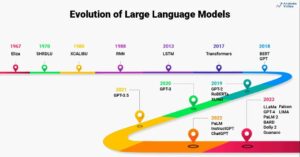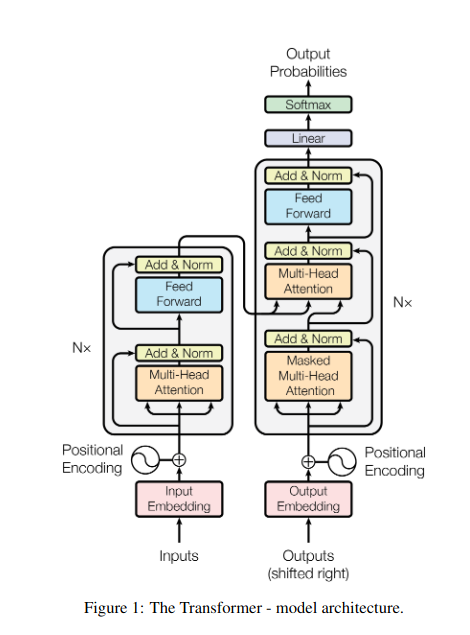
Pengantar
Bayangkan berdiri di perpustakaan yang remang-remang, berjuang untuk menguraikan dokumen yang rumit sambil mengerjakan lusinan teks lainnya. Inilah dunia Transformers sebelum makalah “Attention is All You Need” mengungkap sorotan revolusionernya – the mekanisme perhatian.
Daftar Isi
Keterbatasan RNN
Model sekuensial tradisional, seperti Jaringan Syaraf Berulang (RNNs), bahasa yang diolah kata demi kata, menimbulkan beberapa keterbatasan:
- Ketergantungan jangka pendek: RNN kesulitan memahami hubungan antara kata-kata yang berjauhan, sering kali salah menafsirkan arti kalimat seperti “pria yang mengunjungi kebun binatang kemarin”, yang subjek dan kata kerjanya berjauhan.
- Paralelisme terbatas: Memproses informasi secara berurutan pada dasarnya lambat, sehingga menghambat pelatihan dan pemanfaatan sumber daya komputasi yang efisien, terutama untuk urutan yang panjang.
- Fokus pada konteks lokal: RNN terutama mempertimbangkan tetangga dekat, yang berpotensi kehilangan informasi penting dari bagian lain kalimat.
Keterbatasan ini menghambat kemampuan Transformers untuk melakukan tugas-tugas kompleks seperti terjemahan mesin dan pemahaman bahasa alami. Lalu datanglah mekanisme perhatian, sorotan revolusioner yang menerangi hubungan tersembunyi antar kata, mengubah pemahaman kita tentang pemrosesan bahasa. Tapi apa sebenarnya yang dipecahkan oleh perhatian, dan bagaimana hal itu mengubah permainan Transformers?
Mari kita fokus pada tiga bidang utama:
Ketergantungan Jangka Panjang
- Masalah: Model tradisional sering kali tersandung pada kalimat seperti “wanita yang tinggal di bukit melihat bintang jatuh tadi malam”. Mereka kesulitan menghubungkan “wanita” dan “bintang jatuh” karena jarak yang jauh, sehingga menimbulkan salah tafsir.
- Mekanisme Perhatian: Bayangkan model menyinari kalimat dengan sinar terang, menghubungkan “wanita” langsung dengan “bintang jatuh” dan memahami kalimat secara keseluruhan. Kemampuan untuk menangkap hubungan tanpa memandang jarak sangat penting untuk tugas-tugas seperti terjemahan mesin dan peringkasan.
Baca Juga: Sekilas Tentang Long Short Term Memory (LSTM)
Kekuatan Pemrosesan Paralel
- Masalah: Model tradisional memproses informasi secara berurutan, seperti membaca buku halaman demi halaman. Ini lambat dan tidak efisien, terutama untuk teks yang panjang.
- Mekanisme Perhatian: Bayangkan beberapa lampu sorot memindai perpustakaan secara bersamaan, menganalisis berbagai bagian teks secara paralel. Hal ini secara dramatis mempercepat kerja model, sehingga memungkinkannya menangani data dalam jumlah besar secara efisien. Kekuatan pemrosesan paralel ini penting untuk melatih model yang kompleks dan membuat prediksi secara real-time.
