Di era digital saat ini, data adalah jantung kesuksesan setiap organisasi. Salah satu format yang paling umum digunakan untuk bertukar data adalah XML. Menganalisis file XML sangat penting karena beberapa alasan. Pertama, file XML digunakan di banyak industri, termasuk keuangan, kesehatan, dan pemerintahan. Menganalisis file XML dapat membantu organisasi mendapatkan wawasan tentang data mereka, memungkinkan mereka membuat keputusan yang lebih baik dan meningkatkan operasi mereka. Menganalisis file XML juga dapat membantu dalam integrasi data, karena banyak aplikasi dan sistem menggunakan XML sebagai format data standar. Dengan menganalisis file XML, organisasi dapat dengan mudah mengintegrasikan data dari berbagai sumber dan memastikan konsistensi di seluruh sistem mereka. Namun, file XML berisi data semi-terstruktur dan sangat bertumpuk, sehingga sulit untuk mengakses dan menganalisis informasi, terutama jika file berukuran besar dan memiliki skema yang kompleks dan sangat bersarang.
File XML sangat cocok untuk aplikasi, namun mungkin tidak optimal untuk mesin analisis. Untuk meningkatkan kinerja kueri dan memungkinkan akses mudah di mesin analisis hilir seperti Amazon Athena, sangat penting untuk melakukan praproses file XML menjadi format kolom seperti Parket. Transformasi ini memungkinkan peningkatan efisiensi dan kegunaan dalam alur kerja analitik. Dalam postingan ini, kami menunjukkan cara memproses data XML menggunakan Lem AWS dan Athena.
Ikhtisar solusi
Kami mengeksplorasi dua teknik berbeda yang dapat menyederhanakan alur kerja pemrosesan file XML Anda:
- Teknik 1: Gunakan crawler AWS Glue dan editor visual AWS Glue – Anda dapat menggunakan antarmuka pengguna AWS Glue bersama dengan crawler untuk menentukan struktur tabel untuk file XML Anda. Pendekatan ini menyediakan antarmuka yang ramah pengguna dan sangat cocok untuk individu yang lebih menyukai pendekatan grafis dalam mengelola datanya.
- Teknik 2: Gunakan AWS Glue DynamicFrames dengan skema yang disimpulkan dan diperbaiki – Perayap memiliki batasan dalam memproses satu baris dalam file XML yang lebih besar 1 MB. Untuk mengatasi batasan ini, kami menggunakan notebook AWS Glue untuk membuat AWS Glue
DynamicFrames, memanfaatkan skema yang disimpulkan dan tetap. Metode ini memastikan penanganan file XML yang efisien dengan ukuran baris melebihi 1 MB.
Dalam kedua pendekatan tersebut, tujuan utama kami adalah mengonversi file XML ke dalam format Apache Parket, menjadikannya tersedia untuk kueri menggunakan Athena. Dengan teknik ini, Anda dapat meningkatkan kecepatan pemrosesan dan aksesibilitas data XML, sehingga memungkinkan Anda memperoleh wawasan berharga dengan mudah.
Prasyarat
Sebelum Anda memulai tutorial ini, selesaikan prasyarat berikut (ini berlaku untuk kedua teknik):
- Unduh file XML teknik1.xml dan teknik2.xml.
- Unggah file ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) ember. Anda dapat mengunggahnya ke bucket S3 yang sama di folder berbeda atau ke bucket S3 berbeda.
- Buat Identitas AWS dan Manajemen Akses (IAM) peran untuk pekerjaan ETL atau buku catatan Anda seperti yang diinstruksikan Siapkan izin IAM untuk AWS Glue Studio.
- Tambahkan kebijakan inline ke peran Anda dengan saya: PassRole tindakan:
- Tambahkan kebijakan izin ke peran dengan akses ke bucket S3 Anda.
Sekarang kita sudah selesai dengan prasyaratnya, mari beralih ke penerapan teknik pertama.
Teknik 1: Gunakan crawler AWS Glue dan editor visual
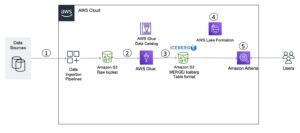
Diagram berikut mengilustrasikan arsitektur sederhana yang dapat Anda gunakan untuk mengimplementasikan solusi.
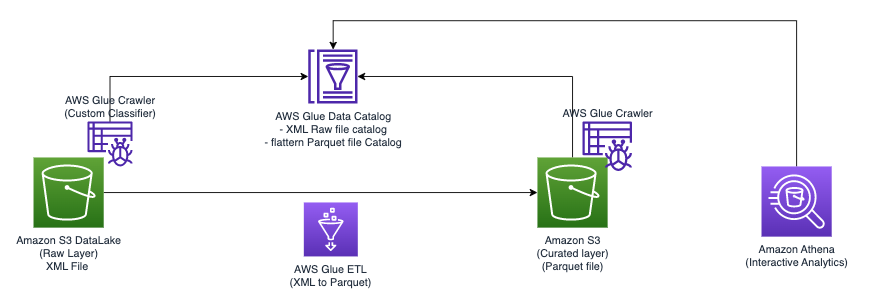
Untuk menganalisis file XML yang disimpan di Amazon S3 menggunakan AWS Glue dan Athena, kami menyelesaikan langkah-langkah tingkat tinggi berikut:
- Buat crawler AWS Glue untuk mengekstrak metadata XML dan membuat tabel di Katalog Data AWS Glue.
- Memproses dan mengubah data XML menjadi format (seperti Parket) yang sesuai untuk Athena menggunakan tugas ekstrak, transformasi, dan muat (ETL) AWS Glue.
- Siapkan dan jalankan tugas AWS Glue melalui konsol AWS Glue atau Antarmuka Baris Perintah AWS (AWS CLI).
- Gunakan data yang diproses (dalam format Parket) dengan tabel Athena, aktifkan kueri SQL.
- Gunakan antarmuka yang ramah pengguna di Athena untuk menganalisis data XML dengan kueri SQL pada data Anda yang disimpan di Amazon S3.
Arsitektur ini adalah solusi terukur dan hemat biaya untuk menganalisis data XML di Amazon S3 menggunakan AWS Glue dan Athena. Anda dapat menganalisis kumpulan data besar tanpa manajemen infrastruktur yang rumit.
Kami menggunakan crawler AWS Glue untuk mengekstrak metadata file XML. Anda dapat memilih pengklasifikasi AWS Glue default untuk klasifikasi XML tujuan umum. Secara otomatis mendeteksi struktur dan skema data XML, yang berguna untuk format umum.
Kami juga menggunakan pengklasifikasi XML khusus dalam solusi ini. Ini dirancang untuk skema atau format XML tertentu, memungkinkan ekstraksi metadata yang tepat. Ini ideal untuk format XML non-standar atau saat Anda memerlukan kontrol mendetail atas klasifikasi. Pengklasifikasi khusus memastikan hanya metadata yang diperlukan yang diekstraksi, sehingga menyederhanakan tugas pemrosesan dan analisis hilir. Pendekatan ini mengoptimalkan penggunaan file XML Anda.
Tangkapan layar berikut menunjukkan contoh file XML dengan tag.
