Di dunia sekarang ini, pelanggan mengelola sejumlah besar data di perangkat mereka Layanan Penyimpanan Sederhana Amazon (Amazon S3) data lake, yang memerlukan saluran data yang berbelit-belit untuk terus memahami perubahan dalam tata letak data dan membuatnya tersedia untuk sistem yang menggunakan. Lem AWS crawler menyediakan cara mudah untuk membuat katalog data di AWS Glue Data Catalog yang menghilangkan beban berat dalam hal manajemen skema dan klasifikasi data. Crawler AWS Glue mengekstrak skema data dan partisi dari Amazon S3 untuk secara otomatis mengisi Katalog Data, menjaga metadata tetap terkini.
Namun dengan pertumbuhan data secara eksponensial dari waktu ke waktu, jumlah partisi dalam tabel tertentu dapat bertambah secara signifikan. Karena layanan analitik menyukainya Amazon Athena menanyakan tabel yang berisi jutaan partisi, waktu yang diperlukan untuk mengambil partisi tersebut meningkat dan dapat menyebabkan waktu proses kueri meningkat.
Saat ini, dukungan crawler AWS Glue telah diperluas untuk secara otomatis menambahkan indeks partisi untuk tabel yang baru ditemukan guna mengoptimalkan pemrosesan kueri pada kumpulan data yang dipartisi. Sekarang, ketika crawler membuat tabel Katalog Data baru selama crawler dijalankan, crawler juga membuat indeks partisi secara default, dengan permutasi terbesar dari semua kolom partisi tipe numerik dan string sebagai kunci. Katalog Data kemudian membuat indeks yang dapat dicari berdasarkan kunci ini, sehingga mengurangi waktu yang diperlukan untuk mengambil dan memfilter metadata partisi pada tabel dengan jutaan partisi. Pembuatan indeks partisi bermanfaat bagi beban kerja analitik yang berjalan di Athena, Amazon ESDM, Spektrum Pergeseran Merah Amazon, dan AWS Glue.
Dalam postingan ini, kami menjelaskan cara membuat indeks partisi dengan crawler AWS Glue dan membandingkan peningkatan kinerja kueri saat mengakses data yang dirayapi dengan dan tanpa indeks partisi dari Athena.
Ikhtisar solusi
Kami menggunakan Formasi AWS Cloud templat untuk membuat sumber daya solusi kami. Pada langkah-langkah berikut, kami mendemonstrasikan cara mengonfigurasi crawler AWS Glue untuk membuat indeks partisi menggunakan konsol AWS Glue atau Antarmuka Baris Perintah AWS (AWS CLI). Kemudian kami membandingkan peningkatan kinerja kueri menggunakan Athena.
Prasyarat
Untuk mengikuti postingan ini, Anda harus memiliki akses ke Identitas AWS dan Manajemen Akses (IAM) peran administrator untuk membuat sumber daya menggunakan AWS CloudFormation.
Siapkan sumber daya solusi Anda
Template CloudFormation menghasilkan sumber daya berikut:
- Peran dan kebijakan IAM
- Basis data AWS Glue untuk menyimpan skema
- Crawler AWS Glue yang menunjuk ke kumpulan data yang sangat terpartisi
- Grup kerja dan keranjang Athena untuk menyimpan hasil kueri
Selesaikan langkah-langkah berikut untuk menyiapkan sumber daya solusi:
- Login ke Konsol Manajemen AWS sebagai administrator IAM.
