Data lake yang diberdayakan AWS, didukung oleh ketersediaan yang tak tertandingi Layanan Penyimpanan Sederhana Amazon (Amazon S3), dapat menangani skala, ketangkasan, dan fleksibilitas yang diperlukan untuk menggabungkan berbagai pendekatan data dan analitik. Seiring dengan semakin besarnya ukuran data lake dan semakin matangnya penggunaan, sejumlah besar upaya dapat dilakukan untuk menjaga konsistensi data dengan peristiwa bisnis. Untuk memastikan file diperbarui dengan cara yang konsisten secara transaksional, semakin banyak pelanggan yang menggunakan format tabel transaksi sumber terbuka seperti Gunung Es Apache, Apache Hudi, dan Yayasan Linux Delta Lake yang membantu Anda menyimpan data dengan tingkat kompresi tinggi, berinteraksi secara asli dengan aplikasi dan kerangka kerja Anda, dan menyederhanakan pemrosesan data tambahan di data lake yang dibangun di Amazon S3. Format ini memungkinkan transaksi ACID (atomisitas, konsistensi, isolasi, daya tahan), peningkatan, dan penghapusan, serta fitur lanjutan seperti perjalanan waktu dan snapshot yang sebelumnya hanya tersedia di gudang data. Setiap format penyimpanan mengimplementasikan fungsi ini dengan cara yang sedikit berbeda; untuk perbandingan, lihat Memilih format tabel terbuka untuk data lake transaksional Anda di AWS.
Dalam 2023, AWS mengumumkan ketersediaan umum untuk Apache Iceberg, Apache Hudi, dan Linux Foundation Delta Lake di Amazon Athena untuk Apache Spark, yang menghilangkan kebutuhan untuk memasang konektor terpisah atau dependensi terkait dan mengelola versi, serta menyederhanakan langkah-langkah konfigurasi yang diperlukan untuk menggunakan kerangka kerja ini.
Dalam postingan ini, kami menunjukkan cara menggunakan Spark SQL Amazon Athena buku catatan dan bekerja dengan format tabel Iceberg, Hudi, dan Delta Lake. Kami mendemonstrasikan operasi umum seperti membuat database dan tabel, memasukkan data ke dalam tabel, menanyakan data, dan melihat snapshot tabel di Amazon S3 menggunakan Spark SQL di Athena.
Prasyarat
Lengkapi prasyarat berikut:
Unduh dan impor contoh buku catatan dari Amazon S3
Untuk mengikutinya, unduh buku catatan yang dibahas dalam postingan ini dari lokasi berikut:
Setelah Anda mengunduh buku catatan, impor buku catatan tersebut ke lingkungan Athena Spark Anda dengan mengikuti Untuk mengimpor buku catatan bagian dalam Mengelola file buku catatan.
Arahkan ke bagian Open Table Format tertentu
Jika Anda tertarik dengan format tabel Iceberg, navigasikan ke Bekerja dengan tabel Apache Iceberg bagian.
Jika Anda tertarik dengan format tabel Hudi, navigasikan ke Bekerja dengan tabel Apache Hudi bagian.
Jika Anda tertarik dengan format tabel Delta Lake, navigasikan ke Bekerja dengan tabel Delta Lake fondasi Linux bagian.
Bekerja dengan tabel Apache Iceberg
Saat menggunakan buku catatan Spark di Athena, Anda bisa menjalankan kueri SQL secara langsung tanpa harus menggunakan PySpark. Kami melakukan ini dengan menggunakan keajaiban sel, yang merupakan header khusus di sel buku catatan yang mengubah perilaku sel. Untuk SQL, kita dapat menambahkan %%sql sihir, yang akan menafsirkan seluruh isi sel sebagai pernyataan SQL untuk dijalankan di Athena.
Di bagian ini, kami menunjukkan bagaimana Anda dapat menggunakan SQL di Apache Spark for Athena untuk membuat, menganalisis, dan mengelola tabel Apache Iceberg.
Siapkan sesi buku catatan
Untuk menggunakan Apache Iceberg di Athena, saat membuat atau mengedit sesi, pilih Gunung Es Apache pilihan dengan memperluas Properti Apache Spark bagian. Ini akan mengisi properti seperti yang ditunjukkan pada gambar layar berikut.
