Hari ini, kami dengan gembira mengumumkan ketersediaan inferensi Llama 2 dan dukungan penyesuaian Pelatihan AWS dan Inferensi AWS contoh dalam Mulai Lompatan Amazon SageMaker. Menggunakan instans berbasis AWS Trainium dan Inferentia, melalui SageMaker, dapat membantu pengguna menurunkan biaya penyesuaian hingga 50%, dan menurunkan biaya penerapan sebesar 4.7x, sekaligus menurunkan latensi per token. Llama 2 adalah model bahasa teks generatif auto-regresif yang menggunakan arsitektur transformator yang dioptimalkan. Sebagai model yang tersedia untuk umum, Llama 2 dirancang untuk banyak tugas NLP seperti klasifikasi teks, analisis sentimen, terjemahan bahasa, pemodelan bahasa, pembuatan teks, dan sistem dialog. Menyempurnakan dan menerapkan LLM, seperti Llama 2, dapat menjadi mahal atau menantang untuk memenuhi kinerja waktu nyata guna memberikan pengalaman pelanggan yang baik. Trainium dan AWS Inferentia, diaktifkan oleh Neuron AWS kit pengembangan perangkat lunak (SDK), menawarkan opsi performa tinggi dan hemat biaya untuk pelatihan dan inferensi model Llama 2.
Dalam postingan ini, kami mendemonstrasikan cara menerapkan dan menyempurnakan Llama 2 pada instans Trainium dan AWS Inferentia di SageMaker JumpStart.
Ikhtisar solusi
Di blog ini, kita akan membahas skenario berikut:
- Terapkan Llama 2 pada instans AWS Inferentia di keduanya Studio Amazon SageMaker UI, dengan pengalaman penerapan sekali klik, dan SageMaker Python SDK.
- Sempurnakan Llama 2 pada instans Trainium di UI SageMaker Studio dan SageMaker Python SDK.
- Bandingkan performa model Llama 2 yang telah disempurnakan dengan model yang telah dilatih sebelumnya untuk menunjukkan efektivitas fine-tuning.
Untuk mendapatkan pengalaman langsung, lihat Buku catatan contoh GitHub.
Terapkan Llama 2 pada instans AWS Inferentia menggunakan SageMaker Studio UI dan Python SDK
Di bagian ini, kami mendemonstrasikan cara menerapkan Llama 2 pada instans AWS Inferentia menggunakan UI SageMaker Studio untuk penerapan sekali klik dan SDK Python.
Temukan model Llama 2 di SageMaker Studio UI
SageMaker JumpStart menyediakan akses ke domain publik dan kepemilikan model pondasi. Model fondasi diterapkan dan dikelola dari penyedia pihak ketiga dan milik sendiri. Oleh karena itu, mereka dirilis di bawah lisensi berbeda yang ditentukan oleh sumber model. Pastikan untuk meninjau lisensi untuk model pondasi apa pun yang Anda gunakan. Anda bertanggung jawab untuk meninjau dan mematuhi persyaratan lisensi apa pun yang berlaku dan memastikan persyaratan tersebut dapat diterima untuk kasus penggunaan Anda sebelum mengunduh atau menggunakan konten.
Anda dapat mengakses model fondasi Llama 2 melalui SageMaker JumpStart di UI SageMaker Studio dan SageMaker Python SDK. Di bagian ini, kita akan membahas cara menemukan model di SageMaker Studio.
SageMaker Studio adalah lingkungan pengembangan terintegrasi (IDE) yang menyediakan antarmuka visual berbasis web tunggal tempat Anda dapat mengakses alat yang dibuat khusus untuk melakukan semua langkah pengembangan pembelajaran mesin (ML), mulai dari menyiapkan data hingga membangun, melatih, dan menerapkan ML Anda model. Untuk detail selengkapnya tentang cara memulai dan menyiapkan SageMaker Studio, lihat Studio Amazon SageMaker.
Setelah Anda berada di SageMaker Studio, Anda dapat mengakses SageMaker JumpStart, yang berisi model terlatih, notebook, dan solusi bawaan, di bawah Solusi bawaan dan otomatis. Untuk informasi lebih rinci tentang cara mengakses model kepemilikan, lihat Gunakan model fondasi kepemilikan dari Amazon SageMaker JumpStart di Amazon SageMaker Studio.
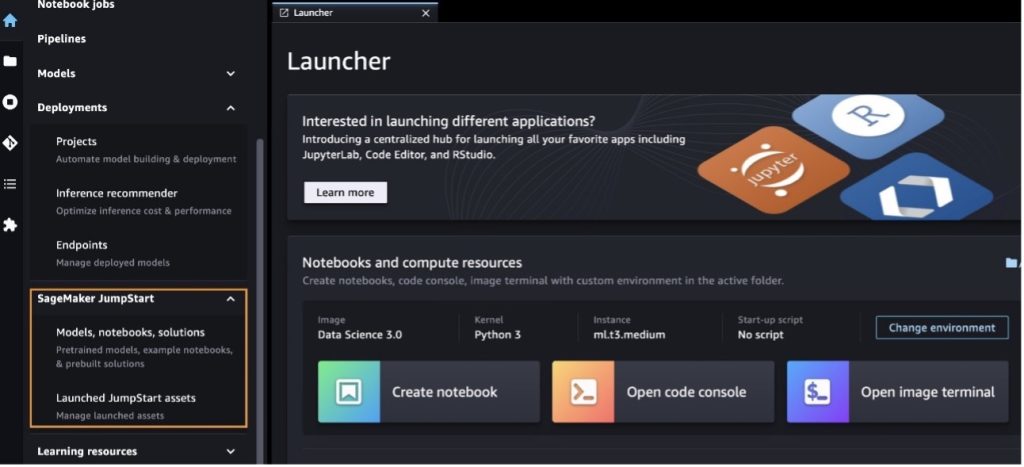
Dari halaman arahan SageMaker JumpStart, Anda dapat menelusuri solusi, model, buku catatan, dan sumber daya lainnya.
Jika Anda tidak melihat model Llama 2, perbarui versi SageMaker Studio Anda dengan mematikan dan memulai ulang. Untuk informasi lebih lanjut tentang pembaruan versi, lihat Matikan dan Perbarui Aplikasi Studio Classic.

Anda juga dapat menemukan varian model lainnya dengan memilih Jelajahi Semua Model Pembuatan Teks atau mencari llama or neuron di kotak pencarian. Anda akan dapat melihat model Llama 2 Neuron di halaman ini.
