Jadi Anda sudah menonton semua tutorial. Anda sekarang memahami cara kerja jaringan saraf. Anda telah membuat pengklasifikasi kucing dan anjing. Anda mencoba tangan Anda di RNN tingkat karakter yang setengah layak. Kamu hanya satu pip install tensorflow jauh dari membangun terminator, kan? Salah.

Bagian yang sangat penting dari pembelajaran mendalam adalah menemukan hyperparameter yang tepat. Ini adalah angka-angka yang modelnya tidak bisa belajar.
Dalam artikel ini, saya akan memandu Anda melalui beberapa hyperparameter paling umum (dan penting) yang akan Anda temui di jalan menuju tempat #1 di papan peringkat Kaggle. Selain itu, saya juga akan menunjukkan beberapa algoritme canggih yang dapat membantu Anda memilih hyperparameter dengan bijak.
Hyperparameter dalam Pembelajaran Mendalam
Hyperparameters dapat dianggap sebagai kenop penyetelan model Anda.
Sistem home theater 7.1 Dolby Atmos yang mewah dengan subwoofer yang menghasilkan bass di luar jangkauan telinga manusia tidak berguna jika Anda menyetel penerima AV ke stereo.

Demikian pula, inception_v3 dengan satu triliun parameter bahkan tidak akan membuat Anda melewati MNIST jika hyperparameter Anda mati.
Jadi sekarang, mari kita lihat kenop yang harus disetel sebelum kita masuk ke cara memutar di pengaturan yang benar.
Tingkat Pembelajaran
Bisa dibilang hyperparameter yang paling penting, tingkat pembelajaran, berbicara kasar, mengontrol seberapa cepat jaringan saraf Anda "belajar".
Jadi mengapa kita tidak meningkatkan ini dan menjalani hidup di jalur cepat?

Tidak sesederhana itu. Ingat, dalam pembelajaran yang mendalam, tujuan kami adalah untuk meminimalkan fungsi kerugian. Jika tingkat pembelajaran terlalu tinggi, kerugian kita akan mulai melompat-lompat dan tidak pernah bertemu.

Dan jika kecepatan pembelajaran terlalu kecil, model akan memakan waktu terlalu lama untuk konvergen, seperti yang digambarkan di atas.
Momentum
Karena artikel ini berfokus pada optimasi hyperparameter, saya tidak akan menjelaskan keseluruhan konsep dari semangat. Tapi singkatnya, konstanta momentum dapat dianggap sebagai massa bola yang menggelinding ke bawah permukaan fungsi kerugian.
Semakin berat bola, semakin cepat jatuh. Namun jika terlalu berat, bisa macet atau melenceng dari target.

Keluar
Jika Anda merasakan tema di sini, sekarang saya akan mengarahkan Anda ke Amar Budirajaartikel tentang putus sekolah.

Tetapi sebagai penyegaran cepat, dropout adalah teknik regularisasi yang diusulkan oleh Geoff Hinton yang secara acak menetapkan aktivasi dalam jaringan saraf ke 0 dengan probabilitas (p). Ini membantu mencegah jaring saraf dari overfitting (menghafal) data yang bertentangan dengan mempelajarinya.
(p) adalah sebuah hiperparameter.
Arsitektur — Jumlah Lapisan, Neuron Per Lapisan, dll.
Ide lain (yang cukup baru) adalah membuat arsitektur jaringan saraf itu sendiri sebagai hyperparameter.
Meskipun kami biasanya tidak membuat mesin mengetahui arsitektur model kami (jika tidak, peneliti AI akan kehilangan pekerjaan mereka), beberapa teknik baru seperti Pencarian Arsitektur Saraf telah menerapkan ide ini dengan berbagai tingkat keberhasilan.
Jika Anda pernah mendengar tentang ML Otomatis, ini pada dasarnya bagaimana Google melakukannya: jadikan semuanya sebagai hyperparameter dan kemudian lemparkan satu miliar TPU pada masalah dan biarkan masalah itu selesai dengan sendirinya.
Tetapi bagi sebagian besar dari kita yang hanya ingin mengklasifikasikan kucing dan anjing dengan mesin anggaran yang dirakit setelah penjualan Black Friday, sudah saatnya kita menemukan cara untuk membuat model pembelajaran mendalam itu benar-benar berfungsi.
Algoritma Optimasi Hyperparameter
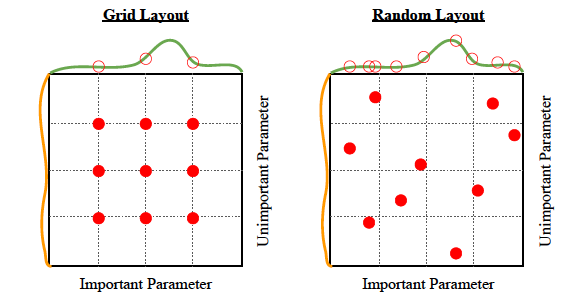
Pencarian Grid
Ini adalah cara termudah untuk mendapatkan hyperparameter yang baik. Ini benar-benar hanya kekerasan.
Algoritma: Cobalah sekelompok hyperparameter dari kumpulan hyperparameter tertentu, dan lihat mana yang paling berhasil.
Pro: Cukup mudah untuk diterapkan oleh siswa kelas lima. Dapat dengan mudah diparalelkan.
Kekurangan: Seperti yang mungkin Anda duga, ini sangat mahal secara komputasi (seperti semua metode brute force).
Haruskah saya menggunakannya: Mungkin tidak. Pencarian grid sangat tidak efisien. Bahkan jika Anda ingin membuatnya tetap sederhana, Anda lebih baik menggunakan pencarian acak.
Pencarian Acak
Semuanya ada dalam nama — pencarian pencarian acak. Secara acak.
Algoritma: Cobalah sekelompok hyperparameter acak dari distribusi seragam di beberapa ruang hyperparameter, dan lihat mana yang paling berhasil.
Pro: Dapat dengan mudah diparalelkan. Sesederhana pencarian grid, tapi sedikit kinerja yang lebih baik, seperti diilustrasikan di bawah ini:

