Di era informasi saat ini, banyaknya volume data yang disimpan dalam dokumen yang tak terhitung jumlahnya menghadirkan tantangan sekaligus peluang bagi bisnis. Metode pemrosesan dokumen tradisional sering kali kurang efisien dan akurat, sehingga menyisakan ruang untuk inovasi, efisiensi biaya, dan optimalisasi. Pemrosesan dokumen telah mengalami kemajuan yang signifikan dengan munculnya Intelligent Document Processing (IDP). Dengan IDP, bisnis dapat mengubah data tidak terstruktur dari berbagai jenis dokumen menjadi wawasan terstruktur dan dapat ditindaklanjuti, sehingga secara signifikan meningkatkan efisiensi dan mengurangi upaya manual. Namun, potensinya tidak berhenti sampai disitu saja. Dengan mengintegrasikan kecerdasan buatan (AI) generatif ke dalam proses, kami dapat lebih meningkatkan kemampuan IDP. AI Generatif tidak hanya memperkenalkan peningkatan kemampuan dalam pemrosesan dokumen, tetapi juga memperkenalkan kemampuan adaptasi dinamis terhadap perubahan pola data. Postingan ini akan membawa Anda memahami sinergi IDP dan AI generatif, mengungkap bagaimana keduanya mewakili garis depan berikutnya dalam pemrosesan dokumen.
Kami membahas IDP secara mendetail dalam seri Pemrosesan dokumen cerdas dengan layanan AWS AI (bagian 1 dan bagian 2). Dalam postingan ini, kami membahas cara memperluas arsitektur IDP baru atau yang sudah ada dengan model bahasa besar (LLM). Lebih khusus lagi, kami membahas bagaimana kami dapat berintegrasi Teks Amazon dengan LangChain sebagai pemuat dokumen dan Batuan Dasar Amazon untuk mengekstrak data dari dokumen dan menggunakan kemampuan AI generatif dalam berbagai fase IDP.
Amazon Textract adalah layanan pembelajaran mesin (ML) yang secara otomatis mengekstrak teks, tulisan tangan, dan data dari dokumen yang dipindai. Amazon Bedrock adalah layanan terkelola sepenuhnya yang menawarkan pilihan model fondasi (FM) berperforma tinggi melalui API yang mudah digunakan.
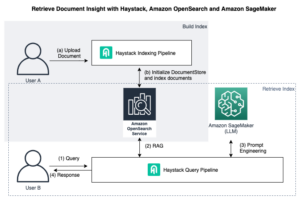
Diagram berikut adalah arsitektur referensi tingkat tinggi yang menjelaskan bagaimana Anda dapat lebih meningkatkan alur kerja IDP dengan model fondasi. Anda dapat menggunakan LLM di satu atau semua fase IDP bergantung pada kasus penggunaan dan hasil yang diinginkan.
Pada bagian berikut, kita mendalami bagaimana Amazon Textract diintegrasikan ke dalam alur kerja AI generatif menggunakan LangChain untuk memproses dokumen untuk setiap tugas spesifik ini. Blok kode yang disediakan di sini telah dipangkas agar singkatnya. Lihat kami Repositori GitHub untuk buku catatan Python terperinci dan panduan langkah demi langkah.
Ekstraksi teks dari dokumen adalah aspek penting dalam pemrosesan dokumen dengan LLM. Anda dapat menggunakan Amazon Textract untuk mengekstrak teks mentah tidak terstruktur dari dokumen dan mempertahankan objek semi-terstruktur atau terstruktur asli seperti pasangan nilai kunci dan tabel yang ada dalam dokumen. Paket dokumen seperti klaim perawatan kesehatan dan asuransi atau hipotek terdiri dari formulir kompleks yang berisi banyak informasi dalam format terstruktur, semi terstruktur, dan tidak terstruktur. Ekstraksi dokumen merupakan langkah penting di sini karena LLM mendapat manfaat dari konten yang kaya untuk menghasilkan tanggapan yang lebih akurat dan relevan, yang sebaliknya dapat berdampak pada kualitas keluaran LLM.
LangChain adalah kerangka kerja sumber terbuka yang kuat untuk berintegrasi dengan LLM. LLM secara umum serbaguna tetapi mungkin kesulitan dengan tugas-tugas spesifik domain yang memerlukan konteks yang lebih dalam dan respons yang berbeda. LangChain memberdayakan pengembang dalam skenario seperti itu untuk membangun agen yang dapat memecah tugas-tugas kompleks menjadi sub-tugas yang lebih kecil. Subtugas kemudian dapat memperkenalkan konteks dan memori ke dalam LLM dengan menghubungkan dan merangkai perintah LLM.