- Pilih Luncurkan Stack untuk menerapkan template CloudFormation:

- Untuk Nama Basis Data, pertahankan default
blog_partition_index_crawlerdb.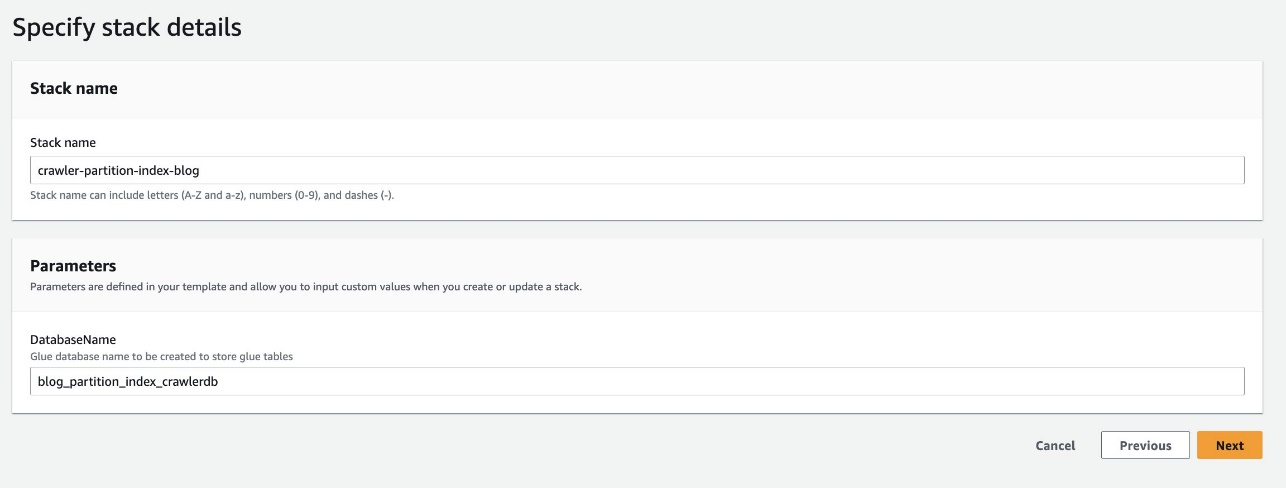
- Pilih Selanjutnya.
- Tinjau detailnya di halaman terakhir dan pilih Saya mengakui bahwa AWS CloudFormation dapat menciptakan sumber daya IAM.
- Pilih Buat tumpukan.
- Saat tumpukan selesai, di konsol AWS CloudFormation, navigasikan ke Output tab tumpukan.
- Catat nilai dari
DatabaseNamedanGlueCrawlerName.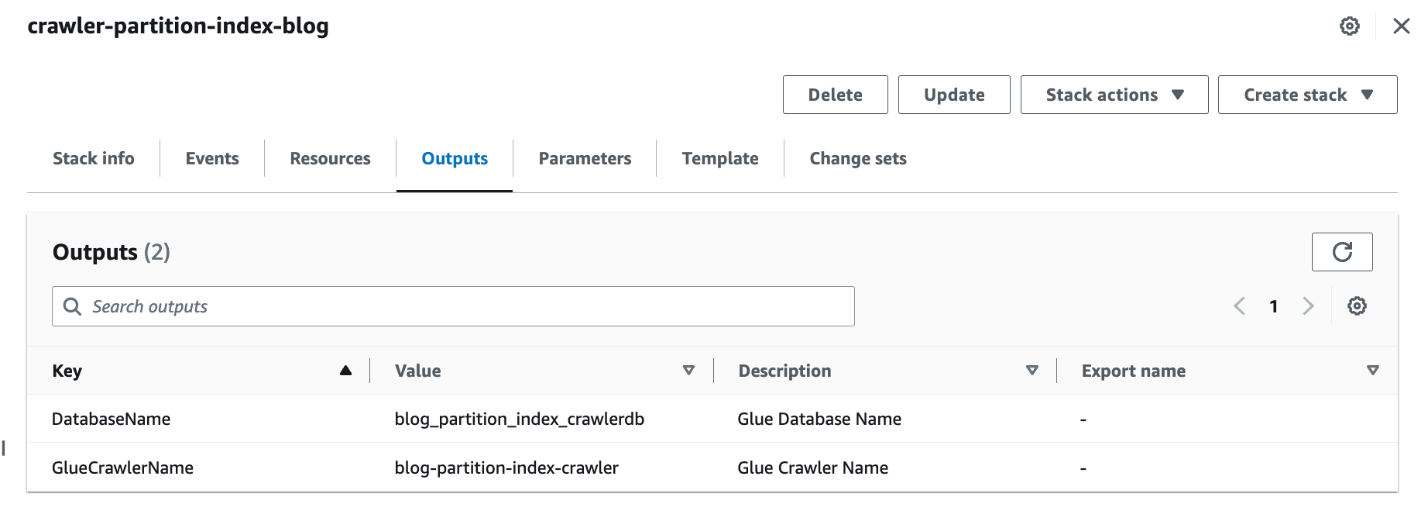
Beberapa sumber daya yang disebarkan tumpukan ini dikenakan biaya saat digunakan.
