Ezt a bejegyzést Pramod Nayak, LakshmiKanth Mannem és Vivek Aggarwal írta az LSEG Low Latency Group-ból.
A tranzakciós költségelemzést (TCA) a kereskedők, portfóliókezelők és brókerek széles körben használják kereskedés előtti és utáni elemzéshez, és segít mérni és optimalizálni a tranzakciós költségeket és kereskedési stratégiáik hatékonyságát. Ebben a bejegyzésben elemezzük a licit-ask spreadeket a LSEG Tick History – PCAP adatkészlet használatával Amazon Athena az Apache Spark számára. Megmutatjuk, hogyan férhet hozzá az adatokhoz, hogyan határozhat meg az adatokra alkalmazható egyedi függvényeket, hogyan kérdezheti le és szűrheti az adatkészletet, és vizualizálhatja az elemzés eredményeit – mindezt anélkül, hogy az infrastruktúra beállításával vagy a Spark konfigurálásával kellene aggódnia, még nagy adatkészletek esetén is.
Háttér
Az Options Price Reporting Authority (OPRA) kulcsfontosságú értékpapír-információ-feldolgozóként szolgál, gyűjti, konszolidálja és terjeszti az utolsó eladási jelentéseket, árajánlatokat és az egyesült államokbeli opciókkal kapcsolatos vonatkozó információkat. 18 aktív amerikai opciós tőzsdével és több mint 1.5 millió jogosult szerződéssel az OPRA kulcsszerepet játszik az átfogó piaci adatok biztosításában.
5. február 2024-én a Securities Industry Automation Corporation (SIAC) 48-ról 96 multicast csatornára frissíti az OPRA feedet. Ennek a fejlesztésnek az a célja, hogy optimalizálja a szimbólumeloszlást és a vonalkapacitás kihasználtságát, válaszul a kereskedési tevékenység fokozódására és az amerikai opciós piac volatilitására. A SIAC azt javasolta, hogy a cégek készüljenek fel a legfeljebb 37.3 GB/s adatátviteli sebességre.
Annak ellenére, hogy a frissítés nem változtatja meg azonnal a közzétett adatok teljes mennyiségét, lehetővé teszi az OPRA számára, hogy lényegesen gyorsabban terjessze az adatokat. Ez az átállás döntő fontosságú a dinamikus opciós piac igényeinek kielégítéséhez.
Az OPRA kiemelkedik az egyik legterjedelmesebb hírcsatornából: 150.4 harmadik negyedévében egyetlen nap alatt 3 milliárd üzenet érkezik, és a kapacitásigénye 2023 milliárd üzenet egyetlen nap alatt. Minden egyes üzenet rögzítése kritikus fontosságú a tranzakciós költségelemzés, a piaci likviditás figyelése, a kereskedési stratégia értékelése és a piackutatás szempontjából.
Az adatokról
LSEG Tick History – PCAP egy felhő alapú adattár, amely meghaladja a 30 PB-t, és rendkívül jó minőségű globális piaci adatokat tárol. Ezeket az adatokat aprólékosan rögzítik közvetlenül az adatcsere-adatközpontokban, redundáns rögzítési folyamatok alkalmazásával, amelyek stratégiailag elhelyezkednek a világ fő elsődleges és tartalék adatközpontjaiban. Az LSEG rögzítési technológiája veszteségmentes adatrögzítést biztosít, és GPS-időforrást használ a nanoszekundumos időbélyeg pontosságához. Ezenkívül kifinomult adatarbitrázs technikákat alkalmaznak az adathiányok zökkenőmentes kitöltésére. A rögzítést követően az adatok aprólékos feldolgozáson és döntésen esnek át, majd a parketta formátumba normalizálódnak. Az LSEG Real Time Ultra Direct (RTUD) takarmánykezelők.
A normalizálási folyamat, amely az adatok elemzésre való előkészítésének szerves részét képezi, akár 6 TB tömörített Parquet fájlt generál naponta. Az adatok hatalmas mennyisége az OPRA átfogó jellegének tudható be, amely több tőzsdére is kiterjed, és számos opciós szerződést tartalmaz, amelyeket különböző tulajdonságok jellemeznek. A megnövekedett piaci volatilitás és az opciós tőzsdék árjegyzői tevékenysége tovább járul hozzá az OPRA-n közzétett adatok mennyiségéhez.
