Apache Hudi adalah format tabel terbuka yang menghadirkan kemampuan database dan gudang data ke data lake. Apache Hudi membantu teknisi data mengelola tantangan kompleks, seperti mengelola kumpulan data yang terus berkembang dengan transaksi sambil mempertahankan performa kueri. Insinyur data menggunakan Apache Hudi untuk mengalirkan beban kerja serta membuat saluran data tambahan yang efisien. Hudi menyediakan tabel, transaksi, ups dan delete yang efisien, indeks lanjutan, layanan penyerapan streaming, data kekelompokan dan pemadatan optimasi, dan kontrol konkurensi, sambil menyimpan data Anda dalam format file sumber terbuka. Pengoptimalan kinerja tingkat lanjut Hudi membuat beban kerja analitis lebih cepat dengan mesin kueri populer mana pun termasuk Apache Spark, Presto, Trino, Hive, dan sebagainya.
Banyak pelanggan AWS mengadopsi Apache Hudi di data lake mereka yang dibangun di atas penggunaan Amazon S3 Lem AWS, layanan integrasi data tanpa server yang memudahkan penemuan, persiapan, pemindahan, dan integrasi data dari berbagai sumber untuk analisis, pembelajaran mesin (ML), dan pengembangan aplikasi. Perayap Lem AWS adalah komponen AWS Glue, yang memungkinkan Anda membuat metadata tabel dari konten data secara otomatis tanpa memerlukan definisi metadata secara manual.
Crawler AWS Glue kini mendukung tabel Apache Hudi, menyederhanakan adopsi Katalog Data AWS Glue sebagai katalog untuk tabel Hudi. Salah satu kasus penggunaan yang umum adalah mendaftarkan tabel Hudi, yang tidak memiliki definisi tabel katalog. Kasus penggunaan umum lainnya adalah migrasi dari katalog Hudi lainnya, seperti metastore Hive. Saat bermigrasi dari Katalog Hudi lainnya, Anda dapat membuat dan menjadwalkan crawler AWS Glue dan menyediakan satu atau lebih jalur Amazon S3 tempat file tabel Hudi berada. Anda memiliki opsi untuk memberikan kedalaman maksimum jalur Amazon S3 yang dapat dilintasi crawler AWS Glue. Dengan setiap proses yang dijalankan, crawler AWS Glue akan mengekstrak informasi skema dan partisi serta memperbarui Katalog Data AWS Glue dengan perubahan skema dan partisi. Crawler AWS Glue memperbarui lokasi file metadata terbaru di Katalog Data AWS Glue yang dapat langsung digunakan oleh mesin analitik AWS.
Dengan peluncuran ini, Anda dapat membuat dan menjadwalkan crawler AWS Glue untuk mendaftarkan tabel Hudi di Katalog Data AWS Glue. Anda kemudian dapat menyediakan satu atau beberapa jalur Amazon S3 tempat tabel Hudi berada. Anda memiliki opsi untuk memberikan kedalaman maksimum jalur Amazon S3 yang dapat dilintasi crawler. Dengan setiap crawler dijalankan, crawler memeriksa setiap jalur S3 dan membuat katalog informasi skema, seperti tabel baru, penghapusan, dan pembaruan skema di AWS Glue Data Catalog. Crawler memeriksa informasi partisi dan menambahkan partisi yang baru ditambahkan ke Katalog Data AWS Glue. Crawler juga memperbarui lokasi file metadata terbaru di Katalog Data AWS Glue yang dapat langsung digunakan oleh mesin analitik AWS.
Posting ini menunjukkan cara kerja kemampuan baru untuk merayapi tabel Hudi.
Cara kerja crawler AWS Glue dengan tabel Hudi
Tabel Hudi memiliki dua kategori, dengan implikasi spesifik untuk masing-masing kategori:
- Salin saat menulis (KK) – Data disimpan dalam format kolom (Parket), dan setiap pembaruan membuat versi file baru selama penulisan.
- Gabung saat dibaca (MoR) – Data disimpan menggunakan kombinasi format kolom (Parket) dan berbasis baris (Avro). Pembaruan dicatat berdasarkan baris
deltafile dan dipadatkan sesuai kebutuhan untuk membuat versi baru dari file kolom.
Dengan kumpulan data Kontrak Karya, setiap kali ada pembaruan pada suatu catatan, file yang berisi catatan tersebut ditulis ulang dengan nilai yang diperbarui. Dengan dataset MoR, setiap kali ada update, Hudi hanya menulis baris untuk record yang diubah. MoR lebih cocok untuk beban kerja tulis atau perubahan yang berat dengan jumlah pembacaan yang lebih sedikit. Kontrak Karya lebih cocok untuk beban kerja baca-berat pada data yang lebih jarang berubah.
Hudi menyediakan tiga tipe kueri untuk mengakses data:
- Kueri cuplikan – Kueri yang melihat cuplikan tabel terbaru pada tindakan penerapan atau pemadatan tertentu. Untuk tabel MoR, kueri snapshot mengekspos status tabel terbaru dengan menggabungkan file dasar dan delta dari potongan file terbaru pada saat kueri.
- Kueri tambahan – Kueri hanya melihat data baru yang ditulis ke tabel, sejak penerapan atau pemadatan tertentu. Hal ini secara efektif menyediakan aliran perubahan untuk memungkinkan saluran data tambahan.
- Baca kueri yang dioptimalkan – Untuk tabel MoR, kueri melihat data terbaru yang dipadatkan. Untuk tabel Kontrak Karya, kueri melihat data terbaru yang dilakukan.
Untuk tabel copy-on-write, crawler membuat satu tabel di Katalog Data AWS Glue dengan ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Untuk tabel gabungan saat dibaca, crawler membuat dua tabel di Katalog Data AWS Glue untuk lokasi tabel yang sama:
- Tabel dengan akhiran
_ro, yang menggunakan Serde ReadOptimizedorg.apache.hudi.hadoop.HoodieParquetInputFormat - Tabel dengan akhiran
_rt, yang menggunakan RealTime Serde yang memungkinkan kueri Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Selama setiap perayapan, untuk setiap jalur Hudi yang disediakan, perayap membuat panggilan API daftar Amazon S3, memfilter berdasarkan .hoodie folder, dan temukan file metadata terbaru di bawah folder metadata tabel Hudi tersebut.
Merayapi tabel Kontrak Karya Hudi menggunakan crawler AWS Glue
Di bagian ini, mari kita bahas cara meng-crawl Kontrak Karya Hudi menggunakan crawler AWS Glue.
Prasyarat
Berikut adalah prasyarat untuk tutorial ini:
- Instal dan konfigurasikan Antarmuka Baris Perintah AWS (AWS CLI).
- Buat bucket S3 Anda jika Anda tidak memilikinya.
- Buat IAM role Anda untuk AWS Glue jika Anda tidak memilikinya. Anda membutuhkan
s3:GetObjectuntuks3://your_s3_bucket/data/sample_hudi_cow_table/. - Jalankan perintah berikut untuk menyalin contoh tabel Hudi ke bucket S3 Anda. (Mengganti
your_s3_bucketdengan nama bucket S3 Anda.)
Instruksi ini memandu Anda untuk menyalin data sampel, namun Anda dapat membuat tabel Hudi dengan mudah menggunakan AWS Glue. Pelajari lebih lanjut di Memperkenalkan dukungan asli untuk Apache Hudi, Delta Lake, dan Apache Iceberg di AWS Glue untuk Apache Spark, Bagian 2: Editor Visual AWS Glue Studio.
Buat perayap Hudi
Dalam instruksi ini, buat crawler melalui konsol. Selesaikan langkah-langkah berikut untuk membuat perayap Hudi:
- Di konsol AWS Glue, pilih Perayap.
