Az elmúlt néhány évben a nagy nyelvi modellek (LLM-ek) kiemelkedő eszközökként emelkedtek előtérbe, mint olyan kiváló eszközök, amelyek soha nem látott hozzáértéssel képesek szöveget megérteni, generálni és manipulálni. Potenciális alkalmazásaik a társalgási ügynököktől a tartalomgenerálásig és információ-visszakeresésig terjednek, az összes iparág forradalmasításának ígéretével. Azonban ennek a lehetőségnek a kiaknázása a modellek felelős és hatékony használatának biztosítása mellett az LLM értékelés kritikus folyamatától függ. Az értékelés egy olyan feladat, amely egy LLM vagy generatív AI-szolgáltatás kimenetének minőségét és felelősségét méri. Az LLM-ek értékelését nem csak a modell teljesítményének megértésének vágya motiválja, hanem a felelős mesterséges intelligencia megvalósításának szükségessége is, valamint a félretájékoztatás vagy az elfogult tartalom nyújtásának kockázatának csökkentése, valamint a káros, nem biztonságos, rosszindulatú és etikátlan tartalom létrehozásának minimalizálása. tartalom. Ezenkívül az LLM-ek értékelése segíthet a biztonsági kockázatok mérséklésében is, különösen az azonnali adatok manipulálása esetén. Az LLM-alapú alkalmazások esetében kulcsfontosságú a sérülékenységek azonosítása és olyan biztosítékok bevezetése, amelyek megvédik az adatok esetleges jogsértéseit és jogosulatlan manipulációit.
Azáltal, hogy alapvető eszközöket biztosít az LLM-ek egyszerű konfigurációval és egy kattintással történő értékeléséhez, Amazon SageMaker Clarify Az LLM kiértékelési képességei hozzáférést biztosítanak az ügyfeleknek a fent említett előnyök többségéhez. Ha ezekkel az eszközökkel a kezünkben van, a következő kihívás az LLM-értékelés integrálása a Machine Learning and Operation (MLOps) életciklusába a folyamat automatizálása és méretezhetősége érdekében. Ebben a bejegyzésben bemutatjuk, hogyan integrálhatja az Amazon SageMaker Clarify LLM-értékelést az Amazon SageMaker Pipelines-szel, hogy lehetővé tegye az LLM-kiértékelést a skálán. Ezen kívül kódpéldát is adunk ebben GitHub adattárat, amely lehetővé teszi a felhasználók számára, hogy párhuzamos többmodell-kiértékelést végezzenek nagy méretekben, olyan példák segítségével, mint a Llama2-7b-f, Falcon-7b és a finomhangolt Llama2-7b modellek.
Kinek kell elvégeznie az LLM értékelést?
Mindenkinek, aki egy előre betanított LLM-et képez, finomhangol vagy egyszerűen csak használ, pontosan ki kell értékelnie azt, hogy felmérje az adott LLM által működtetett alkalmazás viselkedését. Ezen alapelv alapján 3 csoportba sorolhatjuk azokat a generatív AI-felhasználókat, akiknek LLM-kiértékelési képességre van szükségük, amint az a következő ábrán látható: modellszolgáltatók, finomhangolók és fogyasztók.
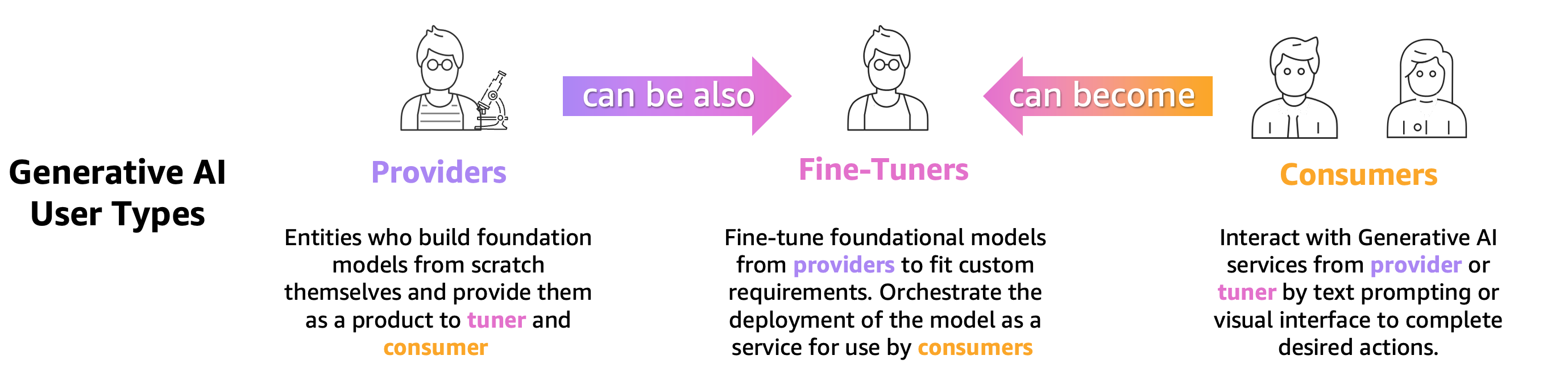
- Foundational Model (FM) szolgáltatók általános célú vonatmodellek. Ezek a modellek számos későbbi feladathoz használhatók, például funkciók kibontására vagy tartalom generálására. Minden egyes betanított modellt számos feladathoz kell viszonyítani, nemcsak teljesítményük értékeléséhez, hanem más meglévő modellekkel való összehasonlításhoz, a fejlesztésre szoruló területek azonosításához, és végül a területen elért fejlődés nyomon követéséhez. A modellszolgáltatóknak ellenőrizniük kell az esetleges torzítások meglétét is, hogy biztosítsák a kiindulási adatkészlet minőségét és modelljük helyes viselkedését. Az értékelési adatok összegyűjtése létfontosságú a modellszolgáltatók számára. Ezenkívül ezeket az adatokat és mutatókat össze kell gyűjteni, hogy megfeleljenek a jövőbeli szabályozásoknak. ISO 42001, a Biden Adminisztráció Végrehajtó Rendeleteés EU AI törvény szabványokat, eszközöket és teszteket dolgozzon ki annak biztosítására, hogy az AI-rendszerek biztonságosak, biztonságosak és megbízhatóak legyenek. Például az EU AI-törvény feladata, hogy tájékoztatást adjon arról, hogy mely adatkészleteket használják a képzéshez, milyen számítási teljesítményre van szükség a modell futtatásához, jelentse a modell eredményeit a nyilvános/ipari szabványok szerinti benchmarkok alapján, és megosszák a belső és külső tesztelések eredményeit.
- Modell finomhangolók szeretne konkrét feladatokat megoldani (pl. érzelmek osztályozása, összegzése, kérdések megválaszolása), valamint előre betanított modelleket szeretne a tartományspecifikus feladatok átvételéhez. A modellszolgáltatók által generált értékelési metrikákra van szükségük ahhoz, hogy kiindulási pontként kiválaszthassák a megfelelő előre betanított modellt.
Feladat- vagy tartományspecifikus adatkészletekkel értékelniük kell a finomhangolt modelleket a kívánt használati esethez képest. Gyakran össze kell gyűjteniük és létrehozniuk privát adatkészleteiket, mivel a nyilvánosan elérhető adatkészletek, még azok is, amelyeket egy adott feladatra terveztek, nem feltétlenül rögzítik megfelelően az adott használati esetükhöz szükséges árnyalatokat.
