In 2021 és a 2020, meséltünk az új funkciókról Amazon RedShift amelyek egyszerűbbé, gyorsabbá és költséghatékonyabbá teszik az összes adat elemzését, valamint gazdag és hatékony betekintést. 2022-ben örömmel jelenthetjük, hogy az Amazon Redshift csapata keményen dolgozott. Az ügyfelek igényeihez képest visszafelé dolgoztunk, és számos új funkciót jelentettünk be, hogy egyszerűbbé, gyorsabbá és költséghatékonyabbá tegyük az összes adat elemzését. Ez a bejegyzés néhány ilyen új funkcióval foglalkozik.
Az AWS-nél az adatok és az elemzések esetében a stratégiánk az, hogy a modern adatarchitektúra amely segít megszabadulni az adatsilóktól; célirányosan felépített adatokkal, elemzésekkel, gépi tanulással (ML) és mesterséges intelligencia szolgáltatással rendelkezzenek a megfelelő eszköz használatához a megfelelő munkához; nyílt, szabályozott, biztonságos és teljes körűen felügyelt szolgáltatásokkal kell rendelkezniük, hogy mindenki számára elérhetővé tegyék az elemzéseket. Az AWS modern adatarchitektúráján belül az Amazon Redshift mint felhő adattárház továbbra is kulcsfontosságú komponens, amely lehetővé teszi komplex SQL-analitika tera- és petabájtnyi strukturált és strukturálatlan adat skálán és teljesítményű futtatását, és a betekintést széles körben elérhetővé teszi a népszerű üzleti intelligencia segítségével ( BI) és elemzőeszközök. Továbbra is visszafelé dolgozunk az ügyfelek igényeihez képest, és 2022-ben több mint 40 funkciót vezettünk be az Amazon Redshiftben, hogy segítsünk ügyfeleinknek a legfontosabb adattárház-használati eseteikben, többek között:
- Önkiszolgáló elemzés
- Könnyű adatbevitel
- Adatmegosztás és együttműködés
- Adattudomány és gépi tanulás
- Biztonságos és megbízható analitika
- A legjobb ár-teljesítmény elemzése
Merüljünk el mélyebben, és beszéljük meg az Amazon Redshift új funkcióit ezeken a területeken.
Önkiszolgáló elemzés
