Bevezetés
Az összevonása mesterséges intelligencia (AI) és a művészet új utakat tár fel a kreatív digitális művészetben, a diffúziós modelleken keresztül. Ezek a modellek kiemelkednek a kreatív AI művészeti generációból, és a hagyományos neurális hálózatoktól eltérő megközelítést kínálnak. Ez a cikk egy felfedező utazásra vezet a diffúziós modellek mélyére, megvilágítva azok egyedi mechanizmusát a lenyűgöző és kreatívan gazdag műalkotások elkészítésében. Ismerje meg a diffúziós modellek árnyalatait, és nyerjen betekintést a művészi kifejezés újradefiniálásában betöltött szerepükbe a fejlett AI-technológiák lencséjén keresztül.

Tanulási célok
- Ismerje meg a diffúziós modellek alapfogalmait az AI-ban.
- Fedezze fel a diffúziós modellek és a hagyományos neurális hálózatok közötti különbséget a művészet generálásában.
- Elemezze a művészet létrehozásának folyamatát diffúziós modellek segítségével.
- Értékelje az AI kreatív és esztétikai vonatkozásait a digitális művészetben.
- Beszéljétek meg az AI által generált alkotások etikai szempontjait.
Ez a cikk részeként jelent meg Adattudományi Blogaton.
Tartalomjegyzék
A diffúziós modellek megértése

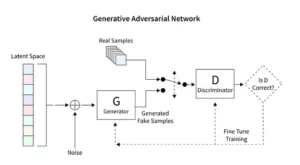
A diffúziós modellek forradalmasítják a generatív AI-t, és egyedülálló képalkotási módszert mutatnak be, amely különbözik az olyan hagyományos technikáktól, mint a Generatív Adversarial Networks (GAN). A véletlenszerű zajtól kezdve ezek a modellek fokozatosan finomítják azt, egy festményt finomhangoló művészhez hasonlítva, ami bonyolult és koherens képeket eredményez.
Ez a fokozatos finomítási folyamat a diffúzió módszeres természetét tükrözi. Itt minden iteráció finoman megváltoztatja a zajt, közelebb hozva azt a végső művészi látásmódhoz. Az eredmény nem pusztán a véletlenszerűség terméke, hanem egy továbbfejlesztett műalkotás, amely előrehaladása és befejezése tekintetében különbözik egymástól.
A diffúziós modellek kódolása megköveteli a neurális hálózatok és a gépi tanulási keretrendszerek, például a TensorFlow vagy a PyTorch alapos megértését. Az eredményül kapott kód bonyolult, és kiterjedt adathalmazokon való alapos képzést igényel az AI által generált művészetben megfigyelt árnyalt hatások eléréséhez.
Stabil diffúzió alkalmazása az Art
A mesterséges intelligencia generátorok, például a stabil diffúziós modellek megjelenése kifinomult kódolást igényel az olyan platformokon belül, mint a TensorFlow vagy a PyTorch. Ezek a modellek kitűnnek azzal a képességükkel, hogy a véletlenszerűséget módszeresen struktúrává alakítják, hasonlóan egy művészhez, aki egy előzetes vázlatot élénk remekművé csiszol.
A stabil diffúziós modellek úgy alakítják át a mesterséges intelligencia művészeti színterét, hogy a véletlenszerűségből rendezett képeket faragnak, elkerülve a GAN-okra jellemző versenydinamikát. Kiemelkednek abban, hogy a konceptuális felszólításokat vizuális művészetté értelmezik, elősegítve a mesterséges intelligencia képességei és az emberi találékonyság közötti szinergikus táncot. A PyTorch felhasználásával megfigyelhetjük, hogy ezek a modellek miként finomítják a káoszt iteratív módon tisztasággá, tükrözve a művész útját a születőben lévő ötlettől a csiszolt alkotásig.
Kísérletezés a mesterséges intelligencia által generált műalkotással
Ez a bemutató a mesterséges intelligencia által generált művészet lenyűgöző világába nyúl, egy konvolúciós neurális hálózat segítségével. ConvDiffusionModel. Ezt a modellt különféle művészeti képekre képezték ki, ideértve a rajzokat, festményeket, szobrokat és metszeteket is. ez a Kaggle adatkészlet. Célunk, hogy feltárjuk a modell azon képességét, hogy megragadja és reprodukálja e műalkotások összetett esztétikáját.