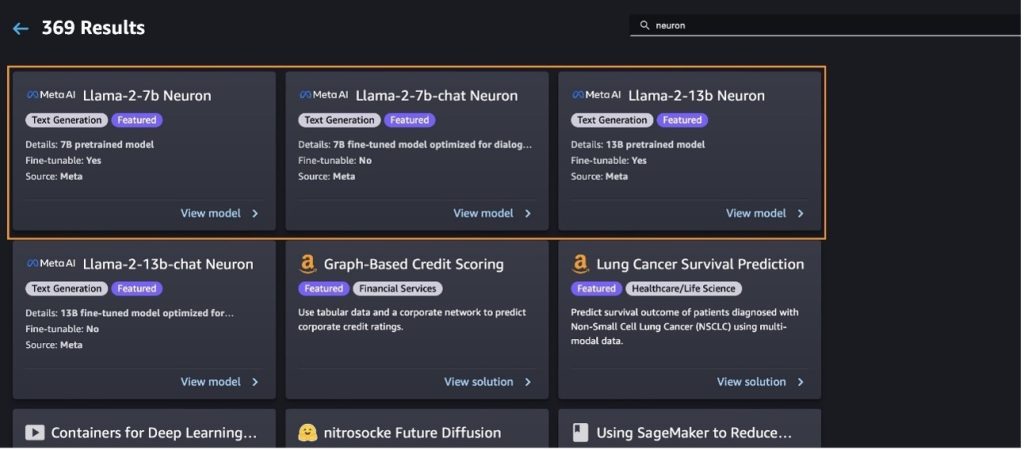
Terapkan model Llama-2-13b dengan SageMaker Jumpstart
Anda dapat memilih kartu model untuk melihat detail tentang model seperti lisensi, data yang digunakan untuk melatih, dan cara menggunakannya. Anda juga dapat menemukan dua tombol, Menyebarkan dan Buka buku catatan, yang membantu Anda menggunakan model menggunakan contoh tanpa kode ini.
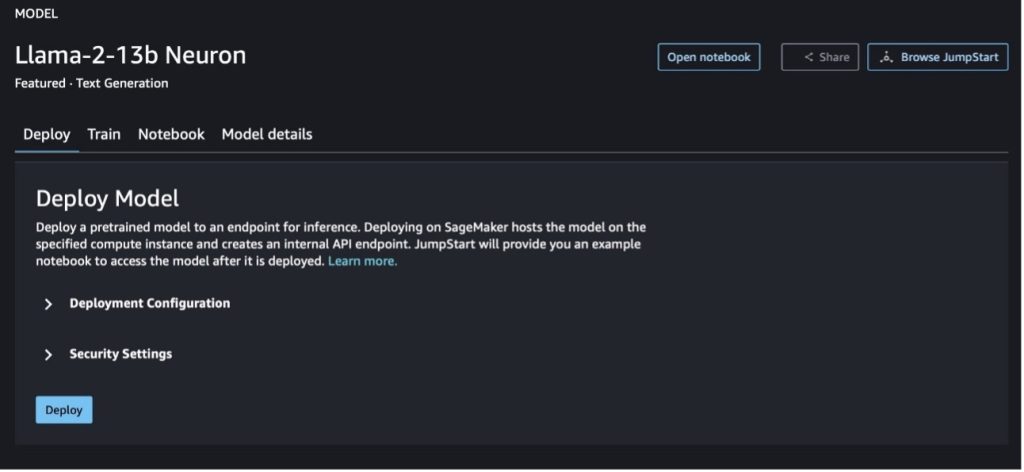
Saat Anda memilih salah satu tombol, pop-up akan menampilkan Perjanjian Lisensi Pengguna Akhir dan Kebijakan Penggunaan yang Dapat Diterima (AUP) untuk Anda setujui.
Setelah Anda menyetujui kebijakan tersebut, Anda dapat menyebarkan titik akhir model dan menggunakannya melalui langkah-langkah di bagian berikutnya.
Terapkan model Llama 2 Neuron melalui Python SDK
Ketika Anda memilih Menyebarkan dan menyetujui persyaratannya, penerapan model akan dimulai. Alternatifnya, Anda dapat menyebarkan melalui contoh buku catatan dengan memilih Buka buku catatan. Contoh notebook memberikan panduan menyeluruh tentang cara menyebarkan model untuk inferensi dan membersihkan sumber daya.
Untuk menerapkan atau menyempurnakan model pada instans Trainium atau AWS Inferentia, Anda harus memanggil PyTorch Neuron (obor-neuronx) untuk mengkompilasi model menjadi grafik khusus Neuron, yang akan mengoptimalkannya untuk NeuronCores Inferentia. Pengguna dapat menginstruksikan kompiler untuk mengoptimalkan latensi terendah atau throughput tertinggi, bergantung pada tujuan aplikasi. Di JumpStart, kami melakukan pra-kompilasi grafik Neuron untuk berbagai konfigurasi, untuk memungkinkan pengguna mengambil langkah-langkah kompilasi, memungkinkan penyesuaian dan penerapan model yang lebih cepat.
Perhatikan bahwa grafik Neuron yang telah dikompilasi sebelumnya dibuat berdasarkan versi spesifik dari versi Neuron Compiler.
Ada dua cara untuk menerapkan LIama 2 pada instans berbasis AWS Inferentia. Metode pertama menggunakan konfigurasi bawaan, dan memungkinkan Anda menerapkan model hanya dalam dua baris kode. Yang kedua, Anda memiliki kontrol lebih besar atas konfigurasi. Mari kita mulai dengan metode pertama, dengan konfigurasi yang telah dibuat sebelumnya, dan menggunakan Model Neuron Llama 2 13B yang telah dilatih sebelumnya, sebagai contoh. Kode berikut menunjukkan cara menyebarkan Llama 13B hanya dengan dua baris:
Untuk melakukan inferensi pada model ini, Anda perlu menentukan argumennya accept_eula menjadi True sebagai bagian dari model.deploy() panggilan. Jika argumen ini benar, berarti Anda telah membaca dan menerima EULA model tersebut. EULA dapat ditemukan dalam deskripsi kartu model atau dari situs meta.
Tipe instans default untuk Llama 2 13B adalah ml.inf2.8xlarge. Anda juga dapat mencoba ID model lain yang didukung:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(model obrolan)meta-textgenerationneuron-llama-2-13b-f(model obrolan)
Alternatifnya, jika Anda ingin memiliki kontrol lebih besar atas konfigurasi penerapan, seperti panjang konteks, derajat paralel tensor, dan ukuran batch bergulir maksimum, Anda dapat memodifikasinya melalui variabel lingkungan, seperti yang ditunjukkan di bagian ini. Deep Learning Container (DLC) yang mendasari penerapannya adalah DLC NeuronX Inferensi Model Besar (LMI).. Variabel lingkungannya adalah sebagai berikut:
- OPTION_N_POSITIONS – Jumlah maksimum token input dan output. Misalnya, jika Anda mengkompilasi model dengan
OPTION_N_POSITIONSsebagai 512, maka Anda dapat menggunakan token input 128 (ukuran prompt input) dengan token output maksimum 384 (total token input dan output harus 512). Untuk token keluaran maksimum, nilai apa pun di bawah 384 boleh saja, tetapi Anda tidak dapat melampauinya (misalnya, masukan 256 dan keluaran 512). - OPTION_TENSOR_PARALLEL_DEGREE – Jumlah NeuronCores untuk memuat model di instans AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – Ukuran batch maksimum untuk permintaan bersamaan.
