Pergeseran Merah Amazon adalah gudang data cloud berskala petabyte yang cepat dan terkelola sepenuhnya yang mempermudah dan menghemat biaya untuk menganalisis semua data Anda menggunakan SQL standar dan alat intelijen bisnis (BI) yang ada. Puluhan ribu pelanggan saat ini menggunakan Amazon Redshift untuk menganalisis data berukuran exabyte dan menjalankan kueri analitis, menjadikannya gudang data cloud yang paling banyak digunakan. Amazon Redshift tersedia dalam konfigurasi tanpa server dan tersedia.
Amazon Redshift memungkinkan Anda mengakses data yang disimpan secara langsung Layanan Penyimpanan Sederhana Amazon (Amazon S3) menggunakan kueri SQL dan menggabungkan data di seluruh gudang data dan data lake Anda. Dengan Amazon Redshift, Anda dapat menanyakan data di data lake S3 Anda menggunakan pusat Lem AWS metastore dari gudang data Redshift Anda.
Amazon Redshift mendukung kueri berbagai format data, seperti CSV, JSON, Parket, dan ORC, serta format tabel seperti Apache Hudi dan Delta. Amazon Redshift juga mendukung kueri data bersarang dengan tipe data kompleks seperti struct, array, dan map.
Dengan kemampuan ini, Amazon Redshift memperluas gudang data berskala petabyte Anda ke data lake berskala exabyte di Amazon S3 dengan cara yang hemat biaya.
Apache Iceberg adalah format tabel terbaru yang saat ini didukung dalam pratinjau oleh Amazon Redshift. Dalam postingan ini, kami menunjukkan kepada Anda cara menanyakan tabel Iceberg menggunakan Amazon Redshift, dan menjelajahi dukungan dan opsi Iceberg.
Ikhtisar solusi
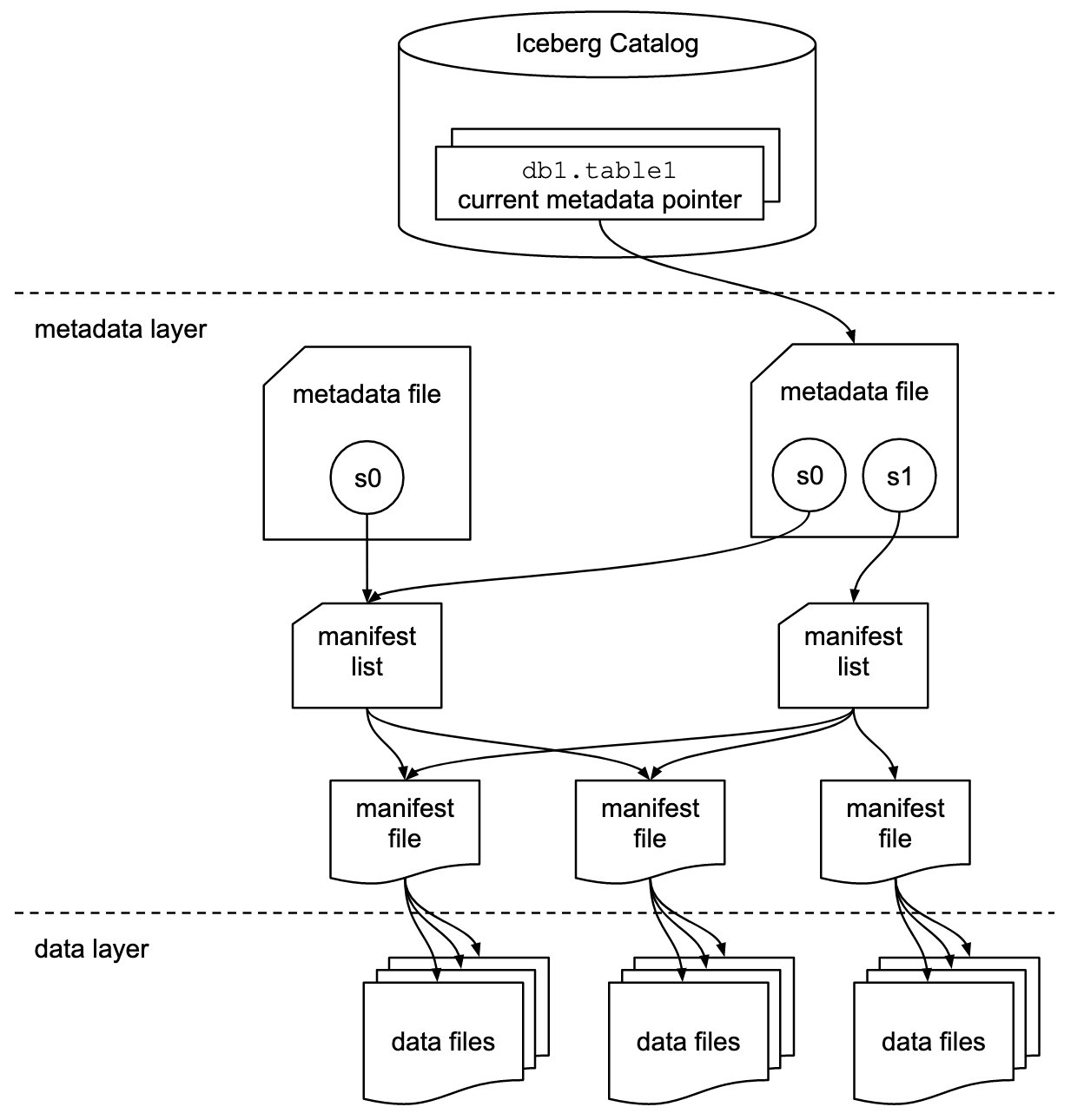
Gunung Es Apache adalah format tabel terbuka untuk kumpulan data analitik berskala petabyte yang sangat besar. Iceberg mengelola kumpulan besar file sebagai tabel, dan mendukung operasi data lake analitis modern seperti penyisipan tingkat rekaman, pembaruan, penghapusan, dan kueri perjalanan waktu. Spesifikasi Iceberg memungkinkan evolusi tabel yang mulus seperti evolusi skema dan partisi, dan desainnya dioptimalkan untuk penggunaan di Amazon S3.
Iceberg menyimpan penunjuk metadata untuk semua file metadata. Saat kueri SELECT membaca tabel Iceberg, mesin kueri pertama-tama masuk ke katalog Iceberg, lalu mengambil entri lokasi file metadata terbaru, seperti yang ditunjukkan dalam diagram berikut.