Modellépítészet és képzés
Építészeti tervezés
A ConvDiffusionModel lényegében a neurális tervezés csodája, amely kifinomult kódoló-dekódoló architektúrát tartalmaz, amely a művészetek generációjának igényeihez igazodik. A modell felépítése egy összetett neurális hálózat, amely kifinomult kódoló-dekódoló mechanizmusokat integrál, amelyeket kifejezetten a művészetek generálására fejlesztettek ki. A művészi intuíciót utánzó további konvolúciós rétegekkel és átugró kapcsolatokkal a modell a kompozíció és a stílus okos megértésével boncolgathatja és összeállíthatja a művészetet.
- Encoder: A kódoló a modell elemző szeme, amely minden bemeneti kép apró részletét megvizsgálja. Ahogy a képek áthaladnak a kódoló konvolúciós rétegein, fokozatosan egy látens térbe tömörülnek – ez az eredeti műalkotás kompakt, kódolt reprezentációja. Kódolónk nem csak a bemeneti képeket vizsgálja meg, de ezt a további rétegek és a kötegelt normalizálási technikák jóvoltából megnövelt mélységű érzékeléssel teszi. Ez a kiterjesztett vizsgálat gazdagabb, sűrített ábrázolást tesz lehetővé a látens téren belül, tükrözve a művész mély elmélkedését a témáról.
- Decoder: Ezzel szemben a dekóder a modell kreatív kezeként szolgál, átveszi az absztrakt vázlatokat a kódolóból, és életet lehel beléjük. Rekonstruálja a műalkotást a látens térből, rétegről rétegre, részletről részletre, amíg egy teljes kép nem jön létre. Dekóderünk előnyben részesíti a kihagyható kapcsolatokat, és nagyobb pontossággal képes rekonstruálni a műalkotásokat. Újra felkeresi a bemenet elvont lényegét, és fokozatosan megszépíti azt, így a forrásanyaghoz hűbb megjelenítést ér el. A továbbfejlesztett rétegek összehangoltan működnek, hogy a végső kép élénk, bonyolult darab legyen, amely tükrözi a bemenet művésziségét.
Képzési folyamat
A ConvDiffusionModel képzése egy 150 korszakot felölelő művészi tájon keresztüli utazás. Minden korszak egy teljes áthaladást jelent a teljes adathalmazon, és a modell arra törekszik, hogy finomítsa a megértését és javítsa a generált képek hűségét.
- Hibrid elvesztési funkció: A képzés középpontjában az átlagos négyzetes hiba (MSE) veszteségfüggvény áll. Ez a funkció számszerűsíti az eredeti remekmű és a modell rekreációja közötti különbséget, egyértelmű mérőszámot biztosítva a minimalizáláshoz. Bevezetünk egy észlelési veszteség komponenst, amely egy előre betanított VGG hálózatból származik, amely kiegészíti az átlagos négyzetes hiba (MSE) metrikáját. Ez a kettős veszteség-stratégia arra készteti a modellt, hogy tiszteletben tartsa az eredetiek művészi integritását, miközben tökéletesíti a részletek technikai reprodukcióját.
- Optimalizáló: Az ütemező által dinamikusan beállított tanulási sebességnek köszönhetően az Adam-optimalizáló fokozott okossággal irányítja a modell tanulását. Ez az adaptív megközelítés biztosítja, hogy a modell előrehaladása a művészet reprodukálásának és megújításának megtanulása terén egyenletes és robusztus legyen.
- Iteráció és finomítás: A képzési iterációk egy tánc a művészi esszencia megőrzése és a technikai replikációra való törekvés között. A modell minden ciklussal közelebb kerül a hűség és a kreativitás szintéziséhez.
- Az előrehaladás vizualizálása: A képek rendszeres időközönként mentésre kerülnek az edzés során, hogy megjelenítsék a modell előrehaladását. Ezek a pillanatképek betekintést nyújtanak a modell tanulási görbéjébe, bemutatva, hogyan fejlődik a létrehozott művészet, világosabbá, részletesebbé és művészileg koherensebbé válva minden korszakban.



