Gambar oleh Penulis
When you are getting started with machine learning, logistic regression is one of the first algorithms you’ll add to your toolbox. It’s a simple and robust algorithm, commonly used for binary classification tasks.
Pertimbangkan masalah klasifikasi biner dengan kelas 0 dan 1. Regresi logistik menyesuaikan fungsi logistik atau sigmoid dengan data masukan dan memprediksi probabilitas titik data kueri yang termasuk dalam kelas 1. Menarik bukan?
Dalam tutorial ini, kita akan belajar tentang regresi logistik dari awal yang mencakup:
- Fungsi logistik (atau sigmoid).
- Bagaimana kita beralih dari regresi linier ke regresi logistik
- Cara kerja regresi logistik
Terakhir, kita akan membuat model regresi logistik sederhana mengklasifikasikan pengembalian RADAR dari ionosfer.
Before we learn more about logistic regression, let’s review how the logistic function works. The logistic (or sigmoid function) is given by:

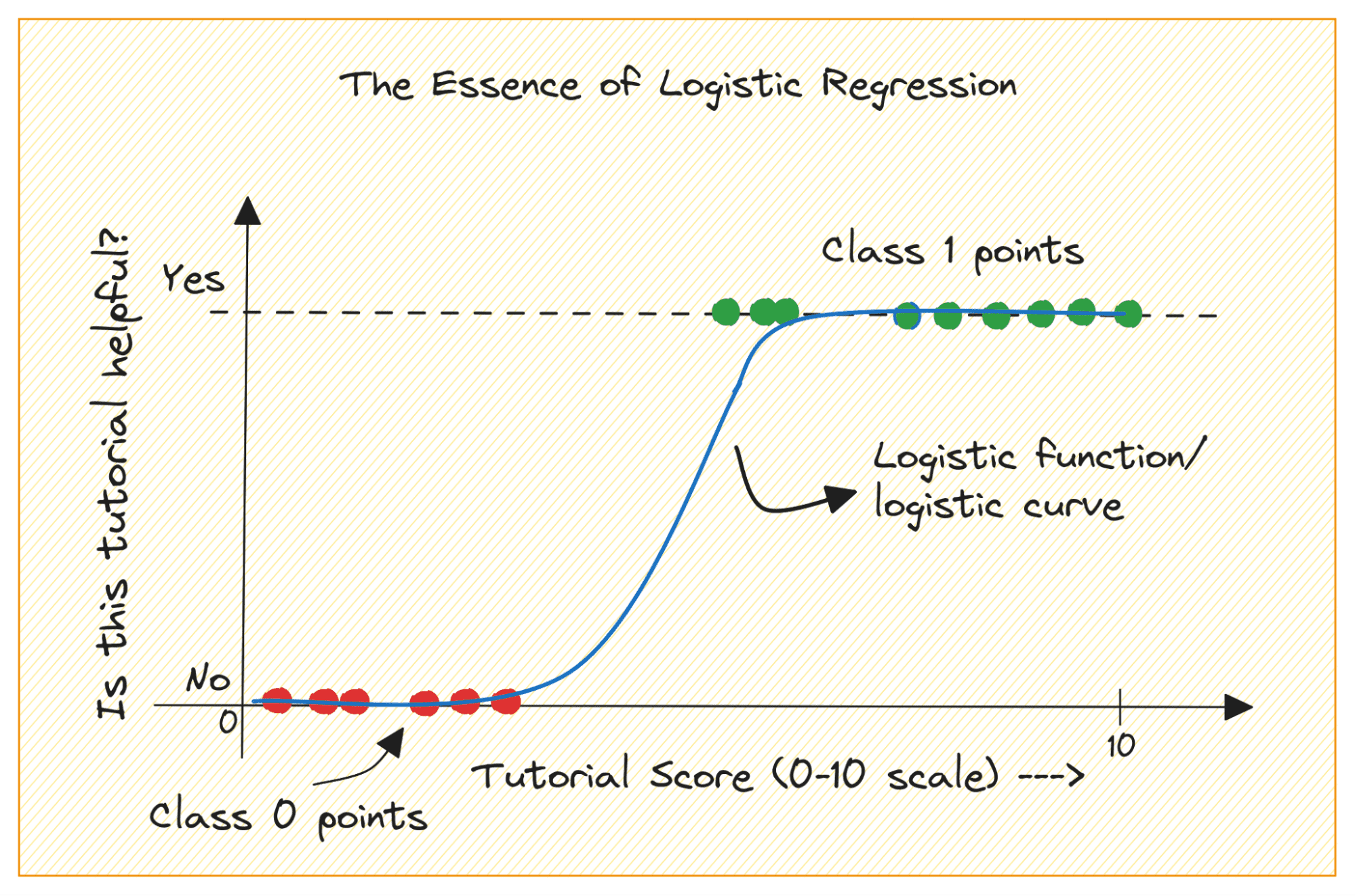
Saat Anda memplot fungsi sigmoid, tampilannya akan seperti ini:
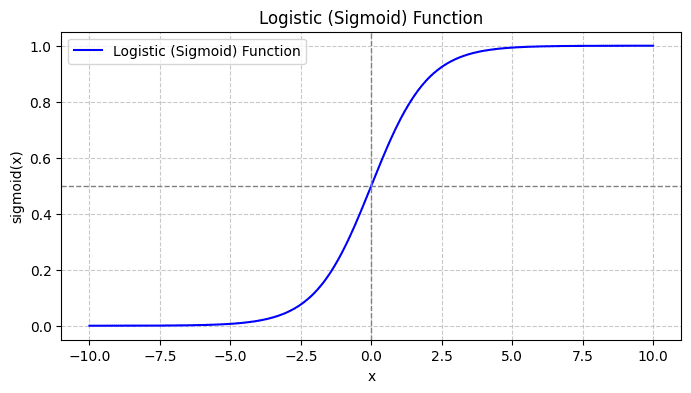
Dari alur cerita kita melihat bahwa:
- Ketika x = 0, σ(x) bernilai 0.5.
- Ketika x mendekati +∞, σ(x) mendekati 1.
- Ketika x mendekati -∞, σ(x) mendekati 0.
Jadi untuk semua masukan nyata, fungsi sigmoid menekannya untuk mengambil nilai dalam rentang [0, 1].
Let’s first discuss why we cannot use linear regression for a binary classification problem.
Dalam masalah klasifikasi biner, keluarannya adalah label kategorikal (0 atau 1). Karena regresi linier memprediksi keluaran bernilai kontinu yang bisa kurang dari 0 atau lebih besar dari 1, hal ini tidak masuk akal untuk permasalahan yang ada.
