Dengan diluncurkannya fitur pencarian saraf untuk Layanan Pencarian Terbuka Amazon di OpenSearch 2.9, integrasi dengan model AI/ML kini menjadi lebih mudah untuk mendukung penelusuran semantik dan kasus penggunaan lainnya. OpenSearch Service telah mendukung pencarian leksikal dan vektor sejak diperkenalkannya fitur k-nearest neighbour (k-NN) pada tahun 2020; namun, mengonfigurasi penelusuran semantik memerlukan pembuatan kerangka kerja untuk mengintegrasikan model pembelajaran mesin (ML) untuk menyerap dan menelusuri. Fitur penelusuran saraf memfasilitasi transformasi teks menjadi vektor selama penyerapan dan penelusuran. Saat Anda menggunakan kueri saraf selama penelusuran, kueri tersebut diterjemahkan ke dalam penyematan vektor dan k-NN digunakan untuk mengembalikan penyematan vektor terdekat dari korpus.
Untuk menggunakan penelusuran neural, Anda harus menyiapkan model ML. Kami merekomendasikan untuk mengonfigurasi konektor AI/ML ke layanan AWS AI dan ML (seperti Amazon SageMaker or Batuan Dasar Amazon) atau alternatif pihak ketiga. Dimulai dengan versi 2.9 pada Layanan OpenSearch, konektor AI/ML berintegrasi dengan penelusuran saraf untuk menyederhanakan dan mengoperasionalkan terjemahan korpus data dan kueri Anda ke penyematan vektor, sehingga menghilangkan banyak kerumitan hidrasi dan penelusuran vektor.
Dalam postingan ini, kami mendemonstrasikan cara mengonfigurasi konektor AI/ML ke model eksternal melalui konsol OpenSearch Service.
Ikhtisar Solusi
Secara khusus, postingan ini memandu Anda dalam menghubungkan ke model di SageMaker. Kemudian kami memandu Anda dalam menggunakan konektor untuk mengonfigurasi pencarian semantik di OpenSearch Service sebagai contoh kasus penggunaan yang didukung melalui koneksi ke model ML. Integrasi Amazon Bedrock dan SageMaker saat ini didukung di UI konsol OpenSearch Service, dan daftar integrasi pihak pertama dan ketiga yang didukung UI akan terus bertambah.