A fentieket a következő kódrészlet mutatja be:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
from torchvision.models import vgg16
from PIL import Image
# Defining a function to check for valid images
def is_valid_image(image_path):
try:
with Image.open(image_path) as img:
img.verify()
return True
except (IOError, SyntaxError) as e:
# Printing out the names of all corrupt files
print(f'Bad file:', image_path)
return False
# Defining the neural network
class ConvDiffusionModel(nn.Module):
def __init__(self):
super(ConvDiffusionModel, self).__init__()
# Encoder
self.enc1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=3,
stride=1, padding=1),
nn.ReLU(),
nn.BatchNorm2d(64),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc2 = nn.Sequential(nn.Conv2d(64, 128,
kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2d(128),
nn.MaxPool2d(kernel_size=2,
stride=2))
self.enc3 = nn.Sequential(nn.Conv2d(128, 256, kernel_size=3,
padding=1),
nn.ReLU(),
nn.BatchNorm2d(256),
nn.MaxPool2d(kernel_size=2,
stride=2))
# Decoder
self.dec1 = nn.Sequential(nn.ConvTranspose2d(256, 128,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(128))
self.dec2 = nn.Sequential(nn.ConvTranspose2d(128, 64,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(),
nn.BatchNorm2d(64))
self.dec3 = nn.Sequential(nn.ConvTranspose2d(64, 3,
kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid())
def forward(self, x):
# Encoder
enc1 = self.enc1(x)
enc2 = self.enc2(enc1)
enc3 = self.enc3(enc2)
# Decoder with skip connections
dec1 = self.dec1(enc3) + enc2
dec2 = self.dec2(dec1) + enc1
dec3 = self.dec3(dec2)
return dec3
# Using a pre-trained VGG16 model to compute perceptual loss
class VGGLoss(nn.Module):
def __init__(self):
super(VGGLoss, self).__init__()
self.vgg = vgg16(pretrained=True).features[:16].cuda()
.eval() # Only the first 16 layers
for param in self.vgg.parameters():
param.requires_grad = False
def forward(self, input, target):
input_vgg = self.vgg(input)
target_vgg = self.vgg(target)
loss = torch.nn.functional.mse_loss(input_vgg,
target_vgg)
return loss
# Checking if CUDA is available and set device to GPU if it is.
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
# Initializing the model and perceptual loss
model = ConvDiffusionModel().to(device)
vgg_loss = VGGLoss().to(device)
mse_loss = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30,
gamma=0.1)
# Dataset and DataLoader setup
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
dataset = datasets.ImageFolder(root='/content/Images',
transform=transform, is_valid_file=is_valid_image)
dataloader = DataLoader(dataset, batch_size=32,
shuffle=True)
# Training loop
num_epochs = 150
for epoch in range(num_epochs):
for i, (inputs, _) in enumerate(dataloader):
inputs = inputs.to(device)
# Zero the parameter gradients
optimizer.zero_grad()
# Forward pass
outputs = model(inputs)
# Calculate losses
mse = mse_loss(outputs, inputs)
perceptual = vgg_loss(outputs, inputs)
loss = mse + perceptual
# Backward pass and optimize
loss.backward()
optimizer.step()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}],
Step [{i+1}/{len(dataloader)}], Loss: {loss.item()},
Perceptual Loss: {perceptual.item()}, MSE Loss:
{mse.item()}')
# Saving the generated image for visualization
save_image(outputs, f'output_epoch_{epoch+1}
_step_{i+1}.png')
# Updating the learning rate
scheduler.step()
# Saving model checkpoints
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(),
f'/content/model_epoch_{epoch+1}.pth')
print('Training Complete')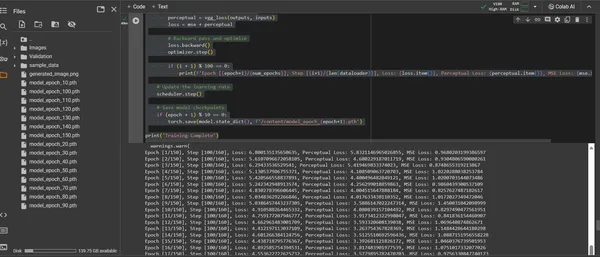
A generált műalkotás vizualizálása
Az AI-Crafted Artistry megnyilvánulása
A teljesen betanított ConvDiffusionModelnek köszönhetően a hangsúly az absztraktról a konkrétra tolódik – a lehetőségről az MI által megalkotott művészet aktualizálására. Az ezt követő kódrészlet a modell tanult művészi képességeit valósítja meg, a bemeneti adatokat digitális kifejezési vászonná alakítva.
