Come praticamente tutti i clienti, vuoi spendere il meno possibile ottenendo le migliori prestazioni possibili. Ciò significa che è necessario prestare attenzione al rapporto qualità-prezzo. Con Amazon RedShift, puoi avere la tua torta e mangiarla anche tu! Amazon Redshift offre costi per utente fino a 4.9 volte inferiori e un rapporto prezzo/prestazioni fino a 7.9 volte migliore rispetto ad altri data warehouse nel cloud su carichi di lavoro reali utilizzando tecniche avanzate come il dimensionamento della concorrenza per supportare centinaia di utenti simultanei, codifica di stringhe migliorata per prestazioni di query più veloci , E Amazon Redshift senza server miglioramenti delle prestazioni. Continua a leggere per capire perché il rapporto prezzo-prestazioni è importante e in che modo il rapporto prezzo-prestazioni di Amazon Redshift è una misura di quanto costa ottenere un particolare livello di prestazioni del carico di lavoro, ovvero il ROI (ritorno sull'investimento) delle prestazioni.
Poiché sia il prezzo che la performance entrano nel calcolo del rapporto prezzo-prestazioni, ci sono due modi di pensare al rapporto prezzo-prestazioni. Il primo modo è mantenere il prezzo costante: se hai $ 1 da spendere, quante prestazioni ottieni dal tuo data warehouse? Un database con un migliore rapporto qualità-prezzo offrirà prestazioni migliori per ogni dollaro speso. Pertanto, mantenendo costante il prezzo quando si confrontano due data warehouse che costano lo stesso, il database con un migliore rapporto prezzo-prestazioni eseguirà le query più velocemente. Il secondo modo di considerare il rapporto prezzo-prestazioni è mantenere costanti le prestazioni: se hai bisogno che il tuo carico di lavoro finisca in 10 minuti, quanto costerà? Un database con un miglior rapporto qualità-prezzo eseguirà il tuo carico di lavoro in 10 minuti a un costo inferiore. Pertanto, mantenendo costanti le prestazioni quando si confrontano due data warehouse dimensionati per fornire le stesse prestazioni, il database con un migliore rapporto prezzo-prestazioni costerà meno e farà risparmiare denaro.
Infine, un altro aspetto importante del rapporto prezzo/prestazioni è la prevedibilità. Sapere quanto costerà il tuo data warehouse man mano che il numero di utenti del data warehouse cresce è fondamentale per la pianificazione. Non dovrebbe solo offrire il miglior rapporto prezzo-prestazioni oggi, ma anche scalare in modo prevedibile e fornire il miglior rapporto prezzo-prestazioni man mano che vengono aggiunti più utenti e carichi di lavoro. Un data warehouse ideale dovrebbe avere scala lineare—la scalabilità del data warehouse per fornire il doppio del throughput delle query dovrebbe idealmente costare il doppio (o meno).
In questo post condividiamo i risultati delle prestazioni per illustrare come Amazon Redshift offra un rapporto prezzo-prestazioni significativamente migliore rispetto ai principali data warehouse sul cloud alternativi. Ciò significa che se spendi su Amazon Redshift lo stesso importo che spenderesti su uno di questi altri data warehouse, otterrai prestazioni migliori con Amazon Redshift. In alternativa, se dimensioni il tuo cluster Redshift per offrire le stesse prestazioni, vedrai costi inferiori rispetto a queste alternative.
Rapporto qualità-prezzo per carichi di lavoro reali
Puoi utilizzare Amazon Redshift per gestire un'ampia varietà di carichi di lavoro, dall'elaborazione batch di report complessi basati su estrazione, trasformazione e caricamento (ETL) e analisi di streaming in tempo reale ai dashboard di business intelligence (BI) a bassa latenza che devono servire centinaia o addirittura migliaia di utenti contemporaneamente con tempi di risposta inferiori al secondo e tutto il resto. Uno dei modi in cui miglioriamo continuamente il rapporto prezzo-prestazioni per i nostri clienti è rivedere costantemente la telemetria delle prestazioni software e hardware della flotta Redshift, alla ricerca di opportunità e casi d'uso dei clienti in cui possiamo migliorare ulteriormente le prestazioni di Amazon Redshift.
Alcuni esempi recenti di ottimizzazioni delle prestazioni guidate dalla telemetria della flotta includono:
- Ottimizzazioni delle query di stringa – Analizzando il modo in cui Amazon Redshift elaborava diversi tipi di dati nel parco risorse Redshift, abbiamo scoperto che l'ottimizzazione delle query con un numero elevato di stringhe apporterebbe vantaggi significativi ai carichi di lavoro dei nostri clienti. (Ne discuteremo più dettagliatamente più avanti in questo post.)
- Viste materializzate automatizzate – Abbiamo scoperto che i clienti Amazon Redshift spesso eseguono molte query con modelli di sottoquery comuni. Ad esempio, diverse query possono unire le stesse tre tabelle utilizzando la stessa condizione di unione. Amazon Redshift è ora in grado di creare e mantenere automaticamente viste materializzate e quindi di riscrivere in modo trasparente le query per utilizzare le viste materializzate utilizzando il machine learning vista materializzata automatizzata funzionalità di autonomia in Amazon Redshift. Se abilitate, le visualizzazioni materializzate automatizzate possono aumentare in modo trasparente le prestazioni delle query ripetitive senza alcun intervento da parte dell'utente. (Si noti che le visualizzazioni materializzate automatizzate non sono state utilizzate in nessuno dei risultati dei benchmark discussi in questo post).
