Amazon SageMaker Studio teljes körűen felügyelt megoldást kínál az adattudósok számára a gépi tanulási (ML) modellek interaktív felépítéséhez, betanításához és üzembe helyezéséhez. Amazon SageMaker notebook munkák lehetővé teszi az adatkutatók számára, hogy igény szerint vagy ütemezetten futtathassák notebookjaikat néhány kattintással a SageMaker Studio alkalmazásban. Ezzel az indítással programozottan futtathatja a notebookokat feladatként a által biztosított API-k használatával Amazon SageMaker csővezetékek, az ML munkafolyamat hangszerelési funkciója Amazon SageMaker. Ezenkívül ezekkel az API-kkal többlépcsős ML munkafolyamatot hozhat létre több függő jegyzetfüzettel.
A SageMaker Pipelines egy natív munkafolyamat-irányítási eszköz ML-folyamatok készítéséhez, amelyek kihasználják a közvetlen SageMaker integrációt. Minden SageMaker csővezeték a következőkből áll lépések, amelyek olyan egyedi feladatoknak felelnek meg, mint a feldolgozás, képzés vagy adatfeldolgozás Amazon EMR. A SageMaker notebook feladatok már beépített lépéstípusként is elérhetők a SageMaker folyamatokban. Ezzel a notebook-feladat-lépéssel egyszerűen futtathatja a notebookokat néhány sornyi kóddal, a következővel Amazon SageMaker Python SDK. Ezenkívül több függő jegyzetfüzet összefűzésével munkafolyamatot hozhat létre irányított aciklikus grafikonok (DAG) formájában. Ezután futtathatja ezeket a notebook-feladatokat vagy DAG-kat, és kezelheti és megjelenítheti őket a SageMaker Studio segítségével.
Az adattudósok jelenleg a SageMaker Studiót használják Jupyter notebookjaik interaktív fejlesztésére, majd a SageMaker notebook jobok segítségével ütemezett jobokként futtatják ezeket a notebookokat. Ezek a jobok azonnal vagy ismétlődő ütemezés szerint futtathatók, anélkül, hogy az adatmunkásoknak Python-modulokká kell átalakítaniuk a kódot. Néhány gyakori felhasználási eset ehhez:
- Hosszú, futó notebookok futása a háttérben
- Rendszeresen futó modellkövetkeztetés jelentések generálásához
- Növekedés a kis mintaadatkészletek elkészítésétől a petabájtos nagy adathalmazok használatáig
- A modellek átképzése és bevezetése bizonyos ütemben
- Feladatok ütemezése a modell minőségéhez vagy az adatsodródás figyeléséhez
- A jobb modellek paraméterterének feltárása
Bár ez a funkció egyszerűvé teszi az adatkezelők számára az önálló jegyzetfüzetek automatizálását, az ML-munkafolyamatok gyakran több notebookból állnak, amelyek mindegyike egy adott feladatot hajt végre összetett függőséggel. Például a modelladatok eltolódását figyelő notebooknak rendelkeznie kell egy előlépéssel, amely lehetővé teszi az új adatok kinyerését, átalakítását és betöltését (ETL) és feldolgozását, valamint egy utólagos modellfrissítési és betanítási lépést arra az esetre, ha jelentős eltolódást észlel. . Ezenkívül az adattudósok esetleg ismétlődő ütemezés szerint szeretnék elindítani ezt a teljes munkafolyamatot, hogy új adatok alapján frissítsék a modellt. A jegyzetfüzetek egyszerű automatizálása és az ilyen összetett munkafolyamatok létrehozása érdekében a SageMaker notebook-feladatok mostantól elérhetők a SageMaker Pipelines-ben. Ebben a bejegyzésben megmutatjuk, hogyan oldhatod meg a következő használati eseteket néhány soros kóddal:
- Automatikusan futtathat egy önálló notebookot azonnal vagy ismétlődő ütemezés szerint
- Hozzon létre többlépcsős munkafolyamatokat notebookokhoz DAG-ként folyamatos integráció és folyamatos szállítás (CI/CD) célokra, amelyeket a SageMaker Studio UI-n keresztül lehet kezelni.
Megoldás áttekintése
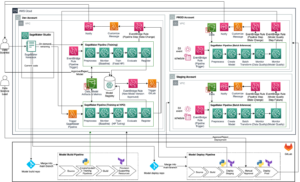
Az alábbi ábra szemlélteti megoldásunk architektúráját. A SageMaker Python SDK segítségével egyetlen notebook-feladatot vagy munkafolyamatot futtathat. Ez a szolgáltatás egy SageMaker képzési feladatot hoz létre a notebook futtatásához.