Edit dan jalankan perayap AWS Glue
Untuk mengonfigurasi dan menjalankan perayap AWS Glue, selesaikan langkah-langkah berikut:
- Di konsol AWS Glue, pilih Perayap di panel navigasi.
- cari
crawler blog-partition-index-crawlerDan pilihlah Edit.
- Dalam majalah Tetapkan keluaran dan penjadwalan bagian, di bawah Advanced options, pilih Buat indeks partisi secara otomatis.
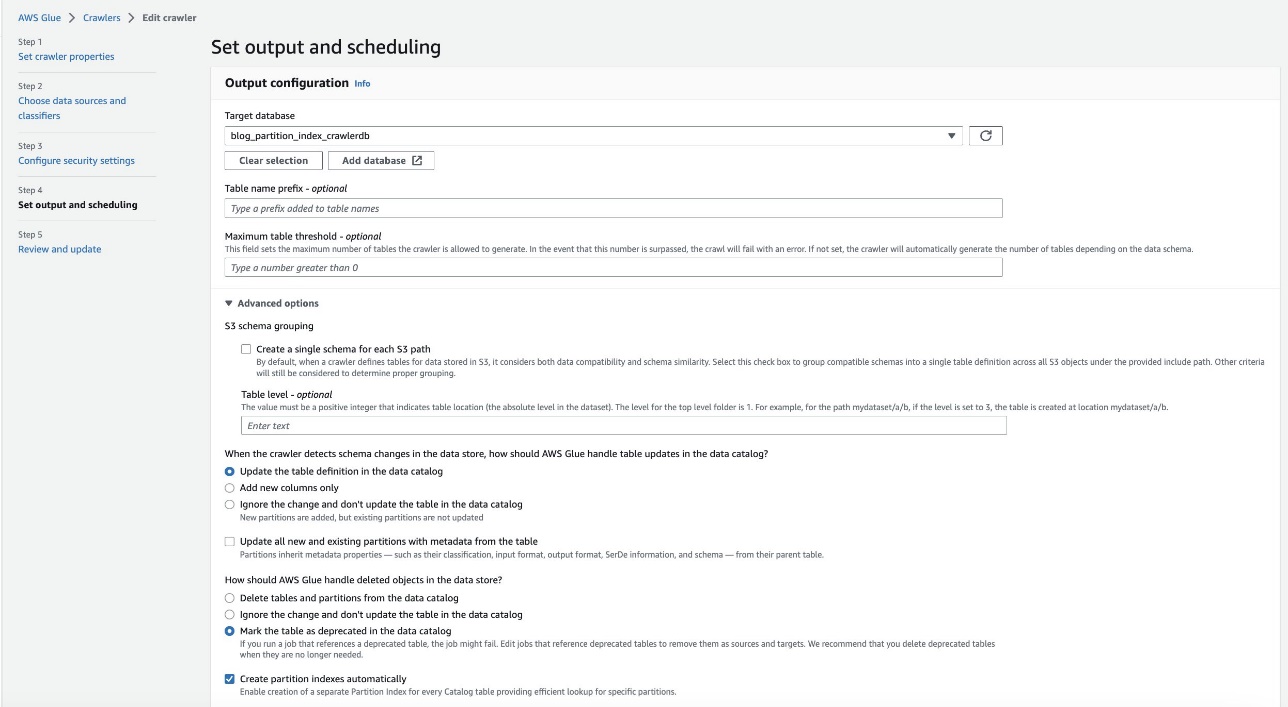
- Tinjau dan perbarui setelan perayap.