Az ügyfelek továbbra is azt mondják nekünk, hogy az adatok és az elemzések mindenütt jelen vannak, és a szervezetükben mindenkinek szüksége van elemzésre. bejelentettük Amazon Redshift Serverless (előzetes verzióban) 2021-ben, hogy egyszerűvé tegyék az elemzések másodpercek alatti futtatását és méretezését anélkül, hogy adattárház-infrastruktúrát kellene kiépíteni és kezelni. 2022 júliusában bejelentettük a a Redshift Serverless általános elérhetősége, és azóta ügyfelek ezrei, köztük a Peloton, a Broadridge Financials és a NextGen Healthcare használják adataik gyors és egyszerű elemzésére. Az Amazon Redshift Serverless automatikusan gondoskodik és intelligensen skálázza az adattárház kapacitását, hogy nagy teljesítményt nyújtson az összes elemzéshez, és Ön csak a munkaterhelés időtartama alatt használt számításokért fizet másodpercenként. A GA óta olyan funkciókat adtunk hozzá, mint pl erőforrás-címkézés, egyszerűsített felügyelet és elérhetőség további AWS-régiókban a számlázás további egyszerűsítése és az elérés kiterjesztése a világ több régiójában.
2021-ben elindítottuk az Amazon Redshift Query Editor V2-t, amely egy ingyenes webalapú eszköz adatelemzők, adattudósok és fejlesztők számára az Amazon Redshift adattárházaiban és adattóiban található adatok feltárására, elemzésére és az adatokon való együttműködésre. 2022-ben a Query Editor V2 további fejlesztéseket kapott, mint pl notebook támogatás a jobb együttműködés érdekében a lekérdezések szerzője, rendszerezése és megjegyzései között; felhasználói hozzáférés keresztül identitásszolgáltató (IdP) hitelesítő adatai egyszeri bejelentkezéshez; és több lekérdezés egyidejű futtatása a fejlesztői termelékenység javítása érdekében.
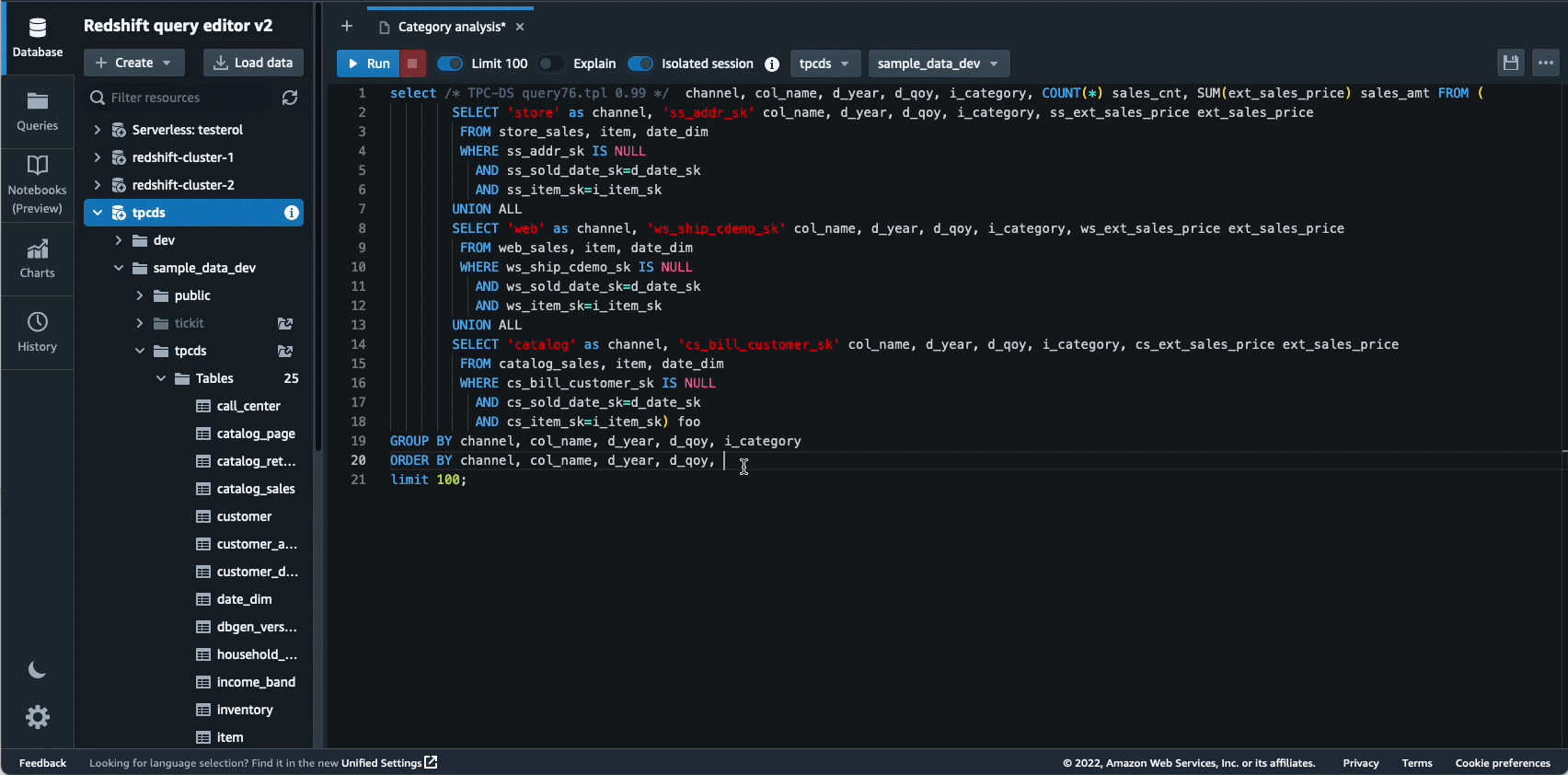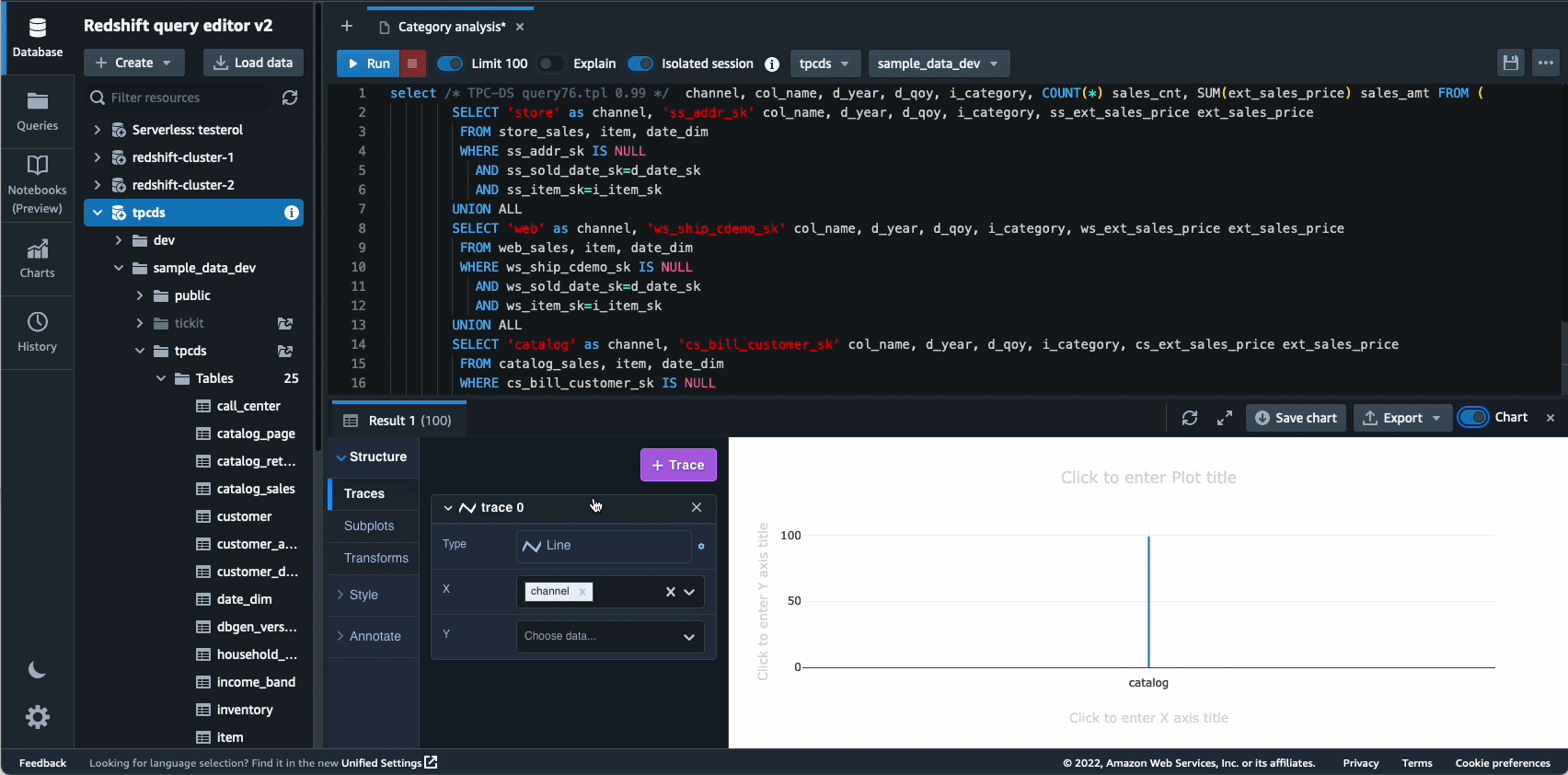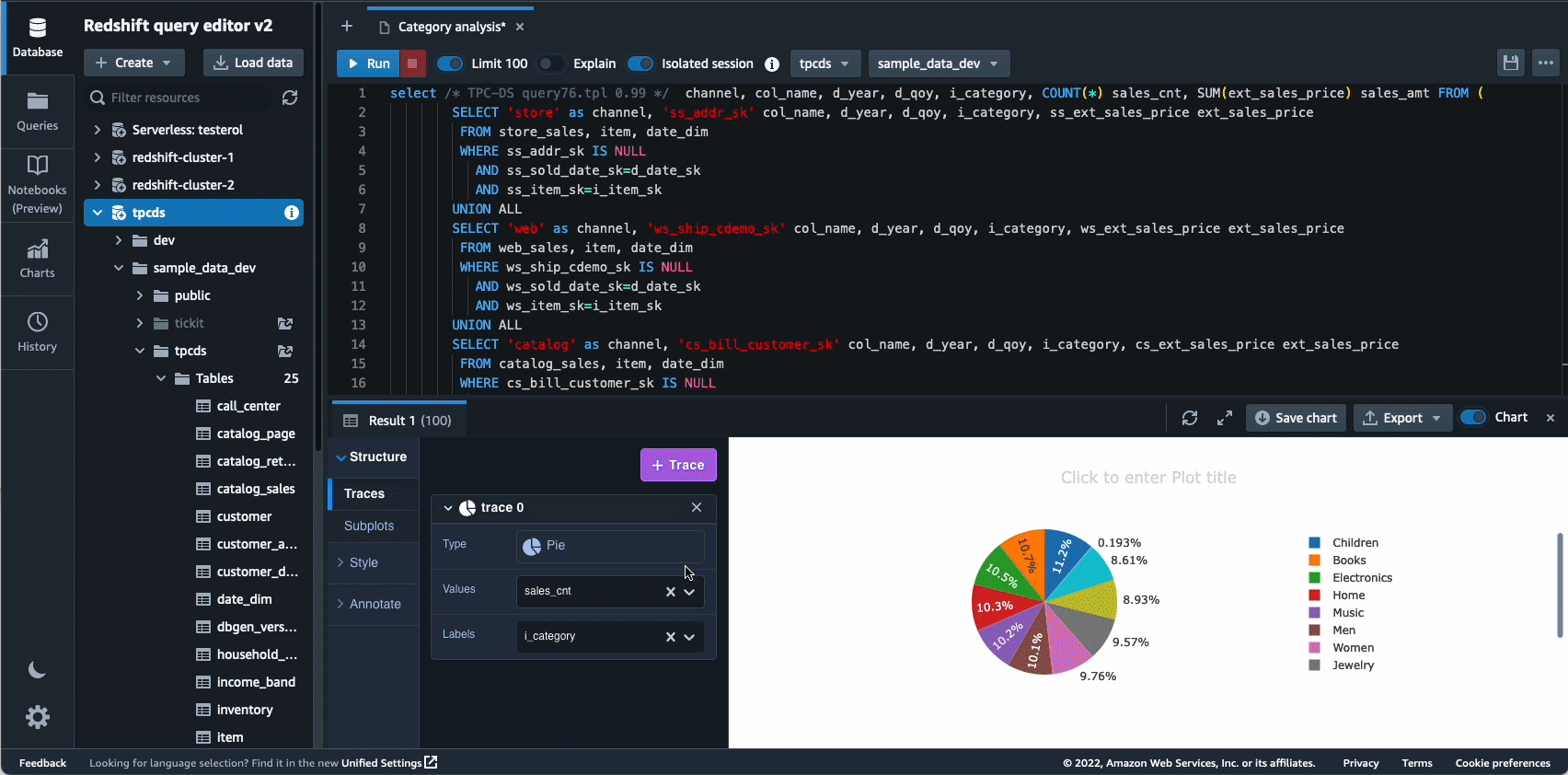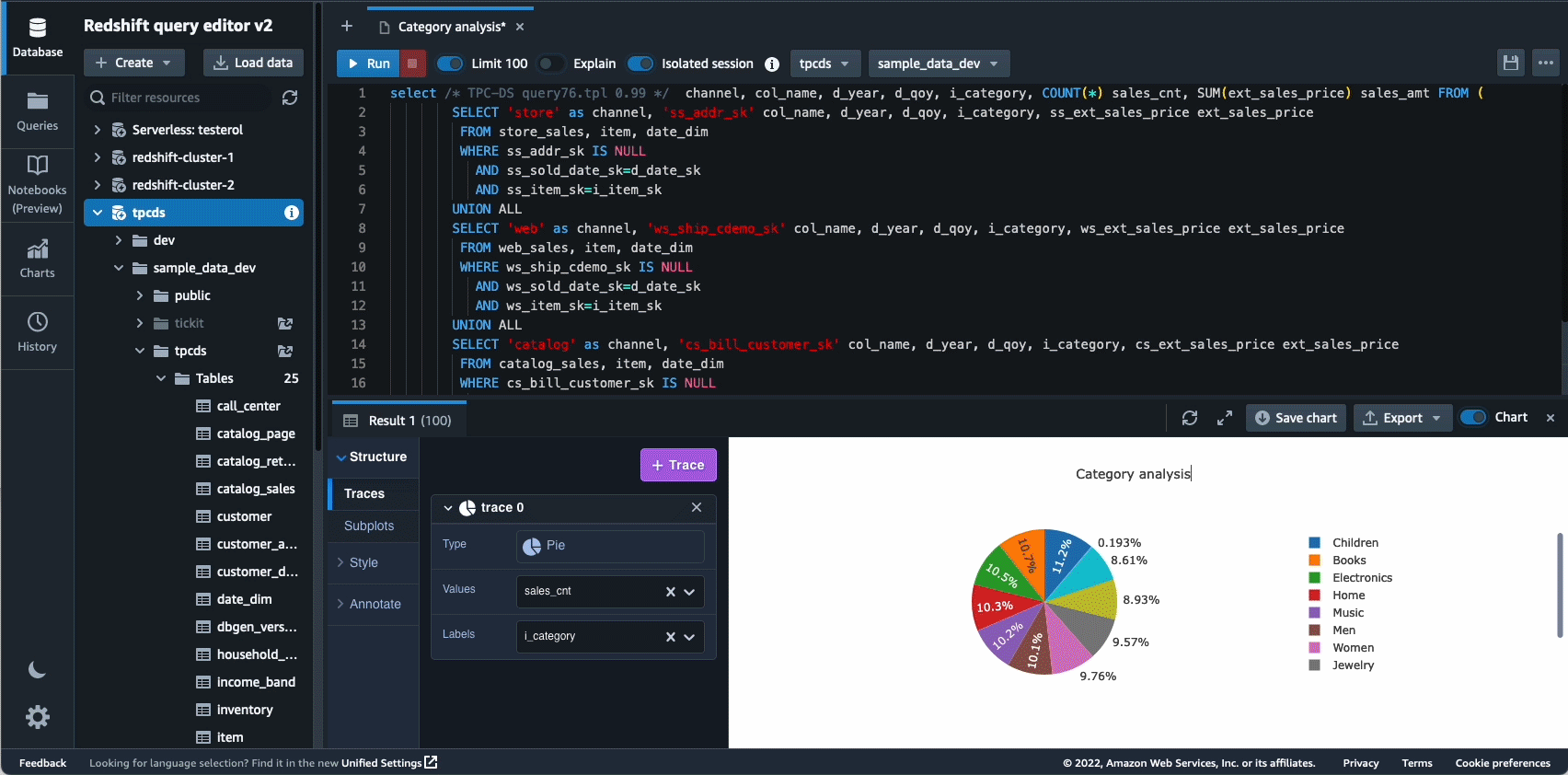
Az autonómia egy másik olyan terület, ahol aktívan dolgozunk az ML-alapú optimalizálás használatán, és az ügyfelek számára öntanuló és önoptimalizáló adattárházat biztosítunk. 