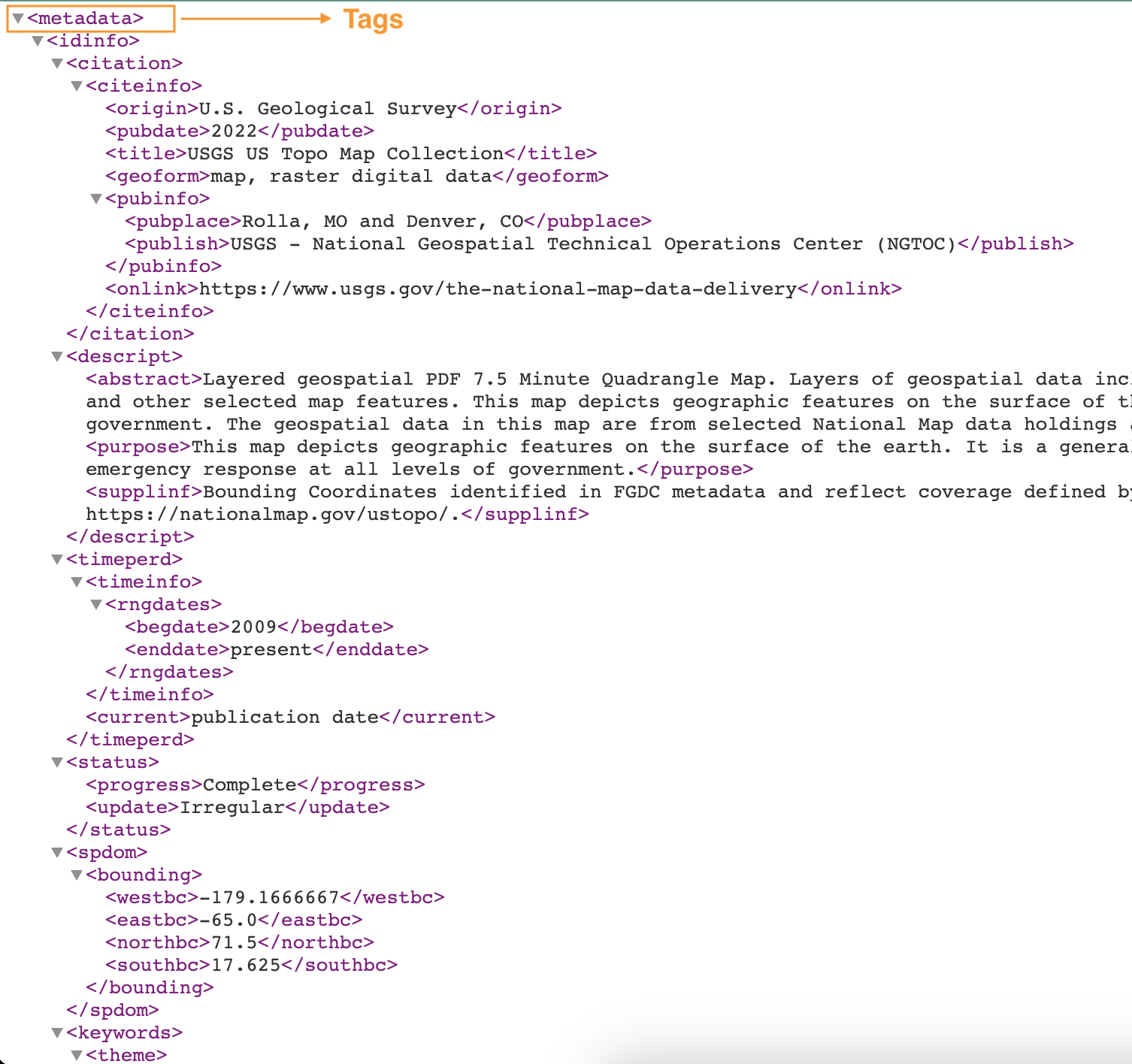
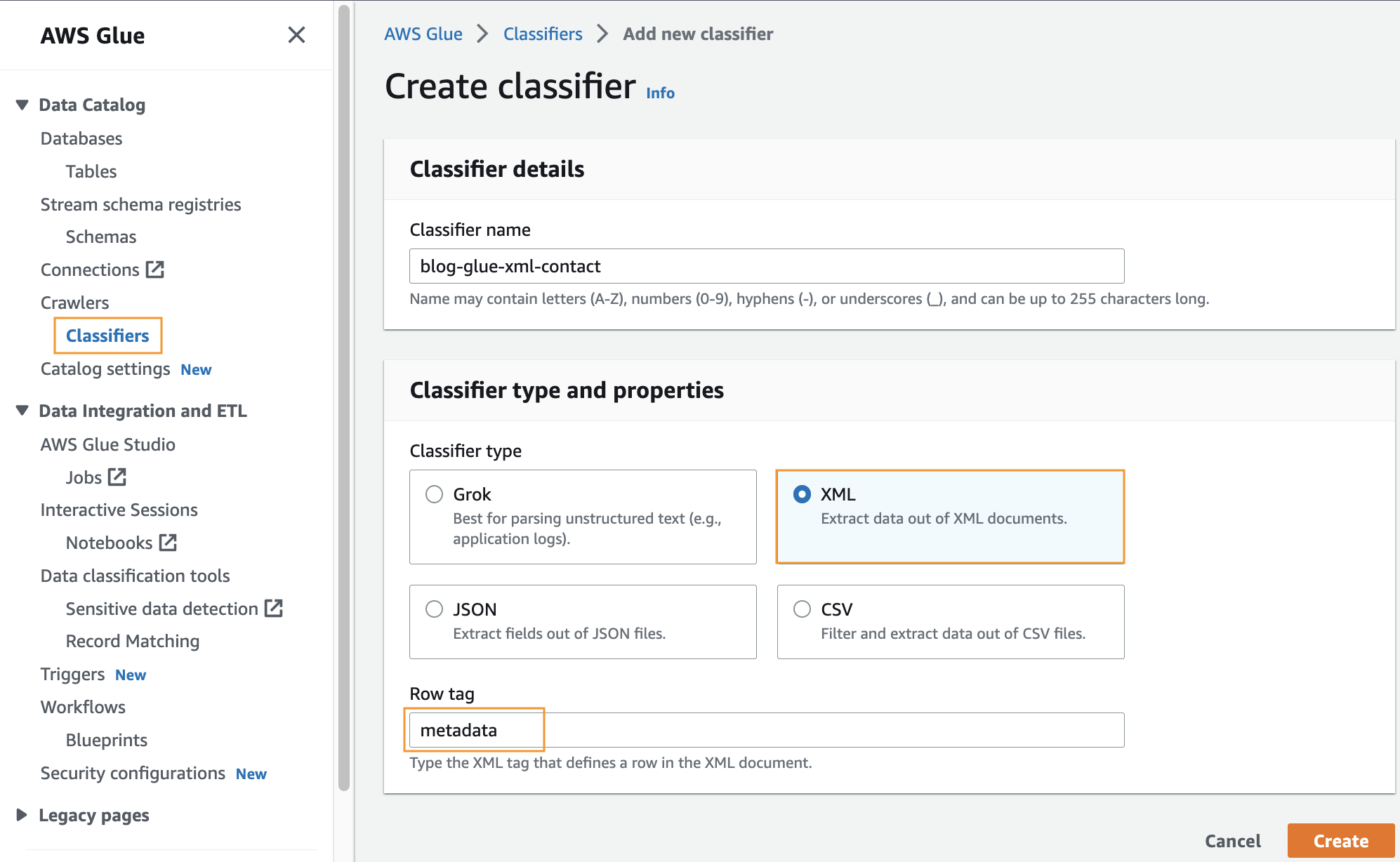
Buat pengklasifikasi khusus
Pada langkah ini, Anda membuat pengklasifikasi AWS Glue khusus untuk mengekstrak metadata dari file XML. Selesaikan langkah-langkah berikut:
- Pada konsol Lem AWS, di bawah Perayap di panel navigasi, pilih Pengklasifikasi.
- Pilih Tambahkan pengklasifikasi.
- Pilih XML sebagai tipe pengklasifikasi.
- Masukkan nama untuk pengklasifikasi, misalnya
blog-glue-xml-contact. - Untuk Tag baris, masukkan nama tag root yang berisi metadata (misalnya,
metadata). - Pilih membuat.
Buat AWS Glue Crawler untuk merayapi file xml
Di bagian ini, kami membuat Glue Crawler untuk mengekstrak metadata dari file XML menggunakan pengklasifikasi pelanggan yang dibuat pada langkah sebelumnya.
Buat database
- Pergi ke Konsol AWS Glue, pilih Database di panel navigasi.
- Klik Tambahkan basis data.
- Berikan nama seperti
blog_glue_xml - Pilih membuat Basis Data
Buat Perayap
Selesaikan langkah-langkah berikut untuk membuat crawler pertama Anda:
- Di konsol AWS Glue, pilih Perayap di panel navigasi.
- Pilih Buat perayap.
- pada Setel properti perayap halaman, berikan nama untuk crawler baru (misalnya
blog-glue-parquet), lalu pilih Selanjutnya. - pada Pilih sumber data dan pengklasifikasi halaman, pilih Belum bawah Konfigurasi sumber data.
- Pilih Tambahkan penyimpanan data.