import os
import matplotlib.pyplot as plt
# Loading the trained model
model = ConvDiffusionModel().to(device)
model.load_state_dict(torch.load('/content/model_epoch_150.pth'))
model.eval() # Set the model to evaluation mode
# Transforming for the input image
transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
# Function to de-normalize the image for viewing
def denormalize(tensor):
mean = torch.tensor([0.485, 0.456, 0.406]).
to(device).view(-1, 1, 1)
std = torch.tensor([0.229, 0.224, 0.225]).
to(device).view(-1, 1, 1)
tensor = tensor * std + mean # De-normalize
tensor = tensor.clamp(0, 1) # Clamp to the valid image range
return tensor
# Loading and transforming the image
input_image_path = '/content/Validation/0006.jpg'
input_image = Image.open(input_image_path).convert('RGB')
input_tensor = transform(input_image).unsqueeze(0).to(device)
# Adding a batch dimension
# Generating the image
with torch.no_grad():
generated_tensor = model(input_tensor)
# Converting the generated image tensor to an image
generated_image = denormalize(generated_tensor.squeeze(0))
# Removing the batch dimension and de-normalizing
generated_image = generated_image.cpu() # Move to CPU
# Saving the generated image
save_image(generated_image, '/content/generated_image.png')
print("Generated image saved to '/content/generated_image.png'")
# Displaying the generated image using matplotlib
plt.figure(figsize=(8, 8))
plt.imshow(generated_image.permute(1, 2, 0))
# Rearrange the channels for plotting
plt.axis('off') # Hide the axes
plt.show()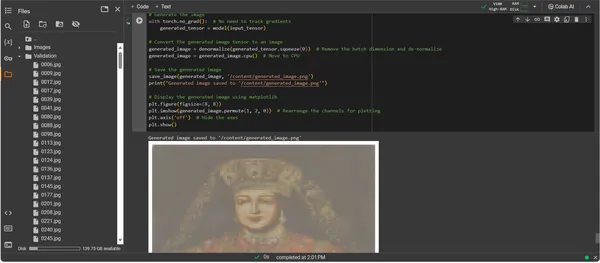

Műalkotás-generációs kód bemutatása
- Modell feltámadás: A műalkotások generálásának első lépése a képzett ConvDiffusionModel újraélesztése. A modell betanult súlyai betöltődnek és kiértékelési módba kerülnek, így a paraméterek további módosítása nélkül beállítják a létrehozáshoz szükséges terepet.
- Kép átalakítása: A képzési rendszerrel való összhang biztosítása érdekében a bemeneti képeket ugyanazon az átalakítási sorozaton keresztül dolgozzák fel. Ez magában foglalja a modell bemeneti méreteihez igazodó átméretezést, a PyTorch-kompatibilitás érdekében tenzorkonverziót, valamint a betanítási adatok statisztikai profilja alapján történő normalizálást.
- Denormalizációs segédprogram: Egy egyéni funkció megfordítja az előfeldolgozási effektusokat, átméretezve a tenzort az eredeti kép színtartományára. Ez a lépés elengedhetetlen a generált kimenet vizuálisan pontos megjelenítéséhez.
- Bemenet előkészítése: Egy kép betöltődik, és alávetjük a fent említett átalakításoknak. Nagyon fontos megjegyezni, hogy ez a kép múzsaként szolgál, amelyből a mesterséges intelligencia ihletet merít – a néma suttogás beindítja a modell szintetikus képzeletét.
- Műalkotás szintézise: A továbbterjedés finom táncában a modell értelmezi a bemeneti tenzort, lehetővé téve, hogy rétegei együttműködjenek egy új művészi vízió kialakításában. Hajtsa végre ezt a folyamatot a színátmenetek követése nélkül, mivel most az alkalmazás, nem pedig a képzés területén vagyunk.
- Kép átalakítása: A most digitálisan született grafikát tároló modell tenzorkimenete denormalizált, így a modell alkotása visszafordítja a színek és fények megszokott terébe, amelyet szemünk is képes értékelni.
- Műalkotás kinyilatkoztatása: Az átalakított tenzort egy digitális vászonra fektetik le, és egy elmentett képfájlban csúcsosodik ki. Ez a fájl egy ablak a mesterséges intelligencia kreatív lelkébe, statikus visszhangja annak a dinamikus folyamatnak, amely életet adott neki.
