Di pos Memperkenalkan alat TCO AWS ProServe Hadoop Migration Delivery Kit, kami memperkenalkan alat TCO AWS ProServe Hadoop Migration Delivery Kit (HMDK) dan manfaat migrasi beban kerja Hadoop lokal ke Amazon ESDM. Dalam postingan ini, kami mendalami alat ini, menelusuri semua langkah mulai dari penyerapan log, transformasi, visualisasi, dan desain arsitektur untuk menghitung TCO.
Ikhtisar solusi
Mari kita kunjungi fitur utama alat HMDK TCO secara singkat. Alat ini menyediakan pengumpul log BENANG untuk menghubungkan Manajer Sumber Daya Hadoop untuk mengumpulkan log BENANG. Penganalisis beban kerja Hadoop berbasis Python, yang disebut penganalisa log YARN, meneliti aplikasi Hadoop. Amazon QuickSight dasbor menampilkan hasil dari penganalisis. Hasil yang sama juga mempercepat desain instans EMR di masa mendatang. Selain itu, kalkulator TCO menghasilkan estimasi TCO dari kluster EMR yang dioptimalkan untuk memfasilitasi migrasi.
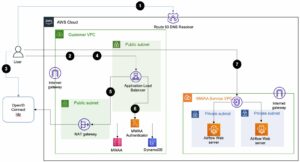
Sekarang mari kita lihat cara kerja alat ini. Diagram berikut mengilustrasikan alur kerja end-to-end.

Di bagian selanjutnya, kita membahas lima langkah utama alat ini:
- Kumpulkan log riwayat pekerjaan YARN.
- Ubah log riwayat pekerjaan dari JSON ke CSV.
- Menganalisis log riwayat pekerjaan.
- Rancang cluster EMR untuk migrasi.
- Hitung TCO-nya.
Prasyarat
Sebelum memulai, pastikan untuk melengkapi prasyarat berikut:
- Clone file repositori hadoop-migration-assessment-tco.
- Instal Python 3 di mesin lokal Anda.
- Miliki akun AWS dengan izin aktif AWS Lambda, QuickSight (edisi Perusahaan), dan Formasi AWS Cloud.
Kumpulkan log riwayat pekerjaan YARN
Pertama, Anda menjalankan a Pengumpul log BENANG, start-collector.sh, di mesin lokal Anda. Langkah ini mengumpulkan log Hadoop YARN dan menempatkan log di mesin lokal Anda. Skrip menghubungkan mesin lokal Anda dengan node utama Hadoop dan berkomunikasi dengan Resource Manager. Kemudian ia mengambil informasi riwayat pekerjaan (log BENANG dari manajer aplikasi) dengan memanggil API aplikasi YARN ResourceManager.
Sebelum menjalankan pengumpul log YARN, Anda perlu mengonfigurasi dan membuat koneksi (HTTP: 8088 atau HTTPS: 8090; yang terakhir disarankan) untuk memverifikasi aksesibilitas YARN ResourceManager dan mengaktifkan YARN Timeline Server (Timeline Server v1 atau yang lebih baru didukung ). Anda mungkin perlu menentukan interval pengumpulan dan kebijakan penyimpanan log YARN. Untuk memastikan bahwa Anda mengumpulkan log YARN berturut-turut, Anda dapat menggunakan tugas cron untuk menjadwalkan pengumpul log dalam interval waktu yang tepat. Misalnya, untuk klaster Hadoop dengan 2,000 aplikasi harian dan pengaturan yarn.resourcemanager.max-completed-applications diatur ke 1,000, secara teoritis, Anda harus menjalankan pengumpul log setidaknya dua kali untuk mendapatkan semua log YARN. Selain itu, kami merekomendasikan untuk mengumpulkan setidaknya 7 hari log YARN untuk menganalisis beban kerja holistik.
Untuk detail selengkapnya tentang cara mengonfigurasi dan menjadwalkan pengumpul log, lihat repo GitHub pengumpul benang-log.