- Untuk jalur S3, telusuri ke
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Pastikan Anda memilih folder XML daripada file di dalam folder tersebut.
- Biarkan opsi lainnya sebagai default dan pilih Tambahkan sumber data S3.
- Lihat lebih lanjut Pengklasifikasi khusus – opsional, pilih blog-glue-xml-contact, lalu pilih Selanjutnya dan pertahankan opsi lainnya sebagai default.
- Pilih peran IAM Anda atau pilih Buat peran IAM baru, tambahkan akhiran
glue-xml-contact(sebagai contoh,AWSGlueServiceNotebookRoleBlog), dan pilih Selanjutnya. - pada Tetapkan keluaran dan penjadwalan halaman, di bawah Konfigurasi keluaran, pilih
blog_glue_xmluntuk Basis data sasaran. - Enter
console_sebagai awalan yang ditambahkan ke tabel (opsional) dan di bawahnya Jadwal perayap, atur frekuensinya ke Sesuai permintaan. - Pilih Selanjutnya.
- Tinjau semua parameter dan pilih Buat perayap.
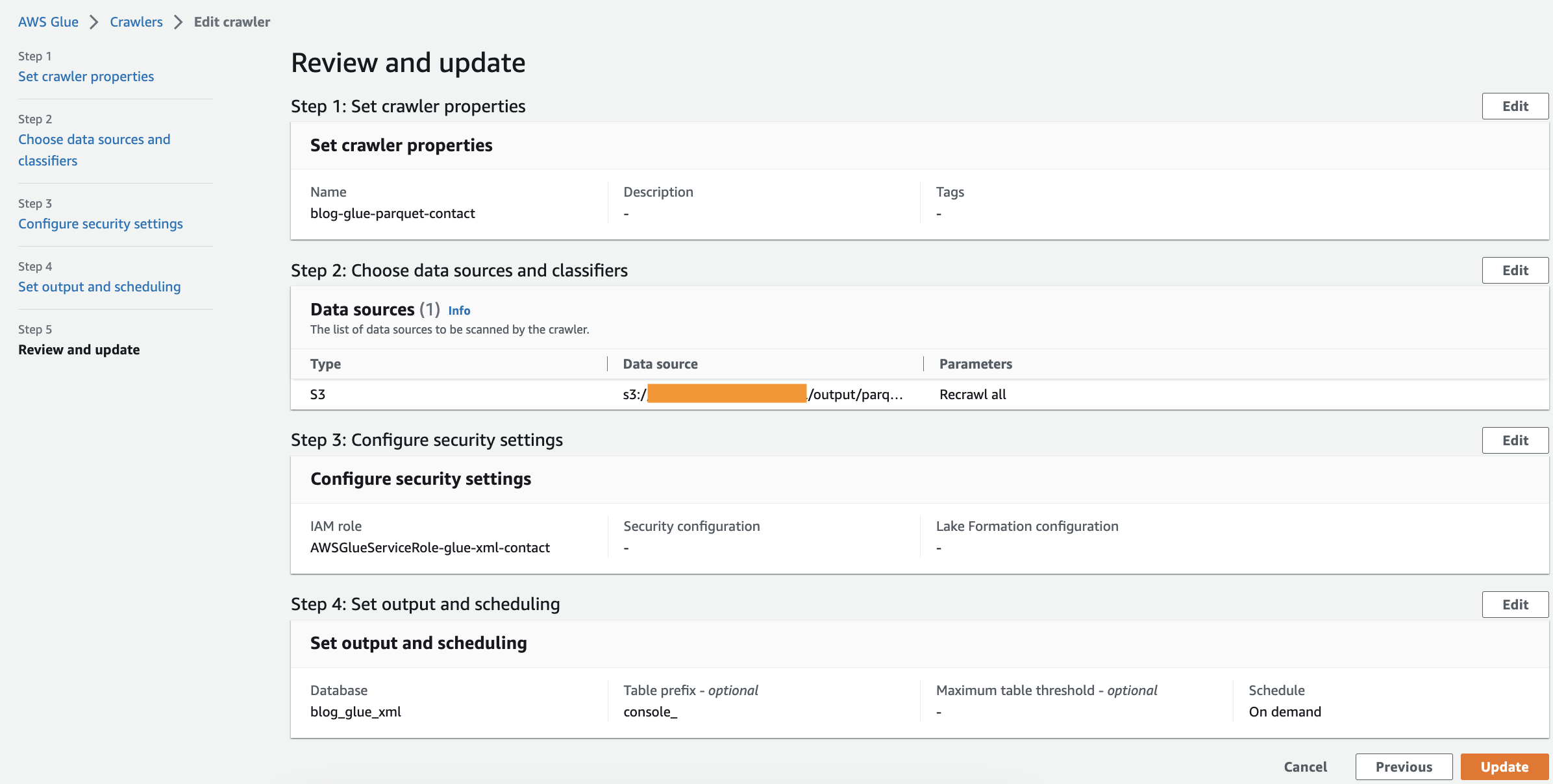
Jalankan Perayap
Setelah Anda membuat crawler, selesaikan langkah-langkah berikut untuk menjalankannya:
- Di konsol AWS Glue, pilih Perayap di panel navigasi.
- Buka crawler yang Anda buat dan pilih Run.
Perayap akan membutuhkan waktu 1–2 menit untuk selesai.
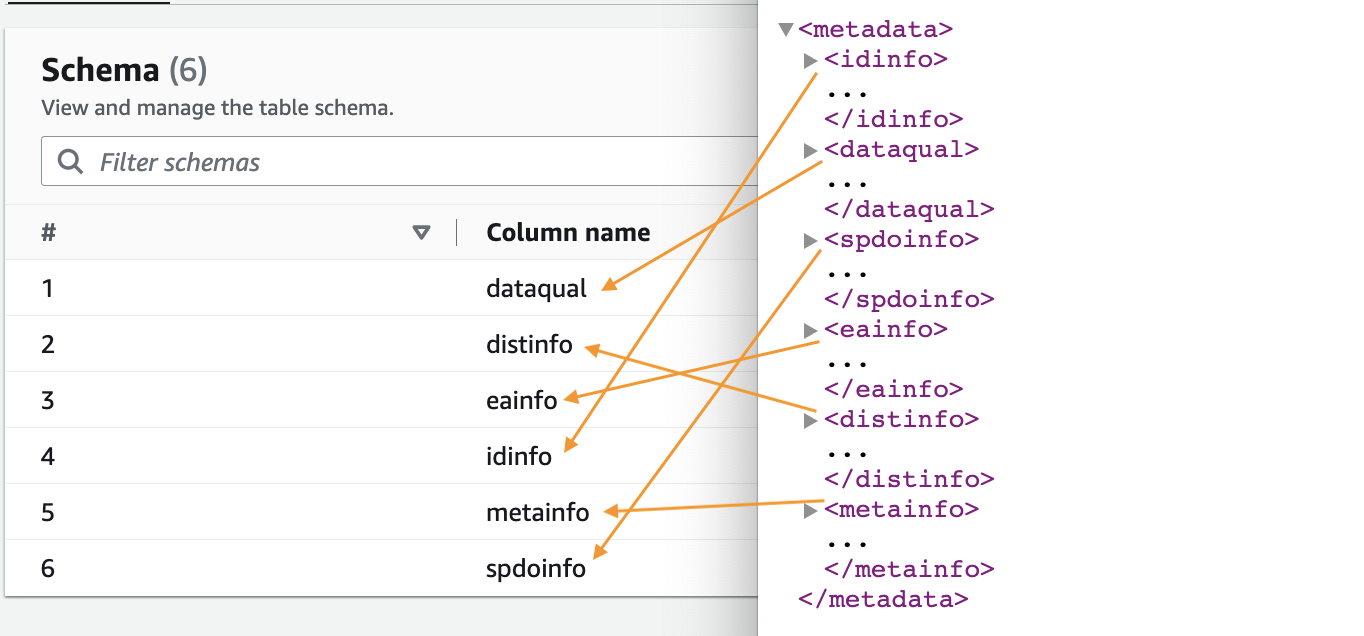
- Saat perayap selesai, pilih Database di panel navigasi.
- Pilih database yang Anda buat dan pilih nama tabel untuk melihat skema yang diekstraksi oleh crawler.