Selain itu, garis lurus mungkin tidak cocok jika label keluaran termasuk dalam salah satu dari dua kategori tersebut.
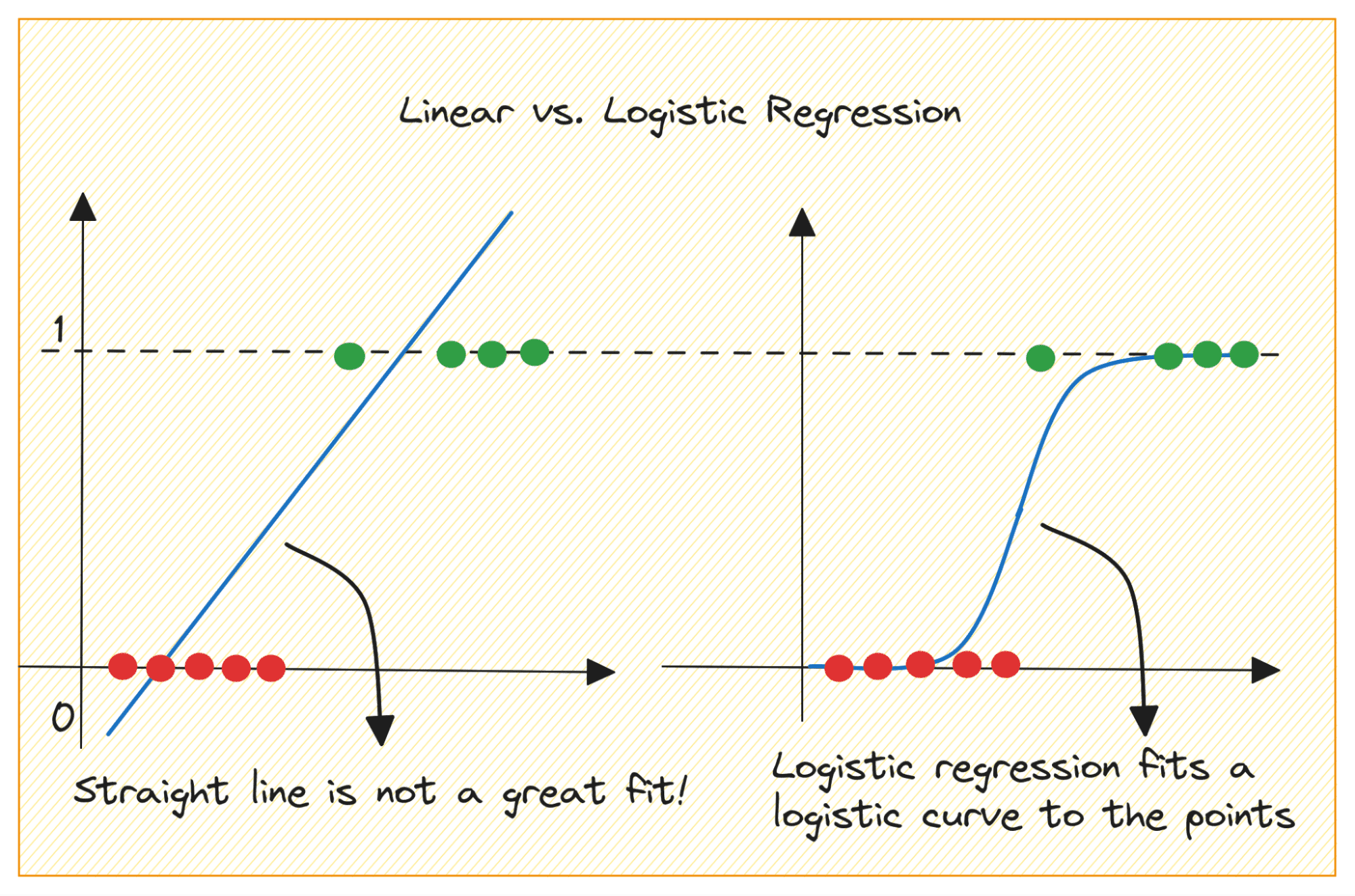
Gambar oleh Penulis
Jadi bagaimana kita beralih dari regresi linier ke regresi logistik? Dalam regresi linier, keluaran yang diprediksi diberikan oleh:
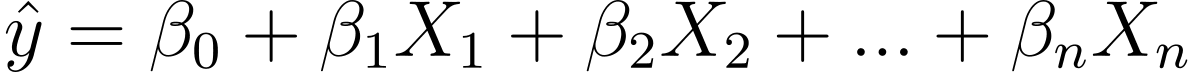
Dimana βs adalah koefisien dan X_is adalah prediktor (atau fitur).
Tanpa kehilangan sifat umum, asumsikan X_0 = 1:

Jadi kita dapat memiliki ekspresi yang lebih ringkas:
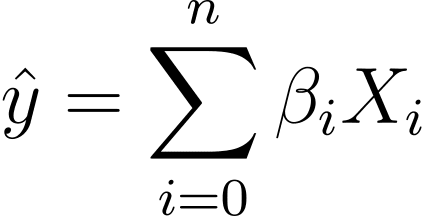
Dalam regresi logistik, kita memerlukan probabilitas prediksi p_i dalam interval [0,1]. Kita tahu bahwa fungsi logistik menekan masukan sehingga mengambil nilai dalam interval [0,1].