Ubah log riwayat pekerjaan YARN dari JSON ke CSV
Setelah mendapatkan log YARN, Anda menjalankan pengelola log YARN, yarn-log-organizer.py, yang merupakan parser untuk mengubah log berbasis JSON menjadi file CSV. File CSV output ini adalah input untuk penganalisa log YARN. Parser juga memiliki kemampuan lain, termasuk mengurutkan peristiwa berdasarkan waktu, menghapus dedikasi, dan menggabungkan beberapa log.
Untuk informasi selengkapnya tentang cara menggunakan pengatur log YARN, lihat repo GitHub yarn-log-organizer.
Menganalisis log riwayat pekerjaan YARN
Selanjutnya, Anda meluncurkan penganalisis log BENANG untuk menganalisis log BENANG dalam format CSV.
Dengan QuickSight, Anda dapat memvisualisasikan data log YARN dan melakukan analisis terhadap kumpulan data yang dihasilkan oleh templat dan widget dasbor bawaan. Widget secara otomatis membuat dasbor QuickSight di akun AWS target, yang dikonfigurasi dalam template CloudFormation.
Diagram berikut mengilustrasikan arsitektur HMDK TCO.

Penganalisis log YARN menyediakan empat fungsi utama:
- Unggah log riwayat pekerjaan YARN yang diubah dalam format CSV (misalnya,
cluster_yarn_logs_*.csv) ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) ember. File CSV ini adalah keluaran dari pengelola log YARN. - Buat file JSON manifes (misalnya,
yarn-log-manifest.json) untuk QuickSight dan unggah ke bucket S3: - Terapkan dasbor QuickSight menggunakan template CloudFormation, yang dalam format YAML. Setelah menerapkan, pilih ikon segarkan hingga Anda melihat status tumpukan sebagai
CREATE_COMPLETE. Langkah ini membuat kumpulan data di dasbor QuickSight di akun target AWS Anda.
- Di dasbor QuickSight, Anda dapat menemukan wawasan tentang beban kerja Hadoop yang dianalisis dari berbagai bagan. Wawasan ini membantu Anda merancang instans EMR mendatang untuk percepatan migrasi, seperti yang ditunjukkan pada langkah berikutnya.

Rancang cluster EMR untuk migrasi
Hasil penganalisa log YARN membantu Anda memahami beban kerja Hadoop aktual pada sistem yang ada. Langkah ini mempercepat perancangan instans EMR mendatang untuk migrasi dengan menggunakan Templat Excel. Templat berisi daftar periksa untuk melakukan analisis beban kerja dan perencanaan kapasitas:
- Apakah aplikasi yang berjalan di cluster digunakan secara tepat dengan kapasitasnya saat ini?
- Apakah cluster sedang dimuat pada waktu tertentu atau tidak? Jika ya, kapan waktunya?
- Jenis aplikasi dan mesin apa (seperti MR, TEZ, atau Spark) yang berjalan di cluster, dan apa penggunaan sumber daya untuk setiap jenis?
- Apakah siklus pekerjaan yang berbeda (real-time, batch, ad hoc) berjalan dalam satu kluster?
- Apakah ada pekerjaan yang berjalan dalam batch reguler, dan jika ya, berapa interval jadwalnya? (Misalnya, setiap 10 menit, 1 jam, 1 hari.) Apakah Anda memiliki pekerjaan yang menggunakan banyak sumber daya dalam jangka waktu lama?
- Apakah ada pekerjaan yang memerlukan peningkatan kinerja?
- Apakah ada organisasi atau individu tertentu yang memonopoli klaster?
- Apakah ada pekerjaan pengembangan dan operasi campuran yang beroperasi dalam satu kluster?
Setelah Anda menyelesaikan daftar periksa, Anda akan memiliki pemahaman yang lebih baik tentang cara mendesain arsitektur masa depan. Untuk mengoptimalkan efektivitas biaya klaster ESDM, tabel berikut memberikan panduan umum untuk memilih tipe klaster ESDM yang tepat dan Cloud komputasi elastis Amazon (Amazon EC2) keluarga.

