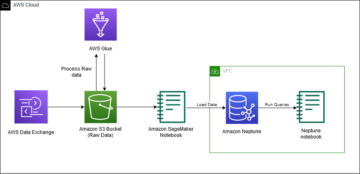
Pelanggan AWS di bidang layanan kesehatan, layanan keuangan, sektor publik, dan industri lainnya menyimpan miliaran dokumen dalam bentuk gambar atau PDF Layanan Penyimpanan Sederhana Amazon (Amazon S3). Namun, mereka tidak dapat memperoleh wawasan seperti menggunakan informasi yang terkunci dalam dokumen untuk model bahasa besar (LLM) atau menelusuri hingga mereka mengekstrak teks, formulir, tabel, dan data terstruktur lainnya. Dengan pemrosesan dokumen cerdas (IDP) AWS menggunakan layanan AI seperti Teks Amazon, Anda dapat memanfaatkan teknologi pembelajaran mesin (ML) terdepan di industri untuk memproses data dari PDF atau gambar dokumen (TIFF, JPEG, PNG) dengan cepat dan akurat. Setelah teks diekstraksi dari dokumen, Anda dapat menggunakannya untuk menyempurnakan model fondasi, merangkum data menggunakan model dasar, atau kirimkan ke database.
Dalam postingan ini, kami fokus pada pemrosesan sejumlah besar dokumen menjadi file teks mentah dan menyimpannya di Amazon S3. Kami memberi Anda dua solusi berbeda untuk kasus penggunaan ini. Yang pertama memungkinkan Anda menjalankan skrip Python dari server atau instance mana pun termasuk notebook Jupyter; ini adalah cara tercepat untuk memulai. Pendekatan kedua adalah penerapan turnkey berbagai komponen infrastruktur menggunakan Kit Pengembangan AWS Cloud (AWSCDK) konstruksi. Konstruksi AWS CDK menyediakan kerangka kerja yang tangguh dan fleksibel untuk memproses dokumen Anda dan membangun pipeline IDP end-to-end. Melalui penggunaan AWS CDK, Anda dapat memperluas fungsinya untuk menyertakan redaksi, simpan hasilnya di Amazon OpenSearch, atau tambahkan kustom AWS Lambda berfungsi dengan logika bisnis Anda sendiri.
Kedua solusi ini memungkinkan Anda memproses jutaan halaman dengan cepat. Sebelum menjalankan salah satu solusi ini dalam skala besar, sebaiknya lakukan pengujian dengan sebagian dokumen Anda untuk memastikan hasilnya memenuhi harapan Anda. Di bagian berikut, pertama-tama kami menjelaskan solusi skrip, diikuti dengan solusi konstruksi AWS CDK.
Solusi 1: Gunakan skrip Python
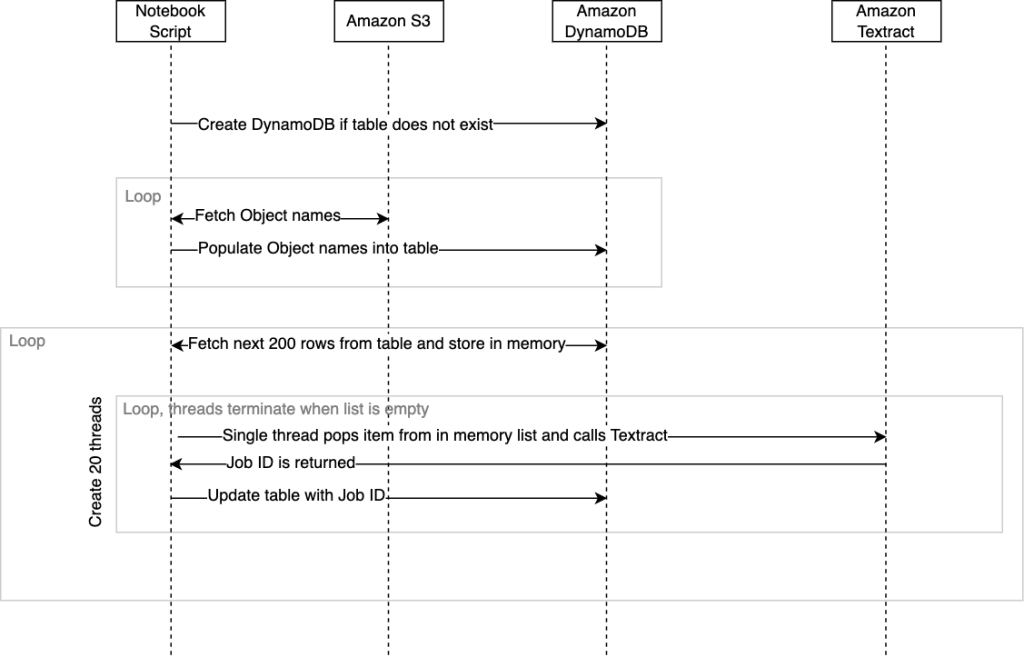
Solusi ini memproses dokumen untuk teks mentah melalui Amazon Textract secepat yang dimungkinkan oleh layanan dengan harapan bahwa jika ada kegagalan dalam skrip, proses akan melanjutkan dari bagian terakhirnya. Solusinya menggunakan tiga layanan berbeda: Amazon S3, Amazon DynamoDB, dan Amazon Textract.