Penawaran LangChain pemuat dokumen yang dapat memuat dan mengubah data dari dokumen. Anda dapat menggunakannya untuk menyusun dokumen ke dalam format pilihan yang dapat diproses oleh LLM. Itu AmazonTekstrakPDFLoader adalah jenis pemuat layanan pemuat dokumen yang menyediakan cara cepat untuk mengotomatiskan pemrosesan dokumen dengan menggunakan Amazon Textract yang dikombinasikan dengan LangChain. Untuk rincian lebih lanjut tentang AmazonTextractPDFLoader, mengacu kepada LangChain dokumentasi. Untuk menggunakan pemuat dokumen Amazon Textract, Anda mulai dengan mengimpornya dari perpustakaan LangChain:
from langchain.document_loaders import AmazonTextractPDFLoaderhttps_loader = AmazonTextractPDFLoader("https://sample-website.com/sample-doc.pdf")
https_document = https_loader.load() s3_loader = AmazonTextractPDFLoader("s3://sample-bucket/sample-doc.pdf")
s3_document = s3_loader.load()Anda juga dapat menyimpan dokumen di Amazon S3 dan merujuknya menggunakan pola URL s3://, seperti yang dijelaskan di Mengakses bucket menggunakan S3://, dan teruskan jalur S3 ini ke pemuat PDF Amazon Textract:
import boto3
textract_client = boto3.client('textract', region_name='us-east-2') file_path = "s3://amazon-textract-public-content/langchain/layout-parser-paper.pdf"
loader = AmazonTextractPDFLoader(file_path, client=textract_client)
documents = loader.load()Dokumen multi-halaman akan berisi beberapa halaman teks, yang kemudian dapat diakses melalui objek dokumen, yang merupakan daftar halaman. Kode berikut menelusuri halaman-halaman di objek dokumen dan mencetak teks dokumen, yang tersedia melalui page_content atribut:
print(len(documents)) for document in documents: print(document.page_content)Amazon Comprehend dan LLM dapat digunakan secara efektif untuk klasifikasi dokumen. Amazon Comprehend adalah layanan pemrosesan bahasa alami (NLP) yang menggunakan ML untuk mengekstrak wawasan dari teks. Amazon Comprehend juga mendukung pelatihan model klasifikasi khusus dengan kesadaran tata letak pada dokumen seperti PDF, Word, dan format gambar. Untuk informasi lebih lanjut tentang penggunaan pengklasifikasi dokumen Amazon Comprehend, lihat Pengklasifikasi dokumen Amazon Comprehend menambahkan dukungan tata letak untuk akurasi yang lebih tinggi.
Ketika dipasangkan dengan LLM, klasifikasi dokumen menjadi pendekatan yang ampuh untuk mengelola dokumen dalam jumlah besar. LLM berguna dalam klasifikasi dokumen karena dapat menganalisis teks, pola, dan elemen kontekstual dalam dokumen menggunakan pemahaman bahasa alami. Anda juga dapat menyempurnakannya untuk kelas dokumen tertentu. Ketika jenis dokumen baru yang diperkenalkan di saluran IDP memerlukan klasifikasi, LLM dapat memproses teks dan mengkategorikan dokumen berdasarkan serangkaian kelas. Berikut ini adalah contoh kode yang menggunakan pemuat dokumen LangChain yang didukung oleh Amazon Textract untuk mengekstrak teks dari dokumen dan menggunakannya untuk mengklasifikasikan dokumen. Kami menggunakan Claude Antropik v2 model melalui Amazon Bedrock untuk melakukan klasifikasi.
Dalam contoh berikut, pertama-tama kami mengekstrak teks dari laporan pemulangan pasien dan menggunakan LLM untuk mengklasifikasikannya berdasarkan daftar tiga jenis dokumen berbeda—DISCHARGE_SUMMARY, RECEIPT, dan PRESCRIPTION. Tangkapan layar berikut menunjukkan laporan kami.
from langchain.document_loaders import AmazonTextractPDFLoader
from langchain.llms import Bedrock
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain loader = AmazonTextractPDFLoader("./samples/document.png")
document = loader.load() template = """ Given a list of classes, classify the document into one of these classes. Skip any preamble text and just give the class name. <classes>DISCHARGE_SUMMARY, RECEIPT, PRESCRIPTION</classes>
<document>{doc_text}<document>
<classification>""" prompt = PromptTemplate(template=template, input_variables=["doc_text"])
bedrock_llm = Bedrock(client=bedrock, model_id="anthropic.claude-v2") llm_chain = LLMChain(prompt=prompt, llm=bedrock_llm)
class_name = llm_chain.run(document[0].page_content) print(f"The provided document is = {class_name}")
Peringkasan melibatkan pemadatan teks atau dokumen tertentu ke dalam versi yang lebih pendek sambil tetap mempertahankan informasi utamanya. Teknik ini bermanfaat untuk pengambilan informasi yang efisien, yang memungkinkan pengguna dengan cepat memahami poin-poin penting dari sebuah dokumen tanpa membaca keseluruhan konten. Meskipun Amazon Textract tidak secara langsung melakukan peringkasan teks, Amazon Textract menyediakan kemampuan dasar untuk mengekstraksi seluruh teks dari dokumen. Teks yang diekstraksi ini berfungsi sebagai masukan ke model LLM kami untuk melakukan tugas peringkasan teks.
Menggunakan laporan pembuangan sampel yang sama, kami menggunakan AmazonTextractPDFLoader untuk mengekstrak teks dari dokumen ini. Seperti sebelumnya, kami menggunakan model Claude v2 melalui Amazon Bedrock dan menginisialisasinya dengan prompt yang berisi instruksi tentang apa yang harus dilakukan dengan teks (dalam hal ini, ringkasan). Terakhir, kami menjalankan rantai LLM dengan meneruskan teks yang diekstrak dari pemuat dokumen. Ini menjalankan tindakan inferensi pada LLM dengan prompt yang berisi instruksi untuk meringkas, dan teks dokumen ditandai dengan Document. Lihat kode berikut:
Kode ini menghasilkan ringkasan laporan ringkasan keluarnya pasien:
Contoh sebelumnya menggunakan dokumen satu halaman untuk melakukan peringkasan. Namun, Anda mungkin akan berurusan dengan dokumen yang berisi banyak halaman yang memerlukan ringkasan. Cara umum untuk melakukan peringkasan pada beberapa halaman adalah dengan terlebih dahulu membuat ringkasan pada potongan teks yang lebih kecil, lalu menggabungkan ringkasan yang lebih kecil tersebut untuk mendapatkan ringkasan akhir dokumen. Perhatikan bahwa metode ini memerlukan beberapa panggilan ke LLM. Logikanya dapat dibuat dengan mudah; namun, LangChain menyediakan rantai ringkasan bawaan yang dapat meringkas teks berukuran besar (dari dokumen multi-halaman). Peringkasan dapat dilakukan melalui map_reduce atau dengan stuff opsi, yang tersedia sebagai opsi untuk mengelola beberapa panggilan ke LLM. Dalam contoh berikut, kami menggunakan map_reduce untuk meringkas dokumen multi-halaman. Gambar berikut mengilustrasikan alur kerja kami.