2022-ben bejelentettük az általános elérhetőséget Automatizált materializált nézetek (AutoMV-k) a lekérdezések teljesítményének javítása (a teljes futási idő csökkentése) a felhasználói erőfeszítések nélkül azáltal, hogy automatikusan létrehozza és karbantartja a materializált nézeteket. Az AutoMV-k az automatikus frissítéssel, a növekményes frissítéssel és az automatikus lekérdezés-újraírással kombinálva a materializált nézetek esetében a materializált nézeteket karbantartásmentessé tették, így automatikusan gyorsabb teljesítményt nyújtanak. Ezen kívül a automatikus táblázat optimalizálás (ATO) képesség séma optimalizálás és automatikus terheléskezelés Az (auto WLM) terhelésoptimalizálási képesség további fejlesztéseket kapott a jobb lekérdezési teljesítmény érdekében.
Könnyű adatbevitel
Ügyfeleink elmondják, hogy adataikat több adatforráson, például tranzakciós adatbázisokon, adattárházakon, adattókon és big data rendszereken keresztül osztják el. Rugalmasságot akarnak biztosítani ezen adatok kód nélküli/alacsony kódú, nulla ETL adatfolyamokkal való integrálásához, vagy ezeknek az adatoknak a helyben történő elemzéséhez anélkül, hogy áthelyeznék őket. Ügyfeleink elmondják, hogy jelenlegi adatfolyamaik összetettek, manuálisak, merevek és lassúak, ami hiányos, következetlen és elavult adatnézeteket eredményez, ami korlátozza a betekintést. Ügyfeleink jobb utat kértek tőlünk, és örömünkre szolgál, hogy számos új lehetőséget jelentünk be az adatfolyamok egyszerűsítésére és automatizálására.
Amazon Aurora nulla-ETL integráció az Amazon Redshifttel (előzetes verzió) lehetővé teszi közel valós idejű elemzések és ML futtatását petabájt tranzakciós adatokon. Kód nélküli megoldást kínál több tranzakciós adat előállításához Amazon Aurora Az Amazon Redshift adattárházaiban elérhető adatbázisok másodperceken belül az Aurora-ra való írásuk után elérhetők, így nincs szükség összetett adatfolyamok építésére és karbantartására. Ezzel a funkcióval az Aurora ügyfelei hozzáférhetnek az Amazon Redshift képességeihez is, mint például az összetett SQL-elemzés, a beépített ML, az adatmegosztás, valamint a több adattárhoz és adattóhoz való egyesített hozzáférés. Ez a funkció már elérhető előnézetben a következőhöz: Amazon Aurora MySQL-kompatibilis kiadás 3-as verzióját (MySQL 8.0 kompatibilitással), és megteheti kérjen hozzáférést az előnézethez.