Diagram berikut menggambarkan urutan kejadian dalam naskah. Ketika skrip berakhir, status penyelesaian beserta waktu yang dibutuhkan akan dikembalikan ke konsol studio SageMaker.

Kami telah mengemas solusi ini dalam a skrip .ipynb dan .py skrip. Anda dapat menggunakan solusi apa pun yang dapat diterapkan sesuai kebutuhan Anda.
Prasyarat
Untuk menjalankan skrip ini dari notebook Jupyter, file Identitas AWS dan Manajemen Akses (IAM) peran yang ditetapkan ke notebook harus memiliki izin yang memungkinkannya berinteraksi dengan DynamoDB, Amazon S3, dan Amazon Textract. Panduan umumnya adalah memberikan izin dengan hak istimewa paling rendah untuk setiap layanan ini kepada Anda AmazonSageMaker-ExecutionRole peran. Untuk mempelajari lebih lanjut, lihat Mulailah dengan kebijakan terkelola AWS dan lanjutkan ke izin dengan hak istimewa paling rendah.
Alternatifnya, Anda dapat menjalankan skrip ini dari lingkungan lain seperti Cloud komputasi elastis Amazon (Amazon EC2) instans atau kontainer yang akan Anda kelola, asalkan Python, Pip3, dan AWS SDK untuk Python (Boto3) dipasang. Sekali lagi, kebijakan IAM yang sama perlu diterapkan agar skrip dapat berinteraksi dengan berbagai layanan terkelola.
Walkthrough
Untuk menerapkan solusi ini, Anda harus mengkloning repositori terlebih dahulu GitHub.
Anda perlu mengatur variabel berikut dalam skrip sebelum Anda dapat menjalankannya:
- pelacakan_tabel – Ini adalah nama tabel DynamoDB yang akan dibuat.
- masukan_bucket – Ini adalah lokasi sumber Anda di Amazon S3 yang berisi dokumen yang ingin Anda kirim ke Amazon Textract untuk deteksi teks. Untuk variabel ini, berikan nama bucket, misalnya
mybucket. - output_bucket – Ini untuk menyimpan lokasi di mana Anda ingin Amazon Textract menulis hasilnya. Untuk variabel ini, berikan nama bucket, misalnya
myoutputbucket. - _input_prefix (opsional) – Jika Anda ingin memilih file tertentu dari dalam folder di bucket S3 Anda, Anda dapat menentukan nama folder ini sebagai awalan input. Jika tidak, biarkan defaultnya kosong untuk memilih semua.
Scriptnya adalah sebagai berikut:
Skema tabel DynamoDB berikut dibuat saat skrip dijalankan:
Saat skrip dijalankan untuk pertama kalinya, skrip akan memeriksa apakah tabel DynamoDB ada dan secara otomatis akan membuatnya jika diperlukan. Setelah tabel dibuat, kita perlu mengisinya dengan daftar referensi objek dokumen dari Amazon S3 yang ingin kita proses. Script dengan desain akan menghitung objek yang ditentukan input_bucket dan secara otomatis mengisi tabel kita dengan namanya saat dijalankan. Dibutuhkan sekitar 10 menit untuk menghitung lebih dari 100,000 dokumen dan mengisi nama-nama tersebut ke dalam tabel DynamoDB dari skrip. Jika Anda memiliki jutaan objek dalam satu ember, Anda dapat menggunakan fitur inventaris Amazon S3 yang menghasilkan file CSV berisi nama, lalu mengisi tabel DynamoDB dari daftar ini dengan skrip Anda sendiri terlebih dahulu dan tidak menggunakan fungsi yang disebut fetchAllObjectsInBucketandStoreName dengan mengomentarinya. Untuk mempelajari lebih lanjut, lihat Mengonfigurasi Inventaris Amazon S3.
