.) Svolgi lavori che utilizzano molte risorse per un lungo periodo di tempo?
- Qualche lavoro richiede un miglioramento delle prestazioni?
- Ci sono organizzazioni o individui specifici che monopolizzano il cluster?
- Ci sono lavori misti di sviluppo e operazioni che operano in un cluster?
Dopo aver completato l'elenco di controllo, avrai una migliore comprensione di come progettare l'architettura futura. Per ottimizzare l'efficacia dei costi del cluster EMR, la tabella seguente fornisce linee guida generali per la scelta del tipo appropriato di cluster EMR e Cloud di calcolo elastico di Amazon (Amazon EC2).

Per scegliere il tipo di cluster e la famiglia di istanze corretti, è necessario eseguire diversi cicli di analisi rispetto ai log YARN in base a vari criteri. Diamo un'occhiata ad alcune metriche chiave.
Cronologia
Puoi trovare modelli di carico di lavoro in base al numero di applicazioni Hadoop eseguite in una finestra temporale. Ad esempio, i grafici giornalieri o orari "Count of Records by Startedtime" forniscono le seguenti informazioni:
- Nei grafici delle serie temporali giornaliere, si confronta il numero di esecuzioni dell'applicazione tra giorni lavorativi e festivi e tra giorni di calendario. Se i numeri sono simili, significa che gli utilizzi giornalieri del cluster sono comparabili. D'altra parte, se la deviazione è ampia, la proporzione di posti di lavoro ad hoc è significativa. Puoi anche capire i possibili lavori settimanali o mensili in giorni particolari. Nella situazione, puoi facilmente vedere giorni specifici in una settimana o in un mese con un'elevata concentrazione del carico di lavoro.
- Nei grafici delle serie temporali orarie, comprendi ulteriormente come le applicazioni vengono eseguite nelle finestre orarie. Puoi trovare le ore di punta e non di punta in un giorno.
Utenti
I registri YARN contengono l'ID utente di ciascuna applicazione. Queste informazioni ti aiutano a capire chi invia una domanda a una coda. In base alle statistiche delle esecuzioni di applicazioni singole e aggregate per coda e per utente, è possibile determinare la distribuzione del carico di lavoro esistente per utente. Di solito, gli utenti dello stesso team hanno code condivise. A volte, più team hanno code condivise. Durante la progettazione delle code per gli utenti, ora disponi di informazioni dettagliate che ti aiutano a progettare e distribuire i carichi di lavoro delle applicazioni che sono più bilanciati tra le code rispetto a prima.
Tipi di applicazioni
Puoi segmentare i carichi di lavoro in base a vari tipi di applicazioni (come Hive, Spark, Presto o HBase) ed eseguire motori (come MR, Spark o Tez). Per i carichi di lavoro pesanti come i lavori MapReduce o Hive-on-MR, utilizza le istanze ottimizzate per la CPU. Per i carichi di lavoro a uso intensivo di memoria come i processi Hive-on-TEZ, Presto e Spark, utilizza le istanze ottimizzate per la memoria.
Tempo trascorso
È possibile classificare le applicazioni in base al runtime. Il modello CloudFormation incorporato crea automaticamente un campo elapsedGroup in un dashboard QuickSight. Ciò abilita una funzionalità chiave che consente di osservare i lavori a esecuzione prolungata in uno dei quattro grafici sui dashboard di QuickSight. Pertanto, è possibile progettare architetture future su misura per questi lavori di grandi dimensioni.
I dashboard QuickSight corrispondenti includono quattro grafici. È possibile visualizzare in dettaglio ogni grafico associato a un gruppo.
| Gruppo Numero |
Tempo di esecuzione/tempo trascorso di un lavoro |
| 1 | Meno di 10 minuti |
| 2 | Tra 10 minuti e 30 minuti |
| 3 | tra 30 minuti e 1 ora |
| 4 | Maggiore di 1 ora |
Nel grafico del Gruppo 4, puoi concentrarti sull'esame di lavori di grandi dimensioni in base a varie metriche, tra cui utente, coda, tipo di applicazione, sequenza temporale, utilizzo delle risorse e così via. In base a questa considerazione, potresti avere code dedicate su un cluster o un cluster EMR dedicato per lavori di grandi dimensioni. Nel frattempo, puoi inviare piccoli lavori a code condivise.
Risorse
In base ai modelli di consumo delle risorse (CPU, memoria), scegli la giusta dimensione e famiglia di istanze EC2 per prestazioni e convenienza. Per le applicazioni a elevato utilizzo di calcolo, consigliamo istanze di famiglie ottimizzate per la CPU. Per le applicazioni a uso intensivo di memoria, sono consigliate le famiglie di istanze ottimizzate per la memoria.