Kesadaran Konteks Global
- Masalah: Model tradisional sering kali berfokus pada kata-kata individual, mengabaikan konteks kalimat yang lebih luas. Hal ini menyebabkan kesalahpahaman dalam kasus-kasus seperti sarkasme atau makna ganda.
- Mekanisme Perhatian: Bayangkan sorotan menyapu seluruh perpustakaan, mengamati setiap buku dan memahami bagaimana buku-buku tersebut berhubungan satu sama lain. Kesadaran konteks global ini memungkinkan model untuk mempertimbangkan keseluruhan teks ketika menafsirkan setiap kata, sehingga menghasilkan pemahaman yang lebih kaya dan bernuansa.
Membedakan Kata-kata Polisemi
- Masalah: Kata-kata seperti “bank” atau “apel” dapat berupa kata benda, kata kerja, atau bahkan perusahaan, sehingga menciptakan ambiguitas yang sulit dipecahkan oleh model tradisional.
- Mekanisme Perhatian: Bayangkan model tersebut menyoroti semua kemunculan kata “bank” dalam sebuah kalimat, lalu menganalisis konteks di sekitarnya dan hubungannya dengan kata lain. Dengan mempertimbangkan struktur tata bahasa, kata benda di dekatnya, dan bahkan kalimat lampau, mekanisme perhatian dapat menyimpulkan makna yang diinginkan. Kemampuan untuk membedakan kata-kata polisemi sangat penting untuk tugas-tugas seperti terjemahan mesin, peringkasan teks, dan sistem dialog.
Keempat aspek ini – ketergantungan jangka panjang, kekuatan pemrosesan paralel, kesadaran konteks global, dan disambiguasi – menunjukkan kekuatan transformatif dari mekanisme perhatian. Mereka telah mendorong Transformers ke garis depan dalam pemrosesan bahasa alami, memungkinkan mereka menangani tugas-tugas kompleks dengan akurasi dan efisiensi luar biasa.
Ketika NLP dan khususnya LLM terus berkembang, mekanisme perhatian pasti akan memainkan peran yang lebih penting. Mereka adalah jembatan antara rangkaian kata yang linier dan kekayaan bahasa manusia, dan pada akhirnya, kunci untuk mengungkap potensi sebenarnya dari keajaiban linguistik ini. Artikel ini mempelajari berbagai jenis mekanisme perhatian dan fungsinya.
1. Perhatian Diri: Bintang Pemandu Transformer
Bayangkan mengerjakan banyak buku dan perlu merujuk bagian tertentu di masing-masing buku sambil menulis ringkasan. Perhatian diri atau perhatian Produk Titik Berskala bertindak seperti asisten cerdas, membantu model melakukan hal yang sama dengan data berurutan seperti kalimat atau deret waktu. Hal ini memungkinkan setiap elemen dalam urutan untuk memperhatikan setiap elemen lainnya, secara efektif menangkap ketergantungan jangka panjang dan hubungan yang kompleks.
Berikut ini melihat lebih dekat aspek teknis intinya:
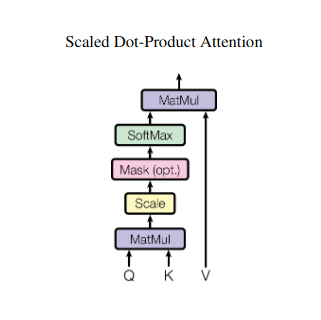
Representasi Vektor
Setiap elemen (kata, titik data) diubah menjadi vektor berdimensi tinggi, mengkodekan konten informasinya. Ruang vektor ini berfungsi sebagai landasan interaksi antar elemen.
Transformasi QKV
Tiga matriks utama didefinisikan:
- Kueri (Q): Mewakili “pertanyaan” yang diajukan setiap elemen kepada elemen lainnya. Q menangkap kebutuhan informasi elemen saat ini dan memandu pencarian informasi relevan dalam urutannya.
- Kunci (K): Memegang "kunci" untuk informasi setiap elemen. K mengkodekan esensi konten setiap elemen, memungkinkan elemen lain mengidentifikasi potensi relevansi berdasarkan kebutuhannya.
- Nilai (V): Menyimpan konten sebenarnya yang ingin dibagikan setiap elemen. V berisi informasi terperinci yang dapat diakses dan dimanfaatkan oleh elemen lain berdasarkan skor perhatian mereka.
