Bevezetés
Az akadémiai kutatás területén a nyers adatoktól a lényegre törő következtetésekig vezető út ijesztő lehet, ha Ön kezdő vagy kezdő. A megfelelő megközelítéssel és eszközökkel azonban az adatok értelmes tudássá alakítása rendkívül hasznos élmény. Ebben az útmutatóban végigvezetjük Önt egy tipikus tudományos adatelemzési munkafolyamaton, egy közelmúltbeli, a különböző diéták súlycsökkentésre gyakorolt hatékonyságáról szóló tanulmány gyakorlati példáján keresztül.

Tartalomjegyzék
Tanulási cél
Speciálist fogunk használni AI adateszköz - Julius, az elemzés elvégzéséhez. Célunk az akadémiai kutatáselemzés folyamatának demisztifikálása, bemutatva, hogy az adatok gondosan és megfelelően elemezve hogyan képesek megvilágítani a lenyűgöző trendeket és választ adni a kritikus kutatási kérdésekre.
Navigálás az Academic Data Workflow-ban Juliusszal
A tudományos kutatásban az adatok kezelésének módja kulcsfontosságú az új felismerések feltárásához. Útmutatónk ezen része végigvezeti a kutatási adatok elemzésének szokásos lépésein. A világos kérdés kezdetétől a végeredmény megosztásáig minden lépés döntő jelentőségű.
Megmutatjuk, hogyan változtathatják meg a kutatók ezt a világos utat követve a nyers adatokat megbízható és értékes eredményekké. Ezután végigvezetjük az egyes lépéseken egy példa-esettanulmányon, amely bemutatja, hogyan takaríthat meg időt, miközben jobb minőségű eredményeket biztosít a Julius használatával a folyamat során.
1. Kérdés megfogalmazása
Kezdje azzal, hogy egyértelműen határozza meg kutatási kérdését vagy hipotézisét. Ez irányítja a teljes elemzést, és meghatározza a használni kívánt módszereket.
2. Adatgyűjtés
Gyűjtsd össze a szükséges adatokat, ügyelve arra, hogy összhangban legyenek a kutatási kérdéseddel. Ez magában foglalhatja új adatok gyűjtését vagy meglévő adatkészletek használatát. Az adatoknak tartalmazniuk kell a vizsgálat szempontjából releváns változókat.
3. Adattisztítás és előfeldolgozás