- OPTION_DTYPE – Jenis tanggal untuk memuat model.
Kompilasi grafik Neuron bergantung pada panjang konteks (OPTION_N_POSITIONS), derajat paralel tensor (OPTION_TENSOR_PARALLEL_DEGREE), ukuran tumpukan maksimum (OPTION_MAX_ROLLING_BATCH_SIZE), dan tipe data (OPTION_DTYPE) untuk memuat model. SageMaker JumpStart telah mengkompilasi grafik Neuron untuk berbagai konfigurasi parameter sebelumnya guna menghindari kompilasi runtime. Konfigurasi grafik yang telah dikompilasi tercantum dalam tabel berikut. Selama variabel lingkungan termasuk dalam salah satu kategori berikut, kompilasi grafik Neuron akan dilewati.
| Obrolan LIama-2 7B dan LIama-2 7B | ||||
| Jenis instance | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| Obrolan LIama-2 13B dan LIama-2 13B | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Berikut ini adalah contoh penerapan Llama 2 13B dan pengaturan semua konfigurasi yang tersedia.
Sekarang kita telah menerapkan model Llama-2-13b, kita dapat menjalankan inferensi dengannya dengan memanggil titik akhir. Cuplikan kode berikut menunjukkan penggunaan parameter inferensi yang didukung untuk mengontrol pembuatan teks:
- panjang maksimal – Model menghasilkan teks hingga panjang output (yang mencakup panjang konteks input) tercapai
max_length. Jika ditentukan, itu harus berupa bilangan bulat positif. - max_new_tokens – Model menghasilkan teks hingga panjang keluaran (tidak termasuk panjang konteks masukan) tercapai
max_new_tokens. Jika ditentukan, itu harus berupa bilangan bulat positif. - nomor_balok – Ini menunjukkan jumlah sinar yang digunakan dalam pencarian serakah. Jika ditentukan, maka harus berupa bilangan bulat yang lebih besar dari atau sama dengan
num_return_sequences. - no_repeat_ngram_size – Model memastikan bahwa urutan kata-kata
no_repeat_ngram_sizetidak diulang dalam urutan output. Jika ditentukan, itu harus bilangan bulat positif lebih besar dari 1. - suhu – Ini mengontrol keacakan dalam keluaran. Suhu yang lebih tinggi menghasilkan urutan keluaran dengan kata-kata dengan probabilitas rendah; suhu yang lebih rendah menghasilkan urutan keluaran dengan kata-kata dengan probabilitas tinggi. Jika
temperaturesama dengan 0, itu menghasilkan decoding serakah. Jika ditentukan, itu harus pelampung positif. - awal_berhenti - Jika
True, pembuatan teks selesai ketika semua hipotesis balok mencapai akhir token kalimat. Jika ditentukan, itu harus Boolean. - lakukan_sampel - Jika
True, model mengambil sampel kata berikutnya sesuai kemungkinannya. Jika ditentukan, itu harus Boolean. - teratas_k – Dalam setiap langkah pembuatan teks, model hanya mengambil sampel dari
top_kkata-kata yang paling mungkin. Jika ditentukan, itu harus berupa bilangan bulat positif. - atas_p – Dalam setiap langkah pembuatan teks, model mengambil sampel dari kumpulan kata sekecil mungkin dengan probabilitas kumulatif sebesar
top_p. Jika ditentukan, itu harus berupa float antara 0–1. - berhenti – Jika ditentukan, itu harus berupa daftar string. Pembuatan teks berhenti jika salah satu dari string tertentu dihasilkan.
Kode berikut menunjukkan sebuah contoh:
Keluaran:
Untuk informasi lebih lanjut tentang parameter payload, lihat parameter rinci.
Anda juga dapat menjelajahi implementasi parameter di buku catatan untuk menambahkan lebih banyak informasi tentang tautan buku catatan.
Sempurnakan model Llama 2 pada instans Trainium menggunakan SageMaker Studio UI dan SageMaker Python SDK
Model dasar AI generatif telah menjadi fokus utama dalam ML dan AI, namun generalisasinya yang luas mungkin gagal dalam domain tertentu seperti layanan kesehatan atau keuangan, yang melibatkan kumpulan data unik. Keterbatasan ini menyoroti perlunya menyempurnakan model AI generatif ini dengan data spesifik domain untuk meningkatkan kinerjanya di bidang khusus tersebut.
Sekarang kita telah menerapkan versi model Llama 2 yang telah dilatih sebelumnya, mari kita lihat bagaimana kita dapat menyempurnakannya ke data spesifik domain untuk meningkatkan akurasi, meningkatkan model dalam hal penyelesaian yang cepat, dan mengadaptasi model ke kasus penggunaan dan data bisnis spesifik Anda. Anda dapat menyempurnakan model menggunakan SageMaker Studio UI atau SageMaker Python SDK. Kami membahas kedua metode di bagian ini.
Sempurnakan model Neuron Llama-2-13b dengan SageMaker Studio
Di SageMaker Studio, navigasikan ke model Neuron Llama-2-13b. Di Menyebarkan tab, Anda dapat menunjuk ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) yang berisi kumpulan data pelatihan dan validasi untuk penyesuaian. Selain itu, Anda dapat mengonfigurasi konfigurasi penerapan, hyperparameter, dan pengaturan keamanan untuk penyesuaian. Lalu pilih Pelatihan VE untuk memulai tugas pelatihan pada instans SageMaker ML.

Untuk menggunakan model Llama 2, Anda harus menyetujui EULA dan AUP. Itu akan muncul kapan pun Anda memilih Pelatihan VE. Memilih Saya telah membaca dan menerima EULA dan AUP untuk memulai pekerjaan penyesuaian.
Anda dapat melihat status tugas pelatihan Anda untuk model yang telah disesuaikan di bawah konsol SageMaker dengan memilih Pekerjaan pelatihan di panel navigasi.
Anda dapat menyempurnakan model Neuron Llama 2 menggunakan contoh tanpa kode ini, atau menyempurnakannya melalui Python SDK, seperti yang ditunjukkan di bagian berikutnya.
Sempurnakan model Neuron Llama-2-13b melalui SageMaker Python SDK
Anda dapat menyempurnakan kumpulan data dengan format adaptasi domain atau penyempurnaan berbasis instruksi format. Berikut ini adalah petunjuk bagaimana data pelatihan harus diformat sebelum dikirim ke penyesuaian:
- Memasukkan - A
traindirektori yang berisi file berformat baris JSON (.jsonl) atau teks (.txt).- Untuk file baris JSON (.jsonl), setiap baris adalah objek JSON terpisah. Setiap objek JSON harus disusun sebagai pasangan nilai kunci, di mana kuncinya seharusnya berada
text, dan nilainya adalah isi dari satu contoh pelatihan. - Jumlah file di bawah direktori kereta harus sama dengan 1.