A finomhangolás gyorsabb és olcsóbb, mint egy teljes képzés, és gyorsabb operatív iterációt igényel a telepítéshez és a teszteléshez, mivel általában sok jelölt modell készül. Ezen modellek kiértékelése lehetővé teszi a modell folyamatos fejlesztését, kalibrálását és hibakeresését. Vegye figyelembe, hogy a finomhangolók saját modelljeik fogyasztóivá válhatnak, amikor valós alkalmazásokat fejlesztenek. - Modell fogyasztók vagy a modellbevezetők szolgálják ki és figyelik az általános célú vagy finomhangolt modelleket a termelésben, céljaik az alkalmazásaik vagy szolgáltatásaik fejlesztése az LLM-ek elfogadásával. Az első kihívás, amivel szembe kell nézniük, annak biztosítása, hogy a kiválasztott LLM megfeleljen sajátos igényeiknek, költségeiknek és teljesítmény-elvárásaiknak. A modell eredményeinek értelmezése és megértése állandó aggodalomra ad okot, különösen akkor, ha az adatvédelemről és az adatbiztonságról van szó (például a kockázatok és a megfelelőség auditálásához a szabályozott iparágakban, például a pénzügyi szektorban). A folyamatos modellértékelés kritikus fontosságú az elfogultság vagy a káros tartalom terjedésének megakadályozása érdekében. Egy robusztus nyomon követési és értékelési keretrendszer bevezetésével a modellfogyasztók proaktívan azonosíthatják és kezelhetik a regressziót az LLM-ekben, biztosítva ezzel, hogy ezek a modellek idővel megőrizzék hatékonyságukat és megbízhatóságukat.
Hogyan kell elvégezni az LLM értékelést
A hatékony modellértékelés három alapvető összetevőt foglal magában: egy vagy több FM-et vagy finomhangolt modelleket a bemeneti adatkészletek (promptok, beszélgetések vagy szokásos bemenetek) és a kiértékelési logika értékeléséhez.
Az értékeléshez szükséges modellek kiválasztásához különféle tényezőket kell figyelembe venni, beleértve az adatok jellemzőit, a probléma összetettségét, a rendelkezésre álló számítási erőforrásokat és a kívánt eredményt. A bemeneti adattár biztosítja a kiválasztott modell betanításához, finomhangolásához és teszteléséhez szükséges adatokat. Létfontosságú, hogy ez az adattár jól strukturált, reprezentatív és jó minőségű legyen, mivel a modell teljesítménye nagymértékben függ attól, hogy milyen adatokból tanul. Végül az értékelési logikák meghatározzák a modell teljesítményének értékeléséhez használt kritériumokat és mérőszámokat.
Ez a három összetevő együtt egy összefüggő keretet alkot, amely biztosítja a gépi tanulási modellek szigorú és szisztematikus értékelését, ami végső soron megalapozott döntésekhez és a modell hatékonyságának javításához vezet.
A modellértékelési technikák még mindig aktív kutatási területnek számítanak. Számos nyilvános benchmarkot és keretrendszert hozott létre a kutatók közössége az elmúlt néhány évben, hogy lefedje a feladatok és forgatókönyvek széles körét, mint pl. ragasztó, Pillanatragasztó, SISAK, MMLU és a NAGY-pad. Ezek a benchmarkok ranglistákkal rendelkeznek, amelyek segítségével összehasonlíthatók és szembeállíthatók az értékelt modellek. A benchmarkok, mint például a HELM, a pontossági mérőszámokon túlmutató mérőszámok értékelésére is irányulnak, mint például a pontosság vagy az F1-es pontszám. A HELM benchmark tartalmazza a méltányosságra, torzításra és toxicitásra vonatkozó mérőszámokat, amelyek ugyanolyan jelentős jelentőséggel bírnak a modell általános értékelési pontszámában.
Mindezek a benchmarkok mérőszámokat tartalmaznak, amelyek azt mérik, hogy a modell hogyan teljesít egy bizonyos feladaton. A leghíresebb és leggyakoribb mérőszámok a PIROS (Előhívás-orientált altanulmány a lényegi értékeléshez), KÉK (BiLingual Evaluation Understudy), ill METEOR (Mutató az explicit megrendeléssel történő fordítás értékeléséhez). Ezek a mérőszámok hasznos eszközként szolgálnak az automatizált kiértékeléshez, kvantitatív méréseket biztosítva a generált és a referenciaszöveg lexikális hasonlóságára vonatkozóan. Azonban nem ragadják meg az emberszerű nyelvgeneráció teljes skáláját, amely magában foglalja a szemantikai megértést, a kontextust vagy a stilisztikai árnyalatokat. A HELM például nem ad konkrét használati esetekre vonatkozó kiértékelési részleteket, megoldásokat az egyéni promptok tesztelésére, és nem szakértők által könnyen értelmezhető eredményeket, mivel a folyamat költséges lehet, nem könnyen méretezhető, és csak meghatározott feladatokhoz.
Ezen túlmenően az emberszerű nyelvgenerálás elérése gyakran megköveteli a humán-in-the-loop beépítését, hogy minőségi értékeléseket és emberi ítéletet hozzon az automatizált pontossági mérőszámok kiegészítésére. Az emberi értékelés értékes módszer az LLM-eredmények értékelésére, de lehet szubjektív és hajlamos az elfogultságra, mivel a különböző emberi értékelőknek eltérő vélemények és értelmezések lehetnek a szövegminőségről. Ezenkívül az emberi értékelés erőforrás-igényes és költséges lehet, valamint jelentős időt és erőfeszítést igényel.
Merüljünk el mélyen abban, hogy az Amazon SageMaker Clarify hogyan köti össze zökkenőmentesen a pontokat, segítve az ügyfeleket a modell alapos értékelésében és kiválasztásában.
LLM értékelés az Amazon SageMaker Clarify segítségével
Az Amazon SageMaker Clarify segít az ügyfeleknek a mutatók automatizálásában, beleértve, de nem kizárólagosan a pontosságot, a robusztusságot, a toxicitást, a sztereotípiákat és a tényszerű ismereteket az automatizáláshoz, valamint a stílust, a koherenciát, az emberi alapú értékeléshez való relevanciát és az értékelési módszereket azáltal, hogy keretet biztosít az LLM-ek értékeléséhez. és LLM-alapú szolgáltatások, mint például az Amazon Bedrock. Teljesen felügyelt szolgáltatásként a SageMaker Clarify leegyszerűsíti a nyílt forráskódú értékelési keretrendszerek használatát az Amazon SageMakeren belül. Az ügyfelek kiválaszthatják a forgatókönyveikhez releváns kiértékelési adatkészleteket és mérőszámokat, és kibővíthetik azokat saját azonnali adatkészleteikkel és kiértékelési algoritmusaikkal. A SageMaker Clarify többféle formátumban nyújt értékelési eredményeket, hogy támogassa a különböző szerepeket az LLM munkafolyamatban. Az adattudósok részletes eredményeket elemezhetnek a SageMaker Clarify vizualizációkkal a notebookokban, a SageMaker modellkártyákban és a PDF-jelentésekben. Eközben a műveleti csapatok az Amazon SageMaker GroundTruth segítségével áttekinthetik és megjegyzésekkel láthatják el a SageMaker Clarify által azonosított magas kockázatú elemeket. Például sztereotípiák, toxicitás, elkerült személyazonosításra alkalmas adatok vagy alacsony pontosság miatt.
A megjegyzéseket és a megerősítő tanulást ezt követően alkalmazzák a lehetséges kockázatok csökkentése érdekében. Az azonosított kockázatok emberbarát magyarázata felgyorsítja a manuális felülvizsgálati folyamatot, ezáltal csökkenti a költségeket. Az összefoglaló jelentések összehasonlító viszonyítási alapokat kínálnak az üzleti érdekelt felek számára a különböző modellek és verziók között, megkönnyítve a megalapozott döntéshozatalt.