Kekurangan: Meskipun memberikan kinerja yang lebih baik daripada pencarian grid, itu masih sama intensifnya dengan komputasi.
Haruskah saya menggunakannya: Jika paralelisasi dan kesederhanaan yang sepele sangat penting, lakukanlah. Tetapi jika Anda dapat meluangkan waktu dan tenaga, Anda akan mendapatkan imbalan besar dengan menggunakan Pengoptimalan Bayesian.
Optimasi Bayesian
Berbeda dengan metode lain yang telah kita lihat sejauh ini, optimasi Bayesian menggunakan pengetahuan tentang iterasi algoritma sebelumnya. Dengan pencarian grid dan pencarian acak, setiap tebakan hyperparameter adalah independen. Tetapi dengan metode Bayesian, setiap kali kami memilih dan mencoba hyperparameter yang berbeda, inci menuju kesempurnaan.

Ide di balik penyetelan hyperparameter Bayesian panjang dan kaya akan detail. Jadi untuk menghindari terlalu banyak lubang kelinci, saya akan memberikan intinya di sini. Tapi pastikan untuk membaca Proses Gaussian dan Optimalisasi Bayesian secara umum, jika itu yang Anda minati.
Ingat, alasan kami menggunakan algoritme penyetelan hyperparameter ini adalah karena tidak mungkin untuk benar-benar mengevaluasi beberapa pilihan hyperparameter satu per satu. Sebagai contoh, katakanlah kita ingin mencari kecepatan belajar yang baik secara manual. Ini akan melibatkan pengaturan tingkat pembelajaran, melatih model Anda, mengevaluasinya, memilih tingkat pembelajaran yang berbeda, melatih model Anda dari awal lagi, mengevaluasi kembali, dan siklus berlanjut.
Masalahnya, "melatih model Anda" bisa memakan waktu hingga berhari-hari (tergantung kerumitan masalahnya) untuk diselesaikan. Jadi, Anda hanya akan dapat mencoba beberapa tingkat pembelajaran pada saat batas waktu pengiriman makalah untuk konferensi muncul. Dan apa yang Anda tahu, Anda bahkan belum mulai bermain dengan momentum. Ups.

Algoritma: Metode Bayesian mencoba membangun fungsi (lebih akurat, distribusi probabilitas atas fungsi yang mungkin) yang memperkirakan seberapa baik model Anda mungkin untuk pilihan hyperparameter tertentu. Dengan menggunakan fungsi perkiraan ini (disebut fungsi pengganti dalam literatur), Anda tidak perlu melalui set, melatih, mengevaluasi loop terlalu banyak waktu, karena Anda hanya dapat mengoptimalkan hyperparameter ke fungsi pengganti.
Sebagai contoh, katakanlah kami ingin meminimalkan fungsi ini (anggap itu seperti proxy untuk fungsi kerugian model Anda):

