Organisasi di semua industri memiliki persyaratan pemrosesan data yang kompleks untuk kasus penggunaan analitik mereka di berbagai sistem analitik, seperti data lake di AWS, gudang data (Pergeseran Merah Amazon), mencari (Layanan Pencarian Terbuka Amazon), NoSQL (Amazon DynamoDB), pembelajaran mesin (Amazon SageMaker), dan banyak lagi. Profesional analitik ditugaskan untuk memperoleh nilai dari data yang disimpan dalam sistem terdistribusi ini untuk menciptakan pengalaman yang lebih baik, aman, dan hemat biaya bagi pelanggan mereka. Misalnya, perusahaan media digital berupaya menggabungkan dan memproses kumpulan data dalam database internal dan eksternal untuk membangun pandangan terpadu tentang profil pelanggan mereka, memacu ide untuk fitur inovatif, dan meningkatkan keterlibatan platform.
Dalam skenario ini, pelanggan mencari penggunaan penawaran integrasi data tanpa server Lem AWS sebagai komponen inti untuk pemrosesan dan katalogisasi data. AWS Glue terintegrasi dengan baik dengan layanan AWS dan produk mitra, dan menyediakan opsi ekstrak, transformasi, dan muat (ETL) kode rendah/tanpa kode untuk mengaktifkan analitik, pembelajaran mesin (ML), atau alur kerja pengembangan aplikasi. Pekerjaan ETL AWS Glue mungkin merupakan salah satu komponen dalam pipeline yang lebih kompleks. Mengorkestrasikan jalannya dan mengelola ketergantungan antara komponen-komponen ini adalah kemampuan utama dalam strategi data. Alur Kerja Terkelola Amazon untuk Apache Airflows (Amazon MWAA) mengatur saluran data menggunakan teknologi terdistribusi termasuk sumber daya lokal, layanan AWS, dan komponen pihak ketiga.
Dalam postingan ini, kami menunjukkan cara menyederhanakan pemantauan pekerjaan AWS Glue yang diatur oleh Airflow menggunakan fitur terbaru Amazon MWAA.
Ikhtisar solusi
Posting ini membahas hal-hal berikut:
- Cara memutakhirkan lingkungan Amazon MWAA ke versi 2.4.3.
- Cara mengatur pekerjaan AWS Glue dari Aliran Udara Grafik Asiklik yang Diarahkan (DAG).
- Penyempurnaan keteramatan paket penyedia Airflow Amazon di Amazon MWAA. Anda sekarang dapat menggabungkan log yang dijalankan dari pekerjaan AWS Glue di konsol Airflow untuk menyederhanakan saluran data pemecahan masalah. Konsol Amazon MWAA menjadi referensi tunggal untuk memantau dan menganalisis pekerjaan AWS Glue. Sebelumnya, tim dukungan diperlukan untuk mengakses Konsol Manajemen AWS dan ambil langkah manual untuk visibilitas ini. Fitur ini tersedia secara default dari Amazon MWAA versi 2.4.3.