Jadi dengan memasukkan ekspresi ini ke dalam fungsi logistik, kita memiliki probabilitas prediksi sebagai:
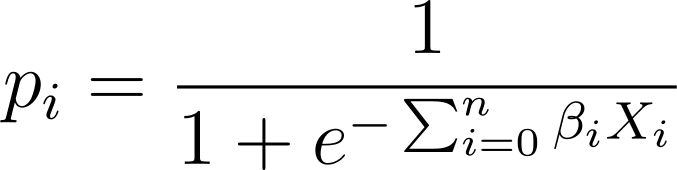
Jadi bagaimana kita menemukan kurva logistik yang paling sesuai untuk kumpulan data tertentu? Untuk menjawabnya, mari kita pahami estimasi kemungkinan maksimum.
Estimasi Kemungkinan Maksimum (MLE) is used to estimate the parameters of the logistic regression model by maximizing the likelihood function. Let’s break down the process of MLE in logistic regression and how the cost function is formulated for optimization using gradient descent.
Merinci Estimasi Kemungkinan Maksimum
Seperti yang telah dibahas, kami memodelkan probabilitas terjadinya hasil biner sebagai fungsi dari satu atau lebih variabel (atau fitur prediktor):
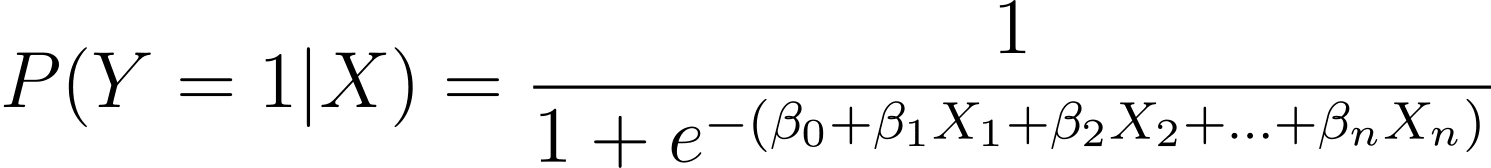
Here, the βs are the model parameters or coefficients. X_1, X_2,…, X_n are the predictor variables.
MLE bertujuan untuk mencari nilai β yang memaksimalkan kemungkinan data observasi. Fungsi kemungkinan, dilambangkan sebagai L(β), mewakili probabilitas pengamatan hasil tertentu untuk nilai prediktor tertentu berdasarkan model regresi logistik.
Merumuskan Fungsi Log-Likehood
To simplify the optimization process, it’s common to work with the log-likelihood function. Because it transforms products of probabilities into sums of log probabilities.
Fungsi log-likelihood untuk regresi logistik diberikan oleh:
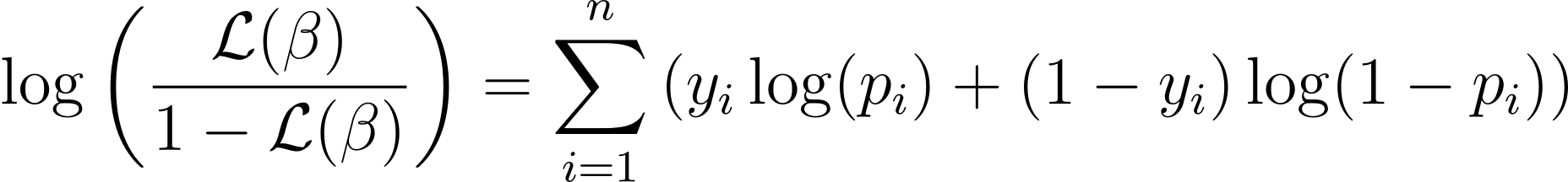
Now that we know the essence of log-likelihood, let’s proceed to formulate the cost function for logistic regression and subsequently gradient descent for finding the best model parameters
Fungsi Biaya untuk Regresi Logistik