Az Amazon Redshift már támogatja automatikus másolás az Amazon S3-ról (előnézet) az adatok betöltésének egyszerűsítésére Amazon egyszerű tárolási szolgáltatás (Amazon S3) az Amazon Redshiftbe. Mostantól folyamatos fájlfeldolgozási szabályokat (másolási feladatokat) állíthat be, amelyek nyomon követhetik Amazon S3 útvonalait, és automatikusan betölthetik az új fájlokat anélkül, hogy további eszközökre vagy egyedi megoldásokra lenne szükség. A másolási feladatok rendszertáblázatokon keresztül figyelhetők, és automatikusan nyomon követik a korábban betöltött fájlokat, és kizárják őket a feldolgozási folyamatból, hogy megakadályozzák az adatok megkettőzését. Ez a funkció már előnézetben is elérhető; kipróbálhatja ezt a funkciót egy új fürt létrehozásával az előnézeti sáv használatával.
Ügyfeleink továbbra is azt mondják nekünk, hogy azonnali, pillanatnyi, valós idejű elemzésre van szükségük, és örömmel jelentjük be, a streaming feldolgozási támogatás általános elérhetősége az Amazon Redshiftben Amazon Kinesis adatfolyamok és a Amazon által kezelt adatfolyam az Apache Kafka számára (Amazon MSK). Ez a funkció kiküszöböli az Amazon S3-ban a streamelési adatok fokozatba állítását az Amazon Redshiftbe való betöltés előtt, így alacsony késleltetést érhet el, másodpercekben mérve, miközben másodpercenként több száz megabájt adatfolyamot tölt be az adattárházba. Használhatja az SQL-t az Amazon Redshiftben több Kinesis adatfolyamhoz vagy MSK-témához való csatlakozáshoz és az onnan származó adatok közvetlen feldolgozásához, automatikusan frissítő, streaming materializált nézetek létrehozásához a folyamok tetején történő transzformációkkal, hogy közvetlenül hozzáférjen a streamelési adatokhoz, és kombinálja a valós idejű adatokat az előzményekkel. adatok a jobb betekintés érdekében. Például az Adobe integrálta az Amazon Redshift adatfolyam-feldolgozást az Adobe Experience Platform részeként, hogy valós időben feldolgozza és elemezze a web és az alkalmazások kattintási és munkameneti adatait különböző alkalmazásokhoz, például CRM-hez és ügyfélszolgálati alkalmazásokhoz.