Perhitungan Skor Perhatian
Kompatibilitas antara setiap pasangan elemen diukur melalui perkalian titik antara vektor Q dan K masing-masing. Skor yang lebih tinggi menunjukkan potensi relevansi yang lebih kuat antar elemen.
Bobot Perhatian Berskala
Untuk memastikan kepentingan relatif, skor kompatibilitas ini dinormalisasi menggunakan fungsi softmax. Hal ini menghasilkan bobot perhatian, mulai dari 0 hingga 1, yang mewakili bobot kepentingan setiap elemen untuk konteks elemen saat ini.
Agregasi Konteks Tertimbang
Bobot perhatian diterapkan pada matriks V, yang pada dasarnya menyoroti informasi penting dari setiap elemen berdasarkan relevansinya dengan elemen saat ini. Jumlah tertimbang ini menciptakan representasi kontekstual untuk elemen saat ini, menggabungkan wawasan yang diperoleh dari semua elemen lain dalam rangkaian tersebut.
Representasi Elemen yang Ditingkatkan
Dengan representasi yang diperkaya, elemen tersebut kini memiliki pemahaman yang lebih dalam tentang kontennya sendiri serta hubungannya dengan elemen lain dalam rangkaian tersebut. Representasi yang diubah ini menjadi dasar untuk pemrosesan selanjutnya dalam model.
Proses multi-langkah ini memungkinkan perhatian diri untuk:
- Menangkap ketergantungan jangka panjang: Hubungan antara unsur-unsur yang berjauhan menjadi jelas terlihat, bahkan jika dipisahkan oleh beberapa unsur yang mengintervensi.
- Modelkan interaksi yang kompleks: Ketergantungan dan korelasi yang halus dalam urutan tersebut akan terungkap, sehingga menghasilkan pemahaman yang lebih kaya tentang struktur dan dinamika data.
- Kontekstualisasikan setiap elemen: Model ini menganalisis setiap elemen tidak secara terpisah tetapi dalam kerangka rangkaian yang lebih luas, sehingga menghasilkan prediksi atau representasi yang lebih akurat dan bernuansa.
Perhatian terhadap diri sendiri telah merevolusi cara model memproses data berurutan, membuka kemungkinan baru di berbagai bidang seperti terjemahan mesin, pembuatan bahasa alami, perkiraan rangkaian waktu, dan seterusnya. Kemampuannya untuk mengungkap hubungan tersembunyi dalam rangkaian memberikan alat yang ampuh untuk mengungkap wawasan dan mencapai kinerja unggul dalam berbagai tugas.
2. Perhatian Multi-Kepala: Melihat Melalui Lensa Berbeda
Perhatian pada diri sendiri memberikan pandangan holistik, namun terkadang fokus pada aspek tertentu dari data sangatlah penting. Di sinilah perhatian multi-kepala berperan. Bayangkan memiliki beberapa asisten, masing-masing dilengkapi dengan lensa berbeda:
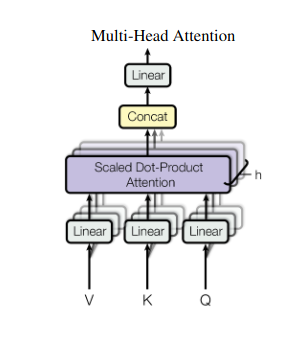
- Banyak “kepala” dibuat, masing-masing memperhatikan urutan masukan melalui matriks Q, K, dan V-nya sendiri.
- Setiap kepala belajar untuk fokus pada aspek data yang berbeda, seperti ketergantungan jangka panjang, hubungan sintaksis, atau interaksi kata lokal.
- Keluaran dari masing-masing kepala kemudian digabungkan dan diproyeksikan ke representasi akhir, yang menangkap sifat masukan yang beragam.
Hal ini memungkinkan model untuk mempertimbangkan berbagai perspektif secara bersamaan, sehingga menghasilkan pemahaman data yang lebih kaya dan lebih beragam.
3. Perhatian Silang: Membangun Jembatan Antar Urutan
Kemampuan untuk memahami hubungan antara berbagai informasi sangat penting untuk banyak tugas NLP. Bayangkan menulis resensi buku – Anda tidak hanya meringkas teks kata demi kata, namun juga menarik wawasan dan hubungan antar bab. Memasuki perhatian silang, mekanisme ampuh yang menjembatani antar rangkaian, memberdayakan model untuk memanfaatkan informasi dari dua sumber berbeda.