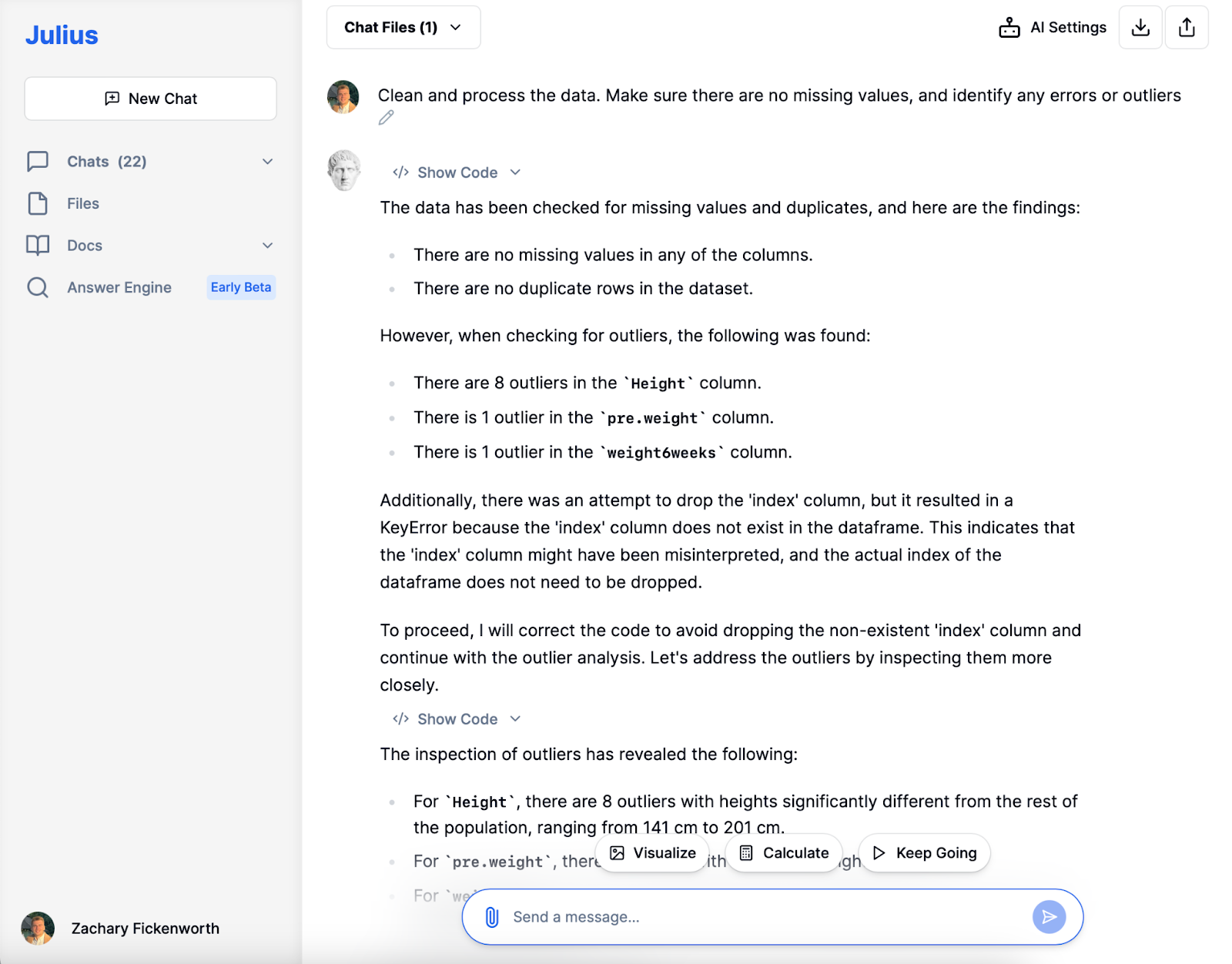
Készítse elő adatkészletét elemzésre. Ez a lépés magában foglalja az adatok konzisztenciájának biztosítását (mint például a szabványos mértékegységek), a hiányzó értékek kezelését, valamint az adatok hibáinak vagy kiugró értékeinek azonosítását.
4. Feltáró adatelemzés (EDA)
Végezze el az adatok kezdeti vizsgálatát. Ez magában foglalja a változók eloszlásának elemzését, a minták vagy kiugró értékek azonosítását, valamint az adatkészlet jellemzőinek megértését.
5. Módszer kiválasztása
- Az elemzési technikák meghatározása: Válassza ki a megfelelő statisztikai módszereket vagy modelleket adatai és kutatási kérdése alapján. Ez magában foglalhatja a csoportok összehasonlítását, a kapcsolatok azonosítását vagy az eredmények előrejelzését.
- Szempontok a módszer kiválasztásához: A kiválasztást befolyásolja az adatok típusa (pl. kategorikus vagy folyamatos), az összehasonlítandó csoportok száma és a vizsgált kapcsolatok jellege.
6. Statisztikai analízis
- Operacionalizáló változók: Ha szükséges, hozzon létre új változókat, amelyek jobban reprezentálják a tanulmányozott fogalmakat.
- Statisztikai tesztek végrehajtása: Alkalmazza a választott statisztikai módszereket az adatok elemzéséhez. Ez magában foglalhat olyan teszteket, mint a t-teszt, ANOVA, regressziós elemzés stb.
- Kovariánsok elszámolása: Bonyolultabb elemzésekben vegyen fel más releváns változókat is, hogy ellenőrizhesse azok lehetséges hatását.
7. Értelmezés
Óvatosan értelmezze az eredményeket a kutatási kérdésével összefüggésben. Ez magában foglalja annak megértését, hogy a statisztikai eredmények mit jelentenek a gyakorlatban, és figyelembe kell venni az esetleges korlátokat.
8. Jelentés
Állítsa össze megállapításait, módszertanát és értelmezéseit átfogó jelentésben vagy tudományos dolgozatban. Ennek világosnak, tömörnek és jól felépítettnek kell lennie ahhoz, hogy hatékonyan kommunikálja a kutatást.