Inoltre, in base alla natura dei carichi di lavoro dell'applicazione e all'utilizzo delle risorse nel tempo, è possibile scegliere un cluster EMR persistente o transitorio, Amazon EMR su EKS, o Amazon EMR senza server.
Dopo aver analizzato i log YARN in base a varie metriche, sei pronto per progettare le future architetture EMR. La tabella seguente elenca esempi di cluster EMR proposti. Puoi trovare maggiori dettagli nella repository GitHub ottimizzato-tco-calcolatore.

Calcola il TCO
Infine, sul tuo computer locale, esegui tco-input-generator.py per aggregare i registri della cronologia dei processi YARN su base oraria prima di utilizzare un modello Excel per calcolare il TCO ottimizzato. Questo passaggio è fondamentale perché i risultati simulano i carichi di lavoro Hadoop nelle future istanze EMR.
Il prerequisito della simulazione TCO è l'esecuzione tco-input-generator.py, che genera log aggregati orari. Successivamente, apri un file modello Excel per abilitare le macro e fornisci i tuoi input nelle celle verdi per il calcolo del TCO. Per quanto riguarda i dati di input, inserisci la dimensione effettiva dei dati senza replica e le specifiche hardware (vCore, mem) del nodo primario Hadoop e dei nodi di dati. È inoltre necessario selezionare e caricare i log aggregati orari generati in precedenza. Dopo aver impostato le variabili di simulazione TCO, come regione, tipo EC2, disponibilità elevata Amazon EMR, effetto motore, sconto Amazon EC2 e Amazon EBS (EDP), sconto volume Amazon S3, tasso nella valuta locale e rapporto prezzo attività/core EMR EC2 e prezzo/ora, il simulatore TCO calcola automaticamente il costo ottimale delle future istanze EMR su Amazon EC2. Gli screenshot seguenti mostrano un esempio dei risultati del TCO di HMDK.

Per ulteriori informazioni e istruzioni sui calcoli del TCO HMDK, fare riferimento a repository GitHub ottimizzato-tco-calcolatore.
ripulire
Dopo aver completato tutti i passaggi e terminato il test, completa i seguenti passaggi per eliminare le risorse ed evitare di incorrere in costi:
- Nella console AWS CloudFormation, scegli lo stack che hai creato.
- Scegli Elimina.
- Scegli Elimina stack.
- Aggiorna la pagina finché non vedi lo stato
DELETE_COMPLETE. - Sulla console Amazon S3, elimina il bucket S3 che hai creato.
Conclusione
Lo strumento TCO di AWS ProServe HMDK riduce significativamente gli sforzi di pianificazione della migrazione, che sono le attività impegnative e dispendiose in termini di tempo di valutazione dei carichi di lavoro Hadoop. Con lo strumento HMDK TCO, la valutazione richiede in genere 2-3 settimane. È inoltre possibile determinare il TCO calcolato delle future architetture EMR. Con lo strumento HMDK TCO, puoi comprendere rapidamente i tuoi carichi di lavoro e i modelli di utilizzo delle risorse. Con le informazioni generate dallo strumento, sei attrezzato per progettare architetture EMR future ottimali. In molti casi d'uso, un TCO di 1 anno dell'architettura ottimizzata con refactoring offre significativi risparmi sui costi (riduzione del 64-80%) su elaborazione e storage, rispetto alle migrazioni lift-and-shift Hadoop.
Per ulteriori informazioni sull'accelerazione delle migrazioni Hadoop ad Amazon EMR e allo strumento CTO HMDK, consulta il Repo GitHub del TCO del kit di distribuzione della migrazione Hadoop, o contattaci AWS-HMDK@amazon.com.
Circa gli autori
 Parco Sungyul è Senior Practice Manager presso AWS ProServe. Aiuta i clienti a innovare la propria attività con i servizi AWS Analytics, IoT e AI/ML. È specializzato in servizi e tecnologie per big data e ha interesse a costruire insieme risultati aziendali per i clienti.
Parco Sungyul è Senior Practice Manager presso AWS ProServe. Aiuta i clienti a innovare la propria attività con i servizi AWS Analytics, IoT e AI/ML. È specializzato in servizi e tecnologie per big data e ha interesse a costruire insieme risultati aziendali per i clienti.
 Jiseong Kim è Senior Data Architect presso AWS ProServe. Lavora principalmente con clienti aziendali per aiutare la migrazione e la modernizzazione dei data lake e fornisce indicazioni e assistenza tecnica su progetti di big data come Hadoop, Spark, data warehousing, elaborazione dei dati in tempo reale e machine learning su larga scala. Capisce anche come applicare le tecnologie per risolvere i problemi dei big data e costruire un'architettura dati ben progettata.
