A kép szerzője
Sok kurzus és forrás áll rendelkezésre a gépi tanulásról és az adattudományról, de nagyon kevés az adatkezelésről. Ez felvet néhány kérdést. Nehéz terep ez? Alacsony fizetést kínál? Nem tekinthető olyan izgalmasnak, mint a többi technológiai szerep? A valóság azonban az, hogy sok vállalat aktívan keresi az adatmérnöki tehetségeket, és jelentős, néha 200,000 XNUMX USD feletti fizetést kínál. Az adatmérnökök kulcsfontosságú szerepet játszanak az adatplatformok építészeiként, olyan alaprendszerek tervezésében és felépítésében, amelyek lehetővé teszik az adattudósok és a gépi tanulási szakértők hatékony működését.
Ennek az iparági szakadéknak a felszámolására a DataTalkClub transzformatív és ingyenes bootcamp-et vezetett be, „Data Engineering Zoomcamp“. Ez a kurzus célja, hogy a pályaváltásra vágyó kezdőket vagy szakembereket felhatalmazza, alapvető készségekkel és gyakorlati tapasztalattal az adatmérnöki területen.
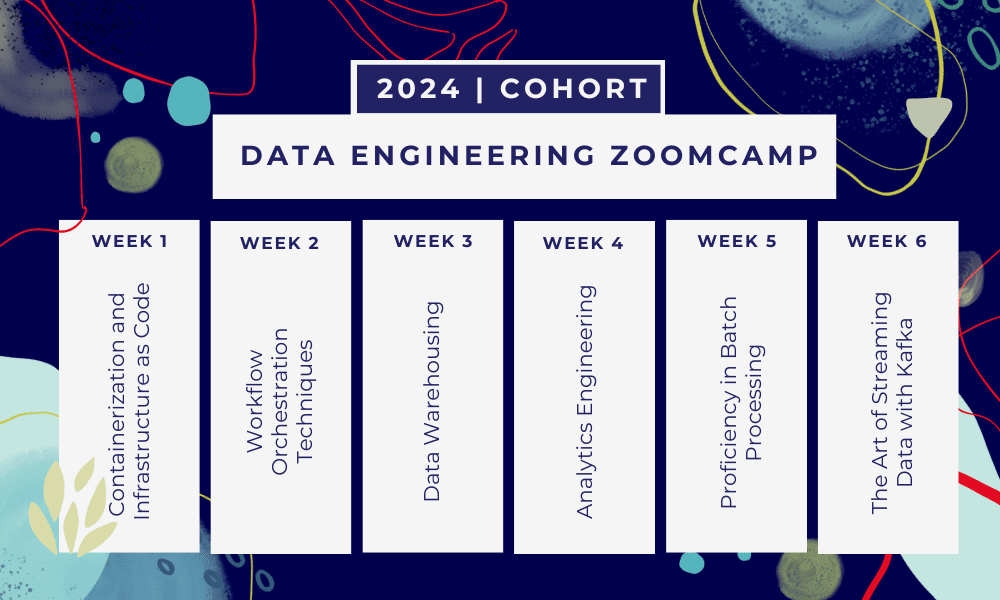
Ez egy 6 hetes bootcamp ahol több tanfolyamon, olvasmányokon, műhelyeken és projekteken keresztül tanulhat. Minden modul végén házi feladatot kap a tanultak gyakorlásához.
- 1 hét: Bevezetés a GCP, a Docker, a Postgres, a Terraform és a környezetbeállításokba.
- 2 hét: Munkafolyamat hangszerelése a Mage segítségével.
- 3 hét: Adattárház a BigQuery segítségével és gépi tanulás a BigQuery segítségével.
- 4 hét: Analitikus mérnök a dbt-vel, a Google Data Studio-val és a Metabase-val.
- 5 hét: Kötegelt feldolgozás Spark segítségével.
- 6 hét: Streamelés Kafkával.
Kép DataTalksClub/data-engineering-zoomcamp
A tananyag 6 modult, 2 workshopot és egy projektet tartalmaz, amely mindent tartalmaz, ami a professzionális adatmérnökké váláshoz szükséges.
