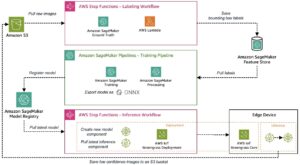
Penyematan memainkan peran penting dalam pemrosesan bahasa alami (NLP) dan pembelajaran mesin (ML). Penyematan teks mengacu pada proses mengubah teks menjadi representasi numerik yang berada dalam ruang vektor berdimensi tinggi. Teknik ini dicapai melalui penggunaan algoritma ML yang memungkinkan pemahaman makna dan konteks data (hubungan semantik) dan pembelajaran hubungan dan pola kompleks dalam data (hubungan sintaksis). Anda dapat menggunakan representasi vektor yang dihasilkan untuk berbagai aplikasi, seperti pengambilan informasi, klasifikasi teks, pemrosesan bahasa alami, dan banyak lainnya.
Penyematan Teks Amazon Titan adalah model penyematan teks yang mengubah teks bahasa alami—yang terdiri dari satu kata, frasa, atau bahkan dokumen berukuran besar—menjadi representasi numerik yang dapat digunakan untuk mendukung kasus penggunaan seperti penelusuran, personalisasi, dan pengelompokan berdasarkan kesamaan semantik.
Dalam postingan ini, kami membahas model Amazon Titan Text Embeddings, fitur-fiturnya, dan contoh kasus penggunaan.
Beberapa konsep utama meliputi:
- Representasi numerik teks (vektor) menangkap semantik dan hubungan antar kata
- Penyematan yang kaya dapat digunakan untuk membandingkan kesamaan teks
- Penyematan teks multibahasa dapat mengidentifikasi makna dalam berbagai bahasa
Bagaimana sepotong teks diubah menjadi vektor?
Ada beberapa teknik untuk mengubah kalimat menjadi vektor. Salah satu metode yang populer adalah menggunakan algoritme penyematan kata, seperti Word2Vec, GloVe, atau FastText, lalu menggabungkan kata penyematan untuk membentuk representasi vektor tingkat kalimat.
Pendekatan umum lainnya adalah dengan menggunakan model bahasa besar (LLM), seperti BERT atau GPT, yang dapat menyediakan penyematan kontekstual untuk keseluruhan kalimat. Model ini didasarkan pada arsitektur pembelajaran mendalam seperti Transformers, yang dapat menangkap informasi kontekstual dan hubungan antar kata dalam kalimat dengan lebih efektif.
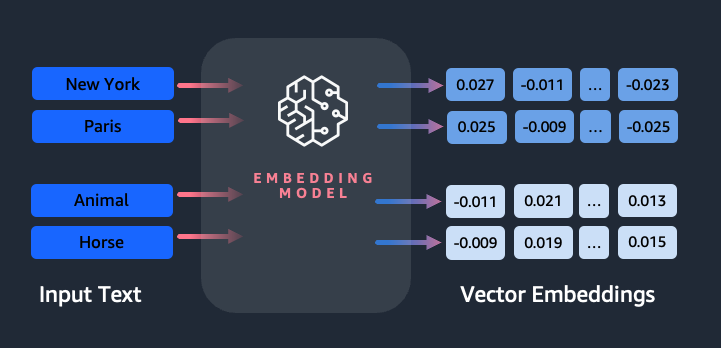
Mengapa kita memerlukan model embeddings?
Penyematan vektor sangat penting bagi LLM untuk memahami tingkat semantik bahasa, dan juga memungkinkan LLM bekerja dengan baik pada tugas NLP hilir seperti analisis sentimen, pengenalan entitas bernama, dan klasifikasi teks.
Selain penelusuran semantik, Anda dapat menggunakan penyematan untuk menambah permintaan Anda agar mendapatkan hasil yang lebih akurat melalui Retrieval Augmented Generation (RAG)—tetapi untuk menggunakannya, Anda harus menyimpannya dalam database dengan kemampuan vektor.