Az alábbi ábra az LLM-ek és az LLM-alapú szolgáltatások értékelésének keretrendszerét mutatja be:

Az Amazon SageMaker Clarify LLM kiértékelés egy nyílt forráskódú Foundation Model Evaluation (FMEval) könyvtár, amelyet az AWS fejlesztett ki, hogy segítse az ügyfeleket az LLM-ek egyszerű értékelésében. Az összes funkciót beépítették az Amazon SageMaker Studio-ba is, hogy lehetővé tegyék az LLM-értékelést a felhasználók számára. A következő szakaszokban bemutatjuk az Amazon SageMaker Clarify LLM kiértékelési képességeinek és a SageMaker Pipelines integrációját, hogy lehetővé tegyük az LLM nagyarányú kiértékelését az MLOps elvek használatával.
Amazon SageMaker MLOps életciklus
Ahogy a bejegyzés "MLOps alapítványi ütemterv az Amazon SageMakerrel rendelkező vállalkozások számára” – írja le, az MLOps folyamatok, emberek és technológia kombinációja az ML használati esetek hatékony gyártása érdekében.
A következő ábra a végpontok közötti MLOps életciklust mutatja:

Egy tipikus utazás azzal kezdődik, hogy egy adattudós elkészít egy koncepcióbizonyítványt (PoC) annak bizonyítására, hogy az ML képes megoldani egy üzleti problémát. A Proof of Concept (PoC) fejlesztése során az adattudós feladata, hogy az üzleti kulcsfontosságú teljesítménymutatókat (KPI-k) gépi tanulási modell mérőszámaivá alakítsa át, mint például a pontosság vagy a hamis pozitív arány, és korlátozott tesztadatkészletet használjon ezek értékelésére. mérőszámok. Az adattudósok együttműködnek az ML mérnökeivel, hogy átállítsák a kódot a notebookokról a tárolókba, és ML folyamatokat hoznak létre az Amazon SageMaker Pipelines segítségével, amelyek különféle feldolgozási lépéseket és feladatokat kapcsolnak össze, beleértve az előfeldolgozást, a képzést, az értékelést és az utófeldolgozást, miközben folyamatosan új termelést építenek be. adat. Az Amazon SageMaker Pipelines üzembe helyezése a tárolókkal való interakciókon és a CI/CD-folyamat aktiválásán alapul. Az ML-folyamat a legjobban teljesítő modelleket, tárolóképeket, kiértékelési eredményeket és állapotinformációkat tartja nyilván egy modellnyilvántartásban, ahol a modellben érdekelt felek értékelik a teljesítményt, és a teljesítményeredmények és benchmarkok alapján döntenek a termelésbe való továbblépésről, amit egy másik CI/CD folyamat aktiválása követ. színpadra állításához és gyártási telepítéséhez. Az éles üzembe helyezést követően az ML-fogyasztók a modellt az alkalmazás által kiváltott következtetések révén használják fel közvetlen hívás vagy API-hívások révén, visszacsatolási hurkokkal a modelltulajdonosokhoz a teljesítmény folyamatos értékeléséhez.
Amazon SageMaker Clarify és MLOps integráció
Az MLOps életciklusát követve a finomhangolók vagy a nyílt forráskódú modellek felhasználói finomhangolt modelleket vagy FM-et állítanak elő az Amazon SageMaker Jumpstart és az MLOps szolgáltatások segítségével, amint azt a MLOps gyakorlatok megvalósítása Amazon SageMaker JumpStart előre betanított modellekkel. Ez új tartományhoz vezetett az alapmodell-műveletek (FMOps) és az LLM-műveletek (LLMOps) számára. FMOps/LLMOps: Operacionalizálja a generatív AI-t és a különbségeket MLOp-okkal.
Az alábbi ábra az LLMOps teljes életciklusát mutatja be:
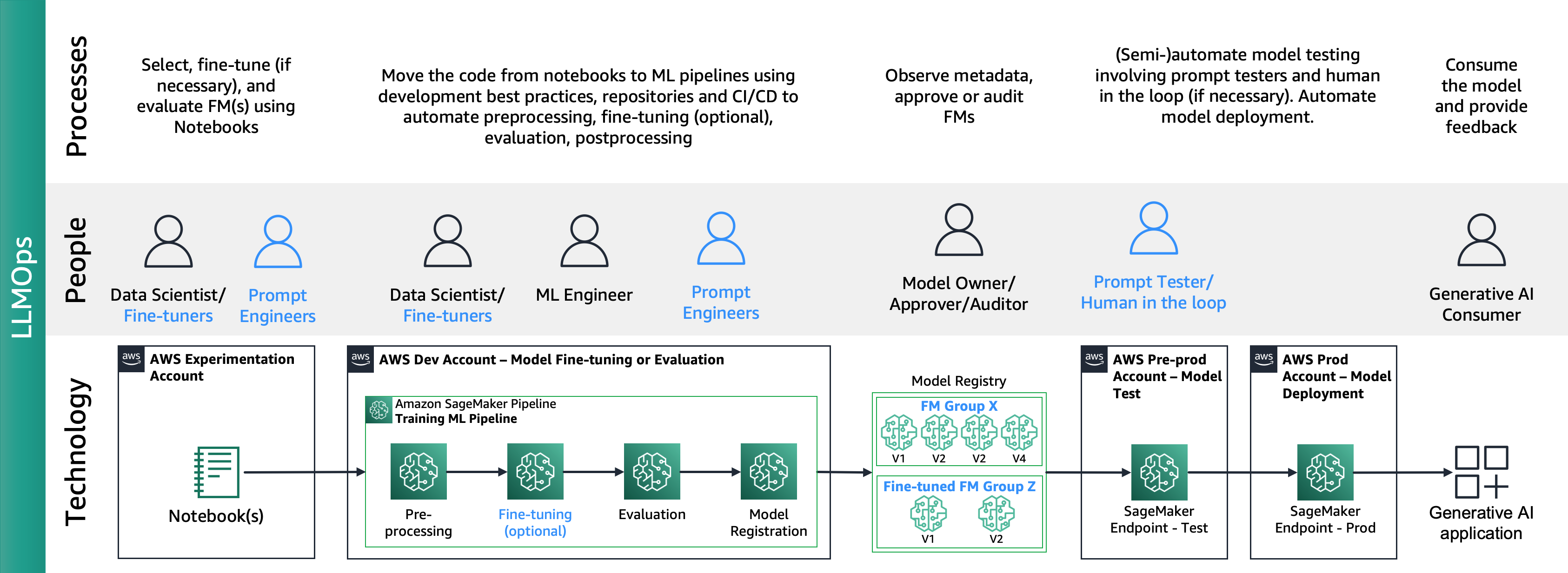
Az LLMOps-ban a fő különbségek az MLOp-okhoz képest a modellválasztás és a modellértékelés, amely különböző folyamatokat és mérőszámokat foglal magában. A kezdeti kísérletezési szakaszban az adattudósok (vagy finomhangolók) kiválasztják azt az FM-et, amelyet egy adott Generatív AI használati esethez használni fognak.
Ez gyakran több FM tesztelését és finomhangolását eredményezi, amelyek közül néhány összehasonlítható eredményeket adhat. A modell(ek) kiválasztása után a prompt mérnökök felelősek a szükséges bemeneti adatok és a várható kimenet előkészítéséért az értékeléshez (pl. bemeneti adatokat és lekérdezést tartalmazó beviteli promptok), valamint olyan mérőszámok meghatározásáért, mint a hasonlóság és a toxicitás. E mérőszámok mellett az adattudósoknak vagy a finomhangolóknak validálniuk kell az eredményeket, és nem csak a precíziós mérőszámok, hanem más képességek, például a késleltetés és a költségek tekintetében is ki kell választaniuk a megfelelő FM-et. Ezután telepíthetnek egy modellt egy SageMaker végpontra, és kis léptékben tesztelhetik a teljesítményét. Míg a kísérletezési szakasz magában foglalhat egy egyszerű folyamatot is, a gyártásra való átállás megköveteli az ügyfelektől, hogy automatizálják a folyamatot, és növeljék a megoldás robusztusságát. Ezért mélyrehatóan el kell merülnünk az értékelés automatizálásában, lehetővé téve a tesztelők számára, hogy nagy léptékben végezzenek hatékony értékelést, és megvalósítsák a modell bemeneti és kimeneti valós idejű monitorozását.