- Pilih Buat perayap.
- Untuk Nama, Masuk
hudi_cow_crawler. Memilih Selanjutnya. - Bawah Konfigurasi sumber data, memilih Tambahkan sumber data.
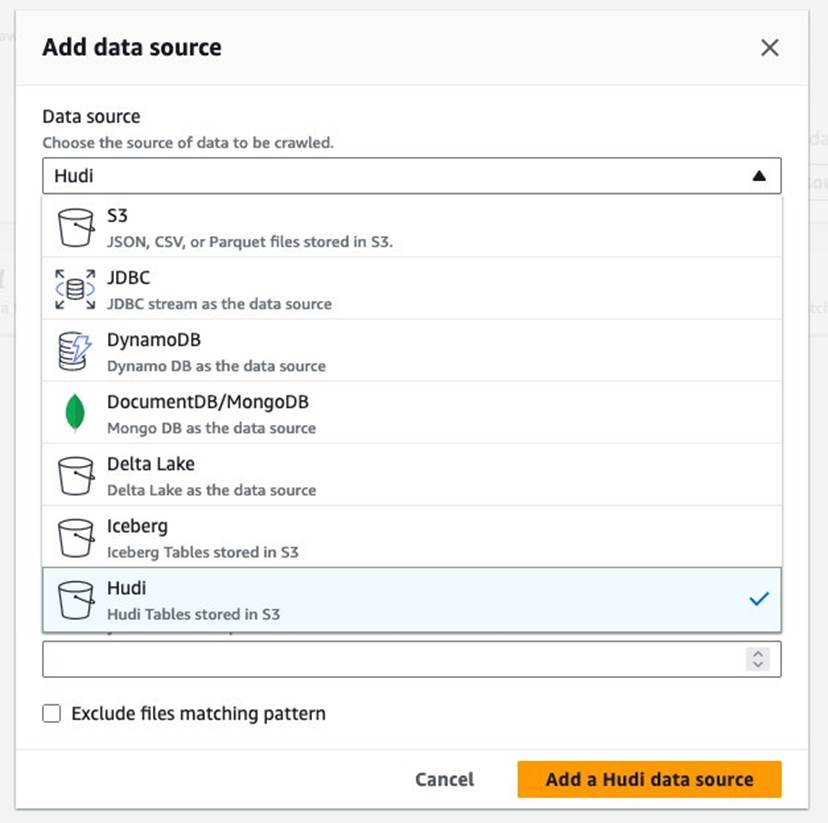
- Untuk Sumber data, pilih hudi.
- Untuk Sertakan jalur tabel hudi, Masuk
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Menggantiyour_s3_bucketdengan nama bucket S3 Anda.) - Pilih Tambahkan sumber data Hudi.
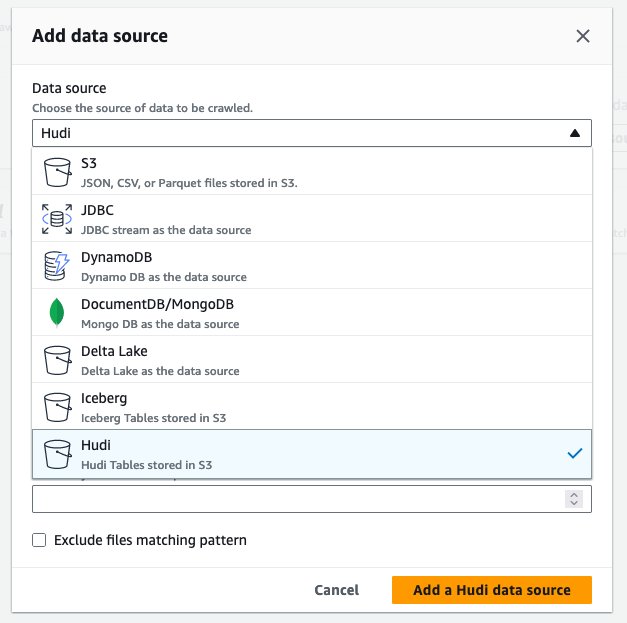
- Pilih Selanjutnya.
- Untuk Peran IAM yang ada, pilih peran IAM Anda, lalu pilih Selanjutnya.
- Untuk Basis data sasaran, pilih Tambahkan database, lalu Tambahkan database dialog muncul. Untuk Nama basis data, Masuk
hudi_crawler_blog, Lalu pilih membuat. Memilih Selanjutnya. - Pilih Buat perayap.
Sekarang crawler Hudi baru telah berhasil dibuat. Crawler dapat dipicu untuk dijalankan melalui konsol atau melalui SDK atau AWS CLI menggunakan StartCrawl API. Itu juga dapat dijadwalkan melalui konsol untuk memicu perayap pada waktu tertentu. Dalam instruksi ini, jalankan perayap melalui konsol.
- Pilih Jalankan crawler.
- Tunggu hingga perayap selesai.
Setelah crawler berjalan, Anda dapat melihat definisi tabel Hudi di konsol AWS Glue:
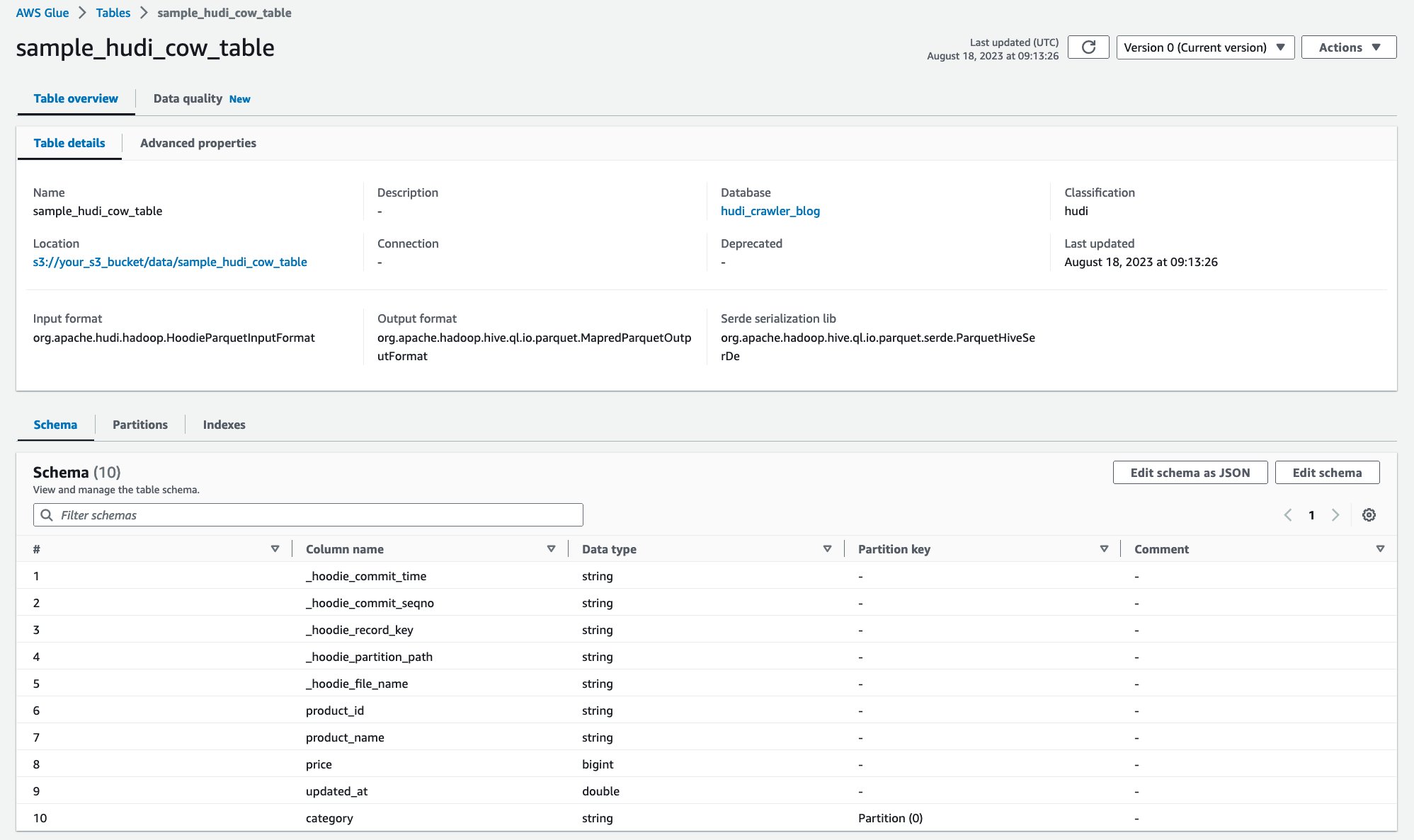
Anda telah berhasil merayapi tabel Hudi CoR dengan data di Amazon S3 dan membuat tabel Katalog Data AWS Glue dengan skema yang terisi. Setelah Anda membuat definisi tabel di AWS Glue Data Catalog, layanan analitik AWS seperti Amazon Athena dapat mengkueri tabel Hudi.