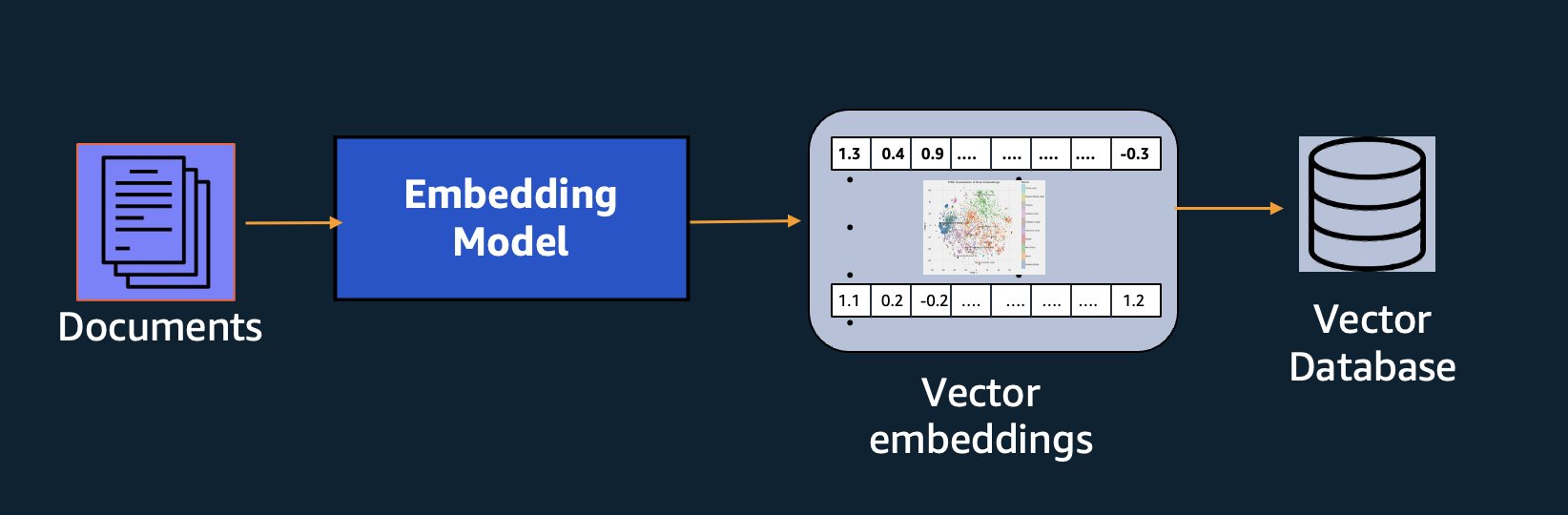
Model Amazon Titan Text Embeddings dioptimalkan untuk pengambilan teks guna mengaktifkan kasus penggunaan RAG. Hal ini memungkinkan Anda untuk terlebih dahulu mengonversi data teks menjadi representasi numerik atau vektor, dan kemudian menggunakan vektor tersebut untuk secara akurat mencari bagian yang relevan dari database vektor, sehingga memungkinkan Anda memanfaatkan data kepemilikan Anda secara maksimal dalam kombinasi dengan model dasar lainnya.
Karena Amazon Titan Text Embeddings adalah model terkelola Batuan Dasar Amazon, ini ditawarkan sebagai pengalaman yang sepenuhnya tanpa server. Anda dapat menggunakannya melalui Amazon Bedrock REST API atau AWS SDK. Parameter yang diperlukan adalah teks yang ingin Anda buatkan penyematannya dan modelID parameter, yang mewakili nama model Amazon Titan Text Embeddings. Kode berikut adalah contoh penggunaan AWS SDK for Python (Boto3):
Outputnya akan terlihat seperti berikut:
Lihat Pengaturan boto3 Batuan Dasar Amazon untuk detail lebih lanjut tentang cara menginstal paket yang diperlukan, terhubung ke Amazon Bedrock, dan memanggil model.