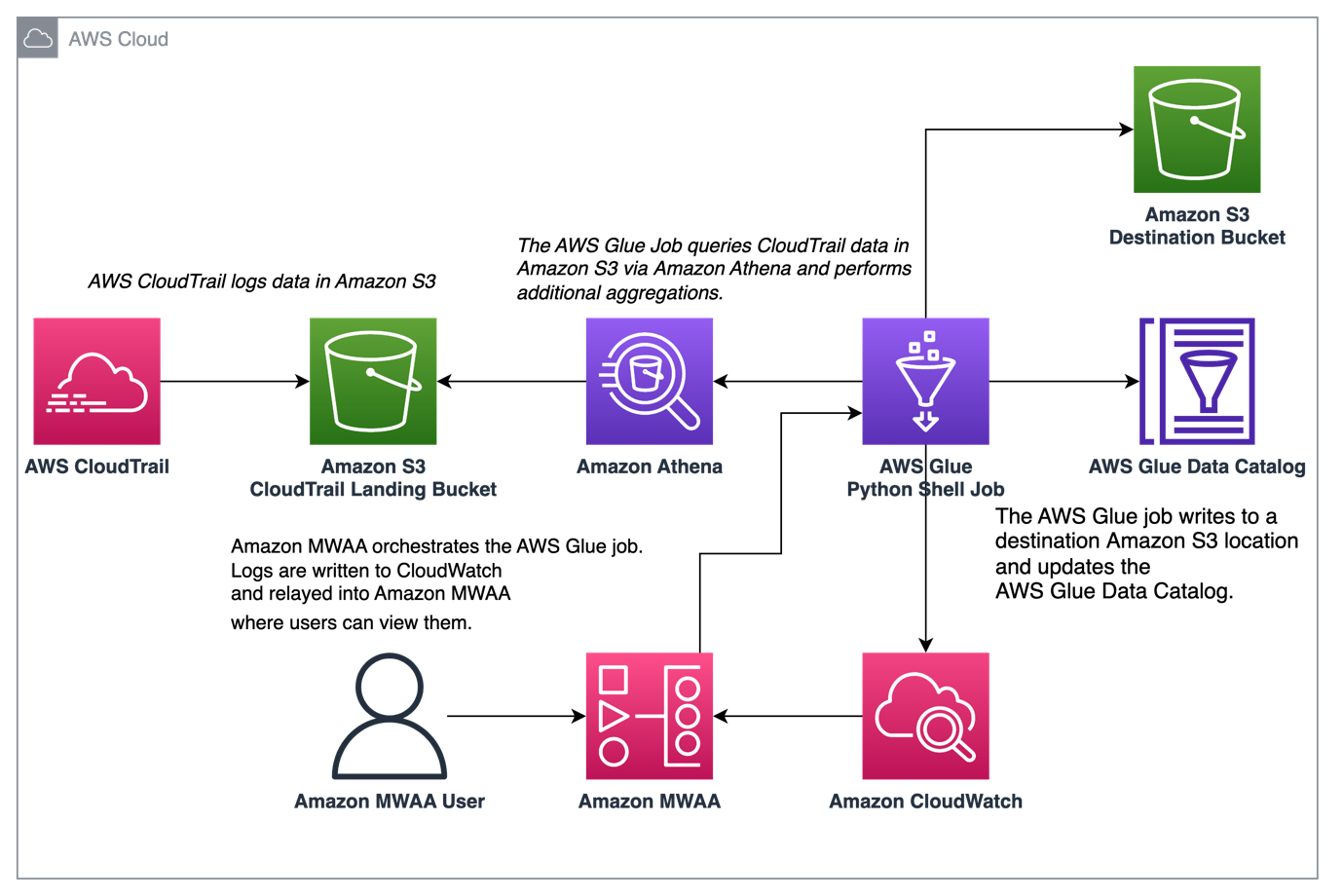
Diagram berikut menggambarkan arsitektur solusi kami.
Prasyarat
Anda memerlukan prasyarat berikut:
Siapkan lingkungan Amazon MWAA
Untuk instruksi tentang membuat lingkungan Anda, lihat Buat lingkungan Amazon MWAA. Untuk pengguna yang sudah ada, kami menyarankan untuk memutakhirkan ke versi 2.4.3 untuk memanfaatkan peningkatan kemampuan observasi yang ditampilkan dalam postingan ini.
Langkah-langkah untuk memutakhirkan Amazon MWAA ke versi 2.4.3 berbeda tergantung pada apakah versi saat ini adalah 1.10.12 atau 2.2.2. Kami membahas kedua opsi di posting ini.