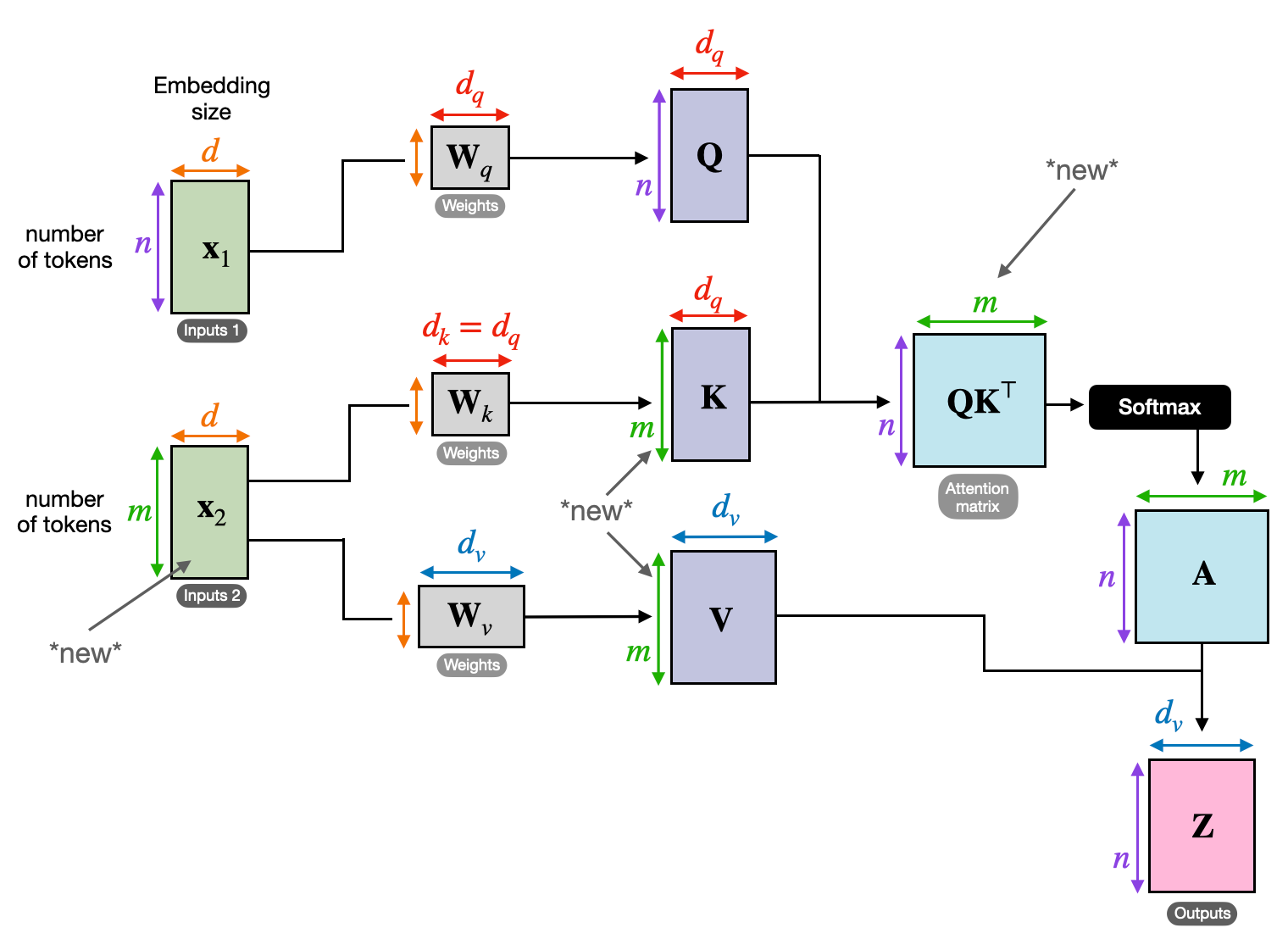
- Dalam arsitektur encoder-decoder seperti Transformers, encoder memproses urutan masukan (buku) dan menghasilkan representasi tersembunyi.