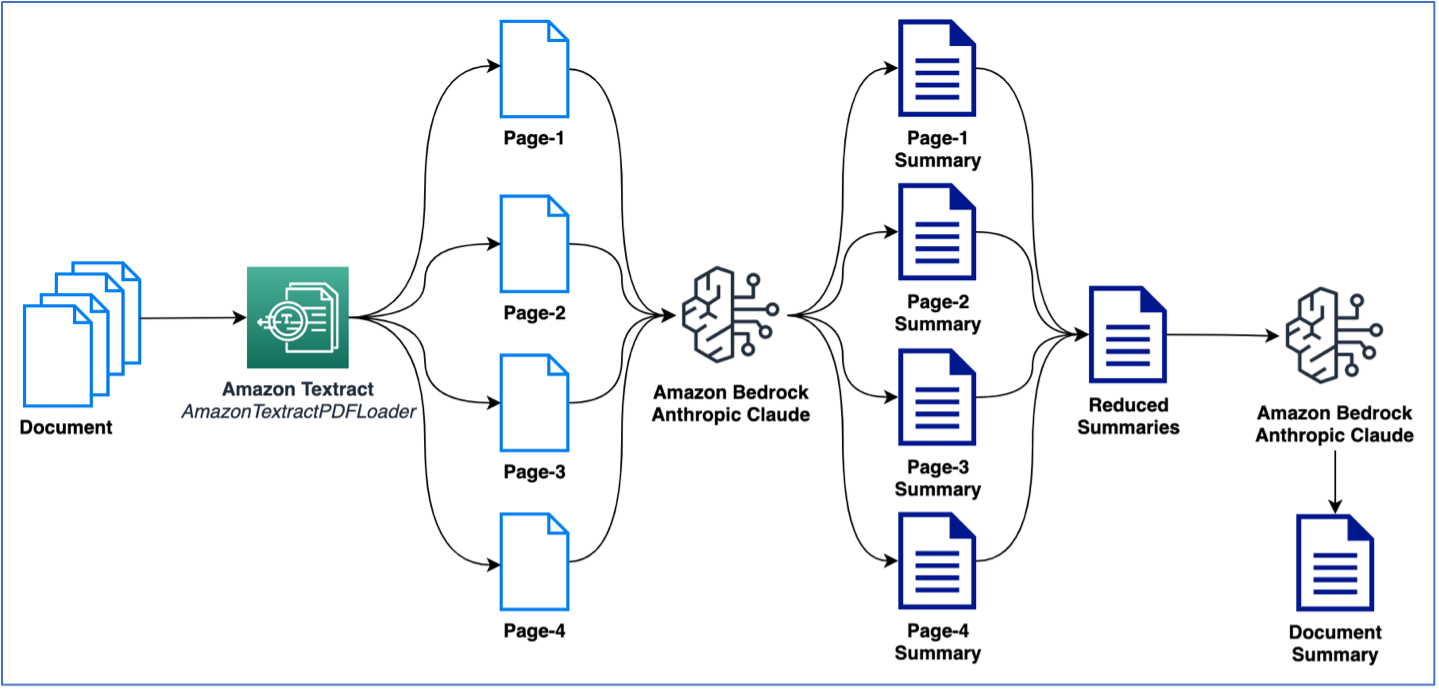
Pertama mari kita mulai dengan mengekstrak dokumen dan melihat jumlah total token per halaman dan jumlah total halaman:
Selanjutnya, kami menggunakan bawaan LangChain load_summarize_chain untuk meringkas seluruh dokumen:
from langchain.chains.summarize import load_summarize_chain summary_chain = load_summarize_chain(llm=bedrock_llm, chain_type='map_reduce')
output = summary_chain.run(document)
print(output.strip())Standardisasi dan Tanya Jawab
Pada bagian ini, kita membahas tugas standardisasi dan tanya jawab.
Standardisasi
Standardisasi keluaran adalah tugas pembuatan teks di mana LLM digunakan untuk menyediakan format teks keluaran yang konsisten. Tugas ini sangat berguna untuk otomatisasi ekstraksi entitas kunci yang memerlukan keluaran agar selaras dengan format yang diinginkan. Misalnya, kita dapat mengikuti praktik terbaik rekayasa cepat untuk menyempurnakan LLM guna memformat tanggal ke dalam format MM/DD/YYYY, yang mungkin kompatibel dengan kolom TANGGAL database. Blok kode berikut menunjukkan contoh bagaimana hal ini dilakukan menggunakan LLM dan rekayasa cepat. Kami tidak hanya menstandarkan format keluaran untuk nilai tanggal, kami juga meminta model untuk menghasilkan keluaran akhir dalam format JSON sehingga mudah digunakan dalam aplikasi hilir kami. Kita gunakan Bahasa Ekspresi LangChain (LCEL) untuk menyatukan dua tindakan. Tindakan pertama meminta LLM untuk menghasilkan keluaran format JSON hanya dengan tanggal dari dokumen. Tindakan kedua mengambil keluaran JSON dan menstandarkan format tanggal. Perhatikan bahwa tindakan dua langkah ini juga dapat dilakukan dalam satu langkah dengan rekayasa cepat yang tepat, seperti yang akan kita lihat dalam normalisasi dan pembuatan templat.
Output dari contoh kode sebelumnya adalah struktur JSON dengan tanggal 07/09/2020 dan 08/09/2020, yang berformat DD/MM/YYYY dan masing-masing merupakan tanggal masuk dan keluar pasien dari rumah sakit, menurut ke laporan ringkasan pemulangan.
