Egy újonnan létrehozott mesterséges intelligencia (AI) rendszer, amely a mélyen megerősített tanuláson (DRL) alapul, képes reagálni a támadókra egy szimulált környezetben, és megakadályozza a kibertámadások 95%-át, mielőtt azok eszkalálódnának.
Ezt állítják az Energiaügyi Minisztérium Pacific Northwest National Laboratory kutatói, akik egy absztrakt szimulációt készítettek a támadók és a védők közötti digitális konfliktusról egy hálózatban, és négy különböző DRL neurális hálózatot képeztek ki, hogy maximalizálják a jutalmat a kompromisszumok megelőzése és a hálózati zavarok minimalizálása alapján.
A szimulált támadók egy sor taktikát alkalmaztak a MITER ATT&CK keretrendszer besorolása, hogy a kezdeti hozzáférési és felderítési fázisból más támadási fázisokba lépjenek, amíg el nem érik céljukat: a becsapódási és kiszűrési fázist.
A mesterséges intelligencia rendszer egyszerűsített támadási környezetre vonatkozó sikeres betanítása azt mutatja, hogy a támadásokra adott védekező válaszok valós időben kezelhetők egy mesterséges intelligencia modellel – mondta Samrat Chatterjee, adattudós, aki bemutatta a csapat munkáját a Szövetség éves találkozóján. A mesterséges intelligencia fejlődése Washingtonban, február 14-én.
„Nem szeretne bonyolultabb architektúrákba lépni, ha még csak nem is tudja megmutatni ezeknek a technikáknak az ígéretét” – mondja. „Először is be akartuk mutatni, hogy valóban képesek vagyunk sikeresen betanítani egy DRL-t, és jó teszteredményeket mutatunk be, mielőtt továbblépnénk.”
A gépi tanulás és a mesterséges intelligencia technikák alkalmazása a kiberbiztonság különböző területein az elmúlt évtizedben a gépi tanulás e-mail biztonsági átjárókba való korai integrációja óta forró trendté vált. az 2010 korai szakaszában az újabb erőfeszítésekhez használja a ChatGPT-t a kód elemzéséhez vagy törvényszéki elemzést végezzen. Most, a legtöbb biztonsági termék rendelkezik – vagy azt állítja, hogy rendelkezik – néhány olyan funkcióval, amelyet nagy adathalmazokra betanított gépi tanulási algoritmusok hajtanak végre.
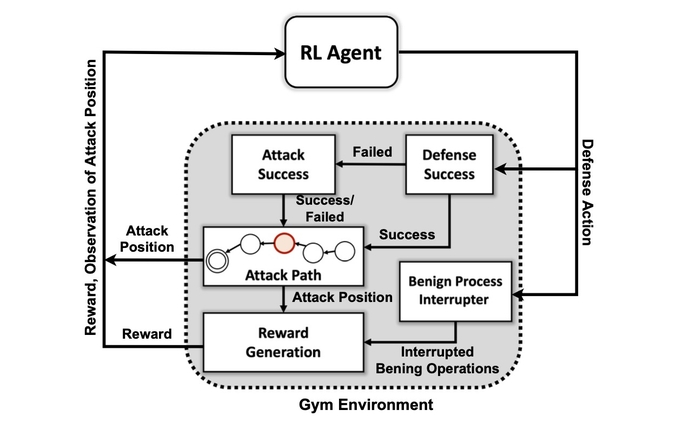
A proaktív védekezésre képes mesterséges intelligencia-rendszer létrehozása azonban továbbra is inkább törekvés, mintsem praktikus. Bár számos akadály áll még a kutatók előtt, a PNNL kutatása azt mutatja, hogy a mesterséges intelligencia-védő a jövőben lehetséges.
A PNNL kutatócsoportja fontos lépést jelent a gyakorlatias autonóm kibervédelmi megoldások felé, ha többféle DRL-algoritmus kiértékelését végezték el a különböző ellentmondásos körülmények között. írták lapjukban. „Kísérleteink azt sugallják, hogy a modell nélküli DRL-algoritmusok hatékonyan képezhetők többlépcsős támadási profilok alatt, különböző képzettségi és kitartási szintekkel, ami kedvező védekezési eredményeket eredményez vitatható körülmények között.”