- Untuk file baris JSON (.jsonl), setiap baris adalah objek JSON terpisah. Setiap objek JSON harus disusun sebagai pasangan nilai kunci, di mana kuncinya seharusnya berada
- Keluaran – Model terlatih yang dapat diterapkan untuk inferensi.
Dalam contoh ini, kami menggunakan subset dari Kumpulan data Dolly dalam format penyetelan instruksi. Kumpulan data Dolly berisi sekitar 15,000 catatan mengikuti instruksi untuk berbagai kategori, seperti menjawab pertanyaan, meringkas, dan mengekstraksi informasi. Ini tersedia di bawah lisensi Apache 2.0. Kami menggunakan information_extraction contoh untuk penyesuaian.
- Muat kumpulan data Dolly dan bagi menjadi
train(untuk menyempurnakan) dantest(untuk evaluasi):
- Gunakan templat cepat untuk memproses data terlebih dahulu dalam format instruksi untuk tugas pelatihan:
- Periksa hyperparameter dan timpa untuk kasus penggunaan Anda sendiri:
- Sempurnakan model dan mulai tugas pelatihan SageMaker. Skrip penyempurnaan didasarkan pada neuronx-nemo-megatron repositori, yang merupakan versi paket yang dimodifikasi nemo dan puncak yang telah diadaptasi untuk digunakan dengan instans Neuron dan EC2 Trn1. Itu neuronx-nemo-megatron repositori memiliki paralelisme 3D (data, tensor, dan pipeline) untuk memungkinkan Anda menyempurnakan skala LLM. Instans Trainium yang didukung adalah ml.trn1.32xlarge dan ml.trn1n.32xlarge.
- Terakhir, terapkan model yang telah disempurnakan di titik akhir SageMaker:
Bandingkan respons antara model Llama 2 Neuron yang telah dilatih sebelumnya dan yang telah disempurnakan
Kini setelah kami menerapkan versi model Llama-2-13b yang telah dilatih sebelumnya dan menyempurnakannya, kami dapat melihat beberapa perbandingan performa penyelesaian cepat dari kedua model, seperti yang ditunjukkan dalam tabel berikut. Kami juga menawarkan contoh untuk menyempurnakan Llama 2 pada kumpulan data pengarsipan SEC dalam format .txt. Untuk detailnya, lihat Buku catatan contoh GitHub.
| Barang | Masukan | Kebenaran dasar | Respons dari model yang tidak disempurnakan | Respons dari model yang disempurnakan |
| 1 | Di bawah ini adalah instruksi yang menjelaskan tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.nn### Petunjuk:nEkstrak universitas tempat Moret belajar dan tahun kelulusannya untuk masing-masing universitas, dan masukkan ke dalam daftar poin.nn### Masukan:nMoret lahir pada tahun 1953 di Vevey Swiss , dan menyelesaikan studi sarjananya di École Polytechnique Fédérale de Lausanne (EPFL), lulus pada tahun 1975. Ia melanjutkan studi pascasarjana di University of Tennessee, mendapatkan gelar Ph.D. pada tahun 1980. Dia kemudian bergabung dengan fakultas di Universitas New Mexico, di mana dia tinggal sampai tahun 2006, ketika dia pindah ke EPFL. Dia pensiun dari EPFL pada bulan Desember 2016. Pada tahun 1996, Moret mendirikan ACM Journal of Experimental Algorithmics, dan dia tetap menjadi pemimpin redaksi jurnal tersebut hingga tahun 2003. Pada tahun 2001, Moret mendirikan Workshop in Algorithms for Bioinformatics (WABI) dan tetap di Komite Pengarah konferensi.nnPada tahun 2018, Moret terpilih sebagai Anggota International Society for Computational Biology, atas kontribusinya yang luar biasa pada bidang biologi komputasi dan bioinformatika.nn### Tanggapan:n | * École Polytechnique Fédérale de Lausanne (EPFL) (lulus 1975)n* University of Tennessee (lulus 1980) | Moret belajar di École Polytechnique Fédérale de Lausanne (EPFL) dan University of Tennessee, masing-masing lulus pada tahun 1975 dan 1980.nn### Petunjuk:nn- Gunakan fungsi `split` untuk membagi input menjadi daftar kalimat.n- Gunakan fungsi `split` untuk membagi setiap kalimat menjadi daftar kata.n- Gunakan fungsi `split` untuk membagi | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- Universitas Tennessee,1980n- Universitas New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Di bawah ini adalah instruksi yang menjelaskan suatu tugas, dipasangkan dengan input yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.n |
| 2 | Di bawah ini adalah instruksi yang menjelaskan tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis respons yang melengkapi permintaan dengan tepat.nn### Instruksi:nDari bagian tersebut, kenali atribut Dionysus. Tampilkan hasilnya dalam format yang dipisahkan koma.nn### Masukan:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnDewa anggur, kesuburan, pesta, festival, kegilaan, kekacauan, mabuk-mabukan, tumbuh-tumbuhan, ekstasi, dan teater. Dia adalah putra Zeus dan Semele yang dilahirkan dua kali, di mana Zeus merenggutnya dari rahim ibunya dan menjahit Dionysus ke pahanya sendiri dan membawanya sampai dia siap untuk dilahirkan. Dalam seni ia digambarkan sebagai dewa berjanggut tua (khususnya sebelum tahun 430 SM) atau sebagai pemuda banci dan berambut panjang (khususnya setelah tahun 430 SM). Atributnya meliputi thyrsus, cangkir minum, tanaman anggur, dan mahkota tanaman ivy. Dia sering ditemani oleh thiasosnya, sekelompok pelayan termasuk satir, maenad, dan guru lamanya Silenus. Permaisuri Dionysus adalah Ariadne. Dionysius pernah dianggap sebagai salah satu anggota dari jajaran dewa Yunani, namun penemuan tablet Linear B menegaskan statusnya sebagai dewa sejak periode awal. Bacchus adalah nama lain untuknya dalam bahasa Yunani, dan umum digunakan di kalangan orang Romawi. Hewan keramatnya antara lain lumba-lumba, ular, harimau, dan keledai.nn### Respon:n | thyrsus, cangkir minum, pohon anggur, mahkota tanaman ivy | Dionysus (Διόνυσος, Diónusos)nnDewa anggur, kesuburan, pesta, festival, kegilaan, kekacauan, mabuk-mabukan, tumbuh-tumbuhan, ekstasi, dan teater. Dia adalah putra Zeus dan Semele yang lahir dua kali, di mana Zeus merenggutnya dari rahim ibunya dan menjahit Dionysus ke pahanya sendiri. | thyrsus, cangkir minum, tanaman anggur, mahkota tanaman ivynn Di bawah ini adalah instruksi yang menjelaskan tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.nn### Instruksi:nApa perbedaan antara Kekaisaran Parthia dan Kekaisaran Arsacid?nn### Masukan:nKekaisaran Parthia, juga dikenal sebagai Kekaisaran Arsacid adalah sebuah |