Untuk mengoptimalkan model regresi logistik, kita perlu memaksimalkan kemungkinan log. Jadi kita dapat menggunakan kemungkinan log negatif sebagai fungsi biaya untuk meminimalkan selama pelatihan. Kemungkinan log negatif, sering disebut sebagai kerugian logistik, didefinisikan sebagai:
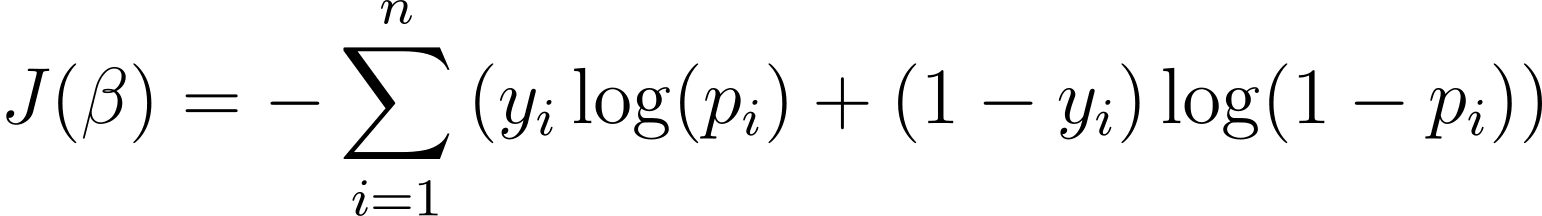
Oleh karena itu, tujuan dari algoritma pembelajaran adalah untuk menemukan nilai ? yang meminimalkan fungsi biaya ini. Penurunan gradien adalah algoritma optimasi yang umum digunakan untuk mencari nilai minimum dari fungsi biaya ini.
Penurunan Gradien dalam Regresi Logistik
Keturunan gradien adalah algoritma optimasi berulang yang memperbarui parameter model β dalam arah yang berlawanan dengan gradien fungsi biaya terhadap β. Aturan pembaruan pada langkah t+1 untuk regresi logistik menggunakan penurunan gradien adalah sebagai berikut:
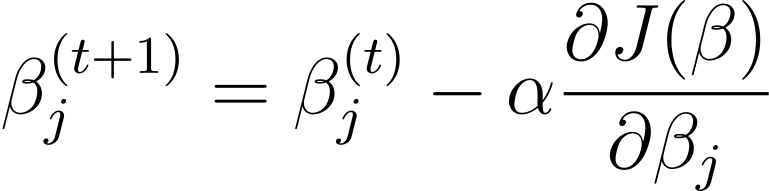
Dimana α adalah kecepatan pembelajaran.
Turunan parsial dapat dihitung dengan menggunakan aturan rantai. Penurunan gradien memperbarui parameter secara berulang—hingga konvergensi—dengan tujuan meminimalkan kerugian logistik. Saat konvergen, ia menemukan nilai β optimal yang memaksimalkan kemungkinan data yang diamati.
Sekarang setelah Anda mengetahui cara kerja regresi logistik, mari buat model prediktif menggunakan pustaka scikit-learn.
Kami akan menggunakan kumpulan data ionosfer dari repositori pembelajaran mesin UCI untuk tutorial ini. Dataset terdiri dari 34 fitur numerik. Outputnya adalah biner, salah satu dari 'baik' atau 'buruk' (dilambangkan dengan 'g' atau 'b'). Label keluaran 'baik' mengacu pada hasil RADAR yang telah mendeteksi beberapa struktur di ionosfer.