Az FM kiértékelés automatizálása
Az Amazon SageMaker Pipelines automatizálja az előfeldolgozás, az FM-finomhangolás (opcionális) és a kiértékelés összes fázisát. Tekintettel a kísérlet során kiválasztott modellekre, az azonnali mérnököknek az esetek nagyobb halmazát kell lefedniük úgy, hogy számos promptot készítenek és tárolnak egy kijelölt tárolóhelyen, amelyet prompt katalógusnak neveznek. További információkért lásd: FMOps/LLMOps: Operacionalizálja a generatív AI-t és a különbségeket MLOp-okkal. Ezután az Amazon SageMaker Pipelines a következőképpen strukturálható:
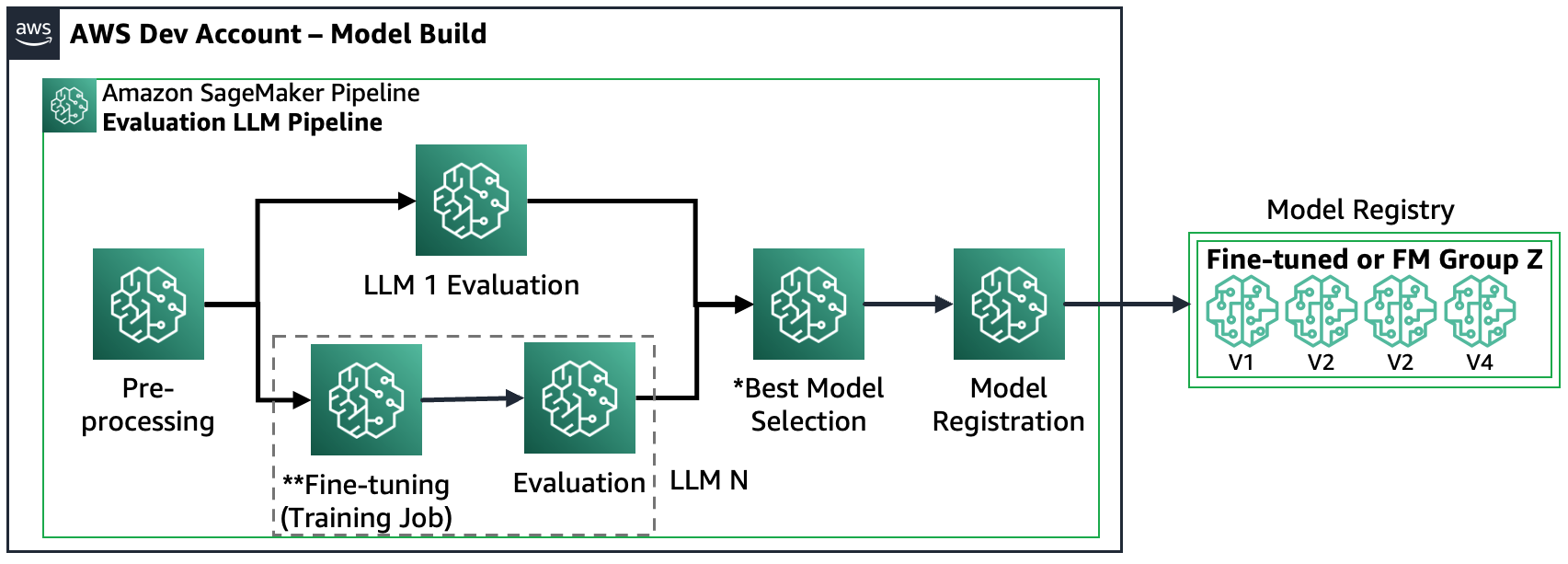
1. forgatókönyv – Több FM értékelése: Ebben a forgatókönyvben az FM-ek finomhangolás nélkül lefedhetik az üzleti felhasználást. Az Amazon SageMaker Pipeline a következő lépésekből áll: adatok előfeldolgozása, több FM párhuzamos kiértékelése, modellek összehasonlítása és kiválasztás a pontosság és egyéb tulajdonságok, például költség vagy késleltetés alapján, a kiválasztott modellműtermékek regisztrálása és metaadatok.
A következő diagram ezt az architektúrát szemlélteti.

2. forgatókönyv – Több FM finomhangolása és értékelése: Ebben a forgatókönyvben az Amazon SageMaker Pipeline felépítése hasonló az 1. forgatókönyvhöz, de párhuzamosan fut mind a finomhangolási, mind a kiértékelési lépésekben minden FM-re. A legjobban finomhangolt modell bekerül a Model Registry-be.
A következő diagram ezt az architektúrát szemlélteti.
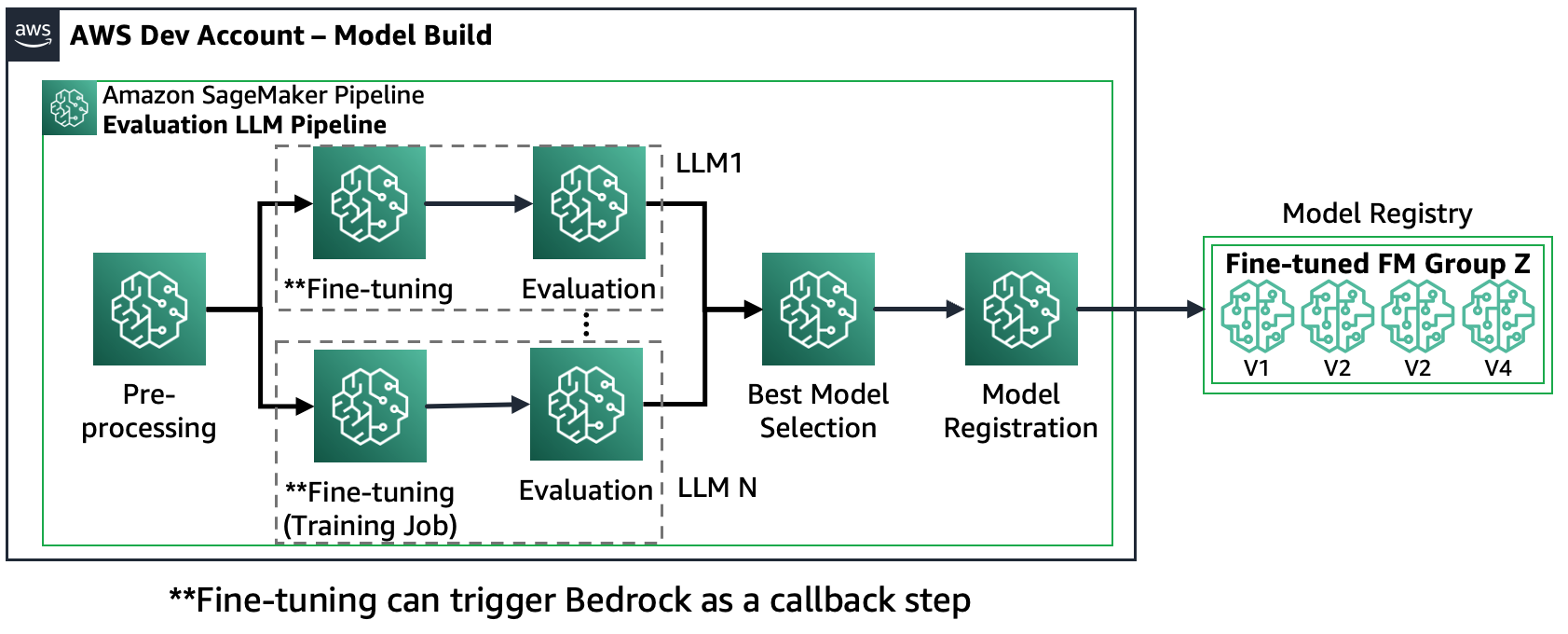
3. forgatókönyv – Több FM és finomhangolt FM értékelése: Ez a forgatókönyv az általános célú FM-ek és a finomhangolt FM-ek kiértékelésének kombinációja. Ebben az esetben az ügyfelek ellenőrizni akarják, hogy egy finomhangolt modell jobban teljesít-e, mint egy általános célú FM.