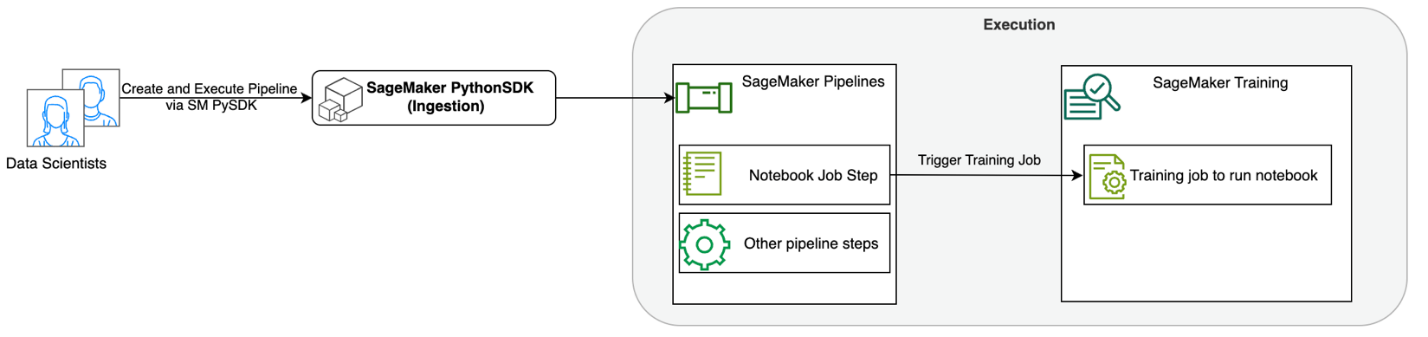
A következő szakaszokban egy példakénti ML használati esetet mutatunk be, és bemutatjuk a jegyzetfüzet-feladatok munkafolyamatának létrehozásának lépéseit, a paraméterek átadását a különböző notebook lépések között, ütemezve a munkafolyamatot és a SageMaker Studio segítségével.
Ebben a példában az ML problémánkra egy hangulatelemzési modellt építünk, amely egyfajta szövegosztályozási feladat. A hangulatelemzés leggyakoribb alkalmazásai közé tartozik a közösségi média figyelése, az ügyfélszolgálat menedzsmentje és az ügyfelek visszajelzéseinek elemzése. A példában használt adatkészlet a Stanford Sentiment Treebank (SST2) adatkészlet, amely filmkritikákat tartalmaz, valamint egy egész számot (0 vagy 1), amely jelzi a vélemény pozitív vagy negatív hangulatát.
A következő példa egy a data.csv az SST2 adatkészletnek megfelelő fájlt, és az értékeket az első két oszlopában jeleníti meg. Vegye figyelembe, hogy a fájlnak nem lehet fejléce.
| Oszlop 1 | Oszlop 2 |
| 0 | elrejteni az új váladékot a szülői egységek elől |
| 0 | nem tartalmaz szellemességet, csak fáradságos gegeket |
| 1 | amely szereti a karaktereit, és valami szépet közöl az emberi természetről |
| 0 | maximálisan elégedett azzal, hogy mindvégig ugyanaz marad |
| 0 | a legrosszabb bosszúvágyó klisékről, amiket a filmesek kitalálhatnak |
| 0 | ez túl tragikus ahhoz, hogy kiérdemelje az ilyen felületes kezelést |
| 1 | bemutatja , hogy az olyan hollywoodi kasszasikerek , mint a hazafias játékok rendezője még mindig képes egy kis , személyes filmet készíteni érzelmekkel teli falatokkal . |
Ebben az ML példában több feladatot kell végrehajtanunk:
- Hajtsa végre a funkciótervezést, hogy ezt az adatkészletet a modellünk számára érthető formátumban készítse elő.
- A funkciótervezés után futtasson egy képzési lépést, amely Transformers-t használ.
- Állítson be kötegelt következtetést a finomhangolt modellel, hogy segítsen megjósolni a beérkező új vélemények hangulatát.
- Állítson be egy adatfigyelési lépést, hogy rendszeresen figyelhessük új adatainkat a minőségi eltérések tekintetében, amelyek miatt szükség lehet a modellsúlyok átképzésére.
A SageMaker folyamatok egyik lépéseként elindított notebookfeladattal megszervezhetjük ezt a munkafolyamatot, amely három különálló lépésből áll. A munkafolyamat minden egyes lépése egy másik notebookban kerül kifejlesztésre, amelyeket azután független notebook-feladatok lépésekké alakítanak át, és egy folyamatként kapcsolódnak össze:
- Előfeldolgozás – Töltse le a nyilvános SST2 adatkészletet innen Amazon egyszerű tárolási szolgáltatás (Amazon S3), és hozzon létre egy CSV-fájlt a notebook számára a 2. lépésben a futtatáshoz. Az SST2 adatkészlet egy szöveges osztályozási adatkészlet két címkével (0 és 1), valamint egy kategorizálandó szövegoszloppal.