A Tick History – PCAP attribútumai lehetővé teszik a cégek számára, hogy különféle elemzéseket végezzenek, beleértve a következőket:
- Kereskedés előtti elemzés – Értékelje a lehetséges kereskedelmi hatásokat, és fedezze fel a különböző végrehajtási stratégiákat a korábbi adatok alapján
- Kereskedés utáni értékelés – Mérje meg a tényleges végrehajtási költségeket a referenciaértékekkel összehasonlítva a végrehajtási stratégiák teljesítményének felmérése érdekében
- optimalizált végrehajtás – A végrehajtási stratégiák finomhangolása a múltbeli piaci minták alapján a piaci hatás minimalizálása és az általános kereskedési költségek csökkentése érdekében
- Kockázat kezelés – A csúszási minták azonosítása, a kiugró értékek azonosítása és a kereskedési tevékenységekkel kapcsolatos kockázatok proaktív kezelése
- Teljesítmény-hozzárendelés – A portfólió teljesítményének elemzésekor válassza el a kereskedési döntések hatását a befektetési döntésektől
Az LSEG Tick History – PCAP adatkészlet itt érhető el AWS adatcsere és a címen érhető el AWS piactér. A AWS adatcsere az Amazon S3-hoz, közvetlenül az LSEG-ből érheti el a PCAP-adatokat Amazon egyszerű tárolási szolgáltatás (Amazon S3). Ez a megközelítés leegyszerűsíti az adatkezelést és -tárolást, azonnali hozzáférést biztosítva az ügyfeleknek a kiváló minőségű PCAP-hoz vagy normalizált adatokhoz, könnyen használható, integrálható és jelentős adattárolási megtakarítás.
Athena az Apache Spark számára
Az elemző törekvésekhez Athena az Apache Spark számára egyszerűsített notebook élményt kínál, amely az Athena konzolon vagy az Athena API-kon keresztül érhető el, lehetővé téve az interaktív Apache Spark alkalmazások létrehozását. Az optimalizált Spark futási idővel az Athena segíti a petabájtnyi adat elemzését azáltal, hogy dinamikusan skálázza a Spark-motorok számát egy másodpercnél kevesebbre. Ezenkívül a gyakori Python-könyvtárak, például a pandák és a NumPy zökkenőmentesen integrálódnak, lehetővé téve bonyolult alkalmazáslogika létrehozását. A rugalmasság kiterjed a notebookokban használható egyedi könyvtárak importálására is. Az Athena for Spark a legtöbb nyílt adatformátumhoz illeszkedik, és zökkenőmentesen integrálódik a AWS ragasztó Adatkatalógus.
adatbázisba
Ehhez az elemzéshez a 17. május 2023-i LSEG Tick History – PCAP OPRA adatkészletet használtuk. Ez az adatkészlet a következő összetevőket tartalmazza:
- Legjobb ajánlat és ajánlat (BBO) – Jelenti az adott tőzsdén a legmagasabb ajánlatot és a legalacsonyabb ajánlatot egy értékpapírra
- Országos legjobb ajánlat és ajánlat (NBBO) – Jelenti a legmagasabb ajánlatot és a legalacsonyabb értékpapírt az összes tőzsdén
- mesterségek – Rögzíti a befejezett kereskedéseket az összes tőzsdén
Az adatkészlet a következő adatmennyiségeket tartalmazza:
- mesterségek – 160 MB körülbelül 60 tömörített Parquet fájl között elosztva
- BBO – 2.4 TB körülbelül 300 tömörített Parquet fájl között elosztva
- NBBO – 2.8 TB körülbelül 200 tömörített Parquet fájl között elosztva
Elemzés áttekintése
Az OPRA Tick History adatainak elemzése a Tranzakciós Költségelemzéshez (TCA) magában foglalja a piaci jegyzések és kereskedések áttekintését egy adott kereskedelmi esemény körül. A tanulmány részeként a következő mutatókat használjuk:
- Idézett spread (QS) – A BBO-kérés és a BBO-ajánlat különbségeként számítva
- Hatékony spread (ES) – A kereskedési ár és a BBO felezőpontja közötti különbségként számítva (BBO licit + (BBO ask – BBO bid)/2)
- Effektív/idézett árrés (EQF) – Kiszámítva (ES / QS) * 100
Ezeket a felárakat a kereskedés előtt és négy időközönként a kereskedés után számítjuk ki (közvetlenül a kereskedés után, 1 másodperccel, 10 másodperccel és 60 másodperccel a kereskedés után).