A következő ábra a kapott SageMaker Pipeline lépéseket mutatja be.
Vegye figyelembe, hogy a modellregisztráció két mintát követ: (a) egy nyílt forráskódú modellt és műtermékeket tárol, vagy (b) egy szabadalmaztatott FM-re való hivatkozást. További információkért lásd: FMOps/LLMOps: Operacionalizálja a generatív AI-t és a különbségeket MLOp-okkal.
Megoldás áttekintése
Annak érdekében, hogy felgyorsítsuk az LLM-kiértékeléshez vezető utat, létrehoztunk egy olyan megoldást, amely az Amazon SageMaker Clarify és az új Amazon SageMaker Pipelines SDK használatával valósítja meg a forgatókönyveket. A kódpélda, beleértve az adatkészleteket, a forrásjegyzetfüzeteket és a SageMaker-folyamatokat (lépések és ML-folyamat), elérhető itt: GitHub. Ennek a példamegoldásnak a kifejlesztéséhez két FM-et használtunk: Llama2-t és Falcon-7B-t. Ebben a bejegyzésben elsősorban a SageMaker Pipeline megoldás kulcsfontosságú elemeire összpontosítunk, amelyek az értékelési folyamathoz kapcsolódnak.
Értékelési konfiguráció: A kiértékelési eljárás szabványosítása érdekében létrehoztunk egy YAML konfigurációs fájlt (evaluation_config.yaml), amely tartalmazza az értékelési folyamathoz szükséges adatokat, beleértve az adatkészletet, a modell(eke)t és a futtatandó algoritmusokat. a SageMaker Pipeline értékelési lépése. A következő példa a konfigurációs fájlt szemlélteti:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Az értékelés lépése: Az új SageMaker Pipeline SDK rugalmasságot biztosít a felhasználóknak az ML munkafolyamat egyéni lépéseinek meghatározásához a „@step” Python-dekorátor segítségével. Ezért a felhasználóknak létre kell hozniuk egy alap Python-szkriptet, amely elvégzi az értékelést, az alábbiak szerint:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker Pipeline: A szükséges lépések, például az adatok előfeldolgozása, a modell üzembe helyezése és a modellértékelés létrehozása után a felhasználónak össze kell kapcsolnia a lépéseket a SageMaker Pipeline SDK használatával. Az új SDK automatikusan létrehozza a munkafolyamatot a különböző lépések közötti függőségek értelmezésével, amikor egy SageMaker Pipeline létrehozási API-t meghívnak, ahogy az a következő példában látható:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()A példa egyetlen FM kiértékelését valósítja meg a kezdeti adatkészlet előfeldolgozásával, a modell telepítésével és a kiértékelés futtatásával. A generált pipeline irányított aciklikus gráf (DAG) a következő ábrán látható.
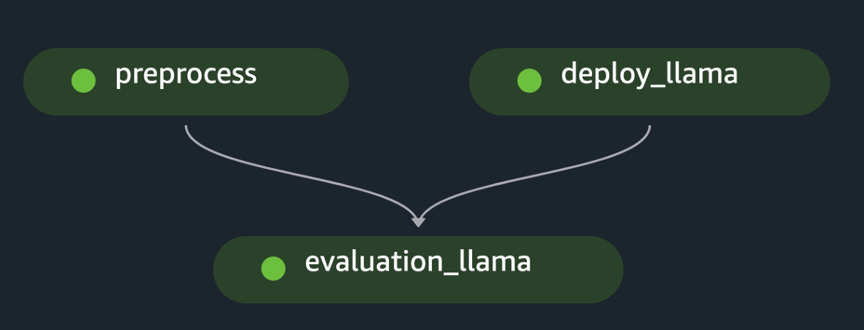
Hasonló megközelítést követve és a példát felhasználva és személyre szabva a Finomhangolja a LLaMA 2 modelleket a SageMaker JumpStarton, létrehoztuk a folyamatot egy finomhangolt modell értékeléséhez, ahogy az a következő ábrán látható.

A SageMaker Pipeline korábbi lépéseit „Lego” blokkként használva kifejlesztettük a megoldást az 1. és 3. forgatókönyvhöz, amint az a következő ábrákon látható. Konkrétan a GitHub A repository lehetővé teszi a felhasználó számára, hogy párhuzamosan több FM-et is kiértékeljen, vagy összetettebb kiértékelést végezzen, kombinálva az alapozó és a finomhangolt modellek értékelését.

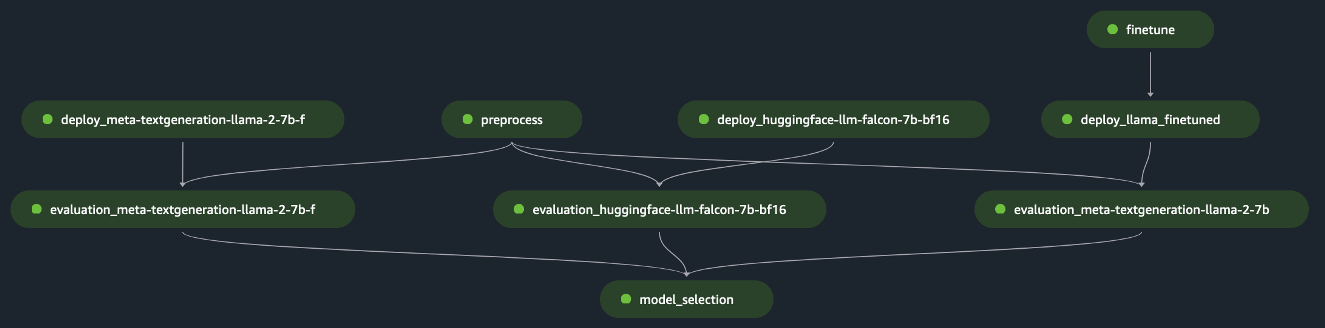
A tárolóban elérhető további funkciók a következők:
- Dinamikus kiértékelési lépések generálása: Megoldásunk dinamikusan generálja az összes szükséges kiértékelési lépést a konfigurációs fájl alapján, hogy a felhasználók tetszőleges számú modellt ki tudjanak értékelni. Kibővítettük a megoldást, hogy támogassa az új típusú modellek egyszerű integrációját, mint például a Hugging Face vagy az Amazon Bedrock.
- A végpontok újratelepítésének megakadályozása: Ha egy végpont már a helyén van, akkor kihagyjuk a telepítési folyamatot. Ez lehetővé teszi a felhasználó számára, hogy újra felhasználja a végpontokat az FM-ekkel az értékeléshez, ami költségmegtakarítást és rövidebb telepítési időt eredményez.
- Végpont tisztítás: Az értékelés befejezése után a SageMaker Pipeline leállítja a telepített végpontokat. Ez a funkció bővíthető a legjobb modell végpont életben tartásához.
- A modell kiválasztásának lépése: Hozzáadtunk egy modellkiválasztási lépés helyőrzőjét, amely megköveteli a végső modellkiválasztás üzleti logikáját, beleértve a költségeket vagy a késleltetést.
- Modell regisztrációs lépés: A legjobb modell egy adott modellcsoport új verziójaként regisztrálható az Amazon SageMaker Model Registry-be.