Selesaikan langkah-langkah berikut untuk memulai kueri di Athena:
- Buka konsol Amazon Athena.
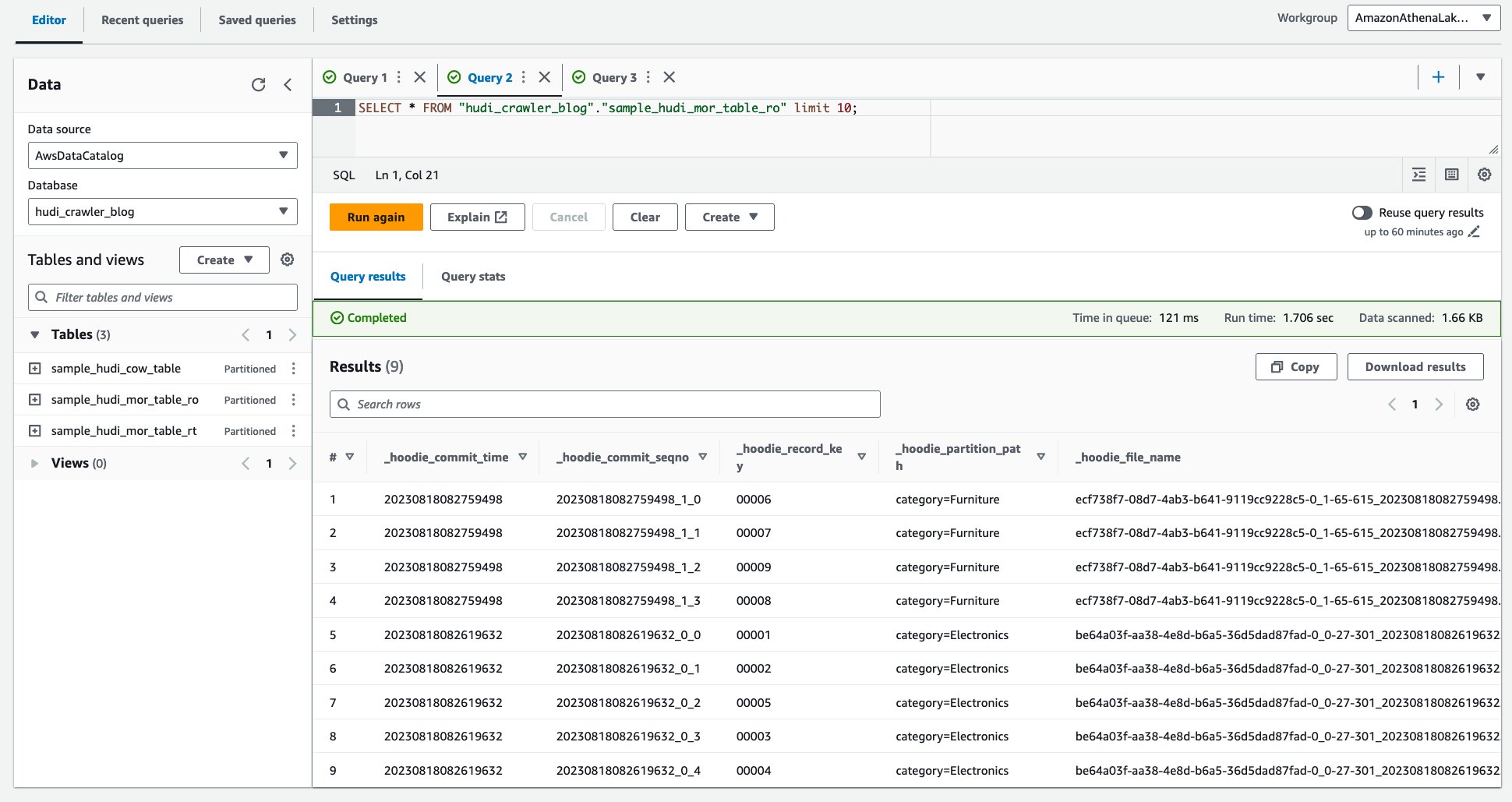
- Jalankan kueri berikut.
Tangkapan layar berikut menunjukkan keluaran kami:
Merayapi tabel Hudi MoR menggunakan crawler AWS Glue dengan izin data AWS Lake Formation
Di bagian ini, mari kita bahas cara meng-crawl tabel Hudi MoR menggunakan AWS Glue. Kali ini, Anda menggunakan izin data AWS Lake Formation untuk merayapi sumber data Amazon S3, bukan izin IAM dan Amazon S3. Ini opsional, namun menyederhanakan konfigurasi izin ketika data lake Anda dikelola oleh izin AWS Lake Formation.
Prasyarat
Berikut adalah prasyarat untuk tutorial ini:
- Instal dan konfigurasikan Antarmuka Baris Perintah AWS (AWS CLI).
- Buat bucket S3 Anda jika Anda tidak memilikinya.
- Buat IAM role Anda untuk AWS Glue jika Anda tidak memilikinya. Anda membutuhkan
lakeformation:GetDataAccess. Tapi kamu tidak perlus3:GetObjectuntuks3://your_s3_bucket/data/sample_hudi_mor_table/karena kami menggunakan izin data Danau Formasi untuk mengakses file. - Jalankan perintah berikut untuk menyalin contoh tabel Hudi ke bucket S3 Anda. (Mengganti
your_s3_bucketdengan nama bucket S3 Anda.)
Selain langkah-langkah pemrosesan, selesaikan langkah-langkah berikut untuk memperbarui pengaturan AWS Glue Data Catalog untuk menggunakan izin Lake Formation untuk mengontrol sumber daya katalog, bukan kontrol akses berbasis IAM:
- Masuk ke konsol Lake Formation sebagai administrator data lake.
- Jika ini pertama kalinya mengakses konsol Lake Formation, tambahkan diri Anda sebagai administrator data lake.
- Bawah Administrasi, pilih Pengaturan katalog data.
- Untuk Izin default untuk database dan tabel yang baru dibuat, batal pilih Gunakan hanya kontrol akses IAM untuk database baru dan Gunakan hanya kontrol akses IAM untuk tabel baru di database baru.
- Untuk Pengaturan versi lintas akun, pilih versi 3.
- Pilih Save.