Prasyarat untuk menyiapkan lingkungan Amazon MWAA
Anda harus memenuhi prasyarat berikut:
Tingkatkan dari versi 1.10.12 ke 2.4.3
Jika Anda menggunakan versi Amazon MWAA 1.10.12, mengacu pada Bermigrasi ke lingkungan Amazon MWAA baru untuk meningkatkan ke 2.4.3.
Tingkatkan dari versi 2.0.2 atau 2.2.2 ke 2.4.3
Jika Anda menggunakan lingkungan Amazon MWAA versi 2.2.2 atau lebih rendah, selesaikan langkah-langkah berikut:
- Membuat requirements.txt untuk dependensi khusus apa pun dengan versi khusus yang diperlukan untuk DAG Anda.
- Unggah file ke Amazon S3 di lokasi yang sesuai di mana lingkungan Amazon MWAA mengarah ke requirements.txt untuk menginstal dependensi.
- Ikuti langkah-langkah di Bermigrasi ke lingkungan Amazon MWAA baru dan pilih versi 2.4.3.
Perbarui DAG Anda
Pelanggan yang memutakhirkan dari lingkungan Amazon MWAA lama mungkin perlu memperbarui DAG yang ada. Di Airflow versi 2.4.3, lingkungan Airflow akan menggunakan paket penyedia Amazon versi 6.0.0 secara default. Paket ini mungkin menyertakan beberapa perubahan yang berpotensi merusak, seperti perubahan nama operator. Misalnya, AWSGlueJobOperator telah ditinggalkan dan diganti dengan LemJobOperator. Untuk mempertahankan kompatibilitas, perbarui DAG Airflow Anda dengan mengganti operator yang tidak digunakan lagi atau tidak didukung dari versi sebelumnya dengan yang baru. Selesaikan langkah-langkah berikut:
- Navigasi ke Operator Amazon AWS.
- Pilih versi yang sesuai yang terinstal di instans Amazon MWAA Anda (6.0.0. secara default) untuk menemukan daftar operator Airflow yang didukung.
- Lakukan perubahan yang diperlukan pada kode DAG yang ada dan unggah file yang dimodifikasi ke lokasi DAG di Amazon S3.
Atur pekerjaan AWS Glue dari Airflow
Bagian ini membahas detail pengaturan tugas AWS Glue dalam Airflow DAG. Aliran udara memudahkan pengembangan saluran data dengan ketergantungan antara sistem heterogen seperti proses lokal, ketergantungan eksternal, layanan AWS lainnya, dan banyak lagi.
Atur agregasi log CloudTrail dengan AWS Glue dan Amazon MWAA
Dalam contoh ini, kami membahas kasus penggunaan Amazon MWAA untuk mengatur pekerjaan AWS Glue Python Shell yang mempertahankan metrik gabungan berdasarkan log CloudTrail.
CloudTrail memungkinkan visibilitas ke dalam panggilan API AWS yang dilakukan di akun AWS Anda. Kasus penggunaan umum dengan data ini adalah untuk mengumpulkan metrik penggunaan pada prinsipal yang bertindak atas sumber daya akun Anda untuk keperluan audit dan peraturan.
Saat peristiwa CloudTrail dicatat, peristiwa tersebut dikirimkan sebagai file JSON di Amazon S3, yang tidak ideal untuk kueri analitik. Kami ingin menggabungkan data ini dan mempertahankannya sebagai file Parket untuk memungkinkan kinerja kueri yang optimal. Sebagai langkah awal, kita dapat menggunakan Athena untuk melakukan kueri data awal sebelum melakukan agregasi tambahan dalam tugas AWS Glue kita. Untuk informasi selengkapnya tentang membuat tabel Katalog Data AWS Glue, lihat Membuat tabel untuk log CloudTrail di Athena menggunakan proyeksi partisi data. Setelah menjelajahi data melalui Athena dan memutuskan metrik apa yang ingin dipertahankan dalam tabel agregat, kita dapat membuat tugas AWS Glue.
