Kép jcomp on Freepik
Az idősorok egy egyedülálló adatkészlet az adattudományi területen. Az adatokat idő-gyakoriságban rögzítjük (pl. napi, heti, havi stb.), és minden megfigyelés a másikhoz kapcsolódik. Az idősorok adatai értékesek, ha elemezni szeretné, hogy mi történik az adatokkal az idő múlásával, és jövőbeli előrejelzéseket szeretne készíteni.
Az idősor-előrejelzés egy olyan módszer, amellyel jövőbeli előrejelzéseket készíthetünk előzménysoros adatok alapján. Az idősoros előrejelzésre számos statisztikai módszer létezik, mint pl ARIMA or Exponenciális simítás.
Az idősoros előrejelzéssel gyakran találkozunk az üzletben, ezért hasznos az adatkutató számára, ha tudja, hogyan kell idősor-modellt kidolgozni. Ebben a cikkben megtudjuk, hogyan lehet idősorokat előre jelezni két népszerű Python-csomag segítségével; statsmodels és Prophet. Menjünk bele.
A statisztikai modellek A Python csomag egy nyílt forráskódú csomag, amely különféle statisztikai modelleket kínál, beleértve az idősoros előrejelzési modellt is. Próbáljuk ki a csomagot egy példaadatkészlettel. Ez a cikk a Digitális valuta idősor adatok a Kaggle-től (CC0: Public Domain).
Tisztítsuk meg az adatokat, és nézzük meg a rendelkezésünkre álló adatkészletet.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
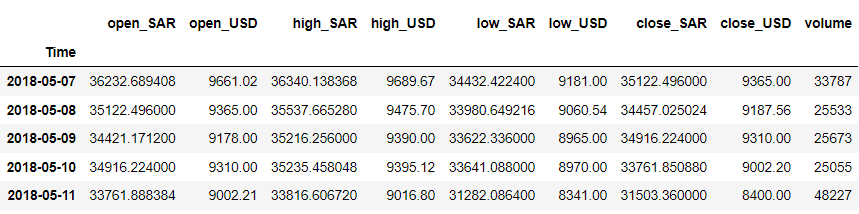
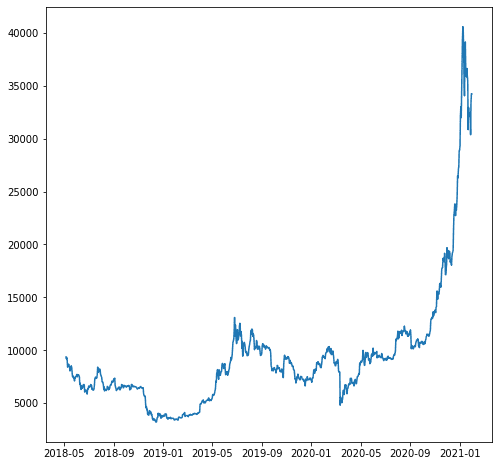
Példánkban tegyük fel, hogy a 'close_USD' változót szeretnénk előre jelezni. Nézzük meg, hogyan alakul az adatminta idővel.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
A fenti adataink alapján építsük fel az előrejelzési modellt. Modellezés előtt osszuk fel az adatokat vonat- és tesztadatokra.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
Nem véletlenszerűen osztjuk fel az adatokat, mert idősoros adatokról van szó, és meg kell őriznünk a sorrendet. Ehelyett arra törekszünk, hogy a vonatadatok a korábbiakból, a tesztadatok pedig a legfrissebb adatokból származzanak.
Használjunk statisztikai modelleket előrejelzési modell létrehozásához. A statisztikai modell sok idősoros modell API-t biztosít, de mi az ARIMA modellt használnánk példaként.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
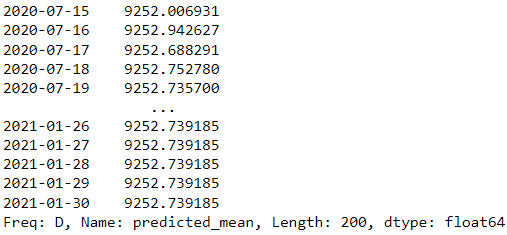
A fenti példánkban a statsmodelsből származó ARIMA modellt használjuk előrejelzési modellként, és megpróbáljuk megjósolni a következő 200 napot.