- Műalkotások visszakeresése: A szkript azzal zárul, hogy elmenti a generált képet egy kijelölt útvonalra, és bejelenti annak befejezését. Az elmentett kép, a tanult művészi elvek és a kialakuló kreativitás szintézise, készen áll a megjelenítésre és az elmélkedésre.
A kimenet elemzése
A ConvDiffusionModel kimenete egy olyan alakot mutat be, amely egyértelműen utal a történelmi művészetre. A kidolgozott öltözékbe burkolt, mesterséges intelligencia által renderelt kép a klasszikus portrék nagyszerűségét visszhangozza, mégis egyedi, modern érintéssel. Az alany öltözéke textúrában gazdag, a modell tanult mintáit újszerű értelmezéssel ötvözi. A finom arcvonások, valamint a fény és az árnyék finom kölcsönhatása bemutatja az AI-nak a hagyományos művészeti technikák árnyalt megértését. Ez a műalkotás a modell kifinomult képzésének bizonyítéka, és a történelmi művészet elegáns szintézisét tükrözi a fejlett gépi tanulás prizmáján keresztül. Lényegében ez egy digitális hódolat a múltnak, a jelen algoritmusaival kidolgozva.
Kihívások és etikai megfontolások
A diffúziós modellek megvalósítása a művészetgeneráció számára számos kihívást és etikai megfontolást hoz magával, amelyeket figyelembe kell vennie:
- Az adatok származása: A képzési adatkészleteket felelősségteljesen kell kezelni. Elengedhetetlen annak ellenőrzése, hogy a diffúziós modellek betanításához használt adatok megfelelő engedély nélkül nem tartalmaznak szerzői joggal védett vagy védett műveket.
- Elfogultság és képviselet: Az AI-modellek képesek fenntartani a torzításokat a képzési adataikban. A változatos és átfogó adatkészletek biztosítása fontos, hogy elkerüljük a sztereotípiák megerősítését a mesterséges intelligencia által generált művészetben.
- Kimenet vezérlése: Mivel a diffúziós modellek sokféle kimenetet generálhatnak, határokat kell felállítani a nem megfelelő vagy sértő tartalom létrehozásának megakadályozása érdekében.
- Jogi keretrendszer: Kihívást jelent az, hogy nincs szilárd jogi keret az AI árnyalatainak kezelésére a kreatív folyamatban. A jogszabályoknak fejlődniük kell minden érintett fél jogainak védelme érdekében.
Következtetés
A diffúziós modellek térnyerése a mesterséges intelligenciában és a művészetben egy átalakuló korszakot jelez, amely egyesíti a számítási pontosságot az esztétikai feltárással. A művészeti világban tett utazásuk jelentős innovációs potenciálra hívja fel a figyelmet, de bonyolultságokkal jár. Az eredetiség, a hatás, az etikus alkotás és a meglévő művek tisztelete egyensúlya a művészi folyamat szerves része.
Kulcs elvezetések
- A diffúziós modellek a művészeti alkotás átalakulásában az élen járnak. Olyan új digitális eszközöket kínálnak, amelyek a hagyományos határokon túl bővítik a művészi kifejezési lehetőségeket.
- A mesterséges intelligencia által továbbfejlesztett művészetben a képzési adatok etikus gyűjtésének előtérbe helyezése és az alkotók szellemi tulajdonának tiszteletben tartása elengedhetetlen a digitális művészet integritásának megőrzéséhez.
- A művészi látásmód és a technológiai innováció konvergenciája ajtót nyit a művészek és a mesterséges intelligencia fejlesztői közötti szimbiotikus kapcsolat előtt. Együttműködési környezet kialakítása, amely úttörő művészetet eredményezhet.
- Létfontosságú annak biztosítása, hogy a mesterséges intelligencia által generált művészet a perspektívák széles spektrumát képviselje. Változatos adatok bevitele, amelyek tükrözik a különböző kultúrák és nézőpontok gazdagságát, elősegítve ezzel az inkluzivitást.
- A mesterséges intelligencia által megalkotott művészet iránti növekvő érdeklődés szilárd jogi keretek kialakítását teszi szükségessé. Ezeknek a kereteknek tisztázniuk kell a szerzői jogi kérdéseket, el kell ismerniük a hozzájárulásokat, és szabályozniuk kell a mesterséges intelligencia által generált műalkotások kereskedelmi felhasználását.