Konfigurálja az Athena-t az Apache Sparkhoz
Az Athena Apache Sparkhoz való konfigurálásához hajtsa végre a következő lépéseket:
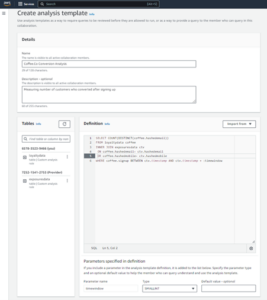
- Az Athena konzolon, alatt Első lépésekválassza Elemezze adatait PySpark és Spark SQL használatával.
- Ha először használja az Athena Sparkot, válassza a lehetőséget Munkacsoport létrehozása.

- A Munkacsoport neve¸ adjon meg egy nevet a munkacsoportnak, például
tca-analysis. - A Analytics motor válasszon Apache Spark.
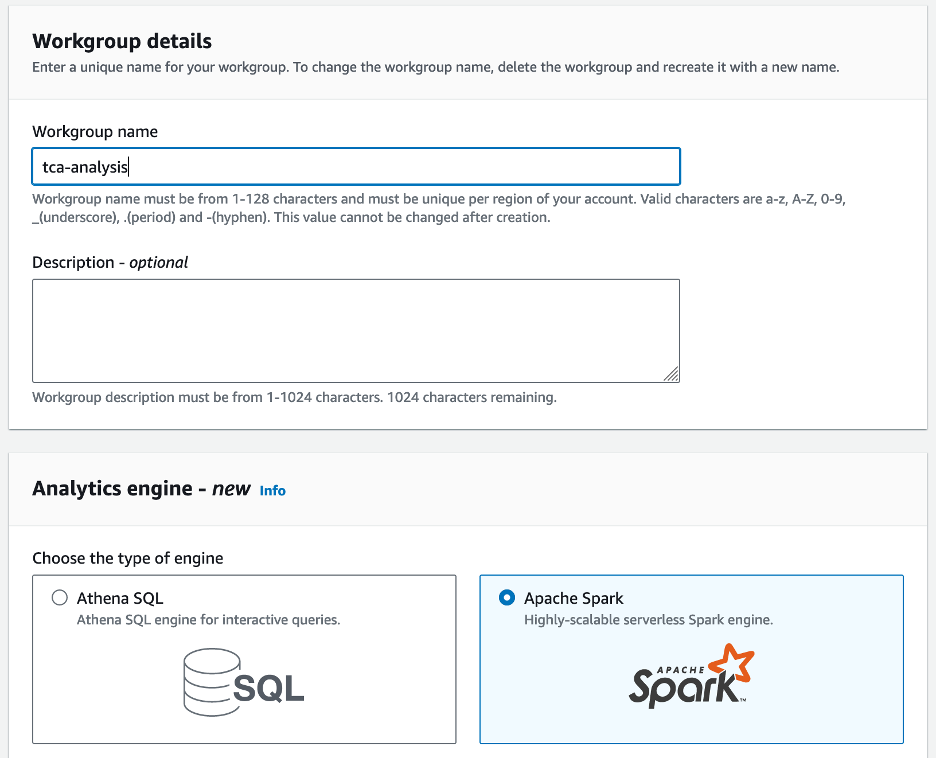
- A További konfigurációk részben választhat Alapértelmezések használata vagy egyéni AWS Identity and Access Management (IAM) szerepkör és Amazon S3 hely a számítási eredményekhez.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Munkacsoport létrehozása.
- A munkacsoport létrehozása után navigáljon a notebookok lapot és válasszon Jegyzetfüzet létrehozása.
- Adja meg a jegyzetfüzet nevét, például
tca-analysis-with-tick-history. - A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Teremt jegyzetfüzet létrehozásához.
Indítsa el a notebookját
Ha már létrehozott egy Spark-munkacsoportot, válassza a lehetőséget Indítsa el a notebook szerkesztőt alatt Első lépések.
![]()
A jegyzetfüzet létrehozása után a rendszer átirányítja az interaktív jegyzetfüzetszerkesztőhöz.
![]()
Most hozzáadhatjuk és futtathatjuk a következő kódot a notebookunkhoz.