Langkah selanjutnya adalah mendaftarkan bucket S3 Anda di lokasi data lake Lake Formation:
- Di konsol Formasi Danau, pilih Lokasi data lake, dan pilih Daftarkan lokasi.
- Untuk Jalur Amazon S3, Masuk
s3://your_s3_bucket/. (Menggantiyour_s3_bucketdengan nama bucket S3 Anda.) - Pilih Daftarkan lokasi.
Lalu, berikan akses peran perayap Glue ke lokasi data sehingga perayap dapat menggunakan izin Lake Formation untuk mengakses data dan membuat tabel di lokasi:
- Di konsol Formasi Danau, pilih Lokasi data Dan pilihlah Hibah.
- Untuk Pengguna dan peran IAM, pilih IAM role yang Anda gunakan untuk crawler.
- Untuk Lokasi penyimpanan, Masuk
s3://your_s3_bucket/data/. (Menggantiyour_s3_bucketdengan nama bucket S3 Anda.) - Pilih Hibah.
Kemudian, berikan peran crawler untuk membuat tabel di bawah database hudi_crawler_blog:
- Di konsol Formasi Danau, pilih Izin danau data.
- Pilih Hibah.
- Untuk Kepala sekolah, pilih Pengguna dan peran IAM, dan pilih peran perayap.
- Untuk Tag LF atau sumber katalog, pilih Sumber daya katalog data bernama.
- Untuk Basis Data, pilih databasenya
hudi_crawler_blog. - Bawah Izin basis data, pilih Buat tabel.
- Pilih Hibah.
Buat perayap Hudi dengan izin data Lake Formation
Selesaikan langkah-langkah berikut untuk membuat perayap Hudi:
- Di konsol AWS Glue, pilih Perayap.
- Pilih Buat perayap.
- Untuk Nama, Masuk
hudi_mor_crawler. Memilih Selanjutnya. - Bawah Konfigurasi sumber data, memilih Tambahkan sumber data.
- Untuk Sumber data, pilih hudi.
- Untuk Sertakan jalur tabel hudi, Masuk
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Menggantiyour_s3_bucketdengan nama bucket S3 Anda.) - Pilih Tambahkan sumber data Hudi.
- Pilih Selanjutnya.
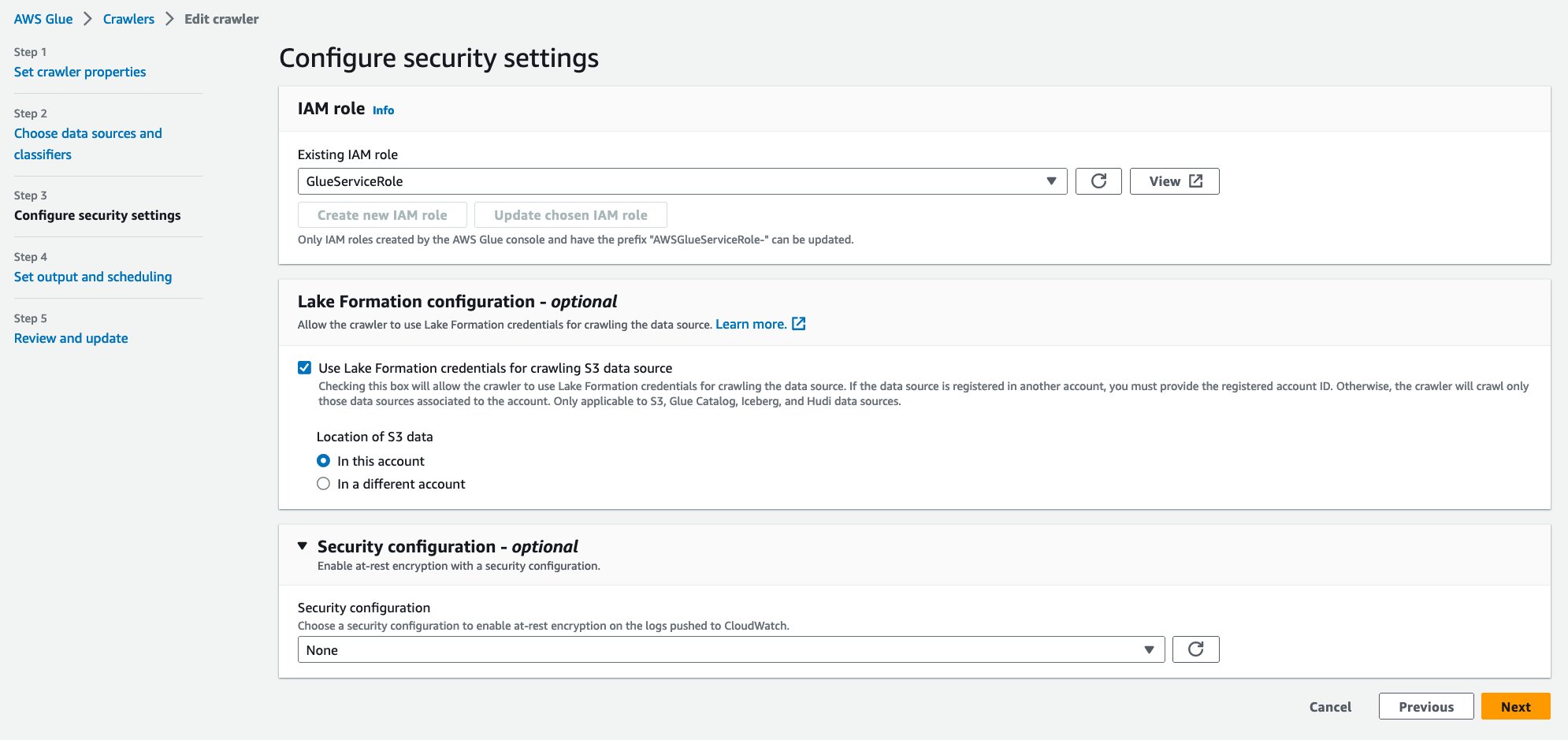
- Untuk Peran IAM yang ada, pilih peran IAM Anda.
- Bawah Konfigurasi Formasi Danau – opsional, pilih Gunakan kredensial Lake Formation untuk merayapi sumber data S3.
- Pilih Selanjutnya.
- Untuk Basis data sasaran, pilih
hudi_crawler_blog. Memilih Selanjutnya. - Pilih Buat perayap.
Sekarang crawler Hudi baru telah berhasil dibuat. Perayap menggunakan kredensi Lake Formation untuk merayapi file Amazon S3. Mari jalankan crawler baru:
- Pilih Jalankan crawler.
- Tunggu hingga perayap selesai.