Buat tugas AWS Glue untuk mengonversi format XML ke Parket
Pada langkah ini, Anda membuat tugas AWS Glue Studio untuk mengonversi file XML menjadi file Parket. Selesaikan langkah-langkah berikut:
- Di konsol AWS Glue, pilih Jobs di panel navigasi.
- Bawah Ciptakan pekerjaan, pilih Visual dengan kanvas kosong.
- Pilih membuat.
- Ganti nama pekerjaan menjadi
blog_glue_xml_job.
Sekarang Anda memiliki editor tugas visual AWS Glue Studio yang kosong. Di bagian atas editor terdapat tab untuk berbagai tampilan.
- Pilih Naskah tab untuk melihat shell kosong skrip ETL AWS Glue.
Saat kami menambahkan langkah baru di editor visual, skrip akan diperbarui secara otomatis.
- Pilih Rincian pekerjaan tab untuk melihat semua konfigurasi pekerjaan.
- Untuk Peran IAM, pilih
AWSGlueServiceNotebookRoleBlog. - Untuk Versi lem, pilih Lem 4.0 – Mendukung Spark 3.3, Scala 2, Python 3.
- set Jumlah pekerja yang diminta ke 2.
- set Jumlah percobaan ulang ke 0.
- Pilih visual tab untuk kembali ke editor visual.
- pada sumber menu tarik-turun, pilih Katalog Data AWS Glue.
- pada Properti sumber data – Katalog Data tab, berikan informasi berikut:
- Untuk Basis Data, pilih
blog_glue_xml. - Untuk tabel, pilih tabel yang dimulai dengan nama console_ yang dibuat crawler (misalnya,
console_geologicalsurvey).
- Untuk Basis Data, pilih
- pada Properti simpul tab, berikan informasi berikut:
- Perubahan Nama untuk
geologicalsurveyHimpunan data. - Pilih Tindakan dan transformasi Ubah Skema (Terapkan Pemetaan).
- Pilih Properti simpul dan ubah nama transformasi dari Ubah Skema (Terapkan Pemetaan) menjadi
ApplyMapping. - pada target menu, pilih S3.
- Perubahan Nama untuk
- pada Properti sumber data - S3 tab, berikan informasi berikut:
- Untuk dibentuk, pilih Parket.
- Untuk Jenis Kompresi, pilih Tidak terkompresi.
- Untuk jenis sumber S3, pilih Lokasi S3.
- Untuk URL S3, Masuk
s3://${BUCKET_NAME}/output/parquet/. - Pilih Properti Node dan ubah namanya menjadi
Output.
- Pilih Save untuk menyelamatkan pekerjaan.
- Pilih Run untuk menjalankan pekerjaan.
Tangkapan layar berikut menunjukkan pekerjaan di editor visual.
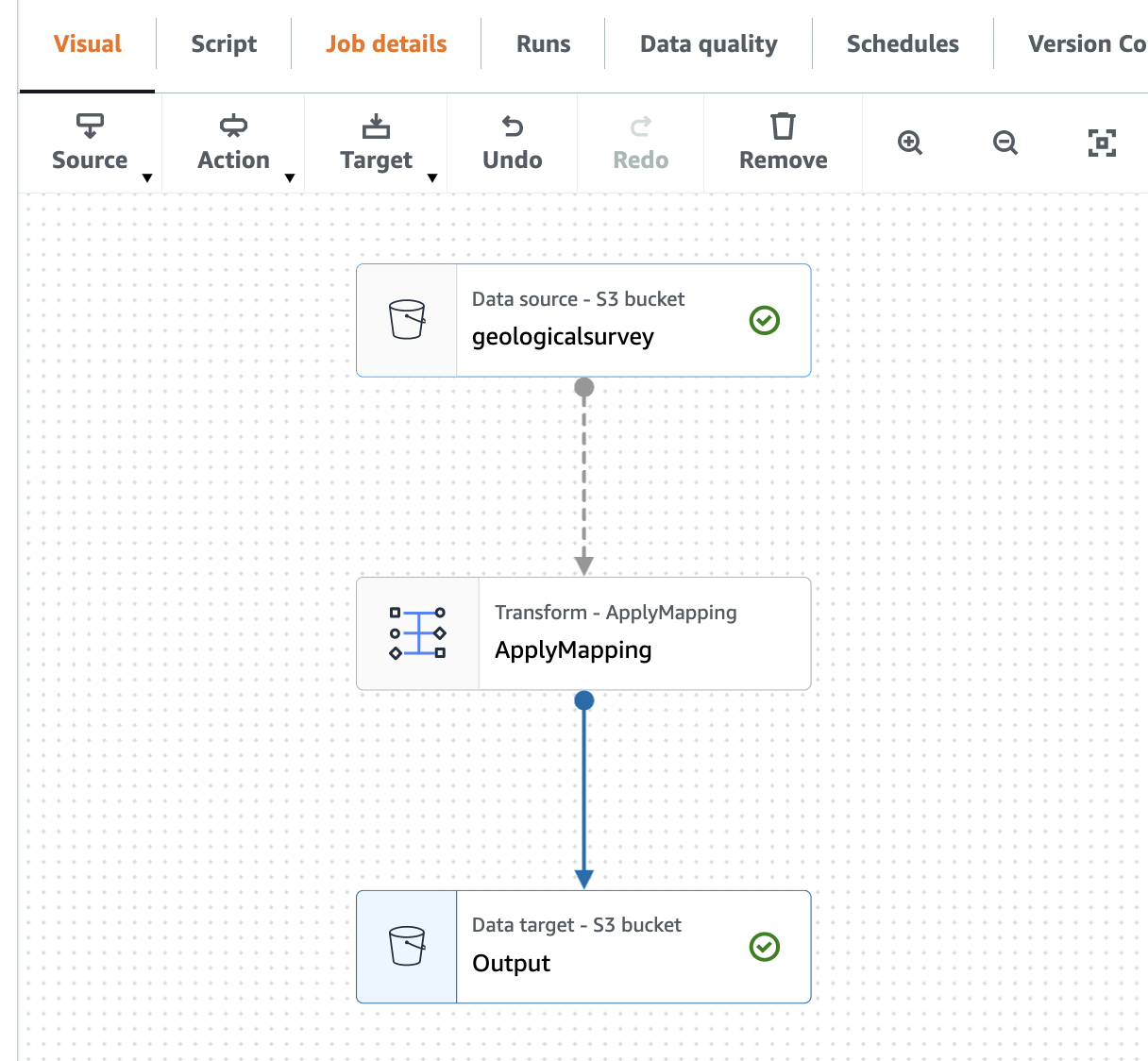
Buat AWS Gue Crawler untuk merayapi file Parket
Pada langkah ini, Anda membuat crawler AWS Glue untuk mengekstrak metadata dari file Parket yang Anda buat menggunakan tugas AWS Glue Studio. Kali ini, Anda menggunakan pengklasifikasi default. Selesaikan langkah-langkah berikut:
- Di konsol AWS Glue, pilih Perayap di panel navigasi.
- Pilih Buat perayap.
- pada Setel properti perayap halaman, berikan nama untuk crawler baru, misalnya blog-lem-parquet-contact, lalu pilih Selanjutnya.
- pada Pilih sumber data dan pengklasifikasi halaman, pilih Belum untuk Konfigurasi sumber data.
- Pilih Tambahkan penyimpanan data.
- Untuk jalur S3, telusuri ke
s3://${BUCKET_NAME}/output/parquet/.
Pastikan Anda memilih parquet folder daripada file di dalam folder.
- Pilih IAM role yang Anda buat pada bagian prasyarat atau pilih Buat peran IAM baru (sebagai contoh,
AWSGlueServiceNotebookRoleBlog), dan pilih Selanjutnya. - pada Tetapkan keluaran dan penjadwalan halaman, di bawah Konfigurasi keluaran, pilih
blog_glue_xmluntuk Basis Data. - Enter
parquet_sebagai awalan yang ditambahkan ke tabel (opsional) dan di bawahnya Jadwal perayap, atur frekuensinya ke Sesuai permintaan. - Pilih Selanjutnya.
- Tinjau semua parameter dan pilih Buat perayap.
