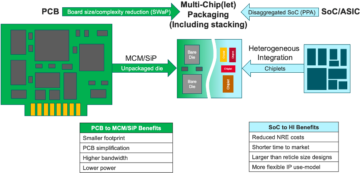
Pakar di Meja: Teknik Semikonduktor duduk untuk membicarakan masa depan memori dalam sistem yang semakin heterogen, dengan Frank Ferro, direktur grup, manajemen produk di Irama; Steven Woo, rekan dan penemu terkemuka di Rambus; Jongsin Yun, ahli teknologi memori di EDA Siemens; Randy White, manajer program solusi memori di Penglihatan kunci; dan Frank Schirrmeister, wakil presiden solusi dan pengembangan bisnis di arteri. Berikut cuplikan percakapan tersebut. Bagian pertama dari pembahasan ini dapat ditemukan di sini.
![[Kiri-Kanan]: Frank Ferro, Irama; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Penglihatan Kunci; dan Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[Kiri-Kanan]: Frank Ferro, Irama; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Penglihatan Kunci; dan Frank Schirrmeister, Arteris
SE: Saat kita berjuang melawan AI/ML dan kebutuhan daya, konfigurasi apa yang perlu dipikirkan ulang? Akankah kita melihat pergeseran dari arsitektur Von Neumann?
Merayu: Dalam hal arsitektur sistem, terdapat bifurkasi yang terjadi di industri. Aplikasi tradisional yang merupakan pekerja keras dominan, yang kami jalankan di cloud pada server berbasis x86, tidak akan hilang. Ada beberapa dekade perangkat lunak yang telah dibangun dan dikembangkan, dan akan bergantung pada arsitektur tersebut untuk bekerja dengan baik. Sebaliknya, AI/ML adalah kelas baru. Orang-orang telah memikirkan kembali arsitekturnya dan membangun prosesor yang sangat spesifik untuk domain. Kami melihat bahwa sekitar dua pertiga energi dihabiskan hanya untuk memindahkan data antara prosesor dan perangkat HBM, sementara hanya sekitar sepertiga yang dihabiskan untuk mengakses bit-bit di inti DRAM. Pergerakan data kini jauh lebih menantang dan mahal. Kami tidak akan menghilangkan ingatan. Kami membutuhkannya karena datasetnya semakin besar. Jadi pertanyaannya adalah, 'Apa cara yang benar untuk maju?' Ada banyak diskusi tentang penumpukan. Jika kami mengambil memori itu dan meletakkannya langsung di atas prosesor, ada dua hal yang bermanfaat bagi Anda. Pertama, bandwidth saat ini dibatasi oleh tepi pantai atau perimeter chip. Di situlah I/O pergi. Namun jika Anda menumpuknya langsung di atas prosesor, sekarang Anda dapat memanfaatkan seluruh area chip untuk interkoneksi terdistribusi, dan Anda bisa mendapatkan lebih banyak bandwidth dalam memori itu sendiri, dan dapat langsung dimasukkan ke dalam memori. prosesor. Tautan menjadi jauh lebih pendek, dan efisiensi daya mungkin meningkat sekitar 5X hingga 6X. Kedua, jumlah bandwidth yang bisa Anda peroleh karena lebih banyak area interkoneksi array ke memori juga meningkat, dengan beberapa faktor bilangan bulat. Melakukan kedua hal tersebut secara bersamaan dapat memberikan lebih banyak bandwidth dan menjadikannya lebih hemat daya. Industri berkembang sesuai kebutuhan, dan hal ini tentunya merupakan salah satu cara kita melihat sistem memori mulai berevolusi di masa depan agar menjadi lebih hemat daya dan menyediakan lebih banyak bandwidth.