Fitur Penyematan Teks Amazon Titan
Dengan Amazon Titan Text Embeddings, Anda dapat memasukkan hingga 8,000 token, sehingga cocok untuk digunakan dengan satu kata, frasa, atau seluruh dokumen berdasarkan kasus penggunaan Anda. Amazon Titan mengembalikan vektor keluaran dimensi 1536, memberikan tingkat akurasi yang tinggi, sekaligus mengoptimalkan hasil latensi rendah dan hemat biaya.
Amazon Titan Text Embeddings mendukung pembuatan dan kueri penyematan teks dalam lebih dari 25 bahasa berbeda. Artinya, Anda dapat menerapkan model tersebut ke kasus penggunaan Anda tanpa perlu membuat dan memelihara model terpisah untuk setiap bahasa yang ingin Anda dukung.
Memiliki satu model penyematan yang dilatih dalam banyak bahasa memberikan manfaat utama berikut:
- Jangkauan lebih luas – Dengan mendukung lebih dari 25 bahasa, Anda dapat memperluas jangkauan aplikasi Anda ke pengguna dan konten di banyak pasar internasional.
- Kinerja yang konsisten – Dengan model terpadu yang mencakup beberapa bahasa, Anda mendapatkan hasil yang konsisten di seluruh bahasa, bukan mengoptimalkan secara terpisah per bahasa. Model ini dilatih secara holistik sehingga Anda mendapatkan keuntungan dalam berbagai bahasa.
- Dukungan kueri multibahasa – Amazon Titan Text Embeddings memungkinkan kueri penyematan teks dalam bahasa apa pun yang didukung. Hal ini memberikan fleksibilitas untuk mengambil konten yang serupa secara semantik di berbagai bahasa tanpa dibatasi pada satu bahasa saja. Anda dapat membangun aplikasi yang mengkueri dan menganalisis data multibahasa menggunakan ruang penyematan terpadu yang sama.
Saat tulisan ini dibuat, bahasa-bahasa berikut ini didukung:
- Arab
- Cina (Modern)
- Cina (Tradisional)
- Ceko
- Dutch
- Inggris
- Perancis
- Jerman
- Ibrani
- Hindi
- Italia
- Jepang
- kannada
- Korea
- Malayalam
- Marathi
- semir
- Portugis
- Rusia
- Spanyol
- Swedia
- Tagalog Filipina
- Tamil
- telugu
- Turki
Menggunakan Penyematan Teks Amazon Titan dengan LangChain
LangChain adalah kerangka kerja sumber terbuka yang populer untuk bekerja dengan model AI generatif dan teknologi pendukung. Ini termasuk a Klien BedrockEmbeddings yang dengan mudah membungkus Boto3 SDK dengan lapisan abstraksi. Itu BedrockEmbeddings klien memungkinkan Anda bekerja dengan teks dan penyematan secara langsung, tanpa mengetahui detail permintaan JSON atau struktur respons. Berikut ini adalah contoh sederhananya:
Anda juga dapat menggunakan LangChain BedrockEmbeddings klien bersama klien Amazon Bedrock LLM untuk menyederhanakan penerapan RAG, pencarian semantik, dan pola terkait penyematan lainnya.
Kasus penggunaan untuk penyematan
Meskipun RAG saat ini merupakan kasus penggunaan paling populer untuk bekerja dengan penyematan, ada banyak kasus penggunaan lain di mana penyematan dapat diterapkan. Berikut adalah beberapa skenario tambahan di mana Anda dapat menggunakan penyematan untuk memecahkan masalah tertentu, baik secara mandiri atau bekerja sama dengan LLM:
- Pertanyaan dan jawaban – Penyematan dapat membantu mendukung antarmuka tanya jawab melalui pola RAG. Pembuatan penyematan yang dipasangkan dengan database vektor memungkinkan Anda menemukan kecocokan yang erat antara pertanyaan dan konten dalam gudang pengetahuan.