Sekarang Anda dapat menjalankan crawler, yang memerlukan waktu 1–2 menit untuk menyelesaikannya.

Anda dapat melihat pratinjau skema yang baru dibuat untuk file Parket di Katalog Data AWS Glue, yang serupa dengan skema file XML.
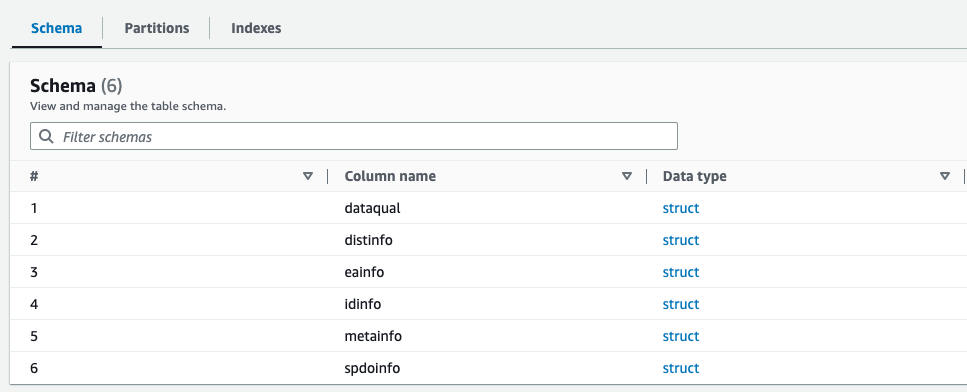
Kami sekarang memiliki data yang cocok untuk digunakan dengan Athena. Di bagian selanjutnya, kami melakukan kueri data menggunakan Athena.
Kueri file Parket menggunakan Athena
Athena tidak mendukung kueri Format berkas XML, itulah sebabnya Anda mengonversi file XML menjadi Parket untuk kueri dan penggunaan data yang lebih efisien notasi titik untuk menanyakan tipe kompleks dan struktur bersarang.
Contoh kode berikut menggunakan notasi titik untuk menanyakan data bertumpuk:
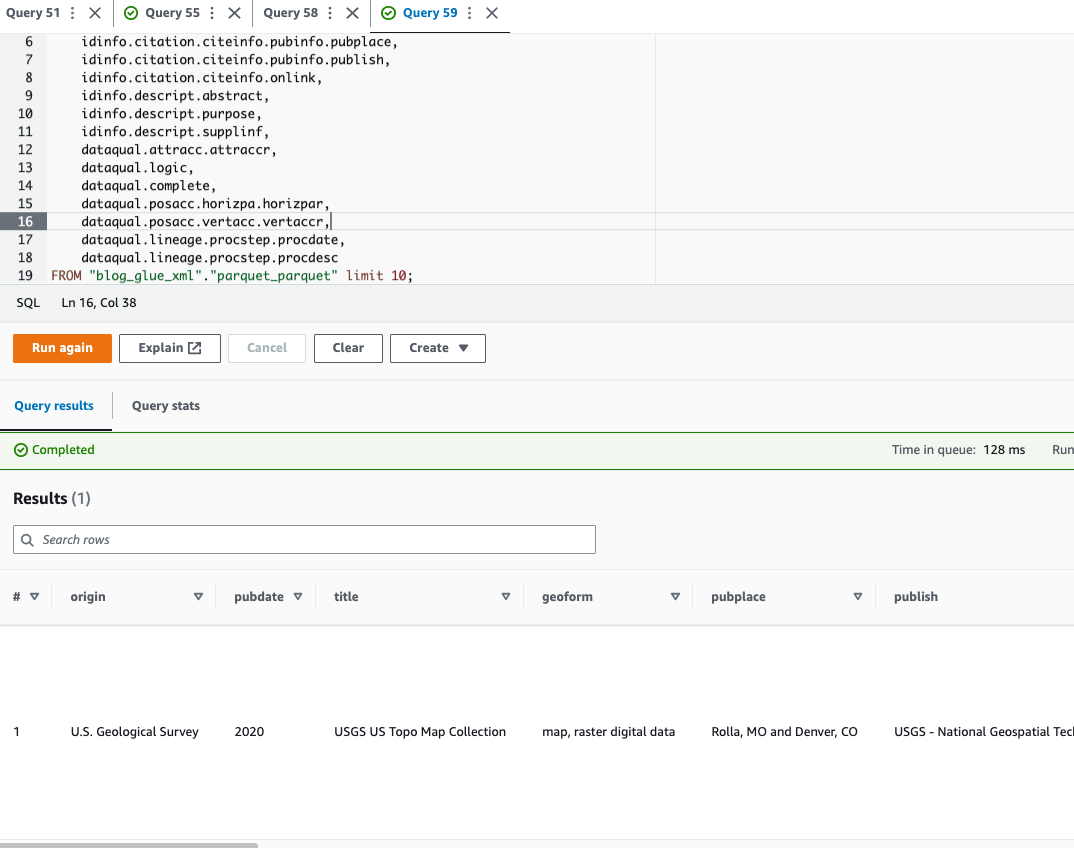
Sekarang kita telah menyelesaikan teknik 1, mari kita lanjutkan mempelajari teknik 2.
Teknik 2: Gunakan AWS Glue DynamicFrames dengan skema yang disimpulkan dan diperbaiki
Di bagian sebelumnya, kita membahas proses penanganan file XML kecil menggunakan crawler AWS Glue untuk menghasilkan tabel, tugas AWS Glue untuk mengonversi file ke format Parket, dan Athena untuk mengakses data Parket. Namun, crawler mengalami keterbatasan saat memproses file XML yang melebihi berukuran 1 MB. Di bagian ini, kita mempelajari topik pemrosesan batch file XML yang lebih besar, yang memerlukan penguraian tambahan untuk mengekstrak peristiwa individual dan melakukan analisis menggunakan Athena.
Pendekatan kami melibatkan membaca file XML melalui AWS Glue Bingkai Dinamis, menggunakan skema yang disimpulkan dan skema tetap. Kemudian kami mengekstrak masing-masing peristiwa dalam format Parket menggunakan menghubungkan transformasi, memungkinkan kami menanyakan dan menganalisisnya dengan lancar menggunakan Athena.
Untuk menerapkan solusi ini, Anda menyelesaikan langkah-langkah tingkat tinggi berikut ini:
- Buat notebook AWS Glue untuk membaca dan menganalisis file XML.
- penggunaan
DynamicFramesdenganInferSchemauntuk membaca file XML. - Gunakan fungsi relasionalisasi untuk menghapus sarang array apa pun.
- Konversikan data ke format Parket.
- Kueri data Parket menggunakan Athena.
- Ulangi langkah sebelumnya, tapi kali ini berikan skema ke
DynamicFramesbukannya menggunakanInferSchema.
File XML data populasi kendaraan listrik memiliki a response tag di tingkat akarnya. Tag ini berisi array row tag, yang bersarang di dalamnya. Tag baris adalah larik yang berisi sekumpulan tag baris lain, yang memberikan informasi tentang kendaraan, termasuk merek, model, dan detail relevan lainnya. Tangkapan layar berikut menunjukkan sebuah contoh.

Buat Buku Catatan AWS Glue
Untuk membuat notebook AWS Glue, selesaikan langkah-langkah berikut:
- Buka Studio Lem AWS konsol, pilih Jobs di panel navigasi.
- Pilih Notebook Jupyter Dan pilihlah membuat.