Seperti disebutkan sebelumnya, ada versi notebook dan versi skrip Python. Buku catatan adalah cara paling mudah untuk memulai; cukup jalankan setiap sel dari awal hingga akhir.
Jika Anda memutuskan untuk menjalankan skrip Python dari CLI, disarankan agar Anda menggunakan terminal multiplexer seperti tmux. Hal ini untuk mencegah skrip berhenti jika sesi SSH Anda selesai. Misalnya: tmux new -d ‘python3 textractFeeder.py’.
Berikut ini adalah titik masuk skrip; dari sini Anda dapat mengomentari metode yang tidak diperlukan:
Bidang berikut disetel saat skrip mengisi tabel DynamoDB:
- nama objek – Nama dokumen yang terletak di Amazon S3 yang akan dikirim ke Amazon Textract
- nama ember – Bucket tempat objek dokumen disimpan
Kedua bidang ini harus diisi jika Anda memutuskan untuk menggunakan file CSV dari laporan inventaris S3 dan melewatkan pengisian otomatis yang terjadi dalam skrip.
Sekarang tabel telah dibuat dan diisi dengan referensi objek dokumen, skrip siap untuk mulai memanggil Amazon Textract StartDocumentTextDetection API. Amazon Textract, mirip dengan layanan terkelola lainnya, memiliki batas bawaan pada API yang disebut transaksi per detik (TPS). Jika diperlukan, Anda dapat meminta penambahan kuota dari konsol Amazon Textract. Kode ini dirancang untuk menggunakan beberapa thread secara bersamaan saat memanggil Amazon Textract untuk memaksimalkan throughput dengan layanan. Anda dapat mengubahnya di dalam kode dengan memodifikasi threadCountforTextractAPICall variabel. Secara default, ini diatur ke 20 thread. Skrip awalnya akan membaca 200 baris dari tabel DynamoDB dan menyimpannya dalam daftar dalam memori yang dibungkus dengan kelas untuk keamanan thread. Setiap thread pemanggil kemudian dimulai dan dijalankan dalam jalur renangnya sendiri. Pada dasarnya, thread pemanggil Amazon Textract akan mengambil item dari daftar dalam memori yang berisi referensi objek kita. Ini kemudian akan memanggil asynchronous start_document_text_detection API dan tunggu pengakuan dengan ID pekerjaan. ID pekerjaan kemudian diperbarui kembali ke baris DynamoDB untuk objek tersebut, dan rangkaian pesan akan diulangi dengan mengambil item berikutnya dari daftar.
Berikut ini adalah kode orkestrasi utama naskah:
Thread pemanggil akan terus berulang hingga tidak ada lagi item apa pun dalam daftar, dan pada saat itulah thread akan berhenti. Ketika semua thread yang beroperasi dalam jalur renangnya telah berhenti, 200 baris berikutnya dari DynamoDB diambil dan rangkaian 20 thread baru dimulai, dan seluruh proses berulang hingga setiap baris yang tidak berisi ID pekerjaan diambil dari DynamoDB dan diperbarui. Jika skrip mogok karena masalah yang tidak terduga, maka skrip dapat dijalankan kembali dari orchestrate() metode. Hal ini memastikan bahwa thread akan terus memproses baris yang berisi ID pekerjaan kosong. Perhatikan bahwa ketika menjalankan kembali orchestrate() metode setelah skrip dihentikan, ada potensi beberapa dokumen akan dikirim lagi ke Amazon Textract. Jumlah ini akan sama dengan atau kurang dari jumlah thread yang berjalan pada saat crash.
