Szponzorált Hozzászólás

A multimodális modellek elölről történő felépítésének kihívásai
Számos gépi tanulási felhasználási esetben a szervezetek kizárólag táblázatos adatokra és faalapú modellekre hagyatkoznak, mint például az XGBoost és a LightGBM. Ennek az az oka, hogy a mély tanulás egyszerűen túl nehéz a legtöbb ML-csapat számára. A gyakori kihívások a következők:
- A komplex mély tanulási modellek kidolgozásához szükséges szakértői ismeretek hiánya
- Az olyan keretrendszerek, mint a PyTorch és a Tensorflow, megkövetelik a csapatoktól, hogy több ezer sornyi kódot írjanak, amelyek hajlamosak emberi hibákra
- Az elosztott DL-folyamatok betanítása mély infrastruktúra-ismeretet igényel, és hetekig is eltarthat a modellek betanítása
Ennek eredményeként a csapatok lemaradnak a strukturálatlan adatokban, például szövegekben és képekben rejtett értékes jelekről.
Gyors modellfejlesztés deklaratív rendszerekkel
Az új deklaratív gépi tanulási rendszerek – mint például a nyílt forráskódú Ludwig az Ubernél – alacsony kódú megközelítést kínálnak az ML automatizálására, amely lehetővé teszi az adatcsapatok számára, hogy egy egyszerű konfigurációs fájl segítségével gyorsabban építsék fel és telepítsék a legkorszerűbb modelleket. Pontosabban, a Predibase – a vezető alacsony kódú deklaratív ML platform – a Ludwig mellett megkönnyíti a multimodális mély tanulási modellek felépítését 15 kódsor alatt.
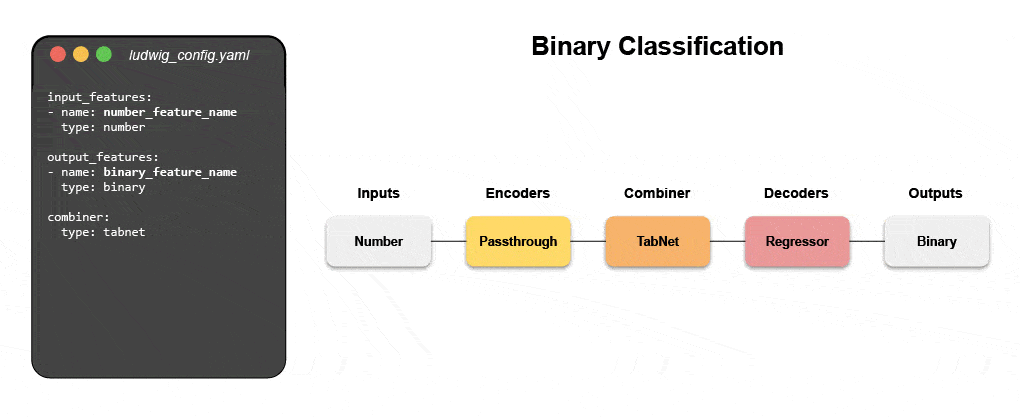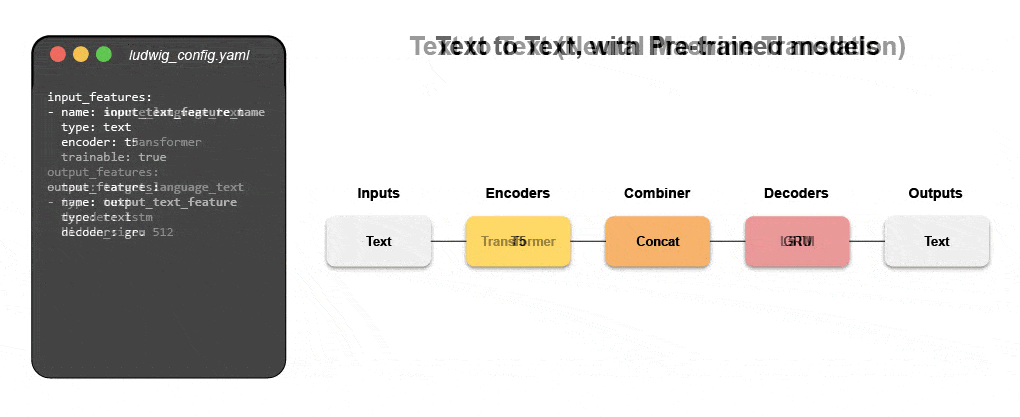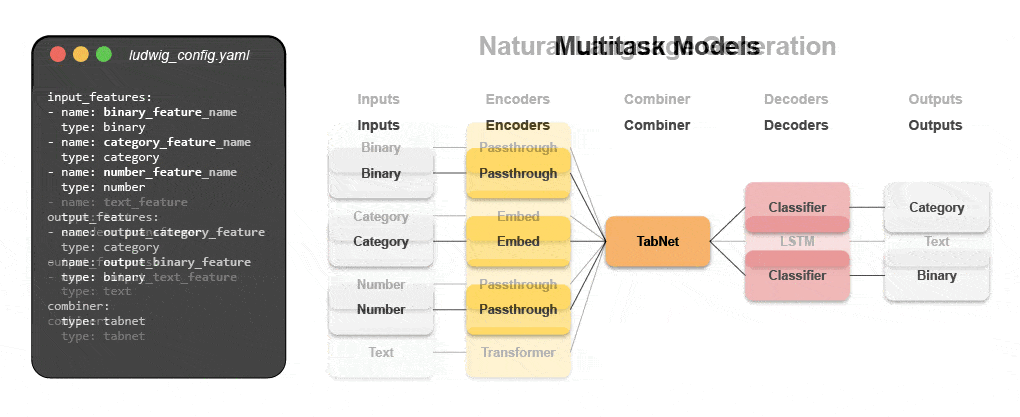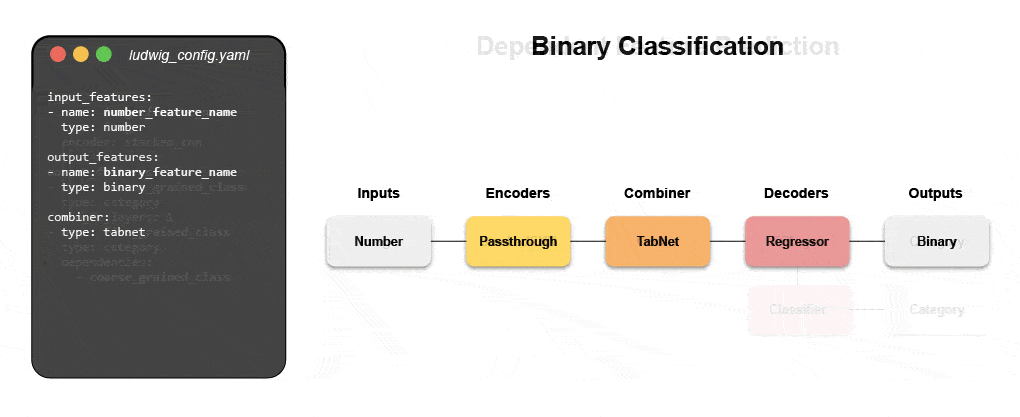
Ismerje meg, hogyan építhet fel egy multimodális modellt deklaratív ML segítségével
Csatlakozzon közelgő webináriumunkhoz és élő oktatóanyag, amellyel megismerheti a deklaratív rendszereket, például a Ludwig-ot, és kövesse a lépésről lépésre szóló utasításokat a szöveges és táblázatos adatok felhasználásával készült multimodális vásárlói vélemény előrejelzési modell felépítéséhez.