Setelah crawler berjalan, Anda dapat melihat dua tabel definisi tabel Hudi di konsol AWS Glue:
sample_hudi_mor_table_ro(baca tabel yang dioptimalkan)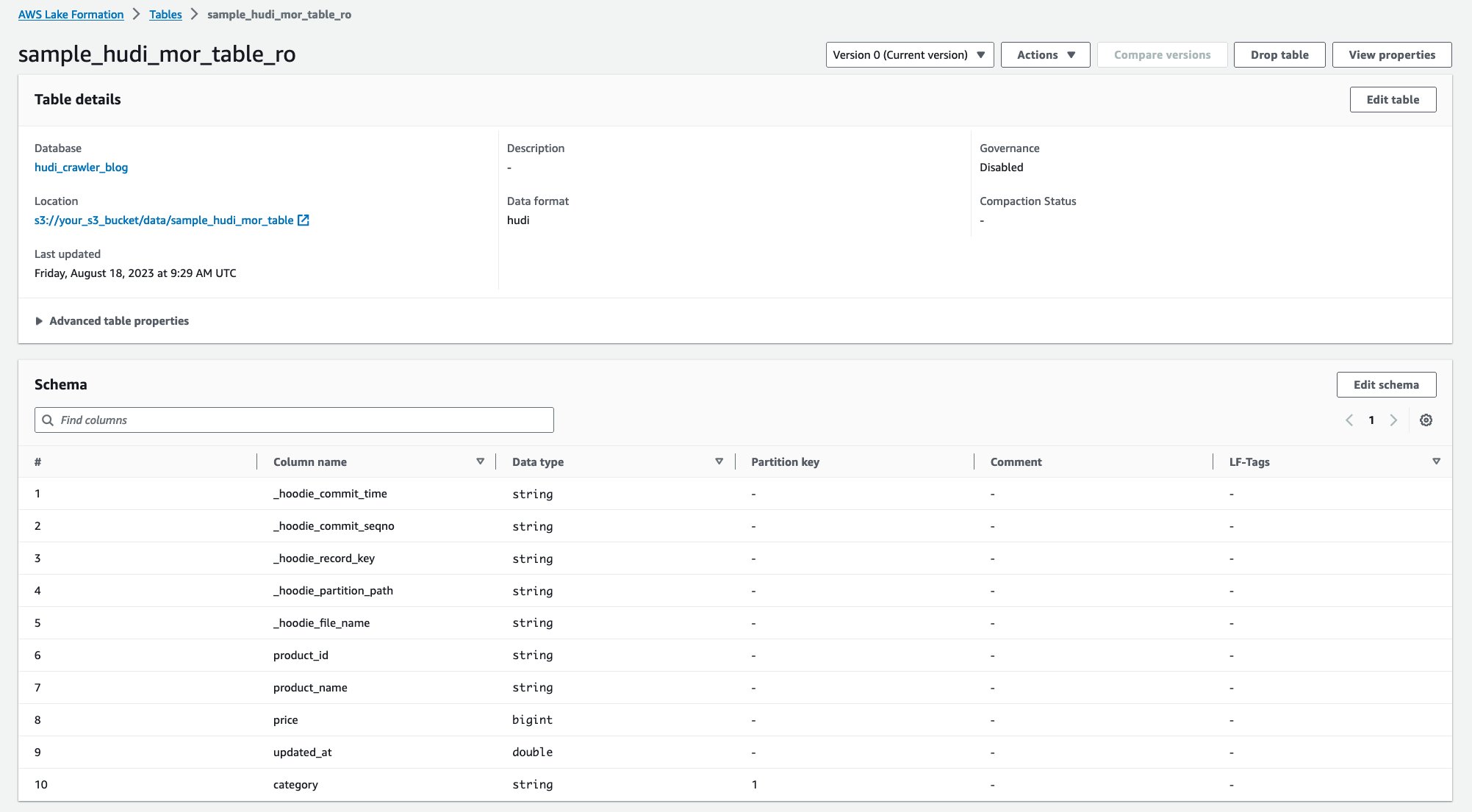
sample_hudi_mor_table_rt(tabel waktu nyata)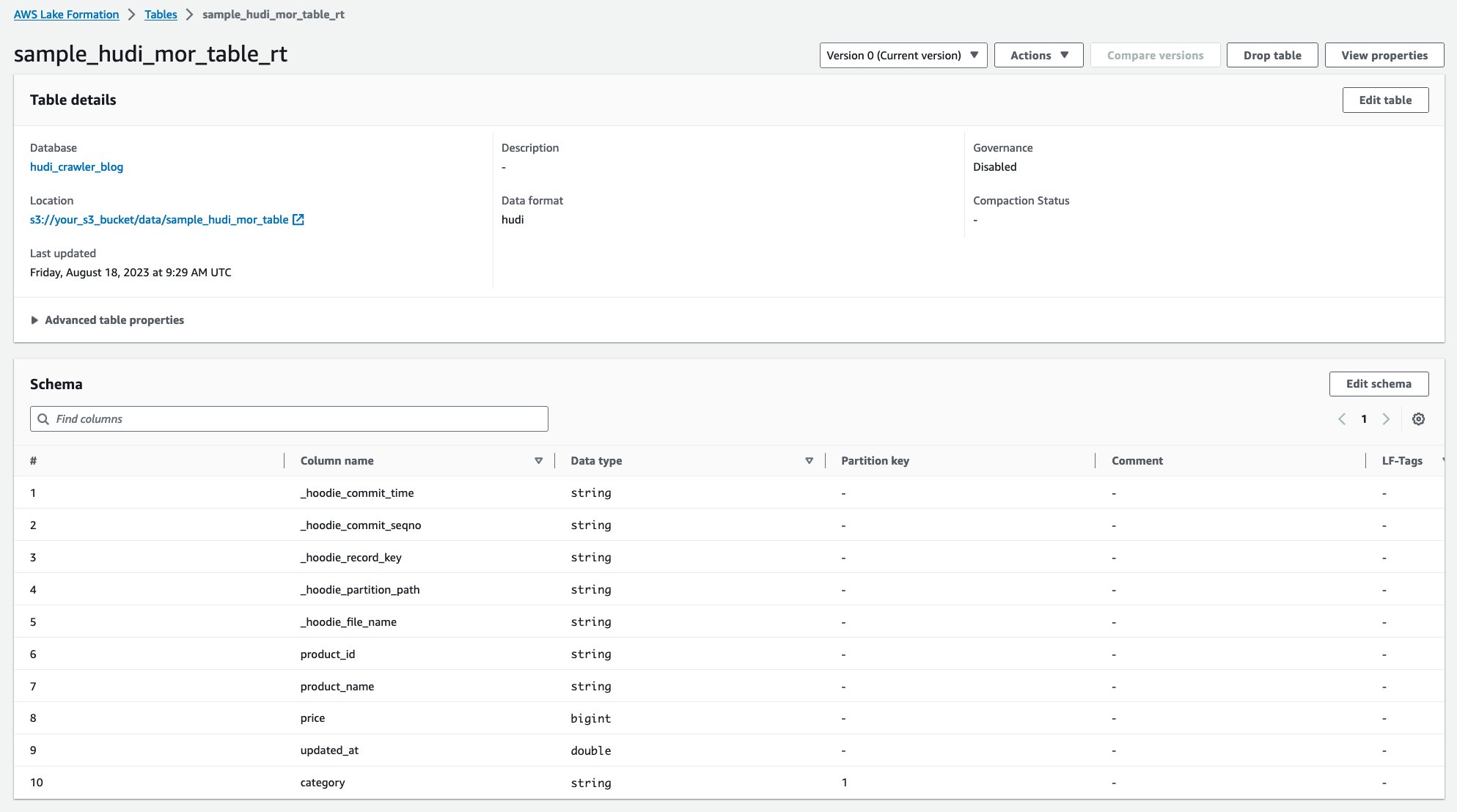
Anda mendaftarkan bucket data lake dengan Lake Formation dan mengaktifkan akses perayapan ke data lake menggunakan izin Lake Formation. Anda telah berhasil merayapi tabel Hudi MoR dengan data di Amazon S3 dan membuat tabel Katalog Data AWS Glue dengan skema yang terisi. Setelah Anda membuat definisi tabel di AWS Glue Data Catalog, layanan analitik AWS seperti Amazon Athena dapat mengkueri tabel Hudi.
Selesaikan langkah-langkah berikut untuk memulai kueri di Athena:
- Buka konsol Amazon Athena.
- Jalankan kueri berikut.
Tangkapan layar berikut menunjukkan keluaran kami:
- Jalankan kueri berikut.