- Carichi di lavoro ad alta concorrenza – Un caso d’uso crescente che vediamo è l’utilizzo di Amazon Redshift per gestire carichi di lavoro simili a dashboard. Questi carichi di lavoro sono caratterizzati da tempi di risposta alle query desiderati di pochi secondi o meno, con decine o centinaia di utenti simultanei che eseguono query simultaneamente con un modello di utilizzo spinoso e spesso imprevedibile. L'esempio tipico di ciò è un dashboard BI supportato da Amazon Redshift che registra un picco di traffico il lunedì mattina quando un gran numero di utenti inizia la settimana.
I carichi di lavoro ad alta concorrenza, in particolare, hanno un'applicabilità molto ampia: la maggior parte dei carichi di lavoro di data warehouse opera in concorrenza e non è raro che centinaia o addirittura migliaia di utenti eseguano query su Amazon Redshift contemporaneamente. Amazon Redshift è stato progettato per mantenere i tempi di risposta alle query prevedibili e rapidi. Redshift Serverless lo fa automaticamente per te aggiungendo e rimuovendo il calcolo secondo necessità per mantenere i tempi di risposta alle query rapidi e prevedibili. Ciò significa che una dashboard supportata da Redshift Serverless che si carica rapidamente quando vi accedono uno o due utenti continuerà a caricarsi rapidamente anche quando molti utenti la caricano contemporaneamente.
Per simulare questo tipo di carico di lavoro, abbiamo utilizzato un benchmark derivato da TPC-DS con un set di dati da 100 GB. TPC-DS è un benchmark standard del settore che include una varietà di query tipiche del data warehouse. Su questa scala relativamente piccola di 100 GB, le query in questo benchmark vengono eseguite su Redshift Serverless in media in pochi secondi, il che è rappresentativo di ciò che si aspetterebbero gli utenti che caricano un dashboard BI interattivo. Abbiamo eseguito da 1 a 200 test simultanei di questo benchmark, simulando da 1 a 200 utenti che tentavano di caricare una dashboard contemporaneamente. Abbiamo anche ripetuto il test con diversi popolari data warehouse cloud alternativi che supportano anche la scalabilità orizzontale automatica (se hai familiarità con il post Amazon Redshift continua a mantenere la leadership in termini di rapporto prezzo-prestazioni, non abbiamo incluso il concorrente A perché non supporta lo scale up automatico). Abbiamo misurato il tempo medio di risposta alle query, ovvero quanto tempo un utente aspetterebbe il completamento delle query (o il caricamento della dashboard). I risultati sono mostrati nel grafico seguente.