Alternatifnya, Anda dapat mengonfigurasi crawler Anda menggunakan AWS CLI (berikan IAM role dan Wilayah Anda):
- Sekarang jalankan crawler dan verifikasi bahwa proses crawler telah selesai.
Ini adalah kumpulan data yang sangat terpartisi dan memerlukan waktu sekitar 90 menit untuk menyelesaikannya.
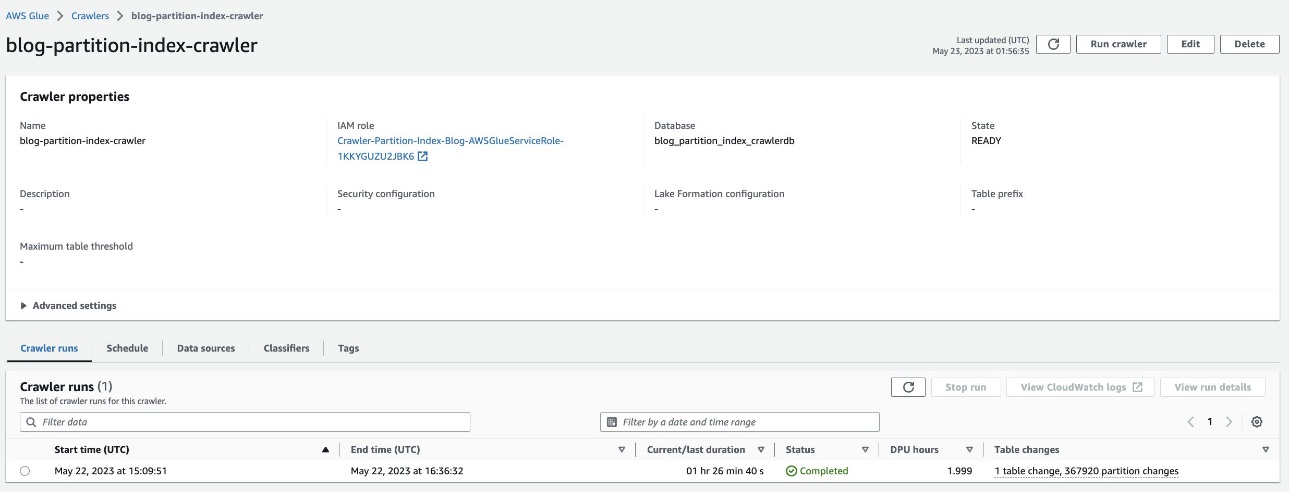
Verifikasi tabel yang dipartisi
Di basis data AWS Glue blog_partition_index_crawlerdb, verifikasi bahwa tabel tersebut highly_partitioned_table dibuat.
Secara default, crawler menentukan indeks berdasarkan permutasi terbesar kolom partisi dari tipe kolom yang valid dalam urutan kolom partisi yang sama, baik berupa numerik atau string. Untuk tabel yang dibuat oleh crawler (highly_partitioned_table), kami memiliki kolom partisi year (tali), month (tali), day (tali), dan hour (rangkaian).
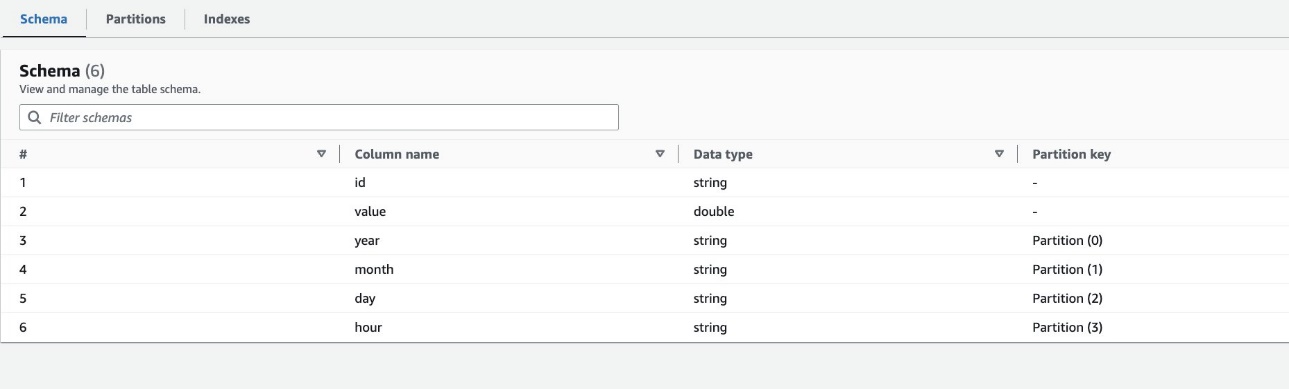
Berdasarkan definisi ini, crawler membuat indeks permutasi tahun, bulan, hari, dan jam. Perayap membuat indeks yang diawali dengan crawler_ pada indeks partisi apa pun yang dibuat secara default.