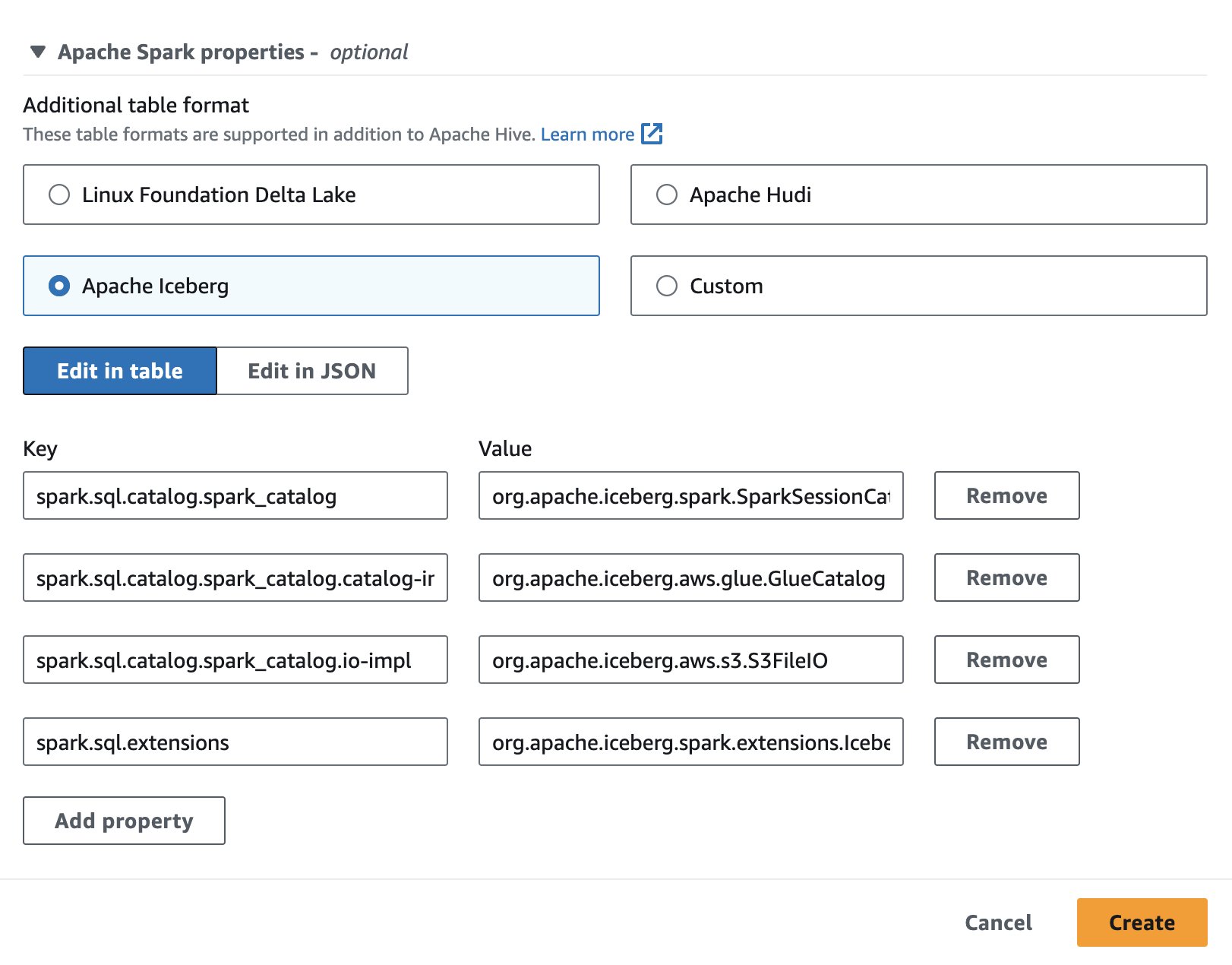
Untuk langkah-langkahnya, lihat Mengedit detail sesi or Membuat buku catatan Anda sendiri.
Kode yang digunakan di bagian ini tersedia di SparkSQL_iceberg.ipynb file untuk diikuti.
Buat database dan tabel Iceberg
Pertama, kita membuat database di Katalog Data AWS Glue. Dengan SQL berikut, kita dapat membuat database bernama icebergdb:
Selanjutnya di database icebergdb, kami membuat tabel Iceberg yang disebut noaa_iceberg menunjuk ke lokasi di Amazon S3 tempat kita akan memuat data. Jalankan pernyataan berikut dan ganti lokasinya s3://<your-S3-bucket>/<prefix>/ dengan bucket dan awalan S3 Anda:
Masukkan data ke dalam tabel
Untuk mengisi noaa_iceberg Tabel Iceberg, kita masukkan data dari tabel Parket sparkblogdb.noaa_pq yang dibuat sebagai bagian dari prasyarat. Anda dapat melakukan ini menggunakan MASUKKAN KE DALAM pernyataan di Spark:
Atau, Anda dapat menggunakan BUAT TABEL SEBAGAI PILIHAN dengan klausa USING iceberg untuk membuat tabel Iceberg dan memasukkan data dari tabel sumber dalam satu langkah:
Kueri tabel Iceberg
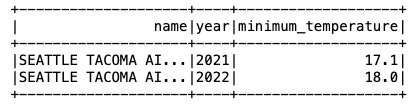
Sekarang data sudah dimasukkan ke dalam tabel Iceberg, kita bisa mulai menganalisisnya. Mari kita jalankan Spark SQL untuk menemukan suhu minimum yang tercatat berdasarkan tahun 'SEATTLE TACOMA AIRPORT, WA US' Lokasi:
Kami mendapatkan output berikut.