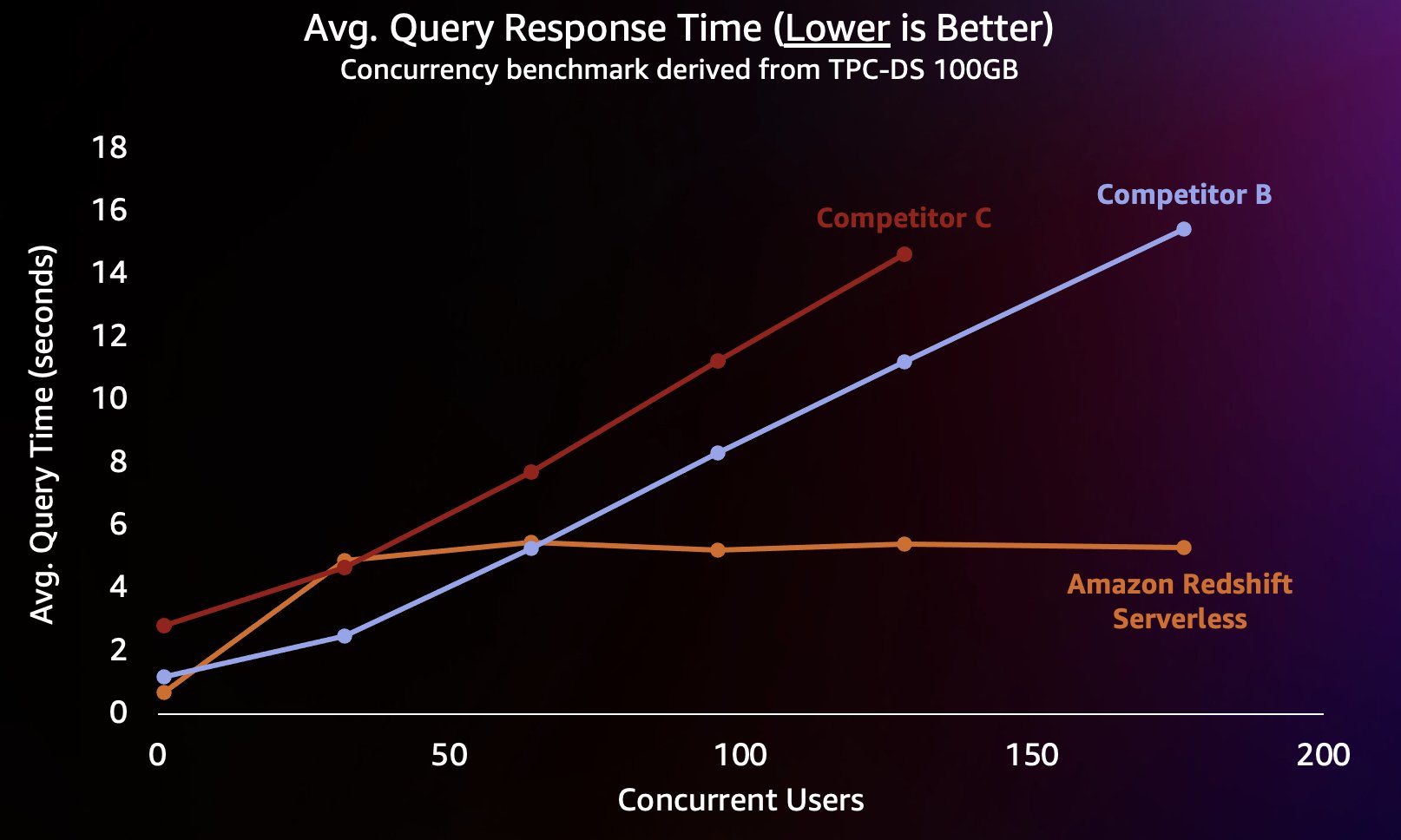
Il concorrente B si adatta bene fino a circa 64 query simultanee, a quel punto non è in grado di fornire ulteriore elaborazione e le query iniziano ad accodarsi, con conseguente aumento dei tempi di risposta alle query. Sebbene il concorrente C sia in grado di scalare automaticamente, si adatta a un throughput di query inferiore rispetto sia ad Amazon Redshift che al concorrente B e non è in grado di mantenere bassi i tempi di esecuzione delle query. Inoltre, non supporta l'accodamento delle query quando esaurisce il calcolo, il che gli impedisce di scalare oltre i 128 utenti simultanei. L'invio di ulteriori query oltre a queste verrà rifiutato dal sistema.
In questo caso, Redshift Serverless è in grado di mantenere il tempo di risposta alle query relativamente coerente a circa 5 secondi anche quando centinaia di utenti eseguono query contemporaneamente. I tempi medi di risposta alle query per i concorrenti B e C aumentano costantemente con l'aumentare del carico sui warehouse, il che fa sì che gli utenti debbano attendere più a lungo (fino a 16 secondi) per la restituzione delle loro query quando il data warehouse è occupato. Ciò significa che se un utente sta tentando di aggiornare una dashboard (che potrebbe anche inviare diverse query simultanee una volta ricaricata), Amazon Redshift sarebbe in grado di mantenere i tempi di caricamento della dashboard molto più coerenti anche se la dashboard viene caricata da decine o centinaia di altri utenti. utenti contemporaneamente.
Poiché Amazon Redshift è in grado di fornire un throughput di query molto elevato per query brevi (come abbiamo scritto in Amazon Redshift continua a mantenere la leadership in termini di rapporto prezzo-prestazioni), è anche in grado di gestire queste maggiori contemporaneità durante la scalabilità orizzontale in modo più efficiente e quindi a un costo notevolmente inferiore. Per quantificare questo, esaminiamo il rapporto prezzo-prestazioni utilizzando pubblicato prezzi su richiesta per ciascuno dei magazzini del test precedente, riportati nella tabella seguente. Vale la pena notare che l'utilizzo Istanze riservate (RI), in particolare le istanze riservate triennali acquistate con l'opzione di pagamento anticipato, hanno il costo più basso per eseguire Amazon Redshift su cluster con provisioning, garantendo il miglior rapporto prezzo/prestazioni rispetto alle opzioni istanze riservate su richiesta o ad altre opzioni istantanee.