Ügyfeleink elmondták, hogy egyszerű, azonnali integrációt szeretnének az Amazon Redshift, a BI és az ETL (extract, transform and load) eszközei, valamint az olyan üzleti alkalmazások között, mint a Salesforce és a Marketo. Örömmel jelentjük be, hogy általánosan elérhető Informatica Data Loader az Amazon Redshifthez, amely lehetővé teszi az Informatica Data Loader használatát az Amazon Redshiftbe történő nagysebességű és nagy volumenű adatok ingyenes betöltéséhez. Egyszerűen kiválaszthatja az Informatica Data Loader opciót az Amazon Redshift konzolon. Az Informatica Data Loaderben csatlakozhat olyan forrásokhoz, mint a Salesforce vagy a Marketo, kiválaszthatja az Amazon Redshiftet célként, és megkezdheti az adatok betöltését.
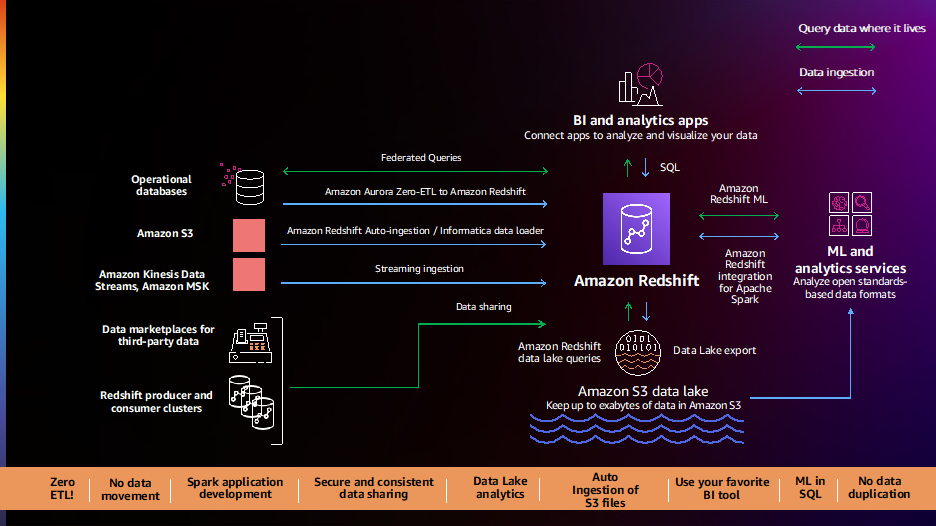
Adatmegosztás és együttműködés
Az ügyfelek továbbra is azt mondják nekünk, hogy szeretnék elemezni saját és harmadik féltől származó összes adatukat, és elérhetővé kívánják tenni ügyfeleik, partnereik és beszállítóik számára a gazdag adatalapú betekintést. 2021-ben új funkciókat vezettünk be, mint pl Adatmegosztás és a AWS adatcsere integráció, hogy könnyebben elemezhesse összes adatát, és megoszthassa azokat szervezetein belül és kívül.
Az Orion nagyszerű példája az adatmegosztást használó ügyfeleknek. Az Orion valós idejű adatszolgáltatási (DaaS) megoldásokat kínál a pénzügyi szolgáltatási ágazat ügyfelei számára, például vagyonkezelési, vagyonkezelési és befektetés-kezelési szolgáltatók számára. Több mint 2,500 adatforrással rendelkeznek, amelyek elsősorban SQL Server adatbázisok, amelyek mind a helyszínen, mind az AWS-ben találhatók. Az adatok Kafka-csatlakozók segítségével streamelhetők az Amazon Redshiftbe. Van egy termelői fürtjük, amely megkapja ezeket az adatokat, majd az adatmegosztást használja az adatok valós idejű megosztására az együttműködés érdekében. Ez egy több bérlős architektúra, amely több ügyfelet szolgál ki. Tekintettel az adatok érzékenységére, az adatmegosztás a munkaterhelés elkülönítésének egyik módja a fürtök között, valamint az adatok biztonságos megosztása a végfelhasználókkal.
2022-ben is folytattuk a beruházásokat ezen a területen, hogy javítsuk a teljesítményt, az irányítást és a fejlesztői termelékenységet új funkciókkal, amelyek megkönnyítik, egyszerűbbé és gyorsabbá teszik az adatok megosztását és együttműködését.
Mivel az ügyfelek nagyszabású adatmegosztási konfigurációkat építenek, egyszerűsített irányítást és biztonságot kértek a megosztott adatokhoz, és mi hozzáadjuk központi hozzáférés-vezérlés az AWS Lake Formation segítségével az Amazon Redshift adatmegosztásokhoz, hogy lehetővé tegye az élő adatok megosztását több Amazon Redshift adattárház között. Ezzel a funkcióval az Amazon Redshift mostantól támogatja az Amazon Redshift adatmegosztások egyszerűsített irányítását AWS-tó formáció egyetlen üvegtáblaként az adatmegosztásokon lévő adatok vagy engedélyek központi kezeléséhez. A Lake Formation API-k és a AWS felügyeleti konzol, és lehetővé teszi az Amazon Redshift adatmegosztások felfedezését és felhasználását más Amazon Redshift adattárházak számára.
Adattudomány és gépi tanulás
Az ügyfelek továbbra is azt mondják nekünk, hogy szeretnék, ha adat- és analitikai rendszereik sokféle kérdés megválaszolásában segítenének nekik, kezdve attól, hogy mi történik a vállalkozásukban (leíró elemzés), a miért történik (diagnosztikai elemzés), és mi fog történni a jövőben. (prediktív elemzés). Az Amazon Redshift olyan funkciókat kínál, mint az összetett SQL-elemzés, a Data Lake-elemzés és Amazon Redshift ML hogy az ügyfelek elemezzék adataikat, és hatékony betekintést nyerjenek. Redshift ML integrálja az Amazon Redshiftet Amazon SageMaker, egy teljesen felügyelt ML-szolgáltatás, amely lehetővé teszi ML-modellek létrehozását, betanítását és üzembe helyezését ismert SQL-parancsok segítségével.