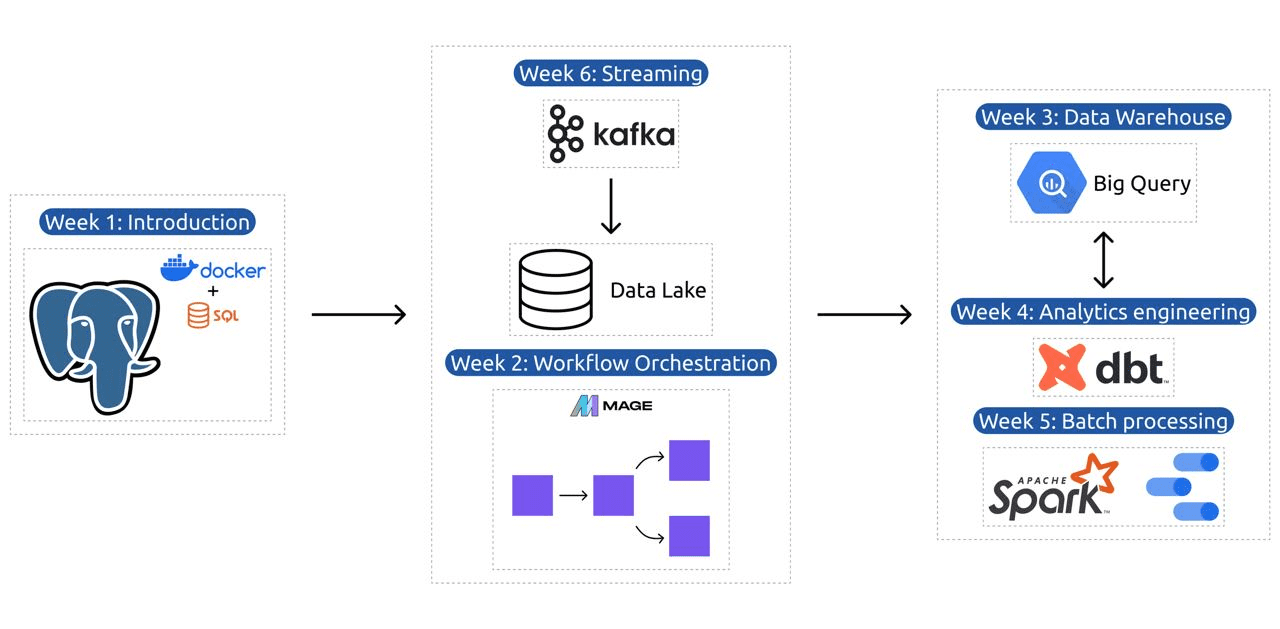
1. modul: A konténerezés és az infrastruktúra kódként való elsajátítása
Ebben a modulban megismerheti a Dockert és a Postgres-t, kezdve az alapokkal, és továbbhaladva az adatfolyamatok létrehozásáról, a Postgres Dockerrel való futtatásáról és sok másról szóló részletes oktatóanyagokon keresztül.
A modul olyan alapvető eszközöket is lefed, mint a pgAdmin, a Docker-compose és az SQL-frissítő témakörök, opcionális tartalommal a Docker-hálózatról, valamint egy speciális áttekintést a Windows alrendszer Linux-felhasználói számára. Végül a kurzus bemutatja a GCP-t és a Terraformot, holisztikus megértést biztosítva a konténerezésről és az infrastruktúráról mint kódról, amely elengedhetetlen a modern felhőalapú környezetekhez.
2. modul: Munkafolyamat-hangszerelési technikák
A modul mélyreható felfedezést kínál a Mage-ről, egy innovatív nyílt forráskódú hibrid keretrendszerről az adatok átalakítására és integrációjára. Ez a modul a munkafolyamatok irányításának alapjaival kezdődik, és a Mage gyakorlati gyakorlataiig tart, beleértve a Dockeren keresztüli beállítást és az ETL-folyamatok építését az API-tól a Postgres-ig és a Google Cloud Storage-ig (GCS), majd a BigQuery-ig.