- Grafik decoder menggunakan perhatian silang untuk memperhatikan representasi tersembunyi pembuat enkode di setiap langkah sambil menghasilkan urutan keluaran (tinjauan).
- Matriks Q decoder berinteraksi dengan matriks K dan V encoder, memungkinkannya fokus pada bagian buku yang relevan sambil menulis setiap kalimat ulasan.
Mekanisme ini sangat berharga untuk tugas-tugas seperti penerjemahan mesin, peringkasan, dan menjawab pertanyaan, yang memerlukan pemahaman hubungan antara rangkaian masukan dan keluaran.
4. Perhatian Kausal: Mempertahankan Aliran Waktu
Bayangkan memprediksi kata berikutnya dalam sebuah kalimat tanpa melihat ke depan. Mekanisme perhatian tradisional kesulitan dengan tugas-tugas yang memerlukan pemeliharaan urutan informasi temporal, seperti pembuatan teks dan perkiraan rangkaian waktu. Mereka dengan mudah “mengintip ke depan” dalam urutan tersebut, sehingga menghasilkan prediksi yang tidak akurat. Perhatian kausal mengatasi keterbatasan ini dengan memastikan prediksi hanya bergantung pada informasi yang diproses sebelumnya.
Berikut Cara Kerjanya
- Mekanisme Penyamaran: Masker khusus diterapkan pada bobot perhatian, yang secara efektif memblokir akses model ke elemen masa depan dalam urutan. Misalnya, saat memprediksi kata kedua dalam “wanita yang…”, model hanya dapat mempertimbangkan “the” dan bukan “who” atau kata-kata berikutnya.
- Pemrosesan Autoregresif: Informasi mengalir secara linear, dengan representasi masing-masing elemen dibangun hanya dari elemen-elemen yang muncul sebelumnya. Model memproses urutan kata demi kata, menghasilkan prediksi berdasarkan konteks yang ditetapkan hingga saat itu.
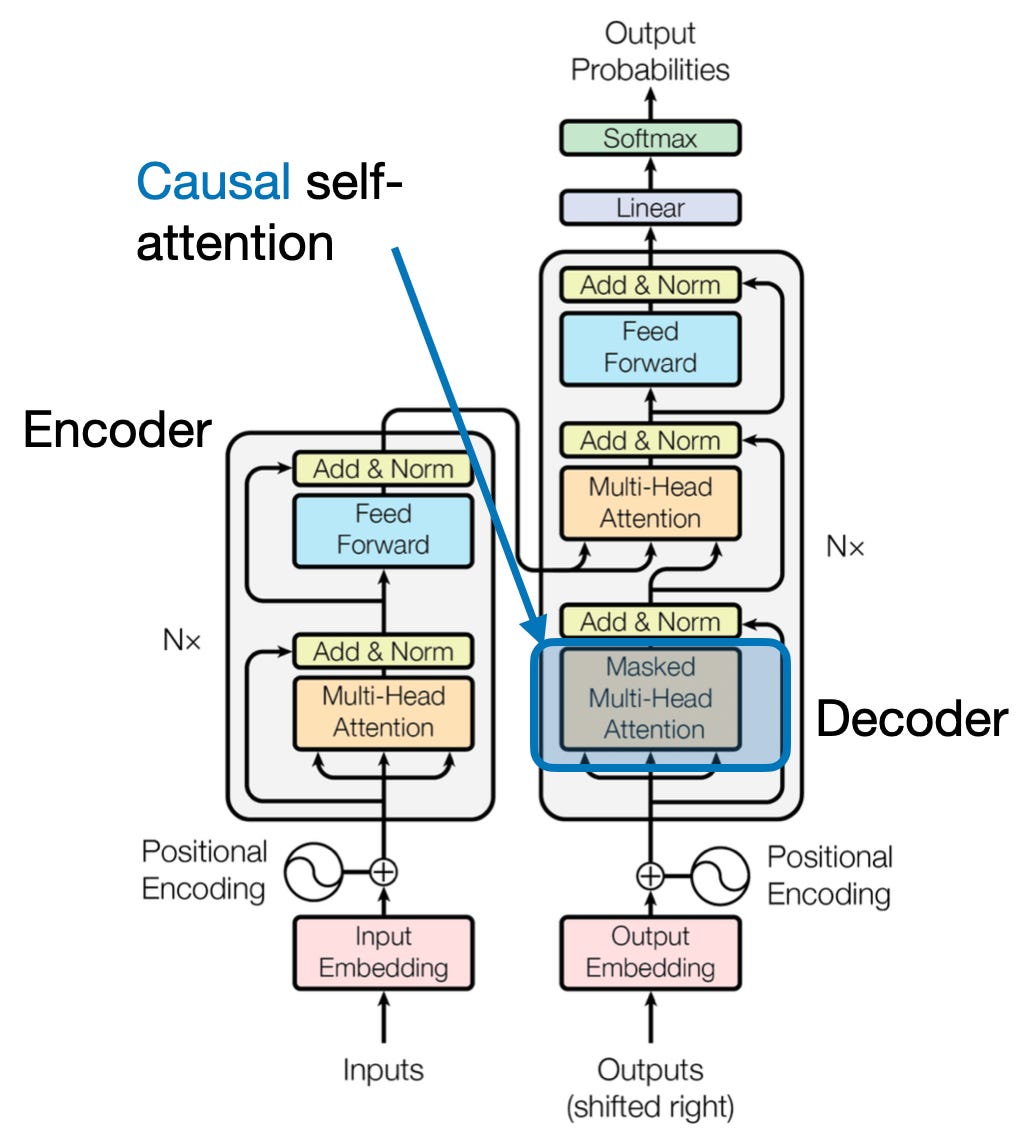
Perhatian kausal sangat penting untuk tugas-tugas seperti pembuatan teks dan perkiraan rangkaian waktu, di mana menjaga urutan temporal data sangat penting untuk prediksi yang akurat.
5. Perhatian Global vs. Lokal: Mencapai Keseimbangan