Untuk memilih jenis klaster dan keluarga instans yang tepat, Anda perlu melakukan beberapa putaran analisis terhadap log YARN berdasarkan berbagai kriteria. Mari kita lihat beberapa metrik utama.
Perusahaan
Anda dapat menemukan pola beban kerja berdasarkan jumlah aplikasi Hadoop yang dijalankan dalam jendela waktu. Misalnya, bagan harian atau per jam "Jumlah Catatan berdasarkan Waktu Mulai" memberikan wawasan berikut:
- Di bagan deret waktu harian, Anda membandingkan jumlah aplikasi yang dijalankan antara hari kerja dan hari libur, dan di antara hari kalender. Jika angkanya sama, berarti pemanfaatan harian cluster tersebut sebanding. Sebaliknya, jika deviasinya besar, proporsi pekerjaan ad hoc juga signifikan. Anda juga dapat mengetahui kemungkinan pekerjaan mingguan atau bulanan pada hari-hari tertentu. Dalam situasi tersebut, Anda dapat dengan mudah melihat hari-hari tertentu dalam seminggu atau sebulan dengan konsentrasi beban kerja yang tinggi.
- Dalam bagan deret waktu per jam, Anda lebih memahami bagaimana aplikasi dijalankan di jendela per jam. Anda dapat menemukan jam sibuk dan tidak sibuk dalam sehari.
pengguna
Log YARN berisi ID pengguna dari setiap aplikasi. Informasi ini membantu Anda memahami siapa yang mengajukan permohonan ke antrean. Berdasarkan statistik aplikasi individual dan gabungan yang berjalan per antrean dan per pengguna, Anda dapat menentukan distribusi beban kerja yang ada menurut pengguna. Biasanya, pengguna di tim yang sama telah berbagi antrean. Terkadang, beberapa tim telah berbagi antrean. Saat mendesain antrean untuk pengguna, kini Anda memiliki wawasan untuk membantu Anda mendesain dan mendistribusikan beban kerja aplikasi yang lebih seimbang di seluruh antrean daripada sebelumnya.
Jenis aplikasi
Anda dapat mengelompokkan beban kerja berdasarkan berbagai jenis aplikasi (seperti Hive, Spark, Presto, atau HBase) dan menjalankan mesin (seperti MR, Spark, atau Tez). Untuk beban kerja berat komputasi seperti tugas MapReduce atau Hive-on-MR, gunakan instans yang dioptimalkan CPU. Untuk beban kerja intensif memori seperti pekerjaan Hive-on-TEZ, Presto, dan Spark, gunakan instans yang dioptimalkan memori.
Waktu berlalu
Anda dapat mengkategorikan aplikasi berdasarkan runtime. Template CloudFormation tertanam secara otomatis membuat bidang elapsedGroup di dasbor QuickSight. Ini mengaktifkan fitur utama untuk memungkinkan Anda mengamati pekerjaan jangka panjang di salah satu dari empat bagan di dasbor QuickSight. Oleh karena itu, Anda dapat merancang arsitektur masa depan yang disesuaikan untuk pekerjaan besar ini.
Dasbor QuickSight yang sesuai menyertakan empat bagan. Anda dapat menelusuri setiap bagan, yang terkait dengan satu grup.
| Kelompok Jumlah |
Waktu Proses/Waktu Berlalu dari Pekerjaan |
| 1 | Kurang dari 10 menit |
| 2 | Antara 10 menit dan 30 menit |
| 3 | antara 30 menit dan 1 jam |
| 4 | Lebih dari 1 jam |
Dalam bagan Grup 4, Anda dapat berkonsentrasi untuk memeriksa pekerjaan besar berdasarkan berbagai metrik, termasuk pengguna, antrean, jenis aplikasi, garis waktu, penggunaan sumber daya, dan sebagainya. Berdasarkan pertimbangan ini, Anda mungkin memiliki antrean khusus pada kluster atau kluster EMR khusus untuk pekerjaan besar. Sementara itu, Anda dapat mengirimkan pekerjaan kecil ke antrean bersama.