A modul videókból, forrásokból és gyakorlati feladatokból álló keveréke átfogó tanulási élményt biztosít, felvértezi a tanulókat a kifinomult adatmunkafolyamatok Mage használatával történő kezeléséhez.
1. workshop: Adatfeldolgozási stratégiák
Az első workshopon elsajátítja a hatékony adatbeviteli folyamatok kiépítését. A műhely olyan alapvető készségekre összpontosít, mint az adatok kinyerése API-kból és fájlokból, az adatok normalizálása és betöltése, valamint a növekményes betöltési technikák. A workshop elvégzése után képes lesz hatékony adatfolyamokat létrehozni, mint egy vezető adatmérnök.
3. modul: Adattárház
A modul az adattárolás és -elemzés mélyreható feltárása, a BigQuery használatával végzett adattárházra összpontosítva. Lefedi az olyan kulcsfontosságú fogalmakat, mint a particionálás és a fürtözés, és belemerül a BigQuery bevált gyakorlataiba. A modul haladja meg a haladó témákat, különösen a Machine Learning (ML) integrációját a BigQuery-vel, kiemeli az SQL for ML használatát, és erőforrásokat biztosít a hiperparaméterek hangolásához, a funkciók előfeldolgozásához és a modellek telepítéséhez.
4. modul: Analytics tervezés
Az analitikai mérnöki modul egy projekt felépítésére összpontosít a dbt (Data Build Tool) segítségével egy meglévő adattárházzal, akár BigQuery-vel, akár PostgreSQL-lel.
A modul lefedi a dbt felhőben és helyi környezetben történő beállítását, az analitikai mérnöki koncepciók, az ETL kontra ELT és az adatmodellezés bevezetését. Lefedi a fejlett dbt-szolgáltatásokat is, mint például a növekményes modellek, címkék, horgok és pillanatképek.
Végül a modul bemutatja az átalakított adatok megjelenítésének technikáit olyan eszközökkel, mint a Google Data Studio és a Metabase, valamint erőforrásokat biztosít a hibaelhárításhoz és a hatékony adatbetöltéshez.
5. modul: Jártasság a kötegelt feldolgozásban
Ez a modul az Apache Spark használatával végzett kötegelt feldolgozást fedi le, kezdve a kötegelt feldolgozás és a Spark bevezetésével, valamint a Windows, Linux és MacOS telepítési utasításaival.
Ez magában foglalja a Spark SQL és a DataFrames felfedezését, az adatok előkészítését, az SQL-műveletek végrehajtását és a Spark belső tulajdonságainak megértését. Végül a Spark felhőben történő futtatásával és a Spark BigQueryvel való integrálásával zárul.
6. modul: Az adatfolyam művészete Kafkával
A modul az adatfolyam-feldolgozási koncepciók bemutatásával kezdődik, majd a Kafka alapos feltárását követi, beleértve annak alapjait, a Confluent Clouddal való integrációt, valamint a gyártókat és fogyasztókat bevonó gyakorlati alkalmazásokat.
A modul a Kafka konfigurációját és adatfolyamait is lefedi, olyan témákkal foglalkozva, mint a stream csatlakozások, a tesztelés, az ablakozás és a Kafka ksqldb & Connect használata. Ezenkívül kiterjeszti a hangsúlyt a Python és a JVM környezetekre, beleértve a Faust for Python adatfolyam-feldolgozást, a Pyspark – Structured Streaming és a Scala példákat a Kafka Streams számára.
Workshop 2: Stream-feldolgozás SQL-lel
Megtanulja feldolgozni és kezelni a streamelési adatokat a RisingWave segítségével, amely költséghatékony megoldást kínál PostgreSQL-stílusú tapasztalattal az adatfolyam-feldolgozó alkalmazások fejlesztéséhez.