Perbarui data di tabel Iceberg
Mari kita lihat cara memperbarui data di tabel kita. Kami ingin memperbarui nama stasiun 'SEATTLE TACOMA AIRPORT, WA US' untuk 'Sea-Tac'. Dengan menggunakan Spark SQL, kita dapat menjalankan UPDATE pernyataan terhadap tabel Iceberg:
Kami kemudian dapat menjalankan kueri SELECT sebelumnya untuk menemukan suhu minimum yang tercatat untuk 'Sea-Tac' Lokasi:
Kami mendapatkan output berikut.

File data ringkas
Format tabel terbuka seperti Iceberg bekerja dengan membuat perubahan delta dalam penyimpanan file, dan melacak versi baris melalui file manifes. Lebih banyak file data menyebabkan lebih banyak metadata yang disimpan dalam file manifes, dan file data yang kecil sering kali menyebabkan jumlah metadata yang tidak perlu, sehingga menghasilkan kueri yang kurang efisien dan biaya akses Amazon S3 yang lebih tinggi. Menjalankan Gunung Es rewrite_data_files prosedur di Spark for Athena akan memadatkan file data, menggabungkan banyak file perubahan delta kecil ke dalam kumpulan file Parket yang lebih kecil dan dioptimalkan untuk dibaca. Memadatkan file mempercepat operasi baca saat ditanya. Untuk menjalankan pemadatan pada tabel kami, jalankan Spark SQL berikut:
rewrite_data_files menawarkan opsi untuk menentukan strategi pengurutan Anda, yang dapat membantu mengatur ulang dan memadatkan data.
Daftar cuplikan tabel
Setiap operasi tulis, perbarui, hapus, upsert, dan pemadatan pada tabel Iceberg membuat snapshot baru dari sebuah tabel sambil tetap menyimpan data dan metadata lama untuk isolasi snapshot dan perjalanan waktu. Untuk mencantumkan cuplikan tabel Iceberg, jalankan pernyataan Spark SQL berikut:
Kedaluwarsa snapshot lama
Disarankan untuk menghapus snapshot yang kedaluwarsa secara berkala untuk menghapus file data yang tidak lagi diperlukan, dan untuk menjaga ukuran metadata tabel tetap kecil. Itu tidak akan pernah menghapus file yang masih diperlukan oleh snapshot yang belum kedaluwarsa. Di Spark for Athena, jalankan SQL berikut untuk mengakhiri masa berlaku snapshot untuk tabel icebergdb.noaa_iceberg yang lebih lama dari stempel waktu tertentu:
Perhatikan bahwa nilai stempel waktu ditentukan sebagai string dalam format yyyy-MM-dd HH:mm:ss.fff. Outputnya akan memberikan hitungan jumlah data dan file metadata yang dihapus.
Jatuhkan tabel dan database
Anda dapat menjalankan Spark SQL berikut untuk membersihkan tabel Iceberg dan data terkait di Amazon S3 dari latihan ini:
Jalankan Spark SQL berikut untuk menghapus database icebergdb:
Untuk mempelajari selengkapnya tentang semua operasi yang dapat Anda lakukan pada tabel Iceberg menggunakan Spark for Athena, lihat Percikan Pertanyaan dan Prosedur Percikan dalam dokumentasi Iceberg.
Bekerja dengan tabel Apache Hudi
Selanjutnya, kami menunjukkan bagaimana Anda dapat menggunakan SQL di Spark for Athena untuk membuat, menganalisis, dan mengelola tabel Apache Hudi.
Siapkan sesi buku catatan
Untuk menggunakan Apache Hudi di Athena, saat membuat atau mengedit sesi, pilih Apache Hudi pilihan dengan memperluas Properti Apache Spark bagian.