Ügyfeleink az Amazon Redshift és az Apache Spark közötti jobb integrációt is kértek tőlünk, ezért örömmel jelentjük be Amazon Redshift integráció az Apache Sparkhoz hogy az adattárházak könnyen elérhetőek legyenek a Spark-alapú alkalmazások számára. Most az AWS-analitikát és ML-szolgáltatásokat használó fejlesztők, mint pl Amazon EMR, AWS ragasztó, a SageMaker pedig könnyedén építhet Apache Spark alkalmazásokat, amelyek olvasnak az Amazon Redshift adattárházaiból, és írnak oda. Az Amazon EMR és az AWS Glue a Redshift-Spark csatlakozót csomagolja, így könnyedén csatlakozhat adattárházához Spark-alapú alkalmazásaiból. Számos lenyomási funkciót használhat olyan műveletekhez, mint a rendezés, aggregálás, a korlátozás, az összekapcsolás és a skaláris függvények, így csak a releváns adatok kerülnek át az Amazon Redshift adattárházból a fogyasztó Spark alkalmazásba. Használatával az alkalmazásait is biztonságosabbá teheti AWS Identity and Access Management (IAM) hitelesítő adatok az Amazon Redshifthez való csatlakozáshoz.
Biztonságos és megbízható analitika
Az ügyfelek továbbra is azt mondják nekünk, hogy adattárházaik kritikus fontosságú rendszerek, amelyek magas rendelkezésre állást, megbízhatóságot és biztonságot igényelnek. 2022-ben számos új funkciót vezettünk be ezen a területen.
Az Amazon Redshift már támogatja Multi-AZ telepítések (előzetes verzióban) RA3-példányalapú fürtökhöz, amely lehetővé teszi az adattárház egyidejű futtatását több AWS rendelkezésre állási zónában, valamint a folyamatos működést előre nem látható, az egész elérhetőségi zónára kiterjedő hibaforgatókönyvek esetén. A Redshift Serverless számára már elérhető a Multi-AZ támogatás. Az Amazon Redshift Multi-AZ telepítése lehetővé teszi a helyreállítást az Availability Zone meghibásodása esetén felhasználói beavatkozás nélkül. Az Amazon Redshift Multi-AZ adattárház egyetlen, egy végponttal rendelkező adattárházként érhető el, és segít a teljesítmény maximalizálásában azáltal, hogy a munkaterhelés-feldolgozást automatikusan több rendelkezésre állási zónára osztja el. Nincs szükség alkalmazásmódosításokra az üzletmenet folytonosságának megőrzéséhez az előre nem látható leállások idején.
2022-ben olyan funkciókat vezettünk be, mint a szerepalapú hozzáférés-vezérlés, a sorszintű biztonság és az adatmaszkolás (előzetes verzióban), hogy megkönnyítsük a hozzáférés kezelését és annak eldöntését, hogy ki milyen adatokhoz férhet hozzá, beleértve a személyazonosításra alkalmas adatok elhomályosítását (PII). ), mint a hitelkártyaszámok.
Használhatja szerep alapú hozzáférés-vezérlés (RBAC) a végfelhasználó adatokhoz való hozzáférésének szabályozása széles vagy részletes szinten a végfelhasználó munkaköre és engedélyei alapján. Az RBAC segítségével létrehozhat egy szerepkört SQL használatával, részletes engedélyek gyűjteményét adhatja a szerepkörhöz, majd hozzárendelheti a szerepkört a végfelhasználókhoz. A szerepkörök objektumszintű, oszlopszintű és rendszerszintű engedélyeket kaphatnak. Ezenkívül az RBAC bevezeti a beépített rendszerszerepköröket a DBA-k, kezelők, biztonsági rendszergazdák vagy testreszabott szerepkörök számára.
Sorszintű biztonság (RLS) leegyszerűsíti a táblázatok soraihoz való finomszemcsés hozzáférés tervezését és megvalósítását. Az RLS segítségével korlátozhatja a hozzáférést a táblán belüli sorok egy részéhez a felhasználók feladatköre vagy SQL-engedélyei alapján.
Amazon Redshift támogatása dinamikus adatmaszkolás (DDM), amely immár előnézetben is elérhető, lehetővé teszi az Amazon Redshift adattárházában található személyazonosításra alkalmas adatok, például társadalombiztosítási számok, hitelkártyaszámok és telefonszámok védelmének egyszerűsítését. A dinamikus adatmaszkolás segítségével egyszerű SQL-alapú maszkolási házirendekkel szabályozhatja az adatokhoz való hozzáférést, amelyek meghatározzák, hogy az Amazon Redshift hogyan küld vissza érzékeny adatokat a felhasználónak lekérdezéskor. Létrehozhat maszkolási házirendeket a konzisztens, formátummegőrző és visszafordíthatatlan maszkolt adatértékek meghatározásához. Maszkolási szabályzatot alkalmazhat egy táblázat egy adott oszlopára vagy oszloplistájára. Ezenkívül rugalmasan megválaszthatja, hogyan jelenítse meg a maszkolt adatokat. Például teljesen elrejtheti az adatokat, helyettesítheti a részleges valós értékeket helyettesítő karakterekkel, vagy meghatározhatja az adatok maszkolásának saját módját SQL-kifejezések, Python vagy AWS Lambda felhasználó által definiált funkciókat. Ezenkívül más oszlopokon alapuló feltételes maszkolási házirendet is alkalmazhat, amely szelektíven védi a táblázat oszlopadatait egy vagy több különböző oszlopban lévő értékek alapján.
Bejelentettük a fejlesztéseket is audit naplózás, natív integrációval Microsoft Azure Active Directory, és a alapértelmezett IAM-szerepek további régiókban a biztonságkezelés további egyszerűsítése érdekében.