- Meleg medence: A SageMaker által felügyelt meleg medencék lehetővé teszik a kiépített infrastruktúra megtartását és újrafelhasználását egy feladat befejezése után az ismétlődő munkaterhelések késésének csökkentése érdekében
Az alábbi ábra szemlélteti ezeket a képességeket és egy többmodell-kiértékelési példát, amelyet a felhasználók egyszerűen és dinamikusan hozhatnak létre a mi megoldásunk segítségével. GitHub tárolóból.

Szándékosan nem hagytuk figyelmen kívül az adatok előkészítését, mivel azt egy másik bejegyzésben részletesen ismertetjük, beleértve az azonnali katalógusterveket, prompt sablonokat, azonnali optimalizálást. További információkért és a kapcsolódó alkatrészek definícióiért lásd: FMOps/LLMOps: Operacionalizálja a generatív AI-t és a különbségeket MLOp-okkal.
Következtetés
Ebben a bejegyzésben arra összpontosítottunk, hogyan automatizálhatjuk és operacionalizálhatjuk az LLM-ek értékelését az Amazon SageMaker Clarify LLM kiértékelési képességei és az Amazon SageMaker Pipelines segítségével. Ebben az elméleti architektúraterveken kívül példakódunk is van GitHub adattár (Llama2 és Falcon-7B FM-ekkel), hogy lehetővé tegye az ügyfelek számára, hogy saját méretezhető kiértékelési mechanizmusaikat fejlesszék.
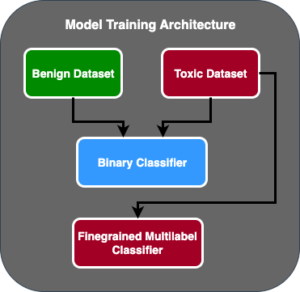
Az alábbi ábra a modellértékelési architektúrát mutatja be.
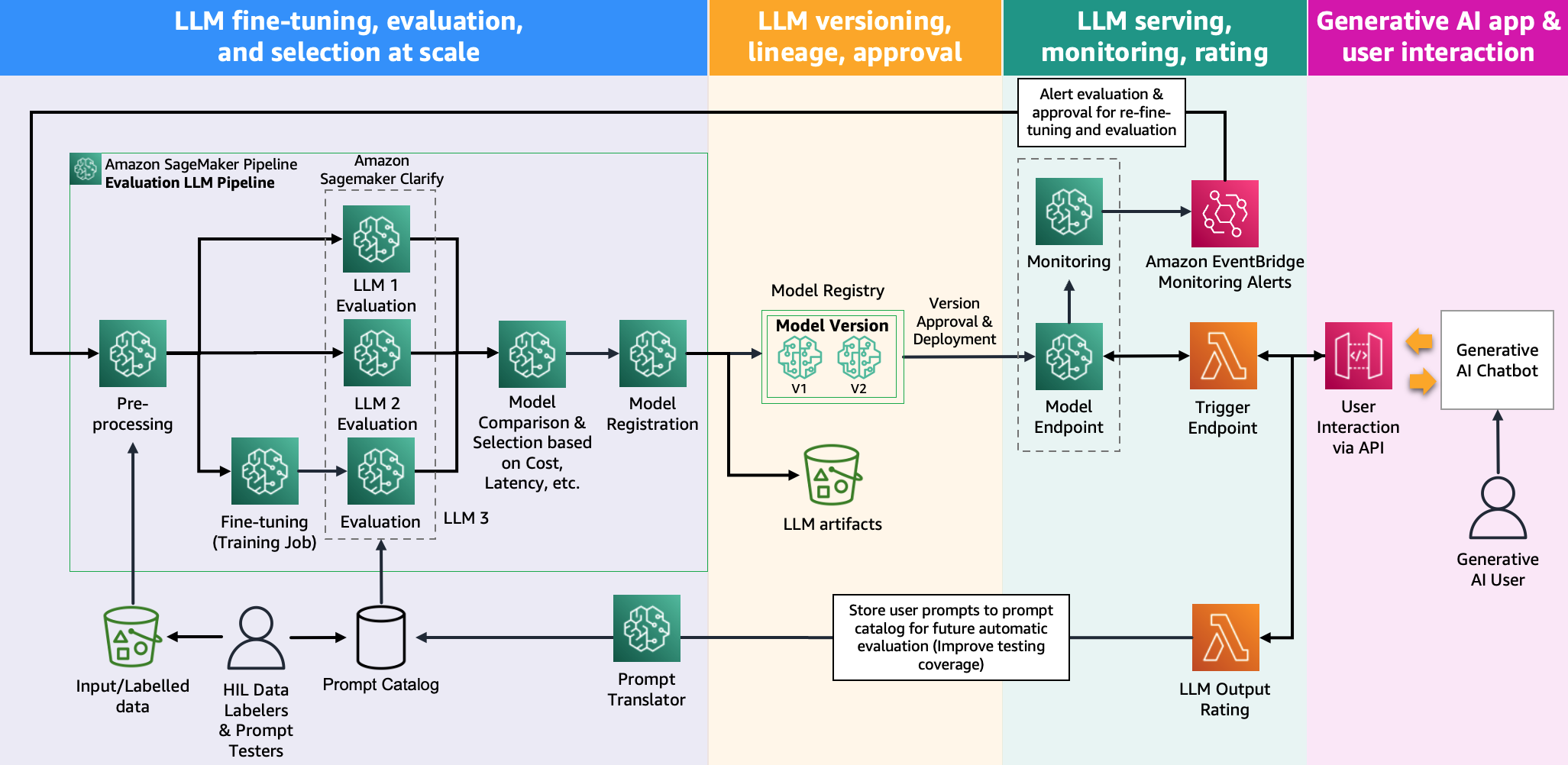
Ebben a bejegyzésben az LLM értékelés skálán történő operacionalizálására összpontosítottunk, amint az az ábra bal oldalán látható. Az FMOps/LLMOps: Operacionalizálja a generatív AI-t és a különbségeket MLOp-okkal. Ez magában foglalja az LLM kiszolgálását, felügyeletét, a kimeneti besorolások tárolását, amelyek végül automatikus újraértékelést és finomhangolást indítanak el, és végül a hurokban lévő embereket a címkézett adatokon vagy felszólítások katalógusán való munkához.
A szerzőkről
 Dr. Sokratis Kartakis az Amazon Web Services fő gépi tanulási és üzemeltetési specialistája. A Sokratis arra összpontosít, hogy lehetővé tegye a vállalati ügyfelek számára Machine Learning (ML) és generatív AI-megoldásaik iparosítását az AWS-szolgáltatások kiaknázásával és működési modelljük, azaz az MLOps/FMOps/LLMOps alapok és az átalakítási ütemterv kialakításával a legjobb fejlesztési gyakorlatok felhasználásával. Több mint 15 évet töltött innovatív, teljes körű termelési szintű ML és AI megoldások feltalálásával, tervezésével, vezetésével és megvalósításával az energia, a kiskereskedelem, az egészségügy, a pénzügy, a motorsport stb. területén.
Dr. Sokratis Kartakis az Amazon Web Services fő gépi tanulási és üzemeltetési specialistája. A Sokratis arra összpontosít, hogy lehetővé tegye a vállalati ügyfelek számára Machine Learning (ML) és generatív AI-megoldásaik iparosítását az AWS-szolgáltatások kiaknázásával és működési modelljük, azaz az MLOps/FMOps/LLMOps alapok és az átalakítási ütemterv kialakításával a legjobb fejlesztési gyakorlatok felhasználásával. Több mint 15 évet töltött innovatív, teljes körű termelési szintű ML és AI megoldások feltalálásával, tervezésével, vezetésével és megvalósításával az energia, a kiskereskedelem, az egészségügy, a pénzügy, a motorsport stb. területén.