Tanya Jawab dengan Retrieval Augmented Generation
LLM diketahui menyimpan informasi faktual, sering disebut sebagai pengetahuan dunia atau pandangan dunia. Jika disetel dengan baik, mereka dapat menghasilkan hasil yang canggih. Namun, terdapat kendala mengenai seberapa efektif LLM dapat mengakses dan memanipulasi pengetahuan ini. Akibatnya, dalam tugas yang sangat bergantung pada pengetahuan spesifik, performanya mungkin tidak optimal untuk kasus penggunaan tertentu. Misalnya, dalam skenario Tanya Jawab, penting bagi model untuk benar-benar mematuhi konteks yang diberikan dalam dokumen tanpa hanya mengandalkan pengetahuan dunianya. Menyimpang dari hal ini dapat menyebabkan kesalahan penafsiran, ketidakakuratan, atau bahkan tanggapan yang salah. Metode yang paling umum digunakan untuk mengatasi masalah ini dikenal sebagai Pengambilan Augmented Generation (LAP). Pendekatan ini mensinergikan kekuatan model pengambilan dan model bahasa, sehingga meningkatkan presisi dan kualitas respons yang dihasilkan.
LLM juga dapat menerapkan batasan token karena keterbatasan memori dan keterbatasan perangkat keras yang dijalankannya. Untuk mengatasi masalah ini, teknik seperti chunking digunakan untuk membagi dokumen besar menjadi bagian-bagian kecil yang sesuai dengan batas token LLM. Di sisi lain, embeddings digunakan di NLP terutama untuk menangkap makna semantik kata dan hubungannya dengan kata lain dalam ruang berdimensi tinggi. Penyematan ini mengubah kata menjadi vektor, memungkinkan model memproses dan memahami data tekstual secara efisien. Dengan memahami nuansa semantik antara kata dan frasa, penyematan memungkinkan LLM menghasilkan keluaran yang koheren dan relevan secara kontekstual. Perhatikan istilah-istilah penting berikut:
- Memotong – Proses ini memecah sejumlah besar teks dari dokumen menjadi potongan teks yang lebih kecil dan bermakna.
- Penyematan – Ini adalah transformasi vektor berdimensi tetap dari setiap potongan yang mempertahankan informasi semantik dari potongan tersebut. Penyematan ini kemudian dimuat ke dalam database vektor.
- Basis data vektor – Ini adalah database penyematan kata atau vektor yang mewakili konteks kata. Ini bertindak sebagai sumber pengetahuan yang membantu tugas-tugas NLP dalam alur pemrosesan dokumen. Manfaat database vektor di sini adalah memungkinkan hanya konteks yang diperlukan untuk diberikan ke LLM selama pembuatan teks, seperti yang kami jelaskan di bagian berikut.
RAG menggunakan kekuatan penyematan untuk memahami dan mengambil segmen dokumen yang relevan selama fase pengambilan. Dengan melakukan hal ini, RAG dapat bekerja dalam batasan token LLM, memastikan informasi yang paling relevan dipilih untuk dihasilkan, sehingga menghasilkan keluaran yang lebih akurat dan relevan secara kontekstual.
Diagram berikut mengilustrasikan integrasi teknik-teknik ini untuk menyusun masukan bagi LLM, meningkatkan pemahaman kontekstualnya dan memungkinkan respons dalam konteks yang lebih relevan. Salah satu pendekatan melibatkan pencarian kesamaan, memanfaatkan database vektor dan pengelompokan. Basis data vektor menyimpan penyematan yang mewakili informasi semantik, dan pengelompokan membagi teks menjadi beberapa bagian yang dapat dikelola. Dengan menggunakan konteks pencarian kesamaan ini, LLM dapat menjalankan tugas seperti menjawab pertanyaan dan operasi spesifik domain seperti klasifikasi dan pengayaan.

Untuk postingan ini, kami menggunakan pendekatan berbasis RAG untuk melakukan Tanya Jawab dalam konteks dengan dokumen. Dalam contoh kode berikut, kami mengekstrak teks dari dokumen dan kemudian membagi dokumen menjadi potongan teks yang lebih kecil. Pemotongan diperlukan karena kami mungkin memiliki dokumen multi-halaman yang besar dan LLM kami mungkin memiliki batasan token. Potongan-potongan ini kemudian dimuat ke dalam database vektor untuk melakukan pencarian kesamaan pada langkah selanjutnya. Dalam contoh berikut, kami menggunakan model Amazon Titan Embed Text v1, yang melakukan penyematan vektor pada potongan dokumen:
Kode ini menciptakan konteks yang relevan untuk LLM menggunakan potongan teks yang dikembalikan oleh tindakan pencarian kesamaan dari database vektor. Untuk contoh ini, kami menggunakan sumber terbuka Toko vektor FAISS sebagai contoh database vektor untuk menyimpan penyematan vektor dari setiap potongan teks. Kami kemudian mendefinisikan database vektor sebagai a Retriever LangChain, yang diteruskan ke RetrievalQA rantai. Ini secara internal menjalankan kueri pencarian kesamaan pada database vektor yang mengembalikan n teratas (di mana n=3 dalam contoh kita) potongan teks yang relevan dengan pertanyaan. Terakhir, rantai LLM dijalankan dengan konteks yang relevan (sekelompok potongan teks yang relevan) dan pertanyaan yang harus dijawab oleh LLM. Untuk panduan kode langkah demi langkah tentang Tanya Jawab dengan RAG, lihat buku catatan Python di GitHub.
Sebagai alternatif FAISS, Anda juga bisa menggunakan Kemampuan basis data vektor Amazon OpenSearch Service, Amazon Relational Database Service (Amazon RDS) untuk PostgreSQL pada pengatur terkenal. Pengatur ini menawarkan bantuan hukum kepada traderapabila trader berselisih dengan broker yang terdaftar dengan mereka. vektor pg ekstensi sebagai basis data vektor, atau Basis Data Chroma sumber terbuka.