Untuk model apa pun yang tidak didukung melalui UI, Anda dapat menyiapkannya menggunakan API yang tersedia dan cetak biru ML. Untuk informasi lebih lanjut, lihat Pengantar Model OpenSearch. Anda dapat menemukan cetak biru untuk setiap konektor di Repositori ML Commons GitHub.
Prasyarat
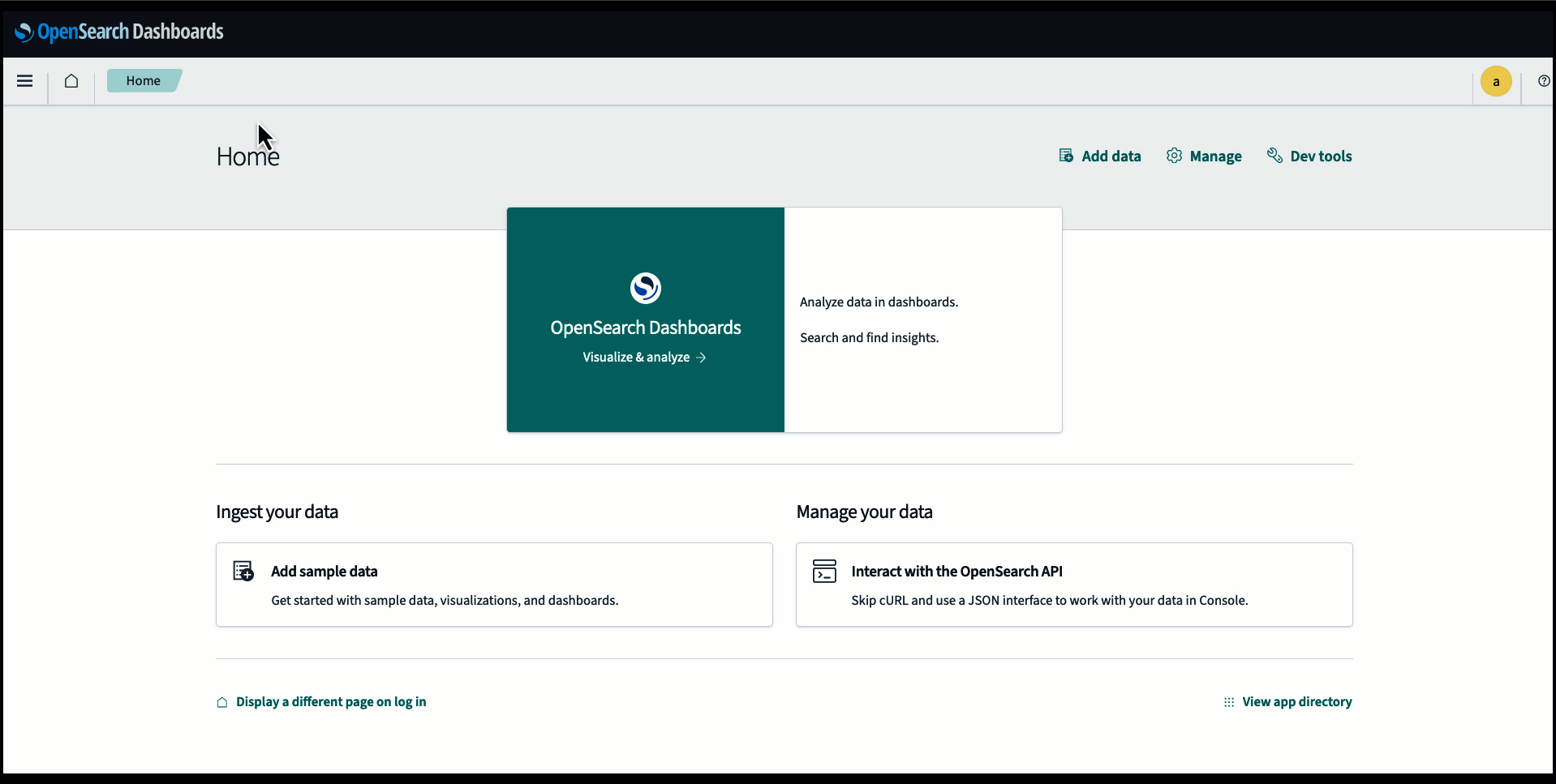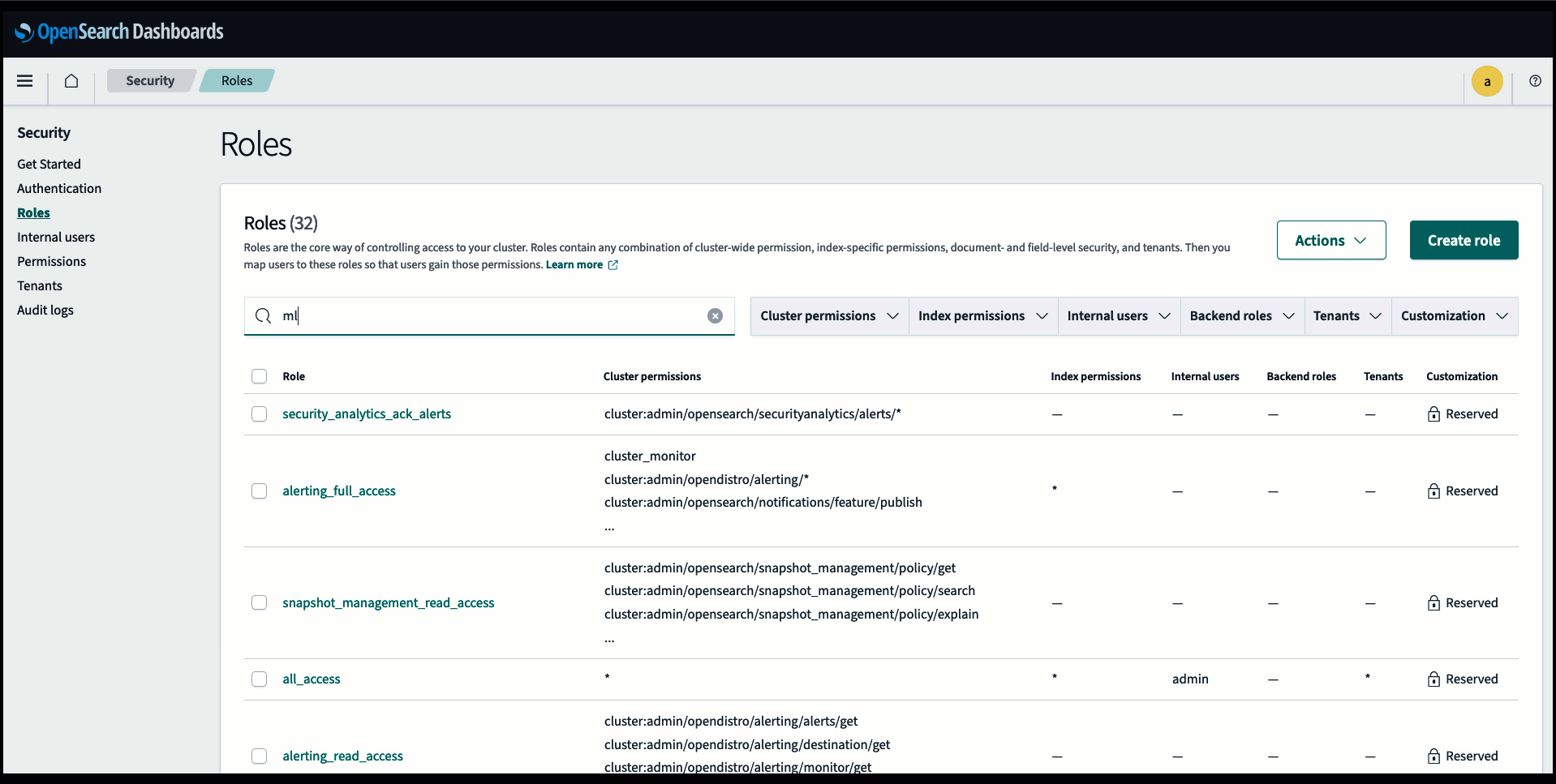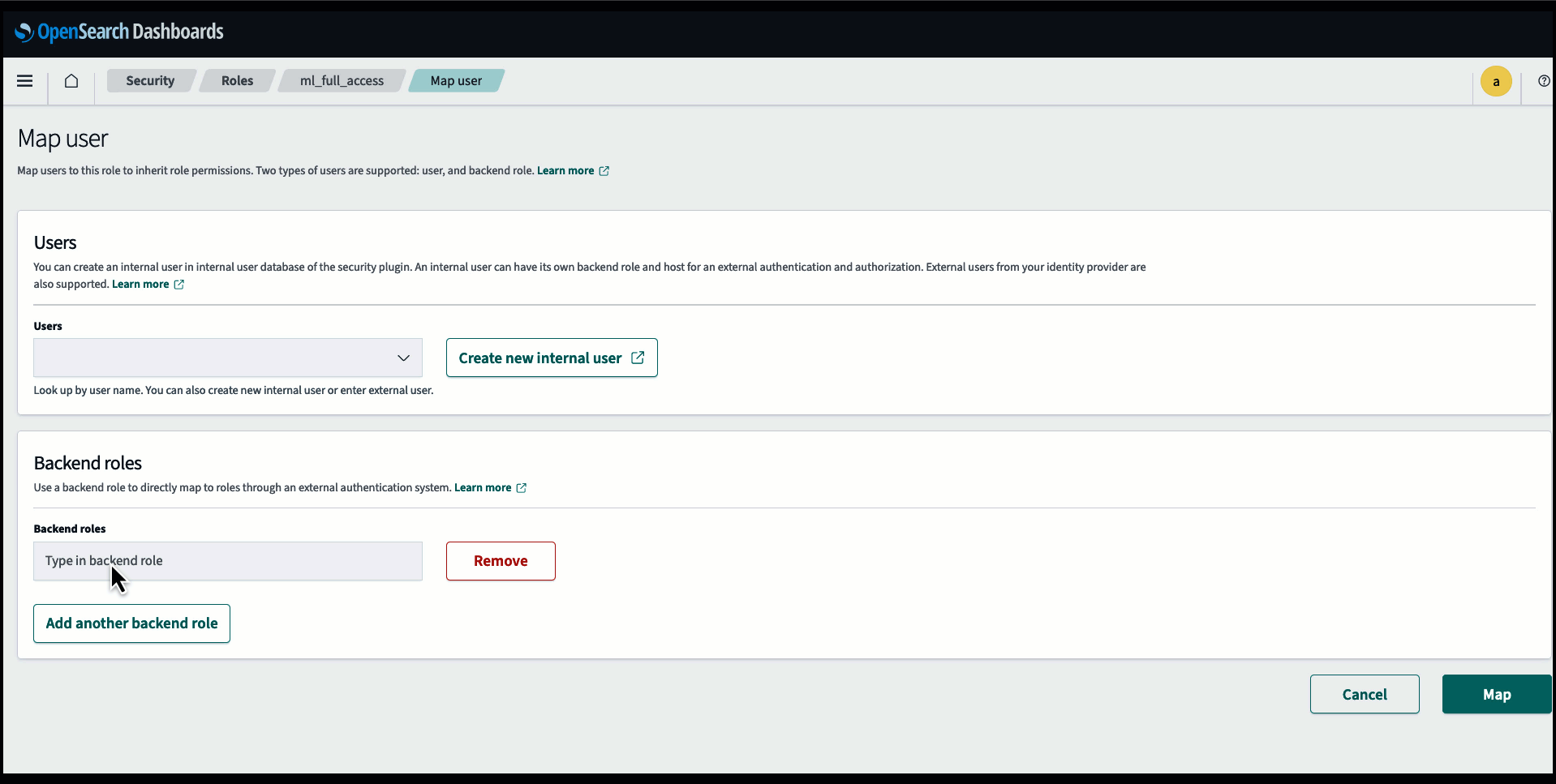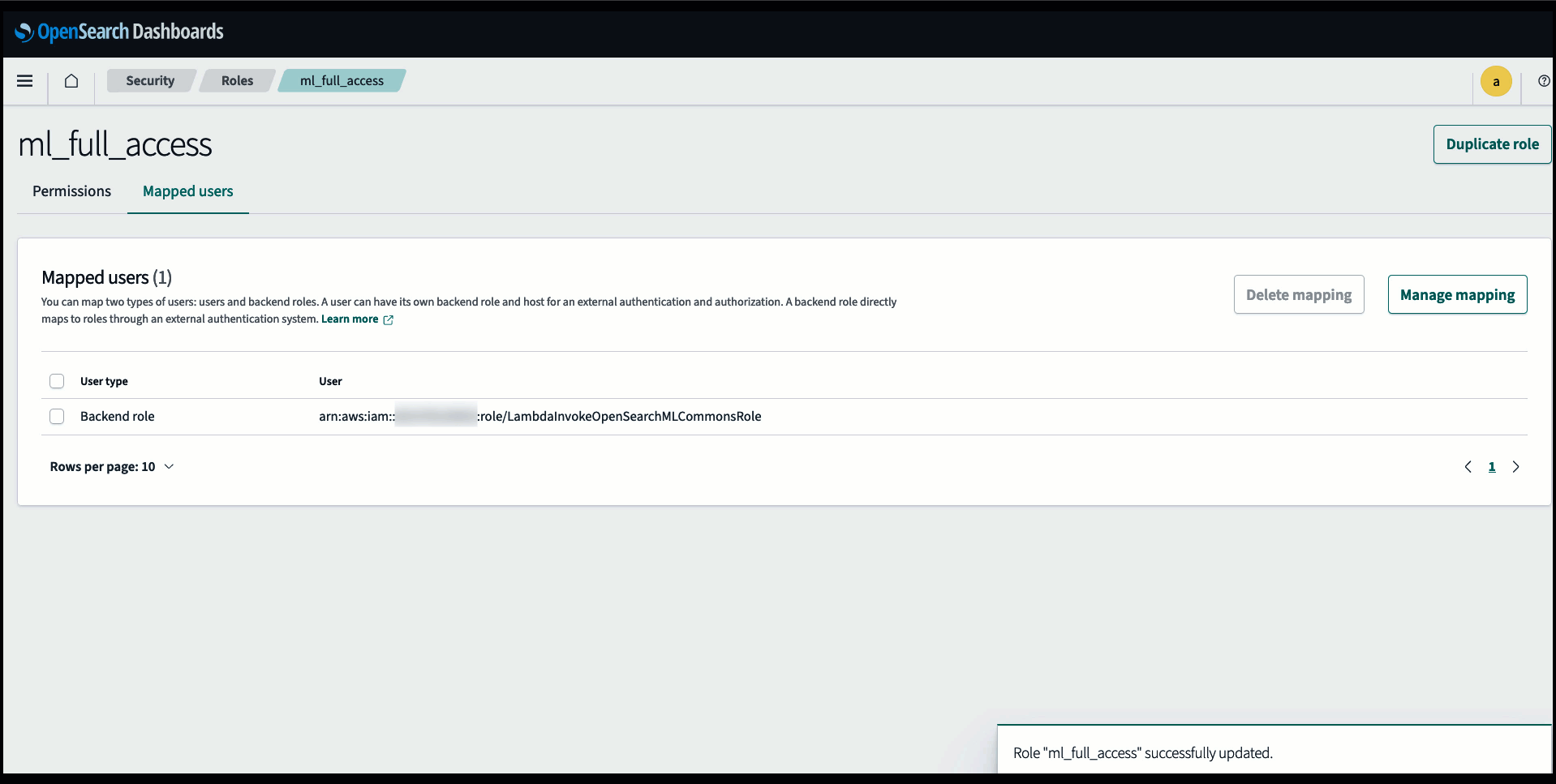
Sebelum menghubungkan model melalui konsol OpenSearch Service, buat domain OpenSearch Service. Peta sebuah Identitas AWS dan Manajemen Akses (IAM) peran berdasarkan nama LambdaInvokeOpenSearchMLCommonsRole sebagai peran backend di ml_full_access peran menggunakan plugin Keamanan di OpenSearch Dashboards, seperti yang ditunjukkan dalam video berikut. Alur kerja integrasi OpenSearch Service telah diisi sebelumnya untuk menggunakan LambdaInvokeOpenSearchMLCommonsRole IAM role secara default untuk membuat konektor antara domain OpenSearch Service dan model yang diterapkan di SageMaker. Jika Anda menggunakan peran IAM khusus pada integrasi konsol Layanan OpenSearch, pastikan peran khusus tersebut dipetakan sebagai peran backend dengan ml_full_access izin sebelum menerapkan templat.