Sumber
Berdasarkan pola konsumsi sumber daya (CPU, memori), Anda memilih ukuran dan rangkaian instans EC2 yang tepat untuk performa dan efektivitas biaya. Untuk aplikasi intensif komputasi, kami merekomendasikan instans rangkaian yang dioptimalkan CPU. Untuk aplikasi intensif memori, keluarga instans yang dioptimalkan memori direkomendasikan.
Selain itu, berdasarkan sifat beban kerja aplikasi dan pemanfaatan sumber daya dari waktu ke waktu, Anda dapat memilih klaster EMR persisten atau sementara, Amazon EMR di EKS, atau Amazon EMR Tanpa Server.
Setelah menganalisis log YARN dengan berbagai metrik, Anda siap merancang arsitektur EMR masa depan. Tabel berikut mencantumkan contoh klaster ESDM yang diusulkan. Anda dapat menemukan detail lebih lanjut di repo GitHub kalkulator-tco yang dioptimalkan.

Hitung TCO
Terakhir, di mesin lokal Anda, jalankan tco-input-generator.py untuk menggabungkan log riwayat pekerjaan YARN setiap jam sebelum menggunakan templat Excel untuk menghitung TCO yang dioptimalkan. Langkah ini penting karena hasilnya mensimulasikan beban kerja Hadoop di instans EMR mendatang.
Prasyarat simulasi TCO adalah untuk dijalankan tco-input-generator.py, yang menghasilkan log agregat per jam. Selanjutnya, Anda membuka file template Excel untuk mengaktifkan makro dan memberikan masukan Anda dalam sel hijau untuk menghitung TCO. Mengenai data masukan, Anda memasukkan ukuran data aktual tanpa replikasi, dan spesifikasi perangkat keras (vCore, mem) dari simpul utama Hadoop dan simpul data. Anda juga harus memilih dan mengunggah log gabungan per jam yang dibuat sebelumnya. Setelah Anda mengatur variabel simulasi TCO, seperti Wilayah, tipe EC2, ketersediaan tinggi Amazon EMR, efek mesin, diskon Amazon EC2 dan Amazon EBS (EDP), diskon volume Amazon S3, kurs mata uang lokal, dan rasio harga tugas/inti EMR EC2 dan harga/jam, simulator TCO secara otomatis menghitung biaya optimal instans EMR mendatang di Amazon EC2. Tangkapan layar berikut menunjukkan contoh hasil HMDK TCO.

Untuk informasi tambahan dan instruksi perhitungan TCO HMDK, lihat repo GitHub kalkulator-tco yang dioptimalkan.
Membersihkan
Setelah Anda menyelesaikan semua langkah dan menyelesaikan pengujian, selesaikan langkah-langkah berikut untuk menghapus sumber daya agar tidak menimbulkan biaya:
- Di konsol AWS CloudFormation, pilih tumpukan yang Anda buat.
- Pilih Delete.
- Pilih Hapus tumpukan.
- Refresh halaman sampai Anda melihat statusnya
DELETE_COMPLETE. - Di konsol Amazon S3, hapus bucket S3 yang Anda buat.
Kesimpulan
Alat TCO HMDK AWS ProServe secara signifikan mengurangi upaya perencanaan migrasi, yang merupakan tugas yang memakan waktu dan menantang untuk menilai beban kerja Hadoop Anda. Dengan alat TCO HMDK, penilaian biasanya memakan waktu 2–3 minggu. Anda juga dapat menentukan TCO terhitung dari arsitektur EMR masa depan. Dengan alat TCO HMDK, Anda dapat dengan cepat memahami beban kerja dan pola penggunaan sumber daya. Dengan wawasan yang dihasilkan oleh alat ini, Anda diperlengkapi untuk merancang arsitektur EMR masa depan yang optimal. Dalam banyak kasus penggunaan, TCO 1 tahun dari arsitektur yang dioptimalkan ulang memberikan penghematan biaya yang signifikan (pengurangan 64–80%) pada komputasi dan penyimpanan, dibandingkan dengan migrasi angkat-dan-geser Hadoop.