Jó a modell eredménye? Próbáljuk meg értékelni őket. Az idősor-modell értékelése általában vizualizációs grafikont használ a tényleges és az előrejelzés összehasonlítására olyan regressziós mérőszámokkal, mint az átlagos abszolút hiba (MAE), a négyzetgyökér hiba (RMSE) és a MAPE (átlagos abszolút százalékos hiba).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
A fenti pontszám jól néz ki, de lássuk, milyen, amikor megjelenítjük őket.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
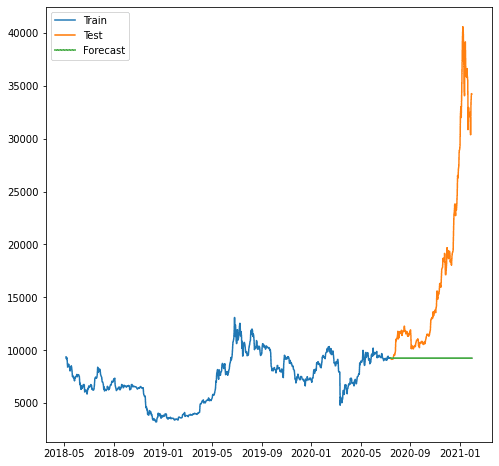
Amint látjuk, az előrejelzés rosszabb volt, mivel modellünk nem tudja előre jelezni a növekvő tendenciát. Az általunk használt ARIMA modell túl egyszerűnek tűnik az előrejelzéshez.
Talán jobb, ha megpróbálunk egy másik modellt használni a statsmodeleken kívül. Próbáljuk ki a híres prófétacsomagot a Facebookról.
próféta egy idősoros előrejelzési modellcsomag, amely szezonális hatású adatokon működik a legjobban. A Prophet robusztus előrejelzési modellnek is számított, mivel képes volt kezelni a hiányzó adatokat és a kiugró értékeket.
Próbáljuk ki a Prophet csomagot. Először is telepítenünk kell a csomagot.
pip install prophet
Ezt követően fel kell készítenünk adatkészletünket az előrejelzési modell képzéshez. A Prófétának van egy speciális követelménye: az időoszlopot „ds”-ként, az értéket „y”-ként kell elnevezni.
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
Adataink készenlétével próbáljunk meg előrejelzést készíteni az adatok alapján.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
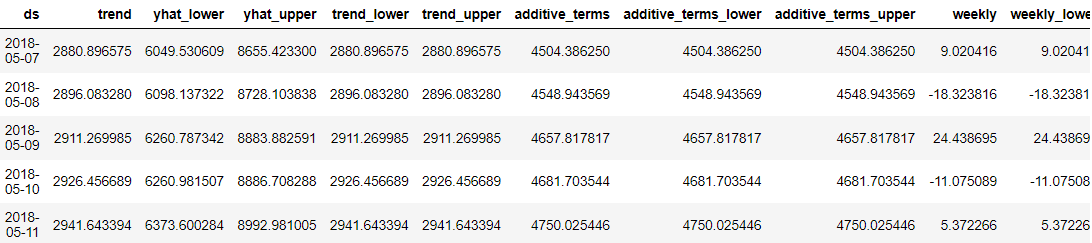
A Prófétában az volt a nagyszerű, hogy minden előrejelzési adatpont részletezett volt, hogy mi, felhasználók megértsük. Az eredményt azonban csak az adatokból nehéz megérteni. Tehát megpróbálhatnánk elképzelni őket a Prophet segítségével.
model.plot(predictions)
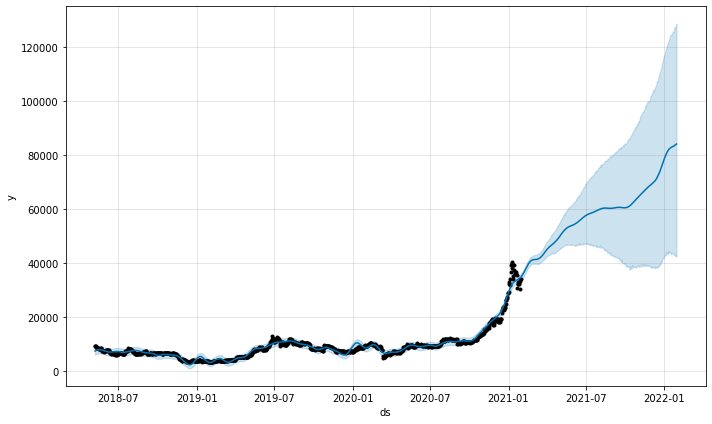
A modellből származó előrejelzések ábrázolási függvényei megmutatják, mennyire voltak megbízhatóak az előrejelzések. A fenti ábrából láthatjuk, hogy az előrejelzés emelkedő tendenciát mutat, de annál nagyobb a bizonytalanság, minél hosszabbak az előrejelzések.