Terapkan model menggunakan AWS CloudFormation
Video berikut menunjukkan langkah-langkah menggunakan konsol OpenSearch Service untuk menerapkan model dalam hitungan menit di Amazon SageMaker dan menghasilkan ID model melalui konektor AI. Langkah pertama adalah memilih Integrasi di panel navigasi pada konsol OpenSearch Service AWS, yang merutekan ke daftar integrasi yang tersedia. Integrasi diatur melalui UI, yang akan meminta Anda memasukkan masukan yang diperlukan.
Untuk menyiapkan integrasi, Anda hanya perlu menyediakan titik akhir domain OpenSearch Service dan memberikan nama model untuk mengidentifikasi koneksi model secara unik. Secara default, templat menerapkan model pengubah kalimat Hugging Face, djl://ai.djl.huggingface.pytorch/sentence-transformers/all-MiniLM-L6-v2.
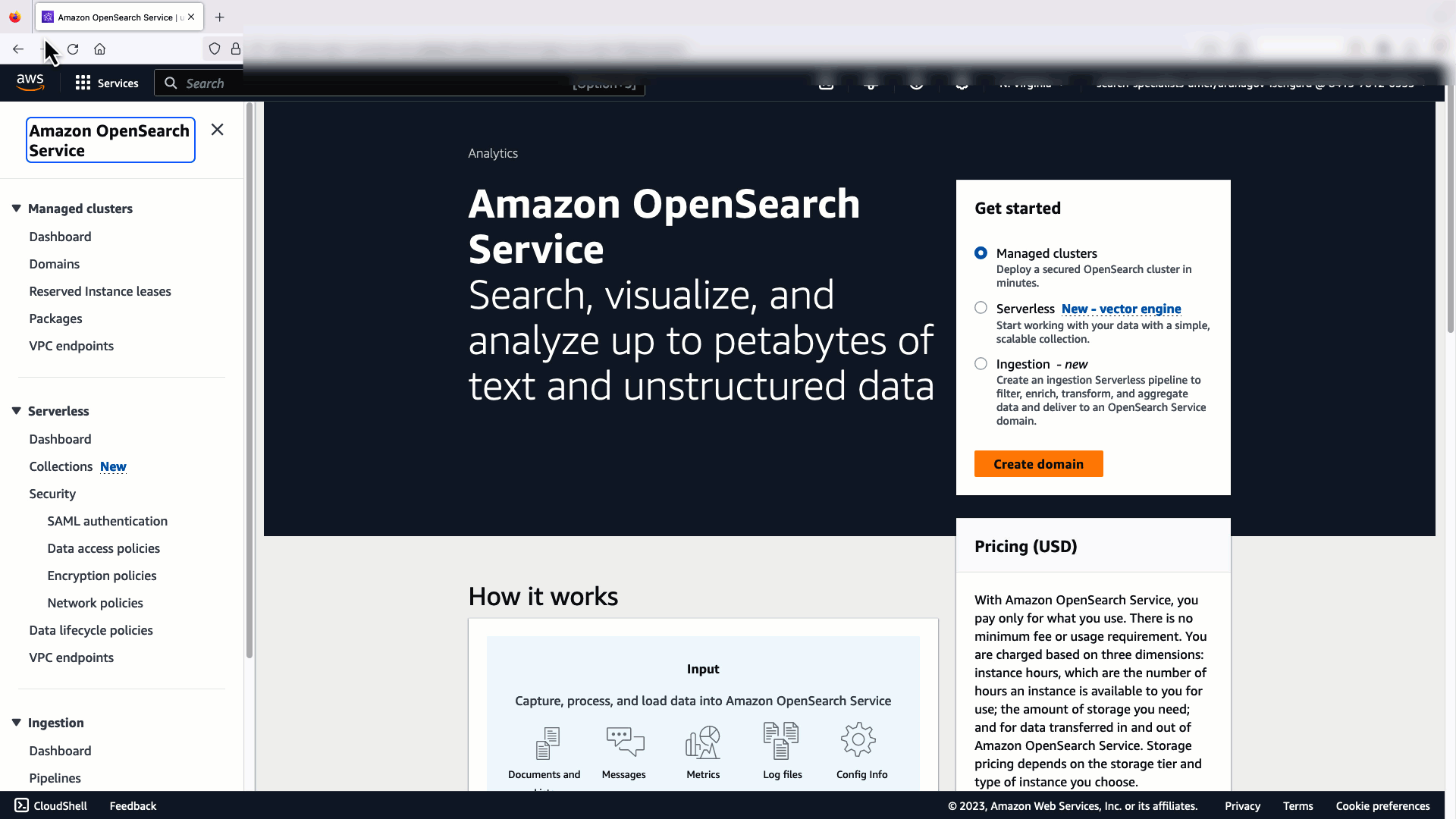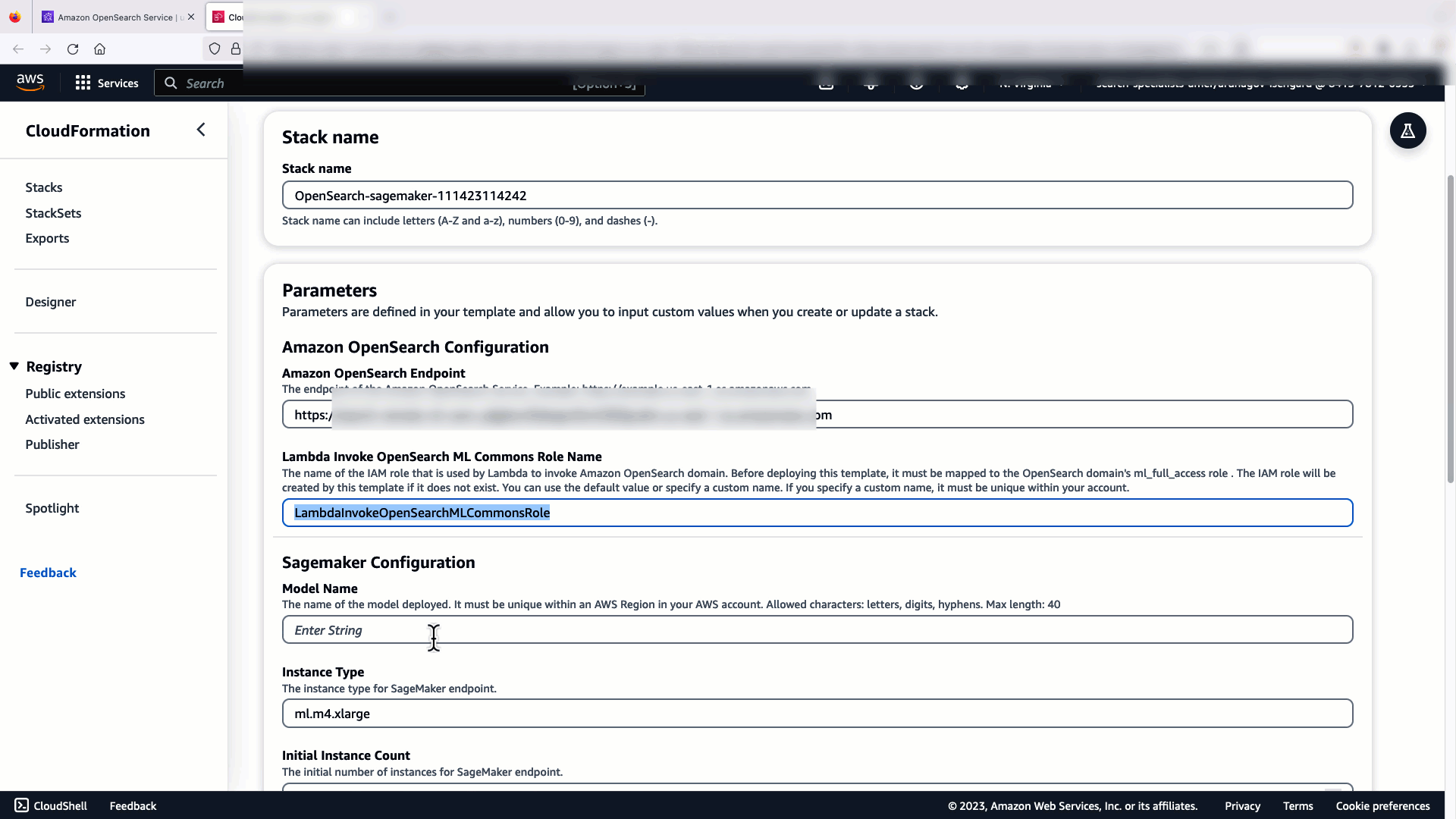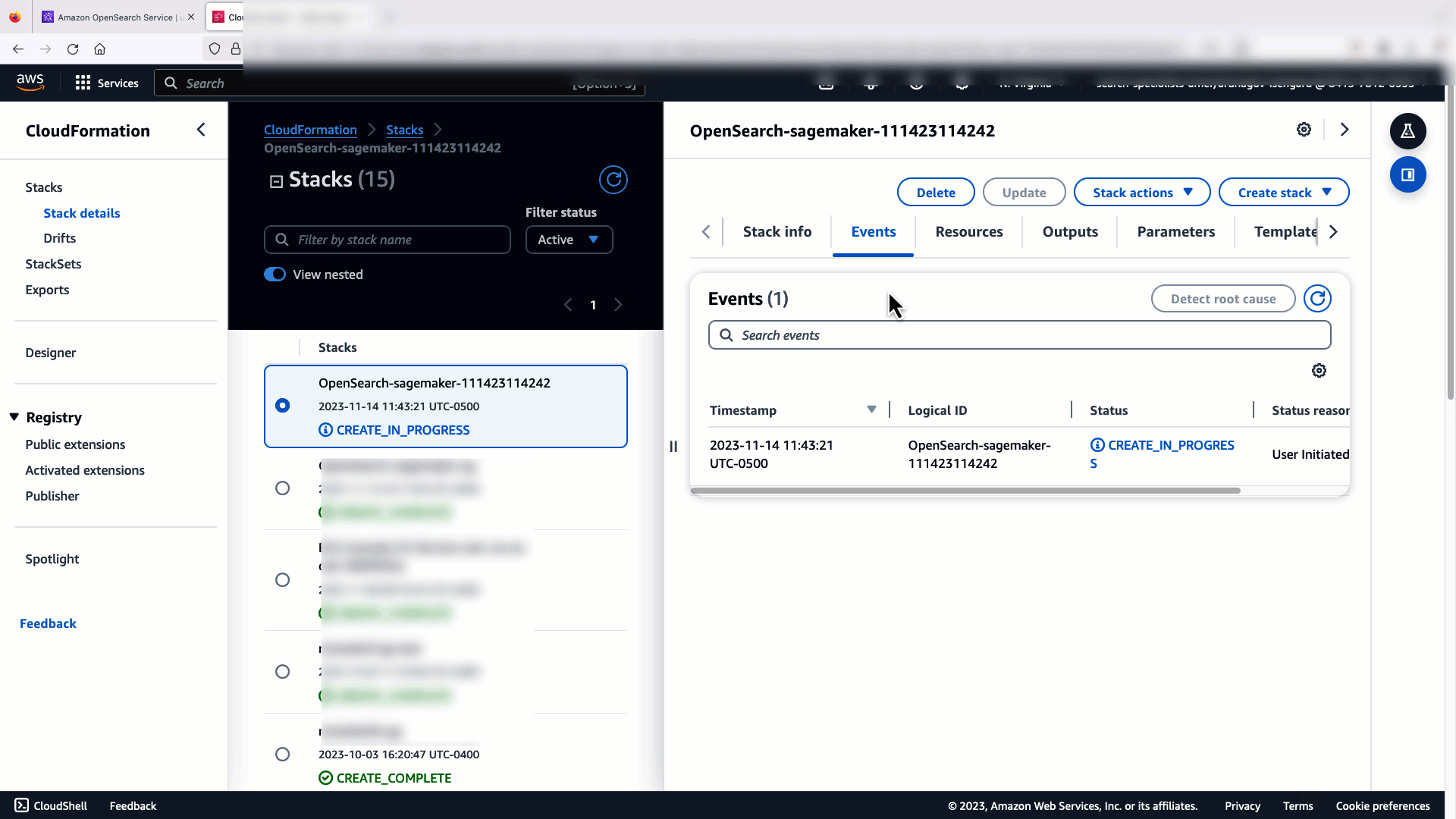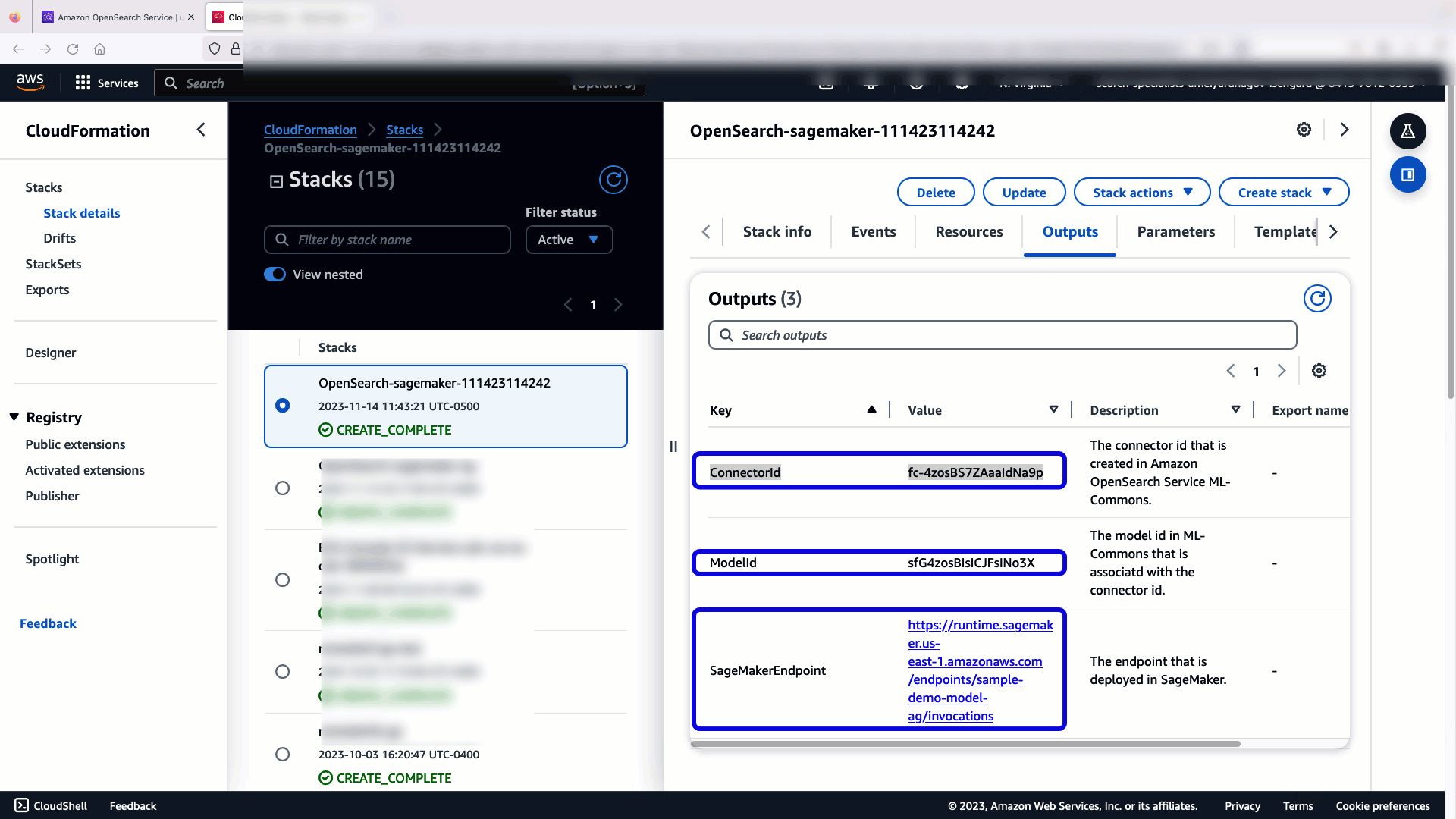
