Posting ini ditulis bersama Preshen Goobiah dan Johan Olivier dari Capitec.
Apache Spark adalah sistem pemrosesan terdistribusi sumber terbuka yang banyak digunakan dan terkenal mampu menangani beban kerja data berskala besar. Ia sering menemukan aplikasi di antara pengembang Spark yang bekerja dengannya Amazon ESDM, Amazon SageMaker, Lem AWS dan aplikasi Spark khusus.
Pergeseran Merah Amazon menawarkan integrasi tanpa batas dengan Apache Spark, memungkinkan Anda mengakses data Redshift dengan mudah di klaster yang disediakan Amazon Redshift dan Amazon Redshift Tanpa Server. Integrasi ini memperluas kemungkinan solusi analitik dan pembelajaran mesin (ML) AWS, menjadikan gudang data dapat diakses oleh lebih banyak aplikasi.
Dengan Integrasi Amazon Redshift untuk Apache Spark, Anda dapat dengan cepat memulai dan dengan mudah mengembangkan aplikasi Spark menggunakan bahasa populer seperti Java, Scala, Python, SQL, dan R. Aplikasi Anda dapat membaca dan menulis ke gudang data Amazon Redshift dengan lancar sambil mempertahankan kinerja optimal dan konsistensi transaksional. Selain itu, Anda akan mendapatkan keuntungan dari peningkatan kinerja melalui optimasi pushdown, yang selanjutnya meningkatkan efisiensi operasi Anda.
Capitec, bank ritel terbesar di Afrika Selatan dengan lebih dari 21 juta klien perbankan ritel, bertujuan untuk menyediakan layanan keuangan yang sederhana, terjangkau, dan mudah diakses untuk membantu masyarakat Afrika Selatan melakukan perbankan dengan lebih baik sehingga mereka dapat hidup lebih baik. Dalam postingan ini, kami membahas keberhasilan integrasi konektor Amazon Redshift sumber terbuka oleh tim Platform Fitur layanan bersama Capitec. Sebagai hasil dari pemanfaatan integrasi Amazon Redshift untuk Apache Spark, produktivitas pengembang meningkat 10 kali lipat, alur pembuatan fitur disederhanakan, dan duplikasi data berkurang hingga nol.
Peluang bisnis
Terdapat 19 model prediktif dalam cakupan penggunaan 93 fitur yang dibangun dengan AWS Glue di seluruh divisi Kredit Ritel Capitec. Catatan fitur diperkaya dengan fakta dan dimensi yang disimpan di Amazon Redshift. Apache PySpark dipilih untuk membuat fitur karena menawarkan mekanisme yang cepat, terdesentralisasi, dan terukur untuk memperdebatkan data dari berbagai sumber.
Fitur-fitur produksi ini memainkan peran penting dalam memungkinkan pengajuan pinjaman jangka tetap secara real-time, pengajuan kartu kredit, pemantauan perilaku kredit bulanan batch, dan identifikasi gaji harian batch dalam bisnis.
Masalah sumber data
Untuk memastikan keandalan saluran data PySpark, penting untuk memiliki data tingkat catatan yang konsisten dari tabel dimensi dan tabel fakta yang disimpan di Gudang Data Perusahaan (EDW). Tabel ini kemudian digabungkan dengan tabel dari Enterprise Data Lake (EDL) saat runtime.
Selama pengembangan fitur, teknisi data memerlukan antarmuka yang mulus ke EDW. Antarmuka ini memungkinkan mereka mengakses dan mengintegrasikan data yang diperlukan dari EDW ke dalam saluran data, memungkinkan pengembangan dan pengujian fitur secara efisien.
Proses solusi sebelumnya
Dalam solusi sebelumnya, teknisi data tim produk menghabiskan waktu 30 menit setiap proses untuk mengekspos data Redshift ke Spark secara manual. Langkah-langkahnya antara lain sebagai berikut:
- Buat kueri berpredikat dengan Python.
- Kirimkan sebuah MEMBONGKAR pertanyaan melalui API Data Amazon Redshift.
- Data katalog di AWS Glue Data Catalog melalui AWS SDK for Pandas menggunakan pengambilan sampel.
Pendekatan ini menimbulkan masalah pada kumpulan data yang besar, memerlukan pemeliharaan berulang dari tim platform, dan rumit untuk diotomatisasi.