- Képzések – Vegye ki a formázott CSV-fájlt, és futtassa a finomhangolást a BERT-tel a szövegosztályozáshoz a Transformers könyvtárak használatával. Ennek a lépésnek a részeként tesztadat-előkészítő jegyzetfüzetet használunk, amely a finomhangolás és a kötegelt következtetés lépésének függősége. Amikor a finomhangolás befejeződött, ez a notebook a run magic segítségével fut, és tesztadatkészletet készít a finomhangolt modell mintakövetkeztetéséhez.
- Átalakítsa és figyelje – Kötegelt következtetés végrehajtása és adatminőség beállítása modellfigyeléssel, hogy kiindulási adatkészlet-javaslatot kapjon.
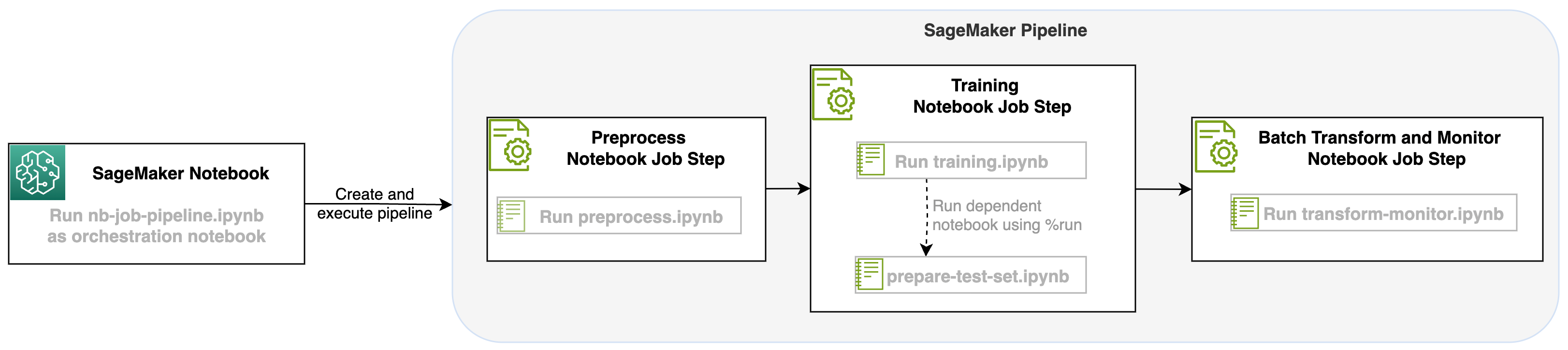
Futtassa a notebookokat
A megoldás mintakódja itt érhető el GitHub.
A SageMaker jegyzetfüzet munkalépésének létrehozása hasonló a SageMaker Pipeline többi lépésének létrehozásához. Ebben a jegyzetfüzetpéldában a SageMaker Python SDK-t használjuk a munkafolyamat összehangolására. Jegyzetfüzet lépés létrehozásához a SageMaker Pipelinesben a következő paramétereket adhatja meg:
- Bemeneti jegyzetfüzet – Annak a jegyzetfüzetnek a neve, amelyet ez a jegyzetfüzet lépés fogja hangszerelni. Itt átadhatja a helyi elérési utat a bemeneti jegyzetfüzethez. Opcionálisan, ha ez a jegyzetfüzet más futó notebookokkal is rendelkezik, átadhatja ezeket a következőben
AdditionalDependenciesparaméter a notebook feladat lépéséhez. - Kép URI – A Docker-kép a notebook feladat lépése mögött. Ezek lehetnek az előre meghatározott képek, amelyeket a SageMaker már biztosít, vagy egy egyéni kép, amelyet definiált és továbbított Amazon Elastic Container Registry (Amazon ECR). A támogatott képekért tekintse meg a bejegyzés végén található megfontolások részt.
- Kernel neve – A SageMaker Studio-ban használt kernel neve. Ez a rendszermag-specifikáció az Ön által megadott képfájlban van regisztrálva.
- Példány típusa (nem kötelező) - A Amazon rugalmas számítási felhő (Amazon EC2) példánytípus a definiált és futtatandó notebookfeladat mögött.
- Paraméterek (opcionális) – Azok a paraméterek, amelyeket megadhat, és amelyek elérhetők lesznek a notebook számára. Ezek kulcs-érték párokban definiálhatók. Ezenkívül ezek a paraméterek módosíthatók a különböző notebook-feladatok vagy folyamatfuttatások között.
Példánkban összesen öt jegyzetfüzet található:
- nb-job-pipeline.ipynb – Ez a fő notebookunk, ahol meghatározzuk a folyamatunkat és a munkafolyamatunkat.