Untuk mempelajari selengkapnya tentang mempercepat migrasi Hadoop Anda ke Amazon EMR dan alat CTO HMDK, lihat Repo GitHub TCO Kit Pengiriman Migrasi Hadoop, atau menjangkau AWS-HMDK@amazon.com.
Tentang penulis
 Taman Sungyoul adalah Manajer Praktik Senior di AWS ProServe. Dia membantu pelanggan berinovasi dalam bisnis mereka dengan layanan AWS Analytics, IoT, dan AI/ML. Dia memiliki spesialisasi dalam layanan dan teknologi data besar dan minat untuk membangun hasil bisnis pelanggan bersama-sama.
Taman Sungyoul adalah Manajer Praktik Senior di AWS ProServe. Dia membantu pelanggan berinovasi dalam bisnis mereka dengan layanan AWS Analytics, IoT, dan AI/ML. Dia memiliki spesialisasi dalam layanan dan teknologi data besar dan minat untuk membangun hasil bisnis pelanggan bersama-sama.
 Jiseong Kim adalah Arsitek Data Senior di AWS ProServe. Dia terutama bekerja dengan pelanggan perusahaan untuk membantu migrasi dan modernisasi danau data, dan memberikan panduan dan bantuan teknis pada proyek data besar seperti Hadoop, Spark, pergudangan data, pemrosesan data waktu nyata, dan pembelajaran mesin skala besar. Dia juga memahami bagaimana menerapkan teknologi untuk memecahkan masalah big data dan membangun arsitektur data yang dirancang dengan baik.
Jiseong Kim adalah Arsitek Data Senior di AWS ProServe. Dia terutama bekerja dengan pelanggan perusahaan untuk membantu migrasi dan modernisasi danau data, dan memberikan panduan dan bantuan teknis pada proyek data besar seperti Hadoop, Spark, pergudangan data, pemrosesan data waktu nyata, dan pembelajaran mesin skala besar. Dia juga memahami bagaimana menerapkan teknologi untuk memecahkan masalah big data dan membangun arsitektur data yang dirancang dengan baik.
 George Zhao adalah Arsitek Data Senior di AWS ProServe. Dia adalah pemimpin analitik berpengalaman yang bekerja dengan pelanggan AWS untuk menghadirkan solusi data modern. Dia juga seorang spesialis domain ProServe Amazon EMR yang memungkinkan konsultan ProServe pada praktik terbaik dan kit pengiriman untuk migrasi Hadoop ke Amazon EMR. Bidang minatnya adalah data lake dan pengiriman arsitektur data cloud modern.
George Zhao adalah Arsitek Data Senior di AWS ProServe. Dia adalah pemimpin analitik berpengalaman yang bekerja dengan pelanggan AWS untuk menghadirkan solusi data modern. Dia juga seorang spesialis domain ProServe Amazon EMR yang memungkinkan konsultan ProServe pada praktik terbaik dan kit pengiriman untuk migrasi Hadoop ke Amazon EMR. Bidang minatnya adalah data lake dan pengiriman arsitektur data cloud modern.
 Kalen Zhang adalah Pimpinan Teknologi Segmen Global untuk Data Mitra dan Analitik di AWS. Sebagai penasihat data dan analitik tepercaya, dia menyusun inisiatif strategis untuk transformasi data, memimpin program modernisasi dan migrasi beban kerja data dan analitik, serta mempercepat perjalanan migrasi pelanggan dengan mitra dalam skala besar. Dia berspesialisasi dalam sistem terdistribusi, manajemen data perusahaan, analitik lanjutan, dan inisiatif strategis skala besar.