- Rekomendasi yang dipersonalisasi – Mirip dengan tanya jawab, Anda dapat menggunakan embeddings untuk mencari tujuan liburan, kampus, kendaraan, atau produk lainnya berdasarkan kriteria yang diberikan oleh pengguna. Ini bisa berupa daftar kecocokan sederhana, atau Anda kemudian bisa menggunakan LLM untuk memproses setiap rekomendasi dan menjelaskan bagaimana rekomendasi tersebut memenuhi kriteria pengguna. Anda juga dapat menggunakan pendekatan ini untuk menghasilkan “10 artikel terbaik” khusus untuk pengguna berdasarkan kebutuhan spesifik mereka.
- Manajemen data – Jika Anda memiliki sumber data yang tidak dipetakan dengan rapi satu sama lain, namun Anda memiliki konten teks yang mendeskripsikan rekaman data, Anda dapat menggunakan penyematan untuk mengidentifikasi potensi rekaman duplikat. Misalnya, Anda dapat menggunakan penyematan untuk mengidentifikasi kandidat duplikat yang mungkin menggunakan format, singkatan, atau bahkan nama terjemahan yang berbeda.
- Rasionalisasi portofolio aplikasi – Saat ingin menyelaraskan portofolio aplikasi antara perusahaan induk dan akuisisi, tidak selalu jelas di mana harus mulai menemukan potensi tumpang tindih. Kualitas data manajemen konfigurasi dapat menjadi faktor pembatas, dan sulitnya koordinasi antar tim untuk memahami lanskap aplikasi. Dengan menggunakan pencocokan semantik dengan penyematan, kita dapat melakukan analisis cepat di seluruh portofolio aplikasi untuk mengidentifikasi kandidat aplikasi yang berpotensi tinggi untuk dirasionalisasi.
- Pengelompokan konten – Anda dapat menggunakan penyematan untuk membantu memfasilitasi pengelompokan konten serupa ke dalam kategori yang mungkin belum Anda ketahui sebelumnya. Misalnya, Anda memiliki kumpulan email pelanggan atau ulasan produk online. Anda dapat membuat penyematan untuk setiap item, lalu menjalankan penyematan tersebut pengelompokan k-means untuk mengidentifikasi pengelompokan logis dari kekhawatiran pelanggan, pujian atau keluhan produk, atau tema lainnya. Anda kemudian dapat membuat ringkasan terfokus dari konten pengelompokan tersebut menggunakan LLM.
Contoh pencarian semantik
Dalam kami contoh di GitHub, kami mendemonstrasikan aplikasi pencarian embeddings sederhana dengan Amazon Titan Text Embeddings, LangChain, dan Streamlit.
Contoh ini mencocokkan kueri pengguna dengan entri terdekat dalam database vektor dalam memori. Kami kemudian menampilkan kecocokan tersebut langsung di antarmuka pengguna. Ini dapat berguna jika Anda ingin memecahkan masalah aplikasi RAG, atau mengevaluasi model embeddings secara langsung.
Untuk mempermudah, kami menggunakan dalam memori FAISS database untuk menyimpan dan mencari vektor embeddings. Dalam skenario dunia nyata dalam skala besar, Anda mungkin ingin menggunakan penyimpanan data persisten seperti mesin vektor untuk Amazon OpenSearch Tanpa Server atau itu vektor pg ekstensi untuk PostgreSQL.
Cobalah beberapa perintah dari aplikasi web dalam berbagai bahasa, seperti berikut:
- Bagaimana cara memantau penggunaan saya?
- Bagaimana cara menyesuaikan model?
- Bahasa pemrograman apa yang bisa saya gunakan?
- Komentari saya yang tidak memiliki keamanan ?
- Bagaimana cara kerjanya?
- Apa yang membutuhkan model ini tersedia untuk sebagian besar Bedrock?