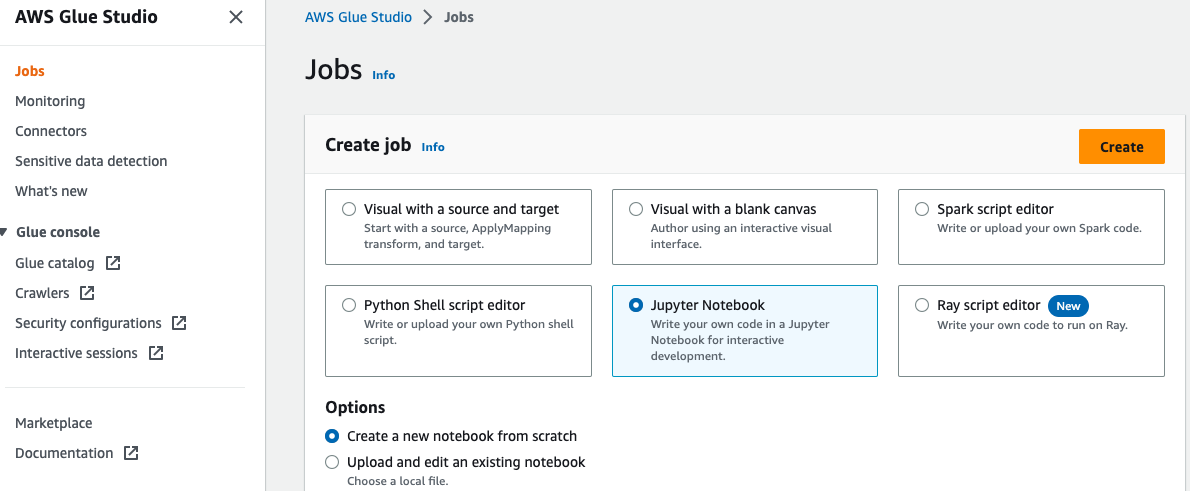
- Masukkan nama untuk tugas AWS Glue Anda, misalnya
blog_glue_xml_job_Jupyter. - Pilih peran yang Anda buat di prasyarat (
AWSGlueServiceNotebookRoleBlog).
Notebook AWS Glue dilengkapi dengan contoh yang sudah ada sebelumnya yang menunjukkan cara melakukan kueri database dan menulis output ke Amazon S3.
- Sesuaikan batas waktu (dalam menit) seperti yang ditunjukkan pada tangkapan layar berikut dan jalankan sel untuk membuat sesi interaktif AWS Glue.
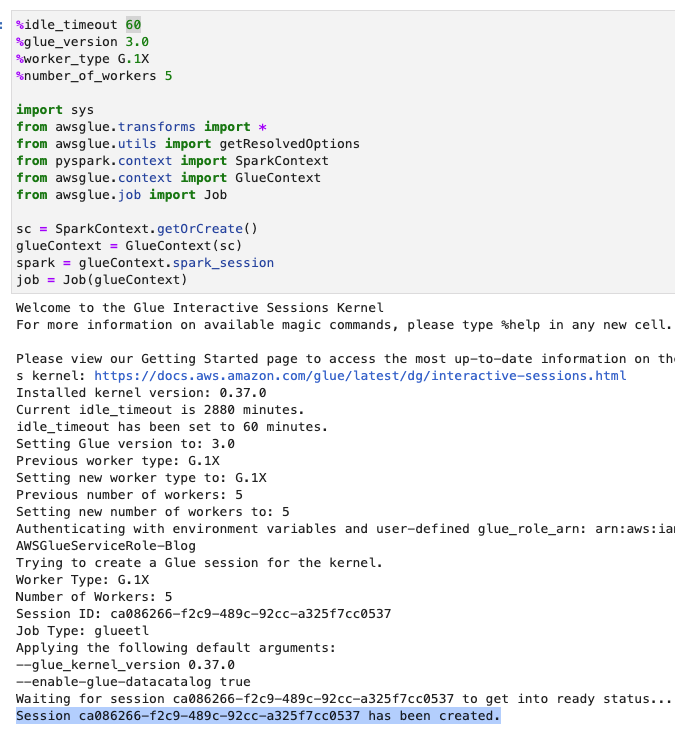
Buat Variabel dasar
Setelah Anda membuat sesi interaktif, di akhir buku catatan, buat sel baru dengan variabel berikut (berikan nama keranjang Anda sendiri):
Baca file XML yang menyimpulkan skema
Jika Anda tidak meneruskan skema ke DynamicFrame, itu akan menyimpulkan skema file. Untuk membaca data menggunakan frame dinamis, Anda dapat menggunakan perintah berikut:
Cetak Skema DynamicFrame
Cetak skema dengan kode berikut:
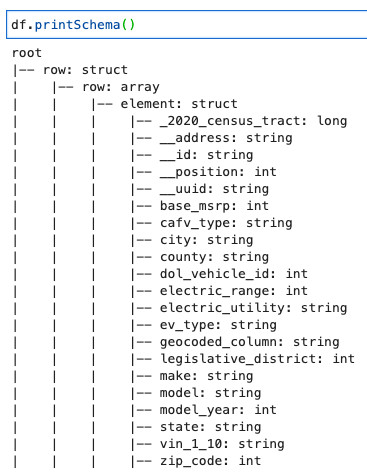
Skema menunjukkan struktur bersarang dengan a row array yang berisi banyak elemen. Untuk memisahkan struktur ini menjadi beberapa garis, Anda dapat menggunakan AWS Glue menghubungkan transformasi:
Kami hanya tertarik pada informasi yang terkandung dalam array baris, dan kami dapat melihat skemanya dengan menggunakan perintah berikut:
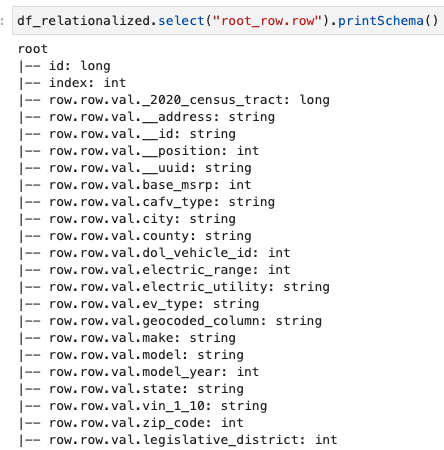
Nama kolom berisi row.row, yang sesuai dengan struktur array dan kolom array dalam kumpulan data. Kami tidak mengganti nama kolom pada postingan ini; untuk instruksi melakukannya, lihat Otomatiskan pemetaan dinamis dan penggantian nama kolom dalam file data menggunakan AWS Glue: Bagian 1. Kemudian Anda dapat mengonversi data ke format Parket dan membuat tabel AWS Glue menggunakan perintah berikut:
Lem AWS DynamicFrame menyediakan fitur yang dapat Anda gunakan dalam skrip ETL Anda untuk membuat dan memperbarui skema di Katalog Data. Kami menggunakan updateBehavior parameter untuk membuat tabel langsung di Katalog Data. Dengan pendekatan ini, kita tidak perlu menjalankan crawler AWS Glue setelah tugas AWS Glue selesai.

Baca file XML dengan mengatur skema
Cara alternatif untuk membaca file adalah dengan menentukan skema sebelumnya. Untuk melakukannya, selesaikan langkah-langkah berikut:
- Impor tipe data AWS Glue:
- Buat skema untuk file XML:
- Lewati skema saat membaca file XML:
- Hapus sarang kumpulan data seperti sebelumnya:
- Konversikan dataset ke Parket dan buat tabel AWS Glue:
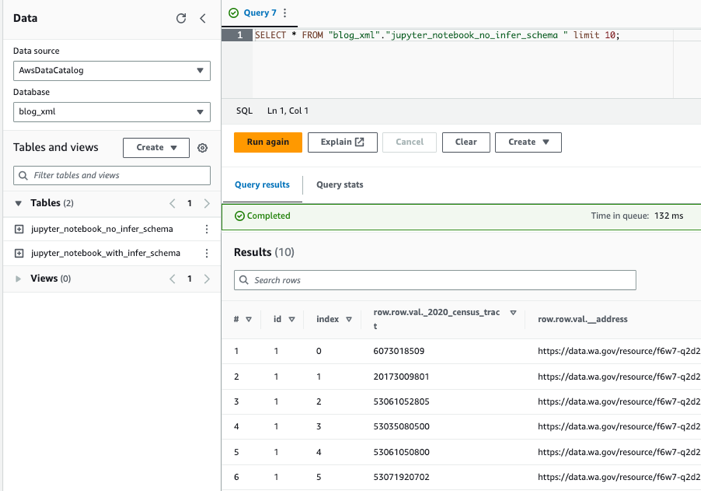
Kueri tabel menggunakan Athena
Sekarang kita telah membuat kedua tabel, kita dapat menanyakan tabel tersebut menggunakan Athena. Misalnya, kita bisa menggunakan kueri berikut:
Membersihkan
Dalam postingan ini, kami membuat IAM role, notebook AWS Glue Jupyter, dan dua tabel di AWS Glue Data Catalog. Kami juga mengunggah beberapa file ke bucket S3. Untuk membersihkan objek ini, selesaikan langkah-langkah berikut:
- Di konsol IAM, hapus peran yang Anda buat.