Fungsi pengganti berasal dari sesuatu yang disebut proses Gaussian (catatan: ada cara lain untuk memodelkan fungsi pengganti, tetapi saya akan menggunakan proses Gaussian). Seperti, saya sebutkan, saya tidak akan melakukan derivasi matematika yang berat, tapi inilah inti dari semua pembicaraan tentang Bayesian dan Gauss:
$$ mathbb{P} (F_n(X)|X_n) = frac{e^{-frac12 F_n^T Sigma_n^{-1} F_n}}{sqrt{(2pi)^n |Sigma_n|}} $$
Yang, harus diakui adalah seteguk. Tapi mari kita coba memecahnya.
Sisi kiri memberi tahu Anda bahwa distribusi probabilitas terlibat (mengingat adanya tampilan mewah ( mathbb{P} ) ). Melihat ke dalam tanda kurung, kita dapat melihat bahwa itu adalah distribusi probabilitas dari ( F_n(X) ), yang merupakan beberapa fungsi arbitrer. Mengapa? Karena ingat, kita mendefinisikan distribusi probabilitas pada semua fungsi yang mungkin, bukan hanya fungsi tertentu. Intinya, sisi kiri mengatakan bahwa probabilitas bahwa fungsi sebenarnya yang memetakan hyperparameters ke metrik model (seperti akurasi validasi, kemungkinan log, tingkat kesalahan pengujian, dll.) adalah ( F_n(X) ), diberikan beberapa data sampel (X_n) sama dengan apa pun yang ada di sisi kanan.
Sekarang kami memiliki fungsi untuk mengoptimalkan, kami mengoptimalkannya.
Berikut adalah tampilan proses Gaussian sebelum kita memulai proses optimasi:

Gunakan pengoptimal pilihan favorit Anda (pro seperti memaksimalkan peningkatan yang diharapkan), tetapi entah bagaimana, cukup ikuti tanda (atau gradien) dan sebelum Anda menyadarinya, Anda akan berakhir di minimum lokal Anda.
Setelah beberapa iterasi, proses Gaussian menjadi lebih baik dalam mendekati fungsi target:

Terlepas dari metode yang Anda gunakan, Anda sekarang telah menemukan `argmin` dari fungsi pengganti. Ans surprise, surprise, argumen-argumen yang meminimalkan fungsi pengganti adalah (perkiraan) dari hyperparameter yang optimal! Ya.
Hasil akhir akan terlihat seperti ini:

Gunakan hyperparameter "optimal" ini untuk melakukan latihan di jaringan saraf Anda, dan Anda akan melihat beberapa peningkatan. Tetapi Anda juga dapat menggunakan informasi baru ini untuk mengulang seluruh proses pengoptimalan Bayesian, lagi, lagi, dan lagi. Jangan ragu untuk menjalankan loop Bayesian sebanyak yang Anda inginkan, tetapi berhati-hatilah. Anda benar-benar menghitung barang. Kredit AWS itu tidak gratis, lho. Atau apakah mereka…
Pro: Optimasi Bayesian memberikan hasil yang lebih baik daripada pencarian grid dan pencarian acak.
Kekurangan: Tidak mudah untuk memparalelkan.
Haruskah Saya Menggunakannya: Dalam kebanyakan kasus, ya! Satu-satunya pengecualian adalah jika
- Anda adalah pakar pembelajaran yang mendalam dan Anda tidak memerlukan bantuan algoritme aproksimasi yang sangat sedikit.
- Anda memiliki akses ke sumber daya komputasi yang luas dan dapat memparalelkan pencarian grid dan pencarian acak secara besar-besaran.
- Jika Anda seorang nerd statistik frequentist/anti-Bayesian.
Pendekatan Alternatif Untuk Menemukan Tingkat Pembelajaran yang Baik
Dalam semua metode yang telah kita lihat sejauh ini, ada satu tema mendasar: mengotomatiskan pekerjaan insinyur pembelajaran mesin. Yang hebat dan semuanya; sampai bos Anda mengetahui hal ini dan memutuskan untuk mengganti Anda dengan 4 kartu RTX Titan. Hah. Kira Anda seharusnya terjebak pada pencarian manual.