Tanya Jawab dengan data tabel
Data tabular dalam dokumen dapat menjadi tantangan bagi LLM untuk diproses karena kompleksitas strukturalnya. Amazon Textract dapat ditambah dengan LLM karena memungkinkan ekstraksi tabel dari dokumen dalam format elemen bertumpuk seperti halaman, tabel, dan sel. Melakukan Tanya Jawab dengan data tabular merupakan proses multi-langkah, dan dapat dicapai melalui menanyakan diri sendiri. Berikut gambaran langkah-langkahnya:
- Ekstrak tabel dari dokumen menggunakan Amazon Textract. Dengan Amazon Textract, struktur tabel (baris, kolom, header) dapat diekstraksi dari dokumen.
- Simpan data tabular ke dalam database vektor bersama dengan informasi metadata, seperti nama header dan deskripsi setiap header.
- Gunakan perintah untuk membuat kueri terstruktur, menggunakan LLM, untuk mendapatkan data dari tabel.
- Gunakan kueri untuk mengekstrak data tabel yang relevan dari database vektor.
Misalnya, dalam laporan bank, jika diberi pertanyaan “Apa saja transaksi yang memiliki simpanan lebih dari $1000”, LLM akan menyelesaikan langkah-langkah berikut:
- Buat kueri, seperti
“Query: transactions” , “filter: greater than (Deposit$)”. - Ubah kueri menjadi kueri terstruktur.
- Terapkan kueri terstruktur ke database vektor tempat data tabel kita disimpan.
Untuk panduan langkah demi langkah contoh kode Tanya Jawab dengan tabel, lihat buku catatan Python di GitHub.
Templating dan normalisasi
Di bagian ini, kita melihat cara menggunakan teknik rekayasa cepat dan mekanisme bawaan LangChain untuk menghasilkan keluaran dengan ekstraksi dari dokumen dalam skema tertentu. Kami juga melakukan beberapa standarisasi pada data yang diekstraksi, menggunakan teknik yang telah dibahas sebelumnya. Kita mulai dengan menentukan template untuk keluaran yang kita inginkan. Ini akan berfungsi sebagai skema dan merangkum detail setiap entitas yang ingin kita ekstrak dari teks dokumen.
Perhatikan bahwa untuk masing-masing entitas, kami menggunakan deskripsi untuk menjelaskan entitas tersebut untuk membantu membantu LLM dalam mengekstraksi nilai dari teks dokumen. Dalam contoh kode berikut, kami menggunakan templat ini untuk membuat prompt untuk LLM bersama dengan teks yang diekstraksi dari dokumen menggunakan AmazonTextractPDFLoader dan selanjutnya melakukan inferensi dengan model:
Seperti yang Anda lihat, {keys} bagian dari prompt adalah kunci dari template kita, dan {details} adalah kunci beserta deskripsinya. Dalam hal ini, kami tidak meminta model secara eksplisit dengan format keluaran selain yang ditentukan dalam instruksi untuk menghasilkan keluaran dalam format JSON. Ini sebagian besar berhasil; namun, karena keluaran dari LLM adalah pembuatan teks non-deterministik, kami ingin menentukan formatnya secara eksplisit sebagai bagian dari instruksi di prompt. Untuk mengatasinya, kita bisa menggunakan LangChain pengurai keluaran terstruktur modul untuk memanfaatkan rekayasa prompt otomatis yang membantu mengubah template kami menjadi prompt instruksi format. Kami menggunakan template yang ditentukan sebelumnya untuk menghasilkan prompt instruksi format sebagai berikut:
Kami kemudian menggunakan variabel ini dalam prompt asli kami sebagai instruksi untuk LLM sehingga variabel tersebut mengekstrak dan memformat output dalam skema yang diinginkan dengan membuat sedikit modifikasi pada prompt kami:
Sejauh ini, kami hanya mengekstrak data dari dokumen dalam skema yang diinginkan. Namun, kita masih perlu melakukan beberapa standarisasi. Misalnya, kami ingin tanggal masuk pasien dan tanggal pulang pasien diekstraksi dalam format DD/MM/YYYY. Dalam hal ini, kami menambah description kunci dengan instruksi pemformatan:
Lihat buku catatan Python di GitHub untuk panduan dan penjelasan langkah demi langkah lengkap.
Periksa ejaan dan koreksi
LLM telah menunjukkan kemampuan luar biasa dalam memahami dan menghasilkan teks mirip manusia. Salah satu penerapan LLM yang jarang dibahas namun sangat berguna adalah potensinya dalam pemeriksaan tata bahasa dan koreksi kalimat dalam dokumen. Tidak seperti pemeriksa tata bahasa tradisional yang mengandalkan seperangkat aturan yang telah ditentukan sebelumnya, LLM menggunakan pola yang telah mereka identifikasi dari sejumlah besar data teks untuk menentukan bahasa mana yang termasuk bahasa yang benar atau lancar. Artinya, mereka dapat mendeteksi nuansa, konteks, dan seluk-beluk yang mungkin terlewatkan oleh sistem berbasis aturan.
Bayangkan teks yang diambil dari ringkasan keluarnya pasien yang berbunyi “Pasien Jon Doe, yang dirawat karena pneumonia berat, telah menunjukkan kemajuan yang signifikan dan dapat dipulangkan dengan aman. Tindak lanjut dijadwalkan untuk minggu depan.” Pemeriksa ejaan tradisional mungkin mengenali “admittd”, “pneumonia”, “improvement”, dan “nex” sebagai kesalahan. Namun, konteks kesalahan ini dapat menyebabkan kesalahan lebih lanjut atau saran umum. Sebuah LLM, yang dilengkapi dengan pelatihan ekstensif, mungkin menyarankan: “Pasien John Doe, yang dirawat karena pneumonia parah, telah menunjukkan kemajuan yang signifikan dan dapat dipulangkan dengan aman. Tindak lanjut dijadwalkan minggu depan.”