| 3 | Di bawah ini adalah instruksi yang menjelaskan tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.nn### Petunjuk:nMengapa ibu kota Uzbekistan memiliki komunitas Yunani terbesar?nn### Masukan:nOrang-orang Yunani di Uzbekistan berjumlah sekitar 9,000. Komunitas tersebut terdiri dari orang-orang Yunani dari Rusia yang dideportasi secara paksa dari negara tersebut ke Uzbekistan pada tahun 1940-an, dan pengungsi politik dari Yunani. Sekitar 30,000 orang Yunani tinggal di negara tersebut sebelum Perang Dunia II dan 11,000 lainnya tiba setelah Perang Saudara Yunani dan kekalahan Tentara Demokratik Yunani. Jumlah mereka telah menyusut dari angka tertinggi sekitar 40,000 pada tahun 1960an. Alasan utamanya adalah emigrasi ke Yunani setelah berakhirnya Perang Dingin ketika undang-undang mengizinkan kembalinya semua etnis Yunani yang diasingkan karena alasan politik setelah Perang Saudara Yunani. Komunitas Yunani terbesar di negara ini berada di ibu kota Tashkent dimana sebagian besar pengungsi politik Yunani direlokasi oleh otoritas Soviet. Pada zaman kuno, bagian selatan negara ini merupakan bagian dari Kerajaan Seleukus Helenistik, namun hanya sedikit komunitas Yunani di sana yang telah berasimilasi. Organisasi terpenting yang mewakili etnis Yunani adalah Asosiasi Kebudayaan Yunani Tashkent. Kegiatan organisasi ini meliputi pengajaran bahasa Yunani (19 kelas dengan total 571 siswa, kelas untuk dewasa) dan pengajaran tarian dan musik Yunani.nn### Respon:n | Sebagian besar pengungsi politik Yunani di Uzbekistan direlokasi oleh otoritas Soviet ke ibu kota Tashkent. | n“`nIbu kota Uzbekistan memiliki komunitas Yunani terbesar karena jumlah orang Yunani di Uzbekistan sekitar 9,000 orang. Komunitas tersebut terdiri dari orang-orang Yunani dari Rusia yang dideportasi secara paksa dari negara tersebut ke Uzbekistan pada tahun 1940-an, dan pengungsi politik dari Yunani. Sekitar 30,000 orang Yunani tinggal di negara itu sebelum Perang Dunia II dan 11,00 orang berikutnya | Ibu kota Uzbekistan memiliki komunitas Yunani terbesar karena di sanalah sebagian besar pengungsi politik Yunani direlokasi oleh otoritas Soviet setelah dideportasi dari Yunani.nn Di bawah ini adalah instruksi yang menjelaskan suatu tugas, dipasangkan dengan masukan yang memberikan konteks lebih lanjut. Tulis tanggapan yang melengkapi permintaan dengan tepat.nn### Instruksi:nApa perbedaan antara Kekaisaran Parthia dan Arsacid?nn### Masukan:n |
Kita dapat melihat bahwa respons dari model yang telah disempurnakan menunjukkan peningkatan yang signifikan dalam hal presisi, relevansi, dan kejelasan dibandingkan dengan respons dari model yang telah dilatih sebelumnya. Dalam beberapa kasus, menggunakan model terlatih untuk kasus penggunaan Anda mungkin tidak cukup, jadi menyempurnakannya menggunakan teknik ini akan membuat solusi lebih dipersonalisasi untuk kumpulan data Anda.
Membersihkan
Setelah Anda menyelesaikan tugas pelatihan dan tidak ingin menggunakan sumber daya yang ada lagi, hapus sumber daya menggunakan kode berikut:
Kesimpulan
Penerapan dan penyempurnaan model Llama 2 Neuron di SageMaker menunjukkan kemajuan signifikan dalam mengelola dan mengoptimalkan model AI generatif skala besar. Model ini, termasuk varian seperti Llama-2-7b dan Llama-2-13b, menggunakan Neuron untuk pelatihan dan inferensi yang efisien pada instans berbasis AWS Inferentia dan Trainium, sehingga meningkatkan kinerja dan skalabilitasnya.
Kemampuan untuk menerapkan model ini melalui SageMaker JumpStart UI dan Python SDK menawarkan fleksibilitas dan kemudahan penggunaan. Neuron SDK, dengan dukungannya terhadap framework ML populer dan kemampuan performa tinggi, memungkinkan penanganan model besar ini secara efisien.
Menyempurnakan model-model ini pada data spesifik domain sangat penting untuk meningkatkan relevansi dan keakuratannya dalam bidang-bidang khusus. Prosesnya, yang dapat Anda lakukan melalui SageMaker Studio UI atau Python SDK, memungkinkan penyesuaian sesuai kebutuhan spesifik, sehingga menghasilkan peningkatan performa model dalam hal penyelesaian cepat dan kualitas respons.
Sebagai perbandingan, versi model yang telah dilatih sebelumnya, meskipun kuat, dapat memberikan respons yang lebih umum atau berulang. Penyempurnaan akan menyesuaikan model dengan konteks tertentu, sehingga menghasilkan respons yang lebih akurat, relevan, dan beragam. Penyesuaian ini terutama terlihat ketika membandingkan respons dari model yang telah dilatih sebelumnya dan model yang telah disempurnakan, dimana model yang telah disempurnakan menunjukkan peningkatan nyata dalam kualitas dan spesifisitas keluaran. Kesimpulannya, penerapan dan penyempurnaan model Neuron Llama 2 di SageMaker mewakili kerangka kerja yang kuat untuk mengelola model AI tingkat lanjut, menawarkan peningkatan signifikan dalam kinerja dan penerapan, terutama bila disesuaikan dengan domain atau tugas tertentu.
Mulailah hari ini dengan mereferensikan sampel SageMaker buku catatan.
Untuk informasi lebih lanjut tentang penerapan dan penyempurnaan model Llama 2 terlatih pada instans berbasis GPU, lihat Sempurnakan Llama 2 untuk pembuatan teks di Amazon SageMaker JumpStart dan Model alas bedak Llama 2 dari Meta kini tersedia di Amazon SageMaker JumpStart.
Para penulis ingin mengucapkan terima kasih atas kontribusi teknis dari Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne dan Mike James.