Esettanulmány bevezetése
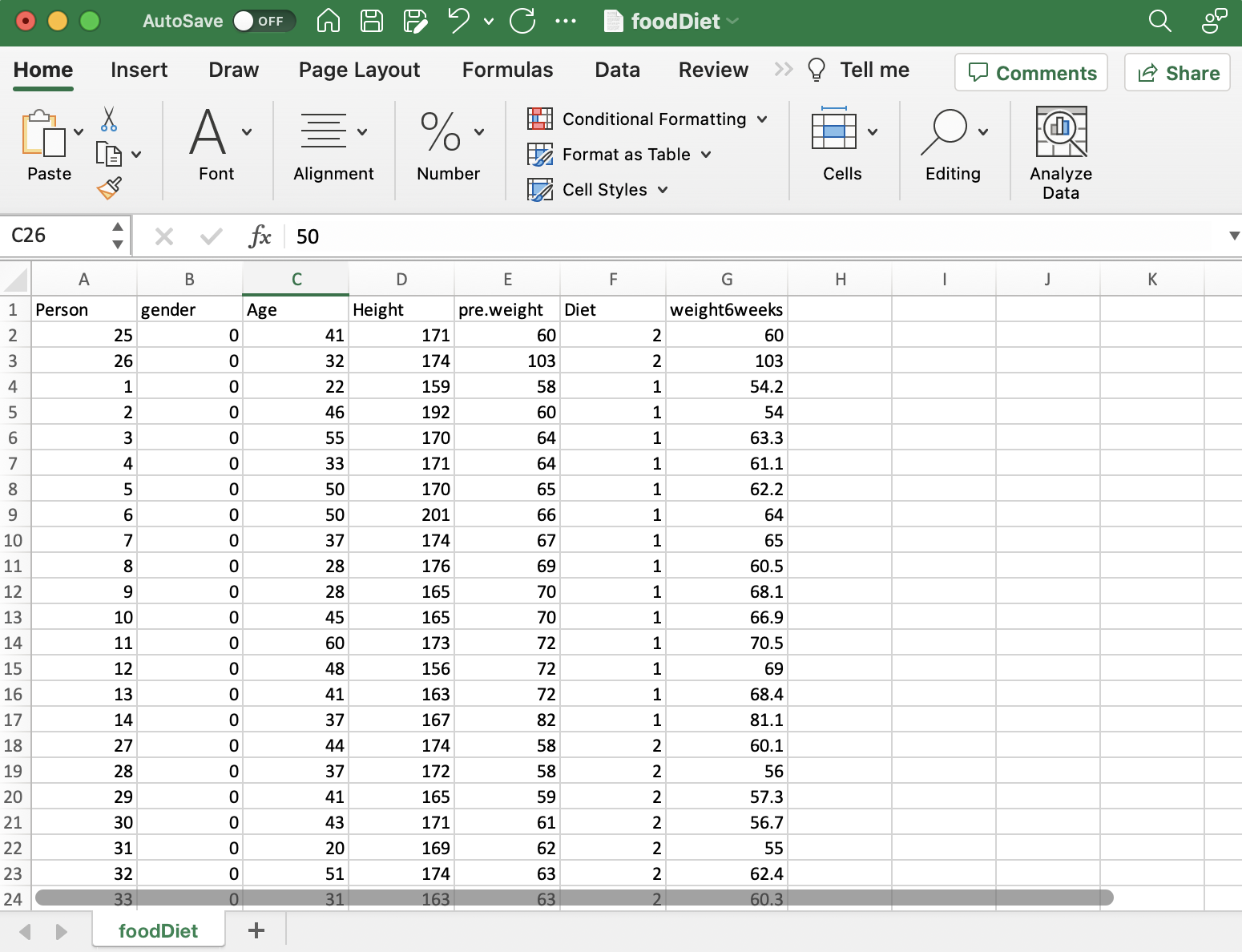
Ebben az esettanulmányban azt vizsgáljuk, hogy a különböző étrendek hogyan befolyásolják a fogyást. Vannak olyan adatok, mint az életkor, a nem, a kezdő súly, az étrend típusa és a hat hét utáni testsúly. Célunk, hogy valódi emberektől származó valós adatok felhasználásával kiderítsük, mely diéták a leghatékonyabbak a fogyásban.
Kérdés megfogalmazása
Minden kutatásban, mint például a diétákkal és a fogyással kapcsolatos tanulmányunkban, minden egy jó kérdéssel kezdődik. Olyan, mint egy ütemterv a kutatáshoz, amely elvezeti Önt, hogy mire kell összpontosítania.
For example, with our diet data, we asked, Egy adott diéta hat hét alatt jelentős fogyáshoz vezet?
Ez a kérdés egyértelmű, és pontosan megmondja, mit kell keresnünk az adatainkban, amelyek olyan részleteket tartalmaznak, mint az egyes személyek étrendjének típusa, testsúlya hat hét előtt és után, életkora és neme. Egy ehhez hasonló egyértelmű kérdés biztosítja, hogy a megfelelő pályán maradjunk, és a megfelelő dolgokat nézzük meg adatainkban, hogy megtaláljuk a szükséges válaszokat.
Adatgyűjtés
A kutatás során kulcsfontosságú a megfelelő adatok gyűjtése. Diétákkal és fogyással kapcsolatos vizsgálatunkhoz információkat gyűjtöttünk az egyes személyek étrendtípusáról, a diéta előtti és utáni testsúlyáról, életkoráról és neméről. Fontos, hogy az adatok megfeleljenek a kutatási kérdésnek. Bizonyos esetekben előfordulhat, hogy új információkat kell gyűjtenie, de itt olyan meglévő adatokat használtunk, amelyek már tartalmaztak minden szükséges adatot. A jó adatok megszerzése az első nagy lépés a tudnivalók kiderítése felé.