- Di Wilayah Welchen Apakah Amazon Bedrock Verfügbar?
- 哪些级别的支持?
Perhatikan bahwa meskipun materi sumbernya dalam bahasa Inggris, pertanyaan dalam bahasa lain dicocokkan dengan entri yang relevan.
Kesimpulan
Kemampuan pembuatan teks pada model dasar sangat menarik, namun penting untuk diingat bahwa memahami teks, menemukan konten yang relevan dari sekumpulan pengetahuan, dan membuat hubungan antar bagian sangat penting untuk mencapai nilai penuh dari AI generatif. Kami akan terus melihat kasus penggunaan baru dan menarik untuk penyematan muncul di tahun-tahun mendatang seiring dengan penyempurnaan model ini.
Langkah berikutnya
Anda dapat menemukan contoh tambahan penyematan sebagai buku catatan atau aplikasi demo di lokakarya berikut:
Tentang Penulis
 Jason Stehle adalah Arsitek Solusi Senior di AWS, yang berbasis di wilayah New England. Dia bekerja dengan pelanggan untuk menyelaraskan kemampuan AWS dengan tantangan bisnis terbesar mereka. Di luar pekerjaan, ia menghabiskan waktunya membangun sesuatu dan menonton film komik bersama keluarganya.
Jason Stehle adalah Arsitek Solusi Senior di AWS, yang berbasis di wilayah New England. Dia bekerja dengan pelanggan untuk menyelaraskan kemampuan AWS dengan tantangan bisnis terbesar mereka. Di luar pekerjaan, ia menghabiskan waktunya membangun sesuatu dan menonton film komik bersama keluarganya.
 Nitin Eusebius adalah Sr. Enterprise Solutions Architect di AWS, berpengalaman dalam Rekayasa Perangkat Lunak, Arsitektur Perusahaan, dan AI/ML. Dia sangat bersemangat mengeksplorasi kemungkinan AI generatif. Dia berkolaborasi dengan pelanggan untuk membantu mereka membangun aplikasi yang dirancang dengan baik di platform AWS, dan berdedikasi untuk memecahkan tantangan teknologi dan membantu perjalanan cloud mereka.
Nitin Eusebius adalah Sr. Enterprise Solutions Architect di AWS, berpengalaman dalam Rekayasa Perangkat Lunak, Arsitektur Perusahaan, dan AI/ML. Dia sangat bersemangat mengeksplorasi kemungkinan AI generatif. Dia berkolaborasi dengan pelanggan untuk membantu mereka membangun aplikasi yang dirancang dengan baik di platform AWS, dan berdedikasi untuk memecahkan tantangan teknologi dan membantu perjalanan cloud mereka.
 Raja Pathak adalah Arsitek Solusi Utama dan Penasihat Teknis untuk perusahaan besar Fortune 50 dan lembaga jasa keuangan (FSI) skala menengah di Kanada dan Amerika Serikat. Ia berspesialisasi dalam aplikasi pembelajaran mesin seperti AI generatif, pemrosesan bahasa alami, pemrosesan dokumen cerdas, dan MLOps.
Raja Pathak adalah Arsitek Solusi Utama dan Penasihat Teknis untuk perusahaan besar Fortune 50 dan lembaga jasa keuangan (FSI) skala menengah di Kanada dan Amerika Serikat. Ia berspesialisasi dalam aplikasi pembelajaran mesin seperti AI generatif, pemrosesan bahasa alami, pemrosesan dokumen cerdas, dan MLOps.
 Mani Khanuja adalah Pimpinan Teknologi – Spesialis AI Generatif, penulis buku – Pembelajaran Mesin Terapan dan Komputasi Kinerja Tinggi di AWS, dan anggota Dewan Direksi Wanita di Dewan Yayasan Pendidikan Manufaktur. Dia memimpin proyek pembelajaran mesin (ML) di berbagai domain seperti visi komputer, pemrosesan bahasa alami, dan AI generatif. Dia membantu pelanggan membangun, melatih, dan menerapkan model pembelajaran mesin besar dalam skala besar. Dia berbicara dalam konferensi internal dan eksternal seperti re:Invent, Women in Manufacturing West, webinar YouTube, dan GHC 23. Di waktu luangnya, dia suka berjalan-jalan di sepanjang pantai.