- előfeldolgozás.ipynb – Ez a jegyzetfüzet a munkafolyamatunk első lépése, és tartalmazza azt a kódot, amely lekéri a nyilvános AWS-adatkészletet, és létrehoz egy CSV-fájlt belőle.
- képzés.ipynb – Ez a notebook a munkafolyamatunk második lépése, és kódot tartalmaz az előző lépés CSV-fájljának átvételéhez, valamint a helyi oktatás és finomhangolás végrehajtásához. Ez a lépés is függ a
prepare-test-set.ipynbnotebook, hogy lehúzzon egy tesztadatkészletet a finomhangolt modell mintakövetkeztetéséhez. - ready-test-set.ipynb – Ez a jegyzetfüzet egy tesztadatkészletet hoz létre, amelyet a képzési jegyzetfüzetünk a második folyamatlépésben fog használni, és a finomhangolt modell mintakövetkeztetésére használ.
- transform-monitor.ipynb – Ez a notebook a munkafolyamatunk harmadik lépése, és az alap BERT modellt használja, és egy SageMaker kötegelt átalakítási feladatot futtat, miközben az adatok minőségét is beállítja a modellfigyeléssel.
Ezután a fő jegyzetfüzetet járjuk végig nb-job-pipeline.ipynb, amely az összes aljegyzetfüzetet egy folyamatba egyesíti, és a végpontok közötti munkafolyamatot futtatja. Vegye figyelembe, hogy bár a következő példa csak egyszer futtatja a jegyzetfüzetet, ütemezheti a folyamatot a jegyzetfüzet ismételt futtatására is. Hivatkozni SageMaker dokumentáció részletes útmutatásért.
Az első notebook feladat lépésünkhöz egy paramétert adunk át egy alapértelmezett S3 gyűjtőrésszel. Használhatjuk ezt a vödröt minden olyan műtermék kiürítésére, amelyet a folyamat többi lépéséhez elérhetővé szeretnénk tenni. Az első jegyzetfüzethez (preprocess.ipynb), lebontjuk az AWS nyilvános SST2 vonatadatkészletét, és létrehozunk belőle egy képzési CSV-fájlt, amelyet továbbítunk ehhez az S3 tárolóhoz. Lásd a következő kódot:
Ezután ezt a notebookot átalakíthatjuk a NotebookJobStep a következő kóddal a fő notebookunkban:
Most, hogy van egy minta CSV-fájlunk, megkezdhetjük modellünk betanítását a képzési jegyzetfüzetünkben. Az edzési jegyzetfüzetünk ugyanazt a paramétert veszi fel, mint az S3 vödör, és onnan húzza le az edzési adatkészletet. Ezután finomhangolást végzünk a Transformers tréner objektum használatával a következő kódrészlettel:
A finomhangolás után egy kötegelt következtetést szeretnénk lefuttatni, hogy megnézzük, hogyan teljesít a modell. Ez egy külön notebook segítségével történik (prepare-test-set.ipynb). A kiegészítő jegyzetfüzetet a következő varázscellával futtathatjuk a tréningfüzetünkben:
Ezt az extra notebook-függőséget a AdditionalDependencies paraméter a második notebook munkalépésünkben:
Azt is meg kell adnunk, hogy a betanítási jegyzetfüzet feladat lépése (2. lépés) a Notebook előfeldolgozási feladat lépésétől (1. lépés) függ, a add_depends_on API hívás a következőképpen:
Utolsó lépésünk, hogy a BERT modellt SageMaker Batch Transform-on futtatjuk, miközben beállítjuk az adatrögzítést és a minőséget a SageMaker Model Monitor segítségével. Vegye figyelembe, hogy ez eltér a beépített használattól Átalakítás or Elfog lépések a csővezetékeken keresztül. Az ehhez a lépéshez tartozó jegyzetfüzetünk ugyanazokat az API-kat fogja végrehajtani, de Notebook Job Stepként lesz nyomon követve. Ez a lépés az általunk korábban definiált betanítási munkalépéstől függ, ezért azt is rögzítjük a depend_on jelzővel.
Miután meghatároztuk a munkafolyamat különböző lépéseit, létrehozhatjuk és futtathatjuk a végpontok közötti folyamatot:
Figyelje a csővezeték futását
A SageMaker Pipelines DAG segítségével nyomon követheti és figyelheti a notebook lépéseit, amint az a következő képernyőképen látható.