Buat tabel CloudTrail di Athena
Pertama, kita perlu membuat tabel di Katalog Data kita yang memungkinkan data CloudTrail dikueri melalui Athena. Kueri contoh berikut membuat tabel dengan dua partisi pada Wilayah dan tanggal (disebut snapshot_date). Pastikan untuk mengganti placeholder untuk bucket CloudTrail, ID akun AWS, dan nama tabel CloudTrail Anda:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Jalankan kueri sebelumnya di konsol Athena, dan catat nama tabel dan database AWS Glue Data Catalog tempat pembuatannya. Kami menggunakan nilai ini nanti dalam kode DAG Airflow.
Contoh kode pekerjaan AWS Glue
Kode berikut adalah contohnya Pekerjaan AWS Glue Python Shell yang melakukan hal berikut:
- Mengambil argumen (yang kami berikan dari DAG Amazon MWAA kami) tentang data hari apa yang akan diproses
- Menggunakan AWS SDK untuk Panda untuk menjalankan kueri Athena untuk melakukan pemfilteran awal data CloudTrail JSON di luar AWS Glue
- Menggunakan Panda untuk melakukan agregasi sederhana pada data yang difilter
- Menampilkan data gabungan ke Katalog Data AWS Glue dalam sebuah tabel
- Menggunakan logging selama pemrosesan, yang akan terlihat di Amazon MWAA
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Berikut adalah beberapa keunggulan utama dalam pekerjaan AWS Glue ini:
- Kami menggunakan kueri Athena untuk memastikan pemfilteran awal dilakukan di luar pekerjaan AWS Glue kami. Dengan demikian, tugas Python Shell dengan komputasi minimal masih cukup untuk menggabungkan kumpulan data CloudTrail yang besar.
- Kami memastikan opsi kumpulan pustaka analitik diaktifkan saat membuat tugas AWS Glue kami untuk menggunakan pustaka AWS SDK for Pandas.
Buat pekerjaan AWS Glue
Selesaikan langkah-langkah berikut untuk membuat tugas AWS Glue Anda:
- Salin skrip di bagian sebelumnya dan simpan di file lokal. Untuk posting ini, file tersebut dipanggil
script.py. - Di konsol AWS Glue, pilih pekerjaan ETL di panel navigasi.
- Buat pekerjaan baru dan pilih Editor skrip Python Shell.
- Pilih Unggah dan edit skrip yang ada dan unggah file yang Anda simpan secara lokal.
- Pilih membuat.

- pada Rincian pekerjaan tab, masukkan nama untuk pekerjaan AWS Glue Anda.
- Untuk Peran IAM, pilih peran yang ada atau buat peran baru yang memiliki izin yang diperlukan untuk Amazon S3, AWS Glue, dan Athena. Peran perlu mengkueri tabel CloudTrail yang Anda buat sebelumnya dan menulis ke lokasi keluaran.
Anda dapat menggunakan contoh kode kebijakan berikut. Ganti placeholder dengan bucket log CloudTrail, nama tabel output, database AWS Glue output, bucket S3 output, nama tabel CloudTrail, database AWS Glue yang berisi tabel CloudTrail, dan ID akun AWS Anda.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Untuk Versi python, pilih Python 3.9.
- Pilih Muat pustaka analitik umum.
- Untuk Unit pemrosesan data, pilih 1 DPU.
- Biarkan opsi lain sebagai default atau sesuaikan sesuai kebutuhan.

- Pilih Save untuk menyimpan konfigurasi pekerjaan Anda.
Konfigurasi DAG Amazon MWAA untuk mengatur pekerjaan AWS Glue
Kode berikut adalah untuk DAG yang dapat mengatur pekerjaan AWS Glue yang kami buat. Kami memanfaatkan fitur utama berikut di DAG ini:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Meningkatkan observabilitas pekerjaan AWS Glue di Amazon MWAA
Pekerjaan AWS Glue menulis log ke amazoncloudwatch. Dengan peningkatan kemampuan pengamatan baru-baru ini pada paket penyedia Amazon Airflow, log ini sekarang terintegrasi dengan log tugas Airflow. Konsolidasi ini memberi pengguna Airflow visibilitas menyeluruh secara langsung di UI Airflow, menghilangkan kebutuhan untuk mencari di CloudWatch atau konsol AWS Glue.