Készítsen elemzést
Az elemzés elkészítéséhez hajtsa végre a következő lépéseket:
- Gyakori könyvtárak importálása:
- Hozza létre adatkereteinket BBO, NBBO és kereskedésekhez:
- Most azonosíthatunk egy kereskedést, amelyet a tranzakciós költségek elemzéséhez használunk:
A következő kimenetet kapjuk:
A kiemelt kereskedelmi információkat használjuk a továbbiakban a kereskedelmi termékre (tp), a kereskedési árra (tpr) és a kereskedési időre (tt).
- Itt számos segítő függvényt hozunk létre elemzésünkhöz
- A következő függvényben létrehozzuk azt az adatkészletet, amely tartalmazza az összes kereskedés előtti és utáni jegyzést. Az Athena Spark automatikusan meghatározza, hogy hány DPU-t indítson el az adatkészletünk feldolgozásához.
- Most hívjuk meg a TCA elemzési függvényt a kiválasztott kereskedésünkből származó információkkal:
Vizualizálja az elemzési eredményeket
Most hozzuk létre a vizualizációhoz használt adatkereteket. Minden adatkeret idézőjeleket tartalmaz az egyes adatfolyamokhoz tartozó öt időintervallum egyikéhez (BBO, NBBO):
A következő szakaszokban példakóddal szolgálunk különböző vizualizációk létrehozásához.
A kereskedés előtt ábrázolja a QS-t és az NBBO-t
Használja a következő kódot a jegyzett spread és az NBBO ábrázolásához a kereskedés előtt:
![]()
Minden piachoz ábrázolja a QS-t és a kereskedés után az NBBO-t
Használja a következő kódot az egyes piacok és NBBO jegyzett felárak ábrázolásához közvetlenül a kereskedés után:
![]()
Ábrázolja a QS-t minden időintervallumhoz és minden piachoz a BBO-hoz
Használja a következő kódot a jegyzett felárak ábrázolásához minden egyes időintervallumhoz és a BBO piacához:
![]()
Ábrázolja az ES-t minden időintervallumhoz és piachoz a BBO-hoz
Használja a következő kódot az egyes időintervallumokra és a BBO piacára vonatkozó effektív spread ábrázolásához:
Ábrázolja az EQF-et minden időintervallumhoz és piachoz a BBO-hoz
Használja a következő kódot az effektív/jegyzett felárak ábrázolásához minden egyes időintervallumhoz és a BBO piacához:
Athena Spark számítási teljesítmény
Kódblokk futtatásakor az Athena Spark automatikusan meghatározza, hogy hány DPU-ra van szüksége a számítás befejezéséhez. Az utolsó kódblokkban, ahol a tca_analysis függvényt, valójában a Sparkot utasítjuk az adatok feldolgozására, majd a kapott Spark-adatkereteket Pandas-adatkeretekké alakítjuk. Ez az elemzés legintenzívebb feldolgozási részét képezi, és amikor az Athena Spark futtatja ezt a blokkot, megmutatja a folyamatjelző sávot, az eltelt időt és azt, hogy hány DPU dolgoz fel jelenleg adatokat. Például a következő számításban az Athena Spark 18 DPU-t használ.
![]()
Az Athena Spark notebook konfigurálásakor beállíthatja az általa használható DPU-k maximális számát. Az alapértelmezett 20 DPU, de ezt a számítást 10, 20 és 40 DPU-val teszteltük, hogy bemutassuk, hogyan skálázódik automatikusan az Athena Spark az elemzés futtatásához. Megfigyeltük, hogy az Athena Spark lineárisan skálázódik: 15 perc és 21 másodperc, amikor a notebook maximum 10 DPU-val volt konfigurálva, 8 perc és 23 másodperc, ha a notebook 20 DPU-val volt konfigurálva, és 4 perc 44 másodperc, amikor a notebook 40 DPU-val konfigurálva. Mivel az Athena Spark a DPU-használat alapján számít, másodpercenkénti részletességgel, ezeknek a számításoknak a költsége hasonló, de ha magasabb maximális DPU-értéket állít be, az Athena Spark sokkal gyorsabban tudja visszaadni az elemzés eredményét. Az Athena Spark árakkal kapcsolatos további részletekért kattintson itt.