Verifikasi hal yang sama dengan menavigasi ke tabel highly_partitioned_table di konsol AWS Glue dan memilih Indeks Tab.
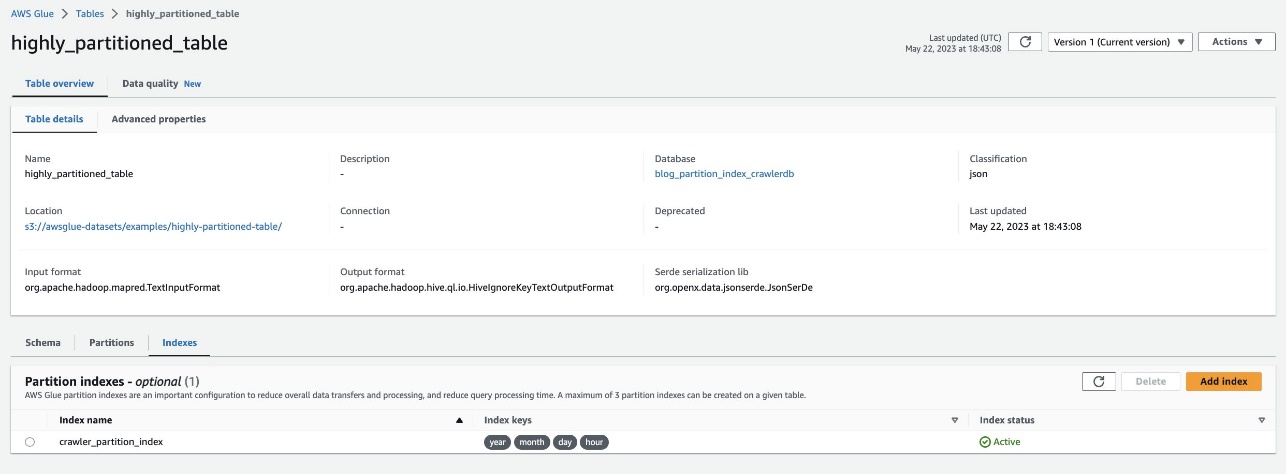
Perayap mampu merayapi sumber data S3 dan berhasil mengisi indeks partisi untuk tabel tersebut.