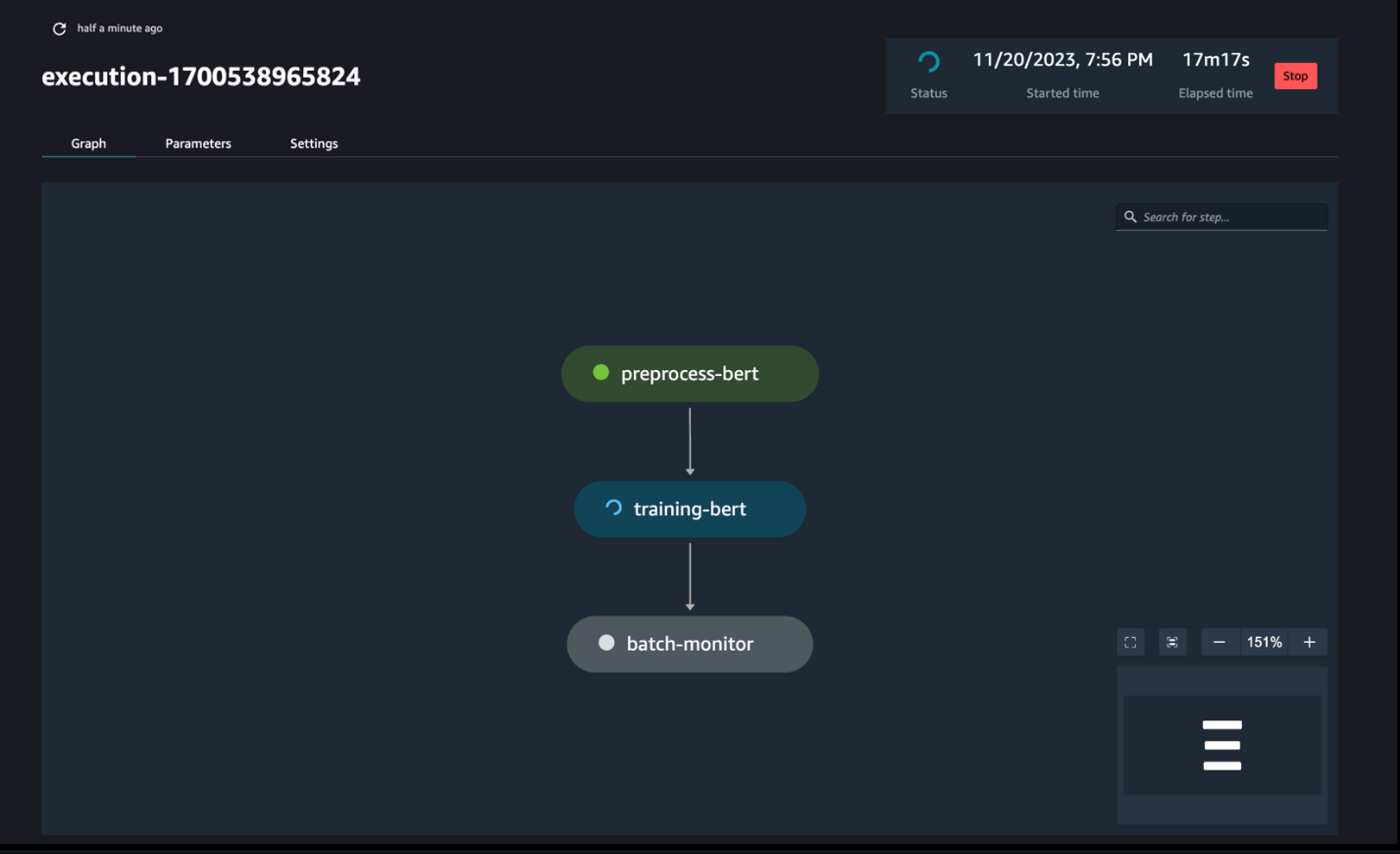
Opcionálisan figyelemmel kísérheti az egyes notebook-futtatásokat a notebookfeladatok irányítópultján, és átkapcsolhatja a SageMaker Studio felhasználói felületén keresztül létrehozott kimeneti fájlokat. Ha ezt a funkciót a SageMaker Studión kívül használja, címkék segítségével meghatározhatja azokat a felhasználókat, akik nyomon követhetik a futás állapotát a notebook munka irányítópultján. A beillesztendő címkékkel kapcsolatos további részletekért lásd: Tekintse meg notebook feladatait és töltse le a kimeneteket a Studio UI irányítópultján.