Jiseong Kim è Senior Data Architect presso AWS ProServe. Lavora principalmente con clienti aziendali per aiutare la migrazione e la modernizzazione dei data lake e fornisce indicazioni e assistenza tecnica su progetti di big data come Hadoop, Spark, data warehousing, elaborazione dei dati in tempo reale e machine learning su larga scala. Capisce anche come applicare le tecnologie per risolvere i problemi dei big data e costruire un'architettura dati ben progettata.
 George Zhao è Senior Data Architect presso AWS ProServe. È un leader esperto di analisi che lavora con i clienti AWS per fornire soluzioni di dati moderne. È anche uno specialista di domini ProServe Amazon EMR che abilita i consulenti ProServe su best practice e kit di distribuzione per le migrazioni da Hadoop ad Amazon EMR. La sua area di interesse sono i data lake e la fornitura di architetture di dati moderne nel cloud.
George Zhao è Senior Data Architect presso AWS ProServe. È un leader esperto di analisi che lavora con i clienti AWS per fornire soluzioni di dati moderne. È anche uno specialista di domini ProServe Amazon EMR che abilita i consulenti ProServe su best practice e kit di distribuzione per le migrazioni da Hadoop ad Amazon EMR. La sua area di interesse sono i data lake e la fornitura di architetture di dati moderne nel cloud.
 Kalen Zhang è stato Global Segment Tech Lead di Partner Data and Analytics presso AWS. In qualità di consulente di fiducia di dati e analisi, ha curato iniziative strategiche per la trasformazione dei dati, ha guidato i programmi di modernizzazione e migrazione dei carichi di lavoro di dati e analisi e ha accelerato i percorsi di migrazione dei clienti con i partner su larga scala. È specializzata in sistemi distribuiti, gestione dei dati aziendali, analisi avanzate e iniziative strategiche su larga scala.
Kalen Zhang è stato Global Segment Tech Lead di Partner Data and Analytics presso AWS. In qualità di consulente di fiducia di dati e analisi, ha curato iniziative strategiche per la trasformazione dei dati, ha guidato i programmi di modernizzazione e migrazione dei carichi di lavoro di dati e analisi e ha accelerato i percorsi di migrazione dei clienti con i partner su larga scala. È specializzata in sistemi distribuiti, gestione dei dati aziendali, analisi avanzate e iniziative strategiche su larga scala.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- capace
- Chi siamo
- accelerare
- accelerata
- accelera
- accelerando
- accelerazione
- accessibilità
- Il mio account
- operanti in
- Ad
- aggiunta
- aggiuntivo
- Informazioni aggiuntive
- Inoltre
- Avanzate
- consulente
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- AI / ML
- Tutti
- Amazon
- Amazon EC2
- Amazon EMR
- tra
- .
- analitica
- analizzare
- l'analisi
- ed
- api
- Applicazioni
- applicazioni
- APPLICA
- appropriatamente
- architettura
- RISERVATA
- valutazione
- Assistenza
- associato
- automaticamente
- disponibilità
- AWS
- AWS CloudFormazione
- basato
- base
- perché
- essendo
- vantaggi
- MIGLIORE
- best practice
- Meglio
- fra
- Big
- Big Data
- brevemente
- costruire
- Costruzione
- affari
- calcolare
- calcolato
- calcola
- calcolo
- Calendario
- detto
- chiamata
- funzionalità
- Ultra-Grande
- casi
- Celle
- certo
- impegnativo
- Grafico
- Grafici
- Scegli
- la scelta
- Cloud
- Cluster
- raccogliere
- Raccolta
- collezione
- collettore
- raccoglie
- COM
- paragonabile
- confrontare
- rispetto
- completamento di una
- Calcolare
- concentrarsi
- concentrazione
- Segui il codice di Condotta
- conduzione
- Connettiti
- veloce
- collega
- consecutivo
- considerazione
- consolle
- consulenti
- consumo
- contiene
- Corrispondente
- Costo
- risparmi
- Costi
- CPU
- creato
- crea
- criteri
- cruciale
- CTO
- a cura
- Valuta
- Corrente
- cliente
- Clienti
- cicli
- alle lezioni
- cruscotto
- dati
- Lago di dati
- gestione dei dati
- elaborazione dati
- dataset