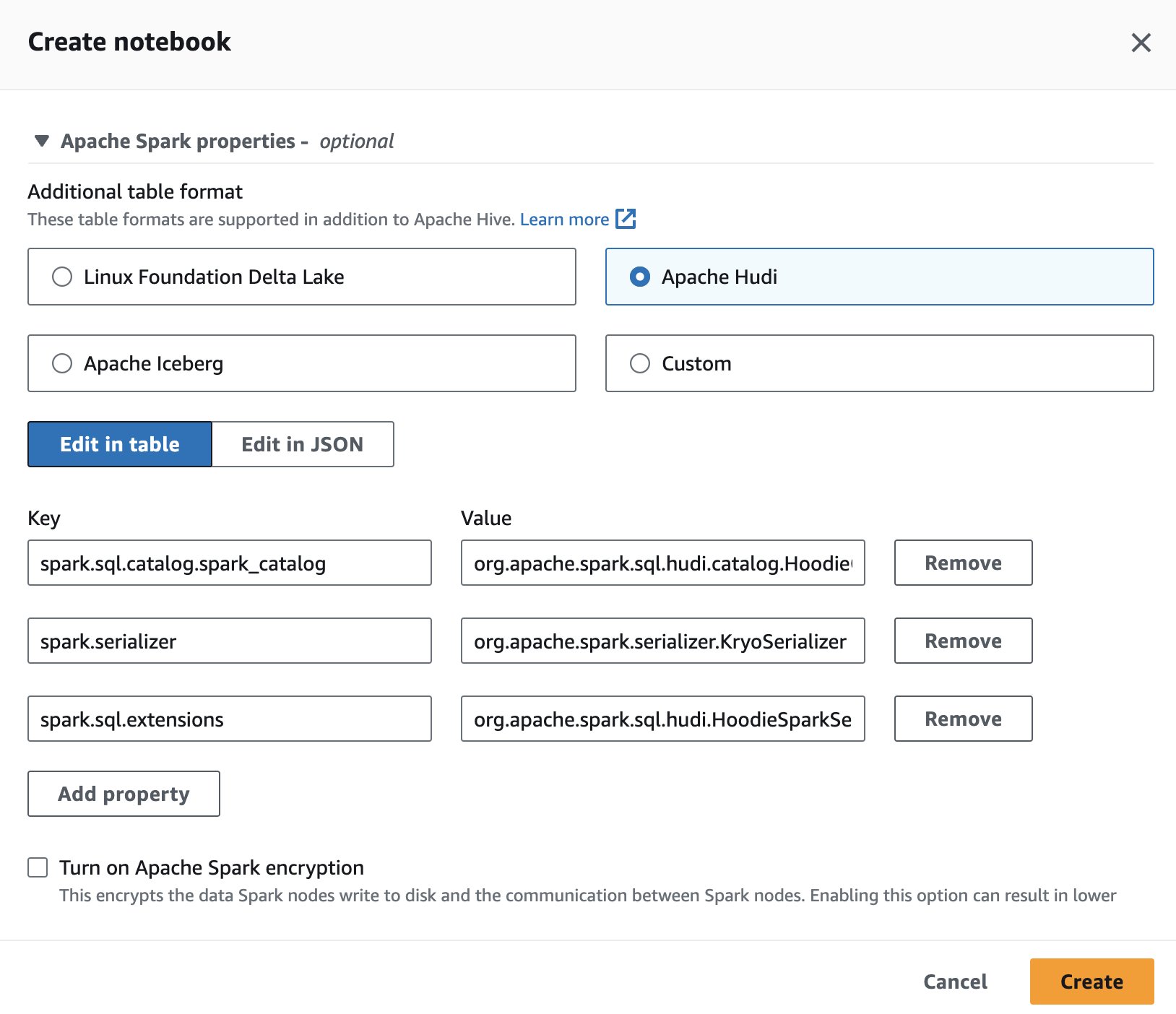
Untuk langkah-langkahnya, lihat Mengedit detail sesi or Membuat buku catatan Anda sendiri.
Kode yang digunakan di bagian ini harus tersedia di SparkSQL_hudi.ipynb file untuk diikuti.