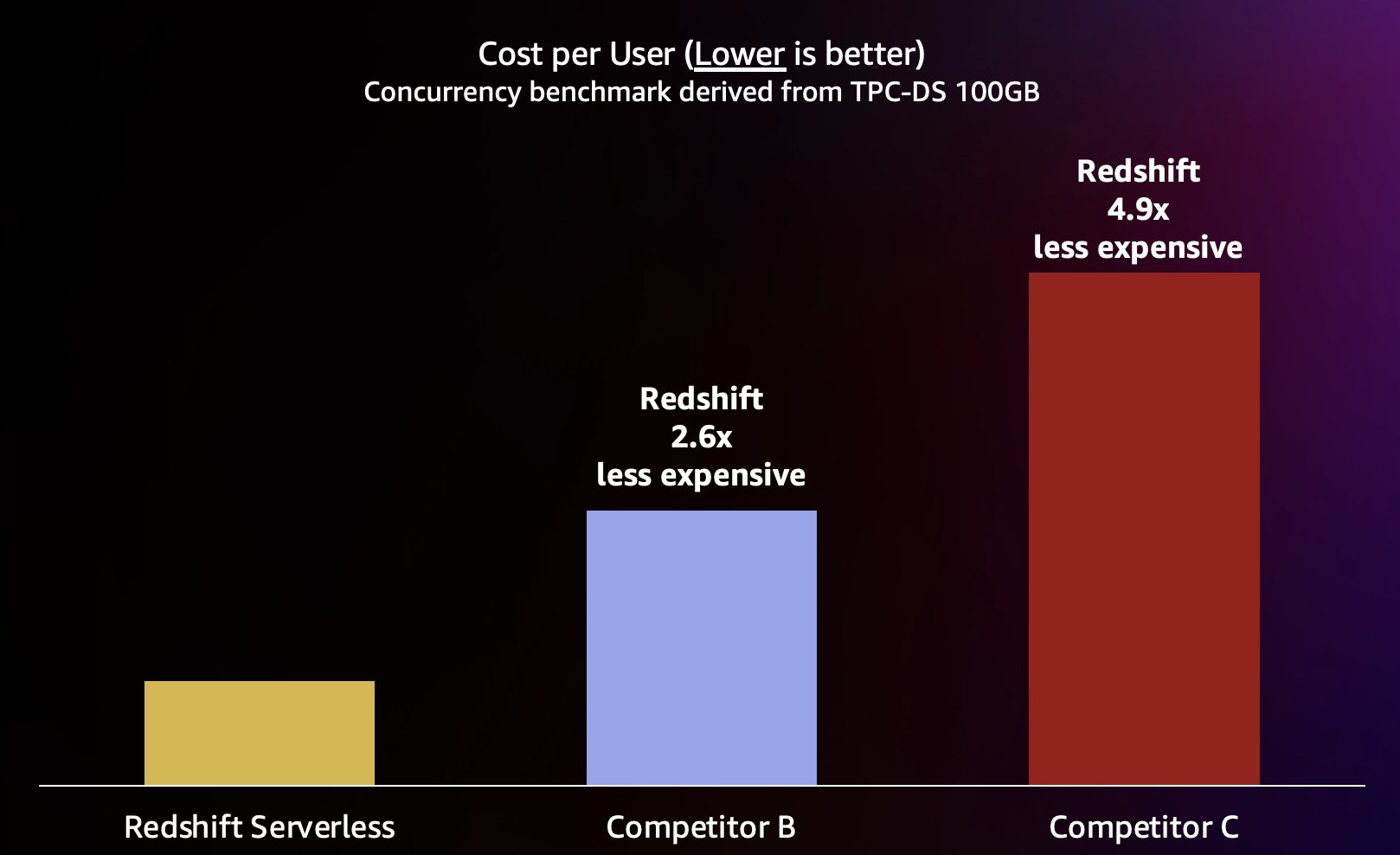
Pertanto, Amazon Redshift non solo è in grado di offrire prestazioni migliori in concomitanze più elevate, ma è anche in grado di farlo a costi significativamente inferiori. Ogni punto dati nel grafico rapporto prezzo/prestazioni equivale al costo per eseguire il benchmark nella concomitanza specificata. Poiché il rapporto prezzo-prestazioni è lineare, possiamo dividere il costo per eseguire il benchmark in qualsiasi concomitanza per la concomitanza (numero di utenti simultanei in questo grafico) per dirci quanto costa aggiungere ogni nuovo utente per questo particolare benchmark.
I risultati precedenti sono semplici da replicare. Tutte le query utilizzate nel benchmark sono disponibili nel nostro Repository GitHub e le prestazioni vengono misurate avviando un data warehouse, abilitando il Concurrency Scaling su Amazon Redshift (o la corrispondente funzionalità di ridimensionamento automatico su altri warehouse), caricando i dati immediatamente (nessuna ottimizzazione manuale o configurazione specifica del database) e quindi eseguendo un flusso simultaneo di query in concomitanza da 1 a 200 in passaggi di 32 su ciascun data warehouse. Lo stesso repository GitHub fa riferimento a dati TPC-DS pregenerati (e non modificati). Servizio di archiviazione semplice Amazon (Amazon S3) su varie scale utilizzando il kit ufficiale di generazione dati TPC-DS.
Ottimizzazione dei carichi di lavoro con uso intensivo di stringhe
Come accennato in precedenza, il team di Amazon Redshift è alla continua ricerca di nuove opportunità per offrire ai nostri clienti un rapporto prezzo-prestazioni ancora migliore. Un miglioramento lanciato di recente che ha migliorato significativamente le prestazioni è un'ottimizzazione che accelera le prestazioni delle query sui dati di stringa. Ad esempio, potresti voler trovare le entrate totali generate dai negozi al dettaglio situati a New York City con una query simile SELECT sum(price) FROM sales WHERE city = ‘New York’. Questa query applica un predicato sui dati stringa (city = ‘New York’). Come puoi immaginare, l'elaborazione dei dati di stringa è onnipresente nelle applicazioni di data warehouse.