Berikut ini adalah contoh dokumen tulisan tangan yang buruk dengan teks yang sama seperti yang dijelaskan sebelumnya.

Kami mengekstrak dokumen dengan pemuat dokumen Amazon Textract dan kemudian menginstruksikan LLM, melalui rekayasa cepat, untuk memperbaiki teks yang diekstraksi guna memperbaiki kesalahan ejaan dan atau tata bahasa:
Output dari kode sebelumnya menunjukkan teks asli yang diekstrak oleh pemuat dokumen diikuti dengan teks yang dikoreksi yang dihasilkan oleh LLM:
Ingatlah bahwa sekuat apa pun LLM, penting untuk melihat saran mereka hanya sebagai saran saja. Meskipun mereka mampu menangkap seluk-beluk bahasa dengan sangat baik, namun mereka tidak sempurna. Beberapa saran mungkin mengubah makna atau nada yang dimaksudkan dari teks asli. Oleh karena itu, penting bagi pengulas manusia untuk menggunakan koreksi yang dihasilkan LLM sebagai panduan, bukan yang mutlak. Kolaborasi intuisi manusia dengan kemampuan LLM menjanjikan masa depan di mana komunikasi tertulis kita tidak hanya bebas dari kesalahan, namun juga lebih kaya dan bernuansa.
Kesimpulan
AI Generatif mengubah cara Anda memproses dokumen dengan IDP untuk mendapatkan wawasan. Di pos Meningkatkan pemrosesan dokumen cerdas AWS dengan AI generatif, kami membahas berbagai tahapan pipeline dan bagaimana pelanggan AWS Ricoh meningkatkan pipeline IDP mereka dengan LLM. Dalam postingan ini, kami membahas berbagai mekanisme untuk menambah alur kerja IDP dengan LLM melalui Amazon Bedrock, Amazon Textract, dan kerangka kerja LangChain yang populer. Anda dapat memulai pemuat dokumen Amazon Textract baru dengan LangChain hari ini menggunakan contoh buku catatan yang tersedia di kami Repositori GitHub. Untuk informasi selengkapnya tentang bekerja dengan AI generatif di AWS, lihat Mengumumkan Alat Baru untuk Membangun dengan AI Generatif di AWS.
Tentang Penulis
 Sonali Sahu memimpin pemrosesan dokumen cerdas dengan tim layanan AI/ML di AWS. Dia adalah seorang penulis, pemimpin pemikiran, dan ahli teknologi yang bersemangat. Area fokus utamanya adalah AI dan ML, dan dia sering berbicara di konferensi dan pertemuan AI dan ML di seluruh dunia. Dia memiliki pengalaman yang luas dan mendalam dalam teknologi dan industri teknologi, dengan keahlian industri di bidang kesehatan, sektor keuangan, dan asuransi.
Sonali Sahu memimpin pemrosesan dokumen cerdas dengan tim layanan AI/ML di AWS. Dia adalah seorang penulis, pemimpin pemikiran, dan ahli teknologi yang bersemangat. Area fokus utamanya adalah AI dan ML, dan dia sering berbicara di konferensi dan pertemuan AI dan ML di seluruh dunia. Dia memiliki pengalaman yang luas dan mendalam dalam teknologi dan industri teknologi, dengan keahlian industri di bidang kesehatan, sektor keuangan, dan asuransi.
 Anjan Biswas adalah Arsitek Solusi Layanan AI Senior dengan fokus pada AI/ML dan Analisis Data. Anjan adalah bagian dari tim layanan AI di seluruh dunia dan bekerja dengan pelanggan untuk membantu mereka memahami dan mengembangkan solusi untuk masalah bisnis dengan AI dan ML. Anjan memiliki lebih dari 14 tahun pengalaman bekerja dengan rantai pasokan global, manufaktur, dan organisasi ritel, dan secara aktif membantu pelanggan memulai dan meningkatkan layanan AI AWS.
Anjan Biswas adalah Arsitek Solusi Layanan AI Senior dengan fokus pada AI/ML dan Analisis Data. Anjan adalah bagian dari tim layanan AI di seluruh dunia dan bekerja dengan pelanggan untuk membantu mereka memahami dan mengembangkan solusi untuk masalah bisnis dengan AI dan ML. Anjan memiliki lebih dari 14 tahun pengalaman bekerja dengan rantai pasokan global, manufaktur, dan organisasi ritel, dan secara aktif membantu pelanggan memulai dan meningkatkan layanan AI AWS.
 Chinmayee Rane adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia tertarik pada matematika terapan dan pembelajaran mesin. Dia berfokus pada perancangan pemrosesan dokumen cerdas dan solusi AI generatif untuk pelanggan AWS. Di luar pekerjaan, dia menikmati tarian salsa dan bachata.