Buat database dan tabel Hudi
Pertama, kita membuat database bernama hudidb yang akan disimpan di Katalog Data AWS Glue diikuti dengan pembuatan tabel Hudi:
Kami membuat tabel Hudi yang menunjuk ke lokasi di Amazon S3 tempat kami akan memuat data. Perhatikan bahwa tabelnya terbuat dari salin-saat-tulis jenis. Hal ini ditentukan oleh type= 'cow' di tabel DDL. Kami telah mendefinisikan stasiun dan tanggal sebagai beberapa kunci utama dan preCombinedField sebagai tahun. Selain itu, tabelnya dipartisi berdasarkan tahun. Jalankan pernyataan berikut dan ganti lokasinya s3://<your-S3-bucket>/<prefix>/ dengan bucket dan awalan S3 Anda:
Masukkan data ke dalam tabel
Seperti halnya Iceberg, kami menggunakan MASUKKAN KE DALAM pernyataan untuk mengisi tabel dengan membaca data dari sparkblogdb.noaa_pq tabel yang dibuat pada postingan sebelumnya:
Kueri tabel Hudi
Sekarang setelah tabel dibuat, mari jalankan kueri untuk menemukan suhu maksimum yang tercatat untuk 'SEATTLE TACOMA AIRPORT, WA US' Lokasi:
Perbarui data di tabel Hudi
Mari kita ubah nama stasiun 'SEATTLE TACOMA AIRPORT, WA US' untuk 'Sea–Tac'. Kita dapat menjalankan pernyataan UPDATE di Spark untuk Athena memperbarui catatan dari noaa_hudi meja:
Kami menjalankan kueri SELECT sebelumnya untuk menemukan suhu maksimum yang tercatat untuk 'Sea-Tac' Lokasi:
Jalankan kueri perjalanan waktu
Kita dapat menggunakan kueri perjalanan waktu dalam SQL di Athena untuk menganalisis cuplikan data masa lalu. Misalnya:
Kueri ini memeriksa data suhu Bandara Seattle pada waktu tertentu di masa lalu. Klausa stempel waktu memungkinkan kita melakukan perjalanan kembali tanpa mengubah data saat ini. Perhatikan bahwa nilai stempel waktu ditentukan sebagai string dalam format yyyy-MM-dd HH:mm:ss.fff.
Optimalkan kecepatan kueri dengan pengelompokan
Untuk meningkatkan kinerja kueri, Anda dapat melakukan kekelompokan pada tabel Hudi menggunakan SQL di Spark for Athena:
Tabel kompak
Pemadatan adalah layanan tabel yang digunakan oleh Hudi khususnya dalam tabel Merge On Read (MOR) untuk menggabungkan pembaruan dari file log berbasis baris ke file dasar berbasis kolom yang sesuai secara berkala untuk menghasilkan versi baru dari file dasar. Pemadatan tidak berlaku pada tabel Copy On Write (COW) dan hanya berlaku pada tabel MOR. Anda dapat menjalankan kueri berikut di Spark for Athena untuk melakukan pemadatan pada tabel MOR:
Jatuhkan tabel dan database
Jalankan Spark SQL berikut untuk menghapus tabel Hudi yang Anda buat dan data terkait dari lokasi Amazon S3:
Jalankan Spark SQL berikut untuk menghapus database hudidb:
Untuk mempelajari tentang semua operasi yang dapat Anda lakukan pada tabel Hudi menggunakan Spark for Athena, lihat SQL DDL dan Prosedur dalam dokumentasi Hudi.
Bekerja dengan tabel Delta Lake fondasi Linux
Selanjutnya, kami memperlihatkan bagaimana Anda dapat menggunakan SQL di Spark for Athena untuk membuat, menganalisis, dan mengelola tabel Delta Lake.
Siapkan sesi buku catatan
Untuk menggunakan Delta Lake di Spark for Athena, saat membuat atau mengedit sesi, pilih Yayasan Linux Delta Lake dengan memperluas Properti Apache Spark bagian.
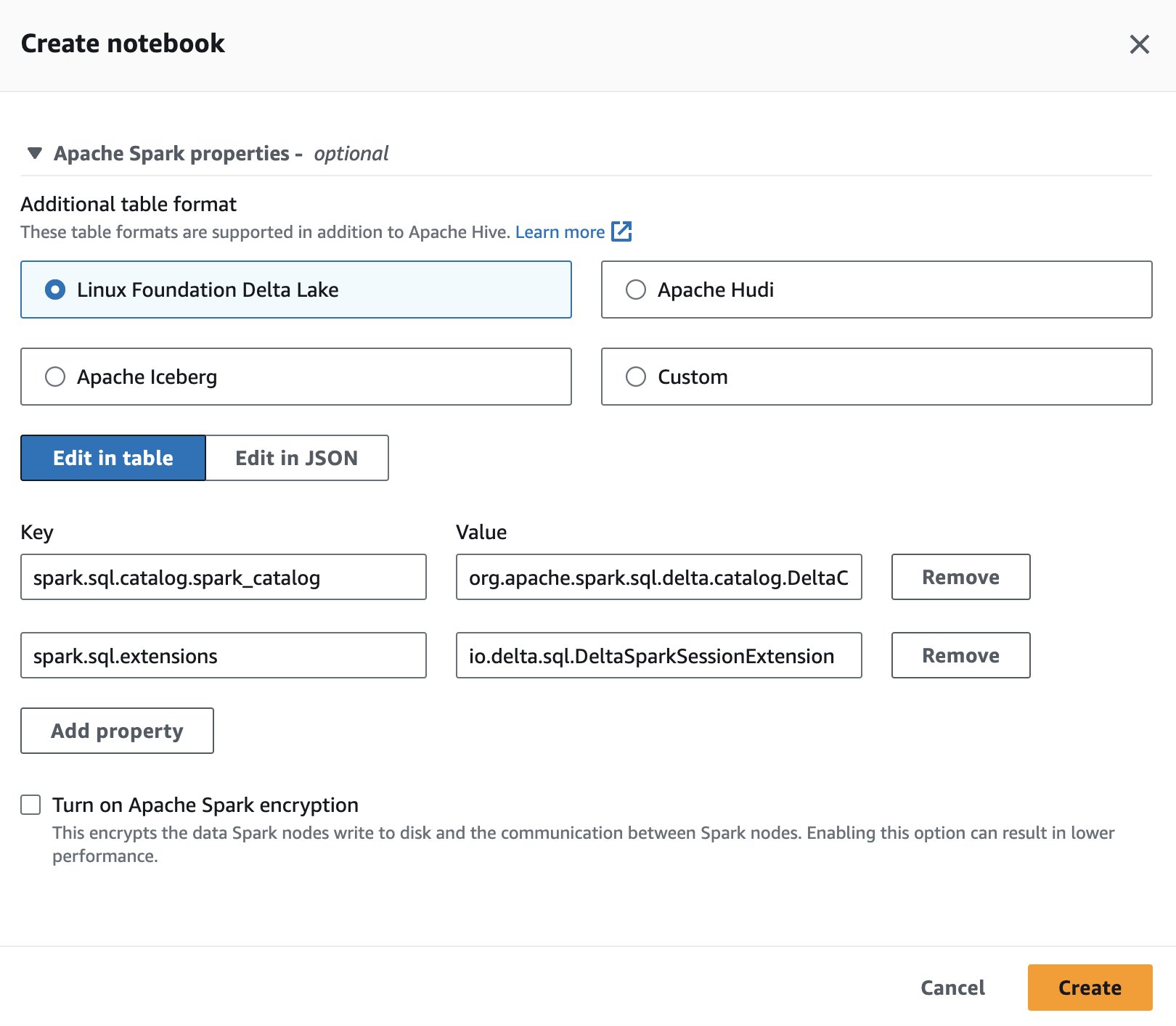
Untuk langkah-langkahnya, lihat Mengedit detail sesi or Membuat buku catatan Anda sendiri.
Kode yang digunakan di bagian ini harus tersedia di SparkSQL_delta.ipynb file untuk diikuti.
Buat database dan tabel Delta Lake
Di bagian ini, kami membuat database di Katalog Data AWS Glue. Dengan menggunakan SQL berikut, kita dapat membuat database bernama deltalakedb:
Selanjutnya di database deltalakedb, kita membuat tabel Delta Lake yang disebut noaa_delta menunjuk ke lokasi di Amazon S3 tempat kita akan memuat data. Jalankan pernyataan berikut dan ganti lokasinya s3://<your-S3-bucket>/<prefix>/ dengan bucket dan awalan S3 Anda:
Masukkan data ke dalam tabel
Kami menggunakan MASUKKAN KE DALAM pernyataan untuk mengisi tabel dengan membaca data dari sparkblogdb.noaa_pq tabel yang dibuat pada postingan sebelumnya:
Anda juga dapat menggunakan CREATE TABLE AS SELECT untuk membuat tabel Delta Lake dan menyisipkan data dari tabel sumber dalam satu kueri.
Kueri tabel Delta Lake
Sekarang data sudah dimasukkan ke dalam tabel Delta Lake, kita bisa mulai menganalisisnya. Mari kita jalankan Spark SQL untuk menemukan suhu minimum yang tercatat untuk 'SEATTLE TACOMA AIRPORT, WA US' Lokasi:
Perbarui data di tabel Delta lake
Mari kita ubah nama stasiun 'SEATTLE TACOMA AIRPORT, WA US' untuk 'Sea–Tac'. Kita bisa menjalankan UPDATE pernyataan tentang Spark untuk Athena untuk memperbarui catatan noaa_delta meja:
Kita dapat menjalankan kueri SELECT sebelumnya untuk menemukan suhu minimum yang tercatat untuk 'Sea-Tac' lokasinya, dan hasilnya harus sama seperti sebelumnya:
File data ringkas
Di Spark for Athena, Anda dapat menjalankan OPTIMIZE pada tabel Delta Lake, yang akan memadatkan file kecil menjadi file yang lebih besar, sehingga kueri tidak terbebani oleh overhead file kecil. Untuk melakukan operasi pemadatan, jalankan kueri berikut:
Lihat Optimasi dalam dokumentasi Delta Lake untuk berbagai opsi yang tersedia saat menjalankan OPTIMIZE.
