Gambar oleh Penulis
Tepat ketika kami merasa telah mencerna cukup banyak berita tentang Model Bahasa Besar (LLM), tim Microsoft Research Asia membawakan kami Visual ChatGPT. Visual ChatGPT mengatasi keterbatasan ChatGPT saat ini karena tidak dapat memproses informasi visual karena dilatih dengan modalitas satu bahasa.
Visual ChatGPT adalah sistem yang menggabungkan Visual Foundation Models (VFM) untuk membantu ChatGPT lebih memahami, menghasilkan, dan mengedit informasi visual. VFM memiliki kemampuan untuk menentukan format input-output, mengubah informasi visual ke format bahasa, dan menangani riwayat, prioritas, dan konflik VFM.
Oleh karena itu, Visual ChatGPT adalah model AI yang menjembatani keterbatasan ChatGPT dan memungkinkan pengguna untuk berkomunikasi melalui obrolan dan menghasilkan visual.
Keterbatasan ChatGPT
ChatGPT telah menjadi percakapan mayoritas orang dalam beberapa minggu dan bulan terakhir. Namun, karena kemampuan pelatihan linguistiknya, tidak memungkinkan pemrosesan dan pembuatan gambar.
Sedangkan Anda memiliki model fondasi visual seperti Visual Transformers dan Steady Diffusion yang memiliki kemampuan visual yang luar biasa. Di sinilah kombinasi model bahasa dan gambar telah menciptakan Visual ChatGPT.
Apa itu Model Fondasi Visual?
Model Yayasan Visual digunakan untuk mengelompokkan algoritma dasar yang digunakan dalam visi komputer. Mereka mengambil keterampilan visi komputer standar dan mentransfernya ke aplikasi AI untuk menangani tugas yang lebih kompleks.
Prompt Manager di Visual ChatGPT terdiri dari 22 VFM, yang meliputi Text-to-Image, ControlNet, Edge-To-Image, dan banyak lagi. Ini membantu ChatGPT untuk mengonversi semua sinyal visual dari suatu gambar ke dalam bahasa agar ChatGPT dapat memahami dengan lebih baik. Jadi bagaimana cara kerja Visual ChatGPT?
Visual ChatGPT terdiri dari berbagai komponen untuk membantu ChatGPT Model Bahasa Besar memahami visual.
Komponen Arsitektur Visual ChatGPT
- Permintaan Pengguna: Di sinilah pengguna akan mengirimkan kueri mereka
- Manajer Cepat: Ini mengonversi kueri visual pengguna ke dalam format bahasa, sehingga model ChatGPT dapat memahaminya.
- Model Fondasi Visual: Ini menggabungkan berbagai VFM, seperti BLIP (Bootstrapping Language-Image Pre-training), Stable Diffusion, ControlNet, Pix2Pix, dan banyak lagi.
- Sistem Prinsip: Ini memberikan aturan dan persyaratan dasar untuk Visual ChatGPT.
- Sejarah Dialog: Ini adalah titik interaksi dan percakapan pertama yang dimiliki sistem dengan pengguna.
- Sejarah Penalaran: Ini menggunakan alasan sebelumnya yang dimiliki VFM berbeda di masa lalu untuk menyelesaikan kueri kompleks.
- Jawaban Antara: Dengan penggunaan VFM, model akan mencoba mengeluarkan beberapa jawaban antara yang memiliki pernyataan logis.