Amazon Redshift kini menyediakan dukungan untuk tabel Apache Iceberg, yang memungkinkan pelanggan data lake menjalankan kueri analitik hanya-baca dengan cara yang konsisten secara transaksional. Hal ini memungkinkan Anda mengelola dan memelihara tabel Anda dengan mudah di data lake transaksional.
Amazon Redshift mendukung skema asli dan kemampuan evolusi partisi Apache Iceberg menggunakan Katalog Data AWS Glue, menghilangkan kebutuhan untuk mengubah definisi tabel untuk menambahkan partisi baru atau untuk memindahkan dan memproses data dalam jumlah besar untuk mengubah skema tabel data lake yang ada. Amazon Redshift menggunakan statistik kolom yang disimpan dalam metadata tabel Apache Iceberg untuk mengoptimalkan rencana kuerinya dan mengurangi pemindaian file yang diperlukan untuk menjalankan kueri.
Dalam posting ini, kami menggunakan Kumpulan data publik taksi kuning dari NYC Taxi & Limousine Commission sebagai sumber data kami. Dataset berisi file data di Parket Apache format di Amazon S3. Kita gunakan Amazon Athena untuk mengonversi kumpulan data Parket ini dan kemudian menggunakannya Spektrum Pergeseran Merah Amazon untuk melakukan kueri dan bergabung dengan tabel lokal Redshift, melakukan penghapusan dan pembaruan tingkat baris serta evolusi partisi, semuanya dikoordinasikan melalui Katalog Data AWS Glue di data lake S3.
Prasyarat
Anda harus memiliki prasyarat berikut:
Ubah data Parket menjadi tabel Iceberg
Untuk posting ini, Anda memerlukan Kumpulan data publik taksi kuning dari NYC Taxi & Limousine Commission tersedia dalam format Gunung Es. Anda dapat mengunduh file dan kemudian menggunakan Athena untuk mengonversi kumpulan data Parket menjadi tabel Iceberg, atau lihat Bangun data lake Apache Iceberg menggunakan Amazon Athena, Amazon EMR, dan AWS Glue posting blog untuk membuat tabel Iceberg.
Dalam postingan ini, kami menggunakan Athena untuk mengonversi data. Selesaikan langkah-langkah berikut:
- Unduh file menggunakan tautan sebelumnya atau gunakan Antarmuka Baris Perintah AWS (AWS CLI) untuk menyalin file dari bucket S3 publik untuk tahun 2020 dan 2021 ke bucket S3 Anda menggunakan perintah berikut:
Untuk informasi lebih lanjut, lihat Menyiapkan CLI Amazon Redshift.
- Buat database
Icebergdbdan buat tabel menggunakan Athena yang menunjuk ke file berformat Parket menggunakan pernyataan berikut: - Validasi data di tabel Parket menggunakan SQL berikut:

- Buat tabel Iceberg di Athena dengan kode berikut. Anda dapat melihat properti tipe tabel sebagai tabel Iceberg dengan format Parket dan kompresi tajam berikut ini
create tablepenyataan. Anda perlu memperbarui lokasi S3 sebelum menjalankan SQL. Perhatikan juga bahwa tabel Iceberg dipartisi denganYearkunci. - Setelah Anda membuat tabel, muat data ke dalam tabel Iceberg menggunakan tabel Parket yang dimuat sebelumnya
nyc_taxi_yellow_parquetdengan SQL berikut: - Ketika pernyataan SQL selesai, validasi data di tabel Iceberg
nyc_taxi_yellow_iceberg. Langkah ini diperlukan sebelum melanjutkan ke langkah berikutnya. - Anda dapat memvalidasi bahwa tabel nyc_taxi_ yellow_iceberg berada dalam tabel format Iceberg dan dipartisi pada kolom Tahun menggunakan perintah berikut:



Buat skema eksternal di Amazon Redshift
Di bagian ini, kami mendemonstrasikan cara membuat skema eksternal di Amazon Redshift yang menunjuk ke database AWS Glue icebergdb untuk menanyakan tabel Iceberg nyc_taxi_yellow_iceberg yang kita lihat di bagian sebelumnya menggunakan Athena.
Masuk ke Redshift melalui Editor Kueri v2 atau klien SQL dan jalankan perintah berikut (perhatikan bahwa database AWS Glue icebergdb dan informasi Wilayah sedang digunakan):

Untuk mempelajari tentang membuat skema eksternal di Amazon Redshift, lihat membuat skema eksternal
Setelah Anda membuat skema eksternal spectrum_iceberg_schema, Anda dapat menanyakan tabel Iceberg di Amazon Redshift.
Kueri tabel Iceberg di Amazon Redshift
Jalankan kueri berikut di Editor Kueri v2. Perhatikan itu spectrum_iceberg_schema adalah nama skema eksternal yang dibuat di Amazon Redshift dan nyc_taxi_yellow_iceberg adalah tabel di database AWS Glue yang digunakan dalam kueri:
Output data kueri pada tangkapan layar berikut menunjukkan bahwa tabel AWS Glue dengan format Iceberg dapat dikueri menggunakan Redshift Spectrum.

Periksa rencana penjelasan untuk menanyakan tabel Iceberg
Anda dapat menggunakan kueri berikut untuk mendapatkan output penjelasan rencana, yang menunjukkan formatnya ICEBERG:

Validasi pembaruan untuk konsistensi data
Setelah pembaruan selesai pada tabel Iceberg, Anda dapat menanyakan Amazon Redshift untuk melihat tampilan data yang konsisten secara transaksional. Mari jalankan kueri dengan memilih a vendorid dan untuk penjemputan dan pengantaran tertentu:

Selanjutnya, perbarui nilai passenger_count ke 4 dan trip_distance hingga 9.4 untuk a vendorid dan tanggal penjemputan dan pengantaran tertentu di Athena:

Terakhir, jalankan kueri berikut di Editor Kueri v2 untuk melihat nilai yang diperbarui passenger_count dan trip_distance:
Seperti yang ditunjukkan pada tangkapan layar berikut, operasi pembaruan pada tabel Iceberg tersedia di Amazon Redshift.