Ennek a művészi fejlődésnek a hajnala olyan utat kínál, amely tele van kreatív potenciállal, ugyanakkor figyelmes felügyeletet igényel. Kötelességünk, hogy olyan tájat műveljünk, ahol a mesterséges intelligencia és a művészet fúziója virágzik, felelősségteljes és kulturálisan érzékeny gyakorlatok által vezérelve.
Gyakran ismételt kérdések
V. A diffúziós modellek generatív ML algoritmusok, amelyek úgy hoznak létre képeket, hogy véletlenszerű zajmintával kezdik, és fokozatosan koherens képpé alakítják. Ez a folyamat olyan, mint egy művész, aki üres vászonnal kezdi, és lassan részletezi a részleteket.
V. A GAN-ok, diffúziós modellek nem igényelnek külön hálózatot a kimenet megítéléséhez. A zaj iteratív hozzáadásával és eltávolításával működnek, ami gyakran részletesebb és árnyaltabb képeket eredményez.
V. Igen, a diffúziós modellek képesek eredeti műalkotásokat generálni, ha tanulnak egy képadatkészletből. Az eredetiséget azonban befolyásolja a képzési adatok sokfélesége és terjedelme. Folyamatos vita folyik a meglévő műalkotások e modellek képzésére való felhasználásának etikájáról.
V. Az etikai szempontok közé tartozik a mesterséges intelligencia által létrehozott műalkotások szerzői jogainak megsértésének elkerülése. Az emberi művészek eredetiségének tiszteletben tartása, az elfogultság fennmaradásának megakadályozása és az AI kreatív folyamatának átláthatóságának biztosítása.
V. A mesterséges intelligencia által generált művészet jövője ígéretesnek tűnik, mivel a diffúziós modellek új eszközöket kínálnak a művészek és alkotók számára. A technológia fejlődésével egyre kifinomultabb és bonyolultabb műalkotásokra számíthatunk. A kreatív közösségnek azonban az etikai megfontolások mentén kell eligazodnia, és világos iránymutatások és legjobb gyakorlatok felé kell törekednie.
A cikkben bemutatott média nem az Analytics Vidhya tulajdona, és a szerző saját belátása szerint használja.
Összefüggő
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2023/12/implementing-diffusion-models-for-creative-ai-art-generation/
- :is
- :nem
- :ahol
- 001
- 1
- 10
- 100
- 11
- 12
- 15%
- 150
- 16
- 19
- 224
- 225
- 8
- 9
- a
- képesség
- Rólunk
- felett
- KIVONAT
- pontos
- Elérése
- elérése
- Ádám
- adaptív
- hozzáadásával
- További
- cím
- Beállított
- fejlett
- előlegek
- megérkezés
- ellenséges
- AI
- ai művészet
- rokon
- algoritmusok
- Minden termék
- lehetővé téve
- lehetővé teszi, hogy
- an
- Analitikai
- analitika
- Analytics Vidhya
- és a
- Bemutatjuk
- Alkalmazás
- méltányol
- megközelítés
- építészet
- VANNAK
- Művészet
- cikkben
- művész
- művészi
- művészileg
- művésziesség
- Előadók
- artwork
- műalkotások
- AS
- At
- bővített
- meghatalmazás
- elérhető
- utakat
- elkerülése érdekében
- elkerülve
- TENGELYEK
- vissza
- Rossz
- kiegyensúlyozó
- alapján
- BE
- egyre
- Előnyök
- BEST
- legjobb gyakorlatok
- között
- Túl
- előítélet
- torzítások
- üres
- keverési
- blogaton
- született
- mindkét
- határait
- lélegző
- telt
- Bring
- széles
- hozott
- virágzó
- de
- by
- számít
- hívott
- TUD
- vászon
- képességek
- képesség
- elfog
- kihívás
- kihívások
- csatornák
- Káosz
- jellegzetes
- ellenőrizze
- ellenőrzése
- fogó
- világosság
- osztály
- világos
- világosabb
- közelebb
- kód
- Kódolás
- ÖSSZEFÜGGŐ
- együttműködik