Mani Khanuja adalah Pimpinan Teknologi – Spesialis AI Generatif, penulis buku – Pembelajaran Mesin Terapan dan Komputasi Kinerja Tinggi di AWS, dan anggota Dewan Direksi Wanita di Dewan Yayasan Pendidikan Manufaktur. Dia memimpin proyek pembelajaran mesin (ML) di berbagai domain seperti visi komputer, pemrosesan bahasa alami, dan AI generatif. Dia membantu pelanggan membangun, melatih, dan menerapkan model pembelajaran mesin besar dalam skala besar. Dia berbicara dalam konferensi internal dan eksternal seperti re:Invent, Women in Manufacturing West, webinar YouTube, dan GHC 23. Di waktu luangnya, dia suka berjalan-jalan di sepanjang pantai.
 Tandai Roy adalah Arsitek Pembelajaran Mesin Utama untuk AWS, membantu pelanggan merancang dan membangun solusi AI/ML. Pekerjaan Mark mencakup berbagai kasus penggunaan ML, dengan minat utama pada visi komputer, pembelajaran mendalam, dan penskalaan ML di seluruh perusahaan. Dia telah membantu perusahaan di banyak industri, termasuk asuransi, jasa keuangan, media dan hiburan, perawatan kesehatan, utilitas, dan manufaktur. Mark memegang enam Sertifikasi AWS, termasuk Sertifikasi Khusus ML. Sebelum bergabung dengan AWS, Mark adalah seorang arsitek, pengembang, dan pemimpin teknologi selama lebih dari 25 tahun, termasuk 19 tahun di bidang layanan keuangan.
Tandai Roy adalah Arsitek Pembelajaran Mesin Utama untuk AWS, membantu pelanggan merancang dan membangun solusi AI/ML. Pekerjaan Mark mencakup berbagai kasus penggunaan ML, dengan minat utama pada visi komputer, pembelajaran mendalam, dan penskalaan ML di seluruh perusahaan. Dia telah membantu perusahaan di banyak industri, termasuk asuransi, jasa keuangan, media dan hiburan, perawatan kesehatan, utilitas, dan manufaktur. Mark memegang enam Sertifikasi AWS, termasuk Sertifikasi Khusus ML. Sebelum bergabung dengan AWS, Mark adalah seorang arsitek, pengembang, dan pemimpin teknologi selama lebih dari 25 tahun, termasuk 19 tahun di bidang layanan keuangan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- Tentang Kami
- abstraksi
- Setuju
- ketepatan
- tepat
- akurat
- dicapai
- mencapai
- perolehan
- di seluruh
- tambahan
- Tambahan
- Keuntungan
- penasihat
- di depan
- AI
- Model AI
- AI / ML
- algoritma
- meluruskan
- Semua
- mengizinkan
- Membiarkan
- memungkinkan
- sepanjang
- di samping
- juga
- selalu
- Amazon
- Amazon Web Services
- an
- analisis
- menganalisa
- dan
- menjawab
- Apa pun
- Aplikasi
- aplikasi
- terapan
- Mendaftar
- pendekatan
- arsitektur
- arsitektur
- ADALAH
- DAERAH
- artikel
- AS
- membantu
- At
- menambah
- ditambah
- penulis
- tersedia
- AWS
- berdasarkan
- BE
- Pantai
- makhluk
- Manfaat
- antara
- papan
- direksi
- tubuh
- Book
- Kotak
- membangun
- Bangunan
- bisnis
- tapi
- by
- CAN
- Kanada
- calon
- calon
- kemampuan
- menangkap
- menangkap