Buat tampilan terpadu dari tabel lokal dan data historis di Amazon Redshift
Sebagai strategi arsitektur data modern, Anda dapat mengatur data historis atau data yang jarang diakses di data lake dan menyimpan data yang sering diakses di gudang data Redshift. Hal ini memberikan fleksibilitas untuk mengelola analitik dalam skala besar dan menemukan solusi arsitektur yang paling hemat biaya.
Dalam contoh ini, kami memuat data 2 tahun dalam tabel Redshift; sisa datanya tetap berada di data lake S3 karena kumpulan data tersebut lebih jarang ditanyakan.
- Gunakan kode berikut untuk memuat data 2 tahun di
nyc_taxi_yellow_recenttabel di Amazon Redshift, bersumber dari tabel Iceberg:
- Selanjutnya, Anda bisa menghapus data 2 tahun terakhir dari tabel Iceberg menggunakan perintah berikut di Athena karena Anda memuat data ke tabel Redshift pada langkah sebelumnya:

Setelah Anda menyelesaikan langkah-langkah ini, tabel Redshift memiliki data selama 2 tahun dan data lainnya ada di tabel Iceberg di Amazon S3.
- Buat tampilan menggunakan
nyc_taxi_yellow_icebergTabel gunung es dannyc_taxi_yellow_recenttabel di Amazon Redshift: - Sekarang kueri tampilannya, bergantung pada kondisi filter, Redshift Spectrum akan memindai data Iceberg, tabel Redshift, atau keduanya. Contoh kueri berikut mengembalikan sejumlah rekaman dari masing-masing tabel sumber dengan memindai kedua tabel:

Evolusi partisi
Penggunaan gunung es partisi tersembunyi, yang berarti Anda tidak perlu menambahkan partisi secara manual untuk tabel Apache Iceberg Anda. Nilai partisi baru atau spesifikasi partisi baru (menambah atau menghapus kolom partisi) di tabel Apache Iceberg secara otomatis terdeteksi oleh Amazon Redshift dan tidak diperlukan operasi manual untuk memperbarui partisi dalam definisi tabel. Contoh berikut menunjukkan hal ini.
Dalam contoh kita, jika tabel Iceberg nyc_taxi_yellow_iceberg awalnya dipartisi berdasarkan tahun dan kemudian kolom vendorid ditambahkan sebagai kolom partisi tambahan, maka Amazon Redshift dapat menanyakan tabel Iceberg dengan lancar nyc_taxi_yellow_iceberg dengan dua skema partisi yang berbeda selama periode waktu tertentu.