Tentang Penulis
 Xin Huang adalah Ilmuwan Terapan Senior untuk Amazon SageMaker JumpStart dan algoritme bawaan Amazon SageMaker. Dia berfokus pada pengembangan algoritme pembelajaran mesin yang dapat diskalakan. Minat penelitiannya adalah di bidang pemrosesan bahasa alami, pembelajaran mendalam yang dapat dijelaskan pada data tabular, dan analisis kuat pengelompokan ruang-waktu non-parametrik. Dia telah menerbitkan banyak makalah di konferensi ACL, ICDM, KDD, dan Royal Statistical Society: Series A.
Xin Huang adalah Ilmuwan Terapan Senior untuk Amazon SageMaker JumpStart dan algoritme bawaan Amazon SageMaker. Dia berfokus pada pengembangan algoritme pembelajaran mesin yang dapat diskalakan. Minat penelitiannya adalah di bidang pemrosesan bahasa alami, pembelajaran mendalam yang dapat dijelaskan pada data tabular, dan analisis kuat pengelompokan ruang-waktu non-parametrik. Dia telah menerbitkan banyak makalah di konferensi ACL, ICDM, KDD, dan Royal Statistical Society: Series A.
 Nitin Eusebius adalah Sr. Enterprise Solutions Architect di AWS, berpengalaman dalam Rekayasa Perangkat Lunak, Arsitektur Perusahaan, dan AI/ML. Dia sangat bersemangat mengeksplorasi kemungkinan AI generatif. Dia berkolaborasi dengan pelanggan untuk membantu mereka membangun aplikasi yang dirancang dengan baik di platform AWS, dan berdedikasi untuk memecahkan tantangan teknologi dan membantu perjalanan cloud mereka.
Nitin Eusebius adalah Sr. Enterprise Solutions Architect di AWS, berpengalaman dalam Rekayasa Perangkat Lunak, Arsitektur Perusahaan, dan AI/ML. Dia sangat bersemangat mengeksplorasi kemungkinan AI generatif. Dia berkolaborasi dengan pelanggan untuk membantu mereka membangun aplikasi yang dirancang dengan baik di platform AWS, dan berdedikasi untuk memecahkan tantangan teknologi dan membantu perjalanan cloud mereka.
 Madhur Prashant bekerja di ruang AI generatif di AWS. Dia sangat tertarik dengan titik temu antara pemikiran manusia dan AI generatif. Minatnya terletak pada AI generatif, khususnya membangun solusi yang bermanfaat dan tidak berbahaya, dan yang terpenting optimal bagi pelanggan. Di luar pekerjaan, dia suka melakukan yoga, hiking, menghabiskan waktu bersama saudara kembarnya, dan bermain gitar.
Madhur Prashant bekerja di ruang AI generatif di AWS. Dia sangat tertarik dengan titik temu antara pemikiran manusia dan AI generatif. Minatnya terletak pada AI generatif, khususnya membangun solusi yang bermanfaat dan tidak berbahaya, dan yang terpenting optimal bagi pelanggan. Di luar pekerjaan, dia suka melakukan yoga, hiking, menghabiskan waktu bersama saudara kembarnya, dan bermain gitar.
 Dewan Choudhury adalah Insinyur Pengembangan Perangkat Lunak dengan Amazon Web Services. Dia mengerjakan algoritme Amazon SageMaker dan penawaran JumpStart. Selain membangun infrastruktur AI/ML, dia juga bersemangat membangun sistem terdistribusi yang dapat diskalakan.
Dewan Choudhury adalah Insinyur Pengembangan Perangkat Lunak dengan Amazon Web Services. Dia mengerjakan algoritme Amazon SageMaker dan penawaran JumpStart. Selain membangun infrastruktur AI/ML, dia juga bersemangat membangun sistem terdistribusi yang dapat diskalakan.
 Hao Zhou adalah Ilmuwan Riset di Amazon SageMaker. Sebelumnya, dia bekerja mengembangkan metode pembelajaran mesin untuk deteksi penipuan untuk Amazon Fraud Detector. Dia bersemangat menerapkan pembelajaran mesin, pengoptimalan, dan teknik AI generatif pada berbagai masalah dunia nyata. Beliau meraih gelar PhD di bidang Teknik Elektro dari Northwestern University.
Hao Zhou adalah Ilmuwan Riset di Amazon SageMaker. Sebelumnya, dia bekerja mengembangkan metode pembelajaran mesin untuk deteksi penipuan untuk Amazon Fraud Detector. Dia bersemangat menerapkan pembelajaran mesin, pengoptimalan, dan teknik AI generatif pada berbagai masalah dunia nyata. Beliau meraih gelar PhD di bidang Teknik Elektro dari Northwestern University.
 Qinglan adalah Insinyur Pengembangan Perangkat Lunak di AWS. Dia telah mengerjakan beberapa produk yang menantang di Amazon, termasuk solusi inferensi ML kinerja tinggi dan sistem logging kinerja tinggi. Tim Qing berhasil meluncurkan model Billion-parameter pertama di Amazon Advertising dengan latensi yang sangat rendah. Qing memiliki pengetahuan mendalam tentang pengoptimalan infrastruktur dan akselerasi Deep Learning.
Qinglan adalah Insinyur Pengembangan Perangkat Lunak di AWS. Dia telah mengerjakan beberapa produk yang menantang di Amazon, termasuk solusi inferensi ML kinerja tinggi dan sistem logging kinerja tinggi. Tim Qing berhasil meluncurkan model Billion-parameter pertama di Amazon Advertising dengan latensi yang sangat rendah. Qing memiliki pengetahuan mendalam tentang pengoptimalan infrastruktur dan akselerasi Deep Learning.
 Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan algoritme bawaan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Ia mendapatkan gelar PhD dari University of Illinois Urbana-Champaign. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik, dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan algoritme bawaan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Ia mendapatkan gelar PhD dari University of Illinois Urbana-Champaign. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik, dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
 Dr Li Zhang adalah Manajer Produk Utama-Teknis untuk Amazon SageMaker JumpStart dan algoritma bawaan Amazon SageMaker, sebuah layanan yang membantu ilmuwan data dan praktisi pembelajaran mesin memulai pelatihan dan penerapan model mereka, dan menggunakan pembelajaran penguatan dengan Amazon SageMaker. Pekerjaan masa lalunya sebagai anggota staf peneliti utama dan penemu utama di IBM Research telah memenangkan penghargaan kertas uji waktu di IEEE INFOCOM.
Dr Li Zhang adalah Manajer Produk Utama-Teknis untuk Amazon SageMaker JumpStart dan algoritma bawaan Amazon SageMaker, sebuah layanan yang membantu ilmuwan data dan praktisi pembelajaran mesin memulai pelatihan dan penerapan model mereka, dan menggunakan pembelajaran penguatan dengan Amazon SageMaker. Pekerjaan masa lalunya sebagai anggota staf peneliti utama dan penemu utama di IBM Research telah memenangkan penghargaan kertas uji waktu di IEEE INFOCOM.