- kasus
- kasus
- kategori
- Sertifikasi
- sertifikasi
- tantangan
- klasifikasi
- klien
- Penyelesaian
- awan
- kekelompokan
- kode
- koleksi
- Perguruan tinggi
- kombinasi
- Umum
- Perusahaan
- perusahaan
- membandingkan
- keluhan
- kompleks
- komputer
- Visi Komputer
- komputasi
- konsep
- Kekhawatiran
- konferensi
- konfigurasi
- Terhubung
- koneksi
- Koneksi
- konsisten
- Konten
- konteks
- kontekstual
- terus
- dengan nyaman
- mengubah
- dikonversi
- kerja sama
- koordinasi
- hemat biaya
- bisa
- penutup
- meliputi
- membuat
- membuat
- kriteria
- sangat penting
- Sekarang
- adat
- pelanggan
- pelanggan
- menyesuaikan
- data
- Basis Data
- de
- dedicated
- mendalam
- belajar mendalam
- sangat
- menetapkan
- Derajat
- Demo
- mendemonstrasikan
- menyebarkan
- menjelaskan
- Mendesain
- tujuan
- rincian
- Pengembang
- berbeda
- sulit
- Dimensi
- langsung
- Direksi
- membahas
- Display
- do
- dokumen
- dokumen
- domain
- Dont
- setiap
- Pendidikan
- efektif
- antara
- embedding
- muncul
- aktif
- memungkinkan
- Mesin
- Teknik
- Inggris
- Inggris
- Enterprise
- Solusi perusahaan
- Menghibur
- Seluruh
- sepenuhnya
- entitas
- Eter (ETH)
- mengevaluasi
- Bahkan
- contoh
- contoh
- menarik
- Lihat lebih lanjut
- pengalaman
- berpengalaman
- Menjelaskan
- Menjelajahi
- perpanjangan
- luar
- memudahkan
- faktor
- keluarga
- Fitur
- beberapa
- keuangan
- jasa keuangan
- Menemukan
- temuan
- Pertama
- keluwesan
- terfokus
- berikut
- Untuk
- bentuk
- Nasib
- Prinsip Dasar
- Kerangka
- Gratis
- dari
- penuh
- mendasar
- menghasilkan
- generasi
- generatif
- AI generatif
- mendapatkan
- mendapatkan
- Pemberian
- sarung tangan
- Go
- terbesar
- memiliki
- Memiliki
- he
- kesehatan
- membantu
- membantu
- membantu
- membantu
- dia
- High
- High Performance Computing
- -nya
- memegang
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- i
- mengenali
- if
- mengimplementasikan
- mengimpor
- penting
- memperbaiki
- in
- Di lain
- memasukkan
- termasuk
- Termasuk
- industri
- informasi
- memasukkan
- install
- sebagai gantinya
- lembaga
- asuransi
- Cerdas
- Pemrosesan dokumen cerdas
- bunga
- menarik
- Antarmuka
- interface
- intern
- Internasional
- ke
- IT
- NYA
- bergabung
- perjalanan
- jpg
- json
- kunci
- Tahu
- Mengetahui
- pengetahuan
- pemandangan
- bahasa
- Bahasa
- besar
- lapisan
- memimpin
- pemimpin
- Memimpin
- pengetahuan
- membiarkan
- 'like'
- Mungkin
- 'like
- membatasi
- Daftar
- lm
- logis
- Panjang
- melihat
- mencari
- mesin
- Mesin belajar
- memelihara
- membuat
- Membuat
- berhasil
- pengelolaan
- pabrik
- banyak
- peta
- tanda
- Tanda
- pasar
- cocok
- korek api
- sesuai
- bahan
- me
- makna
- cara
- Media
- anggota
- metode
- mungkin
- ML
- Algoritme ML
- MLOps
- model
- model
- Memantau
- lebih
- paling
- Paling Populer
- bioskop
- beberapa