Pertimbangan saat menanyakan tabel Iceberg menggunakan Amazon Redshift
Selama periode pratinjau, pertimbangkan hal berikut saat menggunakan Amazon Redshift dengan tabel Iceberg:
- Hanya tabel Iceberg yang ditentukan dalam Katalog Data AWS Glue yang didukung.
- Perintah CREATE atau ALTER tabel eksternal tidak didukung, yang berarti tabel Iceberg harus sudah ada di database AWS Glue.
- Kueri perjalanan waktu tidak didukung.
- Iceberg versi 1 dan 2 didukung. Untuk detail lebih lanjut tentang versi format Iceberg, lihat Format Versi.
- Untuk daftar tipe data yang didukung dengan tabel Iceberg, lihat Tipe data yang didukung dengan tabel Apache Iceberg (pratinjau).
- Harga untuk menanyakan tabel Iceberg sama dengan mengakses format data lainnya menggunakan Amazon Redshift.
Untuk detail tambahan mengenai pertimbangan pratinjau tabel format Iceberg, lihat Menggunakan tabel Apache Iceberg dengan Amazon Redshift (pratinjau).
Timbal balik pelanggan
“Tinuiti, firma pemasaran kinerja independen terbesar, menangani data dalam jumlah besar setiap hari dan harus memiliki strategi data lake dan gudang data yang kuat agar tim intelijen pasar kami dapat menyimpan dan menganalisis semua data pelanggan kami dengan cara yang mudah, terjangkau, dan aman. , dan cara yang tangguh,” kata Justin Manus, Chief Technology Officer di Tinuiti. “Dukungan Amazon Redshift untuk tabel Apache Iceberg di data lake kami, yang merupakan satu-satunya sumber kebenaran, mengatasi tantangan penting dalam mengoptimalkan kinerja dan aksesibilitas dan semakin menyederhanakan jalur integrasi data kami untuk mengakses semua data yang diserap dari berbagai sumber dan untuk mendukung kami potensi merek pelanggan.”
Kesimpulan
Dalam postingan ini, kami menunjukkan contoh kueri tabel Iceberg di Redshift menggunakan file yang disimpan di Amazon S3, dikatalogkan sebagai tabel di Katalog Data AWS Glue, dan mendemonstrasikan beberapa fitur utama seperti pembaruan dan penghapusan tingkat baris yang efisien, dan pengalaman evolusi skema bagi pengguna untuk membuka kekuatan data besar menggunakan Athena.
Anda dapat menggunakan Amazon Redshift untuk menjalankan kueri pada tabel data lake dalam berbagai format file dan tabel, seperti Apache Hudi dan Danau Delta, dan sekarang dengan Gunung Es Apache (pratinjau), yang memberikan opsi tambahan untuk kebutuhan arsitektur data modern Anda.
Kami harap ini memberi Anda titik awal yang bagus untuk menanyakan tabel Iceberg di Amazon Redshift.
Tentang Penulis
 Rohit Bansal adalah Arsitek Solusi Spesialis Analytics di AWS. Dia berspesialisasi dalam Amazon Redshift dan bekerja dengan pelanggan untuk membangun solusi analitik generasi berikutnya menggunakan layanan AWS Analytics lainnya.
Rohit Bansal adalah Arsitek Solusi Spesialis Analytics di AWS. Dia berspesialisasi dalam Amazon Redshift dan bekerja dengan pelanggan untuk membangun solusi analitik generasi berikutnya menggunakan layanan AWS Analytics lainnya.
 Satish Sathiya adalah Insinyur Produk Senior di Amazon Redshift. Dia adalah penggemar big data yang bekerja sama dengan pelanggan di seluruh dunia untuk mencapai kesuksesan dan memenuhi kebutuhan arsitektur data warehousing dan data lake mereka.
Satish Sathiya adalah Insinyur Produk Senior di Amazon Redshift. Dia adalah penggemar big data yang bekerja sama dengan pelanggan di seluruh dunia untuk mencapai kesuksesan dan memenuhi kebutuhan arsitektur data warehousing dan data lake mereka.
 Ranjan Burman adalah Arsitek Solusi Spesialis Analytics di AWS. Dia berspesialisasi dalam Amazon Redshift dan membantu pelanggan membangun solusi analitis yang dapat diskalakan. Dia memiliki lebih dari 16 tahun pengalaman dalam berbagai teknologi database dan pergudangan data. Dia bersemangat mengotomatiskan dan memecahkan masalah pelanggan dengan solusi cloud.
Ranjan Burman adalah Arsitek Solusi Spesialis Analytics di AWS. Dia berspesialisasi dalam Amazon Redshift dan membantu pelanggan membangun solusi analitis yang dapat diskalakan. Dia memiliki lebih dari 16 tahun pengalaman dalam berbagai teknologi database dan pergudangan data. Dia bersemangat mengotomatiskan dan memecahkan masalah pelanggan dengan solusi cloud.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Otomotif / EV, Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- ChartPrime. Tingkatkan Game Trading Anda dengan ChartPrime. Akses Di Sini.