Ikhtisar solusi saat ini
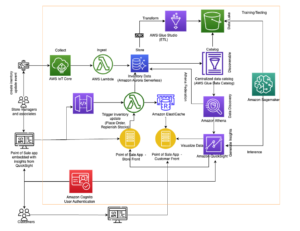
Capitec dapat menyelesaikan masalah ini dengan integrasi Amazon Redshift untuk Apache Spark dalam alur pembuatan fitur. Arsitekturnya didefinisikan dalam diagram berikut.

Alur kerja meliputi langkah-langkah berikut:
- Perpustakaan internal diinstal ke dalam tugas AWS Glue PySpark melalui Artefak Kode AWS.
- Tugas AWS Glue mengambil kredensial klaster Redshift Manajer Rahasia AWS dan mengatur koneksi Amazon Redshift (menyuntikkan kredensial klaster, membongkar lokasi, format file) melalui perpustakaan internal bersama. Integrasi Amazon Redshift untuk Apache Spark juga mendukung penggunaan Identitas AWS dan Manajemen Akses (IAM) ke mengambil kredensial dan terhubung ke Amazon Redshift.
- Kueri Spark diterjemahkan ke kueri yang dioptimalkan Amazon Redshift dan dikirimkan ke EDW. Hal ini dicapai dengan integrasi Amazon Redshift untuk Apache Spark.
- Himpunan data EDW diturunkan ke awalan sementara dalam sebuah Layanan Penyimpanan Sederhana Amazon (Amazon S3).
- Dataset EDW dari bucket S3 dimuat ke eksekutor Spark melalui integrasi Amazon Redshift untuk Apache Spark.
- Himpunan data EDL dimuat ke dalam pelaksana Spark melalui Katalog Data AWS Glue.
Komponen-komponen ini bekerja sama untuk memastikan bahwa teknisi data dan pipeline data produksi memiliki alat yang diperlukan untuk mengimplementasikan integrasi Amazon Redshift untuk Apache Spark, menjalankan kueri, dan memfasilitasi pembongkaran data dari Amazon Redshift ke EDL.
Menggunakan integrasi Amazon Redshift untuk Apache Spark di AWS Glue 4.0
Di bagian ini, kami mendemonstrasikan kegunaan integrasi Amazon Redshift untuk Apache Spark dengan memperkaya tabel permohonan pinjaman yang berada di data lake S3 dengan informasi klien dari gudang data Redshift di PySpark.
Grafik dimclient tabel di Amazon Redshift berisi kolom berikut:
- Kunci Klien – INT8
- KlienAltKey – VARCHAR50
- Nomor Pengenal Pesta – VARCHAR20
- KlienCreateDate - TANGGAL
- Dibatalkan – INT2
- RowIsCurrent – INT2
Grafik loanapplication tabel di Katalog Data AWS Glue berisi kolom berikut:
- ID Rekaman – BESAR
- Tanggal Log – Stempel WAKTU
- Nomor Pengenal Pesta - RANGKAIAN
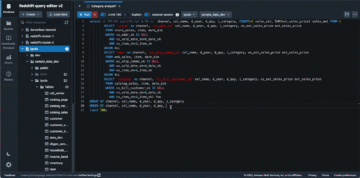
Tabel Redshift dibaca melalui integrasi Amazon Redshift untuk Apache Spark dan disimpan dalam cache. Lihat kode berikut:
Catatan permohonan pinjaman dibaca dari data lake S3 dan diperkaya dengan dimclient tabel pada informasi Amazon Redshift:
Hasilnya, catatan permohonan pinjaman (dari data lake S3) diperkaya dengan ClientCreateDate kolom (dari Amazon Redshift).

Bagaimana integrasi Amazon Redshift untuk Apache Spark memecahkan masalah sumber data
Integrasi Amazon Redshift untuk Apache Spark secara efektif mengatasi masalah sumber data melalui mekanisme berikut:
- Membaca tepat pada waktunya – Integrasi Amazon Redshift untuk konektor Apache Spark membaca tabel Redshift secara tepat waktu, memastikan konsistensi data dan skema. Ini sangat berharga bagi Tipe 2 perlahan mengubah dimensi (SCD) dan rentang waktu yang mengumpulkan fakta cuplikan. Dengan menggabungkan tabel Redshift ini dengan tabel Katalog Data AWS Glue sistem sumber dari EDL dalam pipeline produksi PySpark, konektor ini memungkinkan integrasi data yang lancar dari berbagai sumber sambil menjaga integritas data.
