Blog ini ditulis bersama Josh Reini, Shayak Sen dan Anupam Datta dari TruEra
Mulai Lompatan Amazon SageMaker menyediakan berbagai model pondasi terlatih seperti Llama-2 dan Mistal 7B yang dapat dengan cepat diterapkan ke titik akhir. Model dasar ini bekerja dengan baik dalam tugas generatif, mulai dari menyusun teks dan ringkasan, menjawab pertanyaan, hingga memproduksi gambar dan video. Meskipun model ini memiliki kemampuan generalisasi yang hebat, sering kali ada kasus penggunaan di mana model ini harus disesuaikan dengan tugas atau domain baru. Salah satu cara untuk mengungkapkan kebutuhan ini adalah dengan mengevaluasi model berdasarkan kumpulan data kebenaran dasar yang telah dikurasi. Setelah kebutuhan untuk mengadaptasi model pondasi jelas, Anda dapat menggunakan serangkaian teknik untuk melaksanakannya. Pendekatan yang populer adalah menyempurnakan model menggunakan kumpulan data yang disesuaikan dengan kasus penggunaan. Penyempurnaan dapat meningkatkan model dasar dan efektivitasnya dapat diukur kembali berdasarkan kumpulan data kebenaran dasar. Ini buku catatan menunjukkan cara menyempurnakan model dengan SageMaker JumpStart.
Salah satu tantangan dalam pendekatan ini adalah pembuatan kumpulan data kebenaran dasar yang dikurasi memerlukan biaya yang mahal. Dalam postingan ini, kami mengatasi tantangan ini dengan melengkapi alur kerja ini dengan kerangka kerja untuk evaluasi otomatis yang dapat diperluas. Kami memulai dengan model landasan dasar dari SageMaker JumpStart dan mengevaluasinya Lensa Tru, perpustakaan sumber terbuka untuk mengevaluasi dan melacak aplikasi model bahasa besar (LLM). Setelah kami mengidentifikasi kebutuhan adaptasi, kami dapat menggunakan penyesuaian di SageMaker JumpStart dan mengonfirmasi peningkatan dengan TruLens.

Evaluasi TruLens menggunakan abstraksi fungsi umpan balik. Fungsi-fungsi ini dapat diimplementasikan dalam beberapa cara, termasuk model gaya BERT, LLM yang diminta dengan tepat, dan banyak lagi. Integrasi TruLens dengan Batuan Dasar Amazon memungkinkan Anda menjalankan evaluasi menggunakan LLM yang tersedia dari Amazon Bedrock. Keandalan infrastruktur Amazon Bedrock sangat berharga untuk digunakan dalam melakukan evaluasi di seluruh pengembangan dan produksi.
Posting ini berfungsi sebagai pengenalan tempat TruEra di tumpukan aplikasi LLM modern dan panduan praktis untuk menggunakan Amazon SageMaker dan TrueEra untuk menyebarkan, menyempurnakan, dan mengulangi aplikasi LLM. Ini selengkapnya buku catatan dengan contoh kode untuk menunjukkan evaluasi kinerja menggunakan TruLens
TruEra di tumpukan aplikasi LLM
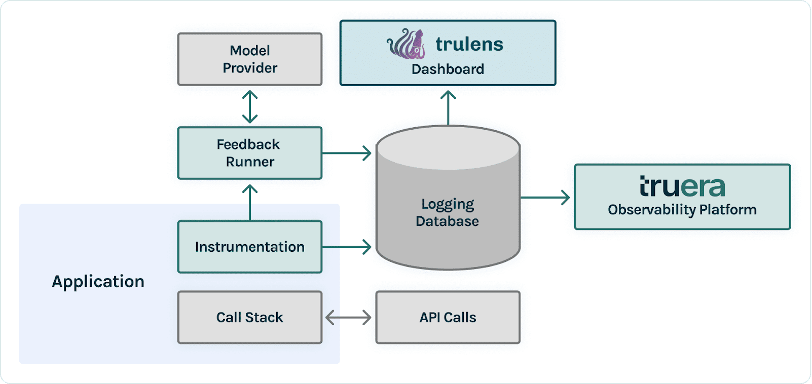
TruEra berada di lapisan observabilitas aplikasi LLM. Meskipun komponen-komponen baru telah masuk ke dalam lapisan komputasi (penyempurnaan, rekayasa cepat, API model) dan lapisan penyimpanan (database vektor), kebutuhan akan kemampuan observasi tetap ada. Kebutuhan ini mencakup pengembangan hingga produksi dan memerlukan kemampuan yang saling berhubungan untuk pengujian, debugging, dan pemantauan produksi, seperti yang diilustrasikan dalam gambar berikut.

Dalam pengembangan, Anda dapat menggunakan TruLens sumber terbuka untuk mengevaluasi, men-debug, dan mengulangi aplikasi LLM di lingkungan Anda dengan cepat. Rangkaian metrik evaluasi yang komprehensif, termasuk metrik berbasis LLM dan metrik tradisional yang tersedia di TruLens, memungkinkan Anda mengukur aplikasi berdasarkan kriteria yang diperlukan untuk memindahkan aplikasi ke produksi.
Dalam produksi, log dan metrik evaluasi ini dapat diproses dalam skala besar dengan pemantauan produksi TruEra. Dengan menghubungkan pemantauan produksi dengan pengujian dan debugging, penurunan kinerja seperti halusinasi, keselamatan, keamanan, dan banyak lagi dapat diidentifikasi dan diperbaiki.
Terapkan model dasar di SageMaker
Anda dapat menerapkan model dasar seperti Llama-2 di SageMaker hanya dengan dua baris kode Python:
Panggil titik akhir model
Setelah penerapan, Anda dapat memanggil titik akhir model yang diterapkan dengan terlebih dahulu membuat payload yang berisi input dan parameter model Anda:
Kemudian Anda cukup meneruskan payload ini ke metode prediksi titik akhir. Perhatikan bahwa Anda harus meneruskan atribut untuk menerima perjanjian lisensi pengguna akhir setiap kali Anda memanggil model:
Evaluasi kinerja dengan TruLens
Sekarang Anda dapat menggunakan TruLens untuk menyiapkan evaluasi Anda. TruLens adalah alat observasi, menawarkan serangkaian fungsi umpan balik yang dapat diperluas untuk melacak dan mengevaluasi aplikasi yang didukung LLM. Fungsi umpan balik sangat penting di sini untuk memverifikasi tidak adanya halusinasi di aplikasi. Fungsi umpan balik ini diterapkan dengan menggunakan model siap pakai dari penyedia seperti Amazon Bedrock. Model Amazon Bedrock merupakan keunggulan di sini karena kualitas dan keandalannya yang terverifikasi. Anda dapat mengatur penyedia dengan TruLens melalui kode berikut:
Dalam contoh ini, kami menggunakan tiga fungsi umpan balik: relevansi jawaban, relevansi konteks, dan landasan. Evaluasi ini dengan cepat menjadi standar untuk deteksi halusinasi dalam aplikasi penjawab pertanyaan yang mendukung konteks dan sangat berguna untuk aplikasi tanpa pengawasan, yang mencakup sebagian besar aplikasi LLM saat ini.

Mari kita bahas masing-masing fungsi umpan balik ini untuk memahami manfaatnya bagi kita.
Relevansi konteks
Konteks adalah masukan penting terhadap kualitas respons aplikasi kita, dan akan berguna untuk memastikan secara terprogram bahwa konteks yang diberikan relevan dengan kueri masukan. Hal ini penting karena konteks ini akan digunakan oleh LLM untuk membentuk jawaban, sehingga informasi yang tidak relevan dalam konteks tersebut dapat dijalin menjadi halusinasi. TruLens memungkinkan Anda mengevaluasi relevansi konteks dengan menggunakan struktur rekaman serial:
Karena konteks yang diberikan kepada LLM adalah langkah paling penting dalam alur Retrieval Augmented Generation (RAG), relevansi konteks sangat penting untuk memahami kualitas pengambilan. Saat bekerja dengan pelanggan lintas sektor, kami telah melihat berbagai mode kegagalan yang diidentifikasi menggunakan evaluasi ini, seperti konteks yang tidak lengkap, konteks yang tidak relevan, atau bahkan kurangnya konteks yang tersedia. Dengan mengidentifikasi sifat mode kegagalan ini, pengguna kami dapat menyesuaikan pengindeksan mereka (seperti model penyematan dan pengelompokan) dan strategi pengambilan (seperti jendela kalimat dan penggabungan otomatis) untuk mengurangi masalah ini.
membumi
Setelah konteks diambil, kemudian dibentuk menjadi jawaban oleh LLM. LLM sering kali cenderung menyimpang dari fakta yang diberikan, melebih-lebihkan atau memperluas jawaban yang terdengar benar. Untuk memverifikasi kebenaran permohonan, Anda harus memisahkan respons ke dalam pernyataan terpisah dan secara independen mencari bukti yang mendukung masing-masing pernyataan dalam konteks yang diambil.
Permasalahan yang bersifat membumi seringkali merupakan dampak hilir dari relevansi konteks. Ketika LLM tidak memiliki konteks yang memadai untuk membentuk respons berbasis bukti, LLM cenderung berhalusinasi dalam upaya menghasilkan respons yang masuk akal. Bahkan dalam kasus di mana konteks yang lengkap dan relevan diberikan, LLM dapat terjerumus ke dalam masalah yang bersifat membumi. Khususnya, hal ini terjadi dalam aplikasi di mana LLM merespons dengan gaya tertentu atau digunakan untuk menyelesaikan tugas yang tidak cocok untuknya. Evaluasi landasan memungkinkan pengguna TruLens untuk memecah respons LLM klaim demi klaim untuk memahami di mana LLM paling sering berhalusinasi. Melakukan hal ini terbukti sangat berguna untuk menjelaskan jalan ke depan dalam menghilangkan halusinasi melalui perubahan sisi model (seperti dorongan, pilihan model, dan parameter model).
Relevansi jawaban
Terakhir, responsnya masih perlu menjawab pertanyaan awal dengan membantu. Anda dapat memverifikasi ini dengan mengevaluasi relevansi respons akhir terhadap masukan pengguna:
Dengan mencapai evaluasi yang memuaskan untuk triad ini, Anda dapat membuat pernyataan yang berbeda tentang kebenaran aplikasi Anda; aplikasi ini diverifikasi bebas halusinasi hingga batas basis pengetahuannya. Dengan kata lain, jika database vektor hanya berisi informasi akurat, maka jawaban yang diberikan oleh aplikasi penjawab pertanyaan berkemampuan konteks juga akurat.
Evaluasi kebenaran dasar
Selain fungsi umpan balik untuk mendeteksi halusinasi, kami memiliki kumpulan data pengujian, DataBricks-Dolly-15k, yang memungkinkan kami menambahkan kesamaan kebenaran dasar sebagai metrik evaluasi keempat. Lihat kode berikut:
Bangun aplikasinya
Setelah Anda menyiapkan evaluator, Anda dapat membangun aplikasi Anda. Dalam contoh ini, kami menggunakan aplikasi QA yang mendukung konteks. Dalam aplikasi ini, berikan instruksi dan konteks ke mesin penyelesaian:
Setelah Anda membuat aplikasi dan fungsi umpan balik, Anda dapat dengan mudah membuat aplikasi terbungkus dengan TruLens. Aplikasi yang dibungkus ini, yang kami beri nama base_recorder, akan mencatat dan mengevaluasi aplikasi setiap kali dipanggil:
Hasil dengan basis Llama-2
Setelah Anda menjalankan aplikasi pada setiap catatan dalam kumpulan data pengujian, Anda dapat melihat hasilnya di buku catatan SageMaker Anda dengan tru.get_leaderboard(). Tangkapan layar berikut menunjukkan hasil evaluasi. Relevansi jawaban sangat rendah, yang menunjukkan bahwa model kesulitan untuk mengikuti instruksi yang diberikan secara konsisten.

Sempurnakan Llama-2 menggunakan SageMaker Jumpstart
Langkah-langkah untuk menyempurnakan model Llama-2 menggunakan SageMaker Jumpstart juga disediakan di sini buku catatan.
Untuk menyiapkan penyesuaian, Anda perlu mengunduh set pelatihan terlebih dahulu dan menyiapkan templat untuk mendapatkan petunjuk
Kemudian, unggah kumpulan data dan instruksi ke Layanan Penyimpanan Sederhana Amazon Bucket (Amazon S3) untuk pelatihan:
Untuk menyempurnakan SageMaker, Anda dapat menggunakan SageMaker JumpStart Estimator. Kami kebanyakan menggunakan hyperparameter default di sini, kecuali kami menyetel penyetelan instruksi ke true:
Setelah melatih model, Anda dapat menerapkannya dan membuat aplikasi seperti yang Anda lakukan sebelumnya:
Evaluasi model yang telah disesuaikan
Anda dapat menjalankan model itu lagi pada set pengujian Anda dan melihat hasilnya, kali ini dibandingkan dengan basis Llama-2:

Model Llama-2 yang baru dan telah disempurnakan telah mengalami peningkatan besar dalam hal relevansi dan landasan jawaban, serta kemiripannya dengan rangkaian pengujian kebenaran dasar. Peningkatan kualitas yang besar ini mengakibatkan sedikit peningkatan latensi. Peningkatan latensi ini merupakan akibat langsung dari penyempurnaan peningkatan ukuran model.
Anda tidak hanya dapat melihat hasil ini di buku catatan, namun Anda juga dapat menjelajahi hasil di UI TruLens dengan menjalankan tru.run_dashboard(). Melakukan hal ini dapat memberikan hasil agregat yang sama pada halaman papan peringkat, namun juga memberi Anda kemampuan untuk menyelami lebih dalam catatan bermasalah dan mengidentifikasi mode kegagalan aplikasi.

Untuk memahami peningkatan aplikasi pada tingkat rekor, Anda dapat berpindah ke halaman evaluasi dan memeriksa skor masukan pada tingkat yang lebih terperinci.
Misalnya, jika Anda menanyakan pertanyaan kepada LLM dasar, “Apa mesin flat six Porsche yang paling bertenaga”, model tersebut akan berhalusinasi sebagai berikut.

Selain itu, Anda dapat memeriksa evaluasi terprogram dari catatan ini untuk memahami kinerja aplikasi terhadap setiap fungsi umpan balik yang telah Anda tetapkan. Dengan memeriksa hasil umpan balik groundedness di TruLens, Anda dapat melihat rincian bukti yang tersedia untuk mendukung setiap klaim yang dibuat oleh LLM.

Jika Anda mengekspor rekaman yang sama untuk LLM yang telah Anda sesuaikan di TruLens, Anda dapat melihat bahwa penyesuaian dengan SageMaker JumpStart secara signifikan meningkatkan landasan respons.

Dengan menggunakan alur kerja evaluasi otomatis dengan TruLens, Anda dapat mengukur aplikasi Anda di serangkaian metrik yang lebih luas untuk lebih memahami kinerjanya. Yang penting, Anda sekarang dapat memahami kinerja ini secara dinamis untuk kasus penggunaan apa pun—bahkan kasus penggunaan yang belum Anda kumpulkan kebenaran dasarnya.
Cara kerja TruLens
Setelah membuat prototipe aplikasi LLM, Anda dapat mengintegrasikan TruLens (ditampilkan sebelumnya) untuk melengkapi tumpukan panggilannya. Setelah tumpukan panggilan diinstrumentasi, tumpukan panggilan tersebut kemudian dapat dicatat setiap kali dijalankan ke database logging yang ada di lingkungan Anda.
Selain kemampuan instrumentasi dan logging, evaluasi adalah komponen nilai inti bagi pengguna TruLens. Evaluasi ini diterapkan di TruLens melalui fungsi umpan balik untuk dijalankan di atas tumpukan panggilan terinstrumentasi Anda, dan pada gilirannya memanggil penyedia model eksternal untuk menghasilkan umpan balik itu sendiri.
Setelah inferensi umpan balik, hasil umpan balik ditulis ke database logging, dari mana Anda dapat menjalankan dasbor TruLens. Dasbor TruLens, yang berjalan di lingkungan Anda, memungkinkan Anda menjelajahi, mengulangi, dan men-debug aplikasi LLM Anda.
Dalam skala besar, catatan dan evaluasi ini dapat dikirim ke TruEra kemampuan observasi produksi yang dapat memproses jutaan pengamatan dalam satu menit. Dengan menggunakan Platform Observabilitas TruEra, Anda dapat dengan cepat mendeteksi halusinasi dan masalah kinerja lainnya, dan memperbesar satu catatan dalam hitungan detik dengan diagnostik terintegrasi. Beralih ke sudut pandang diagnostik memungkinkan Anda dengan mudah mengidentifikasi dan memitigasi mode kegagalan untuk aplikasi LLM Anda seperti halusinasi, kualitas pengambilan yang buruk, masalah keamanan, dan banyak lagi.
Evaluasi tanggapan yang jujur, tidak berbahaya, dan bermanfaat
Dengan mencapai evaluasi yang memuaskan untuk triad ini, Anda dapat mencapai tingkat keyakinan yang lebih tinggi terhadap kebenaran tanggapan yang diberikan. Selain kebenarannya, TruLens memiliki dukungan luas untuk evaluasi yang diperlukan untuk memahami kinerja LLM Anda pada poros “Jujur, Tidak Berbahaya, dan Bermanfaat.” Pengguna kami mendapat banyak manfaat dari kemampuan untuk mengidentifikasi tidak hanya halusinasi seperti yang telah kita bahas sebelumnya, namun juga masalah terkait keselamatan, keamanan, kecocokan bahasa, koherensi, dan banyak lagi. Ini semua adalah masalah dunia nyata yang dihadapi pengembang aplikasi LLM, dan dapat diidentifikasi langsung dengan TruLens.

Kesimpulan
Postingan ini membahas bagaimana Anda dapat mempercepat produksi aplikasi AI dan menggunakan model dasar di organisasi Anda. Dengan SageMaker JumpStart, Amazon Bedrock, dan TruEra, Anda dapat menerapkan, menyempurnakan, dan melakukan iterasi pada model dasar untuk aplikasi LLM Anda. Lihat ini link untuk mengetahui lebih lanjut tentang TruEra dan mencoba buku catatan dirimu sendiri.
Tentang penulis
 Josh Reini adalah kontributor inti TruLens sumber terbuka dan Ilmuwan Data Hubungan Pengembang pendiri di TruEra di mana dia bertanggung jawab atas inisiatif pendidikan dan membina komunitas praktisi Kualitas AI yang berkembang.
Josh Reini adalah kontributor inti TruLens sumber terbuka dan Ilmuwan Data Hubungan Pengembang pendiri di TruEra di mana dia bertanggung jawab atas inisiatif pendidikan dan membina komunitas praktisi Kualitas AI yang berkembang.
 Shayak Sen adalah CTO & Salah Satu Pendiri TruEra. Shayak fokus membangun sistem dan memimpin penelitian untuk membuat sistem pembelajaran mesin lebih mudah dijelaskan, mematuhi privasi, dan adil.
Shayak Sen adalah CTO & Salah Satu Pendiri TruEra. Shayak fokus membangun sistem dan memimpin penelitian untuk membuat sistem pembelajaran mesin lebih mudah dijelaskan, mematuhi privasi, dan adil.
 Anupam Datta adalah Salah Satu Pendiri, Presiden, dan Kepala Ilmuwan TruEra. Sebelum TruEra, ia menghabiskan 15 tahun di fakultas di Carnegie Mellon University (2007-22), terakhir sebagai Profesor tetap di bidang Teknik Elektro & Komputer dan Ilmu Komputer.
Anupam Datta adalah Salah Satu Pendiri, Presiden, dan Kepala Ilmuwan TruEra. Sebelum TruEra, ia menghabiskan 15 tahun di fakultas di Carnegie Mellon University (2007-22), terakhir sebagai Profesor tetap di bidang Teknik Elektro & Komputer dan Ilmu Komputer.
 Vivek Gangasani adalah Arsitek Solusi Startup AI/ML untuk startup AI Generatif di AWS. Dia membantu startup GenAI yang sedang berkembang membangun solusi inovatif menggunakan layanan AWS dan akselerasi komputasi. Saat ini, dia fokus pada pengembangan strategi untuk menyempurnakan dan mengoptimalkan kinerja inferensi Model Bahasa Besar. Di waktu luangnya, Vivek menikmati hiking, menonton film, dan mencoba berbagai masakan.
Vivek Gangasani adalah Arsitek Solusi Startup AI/ML untuk startup AI Generatif di AWS. Dia membantu startup GenAI yang sedang berkembang membangun solusi inovatif menggunakan layanan AWS dan akselerasi komputasi. Saat ini, dia fokus pada pengembangan strategi untuk menyempurnakan dan mengoptimalkan kinerja inferensi Model Bahasa Besar. Di waktu luangnya, Vivek menikmati hiking, menonton film, dan mencoba berbagai masakan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/deploy-foundation-models-with-amazon-sagemaker-iterate-and-monitor-with-truera/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 11
- 12
- 120
- 125
- 14
- 15 tahun
- 15%
- 16
- 179
- 72
- 8
- 9
- a
- kemampuan
- Sanggup
- Tentang Kami
- abstraksi
- mempercepat
- dipercepat
- Setuju
- tepat
- di seluruh
- menyesuaikan
- adaptasi
- disesuaikan
- menambahkan
- tambahan
- alamat
- Keuntungan
- Setelah
- lagi
- terhadap
- Persetujuan
- AI
- AI / ML
- Semua
- mengizinkan
- memungkinkan
- sepanjang
- juga
- Meskipun
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- dan
- menjawab
- jawaban
- Apa pun
- Lebah
- aplikasi
- Aplikasi
- aplikasi
- pendekatan
- tepat
- aplikasi
- ADALAH
- AS
- meminta
- At
- usaha
- ditambah
- Otomatis
- tersedia
- AWS
- Sumbu
- mendasarkan
- Dasar
- BE
- karena
- menjadi
- sebelum
- makhluk
- Percaya
- di bawah
- manfaat
- Lebih baik
- antara
- Luar
- Blog
- kedua
- Kotak
- Istirahat
- Kerusakan
- luas
- membangun
- Bangunan
- tapi
- by
- panggilan
- bernama
- CAN
- kemampuan
- Carnegie Mellon
- Universitas Carnegie Mellon
- membawa
- kasus
- kasus
- Kategori
- menantang
- Perubahan
- Pembayaran
- kepala
- pilihan
- klaim
- kelas
- jelas
- Co-founder
- kode
- koleksi
- Kolom
- datang
- masyarakat
- perbandingan
- lengkap
- Selesaikan
- penyelesaian
- compliant
- komponen
- komponen
- luas
- menghitung
- komputer
- Teknik Komputer
- Komputer Ilmu
- kepercayaan
- Memastikan
- Menghubungkan
- konsekuensial
- secara konsisten
- mengandung
- konteks
- penyumbang
- mengubah
- Core
- kontributor inti
- dikoreksi
- bisa
- menutupi
- membuat
- dibuat
- membuat
- kriteria
- kritis
- CTO
- dikuratori
- Sekarang
- pelanggan
- dasbor
- data
- ilmuwan data
- Basis Data
- database
- kumpulan data
- lebih dalam
- Default
- didefinisikan
- Derajat
- menyebarkan
- dikerahkan
- penyebaran
- menjelaskan
- Meskipun
- terperinci
- menemukan
- Deteksi
- Pengembang
- pengembang
- berkembang
- Pengembangan
- diagnostik
- MELAKUKAN
- berbeda
- langsung
- dibahas
- menyelam
- melakukan
- domain
- turun
- Download
- secara dramatis
- dinamis
- setiap
- Terdahulu
- mudah
- Pendidikan
- efek
- kemanjuran
- menghilangkan
- embedding
- muncul
- memungkinkan
- akhir
- Titik akhir
- Mesin
- Teknik
- memastikan
- Lingkungan Hidup
- terutama
- penting
- Eter (ETH)
- mengevaluasi
- mengevaluasi
- evaluasi
- evaluasi
- Bahkan
- bukti
- memeriksa
- Memeriksa
- contoh
- Kecuali
- memperluas
- mahal
- menyelidiki
- ekspor
- luar
- ekstraksi
- Menghadapi
- fakta
- Kegagalan
- adil
- Jatuh
- palsu
- umpan balik
- Angka
- File
- terakhir
- Menemukan
- akhir
- Pertama
- datar
- terfokus
- mengikuti
- berikut
- Untuk
- bentuk
- dibentuk
- Depan
- Prinsip Dasar
- pembinaan
- Keempat
- Kerangka
- Gratis
- dari
- fungsi
- fungsi
- lebih lanjut
- menghasilkan
- generasi
- generatif
- AI generatif
- memberikan
- Go
- besar
- Tanah
- membimbing
- hands-on
- Memiliki
- he
- bermanfaat
- membantu
- di sini
- lebih tinggi
- mendaki
- -nya
- jujur
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- i
- diidentifikasi
- mengenali
- mengidentifikasi
- if
- yg memperjelas
- gambar
- diimplementasikan
- mengimpor
- penting
- memperbaiki
- ditingkatkan
- perbaikan
- in
- Di lain
- Termasuk
- Meningkatkan
- meningkatkan
- secara mandiri
- Menunjukkan
- informasi
- Infrastruktur
- inisiatif
- inovatif
- memasukkan
- input
- instruksi
- instrumen
- mengintegrasikan
- terpadu
- integrasi
- saling berhubungan
- ke
- Pengantar
- masalah
- IT
- NYA
- Diri
- jpg
- json
- hanya
- kunci
- pengetahuan
- Kekurangan
- bahasa
- besar
- Latensi
- lapisan
- terkemuka
- pengetahuan
- Tingkat
- Perpustakaan
- Lisensi
- Hidup
- Mungkin
- MEMBATASI
- baris
- baris
- Daftar
- hidup
- hidup
- lokal
- mencatat
- login
- penebangan
- Rendah
- mesin
- Mesin belajar
- terbuat
- Mayoritas
- membuat
- secara besar-besaran
- Cocok
- makna
- mengukur
- diukur
- Mellon
- metode
- metrik
- Metrik
- jutaan
- menit
- Mengurangi
- ML
- model
- model
- modern
- mode
- Memantau
- pemantauan
- lebih
- paling
- kebanyakan
- pindah
- bioskop
- bergerak
- harus
- nama
- Alam
- Perlu
- dibutuhkan
- kebutuhan
- New
- berikutnya
- mencatat
- buku catatan
- sekarang
- memelihara
- obyek
- pengamatan
- of
- lepas
- menawarkan
- sering
- on
- ONE
- hanya
- Buka
- open source
- mengoptimalkan
- or
- organisasi
- asli
- Lainnya
- kami
- di luar
- keluaran
- halaman
- dipasangkan
- parameter
- tertentu
- khususnya
- lulus
- melakukan
- prestasi
- melakukan
- pipa saluran
- Tempat
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- masuk akal
- dimainkan
- miskin
- Populer
- Porsche
- Pos
- kuat
- meramalkan
- presiden
- pribadi
- masalah
- proses
- diproses
- menghasilkan
- memproduksi
- Produksi
- Profesor
- terprogram
- memberikan
- disediakan
- pemberi
- penyedia
- menyediakan
- terdorong
- Ular sanca
- Q & A
- kualitas
- pertanyaan
- Pertanyaan
- segera
- acak
- cepat
- mencapai
- mencapai
- dunia nyata
- baru-baru ini
- catatan
- rekaman
- arsip
- hubungan
- relevansi
- relevan
- keandalan
- sisa
- menggantikan
- permintaan
- wajib
- membutuhkan
- penelitian
- tanggapan
- tanggapan
- tanggung jawab
- mengakibatkan
- Hasil
- kembali
- Run
- berjalan
- Safety/keselamatan
- pembuat bijak
- sama
- Skala
- Ilmu
- ilmuwan
- skor
- Pencarian
- detik
- Sektor
- keamanan
- melihat
- terlihat
- memilih
- putusan pengadilan
- terpisah
- melayani
- Layanan
- set
- penyiapan
- beberapa
- harus
- Menunjukkan
- ditunjukkan
- Pertunjukkan
- Sederhana
- hanya
- tunggal
- ENAM
- Ukuran
- So
- Solusi
- sumber
- rentang
- khusus
- menghabiskan
- membagi
- tumpukan
- standar
- awal
- startup
- Startups
- Pernyataan
- Laporan
- Langkah
- Masih
- penyimpanan
- mudah
- strategi
- nyasar
- struktur
- Berjuang
- gaya
- seperti itu
- cukup
- rangkaian
- mendukung
- Mendukung
- Permukaan
- sistem
- disesuaikan
- tugas
- tugas
- teknik
- Template
- uji
- pengujian
- teks
- bahwa
- Grafik
- mereka
- kemudian
- Sana.
- Ini
- mereka
- ini
- itu
- tiga
- berkembang
- Melalui
- Demikian
- waktu
- untuk
- hari ini
- alat
- puncak
- jalur
- Pelacakan
- tradisional
- Pelatihan VE
- terlatih
- Pelatihan
- sangat
- TRU
- benar
- kebenaran
- mencoba
- mencoba
- MENGHIDUPKAN
- dua
- ui
- memahami
- pemahaman
- universitas
- atas
- us
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- menggunakan
- Berharga
- nilai
- variasi
- Luas
- diverifikasi
- memeriksa
- memverifikasi
- melalui
- Video
- View
- W
- menonton
- Cara..
- cara
- we
- jaringan
- layanan web
- BAIK
- ketika
- yang
- lebih luas
- akan
- dengan
- dalam
- kata
- bekerja
- alur kerja
- kerja
- dibungkus
- menulis
- tertulis
- tahun
- kamu
- Anda
- diri
- zephyrnet.dll
- zoom