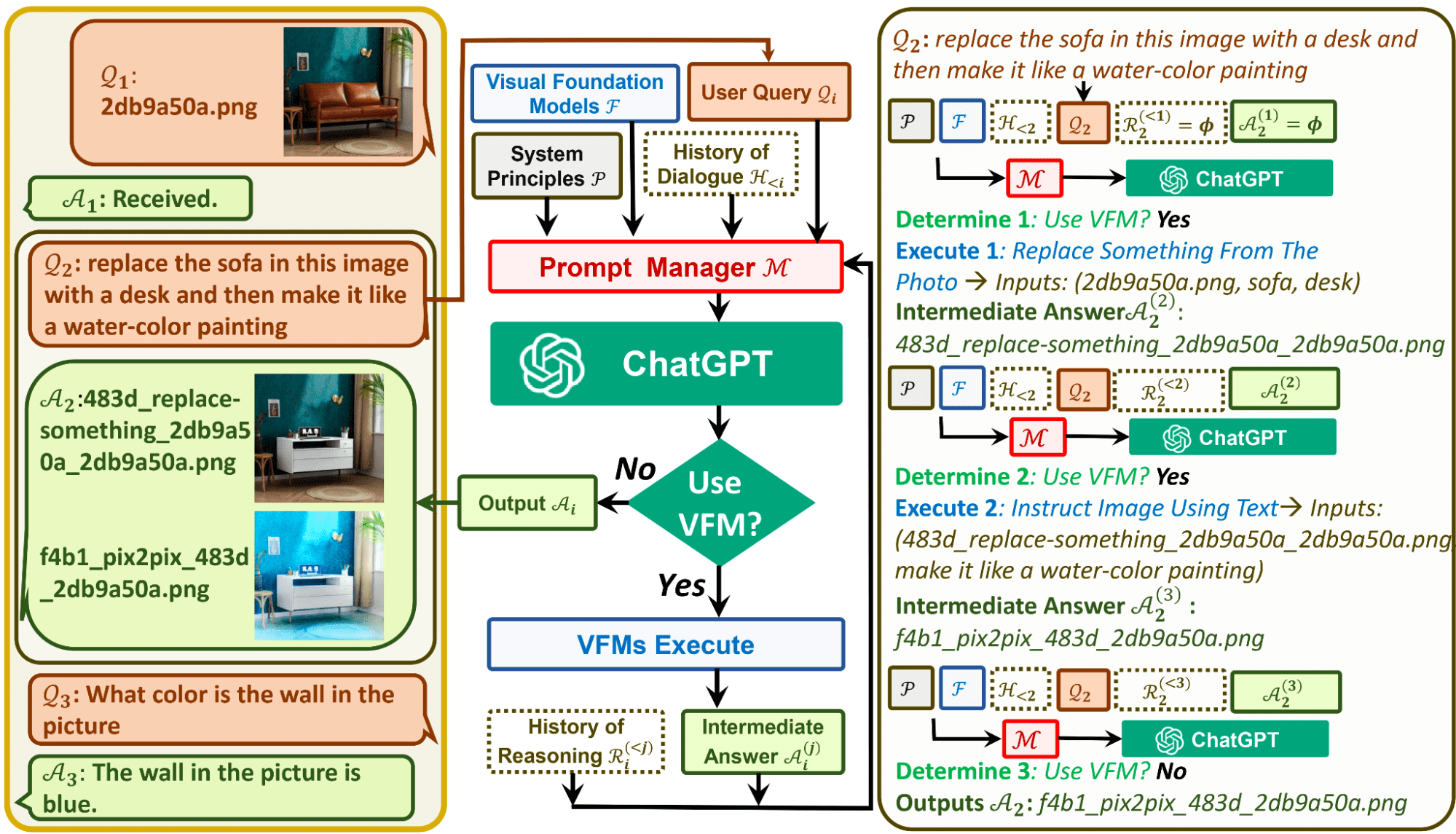
Image by Microsoft GitHub
Lebih Lanjut Tentang Manajer Prompt
Beberapa dari Anda mungkin berpikir bahwa ini adalah solusi paksa untuk ChatGPT untuk menangani visual, karena masih mengubah semua sinyal visual dari suatu gambar menjadi bahasa. Saat mengunggah gambar, Prompt Manager menyintesis riwayat obrolan internal yang menyertakan informasi seperti nama file sehingga ChatGPT dapat lebih memahami apa yang dimaksud dengan kueri.
Misalnya, nama gambar yang dimasukkan oleh pengguna akan bertindak sebagai riwayat operasi dan manajer prompt akan membantu model melalui 'Format Penalaran' untuk mencari tahu apa yang perlu dilakukan dengan gambar tersebut. Anda dapat mempertimbangkan ini sebagai pemikiran batin model sebelum ChatGPT memilih operasi VFM yang benar.