A legjobb ár-teljesítmény elemzése
Ügyfeleink továbbra is azt mondják nekünk, hogy gyors és költséghatékony adattárházakra van szükségük, amelyek bármilyen léptékben nagy teljesítményt nyújtanak, miközben alacsonyan tartják a költségeket. Az 1. naptól kezdve Az Amazon Redshift elindítása 2012-ben, adatvezérelt megközelítést alkalmaztunk, és flottatelemetriával olyan felhőalapú adattárház-szolgáltatást hoztunk létre, amely bármilyen léptékben a legjobb árteljesítményt nyújtja. Az évek során fejlődtünk Az Amazon Redshift architektúrája és olyan funkciókat indított el, mint pl Redshift Managed Storage (RMS) a tárolás és a számítás elkülönítésére, Amazon Red Shift Spectrum Data Lake lekérdezésekhez, automatikus táblázat optimalizálás a fizikai séma optimalizálásához, automatikus terheléskezelés a munkaterhelések rangsorolásához és a megfelelő számítási és memória kiosztásához, fürt átméretezése a számítás és a tárolás függőleges méretezéséhez, és párhuzamossági skálázás hogy dinamikusan skálázzuk ki vagy be. A mi teljesítménymutatókat továbbra is demonstrálja az Amazon Redshift árteljesítményben betöltött vezető szerepét.
2022-ben új funkciókat adtunk hozzá, például az általános elérhetőséget párhuzamossági skálázás írási műveletekhez mint a COPY, INSERT, UPDATE és DELETE, hogy gyakorlatilag korlátlan számú egyidejű felhasználót és lekérdezést támogassanak. Ezenkívül teljesítményjavításokat vezettünk be a karakterlánc-alapú adatfeldolgozáshoz a könnyű, CPU-hatékony, szótárba kódolt karakterlánc-oszlopokon végzett vektorizált vizsgálatokkal, amelyek lehetővé teszik az adatbázismotor számára, hogy közvetlenül tömörített adatok felett működjön.
SQL operátorok támogatását is hozzáadtuk, mint pl MERGE (egyetlen operátor a beillesztésekhez vagy frissítésekhez); CONNECY_BY (hierarchikus lekérdezésekhez); CSOPORTOSÍTÁSI HASZNÁLAT, ROLLUP és KOCKA (többdimenziós jelentéskészítéshez); és 16 MB-ra növelte a SUPER adattípus méretét, hogy megkönnyítse az átállást a régi adattárházakból az Amazon Redshiftbe.
Következtetés
Ügyfeleink továbbra is azt mondják nekünk, hogy az adatok és az elemzések továbbra is elsődleges prioritást élveznek számukra, és az igény, hogy költséghatékonyan több üzleti értéket vonjanak ki adataikból ezekben az időkben, sokkal hangsúlyosabb, mint a múltban bármikor. Az Amazon Redshift, mint felhőadattárháza, lehetővé teszi összetett SQL-analitika futtatását terabájttól petabájtig terjedő strukturált és strukturálatlan adatok méretével és teljesítménnyel, és széles körben elérhetővé teszi a betekintést a népszerű BI- és elemzőeszközökön keresztül.
Noha 40-ben több mint 2022 funkciót vezettünk be, és az innováció üteme folyamatosan gyorsul, ez továbbra is az 1. nap, és várjuk, hogy megtudja, hogyan segíthetnek ezek a funkciók nagyobb értéket felszabadítani szervezetei számára. Meghívjuk Önt, hogy próbálja ki ezeket az új funkciókat, és vegye fel velünk a kapcsolatot az AWS-fiókjával, ha további megjegyzései vannak.
A szerzőről
 Manan Goel az AWS Analytics szolgáltatások piacvezető terméke, beleértve az Amazon Redshiftet az AWS-nél. Több mint 25 éves tapasztalattal rendelkezik, és jól ismeri az adatbázisokat, az adattárházat, az üzleti intelligenciát és az analitikát. Manan a Duke Egyetemen szerzett MBA fokozatot, valamint elektronikai és kommunikációs mérnöki BS diplomát.
Manan Goel az AWS Analytics szolgáltatások piacvezető terméke, beleértve az Amazon Redshiftet az AWS-nél. Több mint 25 éves tapasztalattal rendelkezik, és jól ismeri az adatbázisokat, az adattárházat, az üzleti intelligenciát és az analitikát. Manan a Duke Egyetemen szerzett MBA fokozatot, valamint elektronikai és kommunikációs mérnöki BS diplomát.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- képesség
- Rólunk
- gyorsul
- hozzáférés
- Az adatokhoz való hozzáférés
- igénybe vett
- hozzáférhető
- Fiók
- Elérése
- át
- aktív
- aktívan
- hozzáadott
- mellett
- További
- Ezen kívül
- vályogtégla
- Minden termék
- lehetővé teszi, hogy
- már
- amazon
- Amazon EMR
- Az elemzők
- analitika
- elemez
- elemzése
- és a
- bejelent
- bejelentés
- Másik
- válasz
- Apache
- Apache Spark
- API-k
- Alkalmazás
- alkalmazások
- alkalmaz
- megközelítés
- építészet
- TERÜLET
- területek
- mesterséges
- mesterséges intelligencia
- vagyontárgy
- Vagyonkezelés
- könyvvizsgálat
- Sárgásvörös
- szerző
- auto
- automatizált
- Automatikus
- automatikusan
- elérhetőség
- elérhető
- AWS
- AWS ragasztó
- Égszínkék
- alapján
- alap
- egyre
- előtt
- hogy
- BEST
- Jobb
- között
- Nagy
- Big adatok
- számlázás
- szünet
- széles
- Broadridge
- épít
- Épület
- beépített
- üzleti
- Üzleti alkalmazások
- üzleti folytonosság
- üzleti intelligencia
- képességek
- Kapacitás
- kártya
- eset
- esetek
- Változások
- karakter
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választja
- ügyfél részére
- felhő
- Fürt
- együttműködik
- együttműködés
- gyűjtemény
- Oszlop
- Oszlopok
- össze
- kombinált
- Hozzászólások
- távközlés
- kompatibilitás