- giorno
- Giorni
- dedicato
- deep
- profonda immersione
- consegnare
- consegna
- dimostrato
- distribuzione
- Design
- progettazione
- dettagli
- Determinare
- Mercato
- deviazione
- diverso
- Codice Sconto
- distribuire
- distribuito
- sistemi distribuiti
- distribuzione
- dominio
- giù
- durante
- ogni
- facilmente
- ebs
- edizione
- effetto
- efficacia
- sforzi
- incorporato
- enable
- abilitato
- Abilita
- da un capo all'altro
- motore
- Motori
- garantire
- entrare
- Impresa
- clienti aziendali
- attrezzato
- stabilire
- Etere (ETH)
- eventi
- Ogni
- esempio
- Esempi
- Excel
- esistente
- esperto
- facilitando
- famiglie
- famiglia
- caratteristica
- Caratteristiche
- campo
- figura
- Compila il
- File
- Trovare
- finire
- i seguenti
- formato
- da
- funzionalità
- ulteriormente
- futuro
- Generale
- generato
- genera
- ottenere
- ottenere
- GitHub
- globali
- Green
- Gruppo
- linee guida
- Hadoop
- Hardware
- Aiuto
- aiuta
- Alta
- storia
- Alveare
- Vacanze
- olistica
- ORE
- Come
- Tutorial
- HTML
- HTTPS
- ICON
- miglioramento
- in
- includere
- Compreso
- individuale
- individui
- informazioni
- iniziative
- innovare
- ingresso
- intuizioni
- esempio
- istruzioni
- interesse
- interessi
- introdotto
- IoT
- IT
- Lavoro
- Offerte di lavoro
- Journeys
- json
- Le
- kit
- lago
- grandi
- larga scala
- lanciare
- portare
- leader
- IMPARARE
- apprendimento
- Guidato
- Dati LED
- elenchi
- caricare
- locale
- Lunghi
- a lungo
- Guarda
- lotto
- macchina
- machine learning
- macro
- Principale
- make
- gestione
- direttore
- I gestori
- molti
- si intende
- Nel frattempo
- Memorie
- fusione
- Metrica
- migrazione
- verbale
- misto
- moderno
- modernizzazione
- Mese
- mensile
- Scopri di più
- multiplo
- Natura
- Bisogno
- GENERAZIONE
- nodo
- nodi
- numero
- numeri
- osservare
- ottenendo
- ONE
- aprire
- operativo
- operazione
- ottimale
- ottimizzati
- ottimizzazione
- ottimale
- organizzazioni
- Altro
- particolare
- partner
- partner
- modelli
- Corrente di
- eseguire
- performance
- periodo
- autorizzazione
- Partner
- pianificazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- politica
- possibile
- Post
- pratica
- pratiche
- prerequisiti
- in precedenza
- prezzi
- primario
- Precedente
- problemi
- lavorazione
- Programmi
- progetti
- corretto
- proposto
- fornire
- fornisce
- Python
- rapidamente
- tasso
- rapporto
- raggiungere
- pronto
- tempo reale
- dati in tempo reale
- raccomandare
- raccomandato
- record
- riduce
- per quanto riguarda
- regione
- Basic
- rimozione
- replicazione
- risorsa
- Risorse
- Risultati
- ritenzione
- round
- Correre
- running
- stesso
- Risparmio
- Scala
- programma
- screenshot
- sezioni
- segmento
- anziano
- Serie
- Servizi
- set
- regolazione
- alcuni
- condiviso
- mostrare attraverso le sue creazioni
- vetrina
- significativa
- significativamente
- simile
- Un'espansione
- simulazione
- simulatore
- situazione
- Taglia
- piccole
- So
- Soluzioni
- RISOLVERE
- alcuni
- Scintilla
- specialista
- specializzata
- Specialità
- specifico
- Specifiche tecniche
- pila
- iniziato
- statistica
- Stato dei servizi
- step
- Passi
- conservazione
- Strategico
- inviare
- tale
- supportato
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- su misura
- prende
- Target
- task
- team
- le squadre
- Tech
- Consulenza
- Tecnologie
- modello
- modelli
- Testing
- Il
- Il futuro
- loro
- perciò
- Attraverso
- tempo
- Serie storiche
- richiede tempo
- time line
- a
- insieme
- Trasformare
- Trasformazione
- trasformato
- vero
- di fiducia
- Tipi di
- per
- capire
- e una comprensione reciproca
- capisce
- Impiego
- uso
- Utente
- utenti
- generalmente
- vario
- verificare
- visualizzazione
- volume
- a piedi
- Magazzinaggio
- settimana
- settimanale
- Settimane
- Che
- Che cosa è l'
- quale
- OMS
- finestre
- senza
- flusso di lavoro
- lavoro
- lavori
- YAML
- Trasferimento da aeroporto a Sharm
- zefiro