Tangkapan layar berikut menunjukkan keluaran kami:
Kontrol akses terperinci menggunakan izin AWS Lake Formation
Untuk menerapkan kontrol akses terperinci pada tabel Hudi, Anda dapat memanfaatkan izin AWS Lake Formation. Izin Lake Formation memungkinkan Anda membatasi akses ke tabel, kolom, atau baris tertentu dan kemudian menanyakan tabel Hudi melalui Amazon Athena dengan kontrol akses yang sangat detail. Mari konfigurasikan izin Lake Formation untuk tabel Hudi MoR.
Prasyarat
Berikut adalah prasyarat untuk tutorial ini:
- Selesaikan bagian sebelumnya Merayapi tabel Hudi MoR menggunakan crawler AWS Glue dengan izin data AWS Lake Formation.
- Buat DataAnalyst pengguna IAM, yang memiliki kebijakan terkelola AWS AmazonAthenaAkses Penuh.
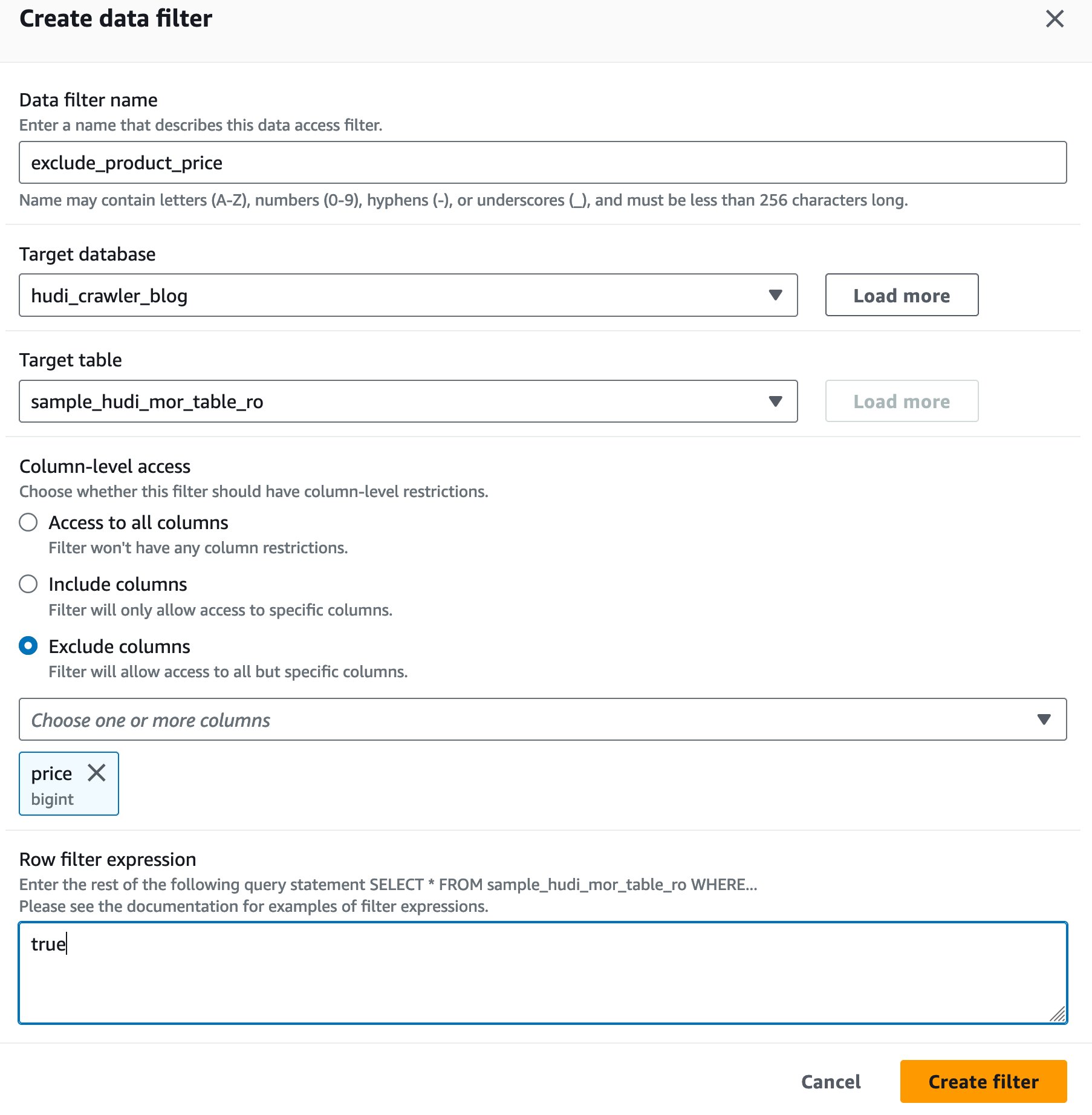
Buat filter sel data Lake Formasi
Pertama-tama mari kita siapkan filter untuk tabel pembacaan MoR yang dioptimalkan.
- Masuk ke konsol Lake Formation sebagai administrator data lake.
- Pilih Filter data.
- Pilih Buat filter baru.
- Untuk Nama filter data, Masuk
exclude_product_price. - Untuk Basis data sasaran, pilih databasenya
hudi_crawler_blog. - Untuk Tabel target, pilih meja
sample_hudi_mor_table_ro. - Untuk Tingkat kolom akses, pilih Kecualikan kolom, dan pilih harga kolom.
- Untuk Ekspresi filter baris, Masuk
true. - Pilih Buat filter.
Berikan izin Lake Formation kepada pengguna DataAnalyst
Selesaikan langkah-langkah berikut untuk memberikan izin Lake Formation kepada DataAnalyst pemakai
- Di konsol Formasi Danau, pilih Izin danau data.
- Pilih Hibah.
- Untuk Kepala sekolah, pilih Pengguna dan peran IAM, dan pilih pengguna
DataAnalyst. - Untuk Tag LF atau sumber katalog, pilih Sumber daya katalog data bernama.
- Untuk Basis Data, pilih databasenya
hudi_crawler_blog. - Untuk Tabel – opsional, pilih meja
sample_hudi_mor_table_ro. - Untuk Filter data – opsional, Pilih
exclude_product_price. - Untuk Izin filter data, pilih Pilih.
- Pilih Hibah.
Anda memberikan izin Lake Formation pada database hudi_crawler_blog dan meja sample_hudi_mor_table_ro, tidak termasuk kolom price kepada pengguna DataAnalyst. Sekarang mari kita validasi akses pengguna ke data menggunakan Athena.
- Masuk ke konsol Athena sebagai pengguna DataAnalyst.