Pada gambar di bawah, Anda dapat melihat bagaimana Prompt Manager memulai aturan untuk Visual ChatGPT:
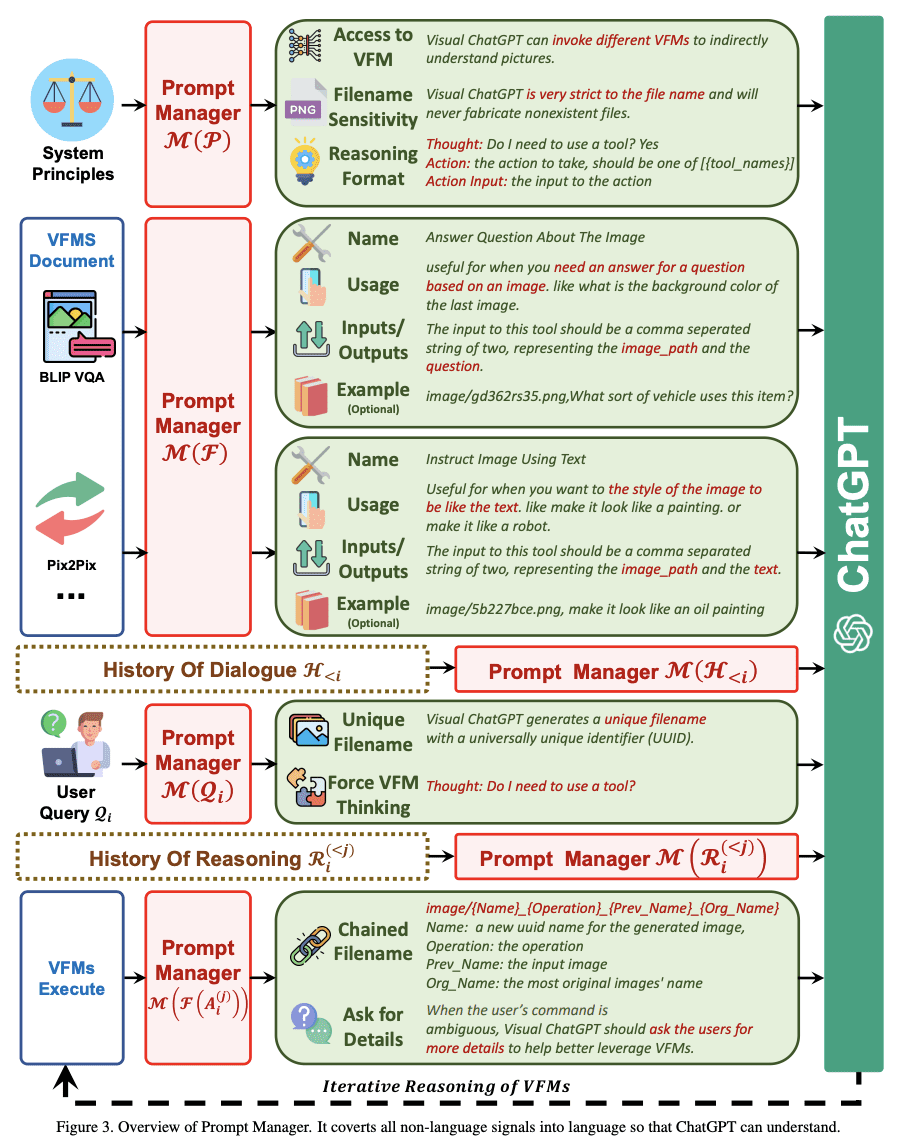
Image by Visual ChatGPT: Berbicara, Menggambar, dan Mengedit dengan Model Visual Foundation
Untuk memulai perjalanan Visual ChatGPT Anda, Anda harus menjalankan demo Visual ChatGPT terlebih dahulu:
# create a new environment
conda create -n visgpt python=3.8 # activate the new environment
conda activate visgpt # prepare the basic environments
pip install -r requirement.txt # download the visual foundation models
bash download.sh # prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key} # create a folder to save images
mkdir ./image # Start Visual ChatGPT !
python visual_chatgpt.py
Anda juga dapat mempelajari lebih lanjut tentang GitHub Obrolan Visual Microsoft. Pastikan Anda melihat penggunaan memori GPU mereka pada masing-masing Model Visual Foundation.
Jadi apa yang bisa dilakukan Visual ChatGPT?
Pembuatan Gambar
Anda dapat meminta Visual ChatGPT untuk membuat gambar dari awal, memberikan deskripsi. Gambar Anda akan dihasilkan dalam hitungan detik, tergantung pada daya komputasi yang tersedia. Pembuatan Gambar Sintetiknya menggunakan data teks berdasarkan Difusi Stabil.
Mengubah Gambar Latar Belakang
Sekali lagi, menggunakan difusi stabil, Visual ChatGPT dapat mengubah latar belakang gambar yang Anda masukkan. Pengguna dapat memberikan asisten dengan deskripsi apa pun tentang perubahan latar belakang yang mereka inginkan, dan model difusi yang stabil akan mewarnai latar belakang gambar.