Chinmayee Rane adalah Arsitek Solusi Spesialis AI/ML di Amazon Web Services. Dia tertarik pada matematika terapan dan pembelajaran mesin. Dia berfokus pada perancangan pemrosesan dokumen cerdas dan solusi AI generatif untuk pelanggan AWS. Di luar pekerjaan, dia menikmati tarian salsa dan bachata.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/intelligent-document-processing-with-amazon-textract-amazon-bedrock-and-langchain/
- :memiliki
- :adalah
- :bukan
- :Di mana
- .nex
- $1000
- $NAIK
- 1
- 10
- 100
- 11
- 12
- 13
- 14
- 15%
- 16
- 22
- 23
- 33
- 35%
- 7
- 9
- a
- kemampuan
- Tentang Kami
- Mutlak
- mengakses
- diakses
- Menurut
- ketepatan
- tepat
- dicapai
- di seluruh
- Tindakan
- tindakan
- aktif
- kegiatan
- tindakan
- Ad
- alamat
- Menambahkan
- mengikuti
- mengakui
- mengaku
- kemajuan
- Keuntungan
- kedatangan
- usia
- agen
- AI
- Layanan AI
- AI / ML
- selaras
- Semua
- Membiarkan
- memungkinkan
- sepanjang
- juga
- alternatif
- Meskipun
- Amazon
- Amazon Comprehend
- Amazon RDS
- Teks Amazon
- Amazon Web Services
- jumlah
- an
- analisis
- menganalisa
- dan
- menjawab
- Antropik
- Antibiotik
- Apa pun
- Lebah
- aplikasi
- terapan
- janji
- pendekatan
- arsitektur
- ADALAH
- DAERAH
- sekitar
- Seni
- buatan
- kecerdasan buatan
- Kecerdasan buatan (AI)
- AS
- penampilan
- membantu
- Asisten
- At
- menambah
- ditambah
- penulis
- mengotomatisasikan
- Otomatis
- secara otomatis
- Otomatisasi
- tersedia
- kesadaran
- AWS
- Pelanggan AWS
- Bank
- BE
- karena
- menjadi
- menjadi
- sebelum
- bermanfaat
- manfaat
- TERBAIK
- Praktik Terbaik
- antara
- Memblokir
- Blok
- kedua
- luasnya
- Istirahat
- istirahat
- membangun
- Bangunan
- built-in
- bisnis
- bisnis
- tapi
- by
- Panggilan
- CAN
- Bisa Dapatkan
- kemampuan
- menangkap
- kasus
- kasus
- Sel
- tertentu
- rantai
- rantai
- menantang
- menantang
- perubahan
- Perubahan
- mengubah
- Cek
- pilihan
- klaim
- kelas
- kelas-kelas
- klasifikasi
- Klasifikasi
- kode
- KOHEREN
- kolaborasi
- Kolom
- Kolom
- kombinasi
- menggabungkan
- datang
- Umum
- umum
- Komunikasi
- cocok
- lengkap
- kompleks
- kompleksitas
- memahami
- ringkas
- konferensi
- Menghubungkan
- konsisten
- terdiri
- kendala
- membangun
- mengandung
- berisi
- mengandung
- Konten
- konteks
- kontekstual
- mengubah
- Core
- benar
- dikoreksi
- Koreksi
- bisa
- kerajinan
- dibuat
- menciptakan
- sangat penting
- adat
- pelanggan
- pelanggan
- Tarian
- data
- Data Analytics
- Basis Data
- database
- Tanggal
- Tanggal
- transaksi
- mendalam
- lebih dalam
- menetapkan
- didefinisikan
- mendefinisikan
- menunjukkan
- Tergantung
- deposito
- kedalaman
- dijelaskan
- deskripsi
- merancang
- diinginkan
- rinci
- terperinci
- rincian
- menemukan
- Menentukan
- mengembangkan
- pengembang
- Diet
- berbeda
- langsung
- membahas
- dibahas
- menyelam
- membagi
- membagi
- do
- Dokter
- dokumen
- dokumentasi
- dokumen
- DOE
- Tidak
- melakukan
- don
- dilakukan
- Dont
- turun
- secara dramatis
- dua
- selama
- dinamis
- e
- setiap
- Terdahulu
- mudah
- mudah digunakan
- efektif
- efisiensi
- efisien
- efisien
- upaya
- antara
- elemen
- menanamkan
- dipekerjakan
- memberdayakan
- aktif
- memungkinkan
- memungkinkan
- akhir
- Teknik
- mempertinggi
- ditingkatkan
- meningkatkan
- memastikan
- memastikan
- Seluruh
- entitas
- entitas
- lengkap
- kesalahan
- penting
- Eter (ETH)
- Bahkan
- contoh
- Kecuali
- pengecualian
- ada
- pengalaman
- keahlian
- Menjelaskan
- menjelaskan
- Menjelaskan
- penjelasan
- secara eksplisit
- ekspresi
- memperpanjang
- perpanjangan
- luas
- ekstrak
- ekstraksi
- Ekstrak
- Nyata
- Jatuh
- palsu
- jauh
- kelelahan
- Fields
- Angka
- terakhir
- Akhirnya
- keuangan
- Sektor keuangan
- Pertama
- cocok
- Fokus
- berfokus
- mengikuti
- diikuti
- berikut
- berikut
- Untuk
- format
- bentuk
- ditemukan
- Prinsip Dasar
- Kerangka
- Gratis
- sering
- dari
- perbatasan
- penuh
- sepenuhnya
- lebih lanjut
- masa depan
- Umum
- menghasilkan
- dihasilkan
- menghasilkan
- menghasilkan
- generasi
- generatif
- AI generatif
- mendapatkan
- Memberikan
- diberikan
- Aksi
- Tatabahasa
- memahami
- lebih besar
- Kelompok
- membimbing
- tangan
- menangani
- terjadi
- Kejadian
- Perangkat keras
- Memiliki
- header
- kesehatan
- berat
- membantu
- bermanfaat
- membantu
- membantu
- dia
- di sini
- tingkat tinggi
- berkinerja tinggi
- lebih tinggi
- memegang
- Rumah sakit
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- HTTPS
- manusia
- i
- ID
- diidentifikasi
- if
- menggambarkan
- gambar
- sangat
- Dampak
- mengimpor
- penting
- pengimporan
- memaksakan
- perbaikan
- in
- Termasuk
- indeks
- industri
- informasi
- Informasi usia
- Innovation
- memasukkan
- wawasan
- contoh
- instruksi
- asuransi
- mengintegrasikan
- terpadu
- Mengintegrasikan
- integrasi
- Intelijen
- Cerdas
- Pemrosesan dokumen cerdas
- dimaksudkan
- internal
- ke
- seluk-beluk
- memperkenalkan
- diperkenalkan
- Memperkenalkan
- intuisi
- melibatkan
- IT
- NYA
- jackson
- John
- JOHN DOE
- jon
- jpg
- json
- hanya
- kunci
- kunci-kunci
- Tahu
- pengetahuan
- dikenal
- bahasa
- besar
- tata ruang
- memimpin
- pemimpin
- terkemuka
- pengetahuan
- meninggalkan
- Perpustakaan
- 'like'
- Mungkin
- keterbatasan
- batas
- Daftar
- memuat
- pemuat
- logika
- melihat
- Lot
- mesin
- Mesin belajar
- Membuat
- mengelola
- berhasil
- pelaksana
- panduan
- pabrik
- ditandai
- matematika
- Mungkin..