- my
- nama
- Bernama
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Perlu
- membutuhkan
- kebutuhan
- New
- berikutnya
- nLP
- laptop
- Jelas
- of
- ditawarkan
- on
- ONE
- secara online
- Buka
- open source
- dioptimalkan
- mengoptimalkan
- or
- urutan
- Lainnya
- Lainnya
- kami
- di luar
- keluaran
- di luar
- lebih
- sendiri
- paket
- dipasangkan
- parameter
- parameter
- perusahaan utama
- bagian
- bergairah
- pola
- pola
- untuk
- melakukan
- prestasi
- Personalisasi
- frase
- bagian
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Bermain
- silahkan
- Populer
- OLEH
- portofolio
- portofolio
- kemungkinan
- Pos
- Postgresql
- potensi
- kekuasaan
- primer
- Utama
- Mencetak
- Sebelumnya
- masalah
- proses
- pengolahan
- Produk
- Ulasan produk
- Produk
- Pemrograman
- bahasa pemrograman
- memprojeksikan
- meminta
- hak milik
- memberikan
- disediakan
- menyediakan
- Ular sanca
- kualitas
- query
- pertanyaan
- pertanyaan
- Pertanyaan
- Cepat
- lap
- jarak
- RE
- mencapai
- dunia nyata
- pengakuan
- Rekomendasi
- rekomendasi
- catatan
- arsip
- mengacu
- Hubungan
- relevan
- ingat
- gudang
- perwakilan
- merupakan
- permintaan
- wajib
- tanggapan
- ISTIRAHAT
- terbatas
- dihasilkan
- Hasil
- pengambilan
- Pengembalian
- Review
- Peran
- Run
- berjalan
- s
- sama
- mengatakan
- Skala
- skala
- skenario
- skenario
- SDK
- Pencarian
- melihat
- semantik
- semantik
- senior
- putusan pengadilan
- sentimen
- terpisah
- Tanpa Server
- Layanan
- dia
- mirip
- Sederhana
- kesederhanaan
- disederhanakan
- menyederhanakan
- tunggal
- ENAM
- So
- Perangkat lunak
- rekayasa Perangkat Lunak
- Solusi
- MEMECAHKAN
- Memecahkan
- beberapa
- sesuatu
- sumber
- sumber
- Space
- Bicara
- spesialis
- spesialisasi
- Khusus
- tertentu
- awal
- mulai
- Negara
- menyimpan
- struktur
- seperti itu
- mendukung
- Didukung
- pendukung
- Mendukung
- Mengambil
- tugas
- tim
- tech
- Teknis
- teknik
- teknik
- Teknologi
- Teknologi
- mengatakan
- teks
- Klasifikasi Teks
- pembuatan teks
- bahwa
- Grafik
- Sumber
- mereka
- Mereka
- tema
- kemudian
- Sana.
- Ini
- hal
- ini
- itu
- meskipun?
- Melalui
- waktu
- titan
- untuk
- Token
- tradisional
- Pelatihan VE
- terlatih
- transformer
- mengubah
- memahami
- pemahaman
- terpadu
- Serikat
- Amerika Serikat
- penggunaan
- menggunakan
- gunakan case
- bekas
- berguna
- Pengguna
- User Interface
- Pengguna
- menggunakan
- keperluan
- liburan
- nilai
- berbagai
- Kendaraan
- sangat
- melalui
- penglihatan
- ingin
- adalah
- menonton
- we
- jaringan
- aplikasi web
- layanan web
- Webinars
- BAIK
- adalah
- Barat
- ketika
- yang
- sementara
- lebar
- Rentang luas
- akan
- dengan
- dalam
- tanpa
- Wanita
- Word
- kata
- Kerja
- kerja
- bekerja
- Lokakarya
- akan
- menulis
- penulisan
- tahun
- kamu
- Anda
- Youtube
- zephyrnet.dll