- Kueri Redshift yang dioptimalkan – Integrasi Amazon Redshift untuk Apache Spark memainkan peran penting dalam mengubah rencana kueri Spark menjadi kueri Redshift yang dioptimalkan. Proses konversi ini menyederhanakan pengalaman pengembangan tim produk dengan mematuhi prinsip lokalitas data. Kueri yang dioptimalkan menggunakan kemampuan dan optimalisasi kinerja Amazon Redshift, memastikan pengambilan dan pemrosesan data yang efisien dari Amazon Redshift untuk pipeline PySpark. Hal ini membantu menyederhanakan proses pengembangan sekaligus meningkatkan kinerja operasi sumber data secara keseluruhan.
Mendapatkan performa terbaik
Integrasi Amazon Redshift untuk Apache Spark secara otomatis menerapkan pushdown predikat dan kueri untuk mengoptimalkan kinerja. Anda bisa mendapatkan peningkatan kinerja dengan menggunakan format Parket default yang digunakan untuk pembongkaran dengan integrasi ini.
Untuk detail tambahan dan contoh kode, lihat Baru – Integrasi Amazon Redshift dengan Apache Spark.
Manfaat Solusi
Penerapan integrasi menghasilkan beberapa manfaat signifikan bagi tim:
- Peningkatan produktivitas pengembang – Antarmuka PySpark yang disediakan oleh integrasi ini meningkatkan produktivitas pengembang sebanyak 10 kali lipat, memungkinkan interaksi yang lebih lancar dengan Amazon Redshift.
- Penghapusan duplikasi data – Tabel Redshift yang dikatalogkan duplikat dan AWS Glue di data lake dihilangkan, sehingga menghasilkan lingkungan data yang lebih efisien.
- Mengurangi beban EDW – Integrasi ini memfasilitasi pembongkaran data secara selektif, meminimalkan beban pada EDW dengan hanya mengekstraksi data yang diperlukan.
Dengan menggunakan integrasi Amazon Redshift untuk Apache Spark, Capitec telah membuka jalan bagi peningkatan pemrosesan data, peningkatan produktivitas, dan ekosistem rekayasa fitur yang lebih efisien.
Kesimpulan
Dalam postingan ini, kami membahas bagaimana tim Capitec berhasil mengimplementasikan integrasi Apache Spark Amazon Redshift untuk Apache Spark guna menyederhanakan alur kerja komputasi fitur mereka. Mereka menekankan pentingnya memanfaatkan jalur data PySpark yang terdesentralisasi dan modular untuk membuat fitur model prediktif.
Saat ini, integrasi Amazon Redshift untuk Apache Spark digunakan oleh 7 pipeline data produksi dan 20 pipeline pengembangan, yang menunjukkan efektivitasnya dalam lingkungan Capitec.
Ke depan, tim Platform Fitur layanan bersama di Capitec berencana untuk memperluas adopsi integrasi Amazon Redshift untuk Apache Spark di berbagai area bisnis, yang bertujuan untuk lebih meningkatkan kemampuan pemrosesan data dan mempromosikan praktik rekayasa fitur yang efisien.
Untuk informasi tambahan tentang penggunaan integrasi Amazon Redshift untuk Apache Spark, lihat sumber daya berikut:
Tentang Penulis
 Preshen Goobiah adalah Insinyur Pembelajaran Mesin Utama untuk Platform Fitur di Capitec. Dia fokus merancang dan membangun komponen Feature Store untuk penggunaan perusahaan. Di waktu luangnya, ia senang membaca dan jalan-jalan.
Preshen Goobiah adalah Insinyur Pembelajaran Mesin Utama untuk Platform Fitur di Capitec. Dia fokus merancang dan membangun komponen Feature Store untuk penggunaan perusahaan. Di waktu luangnya, ia senang membaca dan jalan-jalan.
 Johan Oliviera adalah Insinyur Pembelajaran Mesin Senior untuk Platform Model Capitec. Dia adalah seorang wirausaha dan penggila pemecahan masalah. Dia menikmati musik dan bersosialisasi di waktu luangnya.
Johan Oliviera adalah Insinyur Pembelajaran Mesin Senior untuk Platform Model Capitec. Dia adalah seorang wirausaha dan penggila pemecahan masalah. Dia menikmati musik dan bersosialisasi di waktu luangnya.
 Sudipta Bagchi adalah Arsitek Solusi Spesialis Senior di Amazon Web Services. Dia memiliki pengalaman lebih dari 12 tahun di bidang data dan analitik, serta membantu pelanggan merancang dan membangun solusi analitik yang skalabel dan berkinerja tinggi. Di luar pekerjaan, dia suka berlari, jalan-jalan, dan bermain kriket. Terhubung dengan dia LinkedIn.