Mekanisme perhatian menghadapi trade-off utama: menangkap ketergantungan jangka panjang versus mempertahankan komputasi yang efisien. Hal ini diwujudkan dalam dua pendekatan utama: perhatian global dan perhatian lokal. Bayangkan membaca keseluruhan buku versus berfokus pada bab tertentu. Perhatian global memproses seluruh rangkaian sekaligus, sedangkan perhatian lokal berfokus pada jendela yang lebih kecil:
- Perhatian global menangkap ketergantungan jangka panjang dan konteks keseluruhan tetapi bisa memakan biaya komputasi yang mahal untuk rangkaian yang panjang.
- Perhatian lokal lebih efisien tetapi mungkin kehilangan hubungan jarak jauh.
Pilihan antara perhatian global dan lokal bergantung pada beberapa faktor:
- Persyaratan tugas: Tugas-tugas seperti penerjemahan mesin memerlukan hubungan jarak jauh, lebih mengutamakan perhatian global, sementara analisis sentimen mungkin lebih mengutamakan fokus perhatian lokal.
- Panjang urutan: Urutan yang lebih panjang membuat perhatian global menjadi mahal secara komputasi, sehingga memerlukan pendekatan lokal atau hibrida.
- Kapasitas model: Keterbatasan sumber daya mungkin memerlukan perhatian lokal bahkan untuk tugas-tugas yang memerlukan konteks global.
Untuk mencapai keseimbangan optimal, model dapat menggunakan:
- Peralihan dinamis: menggunakan perhatian global untuk elemen-elemen kunci dan perhatian lokal untuk elemen-elemen lain, beradaptasi berdasarkan kepentingan dan jarak.
- Pendekatan hibrida: menggabungkan kedua mekanisme dalam lapisan yang sama, memanfaatkan kekuatannya masing-masing.
Baca Juga: Menganalisis Jenis Jaringan Syaraf Tiruan dalam Pembelajaran Mendalam
Kesimpulan
Pada akhirnya, pendekatan yang ideal terletak pada spektrum antara perhatian global dan lokal. Memahami trade-off ini dan mengadopsi strategi yang sesuai memungkinkan model untuk mengeksploitasi informasi relevan secara efisien di berbagai skala, sehingga menghasilkan pemahaman yang lebih kaya dan akurat tentang urutannya.
Referensi
- Raschka, S. (2023). “Memahami dan Mengkodekan Perhatian Diri, Perhatian Multi-Kepala, Perhatian Silang, dan Perhatian Kausal di LLM.”