Bandingkan peningkatan kinerja kueri menggunakan Athena
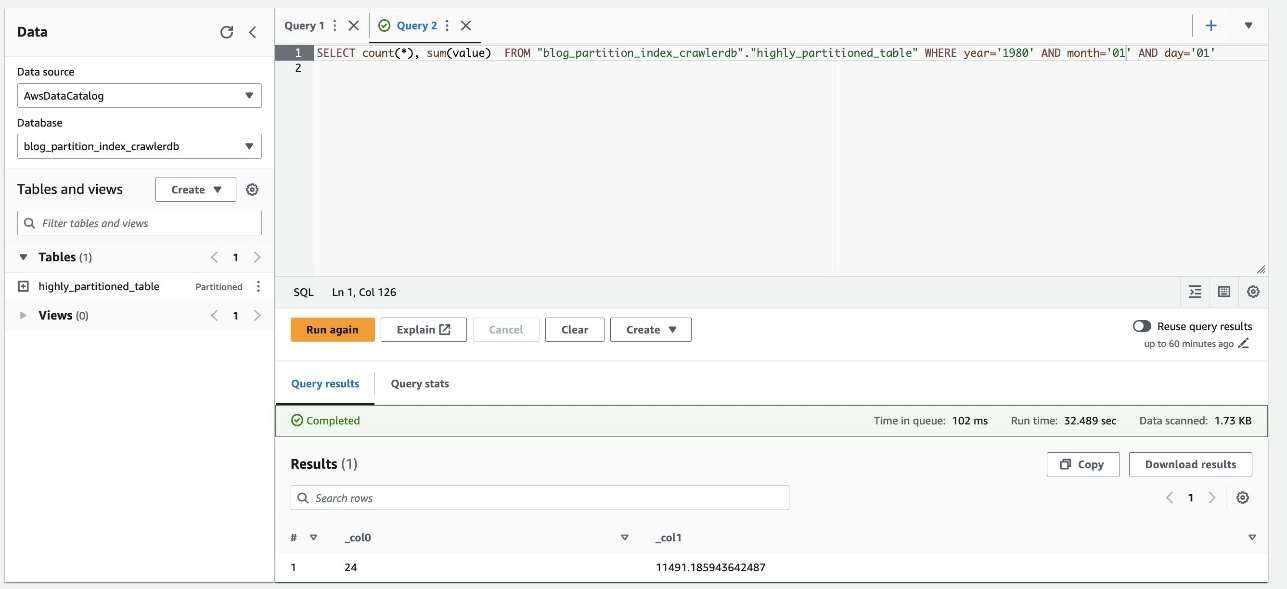
Pertama, kita menanyakan tabel di Athena tanpa menggunakan indeks partisi. Untuk memverifikasi tabel menggunakan Athena, selesaikan langkah-langkah berikut:
- Di konsol Athena, pilih
crawler-primary-workgroupsebagai kelompok kerja Athena dan pilih Mengakui.
- Jalankan kueri berikut:
Tangkapan layar berikut menunjukkan kueri memerlukan waktu sekitar 32 detik tanpa mengaktifkan pemfilteran menggunakan indeks partisi.
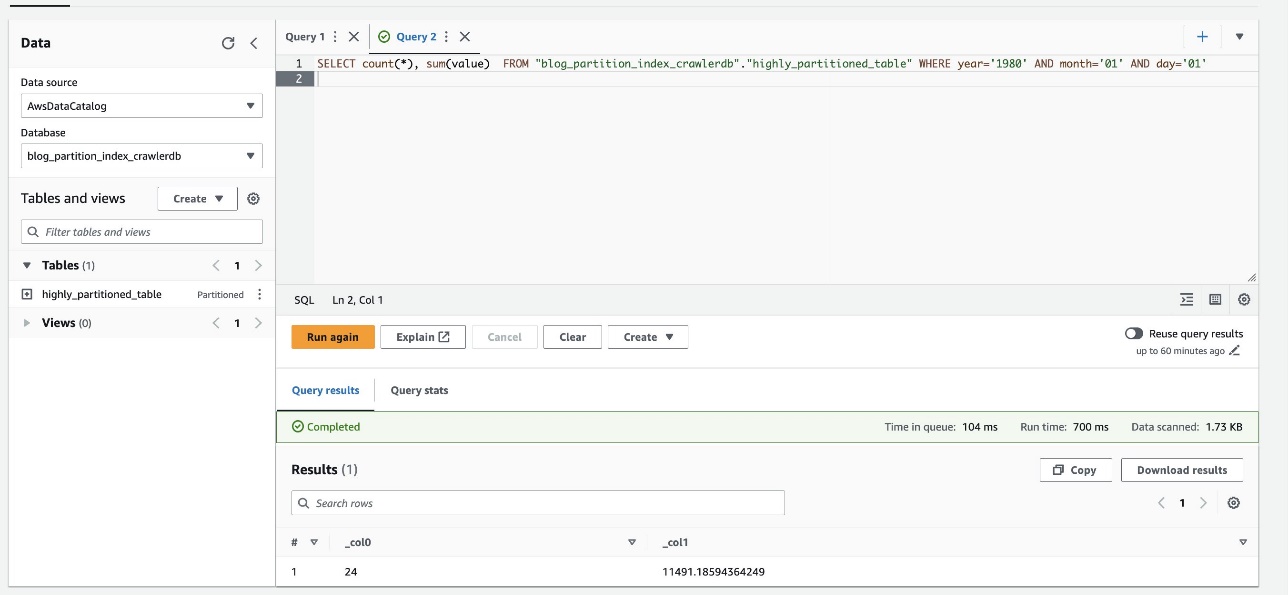
- Sekarang kami mengaktifkan indeks partisi pada kueri Athena:
- Jalankan kueri berikut lagi dan catat runtimenya:
Tangkapan layar berikut menunjukkan kueri hanya membutuhkan waktu 700 milidetik, yang jauh lebih cepat dengan pemfilteran diaktifkan menggunakan indeks partisi.