Kalen Zhang adalah Pimpinan Teknologi Segmen Global untuk Data Mitra dan Analitik di AWS. Sebagai penasihat data dan analitik tepercaya, dia menyusun inisiatif strategis untuk transformasi data, memimpin program modernisasi dan migrasi beban kerja data dan analitik, serta mempercepat perjalanan migrasi pelanggan dengan mitra dalam skala besar. Dia berspesialisasi dalam sistem terdistribusi, manajemen data perusahaan, analitik lanjutan, dan inisiatif strategis skala besar.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- Sanggup
- Tentang Kami
- mempercepat
- dipercepat
- mempercepat
- mempercepat
- percepatan
- aksesibilitas
- Akun
- di seluruh
- Ad
- tambahan
- Tambahan
- Informasi Tambahan
- Selain itu
- maju
- penasihat
- Setelah
- terhadap
- AI / ML
- Semua
- Amazon
- Amazon EC2
- Amazon ESDM
- antara
- analisis
- analisis
- menganalisa
- menganalisis
- dan
- api
- Aplikasi
- aplikasi
- Mendaftar
- tepat
- arsitektur
- DAERAH
- penilaian
- Bantuan
- terkait
- secara otomatis
- tersedianya
- AWS
- Formasi AWS Cloud
- berdasarkan
- dasar
- karena
- makhluk
- Manfaat
- TERBAIK
- Praktik Terbaik
- Lebih baik
- antara
- Besar
- Big data
- secara singkat
- membangun
- Bangunan
- bisnis
- menghitung
- dihitung
- menghitung
- menghitung
- Kalender
- bernama
- panggilan
- kemampuan
- Kapasitas
- kasus
- Sel
- tertentu
- menantang
- Grafik
- Charts
- Pilih
- memilih
- awan
- Kelompok
- mengumpulkan
- Mengumpulkan
- koleksi
- pengumpul
- mengumpulkan
- COM
- sebanding
- membandingkan
- dibandingkan
- lengkap
- menghitung
- memusatkan
- konsentrasi
- Mengadakan
- melakukan
- Terhubung
- koneksi
- menghubungkan
- berturut-turut
- pertimbangan
- konsul
- konsultan
- konsumsi
- mengandung
- Sesuai
- Biaya
- penghematan biaya
- Biaya
- CPU
- dibuat
- menciptakan
- kriteria
- sangat penting
- CTO
- dikuratori
- Currency
- terbaru
- pelanggan
- pelanggan
- siklus
- harian
- dasbor
- data
- Danau Data
- manajemen data
- pengolahan data
- kumpulan data
- hari
- Hari
- dedicated
- mendalam
- menyelam dalam
- menyampaikan
- pengiriman
- menunjukkan
- penggelaran
- Mendesain
- merancang
- rincian
- Menentukan
- Pengembangan
- penyimpangan
- berbeda
- Diskon
- mendistribusikan
- didistribusikan
- sistem terdistribusi
- distribusi
- domain
- turun
- selama
- setiap
- mudah
- ebs
- edisi
- efek
- efektivitas
- upaya
- tertanam
- aktif
- diaktifkan
- memungkinkan
- ujung ke ujung
- Mesin
- Mesin
- memastikan
- Enter
- Enterprise
- pelanggan perusahaan
- lengkap
- menetapkan
- Eter (ETH)
- peristiwa
- Setiap
- contoh
- contoh
- Excel
- ada
- berpengalaman
- memfasilitasi
- keluarga
- keluarga
- Fitur
- Fitur
- bidang
- Angka
- File
- File
- Menemukan
- menyelesaikan
- berikut
- format
- dari
- fungsionalitas
- lebih lanjut
- masa depan
- Umum
- dihasilkan
- menghasilkan
- mendapatkan
- mendapatkan
- GitHub
- Aksi