Sudipta Bagchi adalah Arsitek Solusi Spesialis Senior di Amazon Web Services. Dia memiliki pengalaman lebih dari 12 tahun di bidang data dan analitik, serta membantu pelanggan merancang dan membangun solusi analitik yang skalabel dan berkinerja tinggi. Di luar pekerjaan, dia suka berlari, jalan-jalan, dan bermain kriket. Terhubung dengan dia LinkedIn.
 Syed Humair adalah Arsitek Solusi Spesialis Analisis Senior di Amazon Web Services (AWS). Dia memiliki pengalaman lebih dari 17 tahun dalam arsitektur perusahaan yang berfokus pada Data dan AI/ML, membantu pelanggan AWS secara global untuk memenuhi kebutuhan bisnis dan teknis mereka. Anda dapat terhubung dengannya LinkedIn.
Syed Humair adalah Arsitek Solusi Spesialis Analisis Senior di Amazon Web Services (AWS). Dia memiliki pengalaman lebih dari 17 tahun dalam arsitektur perusahaan yang berfokus pada Data dan AI/ML, membantu pelanggan AWS secara global untuk memenuhi kebutuhan bisnis dan teknis mereka. Anda dapat terhubung dengannya LinkedIn.
 Vuyisa Maswana adalah Arsitek Solusi Senior di AWS, yang berbasis di Cape Town. Vuyisa memiliki fokus yang kuat dalam membantu pelanggan membangun solusi teknis untuk memecahkan masalah bisnis. Dia telah mendukung Capitec dalam perjalanan AWS mereka sejak 2019.
Vuyisa Maswana adalah Arsitek Solusi Senior di AWS, yang berbasis di Cape Town. Vuyisa memiliki fokus yang kuat dalam membantu pelanggan membangun solusi teknis untuk memecahkan masalah bisnis. Dia telah mendukung Capitec dalam perjalanan AWS mereka sejak 2019.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/simplifying-data-processing-at-capitec-with-amazon-redshift-integration-for-apache-spark/
- :memiliki
- :adalah
- $NAIK
- 06
- 1
- 10
- 100
- 12
- 16
- 17
- 19
- 20
- 2019
- 30
- 7
- a
- Sanggup
- mengakses
- dapat diakses
- dicapai
- di seluruh
- Tambahan
- Informasi Tambahan
- Selain itu
- alamat
- alamat
- mengikuti
- Adopsi
- terjangkau
- AI / ML
- Bertujuan
- bertujuan
- Membiarkan
- memungkinkan
- juga
- Amazon
- Amazon Web Services
- Layanan Web Amazon (AWS)
- antara
- an
- analisis
- dan
- Apache
- Apache Spark
- Aplikasi
- aplikasi
- berlaku
- pendekatan
- arsitektur
- ADALAH
- daerah
- AS
- At
- mengotomatisasikan
- secara otomatis
- AWS
- Lem AWS
- Bank
- Perbankan
- berdasarkan
- karena
- laku
- manfaat
- Manfaat
- TERBAIK
- Lebih baik
- antara
- Terbesar
- Didorong
- kedua
- lebih luas
- membangun
- Bangunan
- dibangun di
- bisnis
- by
- CAN
- kemampuan
- tanjung
- kartu
- katalog
- mengubah
- klien
- klien
- Kelompok
- CO
- kode
- Kolom
- Kolom
- menggabungkan
- kompleks
- komponen
- komputasi
- Terhubung
- koneksi
- konsisten
- mengandung
- konteks
- Konversi
- mengkonversi
- membuat
- membuat
- Surat kepercayaan
- kredit
- kartu kredit
- jangkrik
- sangat penting
- adat
- pelanggan
- harian
- data
- Danau Data
- pengolahan data
- data warehouse
- kumpulan data
- Terdesentralisasi
- Default
- didefinisikan
- mendemonstrasikan
- Mendesain
- merancang
- rincian
- mengembangkan
- Pengembang
- pengembang
- Pengembangan
- berbeda
- Dimensi
- ukuran
- membahas
- dibahas
- didistribusikan
- beberapa
- mudah
- ekosistem
- efektif
- efektivitas
- efisiensi
- efisien
- mudah
- dieliminasi
- menekankan
- memungkinkan
- memungkinkan
- insinyur
- Teknik
- Insinyur
- mempertinggi