- teljesen
- bonyolult
- összetevő
- Kiszámít
- egyidejű
- Csatlakozás
- következetes
- Konzol
- fogyasztott
- folytatódik
- tovább
- tovább
- folyamatos
- ellenőrzés
- költséghatékony
- kiadások
- burkolatok
- teremt
- létrehozása
- Hitelesítő adatok
- hitel
- hitelkártya
- Credits
- CRM
- Jelenlegi
- szokás
- vevő
- Vevőszolgálat
- Ügyfelek
- szabott
- dátum
- Adatcsere
- adattó
- adatfeldolgozás
- adatmegosztás
- adattárház
- adattárházak
- adatalapú
- adatbázis
- adatbázisok
- nap
- mélyebb
- szállít
- bizonyítani
- telepíteni
- bevetés
- Design
- Határozzuk meg
- Fejlesztő
- fejlesztők
- különböző
- közvetlenül
- felfedez
- felfedezett
- megvitatni
- megosztott
- elosztó
- Herceg
- herceg egyetem
- alatt
- dinamikus
- könnyebb
- könnyen
- szerkesztő
- erőfeszítés
- Elektronika
- megszünteti
- megszüntetése
- lehetővé
- lehetővé teszi
- lehetővé téve
- Endpoint
- Motor
- Mérnöki
- Eter (ETH)
- mindenki
- alakult ki
- példa
- csere
- izgatott
- Bontsa
- tapasztalat
- feltárása
- kifejezések
- kivonat
- Kudarc
- ismerős
- GYORS
- gyorsabb
- Funkció
- Jellemzők
- filé
- Fájlok
- pénzügyi
- pénzügyi szolgáltatások
- pénzügyeit
- Találjon
- FLOTTA
- Rugalmasság
- képződés
- Előre
- Ingyenes
- ból ből
- teljesen
- funkciók
- további
- jövő
- általános
- kap
- gif
- Ad
- adott
- ad
- Giving
- üveg
- Piacra megy
- kormányzás
- biztosít
- megadott
- nagy
- történik
- boldog
- Kemény
- tekintettel
- egészségügyi
- hallás
- segít
- segít
- elrejt
- Magas
- történeti
- tart
- Hogyan
- How To
- HTML
- HTTPS
- Több száz
- IAM
- Identitás
- végrehajtás
- javul
- javított
- fejlesztések
- in
- Beleértve
- <p></p>
- ipar
- információ
- Infrastruktúra
- Innováció
- Betétek
- meglátások
- integrálni
- integrált
- integrál
- integráció
- Intelligencia
- beavatkozás
- Bevezetett
- Bemutatja
- befektet
- beruházás
- meghívni
- szigetelés
- IT
- Munka
- Állások
- csatlakozik
- július
- Kafka
- Tart
- tartás
- Kulcs
- Kinesis adatfolyamok
- tó
- nagyarányú
- Késleltetés
- indít
- indított
- vezető
- Vezetés
- tanulás
- Örökség
- szint
- könnyűsúlyú
- LIMIT
- Lista
- él
- élő adatok
- kiszámításának
- rakodó
- betöltés
- néz
- Elő/Utó
- gép
- gépi tanulás
- készült
- fenntartása
- karbantartás
- csinál
- Gyártás
- kezelése
- sikerült
- vezetés
- kézikönyv
- Marketo
- maszk
- Maximize
- Memory design
- vándorol
- ML
- modellek
- modern
- módosítása
- ellenőrizni
- ellenőrzés
- több
- mozgó
- többszörös
- MySQL
- bennszülött
- Szükség
- szükséges
- igények
- Új
- Új funkciók
- szám
- számok
- Ajánlatok
- ONE
- nyitva
- működik
- működés
- Művelet
- operátor
- üzemeltetők
- optimalizálás
- opció
- szervezet
- szervezetek
- Más
- kiesések
- kívül
- saját
- Béke
- csomag
- üvegtábla
- rész
- partnerek
- múlt
- Fizet
- peloton
- teljesítmény
- engedélyek
- Személyesen
- telefon
- fizikai
- PII
- Hely
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- elégedett
- Politikák
- politika
- Népszerű
- állás
- erős
- Prediktív elemzés
- megakadályozása
- Preview
- korábban
- ár
- elsősorban
- Fontossági sorrendet
- prioritás
- folyamat
- feldolgozás
- termelő
- Termékek
- termelékenység
- védelme
- ad
- ellátó
- szolgáltatók
- biztosít
- ellátás
- Piton
- Kérdések
- gyorsan
- hatótávolság
- el
- Olvass
- igazi
- real-time
- valós idejű adatok
- kap
- Meggyógyul
- csökkenteni
- régiók
- megbízhatóság
- megbízható
- maradványok
- cserélni
- jelentést
- Jelentő
- követelmények
- korlátoz
- kapott
- Visszatér
- Kritika
- átírás
- Gazdag
- merev
- Szerep
- szerepek
- felteker
- szabályok
- futás
- futás
- sagemaker
- értékesítési erő
- Skála
- Mérleg
- skálázás
- forgatókönyvek
- Tudomány
- tudósok
- Második
- másodperc
- biztonság
- biztosan
- biztonság
- érzékeny
- Érzékenység
- vagy szerver
- szolgálja
- szolgáltatás
- Szolgáltatások
- ülés
- készlet
- Szettek
- számos
- Megosztás
- megosztott
- megosztás
- előadás
- Egyszerű
- egyszerűsített
- egyszerűsítése
- egyszerűen
- egyszerre
- óta
- egyetlen
- Ülés
- Méret
- lassú
- So
- Közösség
- megoldások
- Megoldások
- néhány
- Források
- Szikra
- különleges
- SQL
- Színpad
- tárolás
- árnyékolók
- Stratégia
- áramlott
- folyó
- patakok
- szerkesztett
- strukturált és strukturálatlan adatok
- ilyen
- szuper
- szállítók
- támogatás
- Támogatja
- rendszer
- Systems
- táblázat
- cél
- csapat
- A
- A jövő
- azok
- harmadik fél
- ezer
- Keresztül
- idő
- alkalommal
- nak nek
- szerszám
- szerszámok
- felső
- Témakörök
- Végösszeg
- érintse
- vágány
- Vonat
- ügyleti
- Átalakítás
- transzformációk
- mindenütt jelenlevő
- váratlan
- egyetemi
- korlátlan
- kinyit
- Frissítések
- Frissítés
- us
- használ
- használó
- Felhasználók
- kihasználva
- érték
- Értékek
- különféle
- változat
- Megnézem
- nézetek
- gyakorlatilag
- Raktár
- Raktározás
- Vagyon
- vagyonkezelés
- háló
- web-alapú
- Mit
- Mi
- ami
- míg
- WHO
- széles
- Széleskörű
- széles körben
- lesz
- belül
- nélkül
- Munka
- dolgozott
- dolgozó
- világszerte
- ír
- írott
- év
- év
- A te
- zephyrnet
- zónák