Besi: Saat saya pertama kali mengerjakan HBM sekitar tahun 2016, beberapa pelanggan tingkat lanjut bertanya apakah HBM dapat ditumpuk. Mereka telah mencari cara untuk menumpuk DRAM di atas selama beberapa waktu karena jelas ada keuntungannya. Dari lapisan fisik, PHY pada dasarnya dapat diabaikan, sehingga menghemat banyak daya dan efisiensi. Namun sekarang Anda memiliki prosesor berkekuatan 100W yang dilengkapi memori di atasnya. Ingatan tidak tahan panas. Ini mungkin merupakan mata rantai terlemah dalam rantai panas, sehingga menciptakan tantangan lain. Memang ada manfaatnya, namun mereka masih harus memikirkan cara mengatasi panas tersebut. Kini terdapat lebih banyak insentif untuk memajukan jenis arsitektur tersebut, karena arsitektur tersebut benar-benar menghemat kinerja dan daya secara keseluruhan, serta meningkatkan efisiensi komputasi Anda. Namun ada beberapa tantangan desain fisik yang harus diatasi. Seperti yang Steve katakan, kita melihat semua jenis arsitektur yang bermunculan. Saya sangat setuju bahwa arsitektur GPU/CPU tidak akan kemana-mana, mereka akan tetap dominan. Pada saat yang sama, setiap perusahaan di dunia sedang mencoba membuat perangkap tikus yang lebih baik untuk melakukan AI mereka. Kami melihat SRAM on-chip dan kombinasi memori bandwidth tinggi. LPDDR telah banyak melakukan perubahan akhir-akhir ini dalam hal bagaimana memanfaatkan LPDDR di pusat data karena kekuatannya. Kami bahkan telah melihat GDDR digunakan di beberapa aplikasi inferensi AI, serta semua sistem memori lama. Mereka kini mencoba memanfaatkan sebanyak mungkin DDR5. Saya telah melihat setiap arsitektur yang dapat Anda pikirkan, apakah itu DDR, HBM, GDDR, atau lainnya. Hal ini bergantung pada inti prosesor Anda dalam kaitannya dengan nilai tambah Anda secara keseluruhan, dan kemudian bagaimana Anda dapat menembus arsitektur khusus Anda. Sistem memori yang menyertainya, sehingga Anda dapat menyusun CPU dan arsitektur memori Anda, bergantung pada apa yang tersedia.
Dan sebuah: Masalah lainnya adalah non-volatilitas. Jika AI harus berurusan dengan interval daya di antara menjalankan AI berbasis IoT, misalnya, maka kita memerlukan banyak daya untuk mematikan dan menghidupkan, dan semua informasi untuk pelatihan AI ini harus diputar berulang kali. Jika kita mempunyai solusi yang dapat menyimpan bobot tersebut ke dalam chip sehingga kita tidak harus selalu berpindah-pindah untuk bobot yang sama, maka hal ini akan menghemat banyak daya, terutama untuk AI berbasis IoT. Akan ada solusi lain untuk membantu kebutuhan listrik tersebut.
Schirmeister: Apa yang menurut saya menarik, dari perspektif NoC, adalah saat Anda harus mengoptimalkan jalur ini dari prosesor yang melewati NoC, mengakses antarmuka memori dengan pengontrol yang berpotensi melalui UCIe untuk meneruskan sebuah chiplet ke chiplet lain, yang kemudian memiliki memori di dalamnya. dia. Bukan berarti arsitektur Von Neumann sudah mati. Namun kini ada banyak variasi, bergantung pada beban kerja yang ingin Anda hitung. Mereka perlu dipertimbangkan dalam konteks ingatan, dan ingatan hanyalah salah satu aspek. Dari mana Anda mendapatkan data dari lokalitas data, bagaimana pengaturannya di DRAM ini? Kami sedang mengerjakan semua hal ini, seperti analisis kinerja memori dan kemudian mengoptimalkan arsitektur sistem di dalamnya. Hal ini memacu banyak inovasi untuk arsitektur baru, yang tidak pernah terpikirkan oleh saya ketika saya masih di universitas mempelajari tentang Von Neumann. Di ujung yang lain, Anda memiliki sesuatu seperti jerat. Ada lebih banyak arsitektur yang perlu dipertimbangkan, dan hal ini didorong oleh bandwidth memori, kemampuan komputasi, dan sebagainya, yang tidak tumbuh pada tingkat yang sama.