- Hijau
- Kelompok
- pedoman
- Hadoop
- Perangkat keras
- membantu
- membantu
- High
- sejarah
- Sarang lebah
- hari libur
- holistik
- JAM
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- ICON
- perbaikan
- in
- memasukkan
- Termasuk
- sendiri-sendiri
- individu
- informasi
- inisiatif
- berinovasi
- memasukkan
- wawasan
- contoh
- instruksi
- bunga
- kepentingan
- diperkenalkan
- idiot
- IT
- Pekerjaan
- Jobs
- Perjalanan
- json
- kunci
- kit
- danau
- besar
- besar-besaran
- jalankan
- memimpin
- pemimpin
- BELAJAR
- pengetahuan
- Dipimpin
- Data yang Dipimpin
- daftar
- memuat
- lokal
- Panjang
- lama
- melihat
- Lot
- mesin
- Mesin belajar
- Macro
- Utama
- membuat
- pengelolaan
- manajer
- Manajer
- banyak
- cara
- Sementara itu
- Memori
- penggabungan
- Metrik
- migrasi
- menit
- campur aduk
- modern
- modernisasi
- Bulan
- bulanan
- lebih
- beberapa
- Alam
- Perlu
- berikutnya
- simpul
- node
- jumlah
- nomor
- mengamati
- mendapatkan
- ONE
- Buka
- operasi
- operasi
- optimal
- dioptimalkan
- mengoptimalkan
- optimal
- organisasi
- Lainnya
- tertentu
- pasangan
- rekan
- pola
- Puncak
- melakukan
- prestasi
- periode
- izin
- Tempat
- perencanaan
- plato
- Kecerdasan Data Plato
- Data Plato
- kebijaksanaan
- mungkin
- Pos
- praktek
- praktek
- prasyarat
- sebelumnya
- di harga
- primer
- Sebelumnya
- masalah
- pengolahan
- program
- memprojeksikan
- tepat
- diusulkan
- memberikan
- menyediakan
- Ular sanca
- segera
- Penilaian
- perbandingan
- mencapai
- siap
- real-time
- data waktu nyata
- sarankan
- direkomendasikan
- arsip
- mengurangi
- mengenai
- wilayah
- reguler
- menghapus
- replikasi
- sumber
- Sumber
- Hasil
- penyimpanan
- putaran
- Run
- berjalan
- sama
- Tabungan
- Skala
- menjadwalkan
- screenshot
- bagian
- ruas
- senior
- Seri
- Layanan
- set
- pengaturan
- beberapa
- berbagi
- Menunjukkan
- menampilkan
- penting
- signifikan
- mirip
- Sederhana
- simulasi
- simulator
- situasi
- Ukuran
- kecil
- So
- Solusi
- MEMECAHKAN
- beberapa
- percikan
- spesialis
- spesialisasi
- Khusus
- tertentu
- spesifikasi
- tumpukan
- mulai
- statistika
- Status
- Langkah
- Tangga
- penyimpanan
- Strategis
- menyerahkan
- seperti itu
- Didukung
- sistem
- sistem
- tabel
- disesuaikan
- Dibutuhkan
- target
- tugas
- tim
- tim
- tech
- Teknis
- Teknologi
- Template
- template
- pengujian
- Grafik
- Masa depan
- mereka
- karena itu
- Melalui
- waktu
- Seri waktu
- membuang-buang waktu
- waktu
- untuk
- bersama
- alat
- Mengubah
- Transformasi
- berubah
- benar
- Terpercaya
- jenis
- bawah
- memahami
- pemahaman
- mengerti
- penggunaan
- menggunakan
- Pengguna
- Pengguna
- biasanya
- berbagai
- memeriksa
- visualisasi
- volume
- berjalan
- Pergudangan
- minggu
- mingguan
- minggu
- Apa
- Apa itu
- yang
- SIAPA
- Windows
- tanpa
- alur kerja
- kerja
- bekerja
- yaml
- Anda
- zephyrnet.dll