- Vaswani, A., dkk. (2017). “Hanya Perhatian yang Anda Butuhkan.”
- Radford, A., dkk. (2019). “Model Bahasa adalah Pembelajar Multitask Tanpa Pengawasan.”
terkait
Saya seorang pecinta data dan saya suka mengekstraksi dan memahami pola tersembunyi dalam data. Saya ingin belajar dan berkembang di bidang Pembelajaran Mesin dan Ilmu Data.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- kemampuan
- mengakses
- ketepatan
- tepat
- Mencapai
- mencapai
- di seluruh
- tindakan
- sebenarnya
- alamat
- Mengadopsi
- di depan
- AL
- Semua
- Membiarkan
- memungkinkan
- am
- Kemenduaan
- jumlah
- an
- analisis
- analisis
- menganalisis
- dan
- menjawab
- selain
- semu
- terapan
- pendekatan
- pendekatan
- ADALAH
- daerah
- artikel
- AS
- aspek
- Asisten
- asisten
- At
- menghadiri
- menghadiri
- perhatian
- kesadaran
- Saldo
- berdasarkan
- dasar
- BE
- Balok
- menjadi
- sebelum
- antara
- Luar
- pemblokiran
- Book
- Buku-buku
- kedua
- JEMBATAN
- jembatan
- Bright
- lebih luas
- Terbawa
- Bangunan
- membangun
- dibangun di
- tapi
- by
- datang
- CAN
- menangkap
- menangkap
- Menangkap
- kasus
- perubahan
- Bab
- bab
- pilihan
- lebih dekat
- Pengkodean
- menggabungkan
- datang
- Perusahaan
- kesesuaian
- kompleks
- komputasi
- komputasi
- Terhubung
- Menghubungkan
- Koneksi
- Mempertimbangkan
- mengingat
- kendala
- mengandung
- Konten
- konteks
- terus
- Core
- korelasi
- dibuat
- menciptakan
- membuat
- kritis
- sangat penting
- terbaru
- data
- ilmu data
- Menguraikan
- mendalam
- lebih dalam
- didefinisikan
- menggali
- tergantung
- ketergantungan
- ketergantungan
- Ketergantungan
- tergantung
- terperinci
- Dialog
- MELAKUKAN
- berbeda
- langsung
- jarak
- Jauh
- berbeda
- beberapa
- do
- dokumen
- DOT
- dua kali lipat
- puluhan
- secara dramatis
- seri
- dua
- dinamika
- E&T
- setiap
- efektif
- efisiensi
- efisien
- efisien
- elemen
- elemen
- memberdayakan
- memungkinkan
- memungkinkan
- encoding
- diperkaya
- memastikan
- memastikan
- Enter
- Seluruh
- keseluruhan
- lengkap
- terutama
- esensi
- penting
- dasarnya
- mapan
- Bahkan
- Setiap
- berkembang
- persis
- mahal
- Mengeksploitasi
- ekstrak
- Menghadapi
- faktor
- jauh
- mendukung
- bidang
- Fields
- terakhir
- aliran
- Mengalir
- Fokus
- terfokus
- berfokus
- berfokus
- Untuk
- garis terdepan
- bentuk
- Prinsip Dasar
- empat
- Kerangka
- dari
- fungsi
- fungsionalitas
- masa depan
- permainan
- menghasilkan
- menghasilkan
- generasi
- Aksi
- konteks global
- memahami
- Tumbuh
- Panduan
- membimbing
- menangani
- Memiliki
- memiliki
- kepala
- membantu
- Tersembunyi
- High
- lebih tinggi
- menyoroti
- memegang
- holistik
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTTPS
- manusia
- Hibrida
- i
- ideal
- mengenali
- if
- membayangkan
- Segera
- pentingnya
- penting
- in
- tidak akurat
- menggabungkan
- menunjukkan
- sendiri-sendiri
- tidak efisien
- informasi
- secara inheren
- memasukkan
- wawasan
- contoh
- Cerdas
- dimaksudkan
- interaksi
- interaksi
- interaktif
- campur tangan
- ke
- tak ternilai
- isolasi
- IT
- NYA
- jpg
- hanya
- kunci
- Area Utama
- bahasa
- Terakhir