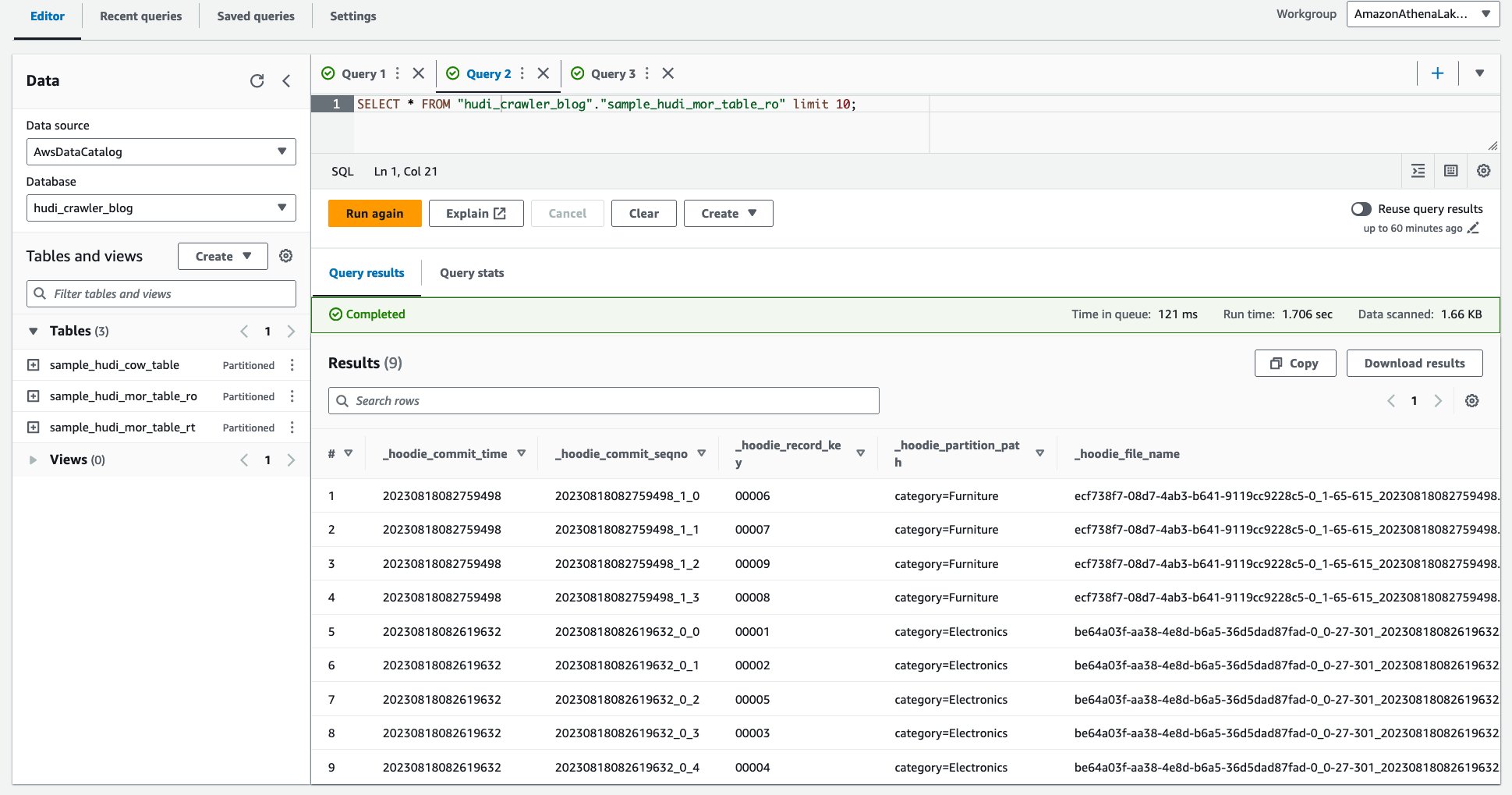
- Di editor kueri, jalankan kueri berikut:
Tangkapan layar berikut menunjukkan keluaran kami:
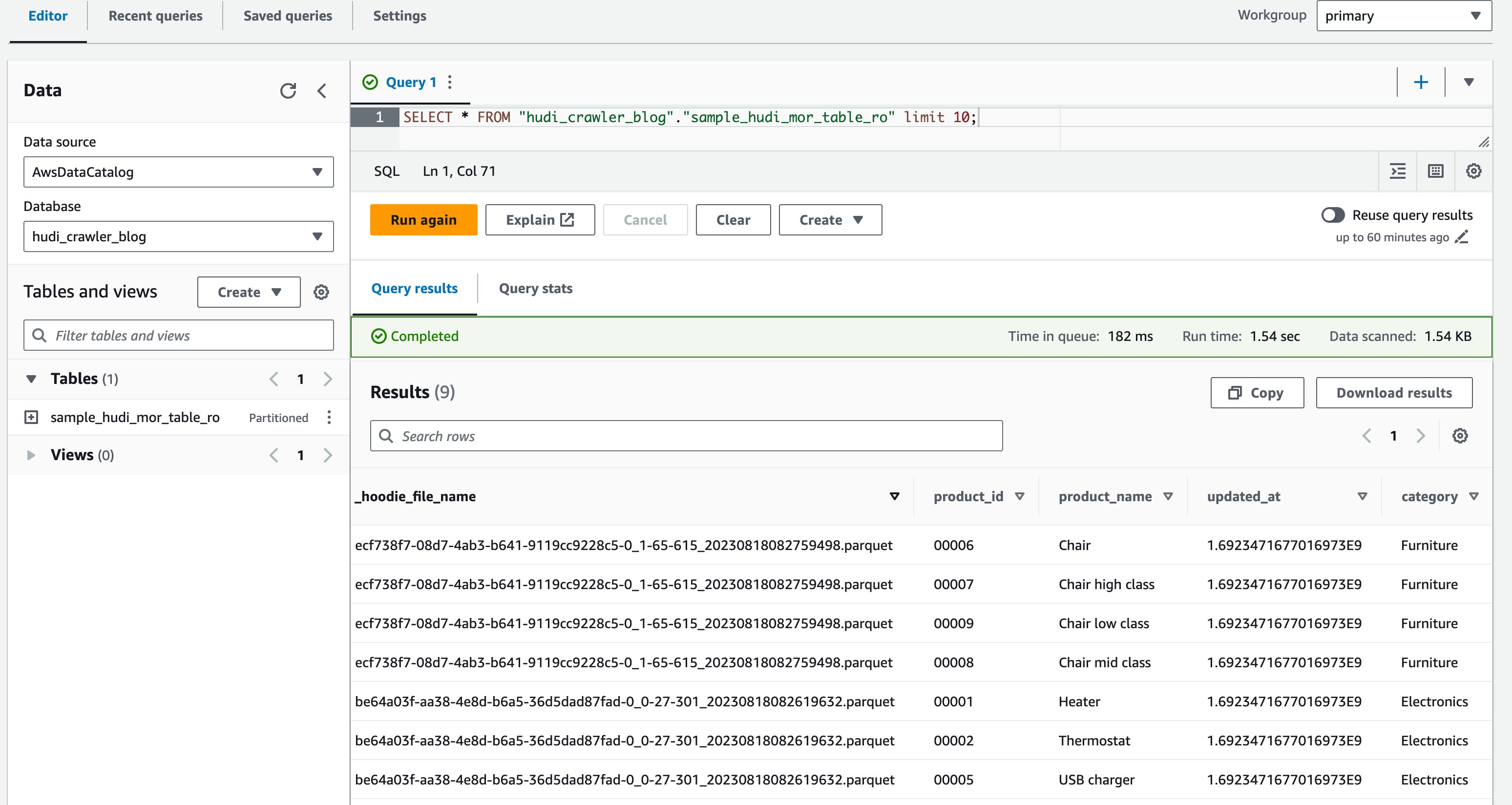
Sekarang Anda memvalidasi kolom itu price tidak ditampilkan, tetapi kolom lainnya product_id, product_name, update_at, dan category ditampilkan.
Membersihkan
Untuk menghindari biaya yang tidak diinginkan ke akun AWS Anda, hapus sumber daya AWS berikut:
- Hapus basis data AWS Glue
hudi_crawler_blog. - Hapus crawler AWS Glue
hudi_cow_crawlerdanhudi_mor_crawler. - Hapus file Amazon S3 di bawah
s3://your_s3_bucket/data/sample_hudi_cow_table/dans3://your_s3_bucket/data/sample_hudi_mor_table/.
Kesimpulan
Postingan ini menunjukkan cara kerja crawler AWS Glue untuk tabel Hudi. Dengan dukungan untuk crawler Hudi, Anda dapat dengan cepat beralih menggunakan AWS Glue Data Catalog sebagai katalog tabel Hudi utama Anda. Anda dapat mulai membangun data lake transaksional tanpa server menggunakan Hudi di AWS menggunakan AWS Glue, Katalog Data AWS Glue, dan kontrol akses terperinci Lake Formation untuk tabel dan format yang didukung oleh mesin analitik AWS.