 Jagdeep Singh Soni Senior Partner Solutions Architect a hollandiai székhelyű AWS-nél. A DevOps, a GenAI és az építőeszközök iránti szenvedélyét a rendszerintegrátorok és a technológiai partnerek támogatására használja. Jagdeep alkalmazásfejlesztési és architektúra hátterét alkalmazza csapatán belüli innováció ösztönzésére és az új technológiák népszerűsítésére.
Jagdeep Singh Soni Senior Partner Solutions Architect a hollandiai székhelyű AWS-nél. A DevOps, a GenAI és az építőeszközök iránti szenvedélyét a rendszerintegrátorok és a technológiai partnerek támogatására használja. Jagdeep alkalmazásfejlesztési és architektúra hátterét alkalmazza csapatán belüli innováció ösztönzésére és az új technológiák népszerűsítésére.
 Dr. Riccardo Gatti Senior Startup Solution Architect Olaszországban él. Technikai tanácsadó az ügyfelek számára, és segíti őket vállalkozásuk növekedésében azáltal, hogy kiválasztja a megfelelő eszközöket és technológiákat az innovációhoz, a gyors méretezéshez és a percek alatti globális piacra lépéshez. Mindig is szenvedélyes volt a gépi tanulás és a generatív mesterséges intelligencia iránt, hiszen karrierje során tanulmányozta és alkalmazta ezeket a technológiákat különböző területeken. A „Casa Startup” olasz AWS podcast házigazdája és szerkesztője, amely a startup alapítóiról és az új technológiai trendekről szól.
Dr. Riccardo Gatti Senior Startup Solution Architect Olaszországban él. Technikai tanácsadó az ügyfelek számára, és segíti őket vállalkozásuk növekedésében azáltal, hogy kiválasztja a megfelelő eszközöket és technológiákat az innovációhoz, a gyors méretezéshez és a percek alatti globális piacra lépéshez. Mindig is szenvedélyes volt a gépi tanulás és a generatív mesterséges intelligencia iránt, hiszen karrierje során tanulmányozta és alkalmazta ezeket a technológiákat különböző területeken. A „Casa Startup” olasz AWS podcast házigazdája és szerkesztője, amely a startup alapítóiról és az új technológiai trendekről szól.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 100
- 9
- a
- Rólunk
- gyorsul
- hozzáférés
- pontosság
- pontosan
- Elérése
- elérése
- át
- törvény
- Az aktiválás
- aktív
- aciklikus
- hozzáadott
- mellett
- Ezen kívül
- cím
- megfelelő
- igazgatás
- Elfogadása
- Örökbefogadás
- fejlesztések
- tanácsadó
- Után
- ellen
- szerek
- AI
- AI törvény
- AI rendszerek
- cél
- Célzás
- algoritmus
- algoritmusok
- Igazítás
- elevenen
- Minden termék
- lehetővé teszi, hogy
- már
- Is
- mindig
- amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon SageMaker csővezetékek
- Amazon SageMaker Studio
- Az Amazon Web Services
- an
- elemez
- és a
- Másik
- válasz
- bármilyen
- api
- Alkalmazás
- Application Development
- alkalmazások
- alkalmazott
- alkalmazandó
- megközelítés
- megfelelő
- építészet
- VANNAK
- területek
- érv
- AS
- értékeli
- értékelése
- értékelés
- értékelések
- At
- könyvvizsgálat
- automatizált
- Automatizált
- Automatikus
- automatikusan
- Automatizálás
- elérhető
- AWS
- b
- háttér
- alapján
- alapvető
- BE
- mert
- válik
- óta
- viselkedés
- benchmark
- összehasonlított
- referenciaértékek
- Előnyök
- BEST
- Jobb
- között
- Túl
- előítélet
- elfogult
- torzítások
- Blocks
- mindkét
- megsértésének
- szélesség
- hoz
- épít
- építész
- üzleti
- de
- by
- hívott
- kéri
- TUD
- jelölt
- képességek
- képes
- elfog
- Kártyák
- Karrier
- eset
- esetek
- katalógus
- bizonyos
- kihívás
- jellemzők
- olcsóbb
- ellenőrizze
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- választott
- besorolás
- osztályoz
- ragadozó ölyv
- kód
- kohéziós
- együttműködik
- kombináció
- kombinálása
- Közös
- közösség
- hasonló
- összehasonlítani
- képest
- összehasonlítás
- Kiegészítés
- befejezés
- bonyolult
- bonyolultság
- teljesítés
- megfelelnek
- összetevő
- alkatrészek
- azzal jellemezve,
- számítási
- Kiszámít
- koncepció
- Vonatkozik
- Magatartás
- vezető
- magatartások
- Configuration
- Csatlakozás
- összeköt
- figyelembe vett
- áll
- konstrukció
- Fogyasztók
- Konténer
- tartalmaz
- tartalom
- kontextus
- folyamatosan
- folyamatos
- kontraszt
- társalgó
- beszélgetések
- megtérít
- kijavítására
- Költség
- költségmegtakarítás
- drága
- kiadások
- terjed
- teremt
- készítette
- létrehozása
- teremtés
- kritériumok
- kritikai
- kritikus
- szokás
- Ügyfelek
- DAG
- dátum
- Adatok előkészítése
- adattudós
- adatbiztonság
- adatkészlet
- adatok manipulálása
- adatkészletek
- dátum idő
- dönt
- Döntéshozatal
- határozatok
- elszánt
- mély
- mély merülést
- alapértelmezett
- meghatározott
- definíciók
- szállít
- Kereslet
- függőségek
- függ
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- mélység
- leírt
- kijelölt
- tervezett
- tervezés
- tervek
- vágy
- kívánatos
- részletes
- részletek
- Fejleszt
- fejlett
- fejlesztése
- Fejlesztés
- DevOps
- különbségek
- különböző
- közvetlen
- irányított
- merülés
- számos
- do
- Nem
- domain
- domainek
- hajtás
- alatt
- dinamikusan
- e
- minden
- könnyen
- könnyű
- szerkesztő
- Hatékony
- hatékonyság
- hatékony
- eredményesen
- erőfeszítés
- bármelyik
- elemek
- más
- munkavállaló
- lehetővé
- lehetővé teszi
- lehetővé téve
- végtől végig
- Endpoint
- végpontok
- energia
- Mérnökök
- növelése
- biztosítására
- biztosítja
- biztosítása
- Vállalkozás
- vállalati ügyfelek
- Vállalatok
- korszak
- egyaránt
- különösen
- alapvető
- stb.