Hapus file yang tidak lagi direferensikan oleh tabel Delta Lake
Anda dapat menghapus file yang disimpan di Amazon S3 yang tidak lagi direferensikan oleh tabel Delta Lake dan lebih lama dari ambang batas retensi dengan menjalankan perintah VACCUM pada tabel menggunakan Spark for Athena:
Lihat Hapus file yang tidak lagi direferensikan oleh tabel Delta dalam dokumentasi Delta Lake untuk opsi yang tersedia dengan VACUUM.
Jatuhkan tabel dan database
Jalankan Spark SQL berikut untuk menghapus tabel Delta Lake yang Anda buat:
Jalankan Spark SQL berikut untuk menghapus database deltalakedb:
Menjalankan DROP TABLE DDL pada tabel dan database Delta Lake akan menghapus metadata untuk objek ini, namun tidak secara otomatis menghapus file data di Amazon S3. Anda dapat menjalankan kode Python berikut di sel buku catatan untuk menghapus data dari lokasi S3:
Untuk mempelajari selengkapnya tentang pernyataan SQL yang bisa Anda jalankan di tabel Delta Lake menggunakan Spark for Athena, lihat mulai cepat dalam dokumentasi Delta Lake.
Kesimpulan
Postingan ini menunjukkan cara menggunakan Spark SQL di buku catatan Athena untuk membuat database dan tabel, menyisipkan dan mengkueri data, serta melakukan operasi umum seperti pembaruan, pemadatan, dan perjalanan waktu pada tabel Hudi, Delta Lake, dan Iceberg. Format tabel terbuka menambahkan transaksi ACID, upsert, dan penghapusan ke data lake, mengatasi keterbatasan penyimpanan objek mentah. Dengan menghilangkan kebutuhan untuk memasang konektor terpisah, integrasi bawaan Spark on Athena mengurangi langkah-langkah konfigurasi dan overhead manajemen saat menggunakan kerangka kerja populer ini untuk membangun data lake yang andal di Amazon S3. Untuk mempelajari selengkapnya tentang memilih format tabel terbuka untuk beban kerja data lake Anda, lihat Memilih format tabel terbuka untuk data lake transaksional Anda di AWS.
Tentang Penulis
![]() Pathik Syah adalah Sr. Arsitek Analytics di Amazon Athena. Dia bergabung dengan AWS pada tahun 2015 dan sejak saat itu fokus pada bidang analisis big data, membantu pelanggan membangun solusi yang skalabel dan tangguh menggunakan layanan analisis AWS.
Pathik Syah adalah Sr. Arsitek Analytics di Amazon Athena. Dia bergabung dengan AWS pada tahun 2015 dan sejak saat itu fokus pada bidang analisis big data, membantu pelanggan membangun solusi yang skalabel dan tangguh menggunakan layanan analisis AWS.
![]() Raj Devnath adalah Manajer Produk di AWS di Amazon Athena. Dia bersemangat membangun produk yang disukai pelanggan dan membantu pelanggan mendapatkan nilai dari data mereka. Latar belakangnya adalah memberikan solusi untuk berbagai pasar akhir, seperti keuangan, ritel, bangunan pintar, otomatisasi rumah, dan sistem komunikasi data.
Raj Devnath adalah Manajer Produk di AWS di Amazon Athena. Dia bersemangat membangun produk yang disukai pelanggan dan membantu pelanggan mendapatkan nilai dari data mereka. Latar belakangnya adalah memberikan solusi untuk berbagai pasar akhir, seperti keuangan, ritel, bangunan pintar, otomatisasi rumah, dan sistem komunikasi data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Tentang Kami
- mengakses
- menambahkan
- maju
- terhadap
- bandara
- Semua
- sepanjang
- juga
- Amazon
- Amazon Athena
- Amazon Web Services
- jumlah
- an
- analisis
- menganalisa
- menganalisis
- dan
- mengumumkan
- Apache
- Apache Spark
- berlaku
- aplikasi
- berlaku
- pendekatan
- ADALAH
- sekitar
- AS
- terkait
- At
- secara otomatis
- Otomatisasi
- tersedianya
- tersedia
- AWS
- Lem AWS
- kembali
- latar belakang
- mendasarkan
- BE
- menjadi
- laku
- Besar
- Big data
- membangun
- Bangunan
- dibangun di
- built-in
- bisnis
- tapi
- by
- panggilan
- bernama
- CAN
- katalog
- Menyebabkan
- sel
- perubahan
- Perubahan
