Postingan ini ditulis bersama Pramod Nayak, LakshmiKanth Mannem, dan Vivek Aggarwal dari Grup Latensi Rendah LSEG.
Analisis biaya transaksi (TCA) banyak digunakan oleh para pedagang, manajer portofolio, dan broker untuk analisis pra-perdagangan dan pasca-perdagangan, dan membantu mereka mengukur dan mengoptimalkan biaya transaksi dan efektivitas strategi perdagangan mereka. Dalam posting ini, kami menganalisis opsi bid-ask spread dari Riwayat Centang LSEG – PCAP kumpulan data menggunakan Amazon Athena untuk Apache Spark. Kami menunjukkan kepada Anda cara mengakses data, menentukan fungsi kustom untuk diterapkan pada data, mengkueri dan memfilter kumpulan data, dan memvisualisasikan hasil analisis, semuanya tanpa harus khawatir menyiapkan infrastruktur atau mengonfigurasi Spark, bahkan untuk kumpulan data besar.
Latar Belakang
Otoritas Pelaporan Harga Opsi (OPRA) berfungsi sebagai pemroses informasi sekuritas yang penting, mengumpulkan, mengkonsolidasikan, dan menyebarkan laporan penjualan terakhir, penawaran harga, dan informasi terkait untuk Opsi AS. Dengan 18 bursa Opsi AS yang aktif dan lebih dari 1.5 juta kontrak yang memenuhi syarat, OPRA memainkan peran penting dalam menyediakan data pasar yang komprehensif.
Pada tanggal 5 Februari 2024, Securities Industry Automation Corporation (SIAC) akan meningkatkan feed OPRA dari 48 menjadi 96 saluran multicast. Peningkatan ini bertujuan untuk mengoptimalkan distribusi simbol dan pemanfaatan kapasitas jalur sebagai respons terhadap meningkatnya aktivitas perdagangan dan volatilitas di pasar opsi AS. SIAC telah merekomendasikan agar perusahaan bersiap menghadapi kecepatan data puncak hingga 37.3 GBits per detik.
Meskipun peningkatan ini tidak serta merta mengubah total volume data yang dipublikasikan, hal ini memungkinkan OPRA untuk menyebarkan data dengan kecepatan yang jauh lebih cepat. Transisi ini sangat penting untuk memenuhi tuntutan pasar opsi yang dinamis.
OPRA menonjol sebagai salah satu feed yang paling banyak jumlahnya, dengan puncak 150.4 miliar pesan dalam satu hari pada Q3 2023 dan kebutuhan kapasitas headroom sebesar 400 miliar pesan dalam satu hari. Menangkap setiap pesan sangat penting untuk analisis biaya transaksi, pemantauan likuiditas pasar, evaluasi strategi perdagangan, dan riset pasar.
Tentang data
Riwayat Centang LSEG – PCAP adalah repositori berbasis cloud, melebihi 30 PB, menampung data pasar global berkualitas sangat tinggi. Data ini ditangkap dengan cermat langsung di dalam pusat data pertukaran, menggunakan proses pengambilan redundan yang ditempatkan secara strategis di pusat data pertukaran utama dan cadangan di seluruh dunia. Teknologi penangkapan LSEG memastikan pengambilan data tanpa kehilangan dan menggunakan sumber waktu GPS untuk ketepatan cap waktu nanodetik. Selain itu, teknik arbitrase data yang canggih digunakan untuk mengisi kesenjangan data dengan lancar. Setelah ditangkap, data menjalani pemrosesan dan arbitrase yang cermat, dan kemudian dinormalisasi ke dalam format Parket menggunakan Ultra Langsung Waktu Nyata LSEG (RTUD) penangan pakan.
Proses normalisasi, yang merupakan bagian integral dalam mempersiapkan data untuk analisis, menghasilkan hingga 6 TB file Parket terkompresi per hari. Volume data yang sangat besar disebabkan oleh sifat OPRA yang mencakup banyak pertukaran, dan menampilkan banyak kontrak opsi yang ditandai dengan beragam atribut. Meningkatnya volatilitas pasar dan aktivitas pembuatan pasar di bursa opsi semakin berkontribusi terhadap volume data yang dipublikasikan di OPRA.
Atribut Tick History – PCAP memungkinkan perusahaan melakukan berbagai analisis, termasuk yang berikut:
- Analisis pra-perdagangan – Mengevaluasi potensi dampak perdagangan dan mengeksplorasi berbagai strategi eksekusi berdasarkan data historis
- Evaluasi pasca-perdagangan – Mengukur biaya eksekusi aktual terhadap tolok ukur untuk menilai kinerja strategi eksekusi
- Dioptimalkan eksekusi – Menyempurnakan strategi eksekusi berdasarkan pola pasar historis untuk meminimalkan dampak pasar dan mengurangi biaya perdagangan secara keseluruhan
- Manajemen risiko – Identifikasi pola slippage, identifikasi outlier, dan kelola risiko yang terkait dengan aktivitas perdagangan secara proaktif
- Atribusi kinerja – Pisahkan dampak keputusan perdagangan dari keputusan investasi saat menganalisis kinerja portofolio
Riwayat Kutu LSEG – kumpulan data PCAP tersedia di Pertukaran Data AWS dan dapat diakses di Pasar AWS. Dengan AWS Pertukaran Data untuk Amazon S3, Anda dapat mengakses data PCAP langsung dari LSEG Layanan Penyimpanan Sederhana Amazon (Amazon S3), menghilangkan kebutuhan bagi perusahaan untuk menyimpan salinan data mereka sendiri. Pendekatan ini menyederhanakan pengelolaan dan penyimpanan data, memberikan klien akses langsung ke PCAP berkualitas tinggi atau data yang dinormalisasi dengan kemudahan penggunaan, integrasi, dan penghematan penyimpanan data yang besar.
Athena untuk Apache Spark
Untuk upaya analitis, Athena untuk Apache Spark menawarkan pengalaman notebook sederhana yang dapat diakses melalui konsol Athena atau API Athena, memungkinkan Anda membuat aplikasi Apache Spark interaktif. Dengan runtime Spark yang dioptimalkan, Athena membantu analisis data berukuran petabyte dengan menskalakan jumlah mesin Spark secara dinamis kurang dari satu detik. Selain itu, pustaka Python umum seperti pandas dan NumPy terintegrasi dengan mulus, memungkinkan pembuatan logika aplikasi yang rumit. Fleksibilitasnya mencakup impor pustaka kustom untuk digunakan di buku catatan. Athena for Spark mengakomodasi sebagian besar format data terbuka dan terintegrasi secara mulus dengan Lem AWS Katalog Data.
Dataset
Untuk analisis ini, kami menggunakan kumpulan data LSEG Tick History – PCAP OPRA mulai 17 Mei 2023. Kumpulan data ini terdiri dari komponen-komponen berikut:
- Tawaran dan penawaran terbaik (BBO) – Melaporkan tawaran tertinggi dan permintaan terendah untuk sekuritas di bursa tertentu
- Penawaran dan Penawaran Terbaik Nasional (NBBO) – Melaporkan tawaran tertinggi dan permintaan keamanan terendah di semua bursa
- Trades – Catatan menyelesaikan perdagangan di semua bursa
Himpunan data melibatkan volume data berikut:
- Trades – 160 MB didistribusikan ke sekitar 60 file Parket terkompresi
- BBO – 2.4 TB didistribusikan ke sekitar 300 file Parket terkompresi
- NBCO – 2.8 TB didistribusikan ke sekitar 200 file Parket terkompresi
Ikhtisar analisis
Menganalisis data Riwayat Tick OPRA untuk Analisis Biaya Transaksi (TCA) melibatkan penelitian kuotasi pasar dan perdagangan seputar peristiwa perdagangan tertentu. Kami menggunakan metrik berikut sebagai bagian dari penelitian ini:
- Spread yang dikutip (QS) – Dihitung sebagai selisih antara permintaan BBO dan tawaran BBO
- Penyebaran efektif (ES) – Dihitung sebagai selisih antara harga perdagangan dan titik tengah BBO (BBO bid + (BBO ask – BBO bid)/2)
- Spread efektif/dikutip (EQF) – Dihitung sebagai (ES / QS) * 100
Kami menghitung spread ini sebelum perdagangan dan juga pada empat interval setelah perdagangan (tepat setelahnya, 1 detik, 10 detik, dan 60 detik setelah perdagangan).
Konfigurasikan Athena untuk Apache Spark
Untuk mengonfigurasi Athena untuk Apache Spark, selesaikan langkah-langkah berikut:
- Di konsol Athena, di bawah Get started, pilih Analisis data Anda menggunakan PySpark dan Spark SQL.
- Jika ini pertama kalinya Anda menggunakan Athena Spark, pilih Buat grup kerja.

- Untuk Nama grup kerja¸ masukkan nama untuk kelompok kerja, misalnya
tca-analysis. - Dalam majalah Mesin analitik bagian, pilih Apache Spark.
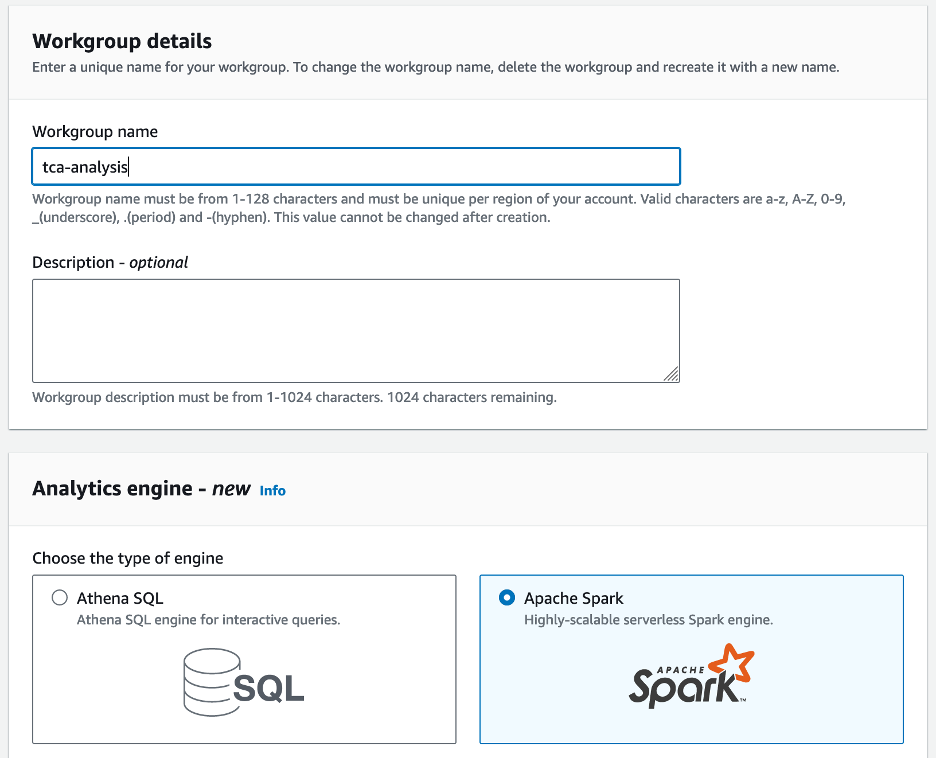
- Dalam majalah Konfigurasi tambahan bagian, Anda dapat memilih Gunakan default atau memberikan kebiasaan Identitas AWS dan Manajemen Akses (IAM) role dan lokasi Amazon S3 untuk hasil perhitungan.
- Pilih Buat grup kerja.
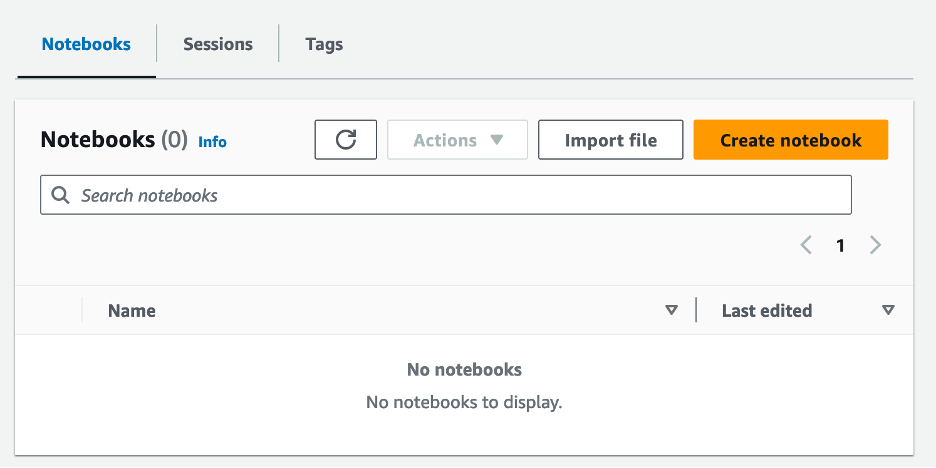
- Setelah Anda membuat grup kerja, navigasikan ke notebook tab dan pilih Buat buku catatan.
- Masukkan nama untuk buku catatan Anda, misalnya
tca-analysis-with-tick-history. - Pilih membuat untuk membuat buku catatan Anda.
Luncurkan buku catatan Anda
Jika Anda sudah membuat grup kerja Spark, pilih Luncurkan editor buku catatan bawah Get started.
![]()
Setelah buku catatan Anda dibuat, Anda akan diarahkan ke editor buku catatan interaktif.
![]()
Sekarang kita dapat menambahkan dan menjalankan kode berikut ke notebook kita.
Buat analisis
Selesaikan langkah-langkah berikut untuk membuat analisis:
- Impor perpustakaan umum:
- Buat bingkai data kami untuk BBO, NBBO, dan perdagangan:
- Sekarang kita dapat mengidentifikasi perdagangan yang akan digunakan untuk analisis biaya transaksi:
Kami mendapatkan output berikut:
Kami menggunakan informasi perdagangan yang disorot ke depan untuk produk perdagangan (tp), harga perdagangan (tpr), dan waktu perdagangan (tt).
- Di sini kami membuat sejumlah fungsi pembantu untuk analisis kami
- Dalam fungsi berikut, kami membuat kumpulan data yang berisi semua kutipan sebelum dan sesudah perdagangan. Athena Spark secara otomatis menentukan berapa banyak DPU yang akan diluncurkan untuk memproses kumpulan data kami.
- Sekarang mari kita panggil fungsi analisis TCA dengan informasi dari perdagangan pilihan kita:
Visualisasikan hasil analisis
Sekarang mari kita buat bingkai data yang kita gunakan untuk visualisasi kita. Setiap bingkai data berisi kutipan untuk salah satu dari lima interval waktu untuk setiap umpan data (BBO, NBBO):
Di bagian berikut, kami memberikan contoh kode untuk membuat visualisasi yang berbeda.
Plot QS dan NBBO sebelum perdagangan
Gunakan kode berikut untuk memplot spread dan NBBO yang dikutip sebelum perdagangan:
![]()
Plot QS untuk setiap pasar dan NBBO setelah perdagangan
Gunakan kode berikut untuk memplot spread yang dikutip untuk setiap pasar dan NBBO segera setelah perdagangan:
![]()
Plot QS untuk setiap interval waktu dan setiap pasar untuk BBO
Gunakan kode berikut untuk memplot spread yang dikutip untuk setiap interval waktu dan setiap pasar untuk BBO:
![]()
Plot ES untuk setiap interval waktu dan pasar untuk BBO
Gunakan kode berikut untuk memplot spread efektif untuk setiap interval waktu dan pasar BBO:
Plot EQF untuk setiap interval waktu dan pasar untuk BBO
Gunakan kode berikut untuk memplot spread efektif/kuotasi untuk setiap interval waktu dan pasar untuk BBO:
Kinerja perhitungan Athena Spark
Saat Anda menjalankan blok kode, Athena Spark secara otomatis menentukan berapa banyak DPU yang diperlukan untuk menyelesaikan penghitungan. Di blok kode terakhir, tempat kita memanggil tca_analysis fungsi, kami sebenarnya menginstruksikan Spark untuk memproses data, dan kami kemudian mengubah kerangka data Spark yang dihasilkan menjadi kerangka data Pandas. Ini merupakan bagian pemrosesan analisis yang paling intensif, dan ketika Athena Spark menjalankan blok ini, blok ini menunjukkan bilah kemajuan, waktu yang berlalu, dan berapa banyak DPU yang memproses data saat ini. Misalnya pada perhitungan berikut, Athena Spark menggunakan 18 DPU.
![]()
Saat mengonfigurasi notebook Athena Spark, Anda memiliki opsi untuk mengatur jumlah maksimum DPU yang dapat digunakan. Defaultnya adalah 20 DPU, namun kami menguji perhitungan ini dengan 10, 20, dan 40 DPU untuk menunjukkan bagaimana Athena Spark secara otomatis menskalakan untuk menjalankan analisis kami. Kami mengamati bahwa Athena Spark menskalakan secara linier, memerlukan waktu 15 menit dan 21 detik saat notebook dikonfigurasi dengan maksimum 10 DPU, 8 menit dan 23 detik saat notebook dikonfigurasi dengan 20 DPU, dan 4 menit dan 44 detik saat notebook dikonfigurasi. dikonfigurasi dengan 40 DPU. Karena Athena Spark mengenakan biaya berdasarkan penggunaan DPU, dengan rincian per detik, biaya penghitungan ini serupa, namun jika Anda menetapkan nilai DPU maksimum yang lebih tinggi, Athena Spark dapat mengembalikan hasil analisis lebih cepat. Untuk detail lebih lanjut mengenai harga Athena Spark silakan klik di sini.
Kesimpulan
Dalam postingan ini, kami mendemonstrasikan bagaimana Anda dapat menggunakan data OPRA dengan fidelitas tinggi dari Tick History-PCAP LSEG untuk melakukan analisis biaya transaksi menggunakan Athena Spark. Ketersediaan data OPRA secara tepat waktu, dilengkapi dengan inovasi aksesibilitas AWS Data Exchange untuk Amazon S3, secara strategis mengurangi waktu analisis bagi perusahaan yang ingin menciptakan wawasan yang dapat ditindaklanjuti untuk keputusan perdagangan penting. OPRA menghasilkan sekitar 7 TB data Parket yang dinormalisasi setiap hari, dan mengelola infrastruktur untuk menyediakan analisis berdasarkan data OPRA merupakan suatu tantangan.
Skalabilitas Athena dalam menangani pemrosesan data berskala besar untuk Tick History – PCAP untuk data OPRA menjadikannya pilihan menarik bagi organisasi yang mencari solusi analitik yang cepat dan terukur di AWS. Postingan ini menunjukkan interaksi yang mulus antara ekosistem AWS dan data Tick History-PCAP dan bagaimana lembaga keuangan dapat memanfaatkan sinergi ini untuk mendorong pengambilan keputusan berbasis data untuk strategi perdagangan dan investasi penting.
Tentang Penulis
![]() Pramod Nayak adalah Direktur Manajemen Produk Grup Latensi Rendah di LSEG. Pramod memiliki pengalaman lebih dari 10 tahun di industri teknologi keuangan, dengan fokus pada pengembangan perangkat lunak, analitik, dan manajemen data. Pramod adalah mantan insinyur perangkat lunak dan sangat tertarik dengan data pasar dan perdagangan kuantitatif.
Pramod Nayak adalah Direktur Manajemen Produk Grup Latensi Rendah di LSEG. Pramod memiliki pengalaman lebih dari 10 tahun di industri teknologi keuangan, dengan fokus pada pengembangan perangkat lunak, analitik, dan manajemen data. Pramod adalah mantan insinyur perangkat lunak dan sangat tertarik dengan data pasar dan perdagangan kuantitatif.
![]() LakshmiKanth Mannem adalah Manajer Produk di Grup Latensi Rendah LSEG. Dia berfokus pada produk data dan platform untuk industri data pasar latensi rendah. LakshmiKanth membantu pelanggan membangun solusi paling optimal untuk kebutuhan data pasar mereka.
LakshmiKanth Mannem adalah Manajer Produk di Grup Latensi Rendah LSEG. Dia berfokus pada produk data dan platform untuk industri data pasar latensi rendah. LakshmiKanth membantu pelanggan membangun solusi paling optimal untuk kebutuhan data pasar mereka.
![]() Vivek Aggarwal adalah Insinyur Data Senior di Grup Latensi Rendah LSEG. Vivek berupaya mengembangkan dan memelihara jalur data untuk pemrosesan dan pengiriman umpan data pasar yang ditangkap dan umpan data referensi.
Vivek Aggarwal adalah Insinyur Data Senior di Grup Latensi Rendah LSEG. Vivek berupaya mengembangkan dan memelihara jalur data untuk pemrosesan dan pengiriman umpan data pasar yang ditangkap dan umpan data referensi.
![]() Alket Memushaj adalah Arsitek Utama di tim Pengembangan Pasar Jasa Keuangan di AWS. Alket bertanggung jawab atas strategi teknis, bekerja sama dengan mitra dan pelanggan untuk menerapkan beban kerja pasar modal yang paling menuntut sekalipun ke AWS Cloud.
Alket Memushaj adalah Arsitek Utama di tim Pengembangan Pasar Jasa Keuangan di AWS. Alket bertanggung jawab atas strategi teknis, bekerja sama dengan mitra dan pelanggan untuk menerapkan beban kerja pasar modal yang paling menuntut sekalipun ke AWS Cloud.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Tentang Kami
- mengakses
- diakses
- aksesibilitas
- dapat diakses
- di seluruh
- aktif
- kegiatan
- sebenarnya
- sebenarnya
- menambahkan
- Selain itu
- menangani
- Keuntungan
- Setelah
- terhadap
- Aggarwal
- bertujuan
- Semua
- Membiarkan
- sudah
- Amazon
- Amazon Athena
- Amazon Web Services
- an
- analisis
- analisis
- Analytical
- analisis
- menganalisa
- menganalisis
- dan
- Apa pun
- Apache
- Apache Spark
- Lebah
- Aplikasi
- aplikasi
- Mendaftar
- pendekatan
- sekitar
- arbitrase
- arbitrasi
- ADALAH
- sekitar
- AS
- meminta
- menilai
- terkait
- At
- atribut
- kewenangan
- secara otomatis
- Otomatisasi
- tersedianya
- tersedia
- AWS
- backup
- bar
- berdasarkan
- BE
- karena
- sebelum
- Benchmark
- TERBAIK
- antara
- tawaran
- Milyar
- Memblokir
- broker
- membangun
- tapi
- by
- menghitung
- dihitung
- perhitungan
- panggilan
- CAN
- Kapasitas
- modal
- Pasar modal
- menangkap
- ditangkap
- Menangkap
- katalog
- Pusat
- menantang
- saluran
- ditandai
- beban
- pilihan
- Pilih
- klien
- awan
- kode
- Mengumpulkan
- Umum
- menarik
- lengkap
- Lengkap
- komponen
- luas
- terdiri dari
- Mengadakan
- dikonfigurasi
- mengkonfigurasi
- konsul
- konsolidasi
- mengandung
- kontrak
- menyumbang
- mengubah
- PERUSAHAAN
- Biaya
- Biaya
- ditulis bersama
- membuat
- dibuat
- penciptaan
- kritis
- sangat penting
- Sekarang
- adat
- pelanggan
- Dash
- data
- Pusat Data
- insinyur data
- Pertukaran data
- manajemen data
- pengolahan data
- penyimpanan data
- Data-driven
- kumpulan data
- hari
- Pengambilan Keputusan
- keputusan
- Default
- menetapkan
- pengiriman
- menuntut
- tuntutan
- mendemonstrasikan
- menunjukkan
- menyebarkan
- rincian
- ditentukan
- berkembang
- Pengembangan
- tim pengembangan
- perbedaan
- berbeda
- langsung
- Kepala
- didistribusikan
- distribusi
- beberapa
- dua kali lipat
- mendorong
- dinamis
- dinamis
- dinamika
- setiap
- memudahkan
- kemudahan penggunaan
- ekosistem
- editor
- Efektif
- efektivitas
- berhak
- menghilangkan
- dipekerjakan
- mempekerjakan
- aktif
- memungkinkan
- meliputi
- usaha keras
- Mesin
- insinyur
- Mesin
- peningkatan
- Memastikan
- Enter
- yg naik perlahan-lahan
- Eter (ETH)
- mengevaluasi
- evaluasi
- Bahkan
- Acara
- Setiap
- contoh
- Pasar Valas
- Bursa
- eksekusi
- pengalaman
- menyelidiki
- ekspres
- Meluas
- lebih cepat
- Menampilkan
- Februari
- Ara
- File
- mengisi
- menyaring
- keuangan
- Lembaga keuangan
- jasa keuangan
- teknologi keuangan
- perusahaan
- Pertama
- pertama kali
- lima
- keluwesan
- berfokus
- berfokus
- berikut
- Untuk
- format
- Bekas
- Depan
- empat
- FRAME
- dari
- fungsi
- fungsi
- lebih lanjut
- kesenjangan
- menghasilkan
- mendapatkan
- diberikan
- Aksi
- pasar global
- Go
- akan
- gps
- Kelompok
- Penanganan
- Memiliki
- memiliki
- he
- ruang utama
- membantu
- berkualitas tinggi
- lebih tinggi
- paling tinggi
- Disorot
- historis
- sejarah
- perumahan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- http
- HTTPS
- IAM
- mengenali
- identitas
- if
- Segera
- segera
- Dampak
- mengimpor
- in
- Termasuk
- Pada meningkat
- industri
- informasi
- Infrastruktur
- inovasi
- wawasan
- lembaga
- integral
- terpadu
- integrasi
- interaksi
- interaktif
- ke
- rumit
- investasi
- melibatkan
- IT
- jpg
- hanya
- besar
- besar-besaran
- Terakhir
- Latensi
- jalankan
- kurang
- perpustakaan
- baris
- Likuiditas
- tempat
- logika
- mencari
- Rendah
- terendah
- mempertahankan
- utama
- MEMBUAT
- Membuat
- mengelola
- pengelolaan
- manajer
- Manajer
- pelaksana
- cara
- banyak
- Pasar
- Data pasar
- dampak pasar
- riset pasar
- Volatilitas pasar
- pembuatan pasar
- pasar
- besar-besaran
- Menguasai
- maksimum
- Mungkin..
- mengukur
- pesan
- pesan
- teliti
- dengan cermat
- Metrik
- juta
- memperkecil
- menit
- pemantauan
- lebih
- Selain itu
- paling
- banyak
- beberapa
- nama
- Alam
- Arahkan
- Perlu
- kebutuhan
- None
- buku catatan
- laptop
- jumlah
- banyak sekali
- mati rasa
- diamati
- of
- menawarkan
- Penawaran
- on
- ONE
- optimal
- Optimize
- dioptimalkan
- pilihan
- Opsi
- or
- organisasi
- kami
- di luar
- keluaran
- lebih
- secara keseluruhan
- sendiri
- panda
- bagian
- rekan
- bergairah
- pola
- Puncak
- untuk
- melakukan
- prestasi
- sangat penting
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- memainkan
- silahkan
- alur
- portofolio
- manajer portofolio
- diposisikan
- Pos
- pasca perdagangan
- potensi
- Ketelitian
- Mempersiapkan
- mempersiapkan
- harga pompa cor beton mini
- di harga
- primer
- Utama
- proses
- proses
- pengolahan
- Prosesor
- Produk
- manajemen Produk
- manajer produk
- Produk
- Kemajuan
- memberikan
- menyediakan
- diterbitkan
- Ular sanca
- Q3
- kuantitatif
- kuantitas
- pertanyaan
- tanda kutip
- Penilaian
- Tarif
- Baca
- nyata
- real-time
- direkomendasikan
- arsip
- Merah
- menurunkan
- mengurangi
- referensi
- refinitiv
- Pelaporan
- laporan
- gudang
- kebutuhan
- membutuhkan
- penelitian
- tanggapan
- tanggung jawab
- mengakibatkan
- dihasilkan
- Hasil
- kembali
- risiko
- Peran
- Run
- berjalan
- penjualan
- Skalabilitas
- terukur
- sisik
- skala
- mulus
- mulus
- Kedua
- detik
- Bagian
- bagian
- Surat-surat berharga
- keamanan
- pencarian
- memilih
- terpilih
- senior
- terpisah
- melayani
- Layanan
- set
- pengaturan
- Menunjukkan
- Pertunjukkan
- signifikan
- mirip
- Sederhana
- disederhanakan
- tunggal
- kelicinan
- Perangkat lunak
- pengembangan perangkat lunak
- Software Engineer
- Solusi
- mutakhir
- ketegangan
- percikan
- tertentu
- penyebaran
- Spread
- berdiri
- Tangga
- penyimpanan
- menyimpan
- Secara strategis
- strategi
- Penyelarasan
- merampingkan
- Belajar
- selanjutnya
- seperti itu
- SWIFT
- simbol
- sinergi
- Mengambil
- pengambilan
- tim
- Teknis
- teknik
- Teknologi
- diuji
- dari
- bahwa
- Grafik
- informasi
- mereka
- Mereka
- kemudian
- Ini
- ini
- Melalui
- tick
- waktu
- tepat waktu
- timestamp
- Judul
- untuk
- Total
- tp
- TPR
- perdagangan
- pedagang
- perdagangan
- Trading
- Perdagangan Strategi
- Strategi perdagangan
- .
- Biaya transaksi
- mengubah
- transisi
- Ultra
- bawah
- mengalami
- meningkatkan
- us
- penggunaan
- menggunakan
- bekas
- kegunaan
- menggunakan
- Memanfaatkan
- nilai
- berbagai
- visualisasi
- membayangkan
- Votalitas
- volume
- volume
- adalah
- we
- jaringan
- layanan web
- ketika
- yang
- sangat
- akan
- dengan
- dalam
- tanpa
- Kelompok Kerja
- kerja
- bekerja
- industri udang di seluruh dunia.
- kuatir
- X
- tahun
- kamu
- Anda
- zephyrnet.dll