Putih: Ada tren yang melibatkan komputasi terpilah atau komputasi terdistribusi, yang berarti arsitek perlu memiliki lebih banyak alat. Hirarki memori telah diperluas. Ada semantik yang disertakan, serta CXL dan memori hybrid berbeda, yang tersedia untuk flash dan DRAM. Aplikasi paralel dengan pusat data adalah otomotif. Otomotif selalu menghitung sensor ini dengan ECU (unit kontrol elektronik). Saya terpesona dengan perkembangannya hingga menjadi pusat data. Maju cepat, dan hari ini kami telah mendistribusikan node komputasi, yang disebut pengontrol domain. Itu adalah hal yang sama. Perusahaan ini mencoba menjawab bahwa mungkin daya bukanlah masalah besar karena skala komputer tidak begitu besar, namun latensi tentu saja merupakan masalah besar dalam dunia otomotif. ADAS membutuhkan bandwidth super tinggi, dan Anda mempunyai pengorbanan yang berbeda. Dan kemudian Anda mendapatkan lebih banyak sensor mekanis, tetapi kendala serupa ada di pusat data. Anda memiliki penyimpanan dingin yang tidak memerlukan latensi rendah, dan Anda juga memiliki aplikasi bandwidth tinggi lainnya. Sangat menarik untuk melihat seberapa banyak alat dan pilihan arsitek telah berkembang. Industri ini telah melakukan upaya yang sangat baik dalam merespons hal ini, dan kami semua memberikan berbagai solusi yang dapat membantu pasar.
SE: Bagaimana alat desain memori berevolusi?
Schirmeister: Ketika saya memulai dengan beberapa chip pertama saya di tahun 90an, alat sistem yang paling banyak digunakan adalah Excel. Sejak saat itu, saya selalu berharap hal ini dapat merusak hal-hal yang kami lakukan pada tingkat sistem, memori, analisis bandwidth, dan sebagainya. Hal ini cukup berdampak pada tim saya. Pada saat itu, hal-hal tersebut sangat canggih. Namun menurut Randy, kini hal-hal rumit tertentu perlu disimulasikan pada tingkat ketelitian yang sebelumnya tidak mungkin dilakukan tanpa komputasi. Sebagai contoh, mengasumsikan latensi tertentu untuk akses DRAM dapat menyebabkan keputusan arsitektur yang buruk dan berpotensi salah merancang arsitektur transportasi data pada chip. Sisi sebaliknya juga benar. Jika Anda selalu berasumsi kasus terburuk, maka Anda akan mendesain arsitektur secara berlebihan. Memiliki alat yang melakukan DRAM dan analisis kinerja, dan memiliki model yang tepat untuk pengontrol memungkinkan seorang arsitek untuk mensimulasikan semuanya, itu adalah lingkungan yang menarik. Harapan saya dari tahun 90an bahwa Excel pada suatu saat akan menjadi sebuah terobosan. alat tingkat sistem mungkin benar-benar menjadi kenyataan, karena pengaruh dinamis tertentu tidak dapat Anda lakukan lagi di Excel karena Anda perlu mensimulasikannya — terutama saat Anda memasukkan antarmuka mati-ke-mati dengan karakteristik PHY, dan kemudian menghubungkan lapisan karakteristik seperti semua pengecekan apakah semuanya sudah benar dan berpotensi mengirim ulang data. Jika simulasi tersebut tidak dilakukan akan menghasilkan arsitektur yang kurang optimal.
Besi: Langkah pertama dalam sebagian besar evaluasi yang kami lakukan adalah memberi mereka testbench memori untuk mulai melihat efisiensi DRAM. Itu adalah langkah besar, bahkan melakukan hal-hal sederhana seperti menjalankan alat lokal untuk melakukan simulasi DRAM, namun kemudian melanjutkan ke simulasi menyeluruh. Kami melihat semakin banyak pelanggan yang meminta simulasi semacam itu. Memastikan efisiensi DRAM Anda mencapai angka 90an adalah langkah pertama yang sangat penting dalam evaluasi apa pun.