Következtetés
Ebben a bejegyzésben bemutattuk, hogyan használhatja fel az LSEG Tick History-PCAP-jából származó nagy pontosságú OPRA-adatokat a tranzakciós költségek elemzéséhez az Athena Spark segítségével. Az OPRA adatok időben történő elérhetősége, kiegészítve az AWS Data Exchange for Amazon S3 akadálymentesítési újításaival, stratégiailag lecsökkenti az elemzéshez szükséges időt azon cégek számára, amelyek a kritikus kereskedési döntésekhez hasznos betekintést szeretnének készíteni. Az OPRA naponta körülbelül 7 TB normalizált parketta adatot generál, és az infrastruktúra kezelése az OPRA adatokon alapuló elemzések biztosítására kihívást jelent.
Az Athena méretezhetősége a Tick History – PCAP for OPRA adatok nagy léptékű adatfeldolgozásának kezelésében – lenyűgöző választássá teszi az AWS-ben gyors és méretezhető elemzési megoldásokat kereső szervezetek számára. Ez a bejegyzés bemutatja az AWS ökoszisztéma és a Tick History-PCAP adatai közötti zökkenőmentes interakciót, és azt, hogy a pénzintézetek hogyan tudják kihasználni ezt a szinergiát az adatvezérelt döntéshozatal érdekében a kritikus kereskedési és befektetési stratégiákhoz.
A szerzőkről
![]() Pramod Nayak az LSEG Low Latency Group termékmenedzsment igazgatója. A Pramod több mint 10 éves tapasztalattal rendelkezik a pénzügyi technológiai iparágban, elsősorban a szoftverfejlesztésre, az elemzésekre és az adatkezelésre összpontosít. Pramod korábbi szoftvermérnök, és szenvedélyesen foglalkozik a piaci adatokkal és a mennyiségi kereskedéssel.
Pramod Nayak az LSEG Low Latency Group termékmenedzsment igazgatója. A Pramod több mint 10 éves tapasztalattal rendelkezik a pénzügyi technológiai iparágban, elsősorban a szoftverfejlesztésre, az elemzésekre és az adatkezelésre összpontosít. Pramod korábbi szoftvermérnök, és szenvedélyesen foglalkozik a piaci adatokkal és a mennyiségi kereskedéssel.
![]() LakshmiKanth Mannem az LSEG Low Latency Group termékmenedzsere. Az alacsony késleltetésű piaci adatipar adat- és platformtermékeire összpontosít. A LakshmiKanth segít az ügyfeleknek a legoptimálisabb megoldások kidolgozásában piaci adatigényeikhez.
LakshmiKanth Mannem az LSEG Low Latency Group termékmenedzsere. Az alacsony késleltetésű piaci adatipar adat- és platformtermékeire összpontosít. A LakshmiKanth segít az ügyfeleknek a legoptimálisabb megoldások kidolgozásában piaci adatigényeikhez.
![]() Vivek Aggarwal vezető adatmérnök az LSEG alacsony késleltetésű csoportjában. A Vivek adatfolyamok fejlesztésén és karbantartásán dolgozik a rögzített piaci adatfolyamok és referencia adatfolyamok feldolgozásához és szállításához.
Vivek Aggarwal vezető adatmérnök az LSEG alacsony késleltetésű csoportjában. A Vivek adatfolyamok fejlesztésén és karbantartásán dolgozik a rögzített piaci adatfolyamok és referencia adatfolyamok feldolgozásához és szállításához.
![]() Alket Memushaj az AWS pénzügyi szolgáltatások piacfejlesztési csapatának vezető építésze. Az Alket felelős a műszaki stratégiáért, partnerekkel és ügyfelekkel együttműködve, hogy még a legigényesebb tőkepiaci munkaterheléseket is telepítse az AWS felhőbe.