Membersihkan
Untuk menghindari tagihan yang tidak diinginkan ke akun AWS Anda, Anda dapat menghapus sumber daya AWS:
- Masuk ke konsol CloudFormation sebagai admin IAM yang digunakan untuk membuat tumpukan CloudFormation.
- Hapus tumpukan CloudFormation yang Anda buat.
Kesimpulan
Dalam postingan ini, kami menjelaskan cara mengonfigurasi crawler AWS untuk membuat indeks partisi dan membandingkan kinerja kueri saat mengakses data dengan indeks dari Athena.
Jika tidak ada indeks partisi pada tabel, AWS Glue memuat semua partisi tabel, dan kemudian memfilter partisi yang dimuat, yang mengakibatkan pengambilan metadata tidak efisien. Layanan analitik seperti Redshift Spectrum, Amazon EMR, dan AWS Glue ETL Spark DataFrames kini dapat memanfaatkan indeks untuk mengambil partisi, sehingga menghasilkan kinerja kueri yang signifikan.
Untuk informasi selengkapnya tentang indeks partisi dan kinerja kueri di berbagai mesin analitik, lihat Tingkatkan kinerja kueri Amazon Athena menggunakan indeks partisi AWS Glue Data Catalog dan Tingkatkan kinerja kueri menggunakan indeks partisi AWS Glue.
Terima kasih khusus kepada semua orang yang berkontribusi pada peluncuran fitur crawler ini: Yuhang Chen, Kyle Duong, dan Mita Gavade.
Tentang penulis
 Srividya Parthasarathy adalah Senior Big Data Architect di tim AWS Lake Formation. Dia menikmati membangun solusi data mesh dan membagikannya dengan komunitas.
Srividya Parthasarathy adalah Senior Big Data Architect di tim AWS Lake Formation. Dia menikmati membangun solusi data mesh dan membagikannya dengan komunitas.
 Sandeep Adwankar adalah Manajer Produk Teknis Senior di AWS. Berbasis di California Bay Area, dia bekerja dengan pelanggan di seluruh dunia untuk menerjemahkan persyaratan bisnis dan teknis menjadi produk yang memungkinkan pelanggan meningkatkan cara mereka mengelola, mengamankan, dan mengakses data.
Sandeep Adwankar adalah Manajer Produk Teknis Senior di AWS. Berbasis di California Bay Area, dia bekerja dengan pelanggan di seluruh dunia untuk menerjemahkan persyaratan bisnis dan teknis menjadi produk yang memungkinkan pelanggan meningkatkan cara mereka mengelola, mengamankan, dan mengakses data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Keuangan EVM. Antarmuka Terpadu untuk Keuangan Terdesentralisasi. Akses Di Sini.