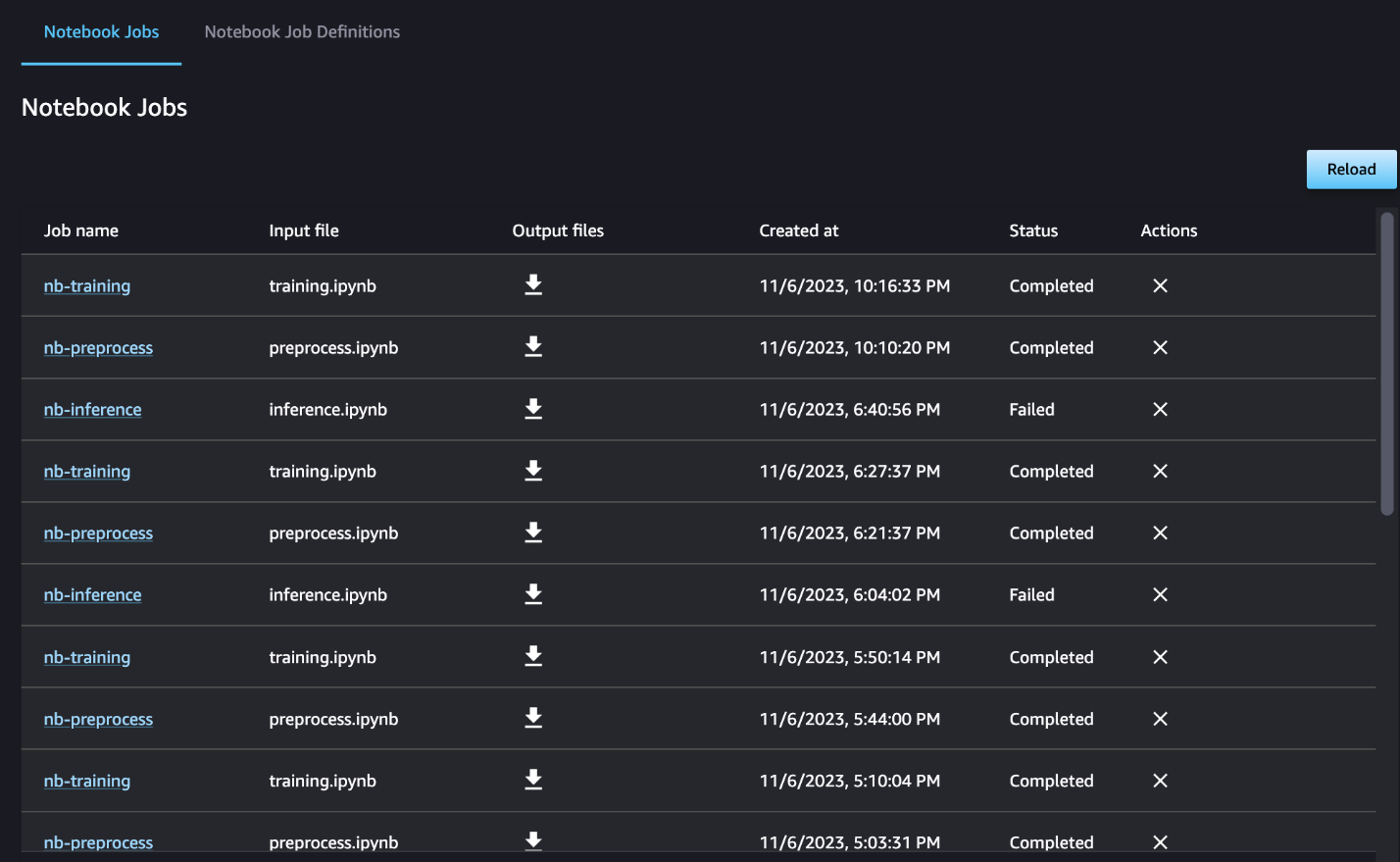
Ebben a példában az eredményül kapott notebook-feladatokat egy nevű könyvtárba írjuk ki outputs a helyi elérési útvonalon a folyamatkóddal. Ahogy a következő képernyőképen látható, itt láthatja a bemeneti notebook kimenetét, valamint az ehhez a lépéshez megadott paramétereket.
Tisztítsuk meg
Ha követte a példánkat, feltétlenül törölje a létrehozott folyamatot, a notebook-feladatokat és a mintajegyzetfüzetek által letöltött s3-adatokat.
Szempontok
A következő néhány fontos szempont ehhez a funkcióhoz:
- SDK-korlátok – A notebook feladat lépése csak a SageMaker Python SDK-n keresztül hozható létre.
- Képkorlátozások – A notebook feladat lépése a következő képeket támogatja:
Következtetés
Ezzel a bevezetéssel az adatkezelők néhány soros kóddal programozottan futtathatják notebookjaikat a következő használatával SageMaker Python SDK. Ezenkívül bonyolult, többlépcsős munkafolyamatokat hozhat létre a notebookok használatával, jelentősen lerövidítve a notebookról a CI/CD folyamatra való átálláshoz szükséges időt. A folyamat létrehozása után a SageMaker Studio segítségével megtekintheti és futtathatja a folyamatok DAG-jait, valamint kezelheti és összehasonlíthatja a futtatásokat. Akár végpontok közötti ML-munkafolyamatokat ütemez, akár azok egy részét, azt javasoljuk, hogy próbálja meg notebook alapú munkafolyamatok.