Merayu: Salah satu alasan mengapa Anda melihat munculnya alat simulasi sistem lengkap adalah karena DRAM menjadi jauh lebih rumit. Saat ini sangat sulit untuk mengatasi beberapa beban kerja kompleks ini dengan menggunakan alat sederhana seperti Excel. Jika Anda melihat datasheet DRAM di tahun 90-an, lembar data tersebut berjumlah 40 halaman. Sekarang jumlahnya ratusan halaman. Itu hanya menunjukkan kompleksitas perangkat untuk mengeluarkan bandwidth tinggi. Anda menggabungkannya dengan fakta bahwa memori merupakan pendorong biaya sistem, serta bandwidth dan latensi yang terkait dengan kinerja prosesor. Ini juga merupakan pendorong besar dalam hal kekuatan, sehingga Anda perlu melakukan simulasi pada tingkat yang jauh lebih detail sekarang. Dalam hal aliran alat, arsitek sistem memahami bahwa memori adalah pendorong yang sangat besar. Jadi alat-alat tersebut harus lebih canggih, dan harus terhubung dengan alat-alat lain dengan sangat baik sehingga arsitek sistem mendapatkan gambaran global terbaik tentang apa yang sedang terjadi — terutama mengenai bagaimana memori berdampak pada sistem.
Dan sebuah: Saat kita beralih ke era AI, banyak sistem multi-core yang digunakan, namun kita tidak tahu data mana yang dibawa ke mana. Ini juga menjadi lebih paralel dengan chip. Ukuran memorinya jauh lebih besar. Jika kita menggunakan AI tipe ChatGPT, maka penanganan data untuk model tersebut memerlukan sekitar 350 MB data, yang merupakan jumlah data yang sangat besar hanya untuk bobotnya, dan input/output sebenarnya jauh lebih besar. Peningkatan jumlah data yang dibutuhkan berarti terdapat banyak efek probabilistik yang belum pernah kita lihat sebelumnya. Ini merupakan pengujian yang sangat menantang untuk melihat semua kesalahan yang terkait dengan jumlah memori yang besar ini. Dan ECC digunakan di mana-mana, bahkan di SRAM, yang biasanya tidak menggunakan ECC, tetapi sekarang ECC sangat umum digunakan pada sistem terbesar. Pengujian terhadap semua itu sangatlah menantang dan perlu didukung oleh solusi EDA untuk menguji semua kondisi yang berbeda tersebut.
SE: Tantangan apa yang dihadapi tim teknik sehari-hari?
Putih: Pada hari tertentu, Anda akan menemukan saya di lab. Saya menyingsingkan lengan baju dan tangan saya kotor, menyodok kabel, menyolder, dan yang lainnya. Saya banyak memikirkan tentang validasi pasca-silikon. Kami berbicara tentang simulasi awal dan alat on-die — BiST, dan hal-hal seperti itu. Pada akhirnya, sebelum mengirimkannya, kami ingin melakukan beberapa bentuk validasi sistem atau pengujian tingkat perangkat. Kami berbicara tentang cara mengatasi dinding memori. Kami menemukan lokasi memori, HBM, hal-hal seperti itu. Jika kita melihat evolusi teknologi pengemasan, kami memulai dengan kemasan bertimbal. Mereka tidak terlalu bagus untuk integritas sinyal. Beberapa dekade kemudian, kami beralih ke integritas sinyal yang dioptimalkan, seperti ball grid arrays (BGA). Kami tidak dapat mengaksesnya, artinya Anda tidak dapat mengujinya. Jadi kami datang dengan konsep yang disebut interposer perangkat — interposer BGA — dan itu memungkinkan kami untuk mengapit perlengkapan khusus yang menyalurkan sinyal keluar. Kemudian kita bisa menghubungkannya ke alat uji. Kini kita memiliki HBM dan chiplet. Bagaimana cara saya menyelipkan perlengkapan saya di antara interposer silikon? Kami tidak bisa, dan itulah perjuangannya. Ini adalah tantangan yang membuat saya terjaga di malam hari. Bagaimana kita melakukan analisis kegagalan di lapangan dengan OEM atau pelanggan sistem, yang tidak mendapatkan efisiensi 90%. Ada lebih banyak kesalahan pada tautan, kesalahan tersebut tidak dapat diinisialisasi dengan benar, dan pelatihan tidak berfungsi. Apakah ini masalah integritas sistem?