- Di konsol AWS Glue Studio, hapus pengklasifikasi khusus, crawler, tugas ETL, dan notebook Jupyter.
- Navigasikan ke Katalog Data AWS Glue dan hapus tabel yang Anda buat.
- Di konsol Amazon S3, navigasikan ke bucket yang Anda buat dan hapus folder bernama
temp,infer_schema, danno_infer_schema.
Pengambilan Kunci
Di AWS Glue, ada fitur yang disebut InferSchema di AWS Glue DynamicFrames. Secara otomatis mengetahui struktur bingkai data berdasarkan data yang dikandungnya. Sebaliknya, mendefinisikan skema berarti secara eksplisit menyatakan bagaimana seharusnya struktur bingkai data sebelum memuat data.
XML, sebagai format berbasis teks, tidak membatasi tipe data kolomnya. Hal ini dapat menyebabkan masalah pada fungsi InferSchema. Misalnya, pada proses pertama, file dengan kolom A bernilai 2 menghasilkan file Parket dengan kolom A sebagai bilangan bulat. Pada proses kedua, file baru memiliki kolom A dengan nilai C, yang mengarah ke file Parket dengan kolom A sebagai string. Sekarang ada dua file di S3, masing-masing dengan kolom A dengan tipe data berbeda, yang dapat menimbulkan masalah di hilir.
Hal yang sama terjadi dengan tipe data kompleks seperti struktur atau array bersarang. Misalnya, jika suatu file memiliki satu entri tag yang disebut transaction, itu disimpulkan sebagai sebuah struct. Namun jika file lain memiliki tag yang sama, maka disimpulkan sebagai array
Meskipun ada masalah tipe data ini, InferSchema berguna ketika Anda tidak mengetahui skemanya atau menentukan skema secara manual tidak praktis. Namun, ini tidak ideal untuk kumpulan data yang besar atau terus berubah. Mendefinisikan skema lebih tepat, terutama dengan tipe data yang kompleks, namun memiliki permasalahan tersendiri, seperti memerlukan upaya manual dan tidak fleksibel terhadap perubahan data.
InferSchema memiliki keterbatasan, seperti inferensi tipe data yang salah dan masalah dalam menangani nilai nol. Mendefinisikan skema juga memiliki keterbatasan, seperti upaya manual dan potensi kesalahan.
Memilih antara menyimpulkan dan mendefinisikan skema bergantung pada kebutuhan proyek. InferSchema sangat bagus untuk eksplorasi cepat kumpulan data kecil, sedangkan mendefinisikan skema lebih baik untuk kumpulan data yang lebih besar dan kompleks yang memerlukan akurasi dan konsistensi. Pertimbangkan trade-off dan kendala masing-masing metode untuk memilih yang paling sesuai dengan proyek Anda.
Kesimpulan
Dalam postingan ini, kami mengeksplorasi dua teknik untuk mengelola data XML menggunakan AWS Glue, masing-masing disesuaikan untuk memenuhi kebutuhan dan tantangan spesifik yang mungkin Anda temui.
Teknik 1 menawarkan jalur yang mudah digunakan bagi mereka yang lebih menyukai antarmuka grafis. Anda dapat menggunakan crawler AWS Glue dan editor visual untuk dengan mudah menentukan struktur tabel untuk file XML Anda. Pendekatan ini menyederhanakan proses pengelolaan data dan sangat menarik bagi mereka yang mencari cara mudah untuk menangani data mereka.
Namun, kami menyadari bahwa crawler memiliki keterbatasan, khususnya ketika menangani file XML yang memiliki baris lebih besar dari 1 MB. Di sinilah teknik 2 membantu. Dengan memanfaatkan AWS Glue DynamicFrames dengan skema yang disimpulkan dan tetap, dan menggunakan notebook AWS Glue, Anda dapat menangani file XML dengan ukuran berapa pun secara efisien. Metode ini memberikan solusi tangguh yang memastikan pemrosesan lancar bahkan untuk file XML dengan baris melebihi batasan 1 MB.
Saat Anda menavigasi dunia manajemen data, memiliki teknik ini dalam perangkat Anda akan memberdayakan Anda untuk membuat keputusan berdasarkan kebutuhan spesifik proyek Anda. Baik Anda lebih menyukai kesederhanaan teknik 1 atau skalabilitas teknik 2, AWS Glue memberikan fleksibilitas yang Anda perlukan untuk menangani data XML secara efektif.
Tentang Penulis
 Navnit Shuklaberfungsi sebagai Arsitek Solusi Spesialis AWS dengan fokus pada Analytics. Dia memiliki antusiasme yang kuat untuk membantu klien menemukan wawasan berharga dari data mereka. Melalui keahliannya, ia membangun solusi inovatif yang memberdayakan dunia usaha untuk mengambil keputusan berdasarkan informasi dan data. Khususnya, Navnit Shukla adalah penulis buku berjudul “Data Wrangling on AWS.
Navnit Shuklaberfungsi sebagai Arsitek Solusi Spesialis AWS dengan fokus pada Analytics. Dia memiliki antusiasme yang kuat untuk membantu klien menemukan wawasan berharga dari data mereka. Melalui keahliannya, ia membangun solusi inovatif yang memberdayakan dunia usaha untuk mengambil keputusan berdasarkan informasi dan data. Khususnya, Navnit Shukla adalah penulis buku berjudul “Data Wrangling on AWS.
 Patrick Muller bekerja sebagai Arsitek Lab Data Senior di AWS. Tanggung jawab utamanya adalah membantu pelanggan mengubah ide mereka menjadi produk data siap produksi. Di waktu luangnya, Patrick senang bermain sepak bola, menonton film, dan jalan-jalan.
Patrick Muller bekerja sebagai Arsitek Lab Data Senior di AWS. Tanggung jawab utamanya adalah membantu pelanggan mengubah ide mereka menjadi produk data siap produksi. Di waktu luangnya, Patrick senang bermain sepak bola, menonton film, dan jalan-jalan.
 Amogh Gaikwad adalah Pengembang Solusi Senior di Amazon Web Services. Dia membantu pelanggan global membangun dan menerapkan solusi AI/ML di AWS. Pekerjaannya terutama berfokus pada visi komputer, dan pemrosesan bahasa alami serta membantu pelanggan mengoptimalkan beban kerja AI/ML mereka demi keberlanjutan. Amogh telah menerima gelar masternya di bidang Ilmu Komputer dengan spesialisasi Pembelajaran Mesin.
Amogh Gaikwad adalah Pengembang Solusi Senior di Amazon Web Services. Dia membantu pelanggan global membangun dan menerapkan solusi AI/ML di AWS. Pekerjaannya terutama berfokus pada visi komputer, dan pemrosesan bahasa alami serta membantu pelanggan mengoptimalkan beban kerja AI/ML mereka demi keberlanjutan. Amogh telah menerima gelar masternya di bidang Ilmu Komputer dengan spesialisasi Pembelajaran Mesin.
 Sheela Sonone adalah Arsitek Residen Senior di AWS. Dia membantu pelanggan AWS membuat pilihan dan pengorbanan yang tepat dalam mempercepat data, analitik, serta beban kerja dan implementasi AI/ML. Di waktu luangnya, ia senang menghabiskan waktu bersama keluarganya – biasanya di lapangan tenis.