Langkah 1 – Memuat Kumpulan Data
Pertama, unduh kumpulan data dan bacakan ke dalam kerangka data pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Langkah 2 – Menjelajahi Kumpulan Data
Let’s take a look at the first few rows of the dataframe:
# Display the first few rows of the DataFrame
df.head()
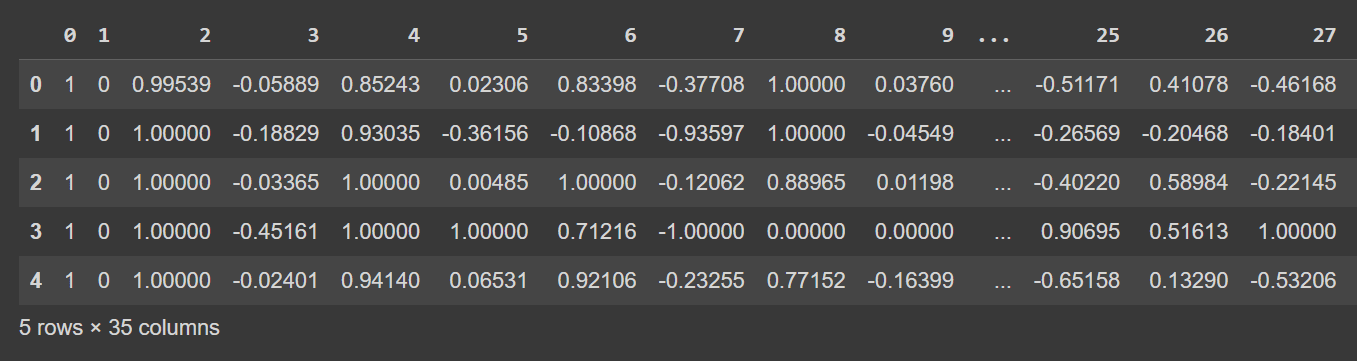
Output terpotong dari df.head()
Let’s get some information about the dataset: the number of non-null values and the data types of each of the columns:
# Get information about the dataset
print(df.info())
 Output terpotong dari df.info()
Output terpotong dari df.info()
Karena kami memiliki semua fitur numerik, kami juga dapat memperoleh beberapa statistik deskriptif menggunakan describe() metode pada kerangka data:
# Get descriptive statistics of the dataset
print(df.describe())
Output terpotong dari df.describe()
Nama kolom saat ini 0 hingga 34—termasuk labelnya. Karena kumpulan data tidak memberikan nama deskriptif untuk kolom, kumpulan data hanya merujuknya sebagai atribut_1 hingga atribut_34 jika Anda mau, Anda dapat mengganti nama kolom bingkai data seperti yang ditunjukkan:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Catatan: Langkah ini murni opsional. Anda dapat melanjutkan dengan nama kolom default jika Anda mau.
# Display the first few rows of the DataFrame
df.head()
Output terpotong dari df.head() [Setelah Mengganti Nama Kolom]
Langkah 3 – Mengganti Nama Label Kelas dan Memvisualisasikan Distribusi Kelas
Karena label kelas keluarannya adalah 'g' dan 'b', kita perlu memetakannya masing-masing ke 1 dan 0 . Anda dapat melakukannya dengan menggunakan map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Mari kita visualisasikan juga distribusi label kelas:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
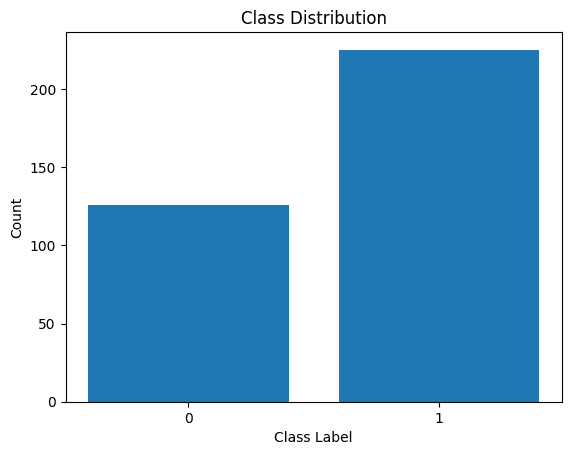
Distribusi Label Kelas
Kami melihat ada ketimpangan distribusi. Ada lebih banyak catatan yang termasuk dalam kelas 1 daripada kelas 0. Kami akan menangani ketidakseimbangan kelas ini saat membuat model regresi logistik.
Langkah 5 – Memproses Kumpulan Data terlebih dahulu
Mari kumpulkan fitur dan label keluaran seperti ini:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Setelah membagi kumpulan data menjadi kumpulan pelatihan dan pengujian, kita perlu melakukan pra-pemrosesan kumpulan data tersebut.