Schirmeister: Bukankah Anda lebih suka melakukan ini dari rumah dengan antarmuka virtual daripada berjalan ke lab? Bukankah jawabannya lebih banyak analisis yang Anda masukkan ke dalam chip? Dengan chiplet, kami mengintegrasikan segalanya lebih jauh lagi. Memasang besi solder Anda sebenarnya bukanlah suatu pilihan, jadi perlu ada cara untuk analisis on-chip. Kami memiliki masalah yang sama untuk NoC. Orang-orang melihat NoC, dan Anda mengirim datanya lalu hilang. Kami memerlukan analitik untuk diterapkan di sana sehingga orang dapat melakukan debug, dan itu meluas hingga ke tingkat manufaktur, sehingga Anda akhirnya dapat bekerja dari rumah dan melakukan semuanya berdasarkan analisis chip.
Besi: Apalagi dengan memori bandwidth tinggi, Anda tidak bisa masuk ke sana secara fisik. Saat kami melisensikan PHY, kami juga memiliki produk yang menyertainya sehingga Anda dapat melihat setiap 1,024 bit tersebut. Anda dapat mulai membaca dan menulis DRAM dari alat ini sehingga Anda tidak perlu masuk ke sana secara fisik. Saya suka ide interposer. Kami mengeluarkan beberapa pin dari interposer selama pengujian, yang tidak dapat Anda lakukan di sistem. Benar-benar sebuah tantangan untuk masuk ke sistem 3D ini. Bahkan dari sudut pandang aliran alat desain, sepertinya sebagian besar perusahaan melakukan alirannya sendiri pada banyak alat 2.5D ini. Kami mulai menyusun cara yang lebih terstandarisasi untuk membangun sistem 2.5D, mulai dari integritas sinyal, daya, dan keseluruhan aliran.
Putih: Seiring berjalannya waktu, saya berharap kita masih dapat mempertahankan tingkat akurasi yang sama. Saya tergabung dalam kelompok kepatuhan faktor bentuk UCIe. Saya sedang mencari cara untuk mengkarakterisasi dadu yang dikenal baik, dadu emas. Pada akhirnya, hal ini akan memakan lebih banyak waktu, namun kami akan menemukan titik temu antara performa dan akurasi pengujian yang kami perlukan, serta fleksibilitas yang ada di dalamnya.
Schirmeister: Jika saya melihat chiplet dan penerapannya di lingkungan produksi yang lebih terbuka, pengujian adalah salah satu tantangan terbesar dalam cara membuatnya berfungsi dengan baik. Jika saya adalah perusahaan besar dan saya mengendalikan semua sisinya, maka saya dapat membatasi berbagai hal dengan tepat sehingga pengujian dan sebagainya dapat dilakukan. Jika saya ingin menggunakan slogan UCIe bahwa UCI hanya berjarak satu huruf dari PCI, dan saya membayangkan masa depan di mana perakitan UCIe, dari perspektif manufaktur, menjadi seperti slot PCI di PC saat ini, maka aspek pengujiannya benar-benar menantang. Kita perlu menemukan solusinya. Ada banyak pekerjaan yang harus dilakukan.