Ketika tidak ada lagi baris yang berisi ID pekerjaan kosong di tabel DynamoDB, skrip akan berhenti. Semua output JSON dari Amazon Textract untuk semua objek akan ditemukan di output_bucket secara default di bawah textract_output map. Setiap subfolder di dalamnya textract_output akan diberi nama dengan ID pekerjaan yang sesuai dengan ID pekerjaan yang disimpan dalam tabel DynamoDB untuk objek tersebut. Di dalam folder ID pekerjaan, Anda akan menemukan JSON, yang akan diberi nama numerik mulai dari 1 dan berpotensi menjangkau file JSON tambahan yang akan diberi label 2, 3, dan seterusnya. Rentang file JSON adalah hasil dari dokumen yang padat atau multi-halaman, di mana jumlah konten yang diekstraksi melebihi ukuran JSON default Amazon Textract yaitu 1,000 blok. Mengacu pada Memblokir untuk informasi lebih lanjut tentang blok. File JSON ini akan berisi semua metadata Amazon Textract, termasuk teks yang diekstrak dari dalam dokumen.
Anda dapat menemukan versi dan skrip buku catatan kode Python untuk solusi ini di GitHub.
Membersihkan
Ketika skrip Python selesai, Anda dapat menghemat biaya dengan mematikan atau menghentikan Studio Amazon SageMaker buku catatan atau wadah yang Anda putar.
Sekarang ke solusi kedua kami untuk dokumen dalam skala besar.
Solusi 2: Gunakan konstruksi AWS CDK tanpa server
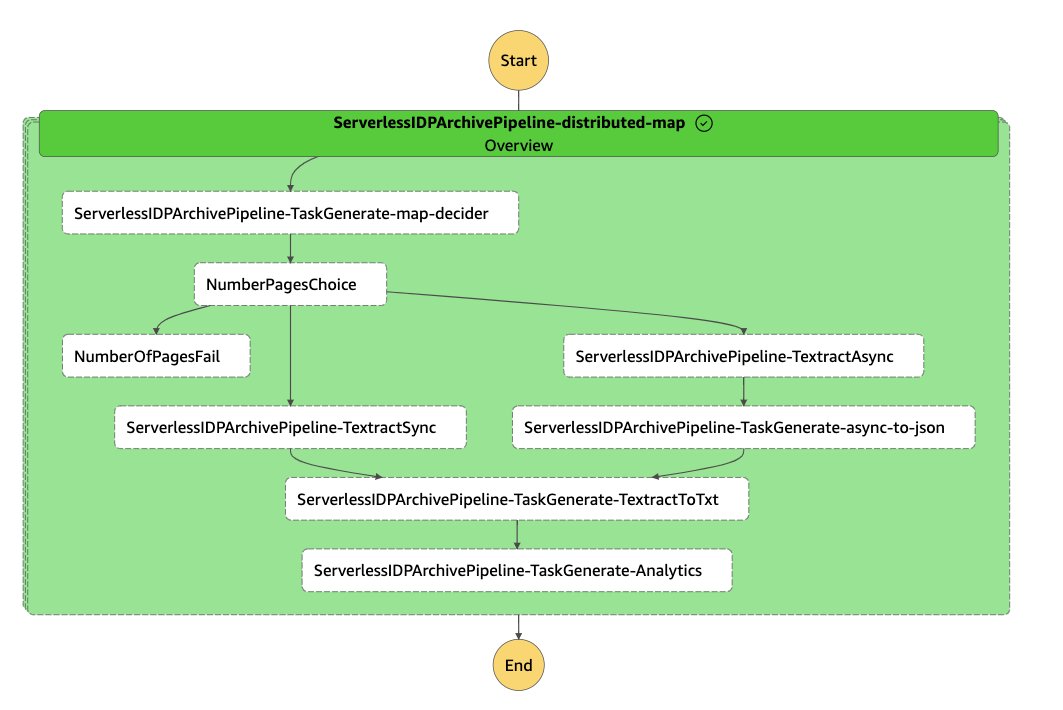
Solusi ini menggunakan Fungsi Langkah AWS dan Lambda berfungsi untuk mengatur jalur pipa IDP. Kami menggunakan Konstruksi IDP AWS CDK, yang memudahkan kerja dengan Amazon Textract dalam skala besar. Selain itu, kami menggunakan a Peta terdistribusi Step Functions untuk mengulangi semua file di bucket S3 dan memulai pemrosesan. Fungsi Lambda pertama menentukan berapa banyak halaman yang dimiliki dokumen Anda. Hal ini memungkinkan alur untuk secara otomatis menggunakan API sinkron (untuk dokumen satu halaman) atau asinkron (untuk dokumen multi-halaman). Saat menggunakan API asinkron, fungsi Lambda tambahan dipanggil ke semua file JSON yang akan dihasilkan Amazon Textract untuk semua halaman Anda ke dalam satu file JSON untuk memudahkan aplikasi hilir Anda bekerja dengan informasi tersebut.