- me
- makna
- berarti
- cara
- mekanisme
- mekanisme
- Meetups
- Memori
- meta
- Metadata
- metode
- metode
- mungkin
- keberatan
- kehilangan
- kesalahan
- ML
- model
- model
- modul
- lebih
- Mortgages
- paling
- beberapa
- nama
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Pemahaman Bahasa Alamiah
- perlu
- Perlu
- dibutuhkan
- kebutuhan
- New
- berikutnya
- minggu depan
- nLP
- mencatat
- buku catatan
- laptop
- sekarang
- nuansa
- jumlah
- obyek
- objek
- of
- Penawaran
- sering
- on
- ONE
- hanya
- open source
- Operasi
- Kesempatan
- optimal
- Opsi
- or
- organisasi
- asli
- Lainnya
- jika tidak
- kami
- di luar
- Hasil
- keluaran
- output
- di luar
- lebih
- ikhtisar
- paket
- halaman
- halaman
- Sakit
- dipasangkan
- pasang
- bagian
- khususnya
- lulus
- Lulus
- Lewat
- bergairah
- path
- pasien
- pola
- pola
- untuk
- melakukan
- prestasi
- dilakukan
- melakukan
- melakukan
- tahap
- phd
- frase
- pipa saluran
- rencana
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- pneumonia
- poin
- Populer
- mungkin
- Pos
- potensi
- kekuasaan
- didukung
- kuat
- praktek
- tepat
- Ketelitian
- disukai
- menyajikan
- sebelumnya
- terutama
- Mencetak
- cetakan
- Masalah
- masalah
- proses
- diproses
- pengolahan
- menghasilkan
- menjanjikan
- tepat
- memberikan
- disediakan
- pemberi
- menyediakan
- Ular sanca
- Q & A
- kualitas
- pertanyaan
- Cepat
- segera
- Mentah
- Bacaan
- mengenali
- mengurangi
- lihat
- referensi
- disebut
- Hubungan
- relevan
- mengandalkan
- mengandalkan
- luar biasa
- melaporkan
- mewakili
- mewakili
- wajib
- membutuhkan
- masing-masing
- tanggapan
- pembatasan
- mengakibatkan
- dihasilkan
- Hasil
- eceran
- menahan
- penahan
- Pengembalian
- Kaya
- Kamar
- aturan
- Run
- berjalan
- s
- aman
- sama
- mengatakan
- Skala
- skenario
- dijadwalkan
- Pencarian
- Kedua
- Bagian
- bagian
- sektor
- melihat
- segmen
- terpilih
- senior
- putusan pengadilan
- Seri
- melayani
- melayani
- layanan
- Layanan
- set
- parah
- dia
- Pendek
- harus
- ditunjukkan
- Pertunjukkan
- penting
- tunggal
- kecil
- lebih kecil
- potongan
- So
- semata-mata
- Solusi
- MEMECAHKAN
- beberapa
- sumber
- Space
- Bicara
- spesialis
- tertentu
- Secara khusus
- ditentukan
- ejaan
- membagi
- magang
- standardisasi
- awal
- mulai
- state-of-the-art
- Pernyataan
- Langkah
- Tangga
- Masih
- menyimpan
- tersimpan
- toko
- kekuatan
- Tali
- struktural
- struktur
- tersusun
- Perjuangan
- selanjutnya
- Kemudian
- seperti itu
- menyarankan
- meringkaskan
- RINGKASAN
- menyediakan
- supply chain
- mendukung
- Mendukung
- sinergi
- sistem
- T
- tabel
- Mengambil
- Dibutuhkan
- tugas
- tugas
- tim
- teknik
- teknik
- teknologis
- Teknologi
- Template
- istilah
- teks
- pembuatan teks
- tekstual
- dari
- bahwa
- Grafik
- Dunia
- mereka
- Mereka
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- ini
- pikir
- tiga
- Melalui
- titan
- untuk
- hari ini
- hari ini
- bersama
- token
- Token
- NADA
- alat
- puncak
- Total
- tradisional
- Pelatihan
- Transaksi
- Mengubah
- transformasi
- benar
- mencoba
- dua
- mengetik
- jenis
- memahami
- pemahaman
- tidak seperti
- pembukaan
- URL
- menggunakan
- gunakan case
- bekas
- Pengguna
- kegunaan
- menggunakan
- dimanfaatkan
- Memanfaatkan
- v1
- nilai
- Nilai - Nilai
- variabel
- berbagai
- Luas
- serba guna
- versi
- melalui
- View
- volume
- walkthrough
- ingin
- adalah
- Cara..
- we
- jaringan
- layanan web
- minggu
- BAIK
- Apa
- ketika
- yang
- sementara
- SIAPA
- akan
- dengan
- dalam
- tanpa
- disaksikan
- Word
- kata
- Kerja
- alur kerja
- Alur kerja
- kerja
- bekerja
- dunia
- akan
- tertulis
- X
- tahun
- kamu
- zephyrnet.dll