Artikel terkait
Masa Depan Memori (Bagian 1 dari putaran di atas)
Dari upaya untuk mengatasi masalah termal dan listrik hingga peran CXL dan UCIe, masa depan memiliki sejumlah peluang untuk diingat.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://semiengineering.com/rethinking-memory/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 2016
- 3d
- 40
- a
- Tentang Kami
- atas
- mengakses
- mengakses
- ketepatan
- sebenarnya
- sebenarnya
- ADA
- menambahkan
- alamat
- Adopsi
- maju
- Keuntungan
- keuntungan
- lagi
- AI
- Pelatihan AI
- AI / ML
- Semua
- diizinkan
- memungkinkan
- juga
- selalu
- jumlah
- an
- analisis
- analisis
- dan
- Lain
- menjawab
- Apa pun
- lagi
- di manapun
- Aplikasi
- aplikasi
- tepat
- arsitek
- arsitektur
- ADALAH
- DAERAH
- sekitar
- diatur
- susunan
- AS
- meminta
- penampilan
- aspek
- Majelis
- menganggap
- At
- Mencoba
- otomotif
- tersedia
- jauh
- kembali
- Buruk
- bola
- Bandwidth
- bar
- berdasarkan
- Pada dasarnya
- dasar
- BE
- karena
- menjadi
- menjadi
- menjadi
- sebelum
- makhluk
- Manfaat
- TERBAIK
- Lebih baik
- antara
- Besar
- lebih besar
- Bit
- Istirahat
- membawa
- membangun
- dibangun di
- bisnis
- pengembangan bisnis
- tapi
- by
- Irama
- bernama
- datang
- CAN
- Bisa Dapatkan
- kemampuan
- kasus
- pusat
- tertentu
- Pasti
- rantai
- menantang
- tantangan
- menantang
- karakteristik
- mencirikan
- memeriksa
- keping
- Keripik
- kelas
- jelas
- awan
- dingin
- Penyimpanan dingin
- kombinasi
- bagaimana
- kedatangan
- Umum
- Perusahaan
- perusahaan
- kompleks
- kompleksitas
- pemenuhan
- rumit
- menghitung
- komputer
- komputasi
- konsep
- Kondisi
- Terhubung
- dianggap
- kendala
- konteks
- kontras
- kontrol
- pengawas
- Percakapan
- Core
- benar
- Biaya
- bisa
- sepasang
- CPU
- menciptakan
- pelanggan
- pelanggan
- data
- Data Center
- kumpulan data
- hari
- hari ke hari
- Hari
- mati
- transaksi
- dekade
- keputusan
- pastinya
- tuntutan
- Tergantung
- tergantung
- Mendesain
- merancang
- terperinci
- Pengembangan
- alat
- Mati
- berbeda
- sulit
- langsung
- Kepala
- diskusi
- pembuangan
- Terkemuka
- didistribusikan
- komputasi terdistribusi
- do
- tidak
- Tidak
- melakukan
- domain
- dominan
- dilakukan
- Dont
- turun
- didorong
- pengemudi
- selama
- dinamis
- Awal
- efek
- efisiensi
- efisien
- Elektronik
- akhir
- energi
- Teknik
- Seluruh
- Lingkungan Hidup
- peralatan
- Era
- kesalahan
- terutama
- Eter (ETH)
- evaluasi
- evaluasi
- Bahkan
- akhirnya
- Setiap
- segala sesuatu
- di mana-mana
- evolusi
- berkembang
- berkembang
- berevolusi
- contoh
- Excel
- diperluas
- mahal
- Meluas
- ekstrim
- sangat
- mata
- Menghadapi
- fakta
- faktor
- Kegagalan
- sangat menarik
- FAST
- layak
- sesama
- kesetiaan
- bidang
- Angka
- Akhirnya
- Menemukan
- Pertama
- flash
- keluwesan
- Penerjunan
- aliran
- berikut
- Tapak
- Untuk
- bentuk
- sebagainya
- Depan
- ditemukan
- jujur
- dari
- penuh
- lebih lanjut
- masa depan
- mendapatkan
- mendapatkan
- Memberikan
- diberikan
- Aksi
- Go
- Pergi
- akan
- Keemasan
- mati
- baik
- pekerjaan yang baik
- mendapat
- kisi
- Kelompok
- Pertumbuhan
- memiliki
- Penanganan
- tangan
- senang
- Memiliki
- memiliki
- kepala
- membantu
- hirarki
- High
- memegang
- Beranda
- berharap
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- besar
- Ratusan
- Hibrida