Alket Memushaj az AWS pénzügyi szolgáltatások piacfejlesztési csapatának vezető építésze. Az Alket felelős a műszaki stratégiáért, partnerekkel és ügyfelekkel együttműködve, hogy még a legigényesebb tőkepiaci munkaterheléseket is telepítse az AWS felhőbe.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Rólunk
- hozzáférés
- igénybe vett
- megközelíthetőség
- hozzáférhető
- át
- aktív
- tevékenység
- tényleges
- tulajdonképpen
- hozzá
- Ezen kívül
- címzés
- Előny
- Után
- ellen
- Aggarwal
- célok
- Minden termék
- lehetővé téve
- már
- amazon
- Amazon Athéné
- Az Amazon Web Services
- an
- elemzések
- elemzés
- Analitikai
- analitika
- elemez
- elemzése
- és a
- bármilyen
- Apache
- Apache Spark
- API-k
- Alkalmazás
- alkalmazások
- alkalmaz
- megközelítés
- körülbelül
- arbitrázs
- döntőbíráskodás
- VANNAK
- körül
- AS
- kérdez
- értékeli
- társult
- At
- attribútumok
- hatóság
- automatikusan
- Automatizálás
- elérhetőség
- elérhető
- AWS
- mentés
- bár
- alapján
- BE
- mert
- előtt
- referenciaértékek
- BEST
- között
- kínálat
- Billió
- Blokk
- brókerek
- épít
- de
- by
- számít
- számított
- számítás
- hívás
- TUD
- Kapacitás
- tőke
- Tőkepiacok
- elfog
- rögzített
- Rögzítése
- katalógus
- Centers
- kihívást
- csatornák
- jellemzett
- díjak
- választás
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- ügyfél részére
- felhő
- kód
- Gyűjtő
- Közös
- kényszerítő
- teljes
- Befejezett
- alkatrészek
- átfogó
- tartalmaz
- Magatartás
- konfigurálva
- konfigurálása
- Konzol
- megszilárdítása
- tartalmaz
- szerződések
- contribuer
- megtérít
- VÁLLALAT
- Költség
- kiadások
- társszerzője
- teremt
- készítette
- teremtés
- kritikai
- kritikus
- Jelenleg
- szokás
- Ügyfelek
- Gondolatjel
- dátum
- adatközpontok
- adatmérnök
- Adatcsere
- adatkezelés
- adatfeldolgozás
- adattárolás
- adatalapú
- adatkészletek
- nap
- Döntéshozatal
- határozatok
- alapértelmezett
- meghatározott
- kézbesítés
- igényes
- igények
- bizonyítani
- igazolták
- telepíteni
- részletek
- meghatározza
- fejlesztése
- Fejlesztés
- fejlesztői csapat
- különbség
- különböző
- közvetlenül
- Igazgató
- megosztott
- terjesztés
- számos
- kétszeresére
- hajtás
- dinamikus
- dinamikusan
- dinamika
- minden
- könnyű
- egyszerű használat
- ökoszisztéma
- szerkesztő
- Hatékony
- hatékonyság
- választható
- megszüntetése
- munkavállaló
- foglalkoztatás
- lehetővé
- lehetővé teszi
- átfogó
- törekvéseket
- Motor
- mérnök
- Motorok
- fokozás
- biztosítja
- belép
- fokozódó
- Eter (ETH)
- értékelni
- értékelés
- Még
- esemény
- Minden
- példa
- csere
- Feltételek
- végrehajtás
- tapasztalat
- feltárása
- expressz
- nyúlik
- gyorsabb
- Featuring
- február
- Füge
- Fájlok
- kitöltése
- szűrő
- pénzügyi
- Pénzintézetek
- pénzügyi szolgáltatások
- pénzügyi technológia
- cégek
- vezetéknév
- első
- öt
- Rugalmasság
- koncentrál
- összpontosítás
- következő
- A
- formátum
- Korábbi
- Előre
- négy
- KERET
- ból ből
- funkció
- funkciók
- további
- rések
- generál
- kap
- adott
- Globális
- világpiac
- Go
- megy
- gps
- Csoport
- Kezelés
- Legyen
- tekintettel
- he
- belmagasság
- segít
- jó minőségű
- <p></p>
- legnagyobb
- Kiemelt
- történeti
- történelem
- ház
- Hogyan
- How To
- http
- HTTPS
- IAM
- azonosítani
- Identitás
- if
- azonnali
- azonnal
- Hatás
- importál
- in
- Beleértve
- <p></p>
- ipar
- információ
- Infrastruktúra
- újítások
- meglátások
- intézmények
- szerves
- integrált
- integráció
- kölcsönhatás
- interaktív
- bele
- bonyolult
- beruházás
- jár
- IT
- jpg
- éppen
- nagy
- nagyarányú
- keresztnév
- Késleltetés
- indít
- kevesebb
- könyvtárak
- vonal
- fizetőképesség
- elhelyezkedés
- logika
- keres
- Elő/Utó
- legalacsonyabb
- fenntartása
- fontos
- KÉSZÍT
- Gyártás
- kezelése
- vezetés
- menedzser
- Menedzserek
- kezelése
- mód
- sok
- piacára
- Piaci adatok
- piaci hatást
- piackutatás
- Piaci volatilitás
- piacteremtés
- piacok
- tömeges
- mastering
- maximális
- Lehet..