Az előrejelzési komponensek vizsgálata is lehetséges a következő függvénnyel.
model.plot_components(predictions)
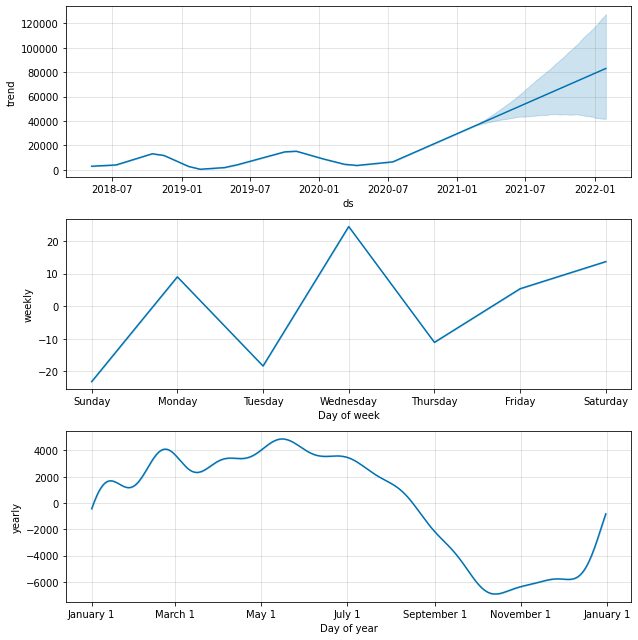
Alapértelmezés szerint az adattrendet éves és heti szezonalitással kapjuk meg. Ez egy jó módja annak, hogy elmagyarázzuk, mi történik az adatainkkal.
Lehetséges lenne a Prophet modellt is értékelni? Teljesen. A Prophet tartalmaz egy diagnosztikai mérést, amelyet használhatunk: idősorok keresztellenőrzése. A módszer az előzményadatok egy részét használja, és minden alkalommal a vágási pontig adatok felhasználásával illeszkedik a modellhez. Ezután a próféta összehasonlítja a jóslatokat a ténylegesekkel. Próbáljuk meg használni a kódot.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
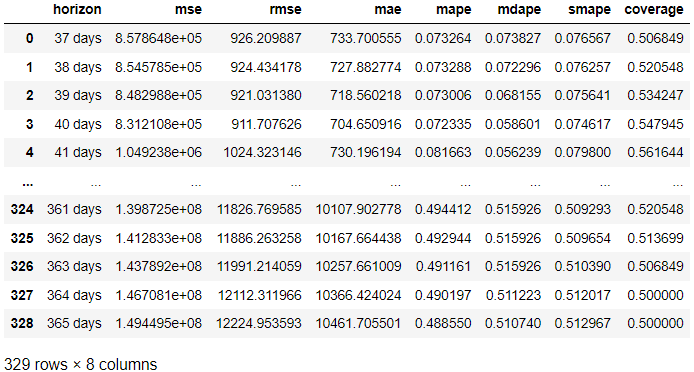
A fenti eredményben minden előrejelzési napon a tényleges eredményből vettük az értékelés eredményét az előrejelzéshez képest. Az eredmény az alábbi kóddal is megjeleníthető.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
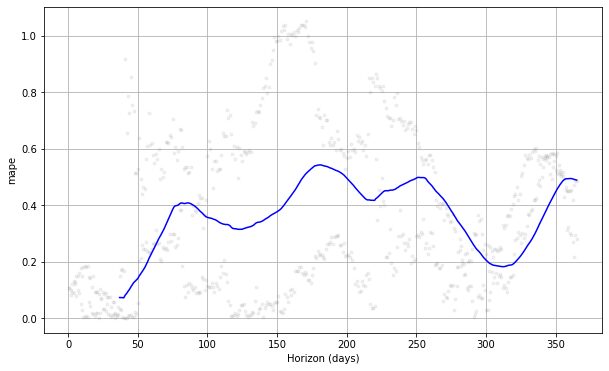
Ha látjuk a fenti ábrát, láthatjuk, hogy az előrejelzési hiba változott a napokban, és egyes pontokon 50%-os hibát is elérhet. Ily módon érdemes lehet tovább finomítani a modellen a hiba kijavításához. Ellenőrizheti a dokumentáció további feltáráshoz.