Jika terdapat banyak fitur numerik—masing-masing memiliki potensi skala yang berbeda—kita perlu melakukan praproses terhadap fitur numerik tersebut. Metode yang umum adalah mentransformasikannya sedemikian rupa sehingga mengikuti distribusi dengan mean nol dan varian satuan.
Grafik StandardScaler dari modul prapemrosesan scikit-learn membantu kami mencapai hal ini.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Langkah 6 – Membangun Model Regresi Logistik
Sekarang kita dapat membuat instance pengklasifikasi regresi logistik. Itu LogisticRegression kelas adalah bagian dari modul linear_model scikit-learn.
Perhatikan bahwa kita telah mengaturnya class_weight parameter menjadi 'seimbang'. Ini akan membantu kita menjelaskan ketidakseimbangan kelas. Dengan memberikan bobot pada setiap kelas—berbanding terbalik dengan jumlah record di kelas tersebut.
Setelah membuat instance kelas, kita dapat menyesuaikan model ke kumpulan data pelatihan:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Langkah 7 – Mengevaluasi Model Regresi Logistik
Anda dapat memanggil predict() metode untuk mendapatkan prediksi model.
Selain skor akurasi, kita juga bisa mendapatkan laporan klasifikasi dengan metrik seperti presisi, perolehan, dan skor F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
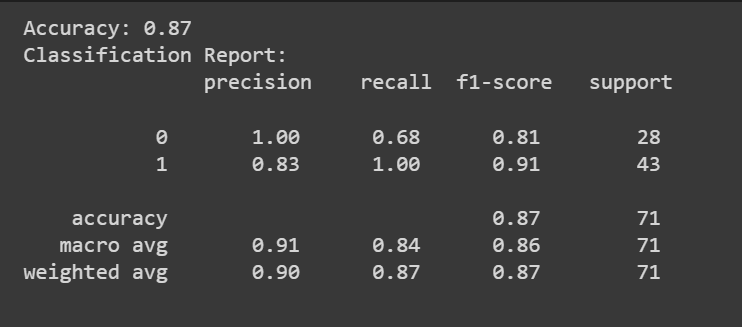
Selamat, Anda telah membuat kode model regresi logistik pertama Anda!
Dalam tutorial ini, kita mempelajari tentang regresi logistik secara detail: mulai dari teori dan matematika hingga pengkodean pengklasifikasi regresi logistik.
Sebagai langkah berikutnya, coba buat model regresi logistik untuk kumpulan data pilihan Anda.
Kumpulan data Ionosfer dilisensikan berdasarkan a Creative Commons Attribution 4.0 Internasional (CC BY 4.0) lisensi:
Sigillito,V., Wing,S., Hutton,L., dan Baker,K.. (1989). Ionosfir. Repositori Pembelajaran Mesin UCI. https://doi.org/10.24432/C5W01B.
Bala Priya C adalah pengembang dan penulis teknis dari India. Dia suka bekerja di persimpangan matematika, pemrograman, ilmu data, dan pembuatan konten. Bidang minat dan keahliannya meliputi DevOps, ilmu data, dan pemrosesan bahasa alami. Dia suka membaca, menulis, coding, dan kopi! Saat ini, dia sedang belajar dan berbagi pengetahuannya dengan komunitas developer dengan menulis tutorial, panduan cara kerja, opini, dan banyak lagi.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :adalah
- :bukan
- $NAIK
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Tentang Kami
- Akun
- ketepatan
- Mencapai
- menambahkan
- tambahan
- Setelah
- bertujuan
- algoritma
- algoritma
- Semua
- juga
- an
- dan
- menjawab
- pendekatan
- ADALAH
- daerah
- AS
- menganggap
- At
- menulis
- b
- tukang roti
- seimbang
- bar
- BE
- karena
- termasuk
- TERBAIK
- Istirahat
- membangun
- Bangunan
- by
- panggilan
- CAN
- tidak bisa
- kategori
- rantai
- pilihan
- kelas
- kelas-kelas
- klasifikasi
- berkode
- Pengkodean
- mengumpulkan
- Kolom
- Kolom
- Umum
- umum
- Ruang makan besar
- masyarakat
- terdiri dari