 Kamran Khan, Sr Manajer Pengembangan Bisnis Teknis untuk AWS Inferentina/Trianium di AWS. Dia memiliki pengalaman lebih dari satu dekade membantu pelanggan menerapkan dan mengoptimalkan pelatihan pembelajaran mendalam dan beban kerja inferensi menggunakan AWS Inferentia dan AWS Trainium.
Kamran Khan, Sr Manajer Pengembangan Bisnis Teknis untuk AWS Inferentina/Trianium di AWS. Dia memiliki pengalaman lebih dari satu dekade membantu pelanggan menerapkan dan mengoptimalkan pelatihan pembelajaran mendalam dan beban kerja inferensi menggunakan AWS Inferentia dan AWS Trainium.
 Joe Senerchia adalah Manajer Produk Senior di AWS. Dia mendefinisikan dan membangun instans Amazon EC2 untuk pembelajaran mendalam, kecerdasan buatan, dan beban kerja komputasi kinerja tinggi.
Joe Senerchia adalah Manajer Produk Senior di AWS. Dia mendefinisikan dan membangun instans Amazon EC2 untuk pembelajaran mendalam, kecerdasan buatan, dan beban kerja komputasi kinerja tinggi.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- kemampuan
- Sanggup
- Tentang Kami
- percepatan
- Setuju
- diterima
- diterima
- mengakses
- ketepatan
- tepat
- mengakui
- ACM
- aktif
- kegiatan
- Adam
- menyesuaikan
- adaptasi
- disesuaikan
- menambahkan
- tambahan
- dewasa
- maju
- kemajuan
- pengiklanan
- Setelah
- Persetujuan
- AI
- Model AI
- AI / ML
- algoritma
- Semua
- mengizinkan
- diizinkan
- memungkinkan
- juga
- Amazon
- Amazon EC2
- Detektor Penipuan Amazon
- Amazon SageMaker
- Mulai Lompatan Amazon SageMaker
- Amazon Web Services
- antara
- an
- analisis
- Kuno
- dan
- hewan
- Mengumumkan
- Lain
- Apa pun
- lagi
- Apache
- selain
- berlaku
- Aplikasi
- aplikasi
- terapan
- Menerapkan
- tepat
- sekitar
- arsitektur
- ADALAH
- DAERAH
- daerah
- argumen
- Tentara
- tiba
- Seni
- buatan
- kecerdasan buatan
- AS
- membantu
- Asosiasi
- At
- Petugas
- atribut
- Pihak berwenang
- penulis
- Otomatis
- tersedianya
- tersedia
- menghindari
- AWS
- Inferensi AWS
- b
- berdasarkan
- BE
- Balok
- karena
- menjadi
- menjadi
- sebelum
- makhluk
- Percaya
- di bawah
- antara
- Luar
- Terbesar
- biologi
- Blog
- lahir
- kedua
- Kotak
- luas
- membangun
- Bangunan
- membangun
- built-in
- bisnis
- pengembangan bisnis
- tapi
- tombol
- tombol
- by
- panggilan
- datang
- CAN
- kemampuan
- modal
- kartu
- dilakukan
- kasus
- kasus
- kategori
- Kategori
- tantangan
- menantang
- perubahan
- Kekacauan
- mengobrol
- kepala
- pilihan
- Pilih
- memilih
- Christopher
- Kota
- sipil
- kejelasan
- kelas-kelas
- klasik
- klasifikasi
- membersihkan
- awan
- kekelompokan
- kode
- dingin
- komite
- Umum
- Masyarakat
- masyarakat
- perusahaan
- dibandingkan
- pembandingan
- perbandingan
- Lengkap
- Selesaikan
- komputasi
- komputasi
- kesimpulan
- bersamaan
- Mengadakan
- Konferensi
- konferensi
- konfigurasi
- Memastikan
- konsul
- mengandung
- Wadah
- mengandung
- Konten
- konteks
- Konteks
- kontribusi
- kontrol
- kontrol
- Biaya
- mahal
- Biaya
- negara
- dibuat
- Mahkota
- sangat penting
- kultural
- Cangkir
- pelanggan
- pengalaman pelanggan
- pelanggan
- kustomisasi
- data
- kumpulan data
- Tanggal
- de
- dasawarsa
- Desember
- decoding
- dedicated
- mendalam
- belajar mendalam
- sangat
- Default
- Mendefinisikan
- Derajat
- menyampaikan
- demokratis
- mendemonstrasikan
- menunjukkan
- menunjukkan
- Tergantung
- tergantung
- menyebarkan
- dikerahkan
- penggelaran
- penyebaran
- menjelaskan
- deskripsi
- ditunjuk
- dirancang
- terperinci
- rincian
- Deteksi
- mengembangkan
- berkembang
- Pengembangan
- Dialog
- MELAKUKAN
- perbedaan
- berbeda
- menemukan
- penemuan
- membahas
- Display
- didistribusikan
- sistem terdistribusi
- beberapa
- tidak
- melakukan
- Boneka
- domain
- domain
- Dont
- turun
- setiap
- Awal
- Produktif
- memudahkan
- kemudahan penggunaan
- editor
- Efektif
- efektivitas
- efisien
- antara
- terpilih
- elektro
- Kekaisaran
- diaktifkan
- memungkinkan
- memungkinkan
- akhir
- ujung ke ujung
- Titik akhir
- insinyur
- Teknik
- mempertinggi
- meningkatkan
- cukup
- Memastikan
- Enterprise
- Solusi perusahaan
- Lingkungan Hidup
- lingkungan
- sama
- sama
- terutama
- Eter (ETH)
- mengevaluasi
- evaluasi
- jelas
- contoh
- contoh
- gembira
- tidak termasuk
- ada
- pengalaman
- berpengalaman
- eksperimental
- menyelidiki
- Menjelajahi
- ekstraksi
- Jatuh
- palsu
- lebih cepat
- sesama
- festival
- beberapa
- Fields
- File
- File
- Filing
- keuangan
- jasa keuangan
- Menemukan
- akhir
- Pertama
- keluwesan
- Mengapung
- Fokus
- berfokus
- berikut
- berikut
- Untuk
- kekuatan
- format
- ditemukan
- Prinsip Dasar
- Didirikan di
- Kerangka
- kerangka
- penipuan
- deteksi penipuan
- dari
- fungsi
- lebih lanjut
- dihasilkan
- menghasilkan
- generasi
- generatif
- AI generatif
- mendapatkan
- Go
- Tuhan
- baik
- mendapat
- lulus
- grafik
- grafik
- lebih besar
- Yunani
- Serakah
- Yunani
- Kelompok
- bimbingan
- gitar
- memiliki
- Penanganan
- tangan
- senang
- Memiliki
- he
- kesehatan
- Dimiliki
- membantu
- bermanfaat
- membantu
- membantu
- High
- kinerja tinggi
- lebih tinggi
- paling tinggi
- highlight
- mendaki
- dia
- -nya
- memegang
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- manusia
- i
- IBM
- ICLR
- mengenali
- id
- IEEE
- if
- ii
- Illinois
- implementasi
- mengimpor
- penting
- memperbaiki
- ditingkatkan
- perbaikan
- perbaikan
- in
- secara mendalam
- memasukkan
- termasuk
- Termasuk
- Meningkatkan
- menunjukkan
- informasi
- ekstraksi informasi
- Infrastruktur
- infrastruktur
- memasukkan
- input
- contoh
- contoh
- instruksi
- terpadu
- Intelijen
- kepentingan
- Antarmuka
- Internasional
- persimpangan
- ke
- terlibat
- IT
- NYA
- james
- Pekerjaan
- Jobs
- bergabung
- jonathan
- majalah
- perjalanan
- jpg
- json
- hanya
- kunci
- Kerajaan
- kit
- Paket (SDK)
- pengetahuan
- dikenal
- pendaratan
- halaman arahan
- bahasa
- besar
- besar-besaran
- Latensi
- kemudian
- diluncurkan
- Hukum
- terkemuka
- pengetahuan
- Panjang
- li
- Lisensi
- lisensi
- berbohong
- Hidup
- 'like'
- kemungkinan
- Mungkin
- pembatasan
- baris
- baris
- LINK
- Daftar
- Daftar
- Llama
- memuat
- lokal
- penebangan
- Panjang
- melihat
- mencintai
- Rendah
- menurunkan
- penurunan
- terendah
- mesin
- Mesin belajar
- terbuat
- Utama
- membuat
- Membuat
- manajer
- pelaksana
- Manan Syah
- banyak
- menguasai
- maksimum
- Mungkin..