Tapi jangan putus asa, ada penelitian aktif di bidang membuat peneliti melakukan lebih sedikit dan sekaligus mendapatkan bayaran lebih. Dan salah satu ide yang berhasil dengan sangat baik adalah tes rentang kecepatan belajar, yang, sejauh pengetahuan saya, pertama kali muncul di makalah oleh Leslie Smith.
Makalah ini sebenarnya tentang metode penjadwalan (mengubah) tingkat pembelajaran dari waktu ke waktu. Tes jangkauan LR (laju pembelajaran) adalah bongkahan emas yang baru saja dijatuhkan oleh penulis dengan santai.
Saat Anda menggunakan jadwal laju pembelajaran yang memvariasikan laju pembelajaran dari nilai minimum hingga maksimum, seperti tingkat pembelajaran siklik or penurunan gradien stokastik dengan restart hangat, penulis menyarankan untuk meningkatkan kecepatan pembelajaran secara linier setelah setiap iterasi dari nilai kecil ke nilai besar (katakanlah, 1e-7 untuk 1e-1), mengevaluasi kerugian pada setiap iterasi, dan memplot kerugian (atau kesalahan pengujian atau akurasi) terhadap kecepatan pembelajaran pada skala log. Plot Anda akan terlihat seperti ini:

Seperti yang ditandai pada plot, Anda kemudian akan menggunakan mengatur jadwal tingkat pembelajaran Anda untuk memantul antara tingkat pembelajaran minimum dan maksimum, yang ditemukan dengan melihat plot dan mencoba mengamati wilayah dengan gradien paling curam.
Berikut adalah contoh plot uji jangkauan LR (DenseNet dilatih di CIFAR10) dari Colab kami buku catatan:

Sebagai aturan praktis, jika Anda tidak melakukan hal-hal jadwal kecepatan belajar yang mewah, cukup atur kecepatan belajar konstan Anda ke urutan besarnya lebih rendah dari nilai minimum pada plot. Dalam hal ini kira-kira 1e-2.
Bagian paling keren tentang metode ini, selain bekerja dengan sangat baik dan menghemat waktu, upaya mental, dan komputasi yang diperlukan untuk menemukan hyperparameter yang baik dengan algoritme lain, adalah biayanya hampir tanpa komputasi tambahan.
Sedangkan algoritma lainnya yaitu grid search, random search, dan Optimasi Bayesian, mengharuskan Anda untuk menjalankan seluruh proyek yang bersinggungan dengan tujuan Anda untuk melatih jaringan saraf yang baik, uji jangkauan LR hanya menjalankan loop pelatihan yang sederhana dan teratur, dan melacak beberapa variabel di sepanjang jalan.
Inilah jenis kecepatan konvergensi yang dapat Anda harapkan saat menggunakan kecepatan belajar yang optimal (dari contoh di buku catatan):

Tes jangkauan LR telah dilaksanakan oleh tim di cepat, dan Anda pasti harus melihat perpustakaan mereka untuk menerapkan uji jangkauan LR (mereka menyebutnya call pencari kecepatan belajar) serta banyak algoritma lainnya dengan mudah.
Untuk Praktisi Pembelajaran Mendalam yang Lebih Canggih
Jika Anda tertarik, ada juga buku catatan yang ditulis dengan murni pytorch yang menerapkan hal di atas. Ini mungkin memberi Anda pemahaman yang lebih baik tentang proses pelatihan di balik layar. Coba lihat di sini.
Selamatkan Diri Anda Upaya

Tentu saja, semua algoritme ini, sehebat apa pun, tidak selalu berhasil dalam praktik. Ada banyak faktor lagi yang perlu dipertimbangkan saat melatih jaringan saraf, seperti bagaimana Anda akan memproses data sebelumnya, menentukan model Anda, dan benar-benar mendapatkan komputer yang cukup kuat untuk menjalankannya.
Nanonet menyediakan API yang mudah digunakan untuk latih dan terapkan pembelajaran mendalam khusus model. Ini menangani semua pekerjaan berat, termasuk augmentasi data, pembelajaran transfer, dan ya, pengoptimalan hyperparameter!
Nanonet memanfaatkan pencarian Bayesian pada kluster GPU mereka yang luas untuk menemukan rangkaian hyperparameter yang tepat tanpa perlu khawatir kehabisan uang pada kartu grafis terbaru dan out of bounds for axis 0.
Setelah menemukan model terbaik, Nanonet menyajikannya di cloud mereka agar Anda dapat menguji model menggunakan antarmuka web mereka atau untuk mengintegrasikannya ke dalam program Anda menggunakan 2 baris kode.
Ucapkan selamat tinggal pada model yang kurang sempurna.
Kesimpulan
Pada artikel ini, kita telah berbicara tentang hyperparameter dan beberapa metode untuk mengoptimalkannya. Tapi apa artinya semua ini?
Saat kami berusaha lebih keras untuk mendemokratisasikan teknologi AI, penyetelan hyperparameter otomatis mungkin merupakan langkah ke arah yang benar. Ini memungkinkan orang biasa seperti Anda dan saya untuk membangun aplikasi pembelajaran mendalam yang luar biasa tanpa gelar PhD matematika.
Meskipun Anda dapat berargumen bahwa membuat model haus akan daya komputasi meninggalkan model terbaik di tangan mereka yang mampu membayar daya komputasi tersebut, layanan cloud seperti AWS dan Nanonets membantu mendemokratisasikan akses ke mesin yang kuat, membuat pembelajaran mendalam jauh lebih mudah diakses.
Tapi yang lebih mendasar, apa kita sebenarnya lakukan di sini menggunakan matematika untuk menyelesaikan lebih banyak matematika. Yang menarik bukan hanya karena bagaimana meta itu terdengar, tetapi juga karena betapa mudahnya itu bisa disalahartikan.