Hogyan használja a rendszer a MITER ATT&CK-t
A kutatócsoport első célja egy egyedi szimulációs környezet létrehozása volt, amely egy nyílt forráskódú eszköztáron alapul Nyissa meg az AI edzőtermet. Ezt a környezetet használva a kutatók különböző készség- és kitartási szintű támadó entitásokat hoztak létre, amelyek képesek voltak a MITER ATT&CK keretrendszer 7 taktikából és 15 technikából álló részhalmazának használatára.
A támadóügynökök célja, hogy végighaladjanak a támadási lánc hét lépésén, a kezdeti hozzáféréstől a végrehajtásig, a kitartástól a parancsnoklásig és irányításig, valamint az összegyűjtéstől a becsapódásig.
A támadó számára bonyolult lehet taktikájának a környezet állapotához és a védő aktuális akcióihoz való igazítása, mondja a PNNL Chatterjee.
„Az ellenfélnek el kell navigálnia az utat a kezdeti felderítési állapottól egészen valamilyen kiszivárgási vagy becsapódási állapotig” – mondja. „Nem próbálunk egyfajta modellt létrehozni, hogy megállítsuk az ellenfelet, mielőtt az bejutna a környezetbe – feltételezzük, hogy a rendszer már kompromittálódott.”
A kutatók négy megközelítést alkalmaztak a neurális hálózatokhoz, amelyek megerősítő tanuláson alapultak. A megerősítési tanulás (RL) egy gépi tanulási megközelítés, amely az emberi agy jutalmazási rendszerét emulálja. A neurális hálózat úgy tanul, hogy megerősít vagy gyengít bizonyos paramétereket az egyes neuronok számára, hogy a jobb megoldásokat jutalmazza, amit a rendszer teljesítményét jelző pontszámmal mérnek.
A megerősítő tanulás lényegében lehetővé teszi a számítógép számára, hogy jó, de nem tökéletes megközelítést hozzon létre a problémára, mondja Mahantesh Halappanavar, a PNNL kutatója és a cikk szerzője.
„Bármilyen megerősítő tanulás nélkül is meg tudnánk csinálni, de ez valóban nagy probléma lenne, és nem lesz elég idő ahhoz, hogy ténylegesen jó mechanizmust kitaláljunk” – mondja. "Kutatásunk... ezt a mechanizmust adja nekünk, ahol a mélyen megerősített tanulás bizonyos mértékig magát az emberi viselkedés egy részét utánozza, és nagyon hatékonyan képes feltárni ezt a hatalmas teret."
Nem áll készen a főműsoridőre
A kísérletek azt találták, hogy egy speciális megerősítési tanulási módszer, az úgynevezett Deep Q Network erős megoldást kínál a védekezési problémára, a támadók 97%-át elkapni a tesztelési adathalmazban. A kutatás azonban csak a kezdet. A biztonsági szakembereknek nem szabad olyan mesterséges intelligencia-társat keresniük, aki a közeljövőben segítene nekik az incidensek kezelésére és a kriminalisztika elvégzésében.
A számos megoldásra váró probléma között szerepel a megerősítő tanulás és a mély neurális hálózatok megszerzése a döntéseiket befolyásoló tényezők megmagyarázására, ez a kutatási terület az magyarázható megerősítés tanulás (XRL).
Ezenkívül az AI-algoritmusok robusztussága és a neurális hálózatok képzésének hatékony módjai egyaránt olyan probléma, amelyet meg kell oldani, mondja a PNNL Chatterjee.
„Termék létrehozása – nem ez volt a kutatás fő motivációja” – mondja. "Ez inkább a tudományos kísérletezésről és az algoritmikus felfedezésről szólt."