Solusi ini juga berisi dua fungsi Lambda tambahan. Fungsi pertama mem-parsing teks dari JSON dan menyimpannya sebagai file teks di Amazon S3. Fungsi kedua menganalisis JSON dan menyimpannya untuk metrik pada beban kerja.
Diagram berikut mengilustrasikan alur kerja Step Functions.
Prasyarat
Basis kode ini menggunakan AWS CDK dan memerlukan Docker. Anda dapat menerapkan ini dari AWS Cloud9 misalnya, yang sudah menyiapkan AWS CDK dan Docker.
Walkthrough
Untuk menerapkan solusi ini, Anda perlu mengkloning file terlebih dahulu gudang.
Setelah Anda mengkloning repositori, instal dependensinya:
Kemudian gunakan kode berikut untuk men-deploy tumpukan AWS CDK:
Anda harus menyediakan bucket sumber dan awalan sumber (lokasi file yang ingin Anda proses) untuk solusi ini.
Saat penerapan selesai, navigasikan ke konsol Step Functions, tempat Anda akan melihat mesin status ServerlessIDPArchivePipeline.
Buka halaman detail mesin negara dan di Eksekusi tab, pilih Mulai eksekusi.

Pilih Mulai eksekusi lagi untuk menjalankan mesin negara.

Setelah Anda memulai mesin status, Anda dapat memantau alur dengan melihat eksekusi peta. Anda akan melihat sebuah Status pemrosesan barang bagian seperti tangkapan layar berikut. Seperti yang Anda lihat, ini dibuat untuk menjalankan dan melacak apa yang berhasil dan apa yang gagal. Proses ini akan terus berjalan hingga seluruh dokumen telah dibaca.

Dengan solusi ini, Anda seharusnya dapat memproses jutaan file di akun AWS Anda tanpa khawatir tentang cara menentukan dengan benar file mana yang akan dikirim ke API mana atau file rusak yang gagal dalam pipeline Anda. Melalui konsol Step Functions, Anda akan dapat melihat dan memantau file Anda secara real time.
Membersihkan
Setelah alur Anda selesai berjalan, untuk membersihkannya, Anda dapat kembali ke proyek Anda dan memasukkan perintah berikut:
Tindakan ini akan menghapus layanan apa pun yang diterapkan untuk proyek ini.
Kesimpulan
Dalam postingan ini, kami menyajikan solusi yang memudahkan konversi gambar dokumen dan PDF Anda menjadi file teks. Ini adalah prasyarat utama dalam menggunakan dokumen Anda untuk AI generatif dan penelusuran. Untuk mempelajari lebih lanjut tentang menggunakan teks untuk melatih atau menyempurnakan model dasar Anda, lihat Sempurnakan Llama 2 untuk pembuatan teks di Amazon SageMaker JumpStart. Untuk digunakan dengan pencarian, lihat Terapkan indeks pencarian dokumen cerdas dengan Amazon Textract dan Amazon OpenSearch. Untuk mempelajari selengkapnya tentang kemampuan pemrosesan dokumen tingkat lanjut yang ditawarkan oleh layanan AWS AI, lihat Panduan untuk Pemrosesan Dokumen Cerdas di AWS.
Tentang Penulis
 Tim Condello adalah arsitek solusi spesialis kecerdasan buatan (AI) dan pembelajaran mesin (ML) senior di Amazon Web Services (AWS). Fokusnya adalah pemrosesan bahasa alami dan visi komputer. Tim senang mengambil ide pelanggan dan mengubahnya menjadi solusi terukur.
Tim Condello adalah arsitek solusi spesialis kecerdasan buatan (AI) dan pembelajaran mesin (ML) senior di Amazon Web Services (AWS). Fokusnya adalah pemrosesan bahasa alami dan visi komputer. Tim senang mengambil ide pelanggan dan mengubahnya menjadi solusi terukur.