Projekt: Real-World Data Engineering Application
Ennek a projektnek az a célja, hogy megvalósítsuk az ezen a tanfolyamon tanult összes koncepciót egy végpontok közötti adatfolyam felépítéséhez. Létrehoz egy két csempéből álló irányítópultot egy adatkészlet kiválasztásával, az adatok feldolgozására szolgáló folyamat felépítésével és egy adattóban való tárolásával, egy folyamat létrehozásával a feldolgozott adatok adattóból adattárházba átviteléhez, átalakításával. az adattárházban lévő adatok és előkészítés a műszerfalhoz, végül pedig egy műszerfal felépítése az adatok vizuális megjelenítéséhez.
2024-es kohorsz részletei
- Bejegyzés: Regisztráljon most
- Kezdés dátuma: 15. január 2024., 17:00 CET
- Saját tempójú tanulás irányított támogatással
- Kohorszmappa házi feladatokkal és határidőkkel
- interaktív Slack Community a társaktól való tanuláshoz
Előfeltételek
- Alapvető kódolási és parancssori ismeretek
- Alapozás SQL-ben
- Python: előnyös, de nem kötelező
Szakértő oktatók vezetik az utazást
- Ankush Khanna
- Victoria Perez Mola
- Alekszej Grigorev
- -- Matt Palmer
- Luis Oliveira
- Michael Shoemaker
Csatlakozzon 2024-es csoportunkhoz, és kezdjen el tanulni egy csodálatos adatmérnöki közösséggel. A szakértők által vezetett képzéssel, gyakorlati tapasztalattal és az iparág igényeire szabott tananyaggal ez a kezdőtábor nemcsak a szükséges készségekkel ruházza fel, hanem egy jövedelmező és keresett karrierút élvonalába is helyezi. Jelentkezzen még ma, és váltsa valóra vágyait!
Abid Ali Awan (@1abidaliawan) okleveles adattudós szakember, aki szereti a gépi tanulási modellek építését. Jelenleg tartalomkészítéssel foglalkozik, és technikai blogokat ír a gépi tanulásról és az adattudományi technológiákról. Abid mesterdiplomát szerzett technológiamenedzsmentből és alapdiplomát távközlési mérnökből. Elképzelése az, hogy egy MI-terméket hozzon létre egy gráf neurális hálózat segítségével a mentális betegséggel küzdő diákok számára.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :van
- :is
- :nem
- :ahol
- $ UP
- 000
- 1
- 15%
- 17
- 2024
- a
- Képes
- Rólunk
- aktívan
- Ezen kívül
- címzés
- fejlett
- továbbjutó
- Után
- AI
- Minden termék
- mentén
- Is
- elképesztő
- an
- elemzés
- Analitikai
- analitika
- és a
- és az infrastruktúra
- Apache
- Apache Spark
- api
- API-k
- alkalmazások
- építészek
- VANNAK
- Művészet
- AS
- At
- elérhető
- Alapjai
- BE
- válik
- egyre
- Kezdők
- előnyös
- BEST
- legjobb gyakorlatok
- bigquery
- Keverék
- blogok
- mindkét
- épít
- Épület
- de
- by
- Karrier
- karrier
- Vizsgázott
- felhő
- felhő tárolási
- csoportosítás
- kód
- Kódolás
- kohort
- közösség
- Companies
- kitöltésével
- átfogó
- fogalmak
- arra a következtetésre jut
- Configuration
- Összefolyó
- Csatlakozás
- figyelembe vett
- Összeáll
- konstrukció
- Fogyasztók
- tartalmaz
- tartalom
- tartalomalkotás
- tanfolyam
- tanfolyamok
- burkolatok
- teremt
- létrehozása
- teremtés
- kritikus
- Jelenleg
- tanterv
- műszerfal
- dátum
- adatmérnök
- adattó
- adat-tudomány
- adattudós
- adattárolás
- adattárház
- találka
- Fok
- bevetés
- tervezett
- tervezés