- ringkas
- Konten
- pembuatan konten
- mengubah
- Biaya
- penutup
- membuat
- penciptaan
- Sekarang
- melengkung
- data
- titik data
- ilmu data
- kumpulan data
- Default
- didefinisikan
- Derivatif
- rinci
- terdeteksi
- Pengembang
- DevOps
- berbeda
- arah
- membahas
- dibahas
- Display
- distribusi
- do
- tidak
- turun
- Download
- selama
- setiap
- esensi
- memperkirakan
- mengevaluasi
- keahlian
- Menjelajahi
- ekspresi
- Fitur
- beberapa
- Menemukan
- temuan
- menemukan
- Pertama
- cocok
- mengikuti
- berikut
- Untuk
- FRAME
- dari
- fungsi
- mendapatkan
- mendapatkan
- diberikan
- Go
- tujuan
- lebih besar
- Tanah
- Panduan
- tangan
- menangani
- Memiliki
- membantu
- membantu
- dia
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTTPS
- ICS
- if
- ketidakseimbangan
- mengimpor
- in
- memasukkan
- indeks
- India
- Indeks
- informasi
- memasukkan
- input
- bunga
- menarik
- persimpangan
- ke
- IT
- hanya
- KDnugget
- Tahu
- pengetahuan
- label
- Label
- bahasa
- BELAJAR
- belajar
- pengetahuan
- kurang
- membiarkan
- Perpustakaan
- Lisensi
- Izin
- 'like'
- kemungkinan
- 'like
- baris
- pemuatan
- mencatat
- melihat
- terlihat seperti
- lepas
- mesin
- Mesin belajar
- membuat
- banyak
- peta
- matematika
- matplotlib.dll
- Maksimalkan
- memaksimalkan
- maksimum
- Mungkin..
- berarti
- metode
- Metrik
- memperkecil
- minimum
- model
- model
- modul
- lebih
- pindah
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Perlu
- negatif
- berikutnya
- jumlah
- diamati
- of
- sering
- on
- ONE
- Pendapat
- seberang
- optimal
- optimasi
- Optimize
- or
- Hasil
- hasil
- keluaran
- output
- panda
- parameter
- parameter
- bagian
- potongan-potongan
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- poin
- berpotensi
- Ketelitian
- diprediksi
- Prediksi
- prediktif
- Predictor
- Prediksi
- lebih suka
- probabilitas
- Masalah
- memproses
- proses
- pengolahan
- Produk
- Pemrograman
- memberikan
- murni
- Ular sanca
- radar
- jarak
- Penilaian
- Baca
- Bacaan
- nyata
- arsip
- disebut
- mengacu
- regresi
- melaporkan
- gudang
- merupakan
- permintaan
- menghormati
- masing-masing
- Pengembalian
- ulasan
- kuat
- Aturan
- s
- Ilmu
- scikit-belajar
- skor
- melihat
- rasa
- set
- set
- berbagi
- dia
- ditunjukkan
- Sederhana
- menyederhanakan
- So
- beberapa
- membagi
- mulai
- statistika
- Langkah
- lurus
- struktur
- Kemudian
- seperti itu
- cocok
- jumlah
- Mengambil
- Dibutuhkan
- target
- tugas
- Teknis
- uji
- pengujian
- dari
- bahwa
- Grafik
- Mereka
- teori
- Sana.
- karena itu
- mereka
- ini
- Melalui
- untuk
- Toolbox
- Pelatihan VE
- terlatih
- Pelatihan
- Mengubah
- transformasi
- mencoba
- tutorial
- tutorial
- dua
- jenis
- bawah
- memahami
- satuan
- Memperbarui
- Pembaruan
- URL
- us
- akun AS
- menggunakan
- bekas
- menggunakan
- nilai
- Nilai - Nilai
- membayangkan
- we
- ketika
- yang
- mengapa
- Wikipedia
- akan
- Sayap
- dengan
- Kerja
- kerja
- bekerja
- akan
- penulis
- penulisan
- X
- iya nih
- kamu
- Anda
- zephyrnet.dll
- nol