Untuk menggunakan fitur ini, pastikan peran IAM yang melekat pada lingkungan Amazon MWAA memiliki izin berikut untuk mengambil dan menulis log yang diperlukan:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Jika verbose=true, log pekerjaan AWS Glue akan ditampilkan di log tugas Airflow. Nilai defaultnya salah. Untuk informasi lebih lanjut, lihat parameter.
Saat diaktifkan, DAG membaca dari aliran log CloudWatch pekerjaan AWS Glue dan meneruskannya ke log langkah pekerjaan Airflow DAG AWS Glue. Ini memberikan wawasan mendetail tentang pekerjaan AWS Glue yang dijalankan secara waktu nyata melalui log DAG. Perhatikan bahwa tugas AWS Glue menghasilkan keluaran dan kesalahan grup log CloudWatch berdasarkan STDOUT dan STDERR tugas masing-masing. Semua log dalam grup log keluaran dan log pengecualian atau kesalahan dari grup log kesalahan diteruskan ke Amazon MWAA.
Admin AWS sekarang dapat membatasi akses tim dukungan hanya ke Airflow, menjadikan Amazon MWAA satu panel kaca pada orkestrasi pekerjaan dan manajemen kesehatan pekerjaan. Sebelumnya, pengguna perlu memeriksa status pelaksanaan tugas AWS Glue di langkah Airflow DAG dan mengambil pengidentifikasi pelaksanaan tugas. Mereka kemudian perlu mengakses konsol AWS Glue untuk menemukan riwayat pekerjaan yang dijalankan, mencari pekerjaan yang diminati menggunakan pengidentifikasi, dan terakhir menavigasi ke log CloudWatch pekerjaan untuk memecahkan masalah.
Buat DAG
Untuk membuat DAG, selesaikan langkah-langkah berikut:
- Simpan kode DAG sebelumnya ke file .py lokal, menggantikan placeholder yang ditunjukkan.
Nilai untuk ID akun AWS Anda, nama pekerjaan AWS Glue, database AWS Glue dengan tabel CloudTrail, dan nama tabel CloudTrail seharusnya sudah diketahui. Anda dapat menyesuaikan bucket S3 output, database AWS Glue output, dan nama tabel output sesuai kebutuhan, tetapi pastikan peran IAM pekerjaan AWS Glue yang Anda gunakan sebelumnya dikonfigurasi dengan benar.
- Di konsol Amazon MWAA, arahkan ke lingkungan Anda untuk melihat di mana kode DAG disimpan.
Folder DAG adalah awalan dalam bucket S3 tempat file DAG Anda harus ditempatkan.
- Unggah file yang telah diedit di sana.

- Buka konsol Amazon MWAA untuk mengonfirmasi bahwa DAG muncul di tabel.

Jalankan DAG
Untuk menjalankan DAG, selesaikan langkah-langkah berikut:
- Pilih dari opsi berikut:
- Pemicu DAG – Ini menyebabkan data kemarin digunakan sebagai data untuk diproses
- Memicu DAG dengan config – Dengan opsi ini, Anda dapat melewati tanggal yang berbeda, berpotensi untuk isi ulang, yang diambil menggunakan
dag_run.confdalam kode DAG dan kemudian diteruskan ke pekerjaan AWS Glue sebagai parameter

Tangkapan layar berikut menunjukkan opsi konfigurasi tambahan jika Anda memilih Memicu DAG dengan config.

- Pantau DAG saat dijalankan.
- Saat DAG selesai, buka detail proses.