Az előrejelzés az üzleti életben előforduló gyakori esetek egyike. Az előrejelzési modell fejlesztésének egyik egyszerű módja a statsforecast és a Prophet Python csomagok használata. Ebben a cikkben megtanuljuk, hogyan hozhat létre előrejelzési modellt, és hogyan értékelheti azokat a statsforecast és a Prophet segítségével.
Cornelius Yudha Wijaya adattudományi asszisztens menedzser és adatíró. Miközben teljes munkaidőben dolgozik az Allianz Indonesia-nál, szeret Python és Data tippeket megosztani a közösségi médián és az írási médián keresztül.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :is
- $ UP
- 1
- 11
- 7
- 8
- 9
- a
- Rólunk
- felett
- Abszolút
- teljesen
- Elérése
- szerzett
- Allianz
- elemez
- és a
- Másik
- API-k
- VANNAK
- cikkben
- AS
- Helyettes
- At
- alapján
- BE
- mert
- előtt
- előnyös
- BEST
- Jobb
- között
- épít
- üzleti
- by
- számít
- TUD
- esetek
- CC0
- ellenőrizze
- kód
- Oszlop
- Oszlopok
- Közös
- összehasonlítani
- képest
- alkatrészek
- magabiztos
- figyelembe vett
- tudott
- lefedettség
- teremt
- Valuta
- napi
- dátum
- adat-tudomány
- adattudós
- találka
- nap
- Nap
- dc
- alapértelmezett
- részletes
- Fejleszt
- domain
- ne
- e
- minden
- Korábban
- hatások
- hiba
- stb.
- értékelni
- értékelés
- Minden
- példa
- Magyarázza
- kutatás
- híres
- mező
- végén
- vezetéknév
- megfelelő
- Rögzít
- következő
- A
- Előrejelzés
- ból ből
- funkció
- további
- jövő
- kap
- GitHub
- jó
- grafikon
- nagy
- fogantyú
- megtörténik
- Kemény
- Legyen
- történeti
- horizont
- Hogyan
- How To
- azonban
- HTML
- HTTPS
- importál
- in
- magában foglalja a
- Beleértve
- <p></p>
- növekvő
- index
- Indonézia
- kezdetben
- telepíteni
- helyette
- IT
- jpg
- KDnuggets
- Ismer
- legutolsó
- TANUL
- hosszabb
- néz
- MEGJELENÉS
- csinál
- menedzser
- sok
- matplotlib
- Média
- módszer
- mód
- Metrics
- esetleg
- hiányzó
- modell
- modellezés
- modellek
- havi
- Nevezett
- Szükség
- igények
- következő
- számtalan
- szerez
- of
- felajánlás
- on
- ONE
- nyílt forráskódú
- érdekében
- Más
- kívül
- csomag
- csomagok
- pandák
- paraméterek
- rész
- Mintás
- százalék
- teljesít
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- pont
- Népszerű
- lehetséges
- előre
- előrejelzés
- Tippek
- Készít
- ad
- biztosít
- nyilvános
- Piton
- kész
- feljegyzett
- regresszió
- összefüggő
- követelmény
- eredményez
- Eredmények
- erős
- gyökér
- Tudomány
- Tudós
- Úgy tűnik,
- Series of
- készlet
- Megosztás
- Egyszerű
- So
- Közösség
- Közösségi média
- néhány
- különleges
- osztott
- négyzet
- statisztikai
- ilyen
- Vesz
- teszt
- hogy
- A
- Őket
- idő
- Idősorok
- tippek
- nak nek
- is
- Vonat
- Képzések
- tendencia
- Bizonytalanság
- megért
- egyedi
- NÉVTELEN
- emelkedő
- us
- használ
- Felhasználók
- rendszerint
- Értékes
- érték
- különféle
- keresztül
- megjelenítés
- Út..
- heti
- JÓL
- Mit
- míg
- Wikipedia
- lesz
- val vel
- belül
- dolgozó
- művek
- lenne
- író
- írás
- A te
- zephyrnet