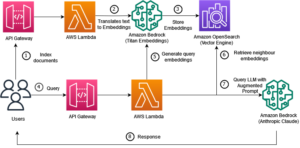
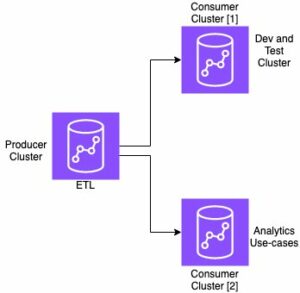
Ketika Anda memilih Buat Stack, Anda diarahkan ke Formasi AWS Cloud menghibur. Templat CloudFormation menerapkan arsitektur yang dirinci dalam diagram berikut.

Tumpukan CloudFormation membuat AWS Lambda aplikasi yang menyebarkan model dari Layanan Penyimpanan Sederhana Amazon (Amazon S3), membuat konektor, dan menghasilkan ID model di output. Anda kemudian dapat menggunakan ID model ini untuk membuat indeks semantik.
Jika model all-MiniLM-L6-v2 default tidak memenuhi tujuan Anda, Anda dapat menerapkan model penyematan teks apa pun pilihan Anda pada host model yang dipilih (SageMaker atau Amazon Bedrock) dengan menyediakan artefak model Anda sebagai objek S3 yang dapat diakses. Alternatifnya, Anda dapat memilih salah satu dari berikut ini model bahasa terlatih dan menyebarkannya ke SageMaker. Untuk petunjuk menyiapkan titik akhir dan model Anda, lihat Tersedia Gambar Amazon SageMaker.