Di panel kanan, Anda dapat melihat log, atau memilih Detail Instance Tugas untuk tampilan penuh.

- Lihat log keluaran pekerjaan AWS Glue di Amazon MWAA tanpa menggunakan konsol AWS Glue berkat
GlueJobOperatorbendera verbose.

Pekerjaan AWS Glue akan memiliki hasil tertulis ke tabel keluaran yang Anda tentukan.
- Tanyakan tabel ini melalui Athena untuk memastikan bahwa tabel ini berhasil.
Kesimpulan
Amazon MWAA kini menyediakan satu tempat untuk melacak status tugas AWS Glue dan memungkinkan Anda menggunakan konsol Airflow sebagai satu panel kaca untuk orkestrasi tugas dan manajemen kesehatan. Dalam postingan ini, kami menelusuri langkah-langkah untuk mengatur pekerjaan AWS Glue melalui penggunaan Airflow GlueJobOperator. Dengan peningkatan kemampuan pengamatan yang baru, Anda dapat memecahkan masalah pekerjaan AWS Glue dengan mulus dalam pengalaman terpadu. Kami juga mendemonstrasikan cara memutakhirkan lingkungan Amazon MWAA Anda ke versi yang kompatibel, memperbarui dependensi, dan mengubah kebijakan peran IAM yang sesuai.
Untuk informasi selengkapnya tentang langkah pemecahan masalah umum, lihat Pemecahan masalah: Membuat dan memperbarui lingkungan Amazon MWAA. Untuk detail mendalam tentang migrasi ke lingkungan Amazon MWAA, lihat Upgrade dari 1.10 ke 2. Untuk mempelajari tentang perubahan kode sumber terbuka untuk peningkatan observabilitas pekerjaan AWS Glue di paket penyedia Amazon Airflow, lihat menyampaikan log dari pekerjaan AWS Glue.
Akhirnya, kami merekomendasikan mengunjungi Blog Data Besar AWS untuk materi lain tentang analitik, ML, dan tata kelola data di AWS.
Tentang Penulis
 Rushabh Lokhande adalah Insinyur Data & ML dengan Praktik Analisis Layanan Profesional AWS. Dia membantu pelanggan mengimplementasikan data besar, pembelajaran mesin, dan solusi analitik. Di luar pekerjaan, dia senang menghabiskan waktu bersama keluarga, membaca, berlari, dan bermain golf.
Rushabh Lokhande adalah Insinyur Data & ML dengan Praktik Analisis Layanan Profesional AWS. Dia membantu pelanggan mengimplementasikan data besar, pembelajaran mesin, dan solusi analitik. Di luar pekerjaan, dia senang menghabiskan waktu bersama keluarga, membaca, berlari, dan bermain golf.
 Ryan Gomes adalah Insinyur Data & ML dengan Praktik Analisis Layanan Profesional AWS. Dia bersemangat membantu pelanggan mencapai hasil yang lebih baik melalui analitik dan solusi pembelajaran mesin di cloud. Di luar pekerjaan, dia menikmati kebugaran, memasak, dan menghabiskan waktu berkualitas bersama teman dan keluarga.
Ryan Gomes adalah Insinyur Data & ML dengan Praktik Analisis Layanan Profesional AWS. Dia bersemangat membantu pelanggan mencapai hasil yang lebih baik melalui analitik dan solusi pembelajaran mesin di cloud. Di luar pekerjaan, dia menikmati kebugaran, memasak, dan menghabiskan waktu berkualitas bersama teman dan keluarga.
 Wiswa Gupta adalah Arsitek Data Senior dengan Praktik Analisis Layanan Profesional AWS. Dia membantu pelanggan menerapkan data besar dan solusi analitik. Di luar pekerjaan, ia senang menghabiskan waktu bersama keluarga, jalan-jalan, dan mencoba makanan baru.