- kollaboratív
- szín
- jön
- kereskedelmi
- közösség
- kompakt
- kompatibilitás
- versenyképes
- teljes
- befejezés
- bonyolult
- bonyodalmak
- összetevő
- összetétel
- számítási
- Kiszámít
- fogalmak
- fogalmi
- aggodalmak
- koncert
- arra a következtetésre jut
- kapcsolatok
- Fontolja
- megfontolások
- tartalmaz
- tartalom
- kontraszt
- hozzájárulások
- hagyományos
- Konvergencia
- Átalakítás
- konvertáló
- konvolúciós neurális hálózat
- copyright
- szerzői jogok megsértése
- Mag
- megvesztegethető
- CPU
- kidolgozott
- teremt
- létrehozása
- teremtés
- Kreatív
- Kreatívan
- kreativitás
- alkotók
- kritikus
- tetőzve
- Művelni
- kulturálisan
- a válogatott
- görbe
- szokás
- ciklus
- tánc
- dátum
- adatkészletek
- vita
- mély
- meghatározó
- igények
- igazolták
- mélység
- mélységben
- Származtatott
- kijelölt
- részlet
- részletes
- részletek
- fejlesztők
- eszköz
- különbözik
- különbség
- különböző
- Diffusion
- digitális
- digitális művészet
- digitálisan
- Dimenzió
- méretek
- belátása
- kijelző
- megjelenítő
- különböző
- megkülönböztetés
- számos
- Sokféleség
- do
- nem
- ajtók
- húz
- Rajzok
- alatt
- dinamikus
- dinamikusan
- dinamika
- e
- minden
- visszhang
- visszhangok
- hatások
- Bonyolult
- más
- kiemelkedik
- kódolt
- felölel
- átfogó
- Mérnöki
- fokozott
- biztosítására
- biztosítja
- biztosítása
- Egész
- Környezet
- korszak
- korszakok
- Ez volt
- hiba
- lényeg
- alapvető
- intézmény
- Eter (ETH)
- etikai
- etika
- értékelés
- Minden
- evolúció
- fejlődik
- alakult ki
- fejlődik
- vizsgálat
- Excel
- Kivéve
- létező
- Bontsa
- kiterjedt
- vár
- kutatás
- feltárása
- kifejezés
- kiterjedt
- kiterjedt
- szem
- Szemek
- arc
- hűséges
- hamis
- ismerős
- elbűvölő
- Jellemzők
- Featuring
- hűség
- Ábra
- filé
- Fájlok
- utolsó
- befejezni
- vezetéknév
- Összpontosít
- következő
- A
- Forefront
- Előre
- Foster
- elősegítése
- Keretrendszer
- keretek
- ból ből
- teljesen
- funkció
- funkcionális
- alapvető
- további
- magfúzió
- jövő
- Nyereség
- Gans
- gyűjtése
- adott
- generál
- generált
- generáló
- generáció
- nemző
- generációs versenytárs hálózatok
- Generatív AI
- generátorok
- Ad
- cél
- GPU
- színátmenetek
- fokozatosan
- nagyszerűség
- fogás
- nagyobb
- úttörő
- vezetett
- irányelvek
- Útmutatók
- kéz
- hasznosítása
- Szív
- itt
- elrejt
- kiemeli
- történeti
- holding
- sarc
- becsület
- Hogyan
- azonban
- HTTPS
- emberi
- i
- ötlet
- if
- meggyullad
- kép
- képek
- képzelet
- parancsoló
- végrehajtási
- következményei
- importál
- fontos
- javul
- in
- magában foglalja a
- befogadó
- befogadás
- bele
- <p></p>
- járulékos
- háruló
- befolyás
- befolyásolható
- megsértése
- találékonyság
- újít
- Innováció
- bemenet
- bemenet
- Insight
- szerves
- integrálása
- sértetlenség
- szellemi
- szellemi tulajdon
- kamat
- értelmezés
- bele
- bonyolult
- bevezet
- intuíció
- részt
- kérdések
- IT
- ismétlés
- iterációk
- ITS
- utazás
- jpg
- bíró
- hiány
- táj
- réteg
- tojók
- tanult
- tanulás
- Jogi
- jogi keretrendszer
- Jogalkotás
- Lencsék
- fekszik
- élet
- fény
- mint
- betöltés
- MEGJELENÉS
- le
- veszteség
- gép
- gépi tanulás
- fenntartása
- csoda
- mestermű
- Mérkőzés
- anyag
- matplotlib
- jelent
- mechanizmus
- mechanizmusok
- Média
- csupán
- egyesülő
- módszer
- módszeres
- metrikus
- minimalizálása