Per quantificare la frequenza con cui i carichi di lavoro dei clienti accedono alle stringhe, abbiamo condotto un'analisi dettagliata dell'utilizzo del tipo di dati stringa utilizzando la telemetria della flotta di decine di migliaia di cluster di clienti gestiti da Amazon Redshift. La nostra analisi indica che nel 90% dei cluster le colonne stringa costituiscono almeno il 30% di tutte le colonne e nel 50% dei cluster le colonne stringa costituiscono almeno il 50% di tutte le colonne. Inoltre, la maggior parte di tutte le query eseguite sulla piattaforma di data warehouse nel cloud Amazon Redshift accede ad almeno una colonna di stringhe. Un altro fattore importante è che i dati stringa molto spesso hanno una cardinalità bassa, ovvero le colonne contengono un insieme relativamente piccolo di valori univoci. Ad esempio, sebbene an orders la tabella che rappresenta i dati di vendita può contenere miliardi di righe, un order_status la colonna all'interno di quella tabella potrebbe contenere solo pochi valori univoci su quei miliardi di righe, come ad esempio pending, in processe completed.
Al momento della stesura di questo documento, la maggior parte delle colonne stringa in Amazon Redshift sono compresse con LZO or ZSTD algoritmi. Si tratta di buoni algoritmi di compressione generici, ma non sono progettati per sfruttare i dati di stringa a bassa cardinalità. In particolare, richiedono che i dati vengano decompressi prima di essere utilizzati e sono meno efficienti nell'uso della larghezza di banda della memoria hardware. Per i dati a bassa cardinalità esiste un altro tipo di codifica che può essere più ottimale: BYTEDIT. Questa codifica utilizza uno schema di codifica del dizionario che consente al motore del database di operare direttamente sui dati compressi senza la necessità di decomprimerli prima.
Per migliorare ulteriormente il rapporto prezzo-prestazioni per carichi di lavoro con un elevato utilizzo di stringhe, Amazon Redshift introduce ora ulteriori miglioramenti delle prestazioni che accelerano le scansioni e le valutazioni dei predicati, rispetto alle colonne di stringhe a bassa cardinalità codificate come BYTEDICT, da 5 a 63 volte più veloci (vedere i risultati in la sezione successiva) rispetto a codifiche di compressione alternative come LZO o ZSTD. Amazon Redshift ottiene questo miglioramento delle prestazioni vettorizzando le scansioni su colonne di stringhe leggere, efficienti in termini di CPU, con codifica BYTEDICT e a bassa cardinalità. Queste ottimizzazioni dell'elaborazione delle stringhe fanno un uso efficace della larghezza di banda della memoria offerta dall'hardware moderno, consentendo analisi in tempo reale sui dati delle stringhe. Queste funzionalità prestazionali appena introdotte sono ottimali per le colonne di stringa con cardinalità bassa (fino a poche centinaia di valori di stringa univoci).
Puoi beneficiare automaticamente di questo nuovo miglioramento delle stringhe ad alte prestazioni abilitandolo ottimizzazione automatica della tabella nel tuo data warehouse Amazon Redshift. Se non hai abilitato l'ottimizzazione automatica delle tabelle sui tuoi tavoli, puoi ricevere consigli da Consulente Amazon Redshift nella console Amazon Redshift sull'idoneità di una colonna di stringa per la codifica BYTEDICT. È inoltre possibile definire nuove tabelle con colonne di stringhe a bassa cardinalità con la codifica BYTEDICT. I miglioramenti alle stringhe in Amazon Redshift sono ora disponibili in tutte le regioni AWS in cui Amazon Redshift è disponibile.
Risultati delle prestazioni
Per misurare l'impatto sulle prestazioni dei nostri miglioramenti alle stringhe, abbiamo generato un set di dati da 10 TB (Tera Byte) costituito da dati di stringhe a bassa cardinalità. Abbiamo generato tre versioni dei dati utilizzando stringhe corte, medie e lunghe, corrispondenti al 25°, 50° e 75° percentile della lunghezza delle stringhe dalla telemetria della flotta Amazon Redshift. Abbiamo caricato questi dati in Amazon Redshift due volte, codificandoli in un caso utilizzando la compressione LZO e nell'altro utilizzando la compressione BYTEDICT. Infine, abbiamo misurato le prestazioni delle query con una scansione intensiva che restituiscono molte righe (90% della tabella), un numero medio di righe (50% della tabella) e poche righe (1% della tabella) rispetto a questi valori bassi. -set di dati di stringhe di cardinalità. I risultati prestazionali sono riassunti nel grafico seguente.

Le query con predicati che corrispondono a un'alta percentuale di righe hanno visto miglioramenti di 5-30 volte con la nuova codifica BYTEDICT vettorizzata rispetto a LZO, mentre le query con predicati che corrispondono a una bassa percentuale di righe hanno visto miglioramenti di 10-63 volte in questo benchmark interno.