Mengubah Warna Gambar dan Efek lainnya
Anda juga akan dapat mengubah warna gambar Anda dan menerapkan efek, berdasarkan penyediaan aplikasi dengan deskripsi. Visual ChatGPT akan menggunakan berbagai model yang telah dilatih sebelumnya dan OpenCV, untuk mengubah warna gambar, menyorot tepi gambar, dan lainnya.
Buat Perubahan pada Gambar
Visual ChatGPT memungkinkan Anda untuk menghapus atau mengganti aspek gambar Anda dengan mengedit dan memodifikasi objek dalam gambar dengan deskripsi teks yang diarahkan ke aplikasi. Namun, perlu dicatat bahwa fitur ini membutuhkan lebih banyak daya komputasi.
Seperti yang kita ketahui, akan selalu ada beberapa bentuk ketidaksempurnaan yang perlu diperbaiki oleh organisasi untuk meningkatkan layanan mereka.
Kombinasi Computer Vision dan Model Bahasa Besar
Visual ChatGPT sangat bergantung pada ChatGPT dan VFM, oleh karena itu, keakuratan dan keandalan aspek individual ini memengaruhi kinerja Visual ChatGPT. Kombinasi penggunaan Model Bahasa Besar dan Visi Komputer memerlukan sejumlah besar rekayasa cepat, dan bisa jadi sulit untuk mencapai kinerja mahir.
Keamanan dan Privasi
Visual ChatGPT memiliki kemampuan untuk memasang dan mencabut VFM dengan mudah, yang mungkin menjadi perhatian sebagian pengguna tentang masalah keamanan dan privasi. Microsoft perlu melihat lebih jauh bagaimana data sensitif tidak disusupi.
Modul Koreksi Diri
Salah satu batasan yang ditemukan oleh para peneliti Visual ChatGPT adalah hasil yang dihasilkan tidak konsisten karena kegagalan VFM dan keragaman petunjuknya. Oleh karena itu, mereka menyimpulkan bahwa mereka perlu mengerjakan modul koreksi diri yang akan memastikan bahwa output yang dihasilkan sejalan dengan apa yang diminta pengguna, dan dapat melakukan koreksi yang diperlukan.
Diperlukan Jumlah GPU yang Tinggi
Untuk memanfaatkan Visual ChatGPT dan memanfaatkan 22 VFM, Anda memerlukan RAM GPU dalam jumlah besar, misalnya A100. Bergantung pada tugas yang dihadapi, pastikan Anda memahami berapa banyak GPU yang diperlukan untuk menyelesaikan tugas secara efektif.
Visual ChatGPT masih memiliki keterbatasan, namun ini merupakan terobosan besar dalam penggunaan Model Bahasa Besar dan Visi Komputer secara bersamaan. Jika Anda ingin mempelajari lebih lanjut tentang Visual ChatGPT, baca makalah ini: Visual ChatGPT: Berbicara, Menggambar, dan Mengedit dengan Model Visual Foundation
Apakah Visual ChatGPT mirip dengan ChatGPT4? Jika Anda sudah mencoba keduanya, bagaimana pendapat Anda? Berikan komentar di bawah ini!