SageMaker adalah layanan terkelola sepenuhnya yang menyatukan serangkaian alat untuk memungkinkan ML berperforma tinggi dan berbiaya rendah untuk kasus penggunaan apa pun, memberikan manfaat utama seperti pemantauan model, hosting tanpa server, dan otomatisasi alur kerja untuk pelatihan dan penerapan berkelanjutan. SageMaker memungkinkan Anda menghosting dan mengelola siklus hidup model penyematan teks, dan menggunakannya untuk mendukung kueri penelusuran semantik di OpenSearch Service. Saat terhubung, SageMaker menghosting model Anda dan Layanan OpenSearch digunakan untuk melakukan kueri berdasarkan hasil inferensi dari SageMaker.
Lihat model yang diterapkan melalui Dasbor OpenSearch
Untuk memverifikasi templat CloudFormation berhasil menerapkan model pada domain OpenSearch Service dan mendapatkan ID model, Anda dapat menggunakan ML Commons REST GET API melalui OpenSearch Dashboards Dev Tools.
GET _plugins REST API sekarang menyediakan API tambahan untuk juga melihat status model. Perintah berikut memungkinkan Anda melihat status model jarak jauh:
Seperti terlihat pada gambar berikut, a DEPLOYED status dalam respons menunjukkan model berhasil diterapkan pada kluster OpenSearch Service.

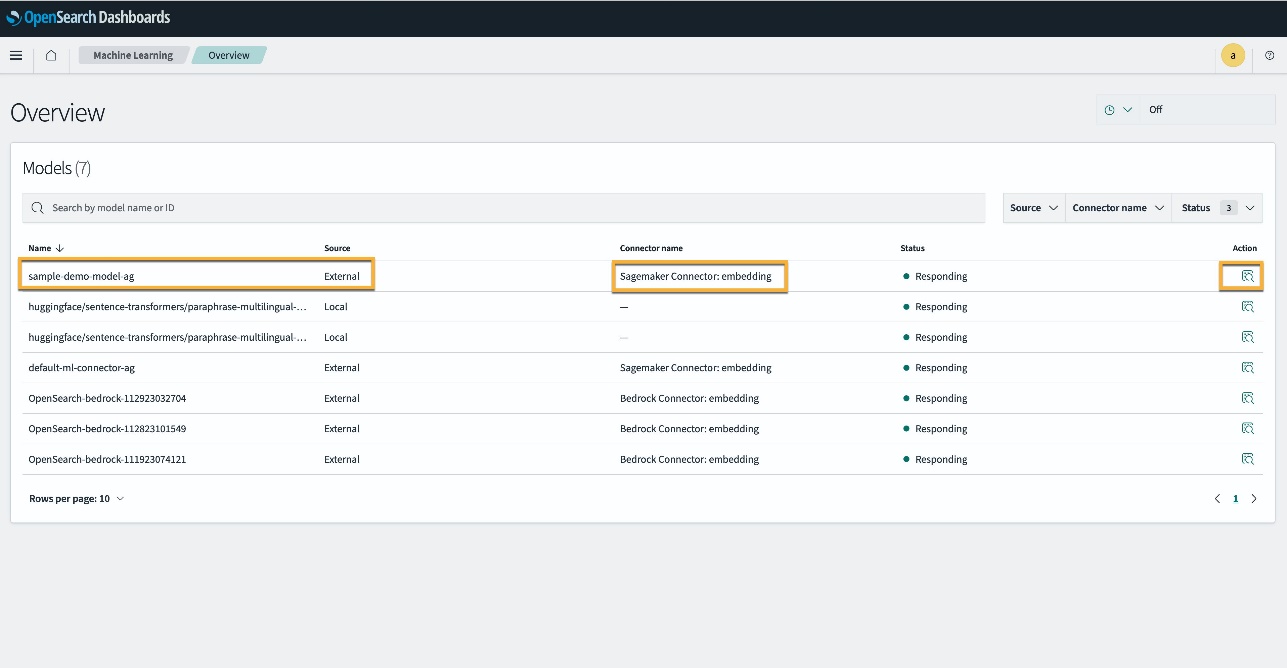
Alternatifnya, Anda dapat melihat model yang diterapkan pada domain OpenSearch Service Anda menggunakan Pembelajaran mesin halaman Dasbor OpenSearch.

Halaman ini mencantumkan informasi model dan status semua model yang disebarkan.

Buat saluran neural menggunakan ID model
Ketika status model ditampilkan sebagai salah satu DEPLOYED di Dev Tools atau hijau dan Menanggapi di Dasbor OpenSearch, Anda dapat menggunakan ID model untuk membangun saluran penyerapan saraf Anda. Alur penyerapan berikut dijalankan di Alat Pengembang Dasbor OpenSearch domain Anda. Pastikan Anda mengganti ID model dengan ID unik yang dihasilkan untuk model yang diterapkan di domain Anda.

Buat indeks pencarian semantik menggunakan saluran saraf sebagai saluran default
Anda kini dapat menentukan pemetaan indeks dengan alur default yang dikonfigurasi untuk menggunakan alur neural baru yang Anda buat pada langkah sebelumnya. Pastikan bidang vektor dideklarasikan sebagai knn_vector dan dimensinya sesuai dengan model yang diterapkan di SageMaker. Jika Anda tetap mempertahankan konfigurasi default untuk menerapkan model all-MiniLM-L6-v2 di SageMaker, pertahankan pengaturan berikut apa adanya dan jalankan perintah di Alat Pengembang.

Serap dokumen sampel untuk menghasilkan vektor
Untuk demo ini, Anda dapat menyerap contoh katalog produk demostore ritel ke yang baru semantic_demostore indeks. Ganti nama pengguna, kata sandi, dan titik akhir domain dengan informasi domain Anda dan serap data mentah ke dalam Layanan OpenSearch:

Validasi indeks semantik_demostore baru
Sekarang setelah Anda menyerap kumpulan data Anda ke domain OpenSearch Service, validasi apakah vektor yang diperlukan dihasilkan menggunakan pencarian sederhana untuk mengambil semua bidang. Validasi jika bidang didefinisikan sebagai knn_vectors memiliki vektor yang diperlukan.

Bandingkan pencarian leksikal dan pencarian semantik yang didukung oleh pencarian saraf menggunakan alat Bandingkan Hasil Pencarian
Grafik Bandingkan alat Hasil Pencarian di Dasbor OpenSearch tersedia untuk beban kerja produksi. Anda dapat menavigasi ke Bandingkan hasil pencarian halaman dan bandingkan hasil kueri antara penelusuran leksikal dan penelusuran saraf yang dikonfigurasi untuk menggunakan ID model yang dihasilkan sebelumnya.

Membersihkan
Anda dapat menghapus sumber daya yang Anda buat dengan mengikuti petunjuk dalam postingan ini dengan menghapus tumpukan CloudFormation. Tindakan ini akan menghapus sumber daya Lambda dan bucket S3 yang berisi model yang disebarkan ke SageMaker. Selesaikan langkah-langkah berikut:
- Di konsol AWS CloudFormation, navigasikan ke halaman detail tumpukan Anda.
- Pilih Delete.

- Pilih Delete untuk mengkonfirmasi.

Anda dapat memantau kemajuan penghapusan tumpukan di konsol AWS CloudFormation.