Redshift Serverless rapporto qualità-prezzo
Oltre ai risultati sulle prestazioni ad alta concorrenza presentati in questo post, abbiamo anche utilizzato il benchmark Cloud Data Warehouse derivato da TPC-DS per confrontare il rapporto prezzo-prestazioni di Redshift Serverless con altri data warehouse che utilizzano un set di dati più grande da 3 TB. Abbiamo scelto data warehouse con prezzi simili, in questo caso entro il 10% di $ 32 l'ora utilizzando prezzi on-demand disponibili al pubblico. Questi risultati mostrano che, come le istanze Amazon Redshift RA3, Redshift Serverless offre un migliore rapporto qualità-prezzo rispetto ad altri principali data warehouse su cloud. Come sempre, questi risultati possono essere replicati utilizzando i nostri script SQL nel nostro Repository GitHub.

Ti invitiamo a provare Amazon Redshift utilizzando il tuo prova del concetto carichi di lavoro come il modo migliore per vedere come Amazon Redshift può soddisfare le tue esigenze di analisi dei dati.
Trova il miglior rapporto qualità-prezzo per i tuoi carichi di lavoro
I benchmark utilizzati in questo post derivano dal benchmark TPC-DS standard del settore e hanno le seguenti caratteristiche:
- Lo schema e i dati vengono utilizzati senza modifiche da TPC-DS.
- Le query vengono generate utilizzando il kit TPC-DS ufficiale con parametri di query generati utilizzando il seme casuale predefinito del kit TPC-DS. Le varianti di query approvate da TPC vengono utilizzate per un magazzino se il magazzino non supporta il dialetto SQL della query TPC-DS predefinita.
- Il test include le 99 query TPC-DS SELECT. Non include le fasi di manutenzione e produttività.
- Per il test di concorrenza singolo da 3 TB, sono state eseguite tre esecuzioni di potenza e per ciascun data warehouse viene eseguita l'esecuzione migliore.
- Il rapporto prezzo-prestazioni per le query TPC-DS viene calcolato come costo orario (USD) moltiplicato per il tempo di esecuzione del benchmark in ore, che equivale al costo per eseguire il benchmark. Per tutti i data warehouse vengono utilizzati gli ultimi prezzi on-demand pubblicati e non i prezzi delle istanze riservate, come indicato in precedenza.
Lo chiamiamo benchmark Cloud Data Warehouse e puoi riprodurre facilmente i risultati del benchmark precedente utilizzando gli script, le query e i dati disponibili nel nostro Repository GitHub. Deriva dai benchmark TPC-DS descritti in questo post e come tale non è paragonabile ai risultati TPC-DS pubblicati, perché i risultati dei nostri test non sono conformi alle specifiche ufficiali.
Conclusione
Amazon Redshift si impegna a fornire il miglior rapporto prezzo/prestazioni del settore per la più ampia varietà di carichi di lavoro. Redshift Serverless scala in modo lineare con il miglior rapporto prezzo/prestazioni (il più basso), supportando centinaia di utenti simultanei e mantenendo tempi di risposta alle query coerenti. Sulla base dei risultati dei test discussi in questo post, Amazon Redshift ha un rapporto prezzo/prestazioni fino a 2.6 volte migliore allo stesso livello di concorrenza rispetto al concorrente più vicino (Concorrente B). Come accennato in precedenza, l'utilizzo delle istanze riservate con l'opzione anticipata di 3 anni offre il costo più basso per eseguire Amazon Redshift, con un conseguente rapporto prezzo/prestazioni ancora migliore rispetto ai prezzi delle istanze on demand che abbiamo utilizzato in questo post. Il nostro approccio al miglioramento continuo delle prestazioni prevede una combinazione unica di ossessione del cliente per comprendere i casi d'uso dei clienti e i colli di bottiglia di scalabilità associati, insieme all'analisi continua dei dati della flotta per identificare opportunità per apportare ottimizzazioni significative delle prestazioni.
Ogni carico di lavoro ha caratteristiche uniche, quindi se hai appena iniziato, a prova del concetto è il modo migliore per capire come Amazon Redshift può ridurre i costi offrendo prestazioni migliori. Quando esegui la tua prova di concetto, è importante concentrarsi sulle metriche giuste: velocità effettiva delle query (numero di query all'ora), tempo di risposta e rapporto prezzo/prestazioni. Puoi prendere una decisione basata sui dati eseguendo una prova di concetto da solo o con assistenza da AWS o a partner di consulenza e integrazione di sistemi.
Per rimanere aggiornato sugli ultimi sviluppi di Amazon Redshift, segui il Novità di Amazon Redshift alimentarsi.
Circa gli autori
 Stefan Gromoll è un Senior Performance Engineer presso il team Amazon Redshift dove è responsabile della misurazione e del miglioramento delle prestazioni di Redshift. Nel tempo libero gli piace cucinare, giocare con i suoi tre figli e tagliare la legna da ardere.
Stefan Gromoll è un Senior Performance Engineer presso il team Amazon Redshift dove è responsabile della misurazione e del miglioramento delle prestazioni di Redshift. Nel tempo libero gli piace cucinare, giocare con i suoi tre figli e tagliare la legna da ardere.