- részletes
- nehéz
- Dokkmunkás
- minden
- hatékonyan
- hatékony
- bármelyik
- képessé
- lehetővé
- végén
- végtől végig
- mérnök
- Mérnöki
- Mérnökök
- felvesz
- biztosítja
- Környezet
- környezetek
- alapvető
- Eter (ETH)
- minden
- példák
- izgalmas
- létező
- tapasztalat
- szakértők
- kutatás
- Feltárása
- nyúlik
- Funkció
- Jellemzők
- Featuring
- kevés
- mező
- Fájlok
- Végül
- vezetéknév
- Összpontosít
- koncentrál
- összpontosítás
- követ
- A
- Forefront
- Alapítványi
- Keretrendszer
- Ingyenes
- ból ből
- funkció
- alapjai
- rés
- GCP
- adott
- A Google Cloud
- grafikon
- Graph Neurális Hálózat
- vezetett
- hands-on
- Legyen
- he
- kiemelve
- övé
- tart
- holisztikus
- házi feladat
- horgok
- azonban
- HTTPS
- hibrid
- Hiperparaméter hangolás
- betegség
- végre
- in
- mélyreható
- magában foglalja a
- Beleértve
- járulékos
- ipar
- Infrastruktúra
- újító
- telepítés
- utasítás
- integrálása
- integráció
- bele
- Bevezetett
- Bemutatja
- bevezetéséről
- Bevezetés
- bemutatkozás
- bevonásával
- IT
- ITS
- január
- csatlakozik
- Kafka
- KDnuggets
- Kulcs
- tó
- vezető
- TANUL
- tanult
- tanulók
- tanulás
- mint
- vonal
- linux
- betöltés
- helyi
- keres
- szeret
- Elő/Utó
- jövedelmező
- gép
- gépi tanulás
- MacOS
- kezelése
- vezetés
- kötelező
- sok
- mester
- mastering
- anyagok
- szellemi
- Mentális betegség
- ML
- modell
- modellezés
- modellek
- modern
- modul
- Modulok
- több
- többszörös
- elengedhetetlen
- Szükség
- szükséges
- igények
- hálózat
- hálózatba
- ideg-
- neurális hálózat
- célkitűzés
- of
- felajánlás
- Ajánlatok
- on
- csak
- nyílt forráskódú
- Művelet
- or
- hangszerelés
- Más
- mi
- Zarándok
- különösen
- ösvény
- Fizet
- egyenrangú
- előadó
- csővezeték
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- játszani
- pozíciók
- postgresql
- Gyakorlati
- Gyakorlati alkalmazások
- gyakorlat
- gyakorlat
- előkészítése
- be
- folyamat
- feldolgozott
- feldolgozás
- Termelők
- Termékek
- szakmai
- tehetséges alkalmazottal
- halad
- program
- projektek
- biztosít
- amely
- Piton
- Kérdések
- emelés
- Olvasás
- való Világ
- Valóság
- Tudástár
- Szerep
- szerepek
- futás
- s
- fizetések
- Scala
- Tudomány
- Tudós
- tudósok
- keres
- kiválasztása
- idősebb
- beállítás
- felépítés
- készségek
- laza
- megoldások
- néhány
- néha
- kifinomult
- Szikra
- speciális
- SQL
- kezdet
- Kezdve
- tárolás
- folyam
- folyó
- patakok
- szerkesztett
- küzd
- Diákok
- stúdió
- lényeges
- ilyen
- támogatás
- kapcsoló
- Systems
- szabott
- Tehetség
- feladatok
- tech
- Műszaki
- technikák
- Technologies
- Technológia
- távközlés
- Terraform
- Tesztelés
- hogy
- A
- Az alapok
- akkor
- ezt
- Keresztül
- nak nek
- Ma
- szerszám
- szerszámok
- Témakörök
- Képzések
- Átadó
- Átalakítás
- Átalakítás
- átalakító
- át
- transzformáló
- oktatóanyagok
- kettő
- megértés
- USAdollár
- használ
- Felhasználók
- segítségével
- Ve
- nagyon
- keresztül
- Videók
- látomás
- előző
- vs
- Raktár
- Raktározás
- we
- Mit
- ami
- WHO
- lesz
- ablakok
- val vel
- munkafolyamat
- munkafolyamatok
- műhely
- Műhelyek
- írás
- te
- A te
- zephyrnet