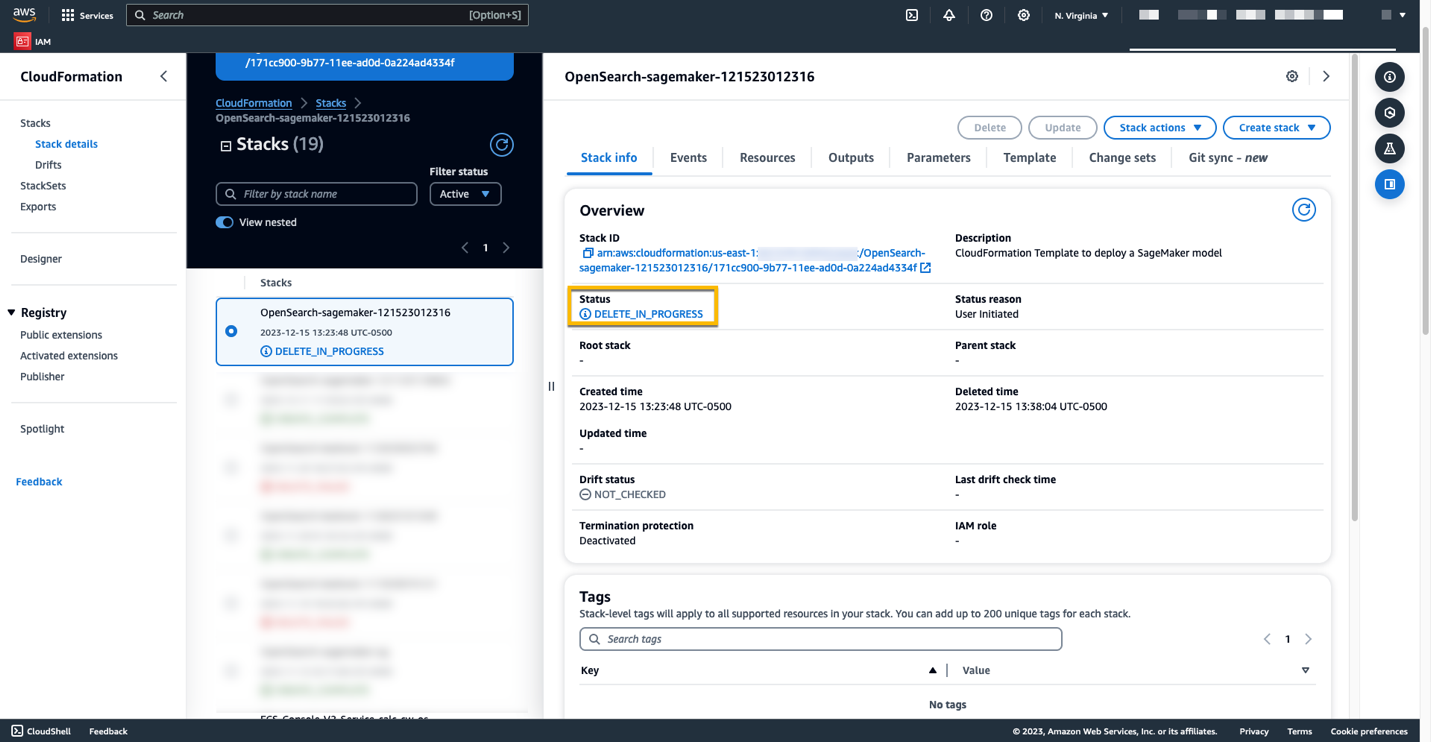
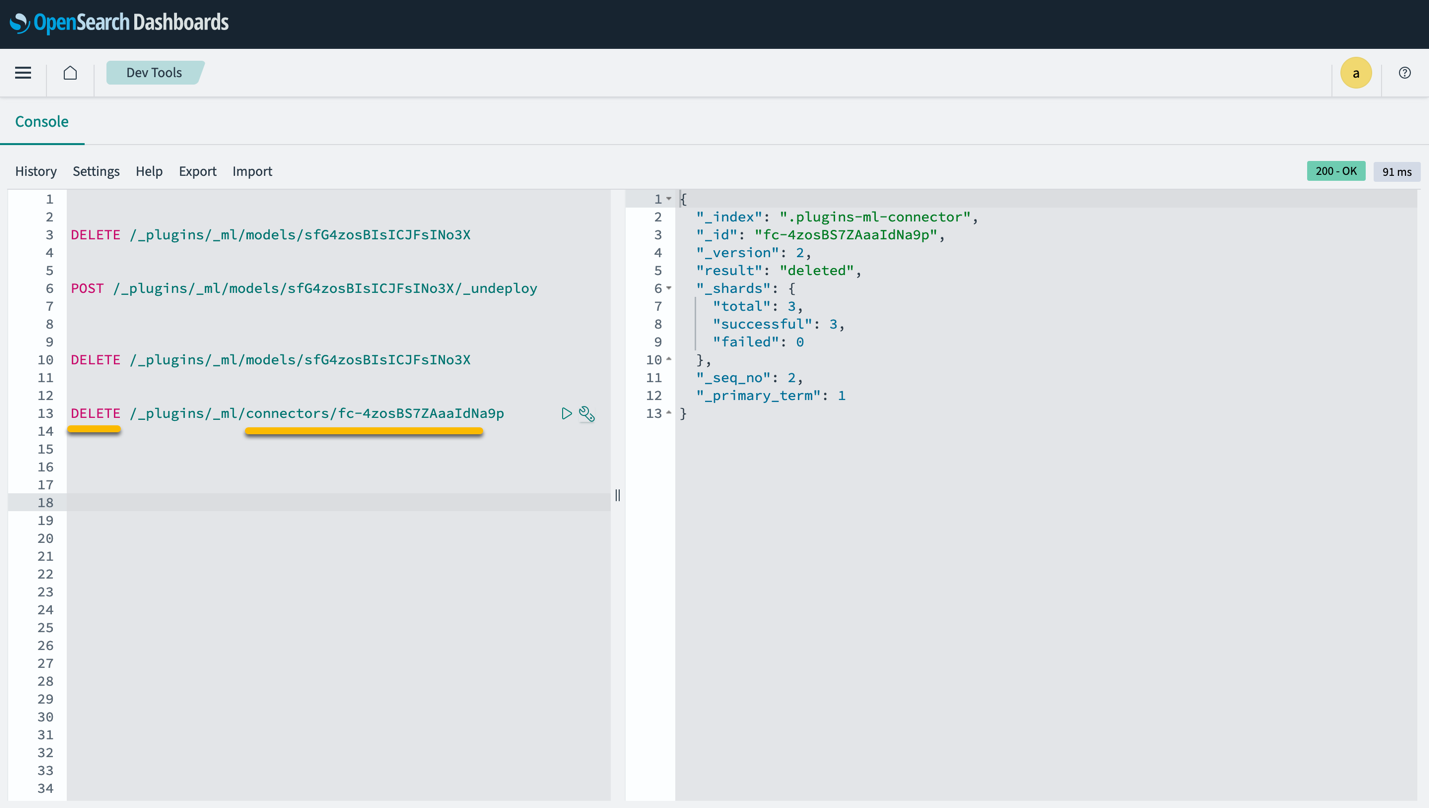
Perhatikan bahwa, menghapus tumpukan CloudFormation tidak menghapus model yang diterapkan pada domain SageMaker dan konektor AI/ML yang dibuat. Hal ini karena model dan konektor ini dapat dikaitkan dengan beberapa indeks dalam domain. Untuk menghapus model dan konektor terkaitnya secara khusus, gunakan API model seperti yang ditunjukkan dalam cuplikan layar berikut.