A szerzőkről
 Anchit Gupta az Amazon SageMaker Studio vezető termékmenedzsere. Arra összpontosít, hogy lehetővé tegye az interaktív adattudományi és adatmérnöki munkafolyamatokat a SageMaker Studio IDE-n belül. Szabadidejében szeret főzni, társasozni/kártyajátékozni és olvasni.
Anchit Gupta az Amazon SageMaker Studio vezető termékmenedzsere. Arra összpontosít, hogy lehetővé tegye az interaktív adattudományi és adatmérnöki munkafolyamatokat a SageMaker Studio IDE-n belül. Szabadidejében szeret főzni, társasozni/kártyajátékozni és olvasni.
 Ram Vegiraju ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse ügyfeleit AI/ML megoldásaik kiépítésében és optimalizálásában az Amazon SageMakeren. Szabadidejében szeret utazni és írni.
Ram Vegiraju ML építész a SageMaker Service csapatánál. Arra összpontosít, hogy segítse ügyfeleit AI/ML megoldásaik kiépítésében és optimalizálásában az Amazon SageMakeren. Szabadidejében szeret utazni és írni.
 Edward Sun Senior SDE, az Amazon Web Services SageMaker Studio-nál dolgozik. Az interaktív ML-megoldások kiépítésére és az ügyfélélmény egyszerűsítésére összpontosít, hogy integrálja a SageMaker Studio-t az adattervezés és az ML ökoszisztéma népszerű technológiáival. Szabadidejében Edward nagy rajongója a kempingezésnek, túrázásnak és horgászatnak, és szereti a családjával eltöltött időt.
Edward Sun Senior SDE, az Amazon Web Services SageMaker Studio-nál dolgozik. Az interaktív ML-megoldások kiépítésére és az ügyfélélmény egyszerűsítésére összpontosít, hogy integrálja a SageMaker Studio-t az adattervezés és az ML ökoszisztéma népszerű technológiáival. Szabadidejében Edward nagy rajongója a kempingezésnek, túrázásnak és horgászatnak, és szereti a családjával eltöltött időt.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/schedule-amazon-sagemaker-notebook-jobs-and-manage-multi-step-notebook-workflows-using-apis/
- :van
- :is
- :ahol
- $ UP
- 1
- 100
- 116
- 125
- 15%
- 17
- 20
- 500
- 7
- 8
- a
- Rólunk
- hozzáférhető
- aciklikus
- További
- Ezen kívül
- Előny
- Után
- AI / ML
- Minden termék
- lehetővé teszi, hogy
- mentén
- már
- Is
- Bár
- amazon
- Amazon EC2
- Amazon SageMaker
- Amazon SageMaker Studio
- Az Amazon Web Services
- an
- elemzés
- elemzése
- és a
- bármilyen
- api
- API-k
- alkalmazások
- építészet
- VANNAK
- AS
- At
- automatizált
- elérhető
- AWS
- bázis
- alapján
- kiindulási
- BE
- szép
- óta
- mögött
- hogy
- Jobb
- között
- Nagy
- épít
- Épület
- beépített
- de
- by
- hívás
- hívott
- kemping
- TUD
- elfog
- eset
- esetek
- sejt
- karakter
- besorolás
- kód
- Oszlop
- Oszlopok
- kombájnok
- hogyan
- Közös
- összehasonlítani
- teljes
- bonyolult
- áll
- Tartalmaz
- Kiszámít
- Magatartás
- összefüggő
- megfontolások
- áll
- Konténer
- tartalmaz
- folyamatos
- megtérít
- átalakított
- főzés
- Megfelelő
- tudott
- teremt
- készítette
- teremt
- létrehozása
- Jelenleg
- szokás
- vevő
- Vásárlói élmény
- Vevőszolgálat
- Ügyfelek
- DAG
- műszerfal
- dátum
- adatfigyelés
- Adatok előkészítése
- adatfeldolgozás
- adatminőség
- adat-tudomány
- adatkészletek
- alapértelmezett
- meghatározott
- meghatározott
- kézbesítés
- Kereslet
- függőségek
- Függőség
- függő
- függ
- telepíteni
- bevezetéséhez
- részletes
- részletek
- Fejleszt
- fejlett
- különböző
- közvetlen
- irányított
- Igazgató
- különböző
- Dokkmunkás
- Ennek
- csinált
- le-
- letöltés
- kiírása
- minden
- könnyen
- ökoszisztéma
- Edward
- lehetővé
- lehetővé téve
- ösztönzése
- végén
- végtől végig