 Ravi Animi è un leader senior di gestione dei prodotti nel team Amazon Redshift e gestisce diverse aree funzionali del servizio di data warehouse sul cloud Amazon Redshift, tra cui prestazioni, analisi spaziale, acquisizione di streaming e strategie di migrazione. Ha esperienza con database relazionali, database multidimensionali, tecnologie IoT, servizi di infrastrutture di archiviazione e calcolo e, più recentemente, come fondatore di startup che utilizzano intelligenza artificiale/deep learning, visione artificiale e robotica.
Ravi Animi è un leader senior di gestione dei prodotti nel team Amazon Redshift e gestisce diverse aree funzionali del servizio di data warehouse sul cloud Amazon Redshift, tra cui prestazioni, analisi spaziale, acquisizione di streaming e strategie di migrazione. Ha esperienza con database relazionali, database multidimensionali, tecnologie IoT, servizi di infrastrutture di archiviazione e calcolo e, più recentemente, come fondatore di startup che utilizzano intelligenza artificiale/deep learning, visione artificiale e robotica.
 Aamer Shah è un ingegnere senior nel team del servizio Amazon Redshift.
Aamer Shah è un ingegnere senior nel team del servizio Amazon Redshift.
 Sanket Hase è un responsabile dello sviluppo software nel team del servizio Amazon Redshift.
Sanket Hase è un responsabile dello sviluppo software nel team del servizio Amazon Redshift.
 Orestis Polychroniou è un ingegnere principale nel team di Amazon Redshift Service.
Orestis Polychroniou è un ingegnere principale nel team di Amazon Redshift Service.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/amazon-redshift-lower-price-higher-performance/
- :ha
- :È
- :non
- :Dove
- $ SU
- 10
- 100
- 16
- 32
- 7
- 9
- a
- capace
- WRI
- accelera
- accesso
- accessibile
- Realizza
- operanti in
- aggiunto
- l'aggiunta di
- aggiunta
- aggiuntivo
- Avanzate
- Vantaggio
- offerto
- contro
- Algoritmi
- Tutti
- consente
- anche
- alternativa
- alternative
- Sebbene il
- sempre
- Amazon
- Amazon Web Services
- quantità
- an
- .
- analitica
- l'analisi
- ed
- Un altro
- in qualsiasi
- applicazioni
- AMMISSIONE
- approccio
- SONO
- aree
- in giro
- AS
- aspetto
- associato
- At
- attenzione
- auto
- Automatizzata
- Automatico
- automaticamente
- disponibile
- media
- AWS
- b
- Larghezza di banda
- basato
- BE
- perché
- prima
- iniziare
- essendo
- Segno di riferimento
- parametri di riferimento
- beneficio
- MIGLIORE
- Meglio
- fra
- Al di là di
- miliardi
- entrambi
- strozzature
- Scatola
- portare
- ampio
- affari
- business intelligence
- occupato
- ma
- by
- TORTA
- calcolato
- calcolo
- chiamata
- Materiale
- funzionalità
- Custodie
- casi
- caratteristiche
- caratterizzato
- Grafico
- chopping
- ha scelto
- Città
- Cloud
- Cluster
- Colonna
- colonne
- combinazione
- impegnata
- Uncommon
- paragonabile
- confrontare
- rispetto
- confronto
- concorrente
- concorrenti
- complesso
- ottemperare
- Calcolare
- computer
- Visione computerizzata
- concetto
- concorrente
- condizione
- condotto
- coerente
- consolle
- costante
- costantemente
- costituire
- consulting
- contenere
- continuamente
- continua
- continua
- continuo
- continuamente
- cucina
- Corrispondente
- Costo
- Costi
- accoppiato
- creare
- cruciale
- cliente
- Clienti
- cruscotto
- cruscotti
- dati
- analisi dei dati
- Dati Analytics
- elaborazione dati
- set di dati
- data warehouse
- data warehouse
- data-driven
- Banca Dati
- banche dati
- dataset
- Data
- decisione
- Predefinito
- definire
- consegnare
- consegna
- fornisce un monitoraggio
- derivato
- descritta
- progettato
- desiderato
- dettaglio
- dettagliati
- Mercato
- sviluppi
- diverso
- direttamente
- discutere
- discusso
- Diversità
- dividere
- do
- effettua
- non
- Dont
- spinto
- ogni
- In precedenza
- facilmente
- mangiare
- Efficace
- efficiente
- in modo efficiente
- abilitato
- consentendo
- incoraggiare
- motore
- ingegnere
- migliorata
- aumento
- miglioramenti
- entrare
- Equivalente
- particolarmente
- Etere (ETH)
- valutazioni
- Anche
- qualunque cosa
- esempio
- Esempi
- attenderti
- esperienza
- estratto
- fattore
- familiare
- lontano
- FAST
- più veloce
- caratteristica
- pochi
- Infine
- Trovate
- finire
- Nome
- FLOTTA
- Focus
- seguire
- i seguenti
- Nel
- essere trovato
- fondatore
- da
- funzionale
- ulteriormente
- scopo generale
- generato
- ELETTRICA
- ottenere
- ottenere
- GitHub
- dà
- andando
- buono
- Crescita
- cresce
- maniglia
- Hardware
- Avere
- avendo
- he
- Alta
- superiore
- il suo
- tenere
- possesso
- ora
- ORE
- Come
- HTML
- http
- HTTPS
- misura di peso di 5.8 chili
- centinaia
- ideale
- idealmente
- identificare
- if
- illustrare
- immagine
- Impact
- importante
- aspetto importante
- competenze
- migliorata
- miglioramento
- miglioramenti
- miglioramento
- in
- includere
- inclusi
- Compreso
- Aumento
- è aumentato
- Aumenta
- indica
- dell'industria
- Infrastruttura
- esempio
- istanze
- integrazione
- Intelligence
- interattivo
- interno
- intervento
- ai miglioramenti
- introdotto
- l'introduzione di
- investimento
- comporta
- IoT
- IT
- SUO
- join
- jpg
- ad appena
- mantenere
- kit
- Conoscere
- grandi
- superiore, se assunto singolarmente.