Pertama, undeploy model dari memori domain OpenSearch Service:

Kemudian Anda dapat menghapus model dari indeks model:

Terakhir, hapus konektor dari indeks konektor:
Kesimpulan
Dalam postingan ini, Anda mempelajari cara menerapkan model di SageMaker, membuat konektor AI/ML menggunakan konsol OpenSearch Service, dan membuat indeks pencarian neural. Kemampuan untuk mengonfigurasi konektor AI/ML di OpenSearch Service menyederhanakan proses hidrasi vektor dengan membuat integrasi ke model eksternal menjadi asli. Anda dapat membuat indeks penelusuran saraf dalam hitungan menit menggunakan saluran penyerapan saraf dan penelusuran saraf yang menggunakan ID model untuk menghasilkan penyematan vektor dengan cepat selama penyerapan dan penelusuran.
Untuk mempelajari lebih lanjut tentang konektor AI/ML ini, lihat Konektor AI Amazon OpenSearch Service untuk layanan AWS, Integrasi templat AWS CloudFormation untuk pencarian semantik, dan Membuat konektor untuk platform ML pihak ketiga.
Tentang Penulis
 Aruna Govindaraju adalah Arsitek Solusi Spesialis Amazon OpenSearch dan telah bekerja dengan banyak mesin pencari komersial dan sumber terbuka. Dia sangat tertarik dengan penelusuran, relevansi, dan pengalaman pengguna. Keahliannya dalam menghubungkan sinyal pengguna akhir dengan perilaku mesin telusur telah membantu banyak pelanggan meningkatkan pengalaman penelusuran mereka.
Aruna Govindaraju adalah Arsitek Solusi Spesialis Amazon OpenSearch dan telah bekerja dengan banyak mesin pencari komersial dan sumber terbuka. Dia sangat tertarik dengan penelusuran, relevansi, dan pengalaman pengguna. Keahliannya dalam menghubungkan sinyal pengguna akhir dengan perilaku mesin telusur telah membantu banyak pelanggan meningkatkan pengalaman penelusuran mereka.
 Dagney Braun adalah Manajer Produk Utama di AWS yang berfokus pada OpenSearch.
Dagney Braun adalah Manajer Produk Utama di AWS yang berfokus pada OpenSearch.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/power-neural-search-with-ai-ml-connectors-in-amazon-opensearch-service/
- :memiliki
- :adalah
- :bukan
- $NAIK
- 1
- 100
- 12
- 15%
- 2020
- 25
- 7
- 8
- 9
- a
- kemampuan
- Tentang Kami
- mengakses
- dapat diakses
- Tambahan
- AI
- AI / ML
- Semua
- memungkinkan
- juga
- alternatif
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- dan
- Apa pun
- api
- Lebah
- Aplikasi
- sesuai
- arsitektur
- ADALAH
- AS
- terkait
- At
- Otomatisasi
- tersedia
- AWS
- Formasi AWS Cloud
- Backend
- berdasarkan
- BE
- karena
- laku
- Manfaat
- antara
- kedua
- Membawa
- luas
- membangun
- Bangunan
- by
- CAN
- kasus
- kasus
- katalog
- pilihan
- Pilih
- terpilih
- Kelompok
- komersial
- Ruang makan besar
- membandingkan
- lengkap
- kompleksitas
- konfigurasi
- dikonfigurasi
- mengkonfigurasi
- Memastikan
- terhubung
- Menghubungkan
- koneksi
- konsul
- mengandung
- terus
- kontinu
- berhubungan
- membuat
- dibuat
- menciptakan
- Sekarang
- adat
- pelanggan
- dasbor
- data
- Default
- menetapkan
- didefinisikan
- mengantarkan
- Demo
- mendemonstrasikan
- menunjukkan
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- menyebarkan
- deskripsi
- terperinci
- rincian
- dev
- Dimensi
- ukuran
- dokumen
- Tidak
- domain
- selama
- setiap
- Terdahulu
- tanpa usaha
- antara
- embedding
- aktif
- Titik akhir
- Mesin
- Mesin
- memastikan
- Eter (ETH)
- contoh
- pengalaman
- keahlian
- luar
- Menghadapi
- memfasilitasi
- Fitur
- Fields
- Menemukan
- Pertama
- terfokus
- berikut
- Untuk
- Kerangka
- dari
- sepenuhnya
- menghasilkan
- dihasilkan
- menghasilkan
- mendapatkan
- gif
- GitHub
- Hijau
- Tumbuh
- membimbing
- Memiliki
- membantu
- dia
- kinerja tinggi
- tuan rumah
- tuan
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- MemelukWajah
- hidrasi
- IAM
- ID
- mengenali
- identitas
- if
- memperbaiki
- in
- indeks
- indeks
- menunjukkan
- informasi
- input
- sebagai gantinya
- instruksi
- mengintegrasikan
- integrasi
- integrasi
- ke
- Pengantar
- IT
- NYA
- jpg
- json
- Menjaga
- kunci
- bahasa
- jalankan
- BELAJAR
- belajar
- pengetahuan
- siklus hidup
- Daftar
- daftar
- murah
- mesin
- Mesin belajar
- membuat
- Membuat
- mengelola
- berhasil
- manajer
- banyak
- peta
- pemetaan
- Memori
- metode
- menit
- ML
- model
- model
- Memantau
- pemantauan
- lebih
- banyak
- beberapa
- harus
- nama
- asli
- Arahkan
- Navigasi
- perlu
- Perlu
- saraf
- New
- sekarang
- obyek
- of
- on
- ONE
- hanya
- Buka
- open source
- or
- Lainnya
- keluaran
- halaman
- pane
- bergairah
- Kata Sandi
- Izin
- pipa saluran
- plato
- Kecerdasan Data Plato
- Data Plato
- Plugin
- Pos
- kekuasaan
- didukung
- sebelumnya
- Utama
- Sebelumnya
- proses
- prosesor
- Produk
- manajer produk
- Produksi
- Kemajuan
- properties
- memberikan
- menyediakan
- menyediakan
- tujuan
- query
- Mentah
- data mentah
- sarankan
- lihat
- terpencil
- menghapus
- menggantikan
- wajib
- Sumber
- tanggapan
- ISTIRAHAT
- Hasil
- eceran
- dipertahankan
- kembali
- Peran
- rute
- Run
- pembuat bijak
- screenshot
- Pencarian
- mesin pencari
- Mesin pencari
- keamanan
- melihat
- memilih
- melayani
- Tanpa Server
- layanan
- Layanan
- set
- pengaturan
- dia
- ditunjukkan
- Pertunjukkan
- sinyal
- Sederhana
- disederhanakan
- menyederhanakan
- sejak
- Solusi
- sumber
- spesialis
- Secara khusus
- tumpukan
- Mulai
- Status
- Langkah
- Tangga
- penyimpanan
- berhasil
- seperti itu
- Didukung
- yakin
- Template
- teks
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- dengan demikian
- Ini
- pihak ketiga
- ini
- Melalui
- untuk
- bersama
- alat
- Pelatihan
- Transformasi
- Terjemahan
- benar
- mengetik
- ui
- unik
- unik
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna Pengalaman
- menggunakan
- MENGESAHKAN
- memeriksa
- versi
- melalui
- Video
- View
- berjalan
- adalah
- we
- jaringan
- layanan web
- ketika
- yang
- akan
- dengan
- dalam
- bekerja
- alur kerja
- otomatisasi alur kerja
- kamu
- Anda
- zephyrnet.dll