Wiswa Gupta adalah Arsitek Data Senior dengan Praktik Analisis Layanan Profesional AWS. Dia membantu pelanggan menerapkan data besar dan solusi analitik. Di luar pekerjaan, ia senang menghabiskan waktu bersama keluarga, jalan-jalan, dan mencoba makanan baru.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Mencetak Masa Depan bersama Adryenn Ashley. Akses Di Sini.
- Beli dan Jual Saham di Perusahaan PRE-IPO dengan PREIPO®. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 12
- 8
- a
- Tentang Kami
- mengakses
- demikian
- Akun
- Mencapai
- di seluruh
- Tindakan
- asiklik
- Tambahan
- Keuntungan
- keuntungan
- Setelah
- pengumpulan
- Semua
- mengizinkan
- memungkinkan
- sudah
- juga
- Amazon
- Amazon Web Services
- an
- Analytical
- analisis
- menganalisa
- dan
- Apa pun
- Apache
- api
- Aplikasi
- Pengembangan Aplikasi
- sesuai
- arsitektur
- ADALAH
- argumen
- argumen
- AS
- At
- atribut
- audit
- tersedia
- AWS
- Lem AWS
- Layanan Profesional AWS
- berdasarkan
- BE
- menjadi
- menjadi
- sebelum
- makhluk
- Lebih baik
- antara
- Besar
- Big data
- kedua
- Melanggar
- membangun
- tapi
- by
- bernama
- Panggilan
- CAN
- kasus
- kasus
- katalog
- penyebab
- perubahan
- Perubahan
- memeriksa
- Pilih
- awan
- kode
- COM
- menggabungkan
- komentar
- Umum
- Perusahaan
- kesesuaian
- cocok
- lengkap
- kompleks
- komponen
- komponen
- menghitung
- konfigurasi
- Memastikan
- konsul
- mengkonsolidasikan
- konsolidasi
- memasak
- Core
- meliputi
- membuat
- dibuat
- menciptakan
- membuat
- terbaru
- adat
- pelanggan
- pelanggan
- DAG
- data
- integrasi data
- pengolahan data
- strategi data
- gudang data
- Basis Data
- database
- kumpulan data
- Tanggal
- Tanggal
- tanggal Waktu
- Hari
- memutuskan
- Default
- disampaikan
- menunjukkan
- Tergantung
- usang
- terperinci
- rincian
- Pengembangan
- berbeda
- berbeda
- digital
- Media digital
- langsung
- membahas
- didistribusikan
- sistem terdistribusi
- do
- tidak
- melakukan
- dilakukan
- selama
- e
- Terdahulu
- Kemudahan
- efek
- menghilangkan
- lain
- aktif
- diaktifkan
- memungkinkan
- ujung ke ujung
- interaksi
- insinyur
- Perangkat tambahan
- memastikan
- Enter
- Lingkungan Hidup
- kesalahan
- Eter (ETH)
- peristiwa
- contoh
- Kecuali
- pengecualian
- ada
- ada
- ada
- pengalaman
- Pengalaman
- Dieksplorasi
- ekspresi
- luar
- ekstrak
- Gagal
- palsu
- keluarga
- Fitur
- fitur
- Fitur
- File
- File
- penyaringan
- Akhirnya
- Menemukan
- kebugaran
- berikut
- makanan
- Untuk
- format
- teman
- dari
- penuh
- mengumpulkan
- menghasilkan
- kaca
- Go
- golf
- pemerintahan
- Kelompok
- Hadoop
- Memiliki
- he
- Kesehatan
- membantu
- membantu
- sejarah
- Sarang lebah
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- IAM
- ID
- ideal
- ide-ide
- identifier
- if
- menggambarkan
- melaksanakan
- mengimpor
- in
- secara mendalam
- memasukkan
- Termasuk
- Meningkatkan
- Pada meningkat
- menunjukkan
- industri
- Info
- informasi
- mulanya
- inovatif
- wawasan
- Instalasi
- contoh
- instruksi
- terpadu
- integrasi
- bunga
- intern
- ke
- IT
- Pekerjaan
- Jobs
- jpg
- json
- kunci
- dikenal
- besar
- kemudian
- Terbaru
- BELAJAR
- pengetahuan
- Perpustakaan
- MEMBATASI
- Daftar
- memuat
- lokal
- lokal
- tempat
- mencatat
- login
- penebangan
- mencari
- mesin
- Mesin belajar
- terbuat
- memelihara
- membuat
- Membuat
- berhasil
- pengelolaan
- pelaksana
- panduan
- bahan
- Mungkin..