- Cek
- membersihkan
- kode
- menggabungkan
- menggabungkan
- Umum
- Komunikasi
- sistem komunikasi
- padat
- perbandingan
- konfigurasi
- konsisten
- isi
- Sesuai
- Biaya
- menghitung
- membuat
- dibuat
- menciptakan
- membuat
- penciptaan
- terbaru
- pelanggan
- data
- Data Analytics
- Danau Data
- pengolahan data
- gudang data
- Basis Data
- database
- Tanggal
- didefinisikan
- mengantarkan
- Delta
- mendemonstrasikan
- menunjukkan
- ketergantungan
- berbeda
- langsung
- dibahas
- do
- dokumentasi
- Tidak
- Download
- Menjatuhkan
- daya tahan
- setiap
- Terdahulu
- mengedit
- efisien
- usaha
- dipekerjakan
- aktif
- akhir
- memastikan
- Seluruh
- Lingkungan Hidup
- Eter (ETH)
- peristiwa
- contoh
- Latihan
- memperluas
- ekstrak
- Fitur
- File
- File
- keuangan
- Menemukan
- Pertama
- keluwesan
- berfokus
- mengikuti
- diikuti
- berikut
- Untuk
- format
- Prinsip Dasar
- kerangka
- dari
- fungsi
- Umum
- mendapatkan
- Memberikan
- Kelompok
- Pertumbuhan
- dewasa
- menangani
- Memiliki
- memiliki
- he
- header
- membantu
- membantu
- hh
- High
- lebih tinggi
- -nya
- Beranda
- Otomasi Rumah
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- gambar
- mengimplementasikan
- mengimpor
- memperbaiki
- in
- inkremental
- install
- integrasi
- tertarik
- Antarmuka
- ke
- isolasi
- IT
- bergabung
- jpg
- Menjaga
- pemeliharaan
- kunci-kunci
- danau
- danau
- lebih besar
- lintang
- Memimpin
- BELAJAR
- kurang
- Lets
- 'like'
- keterbatasan
- linux
- dasar linux
- Daftar
- memuat
- tempat
- lokasi
- mencatat
- lagi
- melihat
- mencari
- cinta
- sihir
- mengelola
- pengelolaan
- manajer
- cara
- banyak
- pasar
- max
- maksimum
- Bergabung
- Metadata
- menit
- minimum
- lebih
- beberapa
- nama
- secara asli
- Arahkan
- Perlu
- dibutuhkan
- tak pernah
- New
- tidak
- mencatat
- buku catatan
- laptop
- jumlah
- obyek
- Penyimpanan Objek
- objek
- of
- Penawaran
- sering
- Tua
- lebih tua
- on
- ONE
- hanya
- OP
- Buka
- open source
- operasi
- Operasi
- Optimize
- pilihan
- Opsi
- or
- urutan
- kami
- keluaran
- mengatasi
- sendiri
- bagian
- bergairah
- lalu
- melakukan
- prestasi
- plato
- Kecerdasan Data Plato
- Data Plato
- Populer
- Pos
- prasyarat
- sebelumnya
- sebelumnya
- primer
- Prosedur
- pengolahan
- menghasilkan
- Produk
- manajer produk
- Produk
- properties
- Ular sanca
- query
- Tarif
- Mentah
- Baca
- Bacaan
- direkomendasikan
- tercatat
- arsip
- mengurangi
- lihat
- direferensikan
- dapat diandalkan
- menghapus
- menghapus
- menghapus
- menggantikan
- wajib
- mengakibatkan
- dihasilkan
- eceran
- penyimpanan
- kuat
- Run
- berjalan
- sama
- terukur
- Skala
- Seattle
- Kedua
- Bagian
- melihat
- memilih
- memilih
- terpisah
- layanan
- Layanan
- Sidang
- set
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- penting
- Sederhana
- disederhanakan
- menyederhanakan
- sejak
- Ukuran
- sedikit berbeda
- SLP
- kecil
- lebih kecil
- pintar
- Potret
- So
- Solusi
- sumber
- Space
- percikan
- khusus
- tertentu
- Secara khusus
- ditentukan
- kecepatan
- kecepatan
- menghabiskan
- SQL
- awal
- Pernyataan
- Laporan
- stasiun
- Langkah
- Tangga
- Masih
- penyimpanan
- menyimpan
- tersimpan
- Penyelarasan
- Tali
- seperti itu
- Didukung
- sistem
- sistem
- tabel
- Tacoma
- dari
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- Ini
- ini
- ambang
- Melalui
- waktu
- perjalanan waktu
- timestamp
- untuk
- Pelacakan
- transaksional
- Transaksi
- perjalanan
- mengetik
- tiada bandingan
- Memperbarui
- diperbarui
- Pembaruan
- us
- penggunaan
- menggunakan
- bekas
- menggunakan
- Kekosongan
- nilai
- versi
- Versi
- ingin
- adalah
- cara
- we
- jaringan
- layanan web
- adalah
- ketika
- yang
- sementara
- akan
- dengan
- tanpa
- Kerja
- menulis
- tahun
- kamu
- Anda
- zephyrnet.dll