- perc
- tükrözés
- ML
- ML algoritmusok
- Mód
- modell
- modellek
- modern
- modul
- több
- mozog
- sok
- Múzsa
- kell
- nevek
- születő
- Természet
- Keresse
- elengedhetetlen
- igények
- hálózat
- hálózatok
- ideg-
- Neurális tervezés
- neurális hálózat
- neurális hálózatok
- Új
- Zaj
- megjegyezni
- regény
- Most
- árnyalatok
- megfigyelni
- megfigyelt
- of
- kedvezmény
- támadó
- ajánlat
- felajánlás
- Ajánlatok
- gyakran
- on
- folyamatban lévő
- csak
- nyit
- Optimalizálja
- or
- eredeti
- eredetiség
- Originals
- OS
- Más
- mi
- ki
- teljesítmény
- kimenetek
- felett
- tulajdonú
- festmény
- festmények
- paraméter
- paraméterek
- rész
- fél
- elhalad
- múlt
- ösvény
- Mintás
- minták
- észlelés
- tökéletesítés
- teljesít
- perspektívák
- kép
- darab
- darabok
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- portrék
- potenciális
- gyakorlat
- Pontosság
- előzetes
- be
- ajándékot
- megőrzése
- megakadályozása
- megakadályozása
- elvek
- nyomtatás
- prioritások
- folyamat
- feldolgozott
- termelő
- Termékek
- profil
- mélységes
- Haladás
- haladás
- fokozatosan
- biztató
- támogatása
- utasításokat
- szaporítás
- megfelelő
- ingatlan
- védelme
- védett
- eredet
- amely
- közzétett
- folytat
- pytorch
- számszerűsíti
- véletlen
- véletlenszerűség
- hatótávolság
- Arány
- kész
- birodalom
- elismerik
- újradefiniálása
- finomítani
- kifinomult
- tükrözve
- tükrözi
- rezsim
- szabályos
- kapcsolat
- eltávolítása
- vakolás
- replikáció
- képviselet
- jelentése
- reprodukció
- szükség
- megköveteli,
- hasonlít
- alakíts
- tisztelet
- vonatkozó
- felelős
- felelősségteljesen
- kapott
- visszatérés
- kinyilatkoztatás
- Feléled
- forradalmasítani
- RGB
- Gazdag
- jogok
- Emelkedik
- erős
- Szerep
- azonos
- mentett
- megtakarítás
- színhely
- Tudomány
- hatálya
- forgatókönyv
- lát
- MAGA
- érzékeny
- különálló
- Sorozat
- szolgálja
- készlet
- beállítás
- felépítés
- számos
- árnyék
- formálás
- váltás
- Műszakok
- kellene
- kirakat
- kirakatba
- mutatott
- jelentős
- óta
- Lassan
- töredék
- So
- kifinomult
- lélek
- forrás
- származó
- Hely
- feszültség
- kifejezetten
- Spektrum
- Négyzet
- stabil
- Színpad
- állvány
- Kezdve
- statisztikai
- állandó
- Lépés
- Stratégia
- törekvés
- struktúra
- Lenyűgöző
- stílus
- tárgy
- későbbi
- ilyen
- Szimbiotikus
- szinergikus
- szintézis
- szintetikus
- szabott
- tart
- bevétel
- cél
- Műszaki
- technikák
- technikai
- Technologies
- Technológia
- tensorflow
- végrendelet
- hogy
- A
- A jövő
- The Source
- azok
- Őket
- Ott.
- Ezek
- ők
- ezt
- virágzik
- Keresztül
- Így
- nak nek
- szerszámok
- fáklya
- Torchvision
- érintse
- felé
- Csomagkövetés
- hagyományos
- Vonat
- kiképzett
- Képzések
- Átalakítás
- Átalakítás
- transzformációk
- átalakító
- át
- transzformáló
- transzformáció
- Átláthatóság
- igaz
- megpróbál
- megért
- megértés
- egyedi
- -ig
- bemutatta
- frissítése
- upon
- us
- használ
- használt
- segítségével
- hasznosság
- érvényes
- ellenőrzése
- keresztül
- megtekintők
- nézőpontok
- látomás
- vizuális
- képzőművészet
- megjelenítés
- Képzeld
- előző
- fontos
- volt
- we
- webp
- Mit
- Mi
- ami
- míg
- Suttogás
- WHO
- széles
- Széleskörű
- lesz
- ablak
- val vel
- belül
- nélkül
- Munka
- művek
- világ
- X
- Igen
- még
- te
- zephyrnet
- nulla