 David Girling adalah arsitek solusi AI/ML senior dengan pengalaman lebih dari dua puluh tahun dalam merancang, memimpin, dan mengembangkan sistem perusahaan. David adalah bagian dari tim spesialis yang berfokus membantu pelanggan belajar, berinovasi, dan memanfaatkan layanan berkemampuan tinggi ini dengan data mereka untuk kasus penggunaan mereka.
David Girling adalah arsitek solusi AI/ML senior dengan pengalaman lebih dari dua puluh tahun dalam merancang, memimpin, dan mengembangkan sistem perusahaan. David adalah bagian dari tim spesialis yang berfokus membantu pelanggan belajar, berinovasi, dan memanfaatkan layanan berkemampuan tinggi ini dengan data mereka untuk kasus penggunaan mereka.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/create-a-document-lake-using-large-scale-text-extraction-from-documents-with-amazon-textract/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 1
- 10
- 100
- 12
- 20
- 200
- 7
- 710
- 8
- a
- Sanggup
- Tentang Kami
- mengakses
- Akun
- akurat
- menambahkan
- Tambahan
- Selain itu
- memajukan
- maju
- Keuntungan
- Setelah
- lagi
- AI
- Layanan AI
- AI / ML
- Semua
- mengizinkan
- memungkinkan
- sepanjang
- sudah
- juga
- Amazon
- Amazon EC2
- Amazon SageMaker
- Teks Amazon
- Amazon Web Services
- Layanan Web Amazon (AWS)
- jumlah
- an
- analisis
- dan
- Apa pun
- api
- Lebah
- aplikasi
- terapan
- pendekatan
- sekitar
- ADALAH
- buatan
- kecerdasan buatan
- Kecerdasan buatan (AI)
- AS
- ditugaskan
- At
- mobil
- secara otomatis
- AWS
- kembali
- mendasarkan
- Pada dasarnya
- BE
- menjadi
- sebelum
- miliaran
- kosong
- Blok
- Bootstrap
- kedua
- membangun
- dibangun di
- bisnis
- by
- panggilan
- bernama
- pemanggil
- panggilan
- CAN
- kemampuan
- mampu
- kasus
- kasus
- sel
- tertentu
- perubahan
- memeriksa
- Pilih
- kelas
- membersihkan
- awan
- kode
- basis kode
- koleksi
- komentar
- Mengomentari
- lengkap
- penyelesaian
- komponen
- menghitung
- komputer
- Visi Komputer
- konsul
- membangun
- mengandung
- Wadah
- mengandung
- Konten
- terus
- mengubah
- berkorespondensi
- korup
- Biaya
- bisa
- Crash
- membuat
- dibuat
- adat
- pelanggan
- pelanggan
- data
- Basis Data
- David
- memutuskan
- Default
- padat
- ketergantungan
- menyebarkan
- dikerahkan
- penyebaran
- menggambarkan
- Mendesain
- dirancang
- merancang
- rincian
- Deteksi
- Menentukan
- ditentukan
- berkembang
- Pengembangan
- berbeda
- didistribusikan
- Buruh pelabuhan
- dokumen
- dokumen
- Tidak
- turun
- dua
- setiap
- Terdahulu
- antara
- kosong
- memungkinkan
- ujung ke ujung
- berakhir
- Enter
- Enterprise
- masuk
- lingkungan
- sama
- Eter (ETH)
- peristiwa
- Setiap
- contoh
- melebihi
- eksekusi
- ada
- harapan
- harapan
- pengalaman
- memperpanjang
- ekstrak
- ekstraksi
- Gagal
- kegagalan
- Kegagalan
- Fitur
- beberapa
- Fields
- File
- File
- keuangan
- jasa keuangan
- Menemukan
- menyelesaikan
- Pertama
- pertama kali
- fleksibel
- Fokus
- berfokus
- diikuti
- berikut
- berikut
- Untuk
- bentuk
- ditemukan
- Prinsip Dasar
- Kerangka
- dari
- fungsi
- fungsi
- fungsi
- Mendapatkan
- Umum
- menghasilkan
- generasi
- generatif
- AI generatif
- mendapatkan
- Go
- bimbingan
- Terjadi
- Memiliki
- kesehatan
- membantu
- di sini
- sangat
- -nya
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- i
- IAM
- ID
- ide-ide
- identitas
- id
- if