- BlockOffset. Modernisasi Kepemilikan Offset Lingkungan. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- Tentang Kami
- mengakses
- diakses
- aksesibilitas
- mengakses
- Mencapai
- di seluruh
- menambahkan
- menambahkan
- Tambahan
- alamat
- terjangkau
- Semua
- memungkinkan
- sudah
- juga
- Amazon
- Amazon Athena
- Amazon ESDM
- Amazon Web Services
- jumlah
- an
- Analitik
- Analytical
- analisis
- menganalisa
- dan
- Apa pun
- Apache
- arsitektur
- ADALAH
- sekitar
- susunan
- AS
- At
- secara otomatis
- mengotomatisasi
- tersedia
- AWS
- Lem AWS
- dasar
- karena
- sebelum
- makhluk
- Besar
- Big data
- mengikat
- Blog
- kedua
- merek
- membangun
- bisnis
- intelijen bisnis
- by
- CAN
- kemampuan
- kemampuan
- katalog
- pusat
- tertentu
- menantang
- perubahan
- kepala
- Chief Technology Officer
- klien
- awan
- kode
- koleksi
- Kolom
- Kolom
- lengkap
- kompleks
- Kondisi
- Mempertimbangkan
- pertimbangan
- konsisten
- mengandung
- mengubah
- dikoordinasikan
- hemat biaya
- membuat
- dibuat
- membuat
- kritis
- pelanggan
- data pelanggan
- pelanggan
- harian
- data
- integrasi data
- Danau Data
- data warehouse
- Basis Data
- kumpulan data
- Tanggal
- Default
- didefinisikan
- definisi
- definisi
- Delta
- mendemonstrasikan
- menunjukkan
- menunjukkan
- Tergantung
- Mendesain
- rincian
- terdeteksi
- dev
- berbeda
- langsung
- Dont
- dua kali lipat
- Download
- setiap
- mudah
- Mudah
- editor
- efisien
- antara
- menghilangkan
- memungkinkan
- Mesin
- insinyur
- penggemar
- masuk
- Eter (ETH)
- evolusi
- contoh
- ada
- ada
- pengalaman
- Menjelaskan
- menyelidiki
- Meluas
- luar
- tambahan
- FAST
- Fitur
- File
- File
- menyaring
- Menemukan
- Perusahaan
- Pertama
- keluwesan
- berikut
- Untuk
- format
- sering
- dari
- sepenuhnya
- lebih lanjut
- mendapatkan
- memberikan
- bumi
- Pergi
- besar
- Kelompok
- Menangani
- Memiliki
- he
- membantu
- historis
- berharap
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- if
- in
- independen
- informasi
- integrasi
- Intelijen
- ke
- IT
- NYA
- ikut
- jpg
- json
- Justin
- Menjaga
- kunci
- danau
- besar
- terbesar
- Terakhir
- kemudian
- Terbaru
- BELAJAR
- kurang
- 'like'
- MEMBATASI
- baris
- LINK
- Daftar
- memuat
- lokal
- tempat
- memelihara
- MEMBUAT
- Membuat
- mengelola
- berhasil
- mengelola
- cara
- panduan
- manual
- peta
- Pasar
- Marketing
- cara
- Pelajari
- Metadata
- modern
- lebih
- paling
- pindah
- bergerak
- harus
- nama
- asli
- Perlu
- dibutuhkan
- kebutuhan
- New
- berikutnya
- generasi selanjutnya
- tidak
- mencatat
- sekarang
- jumlah
- NYC
- of
- Petugas
- on
- Buka
- operasi
- Operasi
- Optimize
- dioptimalkan
- mengoptimalkan
- Opsi
- or
- semula
- Lainnya
- kami
- keluaran
- lebih
- halaman
- bergairah
- melakukan
- prestasi
- periode
- rencana
- rencana
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- Pos
- potensi
- kekuasaan
- prasyarat
- Preview
- sebelumnya
- sebelumnya
- masalah
- proses
- Produk
- properties
- menyediakan
- publik
- query
- Bacaan
- arsip
- menurunkan
- wilayah
- menghapus
- menggantikan
- wajib
- ISTIRAHAT
- Pengembalian
- kuat
- Run
- berjalan
- sama
- melihat
- mengatakan
- terukur
- Skala
- pemindaian
- pemindaian
- scan
- skema
- mulus
- mulus
- Bagian
- aman
- melihat
- senior
- Tanpa Server
- Layanan
- set
- harus
- Menunjukkan
- menunjukkan
- ditunjukkan
- Pertunjukkan
- Sederhana
- tunggal
- larutan
- Solusi
- Memecahkan
- beberapa
- sumber
- sumber
- Sourcing
- spesialis
- spesialisasi
- spesifikasi
- spesifikasi
- Spektrum
- SQL
- standar
- Mulai
- Pernyataan
- statistika
- Langkah
- Tangga
- penyimpanan
- menyimpan
- tersimpan
- toko
- Penyelarasan
- Tali
- sukses
- seperti itu
- mendukung
- Didukung
- Mendukung
- tabel
- tim
- Teknologi
- Teknologi
- memiliki
- dari
- bahwa
- Grafik
- Sumber
- mereka
- kemudian
- Ini
- ini
- ribuan
- Melalui
- waktu
- perjalanan waktu
- timestamp
- untuk
- hari ini
- alat
- transaksional
- perjalanan
- kebenaran
- dua
- mengetik
- jenis
- terpadu
- serikat
- membuka kunci
- Memperbarui
- diperbarui
- Pembaruan
- penggunaan
- menggunakan
- bekas
- Pengguna
- kegunaan
- menggunakan
- MENGESAHKAN
- nilai
- Nilai - Nilai
- variasi
- berbagai
- sangat
- melalui
- View
- volume
- Gudang
- Pergudangan
- adalah
- Cara..
- we
- jaringan
- layanan web
- ketika
- yang
- SIAPA
- lebar
- sangat
- akan
- dengan
- bekerja
- tahun
- tahun
- kamu
- Anda
- zephyrnet.dll