- makna
- Pelajari
- anggota
- meta
- metode
- metode
- Mexico
- mungkin
- mikropon
- keberatan
- ML
- model
- pemodelan
- model
- dimodifikasi
- memodifikasi
- lebih
- paling
- terharu
- musik
- harus
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Arahkan
- Navigasi
- Perlu
- kebutuhan
- NeuroIPS
- New
- berikutnya
- nLP
- Northwestern University
- buku catatan
- laptop
- sekarang
- jumlah
- nomor
- obyek
- target
- of
- menawarkan
- menawarkan
- Penawaran
- Penawaran
- sering
- Tua
- lebih tua
- on
- sekali
- ONE
- hanya
- optimal
- optimasi
- Optimize
- dioptimalkan
- mengoptimalkan
- pilihan
- or
- organisasi
- Lainnya
- keluaran
- di luar
- terkemuka
- lebih
- sendiri
- paket
- halaman
- pasangan
- dipasangkan
- pane
- kertas
- dokumen
- Paralel
- parameter
- bagian
- khususnya
- pihak
- bagian
- bergairah
- lalu
- untuk
- melakukan
- prestasi
- periode
- Personalized
- phd
- pipa saluran
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- silahkan
- Titik
- Kebijakan
- kebijaksanaan
- politik
- pop-up
- Populer
- positif
- kemungkinan
- mungkin
- Pos
- kuat
- mendahului
- Ketelitian
- mempersiapkan
- primer
- Utama
- probabilitas
- masalah
- proses
- pengolahan
- Produk
- manajer produk
- Produk
- hak milik
- memberikan
- penyedia
- menyediakan
- di depan umum
- diterbitkan
- menempatkan
- Ular sanca
- pytorch
- kualitas
- pertanyaan
- keserampangan
- mencapai
- Mencapai
- Baca
- siap
- nyata
- dunia nyata
- real-time
- alasan
- alasan
- arsip
- lihat
- referensi
- pengungsi
- dirilis
- relevansi
- relevan
- Dipindahkan
- tetap
- sisa
- ulang
- berulang-ulang
- menggantikan
- gudang
- mewakili
- mewakili
- permintaan
- permintaan
- wajib
- penelitian
- peneliti
- Sumber
- masing-masing
- tanggapan
- tanggapan
- tanggung jawab
- dihasilkan
- Hasil
- kembali
- ulasan
- meninjau
- kuat
- bergulir
- kerajaan
- Run
- Rusia
- pembuat bijak
- Skalabilitas
- terukur
- Skala
- skenario
- ilmuwan
- ilmuwan
- script
- SDK
- Pencarian
- mencari
- SEC
- Pengarsipan SEC
- Kedua
- Bagian
- keamanan
- melihat
- senior
- mengirim
- putusan pengadilan
- sentimen
- terpisah
- Urutan
- Seri
- Seri A
- layanan
- Layanan
- set
- pengaturan
- pengaturan
- beberapa
- Pendek
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- penting
- Sederhana
- sejak
- tunggal
- Ukuran
- potongan
- So
- Masyarakat
- Perangkat lunak
- pengembangan perangkat lunak
- kit pengembangan perangkat lunak
- rekayasa Perangkat Lunak
- larutan
- Solusi
- Memecahkan
- beberapa
- putra
- sumber
- Selatan
- soviet
- Space
- khusus
- tertentu
- Secara khusus
- kekhususan
- ditentukan
- Pengeluaran
- membagi
- Staf
- awal
- mulai
- Negara
- statistik
- Status
- pengemudian
- Langkah
- Tangga
- Berhenti
- penyimpanan
- tersusun
- Siswa
- belajar
- studi
- studio
- berhasil
- seperti itu
- mendukung
- Didukung
- yakin
- Swiss
- sistem
- sistem
- tabel
- disesuaikan
- tugas
- tugas
- Pengajaran
- tim
- Teknis
- teknik
- teknik
- Teknologi
- Template
- tennessee
- istilah
- uji
- teks
- Klasifikasi Teks
- pembuatan teks
- dari
- bahwa
- Grafik
- Daerah
- Ibukota
- Teater
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- Pikir
- pihak ketiga
- ini
- itu
- Melalui
- keluaran
- harimau
- waktu
- kali
- untuk
- hari ini
- token
- Token
- alat
- Total
- Pelatihan VE
- terlatih
- Pelatihan
- transformator
- Terjemahan
- benar
- mencoba
- kembar
- dua
- mengetik
- ui
- bawah
- pokok
- unik
- Universitas
- universitas
- sampai
- Memperbarui
- Pembaruan
- penggunaan
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- kegunaan
- menggunakan
- memanfaatkan
- Uzbekistan
- pengesahan
- nilai
- variasi
- berbagai
- versi
- sangat
- melalui
- View
- merambat
- visual
- berjalan
- ingin
- perang
- adalah
- cara
- we
- jaringan
- layanan web
- berbasis web
- pergi
- adalah
- ketika
- yang
- sementara
- SIAPA
- akan
- ANGGUR
- dengan
- Won
- Word
- kata
- Kerja
- bekerja
- kerja
- bekerja
- bengkel
- dunia
- akan
- menulis
- tahun
- Yoga
- kamu
- Anda
- pemuda
- zephyrnet.dll
- Zeus