- Grup Media Kuantum. IR/PR Diperkuat. Akses Di Sini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :memiliki
- :adalah
- :Di mana
- $NAIK
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- Sanggup
- mengakses
- mengakses
- Akun
- mengakui
- di seluruh
- menambahkan
- admin
- lagi
- Semua
- sepanjang
- juga
- Amazon
- Amazon Athena
- Amazon ESDM
- Amazon Web Services
- jumlah
- an
- Analytical
- analisis
- dan
- Apa pun
- sekitar
- ADALAH
- DAERAH
- sekitar
- AS
- At
- secara otomatis
- tersedia
- menghindari
- AWS
- Formasi AWS Cloud
- Lem AWS
- Formasi Danau AWS
- berdasarkan
- Teluk
- karena
- menjadi
- Manfaat
- Besar
- Big data
- Bangunan
- bisnis
- by
- california
- CAN
- katalog
- Menyebabkan
- Perubahan
- beban
- chen
- Pilih
- memilih
- klasifikasi
- Kolom
- Kolom
- datang
- masyarakat
- membandingkan
- dibandingkan
- lengkap
- konsul
- terus menerus
- berkontribusi
- Biaya
- crawler
- membuat
- dibuat
- menciptakan
- membuat
- penciptaan
- terbaru
- pelanggan
- data
- akses data
- Danau Data
- Basis Data
- hari
- Default
- mendemonstrasikan
- menyebarkan
- menyebarkan
- menggambarkan
- rincian
- ditentukan
- ditemukan
- turun
- selama
- efisien
- antara
- aktif
- diaktifkan
- Mesin
- Eter (ETH)
- semua orang
- diperluas
- menjelaskan
- eksponensial
- ekstrak
- ekstrak datanya
- lebih cepat
- Fitur
- menyaring
- penyaringan
- filter
- terakhir
- mengikuti
- berikut
- Untuk
- pembentukan
- dari
- menghasilkan
- diberikan
- bumi
- Tumbuh
- Pertumbuhan
- Memiliki
- he
- berat
- angkat berat
- sangat
- memegang
- jam
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- IAM
- identitas
- memperbaiki
- perbaikan
- perbaikan
- in
- Meningkatkan
- Meningkatkan
- indeks
- indeks
- tidak efisien
- informasi
- ke
- IT
- jpg
- Menjaga
- pemeliharaan
- kunci-kunci
- danau
- terbesar
- jalankan
- tata ruang
- pengangkatan
- 'like'
- baris
- beban
- membuat
- mengelola
- pengelolaan
- manajer
- jala
- Metadata
- mungkin
- jutaan
- menit
- Bulan
- lebih
- banyak
- harus
- Arahkan
- menavigasi
- Navigasi
- dibutuhkan
- New
- baru saja
- tidak
- sekarang
- jumlah
- of
- on
- hanya
- Optimize
- or
- urutan
- kami
- keluaran
- lebih
- halaman
- pane
- path
- prestasi
- plato
- Kecerdasan Data Plato
- Data Plato
- Pos
- menyajikan
- pengolahan
- Produk
- manajer produk
- Produk
- memberikan
- mengurangi
- wilayah
- wajib
- Persyaratan
- membutuhkan
- Sumber
- dihasilkan
- Hasil
- Peran
- peran
- Run
- berjalan
- sama
- detik
- Bagian
- aman
- senior
- Layanan
- set
- pengaturan
- berbagi
- dia
- Pertunjukkan
- penting
- signifikan
- Sederhana
- larutan
- Solusi
- sumber
- percikan
- Spektrum
- tumpukan
- Tangga
- penyimpanan
- menyimpan
- mudah
- Tali
- berhasil
- mendukung
- sistem
- tabel
- Mengambil
- tim
- Teknis
- Template
- Terima kasih
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- Ini
- mereka
- ini
- waktu
- untuk
- hari ini
- mengambil
- menterjemahkan
- benar
- mengetik
- jenis
- bawah
- memahami
- tidak diinginkan
- Memperbarui
- menggunakan
- bekas
- menggunakan
- Penggunaan
- nilai
- Nilai - Nilai
- berbagai
- Luas
- memeriksa
- versi
- adalah
- Cara..
- we
- jaringan
- layanan web
- ketika
- yang
- SIAPA
- akan
- dengan
- tanpa
- Kelompok Kerja
- bekerja
- dunia
- yaml
- tahun
- kamu
- Anda
- zephyrnet.dll