- dopo
- con i più recenti
- ultimi sviluppi
- lanciato
- lancio
- leader
- principale
- apprendimento
- meno
- meno
- Livello
- leggero
- piace
- piccolo
- caricare
- Caricamento in corso
- carichi
- collocato
- Lunghi
- più a lungo
- Guarda
- cerca
- Basso
- inferiore
- minore
- mantenere
- mantenimento
- manutenzione
- Maggioranza
- make
- gestito
- gestione
- direttore
- gestisce
- Manuale
- molti
- partita
- Matters
- Maggio..
- significato
- si intende
- misurare
- misurato
- di misura
- medie
- Soddisfare
- Memorie
- menzionato
- forza
- migrazione
- verbale
- moderno
- Lunedì
- soldi
- Scopri di più
- Inoltre
- maggior parte
- molti
- cioè
- Bisogno
- di applicazione
- esigenze
- New
- New York
- New York City
- recentemente
- GENERAZIONE
- no
- Nota
- noto
- notando
- adesso
- numero
- of
- ufficiale
- di frequente
- on
- On-Demand
- ONE
- esclusivamente
- operare
- operato
- Opportunità
- ottimale
- ottimizzazione
- ottimizzazione
- Opzione
- Opzioni
- or
- Altro
- nostro
- su
- ancora
- proprio
- parametri
- particolare
- Cartamodello
- modelli
- Paga le
- Pagamento
- per
- percentuale
- performance
- pianificazione
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- punto
- Popolare
- possibile
- Post
- energia
- Prevedibile
- presentata
- impedisce
- prezzo
- prezzi
- Direttore
- elaborati
- lavorazione
- Prodotto
- gestione del prodotto
- prova
- prova del concetto
- fornire
- pubblicamente
- pubblicato
- acquistati
- query
- rapidamente
- casuale
- Leggi
- mondo reale
- tempo reale
- ricevere
- recente
- recentemente
- raccomandazioni
- Riferimenti
- regioni
- Respinto..
- parente
- relativamente
- rimozione
- ripetuto
- ripetitivo
- replicato
- Report
- rappresentante
- che rappresenta
- richiedere
- riservato
- risposta
- responsabile
- risultante
- Risultati
- nello specifico retail
- ritorno
- Le vendite
- recensioni
- destra
- robotica
- ROI
- Correre
- running
- corre
- vendite
- stesso
- Risparmi
- sega
- Scalabilità
- Scala
- bilancia
- scala
- scansioni
- schema
- script
- Secondo
- secondo
- Sezione
- vedere
- seme
- anziano
- servire
- serverless
- servizio
- Servizi
- set
- flessibile.
- alcuni
- Condividi
- Corti
- dovrebbero
- mostrare attraverso le sue creazioni
- mostrato
- significativa
- significativamente
- Allo stesso modo
- Un'espansione
- contemporaneamente
- singolo
- Taglia
- dimensioni
- piccole
- So
- Software
- lo sviluppo del software
- Spaziale
- specificazione
- specificato
- velocità
- spendere
- esaurito
- spuntone
- SQL
- inizia a
- iniziato
- startup
- soggiorno
- costantemente
- Passi
- conservazione
- negozi
- lineare
- strategie
- ruscello
- Streaming
- Corda
- inviare
- tale
- convenienza
- supporto
- Supporto
- sistema
- tavolo
- Fai
- preso
- team
- tecniche
- Tecnologie
- dire
- decine
- test
- test
- di
- che
- Il
- loro
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- think
- questo
- quelli
- migliaia
- tre
- portata
- tempo
- volte
- a
- oggi
- Totale
- traffico
- Trasformare
- in modo trasparente
- prova
- cerca
- Due volte
- seconda
- Digitare
- Tipi di
- tipico
- onnipresente
- incapace
- Raro
- capire
- unico
- imprevedibile
- fino a quando
- us
- Impiego
- USD
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- Valori
- varietà
- vario
- molto
- visualizzazioni
- potenzialmente
- visione
- aspettare
- volere
- Magazzino
- Prima
- Modo..
- modi
- we
- sito web
- servizi web
- settimana
- WELL
- sono stati
- Che
- quando
- mentre
- quale
- while
- perché
- largo
- volere
- con
- entro
- senza
- valore
- sarebbe
- scrittura
- ha scritto
- York
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro