Banyak organisasi, kecil dan besar, berupaya untuk memigrasikan dan memodernisasi beban kerja analitik mereka di Amazon Web Services (AWS). Ada banyak alasan bagi pelanggan untuk bermigrasi ke AWS, namun salah satu alasan utamanya adalah kemampuan untuk menggunakan layanan yang terkelola sepenuhnya daripada menghabiskan waktu memelihara infrastruktur, patching, pemantauan, pencadangan, dan banyak lagi. Tim kepemimpinan dan pengembangan dapat menghabiskan lebih banyak waktu untuk mengoptimalkan solusi yang ada dan bahkan bereksperimen dengan kasus penggunaan baru, dibandingkan mempertahankan infrastruktur yang ada.
Dengan kemampuan untuk bergerak cepat di AWS, Anda juga harus bertanggung jawab terhadap data yang Anda terima dan proses saat Anda terus melakukan penskalaan. Tanggung jawab ini termasuk mematuhi undang-undang dan peraturan privasi data dan tidak menyimpan atau mengekspos data sensitif seperti informasi identitas pribadi (PII) atau informasi kesehatan yang dilindungi (PHI) dari sumber hulu.
Dalam postingan ini, kami membahas arsitektur tingkat tinggi dan kasus penggunaan spesifik yang menunjukkan bagaimana Anda dapat terus meningkatkan skala platform data organisasi Anda tanpa perlu menghabiskan banyak waktu pengembangan untuk mengatasi masalah privasi data. Kita gunakan Lem AWS untuk mendeteksi, menutupi, dan menyunting data PII sebelum memuatnya Layanan Pencarian Terbuka Amazon.
Ikhtisar solusi
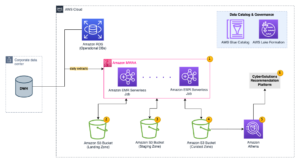
Diagram berikut menggambarkan arsitektur solusi tingkat tinggi. Kami telah mendefinisikan semua lapisan dan komponen desain kami sesuai dengan Lensa Analisis Data Kerangka AWS Well-Architected.
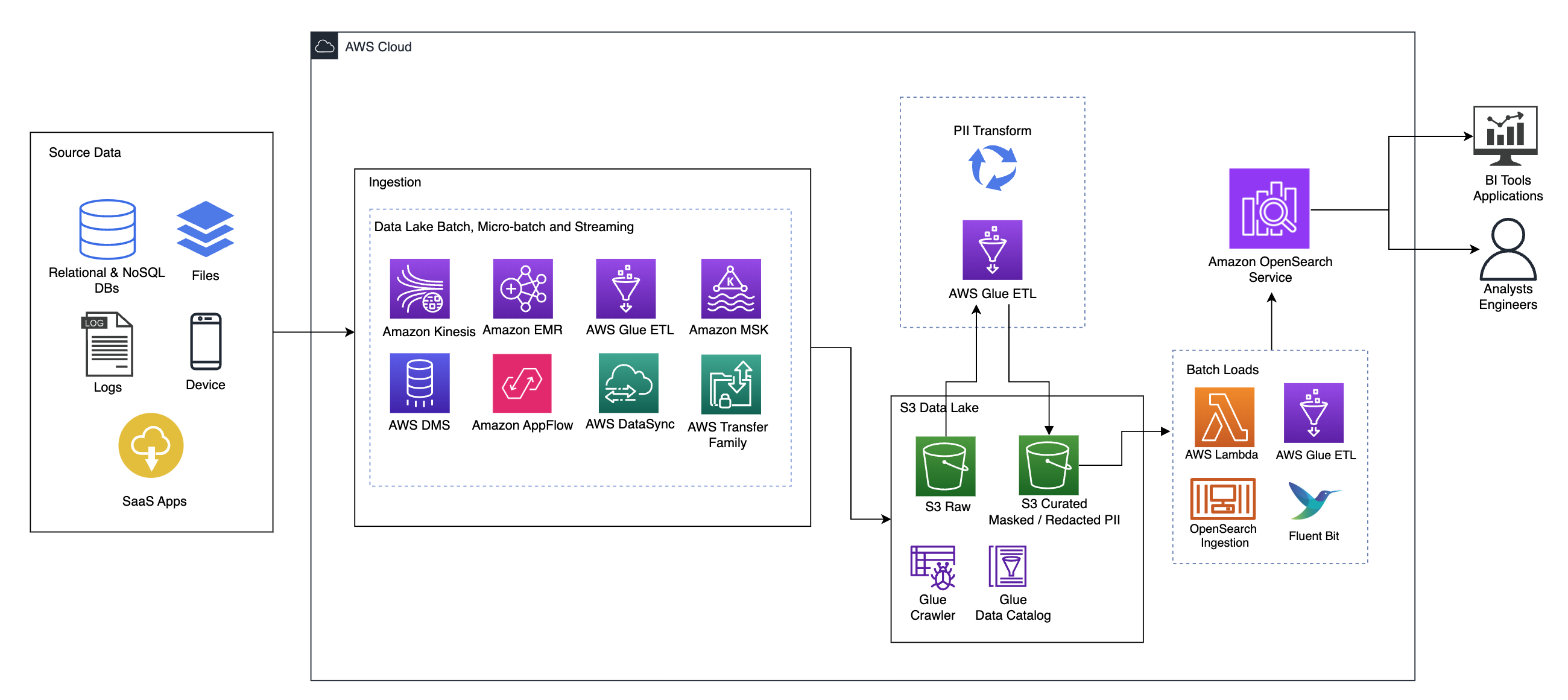
Arsitektur terdiri dari sejumlah komponen:
Sumber data
Data mungkin berasal dari puluhan hingga ratusan sumber, termasuk database, transfer file, log, aplikasi perangkat lunak sebagai layanan (SaaS), dan banyak lagi. Organisasi mungkin tidak selalu memiliki kendali atas data apa yang masuk melalui saluran ini dan ke dalam penyimpanan dan aplikasi hilirnya.
Penyerapan: Kumpulan data lake, kumpulan mikro, dan streaming
Banyak organisasi memasukkan data sumbernya ke dalam data lake dengan berbagai cara, termasuk pekerjaan batch, batch mikro, dan streaming. Misalnya, Amazon ESDM, Lem AWS, dan Layanan Migrasi Database AWS (AWS DMS) semuanya dapat digunakan untuk melakukan operasi batch dan atau streaming yang tenggelam ke data lake Layanan Penyimpanan Sederhana Amazon (Amazon S3). Alur Aplikasi Amazon dapat digunakan untuk mentransfer data dari aplikasi SaaS yang berbeda ke data lake. Sinkronisasi Data AWS dan Keluarga Transfer AWS dapat membantu memindahkan file ke dan dari data lake melalui sejumlah protokol berbeda. Amazon Kinesis dan Amazon MSK juga memiliki kemampuan untuk melakukan streaming data langsung ke data lake di Amazon S3.
Danau data S3
Penggunaan Amazon S3 untuk data lake Anda sejalan dengan strategi data modern. Ini menyediakan penyimpanan berbiaya rendah tanpa mengorbankan kinerja, keandalan, atau ketersediaan. Dengan pendekatan ini, Anda dapat menghadirkan komputasi ke data Anda sesuai kebutuhan dan hanya membayar sesuai kapasitas yang diperlukan untuk menjalankannya.
Dalam arsitektur ini, data mentah dapat berasal dari berbagai sumber (internal dan eksternal), yang mungkin berisi data sensitif.
Dengan menggunakan crawler AWS Glue, kami dapat menemukan dan membuat katalog data, yang akan membangun skema tabel untuk kami, dan pada akhirnya mempermudah penggunaan AWS Glue ETL dengan transformasi PII untuk mendeteksi dan menutupi atau menyunting data sensitif apa pun yang mungkin masuk di danau data.
Konteks bisnis dan kumpulan data
Untuk menunjukkan nilai pendekatan kami, bayangkan Anda adalah bagian dari tim rekayasa data untuk organisasi jasa keuangan. Persyaratan Anda adalah mendeteksi dan menutupi data sensitif saat data tersebut diserap ke dalam lingkungan cloud organisasi Anda. Data akan digunakan oleh proses analitis hilir. Di masa depan, pengguna Anda akan dapat dengan aman mencari riwayat transaksi pembayaran berdasarkan aliran data yang dikumpulkan dari sistem perbankan internal. Hasil pencarian dari tim operasi, pelanggan, dan aplikasi antarmuka harus dimasukkan ke dalam bidang sensitif.
Tabel berikut memperlihatkan struktur data yang digunakan untuk solusi. Untuk kejelasan, kami telah memetakan nama kolom mentah ke nama kolom yang dikurasi. Anda akan melihat bahwa beberapa bidang dalam skema ini dianggap sebagai data sensitif, seperti nama depan, nama belakang, nomor Jaminan Sosial (SSN), alamat, nomor kartu kredit, nomor telepon, email, dan alamat IPv4.
| Nama Kolom Mentah | Nama Kolom yang Dikurasi | Tipe |
| c0 | nama depan | tali |
| c1 | nama keluarga | tali |
| c2 | ssn | tali |
| c3 | alamat | tali |
| c4 | Kode Pos | tali |
| c5 | negara | tali |
| c6 | pembelian_situs | tali |
| c7 | nomor kartu kredit | tali |
| c8 | penyedia_kartu kredit | tali |
| c9 | mata uang | tali |
| c10 | nilai pembelian | bilangan bulat |
| c11 | tanggal transaksi | tanggal |
| c12 | nomor telepon | tali |
| c13 | tali | |
| c14 | ipv4 | tali |
Kasus penggunaan: Deteksi batch PII sebelum memuat ke Layanan OpenSearch
Pelanggan yang menerapkan arsitektur berikut telah membangun data lake mereka di Amazon S3 untuk menjalankan berbagai jenis analitik dalam skala besar. Solusi ini cocok untuk pelanggan yang tidak memerlukan penyerapan waktu nyata ke Layanan OpenSearch dan berencana menggunakan alat integrasi data yang berjalan sesuai jadwal atau dipicu melalui peristiwa.
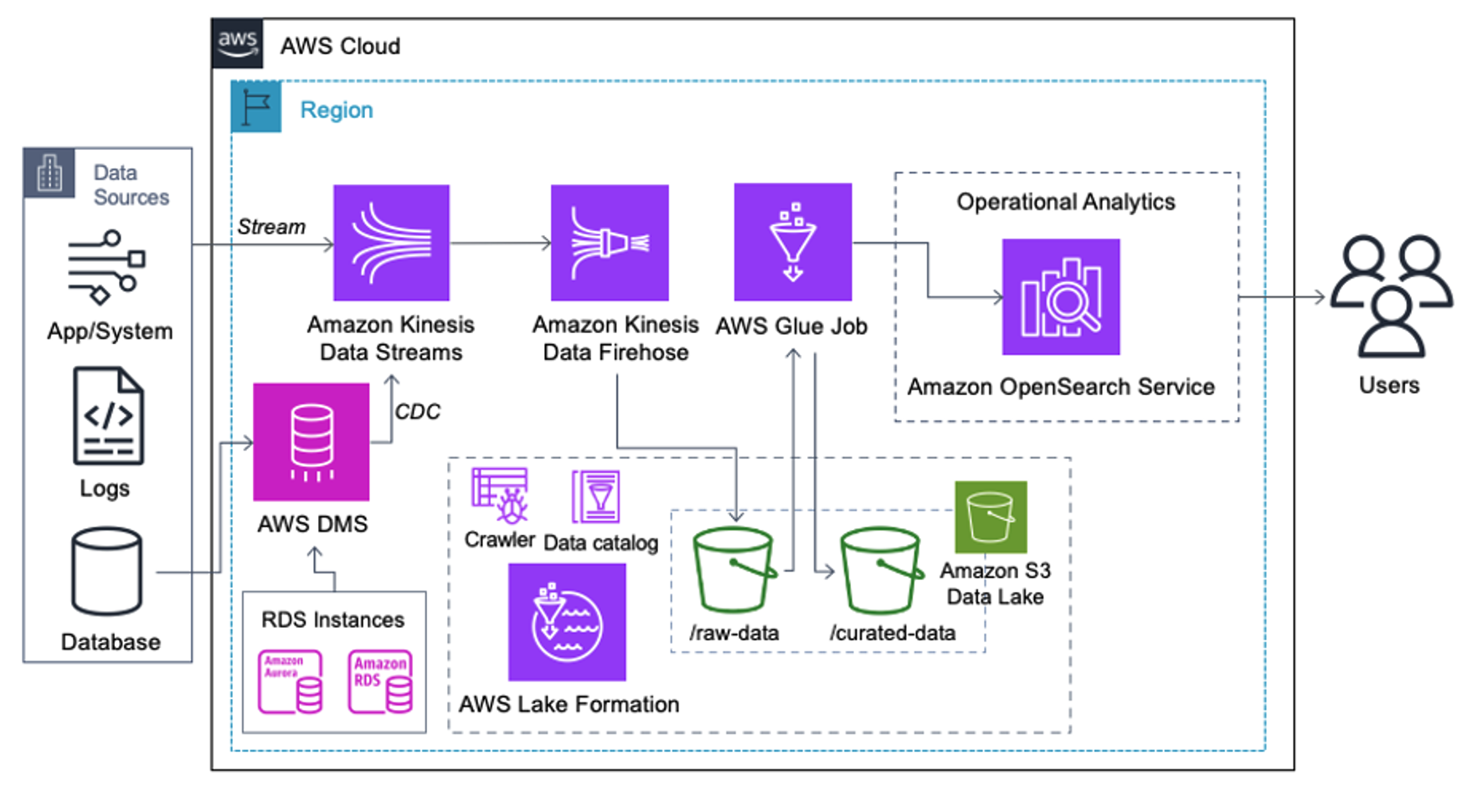
Sebelum rekaman data mendarat di Amazon S3, kami menerapkan lapisan penyerapan untuk membawa semua aliran data ke data lake dengan andal dan aman. Kinesis Data Streams diterapkan sebagai lapisan penyerapan untuk mempercepat pengambilan aliran data terstruktur dan semi-terstruktur. Contohnya adalah perubahan database relasional, aplikasi, log sistem, atau aliran klik. Untuk kasus penggunaan perubahan pengambilan data (CDC), Anda dapat menggunakan Kinesis Data Streams sebagai target untuk AWS DMS. Aplikasi atau sistem yang menghasilkan aliran yang berisi data sensitif dikirim ke aliran data Kinesis melalui salah satu dari tiga metode yang didukung: Amazon Kinesis Agent, AWS SDK for Java, atau Kinesis Producer Library. Sebagai langkah terakhir, Firehose Data Amazon Kinesis membantu kami memuat kumpulan data yang hampir real-time dengan andal ke tujuan data lake S3 kami.
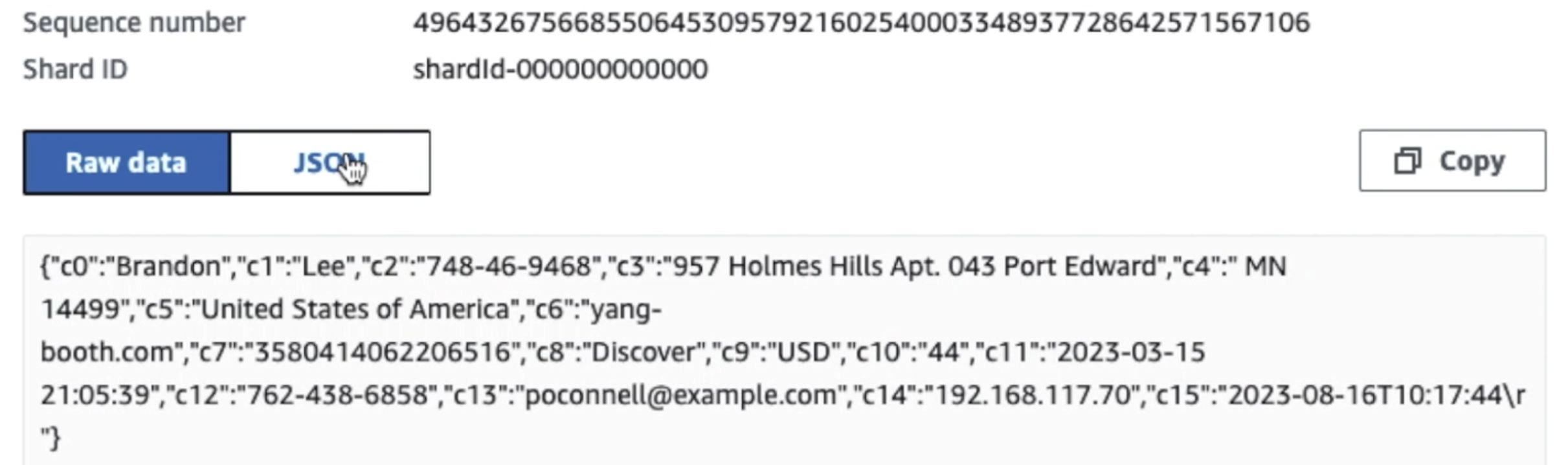
Tangkapan layar berikut menunjukkan bagaimana data mengalir melalui Kinesis Data Streams melalui Penampil Data dan mengambil data sampel yang ada di awalan S3 mentah. Untuk arsitektur ini, kami mengikuti siklus hidup data untuk prefiks S3 seperti yang direkomendasikan dalam Yayasan danau data.
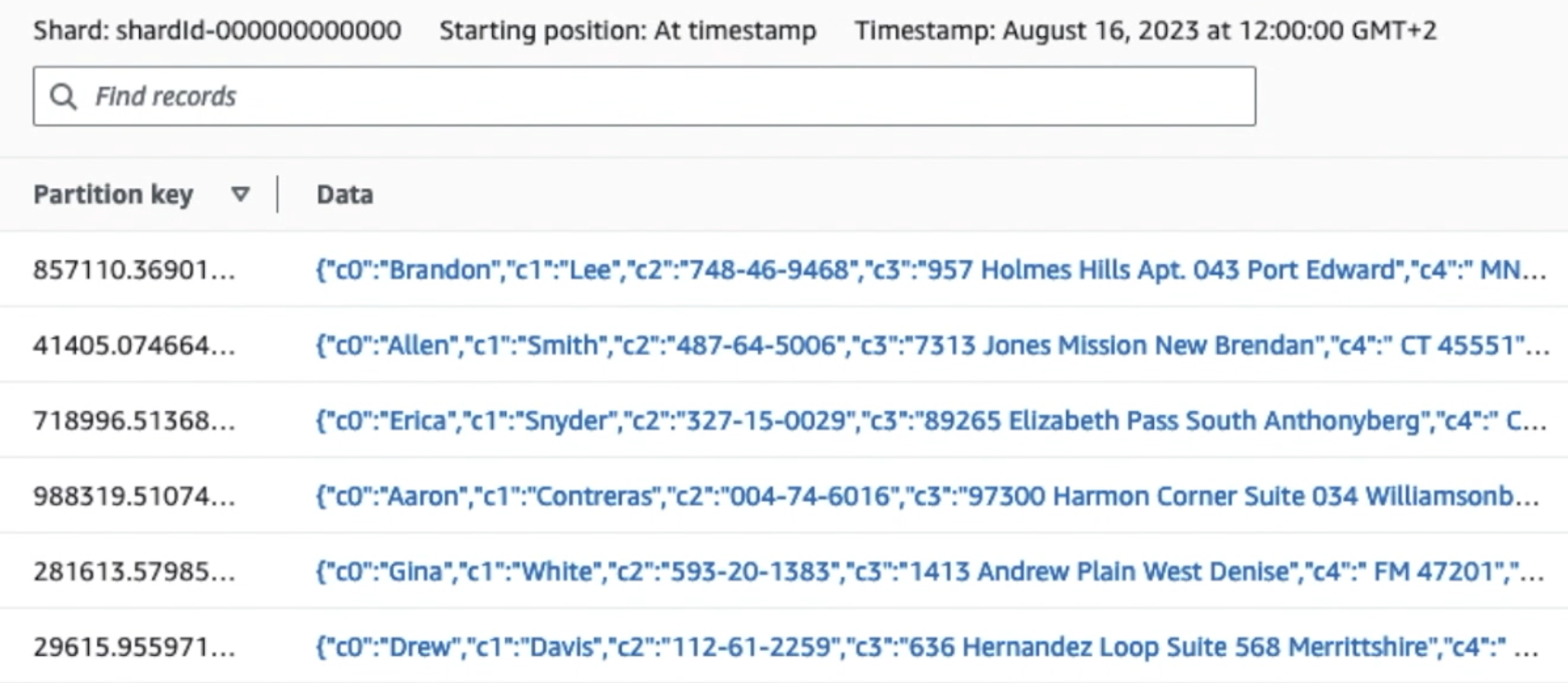
Seperti yang dapat Anda lihat dari detail rekaman pertama di tangkapan layar berikut, payload JSON mengikuti skema yang sama seperti di bagian sebelumnya. Anda dapat melihat data yang belum disunting mengalir ke aliran data Kinesis, yang nantinya akan dikaburkan pada tahap berikutnya.
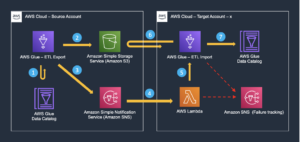
Setelah data dikumpulkan dan diserap ke dalam Kinesis Data Streams dan dikirim ke bucket S3 menggunakan Kinesis Data Firehose, lapisan pemrosesan arsitektur akan mengambil alih. Kami menggunakan transformasi PII AWS Glue untuk mengotomatiskan deteksi dan penyembunyian data sensitif di saluran kami. Seperti yang ditunjukkan dalam diagram alur kerja berikut, kami menggunakan pendekatan ETL visual tanpa kode untuk mengimplementasikan tugas transformasi kami di AWS Glue Studio.
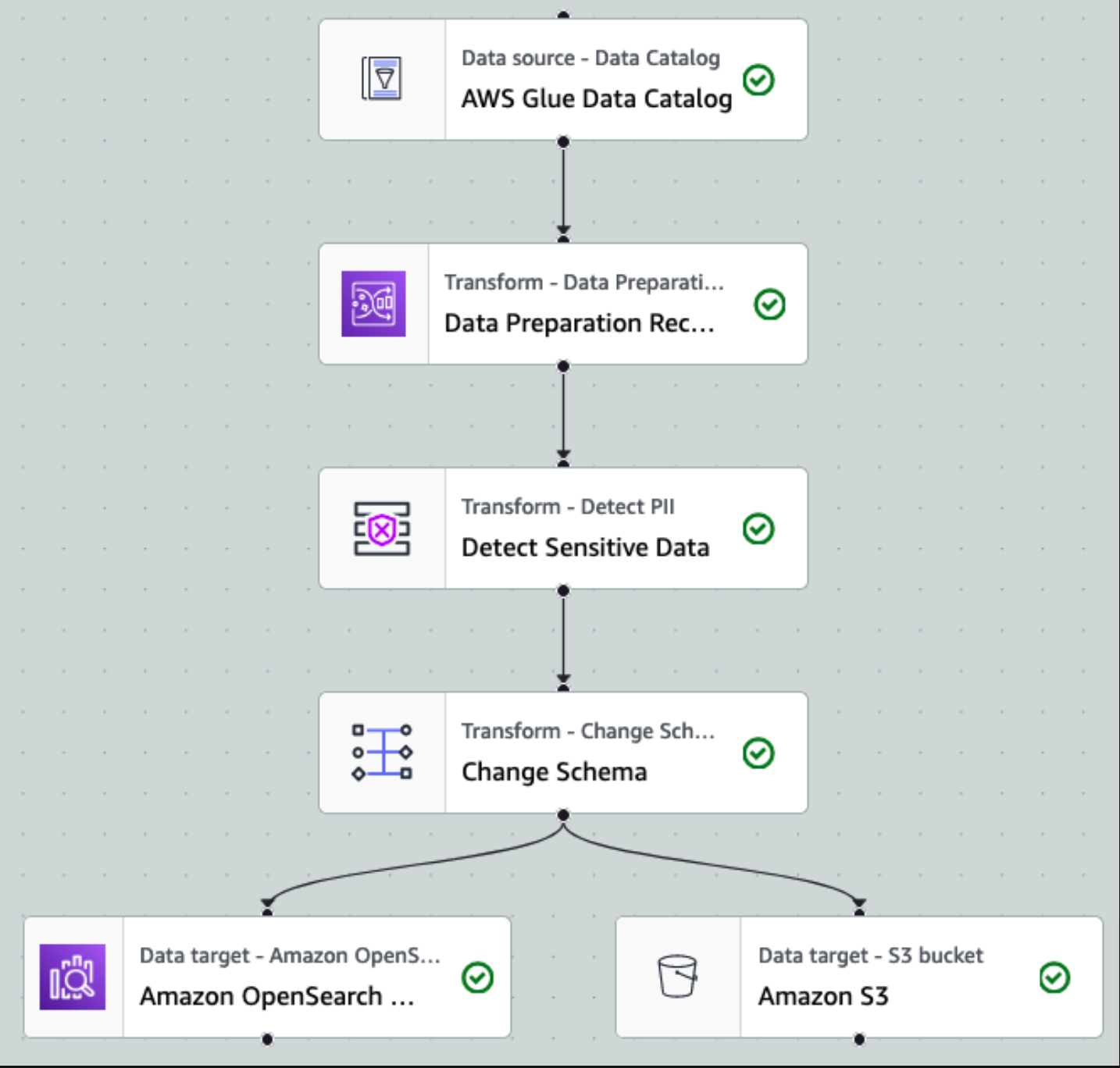
Pertama, kita mengakses tabel Katalog Data sumber mentah dari pii_data_db basis data. Tabel ini memiliki struktur skema yang disajikan pada bagian sebelumnya. Untuk melacak data mentah yang diproses, kami menggunakan penanda pekerjaan.

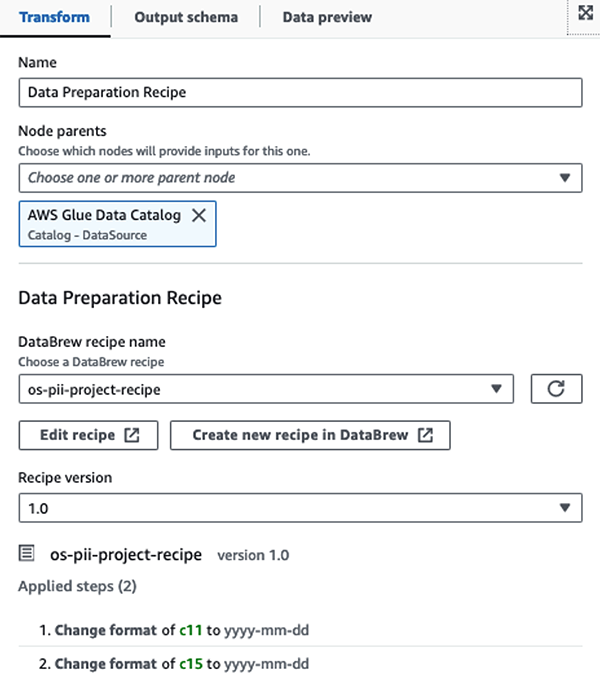
Kami menggunakan Resep AWS Glue DataBrew dalam tugas ETL visual AWS Glue Studio untuk mengubah dua atribut tanggal agar kompatibel dengan OpenSearch yang diharapkan format. Hal ini memungkinkan kami mendapatkan pengalaman tanpa kode sepenuhnya.
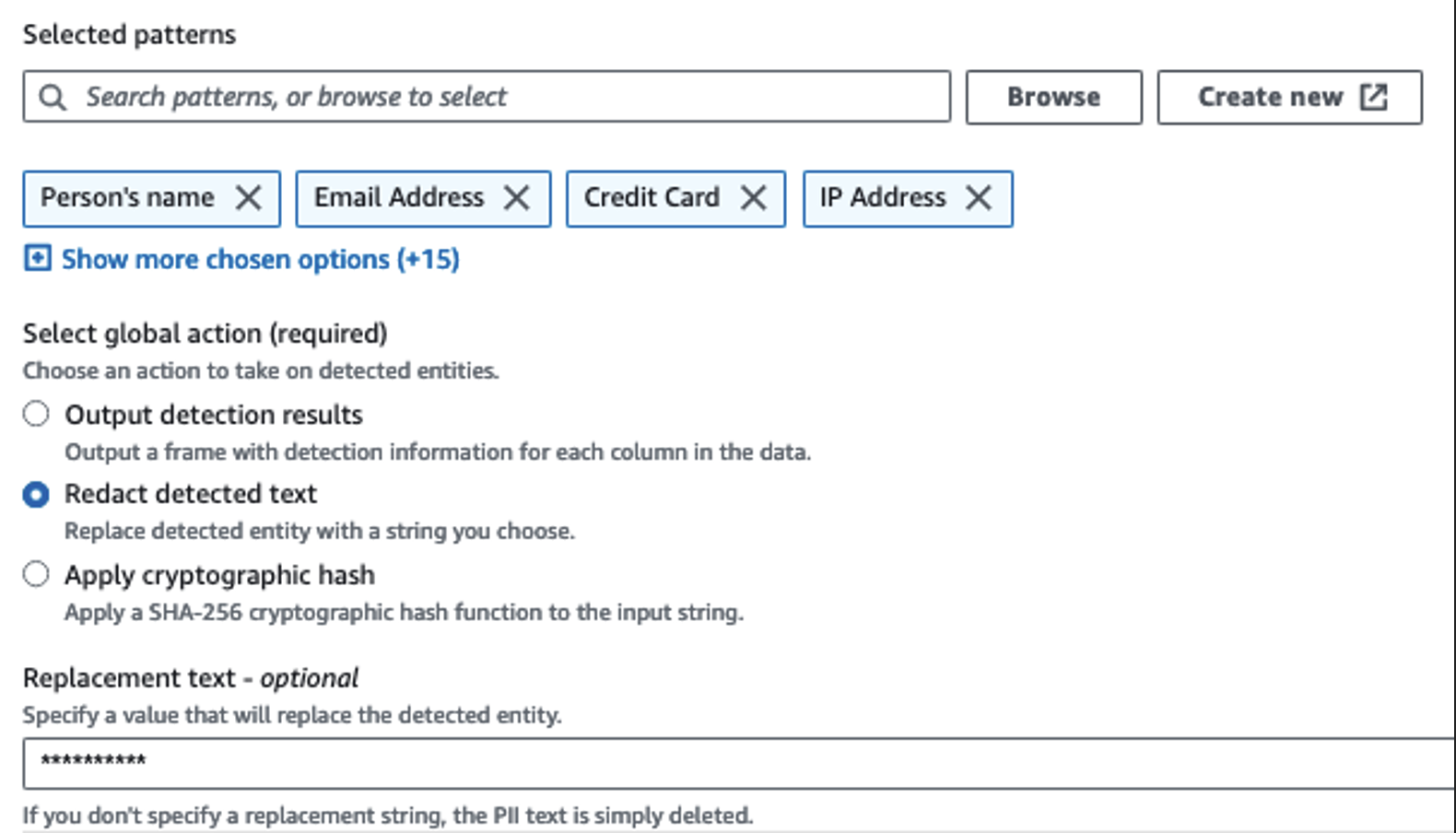
Kami menggunakan tindakan Deteksi PII untuk mengidentifikasi kolom sensitif. Kami membiarkan AWS Glue menentukan ini berdasarkan pola yang dipilih, ambang batas deteksi, dan porsi sampel baris dari kumpulan data. Dalam contoh kami, kami menggunakan pola yang berlaku khusus di Amerika Serikat (seperti SSN) dan mungkin tidak mendeteksi data sensitif dari negara lain. Anda dapat mencari kategori dan lokasi yang tersedia yang berlaku untuk kasus penggunaan Anda atau menggunakan ekspresi reguler (regex) di AWS Glue untuk membuat entitas deteksi untuk data sensitif dari negara lain.
Penting untuk memilih metode pengambilan sampel yang tepat yang ditawarkan AWS Glue. Dalam contoh ini, diketahui bahwa data yang masuk dari aliran memiliki data sensitif di setiap barisnya, sehingga tidak perlu mengambil sampel 100% baris dalam kumpulan data. Jika Anda memiliki persyaratan di mana tidak ada data sensitif yang diizinkan ke sumber hilir, pertimbangkan untuk mengambil sampel 100% data untuk pola yang Anda pilih, atau pindai seluruh kumpulan data dan bertindak pada setiap sel individual untuk memastikan semua data sensitif terdeteksi. Manfaat yang Anda peroleh dari pengambilan sampel adalah pengurangan biaya karena Anda tidak perlu memindai banyak data.

Tindakan Deteksi PII memungkinkan Anda memilih string default saat menutupi data sensitif. Dalam contoh kita, kita menggunakan string **********.
Kami menggunakan operasi penerapan pemetaan untuk mengganti nama dan menghapus kolom yang tidak perlu seperti ingestion_year, ingestion_month, dan ingestion_day. Langkah ini juga memungkinkan kita mengubah tipe data salah satu kolom (purchase_value) dari string ke integer.

Mulai saat ini, pekerjaan dibagi menjadi dua tujuan output: OpenSearch Service dan Amazon S3.
Kluster Layanan OpenSearch kami yang disediakan terhubung melalui Konektor bawaan OpenSearch untuk Lem. Kami menentukan Indeks OpenSearch yang ingin kami tulis dan konektor menangani kredensial, domain, dan port. Pada cuplikan layar di bawah, kami menulis ke indeks yang ditentukan index_os_pii.
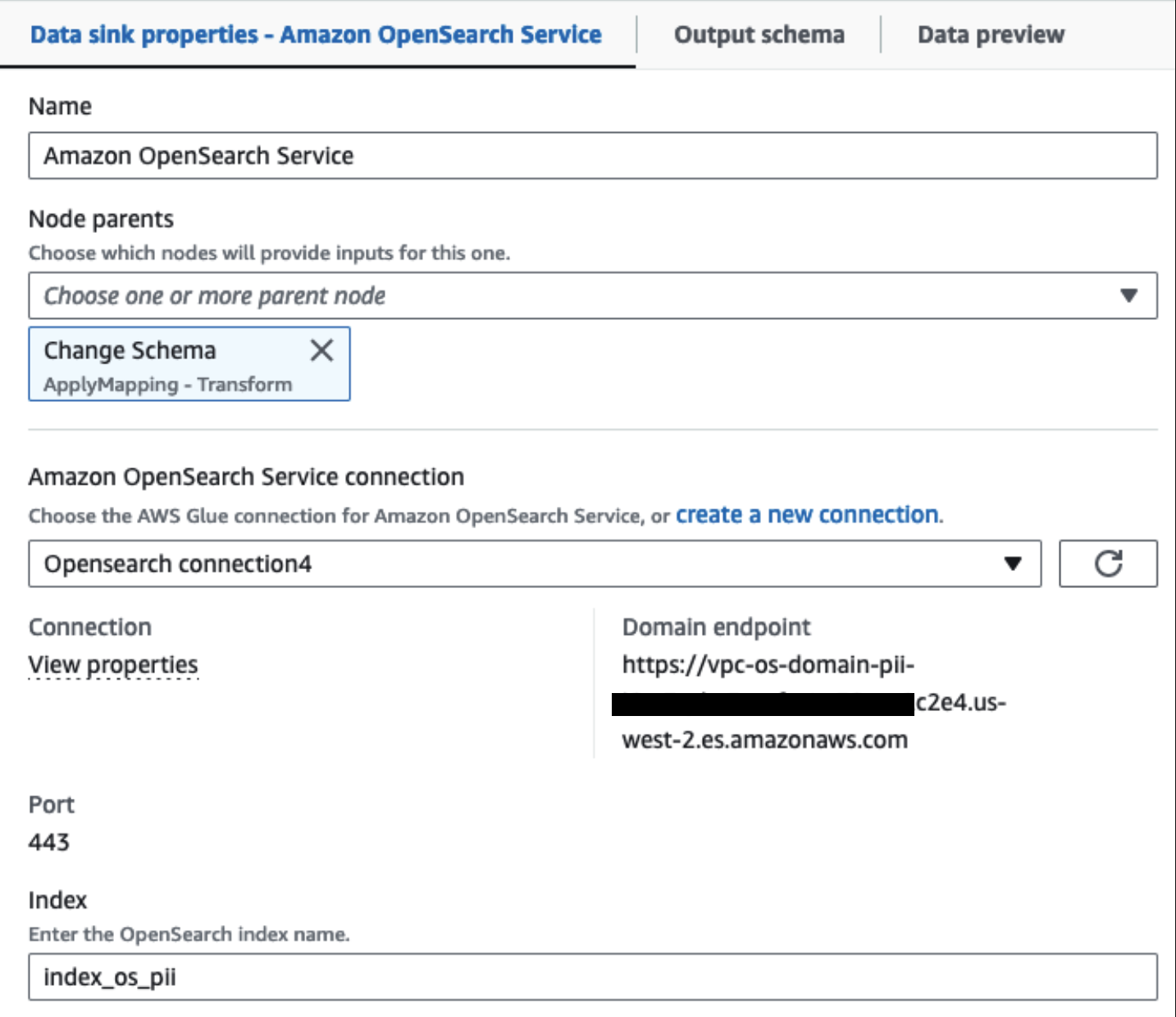
Kami menyimpan himpunan data bertopeng di awalan S3 yang dikurasi. Di sana, kami memiliki data yang dinormalisasi ke kasus penggunaan tertentu dan konsumsi yang aman oleh data scientist atau untuk kebutuhan pelaporan ad hoc.
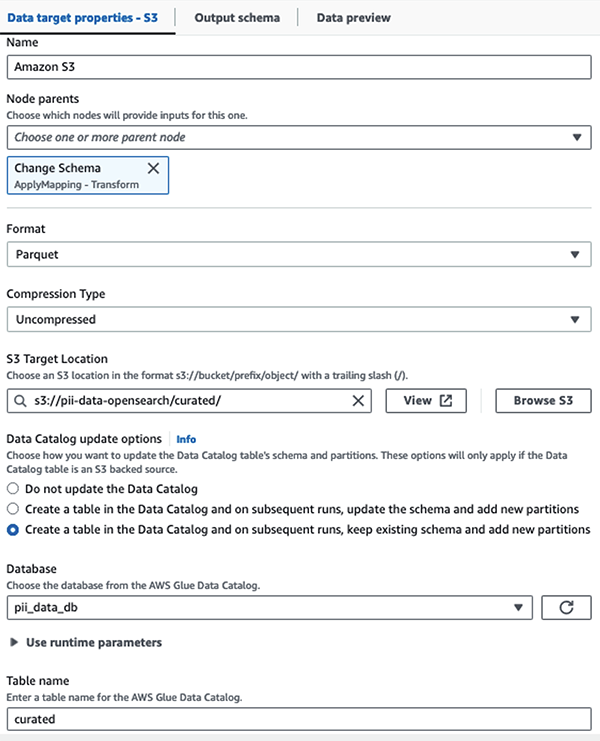
Untuk tata kelola terpadu, kontrol akses, dan jejak audit semua himpunan data dan tabel Katalog Data, Anda dapat menggunakan Formasi Danau AWS. Hal ini membantu Anda membatasi akses ke tabel AWS Glue Data Catalog dan data pokok hanya untuk pengguna dan peran yang telah diberikan izin yang diperlukan untuk melakukannya.
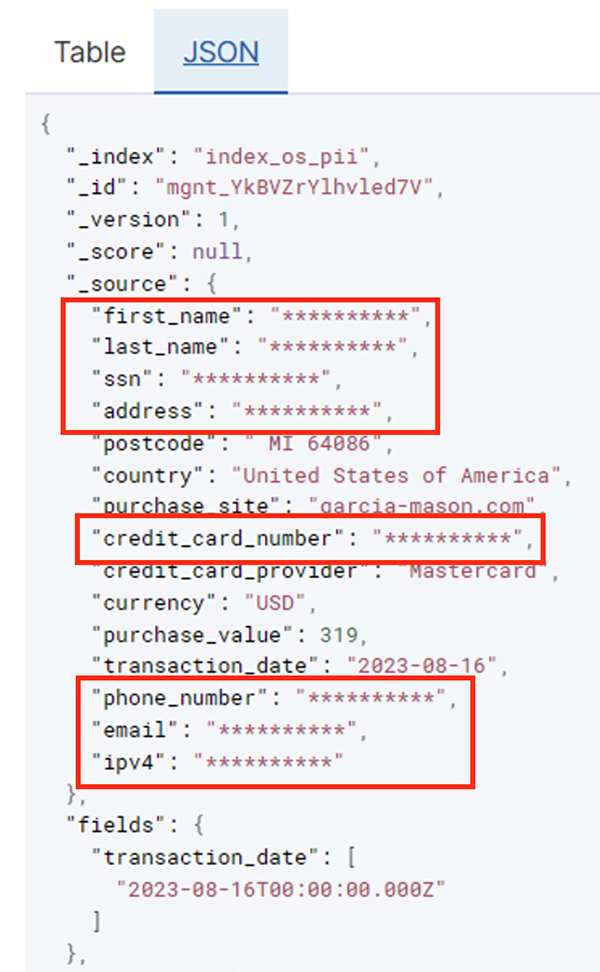
Setelah pekerjaan batch berhasil dijalankan, Anda dapat menggunakan OpenSearch Service untuk menjalankan kueri atau laporan pencarian. Seperti yang ditunjukkan dalam tangkapan layar berikut, alur menutupi bidang sensitif secara otomatis tanpa upaya pengembangan kode.

Anda dapat mengidentifikasi tren dari data operasional, seperti jumlah transaksi per hari yang difilter berdasarkan penyedia kartu kredit, seperti yang ditunjukkan pada tangkapan layar sebelumnya. Anda juga dapat menentukan lokasi dan domain tempat pengguna melakukan pembelian. Itu transaction_date atribut membantu kita melihat tren ini dari waktu ke waktu. Tangkapan layar berikut menunjukkan catatan dengan semua informasi transaksi disunting dengan tepat.
Untuk metode alternatif tentang cara memuat data ke Amazon OpenSearch, lihat Memuat data streaming ke Amazon OpenSearch Service.
Selain itu, data sensitif juga dapat ditemukan dan ditutup menggunakan solusi AWS lainnya. Misalnya, Anda bisa menggunakan Amazon Macie untuk mendeteksi data sensitif di dalam bucket S3, lalu menggunakannya Amazon Comprehend untuk menyunting data sensitif yang terdeteksi. Untuk informasi lebih lanjut, lihat Teknik umum untuk mendeteksi data PHI dan PII menggunakan Layanan AWS.
Kesimpulan
Postingan ini membahas pentingnya menangani data sensitif dalam lingkungan Anda dan berbagai metode serta arsitektur agar tetap patuh sekaligus memungkinkan organisasi Anda berkembang dengan cepat. Anda sekarang seharusnya memiliki pemahaman yang baik tentang cara mendeteksi, menutupi, atau menyunting dan memuat data Anda ke Amazon OpenSearch Service.
Tentang penulis
 Michael Hamilton adalah Sr Analytics Solutions Architect yang berfokus membantu pelanggan perusahaan memodernisasi dan menyederhanakan beban kerja analitik mereka di AWS. Ia senang bersepeda gunung dan menghabiskan waktu bersama istri dan ketiga anaknya saat tidak bekerja.
Michael Hamilton adalah Sr Analytics Solutions Architect yang berfokus membantu pelanggan perusahaan memodernisasi dan menyederhanakan beban kerja analitik mereka di AWS. Ia senang bersepeda gunung dan menghabiskan waktu bersama istri dan ketiga anaknya saat tidak bekerja.
 Daniel Rozo adalah Arsitek Solusi Senior dengan pelanggan pendukung AWS di Belanda. Minatnya adalah merekayasa solusi data dan analitik sederhana serta membantu pelanggan beralih ke arsitektur data modern. Di luar pekerjaan, dia menikmati bermain tenis dan bersepeda.
Daniel Rozo adalah Arsitek Solusi Senior dengan pelanggan pendukung AWS di Belanda. Minatnya adalah merekayasa solusi data dan analitik sederhana serta membantu pelanggan beralih ke arsitektur data modern. Di luar pekerjaan, dia menikmati bermain tenis dan bersepeda.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :memiliki
- :adalah
- :bukan
- :Di mana
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- kemampuan
- Sanggup
- dipercepat
- mengakses
- Bertindak
- Tindakan
- Ad
- alamat
- Agen
- Semua
- diizinkan
- Membiarkan
- memungkinkan
- juga
- selalu
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Layanan Web Amazon (AWS)
- jumlah
- jumlah
- an
- Analytical
- analisis
- dan
- Apa pun
- berlaku
- aplikasi
- Mendaftar
- pendekatan
- tepat
- arsitektur
- ADALAH
- AS
- At
- atribut
- Audit
- mengotomatisasikan
- secara otomatis
- tersedianya
- tersedia
- AWS
- Lem AWS
- backup
- Perbankan
- Sistem perbankan
- berdasarkan
- BE
- karena
- menjadi
- sebelum
- makhluk
- di bawah
- manfaat
- membawa
- membangun
- dibangun di
- built-in
- tapi
- by
- CAN
- kemampuan
- Kapasitas
- menangkap
- kartu
- kasus
- kasus
- katalog
- kategori
- CDC
- sel
- perubahan
- Perubahan
- saluran
- anak-anak
- memilih
- kejelasan
- awan
- Kelompok
- kode
- Kolom
- Kolom
- bagaimana
- datang
- kedatangan
- cocok
- compliant
- komponen
- Terdiri dari
- menghitung
- Kekhawatiran
- terhubung
- Mempertimbangkan
- dianggap
- dikonsumsi
- konsumsi
- mengandung
- konteks
- terus
- kontrol
- benar
- Biaya
- bisa
- negara
- membuat
- Surat kepercayaan
- kredit
- kartu kredit
- dikuratori
- terbaru
- pelanggan
- data
- Data Analytics
- integrasi data
- Danau Data
- Platform Data
- privasi data
- strategi data
- Basis Data
- database
- kumpulan data
- Tanggal
- hari
- Default
- didefinisikan
- disampaikan
- mendemonstrasikan
- menunjukkan
- dikerahkan
- Mendesain
- tujuan
- tujuan
- rincian
- menemukan
- terdeteksi
- Deteksi
- Menentukan
- Pengembangan
- tim pengembangan
- berbeda
- langsung
- menemukan
- ditemukan
- dibahas
- do
- domain
- domain
- Dont
- setiap
- upaya
- Teknik
- memastikan
- Enterprise
- pelanggan perusahaan
- Seluruh
- entitas
- Lingkungan Hidup
- Eter (ETH)
- Bahkan
- peristiwa
- Setiap
- contoh
- contoh
- diharapkan
- pengalaman
- ekspresi
- luar
- FAST
- Fields
- File
- File
- keuangan
- jasa keuangan
- Pertama
- Mengalir
- Mengalir
- berfokus
- diikuti
- berikut
- berikut
- Untuk
- Kerangka
- dari
- penuh
- sepenuhnya
- masa depan
- menghasilkan
- mendapatkan
- baik
- pemerintahan
- diberikan
- Menangani
- Penanganan
- Memiliki
- he
- Kesehatan
- Informasi kesehatan
- membantu
- membantu
- membantu
- tingkat tinggi
- -nya
- historis
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- Ratusan
- mengenali
- if
- menggambarkan
- membayangkan
- melaksanakan
- pentingnya
- penting
- in
- memasukkan
- Termasuk
- indeks
- sendiri-sendiri
- informasi
- Infrastruktur
- dalam
- integrasi
- intern
- ke
- IT
- Jawa
- Pekerjaan
- Jobs
- jpg
- json
- Menjaga
- Firehose Data Kinesis
- Aliran Data Kinesis
- dikenal
- danau
- Tanah
- Tanah
- besar
- Terakhir
- kemudian
- Hukum
- Undang undang Undang
- lapisan
- lapisan
- Kepemimpinan
- membiarkan
- Perpustakaan
- siklus hidup
- 'like'
- baris
- memuat
- pemuatan
- lokasi
- melihat
- murah
- Utama
- mempertahankan
- membuat
- berhasil
- banyak
- pemetaan
- masker
- Mungkin..
- metode
- metode
- bermigrasi
- migrasi
- modern
- memodernisasi
- pemantauan
- lebih
- Gunung
- pindah
- bergerak
- banyak
- beberapa
- harus
- nama
- nama
- perlu
- Perlu
- dibutuhkan
- membutuhkan
- kebutuhan
- Belanda
- New
- tidak
- node
- Melihat..
- sekarang
- jumlah
- of
- Penawaran
- on
- ONE
- hanya
- operasi
- operasional
- Operasi
- mengoptimalkan
- Opsi
- or
- organisasi
- organisasi
- Lainnya
- kami
- keluaran
- di luar
- lebih
- bagian
- gairah
- Menambal
- pola
- Membayar
- pembayaran
- untuk
- melakukan
- prestasi
- Izin
- Sendiri
- telepon
- saleh
- pipa saluran
- rencana
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- Titik
- bagian
- Pos
- mendahului
- disajikan
- sebelumnya
- pribadi
- hukum privasi
- diproses
- proses
- pengolahan
- produsen
- terlindung
- protokol
- pemberi
- menyediakan
- pembelian
- query
- segera
- agak
- Mentah
- data mentah
- real-time
- alasan
- menerima
- Resep
- direkomendasikan
- catatan
- arsip
- mengurangi
- lihat
- reguler
- peraturan
- keandalan
- tinggal
- menghapus
- Pelaporan
- laporan
- membutuhkan
- kebutuhan
- Persyaratan
- tanggung jawab
- tanggung jawab
- membatasi
- Hasil
- peran
- BARIS
- Run
- berjalan
- SaaS
- berkorban
- aman
- aman
- sama
- Skala
- pemindaian
- menjadwalkan
- ilmuwan
- Layar
- SDK
- Pencarian
- Bagian
- aman
- keamanan
- melihat
- memilih
- terpilih
- senior
- peka
- mengirim
- layanan
- Layanan
- tembakan
- harus
- ditunjukkan
- Pertunjukkan
- Sederhana
- menyederhanakan
- kecil
- So
- Sosial
- Perangkat lunak
- perangkat lunak sebagai layanan
- larutan
- Solusi
- sumber
- sumber
- tertentu
- Secara khusus
- ditentukan
- menghabiskan
- Pengeluaran
- Berpisah
- magang
- Negara
- Langkah
- penyimpanan
- menyimpan
- mudah
- Penyelarasan
- aliran
- Streaming
- stream
- Tali
- struktur
- tersusun
- studio
- selanjutnya
- berhasil
- seperti itu
- cocok
- Didukung
- pendukung
- sistem
- sistem
- tabel
- Dibutuhkan
- target
- tim
- tim
- teknik
- tenis
- memiliki
- dari
- bahwa
- Grafik
- Masa depan
- Belanda
- Sumber
- mereka
- kemudian
- Sana.
- Ini
- ini
- itu
- tiga
- ambang
- Melalui
- waktu
- untuk
- mengambil
- alat
- jalur
- Transaksi
- transfer
- transfer
- Mengubah
- Transformasi
- Tren
- dipicu
- dua
- mengetik
- jenis
- Akhirnya
- pokok
- pemahaman
- terpadu
- Serikat
- Amerika Serikat
- us
- menggunakan
- gunakan case
- bekas
- Pengguna
- menggunakan
- nilai
- variasi
- berbagai
- melalui
- visual
- berjalan
- adalah
- cara
- we
- jaringan
- layanan web
- Apa
- ketika
- yang
- sementara
- SIAPA
- istri
- akan
- dengan
- dalam
- tanpa
- Kerja
- alur kerja
- kerja
- menulis
- kamu
- Anda
- zephyrnet.dll