- lapisan
- terkemuka
- BELAJAR
- Belajar dan Tumbuh
- pelajar
- pengetahuan
- Dipimpin
- lensa
- lensa
- Leverage
- leveraging
- Perpustakaan
- terletak
- cahaya
- 'like'
- pembatasan
- keterbatasan
- lokal
- Panjang
- lagi
- melihat
- cinta
- mesin
- Mesin belajar
- mesin penerjemah
- mempertahankan
- membuat
- Membuat
- pria
- banyak
- masker
- Matriks
- max-width
- makna
- makna
- diukur
- mekanisme
- mekanisme
- Memori
- mungkin
- kehilangan
- hilang
- model
- model
- lebih
- lebih efisien
- multifaset
- beberapa
- Alam
- Bahasa Alami
- Generasi Bahasa Alami
- Pengolahan Bahasa alami
- Pemahaman Bahasa Alamiah
- Alam
- Perlu
- membutuhkan
- kebutuhan
- tetangga
- jaringan
- saraf
- jaringan saraf
- New
- berikutnya
- malam
- nLP
- kata benda
- sekarang
- bernuansa
- of
- sering
- on
- sekali
- hanya
- optimal
- or
- urutan
- Lainnya
- Lainnya
- kami
- di luar
- keluaran
- output
- secara keseluruhan
- ikhtisar
- sendiri
- halaman
- pasangan
- kertas
- Paralel
- bagian
- bagian
- lalu
- pola
- melakukan
- prestasi
- perspektif
- potongan-potongan
- plato
- Kecerdasan Data Plato
- Data Plato
- Bermain
- Titik
- pose
- memiliki
- kemungkinan
- ampuh
- potensi
- berpotensi
- kekuasaan
- kuat
- memprediksi
- Prediksi
- melestarikan
- mencegah
- sebelumnya
- terutama
- primer
- proses
- diproses
- proses
- pengolahan
- Memproses Daya
- Produk
- diproyeksikan
- didorong
- menyediakan
- pertanyaan
- jarak
- mulai
- agak
- Baca
- segera
- Bacaan
- real-time
- referensi
- Bagaimanapun juga
- Hubungan
- relatif
- relevansi
- relevan
- luar biasa
- perwakilan
- mewakili
- merupakan
- membutuhkan
- menyelesaikan
- sumber
- Sumber
- itu
- Hasil
- ulasan
- revolusioner
- merevolusi
- Kaya
- Peran
- s
- sama
- Sarkasme
- melihat
- sisik
- pemindaian
- Ilmu
- skor
- skor
- Pencarian
- Kedua
- melihat
- putusan pengadilan
- sentimen
- Urutan
- Seri
- melayani
- beberapa
- Share
- bersinar
- penembakan
- Pendek
- menampilkan
- serentak
- lambat
- lebih kecil
- semata-mata
- MEMECAHKAN
- kadang-kadang
- sumber
- Space
- tertentu
- Secara khusus
- Spektrum
- kecepatan
- lampu sorot
- kedudukan
- Bintang
- Langkah
- toko
- strategi
- kekuatan
- lebih kuat
- struktur
- Perjuangan
- Berjuang
- subyek
- selanjutnya
- seperti itu
- cocok
- jumlah
- meringkaskan
- RINGKASAN
- unggul
- Sekitarnya
- sistem
- memecahkan
- pengambilan
- permadani
- tugas
- Teknis
- istilah
- teks
- pembuatan teks
- bahwa
- Grafik
- Dunia
- mereka
- Mereka
- kemudian
- Ini
- mereka
- ini
- tiga
- Melalui
- waktu
- Seri waktu
- untuk
- alat
- tradisional
- Pelatihan
- transformatif
- berubah
- transformator
- transformer
- mengubah
- Terjemahan
- benar
- dua
- jenis
- Akhirnya
- memahami
- pemahaman
- niscaya
- unlocking
- menyingkap
- meluncurkan
- menggunakan
- kegunaan
- menggunakan
- berbagai
- Luas
- Lawan
- View
- mengunjungi
- vital
- vs
- ingin
- ingin
- adalah
- BAIK
- Apa
- ketika
- sementara
- SIAPA
- seluruh
- lebar
- Rentang luas
- akan
- jendela
- dengan
- dalam
- tanpa
- wanita
- Word
- kata
- Kerja
- dunia
- penulisan
- kemarin
- kamu
- zephyrnet.dll
- KEBUN BINATANG