- meningkatkan
- diperkaya
- memperkaya
- memastikan
- memastikan
- Enterprise
- penggemar
- Pengusaha
- Lingkungan Hidup
- penting
- Eter (ETH)
- ada
- Lihat lebih lanjut
- mengembang
- pengalaman
- memudahkan
- difasilitasi
- fakta
- faktor
- fakta
- FAST
- Fitur
- Fitur
- File
- keuangan
- jasa keuangan
- menemukan
- Fokus
- terfokus
- berfokus
- berikut
- Untuk
- format
- Depan
- sering
- dari
- fungsi
- lebih lanjut
- Mendapatkan
- generasi
- mendapatkan
- GitHub
- Secara global
- Penanganan
- Memiliki
- he
- membantu
- membantu
- membantu
- dia
- -nya
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTML
- http
- HTTPS
- IAM
- Identifikasi
- identitas
- melaksanakan
- diimplementasikan
- mengimpor
- pentingnya
- ditingkatkan
- perbaikan
- in
- termasuk
- termasuk
- Pada meningkat
- informasi
- mengintegrasikan
- integrasi
- integritas
- interaksi
- Antarmuka
- intern
- ke
- masalah
- IT
- NYA
- Jawa
- Pekerjaan
- ikut
- bergabung
- perjalanan
- danau
- Bahasa
- besar
- besar-besaran
- memimpin
- pengetahuan
- meninggalkan
- perpustakaan
- Perpustakaan
- 'like'
- hidup
- memuat
- pinjaman
- lokasi
- mencintai
- mesin
- Mesin belajar
- mempertahankan
- pemeliharaan
- Membuat
- cara
- manual
- mekanisme
- mekanisme
- juta
- meminimalkan
- menit
- ML
- model
- model
- modular
- pemantauan
- bulanan
- lebih
- lebih efisien
- beberapa
- musik
- perlu
- of
- Penawaran
- zaitun
- on
- hanya
- Buka
- open source
- Operasi
- optimal
- Optimize
- dioptimalkan
- urutan
- di luar
- lebih
- secara keseluruhan
- panda
- khususnya
- Kata Sandi
- untuk
- prestasi
- rencana
- rencana
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Bermain
- bermain
- memainkan
- Populer
- berpose
- kemungkinan
- Pos
- praktek
- prediktif
- sebelumnya
- prinsip
- Masalah
- pemecahan masalah
- masalah
- proses
- pengolahan
- Produk
- Produksi
- produktifitas
- mendorong
- memberikan
- disediakan
- Ular sanca
- query
- segera
- R
- jarak
- Baca
- Bacaan
- real-time
- catatan
- arsip
- berulang
- mengurangi
- lihat
- keandalan
- Terkenal
- membutuhkan
- wajib
- Persyaratan
- menyelesaikan
- Sumber
- mengakibatkan
- dihasilkan
- eceran
- Perbankan ritel
- Peran
- Run
- berjalan
- gaji
- SC
- Scala
- terukur
- cakupan
- SDK
- mulus
- mulus
- rahasia
- Bagian
- melihat
- terpilih
- memilih
- selektif
- senior
- Layanan
- set
- beberapa
- berbagi
- menampilkan
- penting
- Sederhana
- menyederhanakan
- menyederhanakan
- sejak
- Perlahan
- lebih halus
- Potret
- So
- bersosialisasi
- larutan
- Solusi
- MEMECAHKAN
- Memecahkan
- sumber
- sumber
- Sourcing
- Selatan
- percikan
- spesialis
- menghabiskan
- SQL
- mulai
- Tangga
- penyimpanan
- tersimpan
- mempersingkat
- efisien
- Tali
- kuat
- disampaikan
- sukses
- berhasil
- Didukung
- Mendukung
- sistem
- tabel
- tim
- Teknis
- sementara
- pengujian
- bahwa
- Grafik
- Sumber
- mereka
- Mereka
- kemudian
- Ini
- mereka
- ini
- Melalui
- waktu
- untuk
- bersama
- alat
- kota
- transaksional
- Perjalanan
- URL
- menggunakan
- bekas
- menggunakan
- kegunaan
- dimanfaatkan
- Memanfaatkan
- Berharga
- melalui
- Gudang
- adalah
- Cara..
- we
- jaringan
- layanan web
- adalah
- sementara
- dengan
- dalam
- Kerja
- bekerja sama
- alur kerja
- Alur kerja
- kerja
- menulis
- tahun
- menghasilkan
- kamu
- Anda
- zephyrnet.dll
- nol