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- képesség
- Rólunk
- KIVONAT
- hozzáférés
- Szerint
- cselekvések
- tulajdonképpen
- mellett
- haladás
- ellenséges
- szerek
- AI
- AI-hajtású
- algoritmikus
- algoritmusok
- Minden termék
- lehetővé teszi, hogy
- már
- elemzés
- elemez
- és a
- évi
- Alkalmazás
- megközelítés
- megközelít
- TERÜLET
- mesterséges
- mesterséges intelligencia
- Mesterséges intelligencia (AI)
- Egyesület
- támadás
- Támadások
- szerző
- autonóm
- alapján
- válik
- előtt
- Jobb
- között
- Nagy
- Blokk
- Agy
- épült
- hívott
- nem tud
- képes
- bizonyos
- lánc
- ChatGPT
- követelés
- besorolás
- gyűjtemény
- hogyan
- bonyolult
- Veszélyeztetett
- számítógép
- Magatartás
- konfliktus
- tovább
- ellenőrzés
- tudott
- teremt
- készítette
- létrehozása
- Jelenlegi
- szokás
- cyber
- cyberattacks
- Kiberbiztonság
- dátum
- adattudós
- adatkészlet
- adatkészletek
- dc
- évtized
- döntés
- határozatok
- mély
- mély idegi hálózatok
- Védők
- Védelem
- védekező
- bizonyítani
- mutatja
- osztály
- Department of Energy
- különböző
- digitális
- felfedezés
- Zavar
- számos
- DOE
- Korai
- hatékonyan
- hatékony
- eredményesen
- erőfeszítések
- e-mail biztonság
- energia
- elég
- Szervezetek
- Környezet
- lényegében
- Eter (ETH)
- értékelő
- Még
- végrehajtás
- kiszűrés
- Magyarázza
- feltárása
- tényezők
- Jellemzők
- kevés
- Fields
- megtalálása
- vezetéknév
- áramlási
- Törvényszéki
- kriminalisztika
- Előre
- talált
- Keretrendszer
- ból ből
- jövő
- kap
- szerzés
- ad
- cél
- Célok
- jó
- kéz
- segít
- FORRÓ
- Hogyan
- HTTPS
- emberi
- gátfutás
- Hatás
- fontos
- in
- incidens
- eseményre adott válasz
- jelezve
- egyéni
- befolyásolható
- kezdetben
- integráció
- Intelligencia
- IT
- maga
- Kedves
- ismert
- laboratórium
- nagy
- tanulás
- szintek
- néz
- gép
- gépi tanulás
- Fő
- sok
- max-width
- Maximize
- mechanizmus
- találkozó
- módszer
- minimalizálása
- modell
- több
- Motiváció
- mozog
- mozgó
- többszörös
- nemzeti
- Keresse
- Szükség
- hálózat
- hálózatok
- ideg-
- neurális hálózat
- neurális hálózatok
- neuronok
- nyitva
- nyílt forráskódú
- Más
- Csendes-óceán
- Papír
- paraméterek
- múlt
- tökéletes
- Előadja
- kitartás
- fázis
- Plató
- Platón adatintelligencia
- PlatoData
- lehetséges
- powered
- Gyakorlati
- bemutatott
- megakadályozása
- Első
- proaktív
- Probléma
- problémák
- Termékek
- tehetséges alkalmazottal
- Profilok
- ígéret
- RE
- elérte
- Reagál
- reagál
- kész
- igazi
- real-time
- új
- megerősítő tanulás
- marad
- kutatás
- kutató
- kutatók
- válasz
- Jutalom
- Jutalmak
- robusztusság
- azt mondja,
- Tudós
- biztonság
- Series of
- készlet
- beállítások
- hét
- kellene
- előadás
- Műsorok
- egyszerűsített
- tettetés
- jártasság
- megoldások
- Megoldások
- néhány
- Nemsokára
- forrás
- Hely
- különleges
- kezdet
- Állami
- Lépés
- Lépései
- Még mindig
- megáll
- erősítő
- erős
- sikeres
- sikeresen
- rendszer
- taktika
- csapat
- technikák
- Tesztelés
- A
- A jövő
- Az állam
- azok
- Keresztül
- idő
- nak nek
- eszköztár
- felé
- Vonat
- kiképzett
- Képzések
- tendencia
- alatt
- us
- használ
- fajta
- Hatalmas
- kívánatos
- washington
- módon
- míg
- WHO
- lesz
- belül
- nélkül
- Munka
- lenne
- így
- zephyrnet