- i
- ide
- if
- membayangkan
- dampak
- berdampak
- penting
- memperbaiki
- in
- Insentif
- termasuk
- salah
- Meningkatkan
- makin
- sendiri-sendiri
- industri
- informasi
- Innovation
- dalam
- mengintegrasikan
- integritas
- interkoneksi
- Antarmuka
- ke
- melibatkan
- isu
- masalah
- IT
- NYA
- Diri
- Pekerjaan
- hanya
- Tahu
- dikenal
- laboratorium
- besar
- lebih besar
- terbesar
- Latensi
- kemudian
- lapisan
- memimpin
- pengetahuan
- surat
- Tingkat
- Lisensi
- 'like'
- Terbatas
- LINK
- link
- lokal
- melihat
- mencari
- Lot
- banyak
- Rendah
- memelihara
- membuat
- Membuat
- pengelolaan
- manajer
- pabrik
- banyak
- Pasar
- max-width
- mungkin
- me
- cara
- berarti
- mekanis
- medium
- kenangan
- Memori
- mungkin
- model
- lebih
- paling
- pindah
- terharu
- gerakan
- bergerak
- banyak
- my
- Perlu
- kebutuhan
- tak pernah
- New
- malam
- node
- sekarang
- jumlah
- of
- lepas
- Tua
- on
- ONE
- hanya
- Buka
- Peluang
- Optimize
- dioptimalkan
- mengoptimalkan
- pilihan
- Opsi
- or
- urutan
- Lainnya
- Lainnya
- di luar
- secara keseluruhan
- Mengatasi
- sendiri
- paket
- pengemasan
- halaman
- Paralel
- bagian
- tertentu
- lulus
- path
- jalan
- PC
- Konsultan Ahli
- melakukan
- prestasi
- perspektif
- fisik
- Secara fisik
- pin
- planet
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- mungkin
- berpotensi
- kekuasaan
- presiden
- sebelumnya
- mungkin
- Masalah
- Prosesor
- prosesor
- Produk
- manajemen Produk
- Produksi
- program
- tepat
- tepat
- memberikan
- menempatkan
- pertanyaan
- agak
- pemeliharaan
- Penilaian
- agak
- Bacaan
- benar-benar
- terkait
- mengandalkan
- wajib
- membutuhkan
- menyelesaikan
- menanggapi
- mengakibatkan
- Membersihkan
- benar
- Naik
- peran
- Menggulung
- Run
- berjalan
- sama
- Save
- Tabungan
- mengatakan
- Skala
- Kedua
- melihat
- melihat
- tampaknya
- terlihat
- semantik
- semikonduktor
- mengirim
- Sensor
- sensor
- server
- beberapa
- lembar
- bergeser
- kapal
- sisi
- Sisi
- Siemens
- Sinyal
- sinyal
- Silikon
- mirip
- Sederhana
- simulasi
- simulasi
- sejak
- tunggal
- Ukuran
- slot
- So
- Perangkat lunak
- larutan
- Solusi
- beberapa
- mutakhir
- Bicara
- khusus
- menghabiskan
- Meremas
- tumpukan
- ditumpuk
- menumpuk
- standar
- sudut
- awal
- mulai
- Mulai
- Langkah
- Steve
- steven
- Masih
- penyimpanan
- menyimpan
- Perjuangan
- seperti itu
- Didukung
- yakin
- sistem
- sistem
- tabel
- Mengambil
- Berbicara
- tim
- teknologis
- Teknologi
- istilah
- uji
- pengujian
- tes
- dari
- bahwa
- Grafik
- Masa depan
- mereka
- Mereka
- kemudian
- Sana.
- panas
- Ini
- mereka
- hal
- hal
- berpikir
- Ketiga
- ini
- itu
- pikir
- Melalui
- waktu
- untuk
- hari ini
- bersama
- alat
- alat
- puncak
- SAMA SEKALI
- pengorbanan
- tradisional
- secara tradisional
- Pelatihan
- mengangkut
- kecenderungan
- benar
- mencoba
- dua
- dua pertiga
- mengetik
- memahami
- unit
- universitas
- us
- menggunakan
- bekas
- menggunakan
- pengesahan
- nilai
- variasi
- berbagai
- sangat
- wakil
- Wakil Presiden
- View
- maya
- dari
- berjalan
- Dinding
- ingin
- adalah
- Cara..
- we
- berat
- BAIK
- adalah
- Apa
- apa pun
- ketika
- apakah
- yang
- sementara
- putih
- seluruh
- mengapa
- akan
- dengan
- tanpa
- woo
- Kerja
- bekerja dari rumah
- kerja
- terburuk
- penulisan
- kamu
- Anda
- zephyrnet.dll