Ezen a foglalkozáson megtanulod, hogyan:
- Gyorsan betaníthat, iterálhat és telepíthet egy multimodális modellt az ügyfelek véleményének előrejelzéséhez,
- Használjon alacsony kódú deklaratív ML-eszközöket, hogy drámai módon csökkentse a több ML-modell elkészítéséhez szükséges időt,
- Használja ki a strukturálatlan adatokat ugyanolyan egyszerűen, mint a strukturált adatokat a nyílt forráskódú Ludwig és Predibase segítségével
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/01/predibase-multi-modal-deep-learning-less-15-lines-code.html?utm_source=rss&utm_medium=rss&utm_campaign=multi-modal-deep-learning-in-less-than-15-lines-of-code
- a
- Rólunk
- és a
- megközelítés
- automatizálás
- mert
- épít
- Épület
- kihívások
- kód
- Közös
- bonyolult
- Configuration
- vevő
- dátum
- mély
- mély tanulás
- telepíteni
- Fejleszt
- Fejlesztés
- megosztott
- drámaian
- könnyen
- lehetővé teszi
- hiba
- szakértő
- gyorsabb
- filé
- következik
- ból ből
- gif
- Kemény
- Rejtett
- Hogyan
- How To
- HTML
- HTTPS
- emberi
- képek
- in
- tartalmaz
- Infrastruktúra
- utasítás
- IT
- KDnuggets
- tudás
- vezető
- TANUL
- tanulás
- erőfölény
- vonalak
- él
- gép
- gépi tanulás
- csinál
- sok
- ML
- modell
- modellek
- a legtöbb
- többszörös
- szükséges
- nyílt forráskódú
- szervezetek
- Plató
- Platón adatintelligencia
- PlatoData
- előrejelzés
- Tippek
- pytorch
- csökkenteni
- szükség
- megköveteli,
- eredményez
- Kritika
- ülés
- jelek
- Egyszerű
- egyszerűen
- kifejezetten
- kezdődött
- csúcs-
- Lépés
- szerkesztett
- Systems
- Vesz
- tart
- csapat
- tensorflow
- A
- ezer
- idő
- nak nek
- is
- szerszámok
- Vonat
- oktatói
- közelgő
- felhasználási esetek
- Értékes
- Hetek
- lesz
- belül
- ír
- XGBoost
- A te
- zephyrnet