- intézkedés
- üzenet
- üzenetek
- aprólékos
- aprólékosan
- Metrics
- millió
- minimalizálása
- jegyzőkönyv
- ellenőrzés
- több
- Ráadásul
- a legtöbb
- sok
- többszörös
- név
- Természet
- Keresse
- Szükség
- igények
- Egyik sem
- jegyzetfüzet
- laptopok
- szám
- számos
- számtalan
- megfigyelt
- of
- ajánlat
- Ajánlatok
- on
- ONE
- optimálisan
- Optimalizálja
- optimalizált
- opció
- Opciók
- or
- szervezetek
- mi
- ki
- teljesítmény
- felett
- átfogó
- saját
- pandák
- rész
- partnerek
- szenvedélyes
- minták
- Csúcs
- mert
- teljesít
- teljesítmény
- döntő
- emelvény
- Plató
- Platón adatintelligencia
- PlatoData
- játszik
- kérem
- cselekmény
- portfolió
- portfóliókezelők
- pozicionált
- állás
- kereskedés utáni
- potenciális
- Pontosság
- Készít
- előkészítése
- ár
- árazás
- elsődleges
- Fő
- folyamat
- Folyamatok
- feldolgozás
- Processzor
- Termékek
- termékmenedzsment
- termék menedzser
- Termékek
- Haladás
- ad
- amely
- közzétett
- Piton
- Q3
- mennyiségi
- mennyiség
- kérdés
- idézetek
- Arány
- Az árak
- Olvass
- igazi
- real-time
- ajánlott
- nyilvántartások
- Piros
- csökkenteni
- csökkenti
- referencia
- refinitiv
- Jelentő
- Jelentések
- raktár
- követelmény
- megköveteli,
- kutatás
- válasz
- felelős
- eredményez
- kapott
- Eredmények
- visszatérés
- kockázatok
- Szerep
- futás
- fut
- eladás
- skálázhatóság
- skálázható
- Mérleg
- skálázás
- zökkenőmentes
- zökkenőmentesen
- Második
- másodperc
- Rész
- szakaszok
- Értékpapír
- biztonság
- keres
- válasszuk
- kiválasztott
- idősebb
- különálló
- szolgálja
- Szolgáltatások
- készlet
- beállítás
- előadás
- Műsorok
- jelentősen
- hasonló
- Egyszerű
- egyszerűsített
- egyetlen
- csúszás
- szoftver
- szoftverfejlesztés
- Software Engineer
- Megoldások
- kifinomult
- feszültség
- Szikra
- különleges
- terjedése
- Kenhető
- állványok
- Lépései
- tárolás
- tárolni
- Stratégiailag
- stratégiák
- Stratégia
- egyszerűsíti
- Tanulmány
- későbbi
- ilyen
- SWIFT
- szimbólum
- szinergia
- Vesz
- bevétel
- csapat
- Műszaki
- technikák
- Technológia
- kipróbált
- mint
- hogy
- A
- az információ
- azok
- Őket
- akkor
- Ezek
- ezt
- Keresztül
- Jelöld be
- idő
- időszerű
- időbélyeg
- Cím
- nak nek
- Végösszeg
- tp
- TPR
- kereskedelem
- Kereskedők
- szakmák
- Kereskedés
- Trading Strategies
- kereskedési stratégia
- tranzakció
- tranzakciós költségek
- transzformáló
- átmenet
- Ultra
- alatt
- keresztülmegy
- frissítés
- us
- Használat
- használ
- használt
- használ
- segítségével
- kihasználva
- érték
- különféle
- megjelenítés
- Képzeld
- Illékonyság
- kötet
- kötetek
- volt
- we
- háló
- webes szolgáltatások
- amikor
- ami
- széles körben
- lesz
- val vel
- belül
- nélkül
- Munkacsoport
- dolgozó
- művek
- világszerte
- aggódik
- X
- év
- te
- A te
- zephyrnet