Sheela Sonone adalah Arsitek Residen Senior di AWS. Dia membantu pelanggan AWS membuat pilihan dan pengorbanan yang tepat dalam mempercepat data, analitik, serta beban kerja dan implementasi AI/ML. Di waktu luangnya, ia senang menghabiskan waktu bersama keluarganya – biasanya di lapangan tenis.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- Tentang Kami
- ABSTRAK
- mempercepat
- mengakses
- aksesibilitas
- dicapai
- ketepatan
- di seluruh
- Tindakan
- menambahkan
- menambahkan
- Tambahan
- alamat
- Setelah
- usia
- AI / ML
- Semua
- mengizinkan
- Membiarkan
- memungkinkan
- juga
- alternatif
- Amazon
- Amazon Athena
- Amazon Web Services
- an
- analisis
- analisis
- menganalisa
- menganalisis
- dan
- Lain
- Apa pun
- Apache
- menarik
- aplikasi
- Mendaftar
- pendekatan
- pendekatan
- arsitektur
- ADALAH
- susunan
- AS
- membantu
- membantu
- At
- penulis
- secara otomatis
- tersedia
- AWS
- Lem AWS
- kembali
- berdasarkan
- dasar
- BE
- karena
- sebelum
- mulai
- makhluk
- TERBAIK
- Lebih baik
- antara
- kosong
- Book
- kedua
- membangun
- bisnis
- tapi
- by
- bernama
- CAN
- katalog
- Menyebabkan
- sel
- tantangan
- perubahan
- Perubahan
- mengubah
- pilihan
- Pilih
- Kota
- klasifikasi
- klien
- kode
- Kolom
- Kolom
- COM
- datang
- Umum
- umum
- lengkap
- Lengkap
- kompleks
- komputer
- Komputer Ilmu
- Visi Komputer
- kondisi
- Mengadakan
- hubungan
- Mempertimbangkan
- konsul
- terus-menerus
- kendala
- membangun
- mengandung
- berisi
- mengandung
- kontras
- kontrol
- mengubah
- dikonversi
- hemat biaya
- solusi hemat biaya
- daerah
- Pengadilan
- tercakup
- crawler
- membuat
- dibuat
- membuat
- sangat penting
- adat
- pelanggan
- pelanggan
- data
- integrasi data
- manajemen data
- Data-driven
- Basis Data
- kumpulan data
- berurusan
- keputusan
- Default
- menetapkan
- mendefinisikan
- menggali
- menunjukkan
- tergantung
- menyebarkan
- dirancang
- terperinci
- rincian
- Pengembang
- berbeda
- sulit
- digital
- era digital
- langsung
- menemukan
- berbeda
- do
- Tidak
- dilakukan
- Dont
- DOT
- selama
- dinamis
- setiap
- memudahkan
- mudah
- Mudah
- editor
- efek
- efektif
- efisiensi
- efisien
- efisien
- usaha
- mudah
- Listrik
- kendaraan listrik
- elemen
- mempekerjakan
- memberdayakan
- memberdayakan
- kosong
- aktif
- memungkinkan
- pertemuan
- akhir
- Mesin
- mempertinggi
- memastikan
- Memastikan
- Enter
- antusiasme
- masuk
- kesalahan
- terutama
- Eter (ETH)
- Bahkan
- peristiwa
- Setiap
- contoh
- melebihi
- bertukar
- keahlian
- eksplorasi
- menyelidiki
- Dieksplorasi
- ekstrak
- ekstraksi
- keluarga
- Fitur
- Fitur
- angka-angka
- File
- File
- keuangan
- Pertama
- tetap
- keluwesan
- Fokus
- terfokus
- berikut
- Untuk
- format
- FRAME
- Gratis
- Frekuensi
- dari
- fungsi
- Mendapatkan
- tujuan umum
- menghasilkan
- Aksi
- Go
- tujuan
- Pemerintah
- besar
- menangani
- Penanganan
- Terjadi
- Memanfaatkan
- Memiliki
- memiliki
- he
- kesehatan
- Hati
- membantu
- membantu
- membantu
- dia
- tingkat tinggi
- sangat
- -nya
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- IAM
- ideal
- ide-ide
- identitas
- if
- menggambarkan
- melaksanakan
- implementasi
- mengimplementasikan
- mengimpor
- memperbaiki
- ditingkatkan
- in
- Termasuk
- sendiri-sendiri
- individu
- industri
- informasi
- informasi
- Infrastruktur
- inovatif
- dalam
- wawasan
- sebagai gantinya
- instruksi
- mengintegrasikan
- integrasi
- interaktif
- tertarik
- Antarmuka
- ke
- melibatkan
- masalah
- IT
- NYA
- Pekerjaan
- Jobs
- jpg
- json
- Notebook Jupyter
- Menjaga
- Tahu
- laboratorium
- bahasa
- besar
- lebih besar
- terkemuka
- BELAJAR
- pengetahuan
- Tingkat
- 'like'
- MEMBATASI
- pembatasan
- keterbatasan
- baris
- baris
- memuat
- pemuatan
- logika
- mencari
- mesin
- Mesin belajar
- Utama
- terutama
- membuat
- Membuat
- pengelolaan
- pelaksana
- panduan
- manual
- banyak
- pemetaan
- tuan
- Mungkin..
- cara
- menu
- Metadata
- metode
- menit
- model
- lebih
- lebih efisien
- paling
- pindah
- bioskop
- beberapa
- nama
- Bernama
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Arahkan
- Navigasi
- perlu
- Perlu
- kebutuhan
- New
- baru saja
- berikutnya
- terutama
- buku catatan
- sekarang
- jumlah
- objek
- of
- Penawaran
- on
- ONE
- hanya
- Operasi
- optimal
- Optimize
- Mengoptimalkan
- Opsi
- or
- urutan
- organisasi
- Asal
- Lainnya
- kami
- di luar
- keluaran
- lebih
- Mengatasi
- sendiri
- halaman
- pane
- parameter
- parameter
- bagian
- khususnya
- lulus
- path
- patrick
- melakukan
- prestasi
- Izin
- memilih
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- kebijaksanaan
- populasi
- memiliki
- Pos
- potensi
- perlu
- lebih suka
- prasyarat
- Preview
- sebelumnya
- masalah
- proses
- diproses
- pengolahan
- Produk
- proyek
- memprojeksikan
- properties
- memberikan
- menyediakan
- menerbitkan
- tujuan
- Ular sanca
- query
- Cepat
- agak
- Baca
- segera
- Bacaan
- alasan
- diterima
- mengenali
- lihat
- relevan
- Persyaratan
- menyelamatkan
- sumber
- tanggapan
- tanggung jawab
- ISTIRAHAT
- membatasi
- pembatasan
- Hasil
- kuat
- Peran
- akar
- BARIS
- Run
- sama
- Save
- Scala
- Skalabilitas
- terukur
- Ilmu
- naskah
- mulus
- mulus
- Kedua
- Bagian
- melihat
- senior
- Layanan
- Sidang
- set
- pengaturan
- beberapa
- dia
- Kulit
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- mirip
- Sederhana
- kesederhanaan
- menyederhanakan
- tunggal
- Ukuran
- kecil
- So
- Sepak bola
- larutan
- Solusi
- beberapa
- sumber
- sumber
- percikan
- spesialis
- mengkhususkan diri
- tertentu
- Secara khusus
- kecepatan
- Pengeluaran
- SQL
- standar
- dimulai
- Negara
- Pernyataan
- menyatakan
- Langkah
- Tangga
- penyimpanan
- tersimpan
- mudah
- mempersingkat
- Tali
- kuat
- struktur
- struktur
- studio
- sukses
- seperti itu
- cocok
- mendukung
- yakin
- Keberlanjutan
- sistem
- tabel
- MENANDAI
- disesuaikan
- Mengambil
- Dibutuhkan
- tugas
- teknik
- tenis
- dari
- bahwa
- Grafik
- informasi
- Dunia
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- ini
- itu
- Melalui
- waktu
- Judul
- berjudul
- untuk
- hari ini
- toolkit
- puncak
- tema
- Mengubah
- Transformasi
- Perjalanan
- Putar
- tutorial
- dua
- mengetik
- jenis
- terakhir
- bawah
- Memperbarui
- diperbarui
- upload
- us
- kegunaan
- menggunakan
- bekas
- Pengguna
- User Interface
- user-friendly
- kegunaan
- menggunakan
- biasanya
- Memanfaatkan
- Berharga
- nilai
- Nilai - Nilai
- kendaraan
- versi
- melalui
- View
- 'view'
- penglihatan
- menonton
- Cara..
- we
- jaringan
- layanan web
- Apa
- ketika
- sedangkan
- apakah
- yang
- SIAPA
- mengapa
- akan
- dengan
- dalam
- tanpa
- Kerja
- alur kerja
- Alur kerja
- bekerja
- dunia
- menulis
- XML
- kamu
- Anda
- zephyrnet.dll