Tentang penulis
 Noritaka Sekiyama adalah Arsitek Big Data Utama di tim AWS Glue. Dia bekerja berbasis di Tokyo, Jepang. Dia bertanggung jawab untuk membangun artefak perangkat lunak untuk membantu pelanggan. Di waktu luangnya, ia menikmati bersepeda dengan sepeda jalan raya.
Noritaka Sekiyama adalah Arsitek Big Data Utama di tim AWS Glue. Dia bekerja berbasis di Tokyo, Jepang. Dia bertanggung jawab untuk membangun artefak perangkat lunak untuk membantu pelanggan. Di waktu luangnya, ia menikmati bersepeda dengan sepeda jalan raya.
 Kyle Duong adalah Insinyur Pengembangan Perangkat Lunak di tim AWS Glue dan Lake Formation. Dia bersemangat membangun teknologi big data dan sistem terdistribusi.
Kyle Duong adalah Insinyur Pengembangan Perangkat Lunak di tim AWS Glue dan Lake Formation. Dia bersemangat membangun teknologi big data dan sistem terdistribusi.
 Sandeep Adwankar adalah Manajer Produk Teknis Senior di AWS. Berbasis di California Bay Area, dia bekerja dengan pelanggan di seluruh dunia untuk menerjemahkan persyaratan bisnis dan teknis menjadi produk yang memungkinkan pelanggan meningkatkan cara mereka mengelola, mengamankan, dan mengakses data.
Sandeep Adwankar adalah Manajer Produk Teknis Senior di AWS. Berbasis di California Bay Area, dia bekerja dengan pelanggan di seluruh dunia untuk menerjemahkan persyaratan bisnis dan teknis menjadi produk yang memungkinkan pelanggan meningkatkan cara mereka mengelola, mengamankan, dan mengakses data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Sanggup
- Tentang Kami
- mengakses
- Akses ke data
- mengakses
- Akun
- Tindakan
- menambahkan
- menambahkan
- tambahan
- diadopsi
- Adopsi
- maju
- Setelah
- Semua
- mengizinkan
- Membiarkan
- memungkinkan
- juga
- Amazon
- Amazon Athena
- Amazon Web Services
- an
- Analytical
- analisis
- dan
- Lain
- Apa pun
- Apache
- Apache Spark
- api
- muncul
- Aplikasi
- Pengembangan Aplikasi
- Mendaftar
- ADALAH
- DAERAH
- sekitar
- AS
- At
- secara otomatis
- menghindari
- AWS
- Lem AWS
- Formasi Danau AWS
- mendasarkan
- berdasarkan
- Teluk
- BE
- karena
- menjadi
- manfaat
- Lebih baik
- Besar
- Big data
- Membawa
- Bangunan
- dibangun di
- bisnis
- tapi
- by
- california
- panggilan
- CAN
- kemampuan
- kemampuan
- kasus
- katalog
- katalog
- kategori
- sel
- tantangan
- perubahan
- berubah
- Perubahan
- beban
- Pilih
- Kolom
- Kolom
- kombinasi
- melakukan
- berkomitmen
- lengkap
- kompleks
- komponen
- konfigurasi
- konsul
- mengandung
- Konten
- terus menerus
- kontrol
- kontrol
- bisa
- crawler
- membuat
- dibuat
- menciptakan
- Surat kepercayaan
- pelanggan
- data
- integrasi data
- Danau Data
- data warehouse
- Basis Data
- database
- kumpulan data
- definisi
- definisi
- Delta
- menunjukkan
- menunjukkan
- kedalaman
- Pengembangan
- langsung
- menemukan
- didistribusikan
- sistem terdistribusi
- do
- tidak
- selama
- setiap
- mudah
- mudah
- editor
- efektif
- efisien
- aktif
- diaktifkan
- insinyur
- Insinyur
- Mesin
- Enter
- Eter (ETH)
- berkembang
- tidak termasuk
- ekstrak
- lebih cepat
- sedikit
- File
- File
- menyaring
- filter
- Menemukan
- Pertama
- pertama kali
- berikut
- Untuk
- format
- pembentukan
- sering
- dari
- diberikan
- bumi
- Go
- memberikan
- diberikan
- Panduan
- Hadoop
- Memiliki
- he
- membantu
- membantu
- -nya
- Sarang lebah
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- IAM
- if
- implikasi
- memperbaiki
- in
- Termasuk
- inkremental
- informasi
- sebagai gantinya
- mengintegrasikan
- integrasi
- Antarmuka
- ke
- memperkenalkan
- IT
- Jepang
- jpg
- pemeliharaan
- danau
- danau
- Terbaru
- jalankan
- BELAJAR
- pengetahuan
- kurang
- MEMBATASI
- baris
- Daftar
- terletak
- tempat
- lokasi
- login
- mesin
- Mesin belajar
- mempertahankan
- membuat
- MEMBUAT
- mengelola
- berhasil
- manajer
- pelaksana
- panduan
- maksimum
- penggabungan
- Metadata
- bermigrasi
- migrasi
- ML
- lebih
- paling
- pindah
- beberapa
- nama
- asli
- Perlu
- dibutuhkan
- New
- baru saja
- berikutnya
- sekarang
- of
- on
- ONE
- hanya
- Buka
- open source
- dioptimalkan
- pilihan
- or
- Lainnya
- kami
- keluaran
- bagian
- bergairah
- path
- jalan
- prestasi
- izin
- Izin
- plato
- Kecerdasan Data Plato
- Data Plato
- Populer
- diisi
- Pos
- Mempersiapkan
- prasyarat
- sebelumnya
- harga pompa cor beton mini
- primer
- Utama
- pengolahan
- Produk
- manajer produk
- Produk
- memberikan
- disediakan
- menyediakan
- query
- segera
- Baca
- nyata
- real-time
- realtime
- baru
- catatan
- daftar
- terdaftar
- menggantikan
- Persyaratan
- Sumber
- tanggung jawab
- membatasi
- jalan
- Peran
- BARIS
- Run
- sama
- menjadwalkan
- dijadwalkan
- SDK
- Bagian
- aman
- melihat
- memilih
- senior
- Tanpa Server
- layanan
- Layanan
- set
- pengaturan
- ditunjukkan
- Pertunjukkan
- disederhanakan
- sejak
- tunggal
- Iris
- Potret
- So
- Perangkat lunak
- pengembangan perangkat lunak
- sumber
- sumber
- percikan
- tertentu
- awal
- Negara
- Langkah
- Tangga
- tersimpan
- Streaming
- stream
- studio
- berhasil
- seperti itu
- mendukung
- Didukung
- sinkronisasi.
- sistem
- tabel
- tim
- Teknis
- Teknologi
- bahwa
- Grafik
- mereka
- kemudian
- Sana.
- mereka
- ini
- tiga
- Melalui
- waktu
- kali
- untuk
- Tokyo
- puncak
- transaksional
- Transaksi
- menterjemahkan
- melintasi
- memicu
- dipicu
- tutorial
- dua
- jenis
- khas
- bawah
- tidak diinginkan
- Memperbarui
- diperbarui
- Pembaruan
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- kegunaan
- menggunakan
- MENGESAHKAN
- divalidasi
- Nilai - Nilai
- versi
- visual
- Gudang
- we
- jaringan
- layanan web
- BAIK
- ketika
- yang
- sementara
- SIAPA
- akan
- dengan
- tanpa
- Kerja
- bekerja
- menulis
- tertulis
- kamu
- Anda
- diri
- zephyrnet.dll