Nisa Arya adalah Ilmuwan Data, Penulis Teknis Lepas, dan Manajer Komunitas di KDnuggets. Dia sangat tertarik untuk memberikan nasihat atau tutorial karir Ilmu Data dan pengetahuan berbasis teori seputar Ilmu Data. Dia juga ingin menjelajahi berbagai cara Kecerdasan Buatan bermanfaat bagi umur panjang kehidupan manusia. Seorang pembelajar yang tajam, berusaha memperluas pengetahuan teknologi dan keterampilan menulisnya, sambil membantu membimbing orang lain.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/03/visual-chatgpt-microsoft-combine-chatgpt-vfms.html?utm_source=rss&utm_medium=rss&utm_campaign=visual-chatgpt-microsoft-combine-chatgpt-and-vfms
- :adalah
- $NAIK
- 10
- 8
- a
- A100
- kemampuan
- Sanggup
- Tentang Kami
- ketepatan
- Mencapai
- di seluruh
- Bertindak
- tindakan
- nasihat
- AI
- algoritma
- Semua
- Membiarkan
- memungkinkan
- selalu
- menakjubkan
- jumlah
- dan
- jawaban
- Aplikasi
- aplikasi
- Mendaftar
- ADALAH
- sekitar
- buatan
- kecerdasan buatan
- AS
- Asia
- aspek
- membantu
- Asisten
- At
- tersedia
- latar belakang
- berdasarkan
- menampar
- dasar
- BE
- sebelum
- makhluk
- di bawah
- manfaat
- Lebih baik
- antara
- terobosan
- JEMBATAN
- memperluas
- Terbawa
- by
- CAN
- kemampuan
- Lowongan Kerja
- perubahan
- Perubahan
- ChatGPT
- warna
- kombinasi
- menggabungkan
- menggabungkan
- komentar
- menyampaikan
- masyarakat
- lengkap
- kompleks
- komponen
- memahami
- Dikompromikan
- komputer
- Visi Komputer
- komputasi
- daya komputasi
- Perhatian
- Kekhawatiran
- Disimpulkan
- Mempertimbangkan
- Percakapan
- mengubah
- Koreksi
- membuat
- dibuat
- terbaru
- data
- ilmu data
- ilmuwan data
- transaksi
- Demo
- Tergantung
- deskripsi
- berbeda
- sulit
- Difusi
- Keragaman
- Download
- gambar
- Menjatuhkan
- setiap
- mudah
- mengedit
- efektif
- efek
- Teknik
- cukup
- memastikan
- Lingkungan Hidup
- lingkungan
- contoh
- menyelidiki
- ekspor
- Kegagalan
- Fitur
- beberapa
- Angka
- File
- Pertama
- Untuk
- bentuk
- format
- Prinsip Dasar
- lepas
- dari
- mendasar
- menghasilkan
- dihasilkan
- menghasilkan
- generasi
- GitHub
- Go
- baik
- GPU
- Kelompok
- membimbing
- tangan
- menangani
- Memiliki
- berat
- membantu
- membantu
- membantu
- High
- Menyoroti
- sejarah
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTTPS
- manusia
- gambar
- generasi gambar
- gambar
- memperbaiki
- in
- termasuk
- menggabungkan
- sendiri-sendiri
- mempengaruhi
- informasi
- Inisiat
- install
- Intelijen
- interaksi
- tertarik
- Menengah
- intern
- IT
- NYA
- perjalanan
- KDnugget
- Tajam
- kunci
- Tahu
- pengetahuan
- bahasa
- besar
- BELAJAR
- pelajar
- Hidup
- 'like'
- keterbatasan
- baris
- logis
- umur panjang
- melihat
- terbuat
- utama
- Mayoritas
- membuat
- manajer
- Memori
- Microsoft
- Microsoft Research
- model
- model
- modul
- bulan
- lebih
- nama
- perlu
- Perlu
- kebutuhan
- New
- berita
- objek
- of
- on
- OpenAI
- operasi
- Pendapat
- urutan
- organisasi
- Lainnya
- Lainnya
- keluaran
- kertas
- khususnya
- lalu
- prestasi
- plato
- Kecerdasan Data Plato
- Data Plato
- steker
- Titik
- kekuasaan
- Mempersiapkan
- sebelumnya
- pribadi
- swasta
- Key pribadi
- proses
- pengolahan
- memberikan
- menyediakan
- menyediakan
- Ular sanca
- RAM
- Baca
- keandalan
- menghapus
- menggantikan
- diminta
- wajib
- kebutuhan
- Persyaratan
- membutuhkan
- penelitian
- peneliti
- aturan
- Run
- s
- Save
- Ilmu
- ilmuwan
- detik
- keamanan
- pencarian
- peka
- Layanan
- beberapa
- sinyal
- mirip
- serentak
- tunggal
- keterampilan
- So
- MEMECAHKAN
- beberapa
- stabil
- standar
- awal
- mantap
- Masih
- menyerahkan
- seperti itu
- sintetis
- sistem
- Mengambil
- pembicaraan
- tugas
- tugas
- tim
- tech
- Teknis
- bahwa
- Grafik
- mereka
- Mereka
- karena itu
- Ini
- Pikir
- pikir
- Melalui
- untuk
- terlatih
- Pelatihan
- transfer
- transformer
- tutorial
- memahami
- Mengunggah
- us
- penggunaan
- menggunakan
- Pengguna
- Pengguna
- variasi
- melalui
- penglihatan
- cara
- minggu
- Apa
- yang
- Sementara
- akan
- keinginan
- dengan
- dalam
- Kerja
- akan
- penulis
- penulisan
- Anda
- zephyrnet.dll