- menggambarkan
- gambar
- melaksanakan
- in
- memasukkan
- Termasuk
- Meningkatkan
- indeks
- industri
- industri terkemuka
- informasi
- Infrastruktur
- mulanya
- memulai
- berinovasi
- memasukkan
- wawasan
- install
- contoh
- Intelijen
- Cerdas
- Pemrosesan dokumen cerdas
- berinteraksi
- ke
- inventaris
- IT
- item
- NYA
- Pekerjaan
- jpg
- json
- Notebook Jupyter
- kunci
- danau
- Jalur
- bahasa
- besar
- besar-besaran
- terkemuka
- BELAJAR
- pengetahuan
- Meninggalkan
- meninggalkan
- kurang
- 'like'
- Daftar
- Llama
- terletak
- tempat
- terkunci
- logika
- lagi
- mencari
- mesin
- Mesin belajar
- Utama
- membuat
- MEMBUAT
- mengelola
- berhasil
- banyak
- peta
- Maksimalkan
- Pelajari
- tersebut
- Metadata
- metode
- metode
- Metrik
- jutaan
- menit
- ML
- model
- model
- Memantau
- lebih
- paling
- pindah
- beberapa
- harus
- nama
- Bernama
- nama
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Arahkan
- Perlu
- dibutuhkan
- New
- berikutnya
- tidak
- mencatat
- buku catatan
- sekarang
- jumlah
- obyek
- objek
- of
- lepas
- ditawarkan
- on
- ONE
- operasi
- or
- teknik mengatur musik
- Lainnya
- jika tidak
- kami
- di luar
- keluaran
- lebih
- sendiri
- dikemas
- halaman
- halaman
- bagian
- untuk
- Izin
- memilih
- pipa saluran
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- Kebijakan
- diisi
- Pos
- potensi
- berpotensi
- disajikan
- mencegah
- Masalah
- proses
- proses
- pengolahan
- menghasilkan
- proyek
- tepat
- memberikan
- disediakan
- menyediakan
- publik
- menempatkan
- Ular sanca
- tercepat
- segera
- Mentah
- Baca
- siap
- nyata
- real-time
- sarankan
- direkomendasikan
- catatan
- arsip
- lihat
- referensi
- referensi
- ulangi
- melaporkan
- gudang
- permintaan
- wajib
- Persyaratan
- membutuhkan
- tabah
- mengakibatkan
- Hasil
- Peran
- BARIS
- Run
- berjalan
- berjalan
- aman
- Safety/keselamatan
- pembuat bijak
- sama
- Save
- terukur
- Skala
- naskah
- SDK
- Pencarian
- Kedua
- Bagian
- bagian
- sektor
- melihat
- memilih
- mengirim
- senior
- mengirim
- Urutan
- Server
- Tanpa Server
- layanan
- Layanan
- Sidang
- set
- harus
- mirip
- Sederhana
- hanya
- Ukuran
- pintar
- So
- larutan
- Solusi
- beberapa
- sumber
- merentang
- ketegangan
- spesialis
- ditentukan
- pintal
- tumpukan
- awal
- mulai
- Mulai
- Negara
- Status
- Langkah
- berhenti
- terhenti
- henti
- penyimpanan
- menyimpan
- tersimpan
- toko
- mudah
- Tali
- tersusun
- studio
- sukses
- seperti itu
- yakin
- sistem
- tabel
- Mengambil
- diambil
- Dibutuhkan
- pengambilan
- tim
- Teknologi
- terminal
- pengujian
- teks
- pembuatan teks
- dari
- bahwa
- Grafik
- informasi
- Sumber
- Negara
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- ini
- itu
- tiga
- Melalui
- keluaran
- Tim
- waktu
- untuk
- terhadap
- terima kasih
- jalur
- Pelatihan VE
- Transaksi
- transaksi per detik
- Putar
- penjaga penjara
- dua puluh
- dua
- tidak mampu
- bawah
- Tiba-tiba
- sampai
- diperbarui
- menggunakan
- gunakan case
- kegunaan
- menggunakan
- Penggunaan
- memanfaatkan
- variabel
- berbagai
- versi
- penglihatan
- menunggu
- ingin
- adalah
- Menonton
- Cara..
- we
- jaringan
- layanan web
- adalah
- Apa
- ketika
- yang
- seluruh
- akan
- dengan
- dalam
- tanpa
- Kerja
- alur kerja
- mengkhawatirkan
- akan
- dibungkus
- menulis
- tahun
- kamu
- Anda
- zephyrnet.dll