- Mérnöki
- Egész
- korszak
- Eter (ETH)
- példa
- kivégez
- végrehajtás
- tapasztalat
- külön-
- kivonat
- család
- ventilátor
- messze
- Funkció
- Visszacsatolás
- kevés
- filé
- Fájlok
- Film
- filmesek
- vezetéknév
- Halászat
- öt
- összpontosított
- koncentrál
- követ
- következő
- következik
- A
- forma
- formátum
- ból ből
- teljesen
- funkcionalitás
- Továbbá
- Games
- generál
- grafikonok
- Legyen
- he
- segít
- segít
- neki
- itt
- turisztika
- övé
- Hollywood
- Hogyan
- HTML
- http
- HTTPS
- emberi
- if
- illusztrálja
- kép
- képek
- azonnal
- importál
- fontos
- in
- tartalmaz
- független
- jelzi
- egyéni
- bemenet
- példa
- utasítás
- integrálni
- integráció
- interaktív
- bele
- IT
- ITS
- Munka
- Állások
- jpg
- éppen
- Címke
- Címkék
- keresztnév
- indít
- tanulás
- könyvtárak
- vonal
- vonalak
- kiszámításának
- helyi
- elhelyezkedés
- Hosszú
- szeret
- gép
- gépi tanulás
- mágia
- Fő
- KÉSZÍT
- kezelése
- sikerült
- vezetés
- menedzser
- Média
- Érdem
- esetleg
- ML
- modell
- modellek
- módosított
- Modulok
- monitor
- ellenőrzés
- monitorok
- több
- a legtöbb
- mozog
- film
- többszörös
- kell
- név
- bennszülött
- Szükség
- szükséges
- negatív
- Új
- nem
- megjegyezni
- jegyzetfüzet
- laptopok
- Most
- tárgy
- of
- gyakran
- on
- ONE
- csak
- Optimalizálja
- or
- hangszerelés
- Más
- mi
- ki
- teljesítmény
- kimenetek
- kívül
- párok
- paraméter
- paraméterek
- rész
- elhalad
- Múló
- ösvény
- teljesít
- előadó
- személyes
- csővezeték
- Plató
- Platón adatintelligencia
- PlatoData
- játék
- Népszerű
- pozitív
- állás
- előre
- előkészítés
- Készít
- Előkészíti
- előkészítése
- előző
- korábban
- Probléma
- feldolgozás
- Termékek
- termék menedzser
- ad
- feltéve,
- biztosít
- nyilvános
- Húz
- célokra
- Nyomja
- meglökött
- Piton
- világítás
- gyorsabb
- R
- Inkább
- Olvass
- Olvasás
- ismétlődő
- csökkentő
- Refaktor
- utal
- nyilvántartott
- rendszeresen
- marad
- TÖBBSZÖR
- szükség
- kapott
- Kritika
- Vélemények
- futás
- futás
- fut
- sagemaker
- SageMaker csővezetékek
- azonos
- elégedett
- menetrend
- tervezett
- Ütemezett munkák
- ütemezés
- Tudomány
- tudósok
- sdk
- Második
- Rész
- szakaszok
- lát
- látott
- idősebb
- érzés
- különálló
- szolgáltatás
- Szolgáltatások
- ülés
- készlet
- beállítás
- számos
- alakú
- ő
- kellene
- előadás
- kirakat
- mutatott
- Műsorok
- jelentős
- jelentősen
- hasonló
- Egyszerű
- egyszerűsítése
- egyetlen
- kicsi
- kisebb
- töredék
- So
- Közösség
- Közösségi média
- megoldások
- Megoldások
- SOLVE
- néhány
- valami
- Hely
- különleges
- Költési
- önálló
- Stanford
- kezdet
- Állapot
- Lépés
- Lépései
- Még mindig
- tárolás
- egyértelmű
- stúdió
- ilyen
- nap
- támogatás
- Támogatott
- Támogatja
- biztos
- Vesz
- tart
- Feladat
- feladatok
- csapat
- Technologies
- teszt
- szöveg
- Szöveg osztályozása
- hogy
- A
- azok
- Őket
- akkor
- Ezek
- Harmadik
- ezt
- azok
- három
- Keresztül
- idő
- nak nek
- együtt
- is
- szerszám
- Végösszeg
- vágány
- Vonat
- kiképzett
- Képzések
- Átalakítás
- transzformerek
- Utazó
- kiváltó
- FORDULAT
- kettő
- típus
- ui
- megért
- Frissítések
- us
- használ
- használati eset
- használt
- Felhasználók
- használ
- segítségével
- kihasználva
- Értékek
- különféle
- keresztül
- Megnézem
- Képzeld
- séta
- akar
- we
- háló
- webes szolgáltatások
- amikor
- vajon
- ami
- míg
- WHO
- lesz
- val vel
- belül
- nélkül
- dolgozók
- munkafolyamat
- munkafolyamatok
- dolgozó
- Legrosszabb
- írás
- te
- A te
- zephyrnet