Kami tentu telah menempuh perjalanan jauh dari era kartu punch dan tabel jejak ke zaman di mana kami mengoptimalkan fungsi yang mengoptimalkan fungsi yang mengoptimalkan fungsi. Tapi kita sama sekali tidak bisa membuat mesin yang bisa "berpikir" sendiri.
Dan itu tidak mengecilkan hati, tidak sedikit, karena jika umat manusia dapat melakukan banyak hal dengan sedikit, bayangkan apa yang akan terjadi di masa depan, ketika visi kita menjadi sesuatu yang benar-benar dapat kita lihat.
Jadi kami duduk, di kursi empuk sambil menatap layar terminal kosong, setiap penekanan tombol memberi kami sudo kekuatan super yang dapat menghapus disk bersih.
Jadi kami duduk, kami duduk di sana sepanjang hari, karena terobosan besar berikutnya mungkin hanya satu pip install pergi.
Malas membuat kode? Tidak ingin menghabiskan sumber daya komputasi? Pergi ke Nanonet dan Mulai Membangun Model sekarang!
Anda mungkin tertarik dengan postingan terbaru kami di:
Sumber: https://nanonets.com/blog/hyperparameter-optimization/
- 7
- 9
- mengakses
- aktif
- AI
- algoritma
- algoritma
- Semua
- amp
- Lebah
- aplikasi
- arsitektur
- argumen
- artikel
- Terdengar
- Otomatis
- AV
- AWS
- TERBAIK
- Milyar
- Bit
- Black
- Black Friday
- membangun
- Bangunan
- ikat
- panggilan
- yang
- kasus
- Uang tunai
- Kucing
- awan
- layanan cloud
- kode
- Umum
- menghitung
- komputasi
- daya komputasi
- Konferensi
- terus
- Biaya
- Kredit
- data
- hari
- belajar mendalam
- Anjing
- menjatuhkan
- insinyur
- perkiraan
- dll
- FAST
- Angka
- menemukan
- Pertama
- cocok
- mengikuti
- Gratis
- Jumat
- FS
- fungsi
- masa depan
- gif
- GitHub
- Pemberian
- Gold
- baik
- GPU
- besar
- kisi
- kepala
- di sini
- High
- Beranda
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTTPS
- Lapar
- ide
- inci
- Termasuk
- informasi
- terlibat
- IT
- Pekerjaan
- Jobs
- pemeliharaan
- pengetahuan
- besar
- Terbaru
- BELAJAR
- pengetahuan
- Perpustakaan
- literatur
- lokal
- logo
- Panjang
- Mesin belajar
- Mesin
- Mayoritas
- Membuat
- Peta
- matematika
- Media
- medium
- meme
- meta
- Metrik
- model
- Momentum
- yaitu
- bersih
- jaringan
- saraf
- saraf jaringan
- nomor
- urutan
- Lainnya
- kertas
- prestasi
- Posts
- kekuasaan
- program
- proyek
- wakil
- pons
- jarak
- Tarif
- RE
- penelitian
- Sumber
- Hasil
- Run
- penjualan
- Skala
- Layar
- Pencarian
- Layanan
- set
- pengaturan
- Pendek
- Tanda
- Sederhana
- kecil
- So
- MEMECAHKAN
- Space
- kecepatan
- menghabiskan
- Spot
- awal
- mulai
- statistika
- sukses
- Permukaan
- mengherankan
- sistem
- target
- Teknologi
- uji
- Masa depan
- teater
- tema
- waktu
- jalur
- Pelatihan
- tutorial
- Unsplash
- us
- kegunaan
- nilai
- Menonton
- jaringan
- SIAPA
- angin
- Kerja
- bekerja
- X







{kind=link}
{kind=link}
{kind=link}