- Media
- Pelajari
- pesan
- Metrik
- bermigrasi
- minimal
- ML
- dimodifikasi
- modul
- Memantau
- pemantauan
- lebih
- harus
- nama
- nama
- Arahkan
- Navigasi
- perlu
- Perlu
- dibutuhkan
- kebutuhan
- New
- tidak ada
- sekarang
- of
- menawarkan
- on
- ONE
- yang
- hanya
- Buka
- open source
- kode sumber terbuka
- operator
- operator
- optimal
- pilihan
- Opsi
- or
- diatur
- teknik mengatur musik
- Lainnya
- kami
- hasil
- keluaran
- di luar
- paket
- panda
- pane
- parameter
- pasangan
- lulus
- Lulus
- bergairah
- prestasi
- Izin
- terus berlanjut
- pipa saluran
- Tempat
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- poin
- kebijaksanaan
- Pos
- berpotensi
- praktek
- prasyarat
- sebelumnya
- sebelumnya
- proses
- proses
- pengolahan
- Produk
- profesional
- profesional
- profil
- Proyeksi
- pemberi
- penyedia
- menyediakan
- Ular sanca
- kualitas
- query
- menaikkan
- jarak
- Baca
- Bacaan
- nyata
- real-time
- baru
- sarankan
- wilayah
- regulator
- menyampaikan
- menggantikan
- diganti
- wajib
- Persyaratan
- sumber
- Sumber
- masing-masing
- tanggapan
- Hasil
- menahan
- benar
- Peran
- BARIS
- Run
- berjalan
- s
- Save
- skenario
- SDK
- mulus
- Pencarian
- Bagian
- aman
- melihat
- Mencari
- senior
- Tanpa Server
- Layanan
- pengaturan
- penyiapan
- Kulit
- harus
- Menunjukkan
- Pertunjukkan
- Sederhana
- menyederhanakan
- sejak
- tunggal
- Potret
- larutan
- Solusi
- beberapa
- tertentu
- ditentukan
- Pengeluaran
- Pernyataan
- Status
- Langkah
- Tangga
- Masih
- penyimpanan
- tersimpan
- Penyelarasan
- aliran
- Tali
- sukses
- seperti itu
- cukup
- mendukung
- Didukung
- sistem
- tabel
- Mengambil
- pengambilan
- tugas
- tim
- Teknologi
- Template
- Terima kasih
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- pihak ketiga
- ini
- Melalui
- waktu
- untuk
- jalur
- Mengubah
- Perjalanan
- benar
- mencoba
- Selasa
- Berbalik
- dua
- mengetik
- ui
- terpadu
- satuan
- Memperbarui
- Pembaruan
- memperbarui
- meningkatkan
- upgrade
- Mengunggah
- penggunaan
- menggunakan
- gunakan case
- bekas
- Pengguna
- menggunakan
- nilai
- Nilai - Nilai
- versi
- melalui
- View
- 'view'
- jarak penglihatan
- terlihat
- berjalan
- ingin
- adalah
- we
- jaringan
- layanan web
- BAIK
- Apa
- ketika
- apakah
- yang
- SIAPA
- akan
- dengan
- dalam
- tanpa
- Kerja
- Alur kerja
- akan
- menulis
- tertulis
- kamu
- Anda
- zephyrnet.dll