- Eter (ETH)
- EU
- értékelni
- értékelték
- értékelő
- értékelés
- Még
- végül is
- példa
- példák
- végrehajtó
- létező
- várakozások
- várható
- gyors
- terjed
- kiterjedt
- külső
- kitermelés
- f1
- Arc
- megkönnyítését
- tényezők
- Tényleges
- méltányosság
- Vízesés
- hamis
- híres
- GYORS
- gyorsabb
- Funkció
- Featuring
- Visszacsatolás
- kevés
- mező
- Ábra
- ábrák
- filé
- utolsó
- Végül
- finanszíroz
- pénzügyi
- Pénzügyi szektor
- vezetéknév
- Rugalmasság
- Összpontosít
- összpontosított
- koncentrál
- követ
- következő
- következik
- A
- forma
- Alapítvány
- Alapok
- alapítók
- Keretrendszer
- keretek
- gyakran
- ból ből
- teljesítése
- Tele
- funkciós
- funkcionalitás
- alapvető
- Továbbá
- jövő
- gyűjtése
- általános
- Általános rendeltetésű
- generál
- generált
- generál
- generáló
- generáció
- nemző
- Generatív AI
- kap
- adott
- Globális
- Go
- biztosít
- grafikon
- Csoport
- Csoportok
- Növekvő
- kéz
- káros
- hasznosítása
- Legyen
- tekintettel
- he
- Egészség
- súlyosan
- segít
- segít
- segít
- Magas
- magas kockázatú
- zsanérok
- övé
- holding
- vendéglátó
- Hogyan
- How To
- azonban
- HTML
- HTTPS
- emberi
- i
- IAM
- azonosított
- azonosítja
- azonosítani
- if
- illusztrálja
- képek
- végre
- végrehajtási
- munkagépek
- importál
- fontosság
- javulás
- fejlesztések
- in
- tartalmaz
- magában foglalja a
- Beleértve
- Bejegyzett
- amely magában foglalja
- mutatók
- iparágak
- információ
- tájékoztatták
- Infrastruktúra
- kezdetben
- újít
- Innováció
- újító
- bemenet
- bemenet
- integrálni
- integráció
- szándékosan
- kölcsönhatások
- belső
- bele
- bevezet
- hivatkozni
- vonja
- részt
- jár
- bevonásával
- ISO
- IT
- olasz
- Olaszország
- tételek
- ismétlés
- ITS
- Munka
- utazás
- jpg
- Tart
- tartotta
- Kulcs
- tudás
- nyelv
- nagy
- nagyobb
- keresztnév
- végül
- Késleltetés
- vezet
- ranglisták
- vezető
- tanulás
- balra
- hadd
- erőfölény
- könyvtár
- életciklus
- mint
- Korlátozott
- LINK
- Láma
- elhelyezkedés
- logika
- Elő/Utó
- gép
- gépi tanulás
- Fő
- fenntartása
- fenntartja
- sikerült
- manipuláló
- manipulációk
- kézikönyv
- sok
- Lehet..
- Közben
- intézkedés
- intézkedések
- mechanizmusok
- Metaadatok
- módszer
- mód
- metrikus
- Metrics
- minimalizálása
- jegyzőkönyv
- félrevezető tájékoztatás
- Enyhít
- enyhítő
- ML
- MLOps
- modell
- modellek
- modul
- monitor
- ellenőrzés
- több
- a legtöbb
- motivált
- Motorsport
- sok
- többszörös
- kell
- név
- elengedhetetlen
- Szükség
- igények
- Hollandia
- Új
- Új technológiák
- következő
- nem szakértők
- megjegyezni
- jegyzetfüzet
- laptopok
- árnyalatok
- szám
- of
- ajánlat
- gyakran
- on
- egyszer
- ONE
- folyamatban lévő
- csak
- nyílt forráskódú
- üzemeltetési
- működés
- Művelet
- Vélemények
- optimalizálás
- or
- OS
- Más
- mi
- ki
- Eredmény
- eredmények
- teljesítmény
- kimenetek
- kiemelkedő
- felett
- átfogó
- saját
- tulajdonosok
- Párhuzamos
- paraméterek
- különös
- különösen
- partner
- partnerek
- szenvedély
- szenvedélyes
- ösvény
- minták
- Emberek (People)
- teljesít
- teljesítmény
- előadások
- Előadja
- fázis
- PII
- csővezeték
- Hely
- placeholder
- Plató
- Platón adatintelligencia
- PlatoData
- PoC
- podcast
- pont
- medence
- medencék
- állás
- utófeldolgozás
- potenciális
- hatalom
- powered
- gyakorlat
- Pontosság
- előkészítés
- előkészítése
- jelenlét
- megakadályozása
- előző
- elsődleges
- Fő
- elvek
- magánélet
- magán
- Probléma
- eljárás
- folyamat
- Folyamatok
- feldolgozás
- Termelés
- haladás
- kiemelkedés
- ígéret
- kellene támogatnia,
- utasításokat
- bizonyíték
- bizonyíték a koncepcióra
- szaporítás
- ingatlanait
- szabadalmazott
- védelme
- Bizonyít
- ad
- szolgáltatók
- biztosít
- amely
- nyilvános
- nyilvánosan
- cél
- Piton
- minőségi
- világítás
- mennyiségi
- kérdés
- hatótávolság
- Arány
- értékelés
- igazi
- való Világ
- real-time
- csökkenteni
- Csökkent
- csökkentő
- utal
- referencia
- nyilvántartott
- Bejegyzés
- iktató hivatal
- regresszió
- szabályos
- szabályozott
- szabályozott iparágak
- előírások
- megerősítő tanulás
- összefüggő
- relevancia
- megbízhatóság
- ismétlő
- jelentést
- Jelentő
- Jelentések
- raktár
- reprezentatív
- kötelező
- megköveteli,
- kutatás
- kutatók
- erőforrás-igényes
- Tudástár
- felelősség
- felelős
- kapott
- Eredmények
- kiskereskedelem
- megtartása
- visszatérés
- újra
- Kritika
- Optimális
- jobb
- szigorú
- felkelt
- Kockázat
- kockázatok
- ütemterv
- erős
- robusztusság
- Szerep
- szerepek
- futás
- futás
- fut
- s
- biztonságos
- biztosítékok
- sagemaker
- SageMaker csővezetékek
- Megtakarítás
- skálázhatóság
- skálázható
- Skála
- forgatókönyv
- forgatókönyvek
- Tudós
- tudósok
- hatálya
- pontszám
- forgatókönyv
- sdk
- zökkenőmentesen
- szakaszok
- szektor
- biztonság
- biztonság
- biztonsági kockázatok
- válasszuk
- kiválasztott
- kiválasztása
- kiválasztás
- idősebb
- érzés
- szolgál
- szolgáltatás
- Szolgáltatások
- szolgáló
- ülés
- készlet
- formálás
- Megosztás
- előadás
- mutatott
- Műsorok
- oldal
- jelentős
- hasonló
- egyszerűsíti
- egyszerűen
- óta
- egyetlen
- kicsi
- megoldások
- Megoldások
- SOLVE
- néhány
- forrás
- arasz
- szakember
- különleges
- kifejezetten
- költött
- színpadra állítás
- érdekeltek
- szabványosítása
- szabványok
- Stanford
- Kezdve
- kezdődik
- indítás
- Állapot
- Lépés
- Lépései
- Még mindig
- tárolás
- tárolni
- TÖRTÉNETEK
- egyértelmű
- szerkesztett
- tanult
- stúdió
- stílus
- Később
- ilyen
- ÖSSZEFOGLALÓ
- támogatás
- rendszer
- Systems
- szabászat
- Feladat
- feladatok
- csapat
- csapat
- Műszaki
- technikák
- technikai
- Technologies
- Technológia
- sablonok
- teszt
- tesztelők
- Tesztelés
- tesztek
- szöveg
- mint
- hogy
- A
- A jövő
- azok
- Őket
- akkor
- elméleti
- ezáltal
- ebből adódóan
- Ezek
- ők
- ezt
- azok
- három
- Keresztül
- egész
- idő
- nak nek
- együtt
- szerszám
- szerszámok
- vágány
- Vonat
- kiképzett
- Képzések
- vonatok
- Átalakítás
- átmenet
- átálláshoz
- Fordítás
- Trends
- kiváltó
- igaz
- megbízható
- kettő
- típusok
- tipikus
- Végül
- jogtalan
- megért
- megértés
- példátlan
- közelgő
- használ
- használati eset
- használt
- használó
- Felhasználók
- használ
- segítségével
- rendszerint
- hasznosít
- ÉRVÉNYESÍT
- Értékes
- különféle
- változat
- keresztül
- fontos
- sérülékenységek
- akar
- meleg
- we
- háló
- webes szolgáltatások
- JÓL
- voltak
- Mit
- amikor
- ami
- míg
- WHO
- széles
- Széleskörű
- Wikipedia
- lesz
- val vel
- belül
- nélkül
- Munka
- munkafolyamat
- dolgozó
- világ
- yaml
- év
- Hozam
- te
- A te
- zephyrnet