Adattisztítás és előfeldolgozás
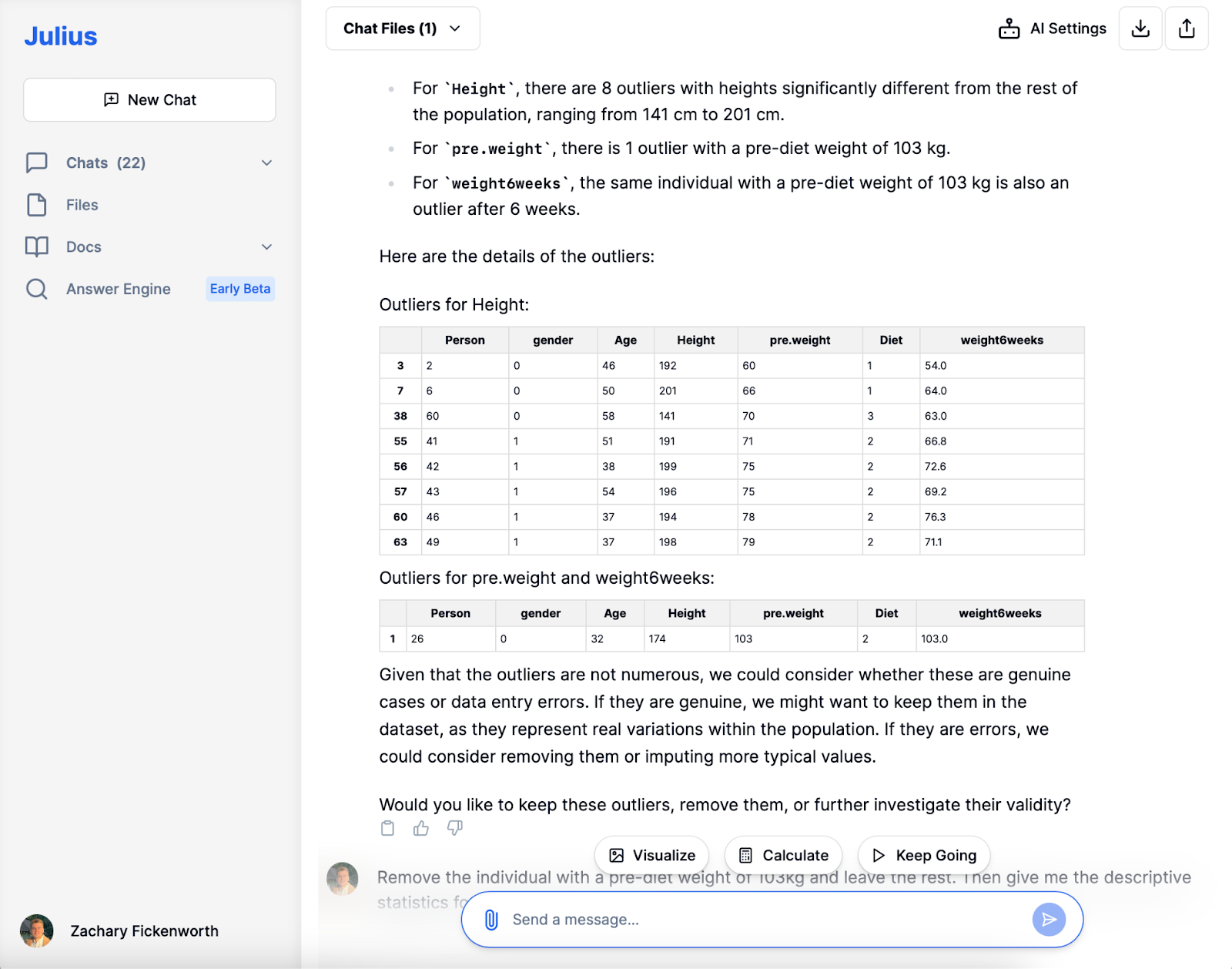
Diétás vizsgálatunkban a Juliussal végzett adattisztítás kulcsfontosságú volt. Az adatok betöltése után Julius azonosította a hiányzó értékeket és a duplikációkat, biztosítva az adatkészlet egyértelműségét. Miközben megőriztük a kiugró magassági értékeket a diverzitás szempontjából, úgy döntöttünk, hogy kizárjuk a diéta előtti kivételesen magas súlyú (103 kg) egyént, hogy megőrizzük az elemzés integritását, biztosítva az adatkészlet készenlétét a következő szakaszokhoz.
Feltáró adatelemzés (EDA)
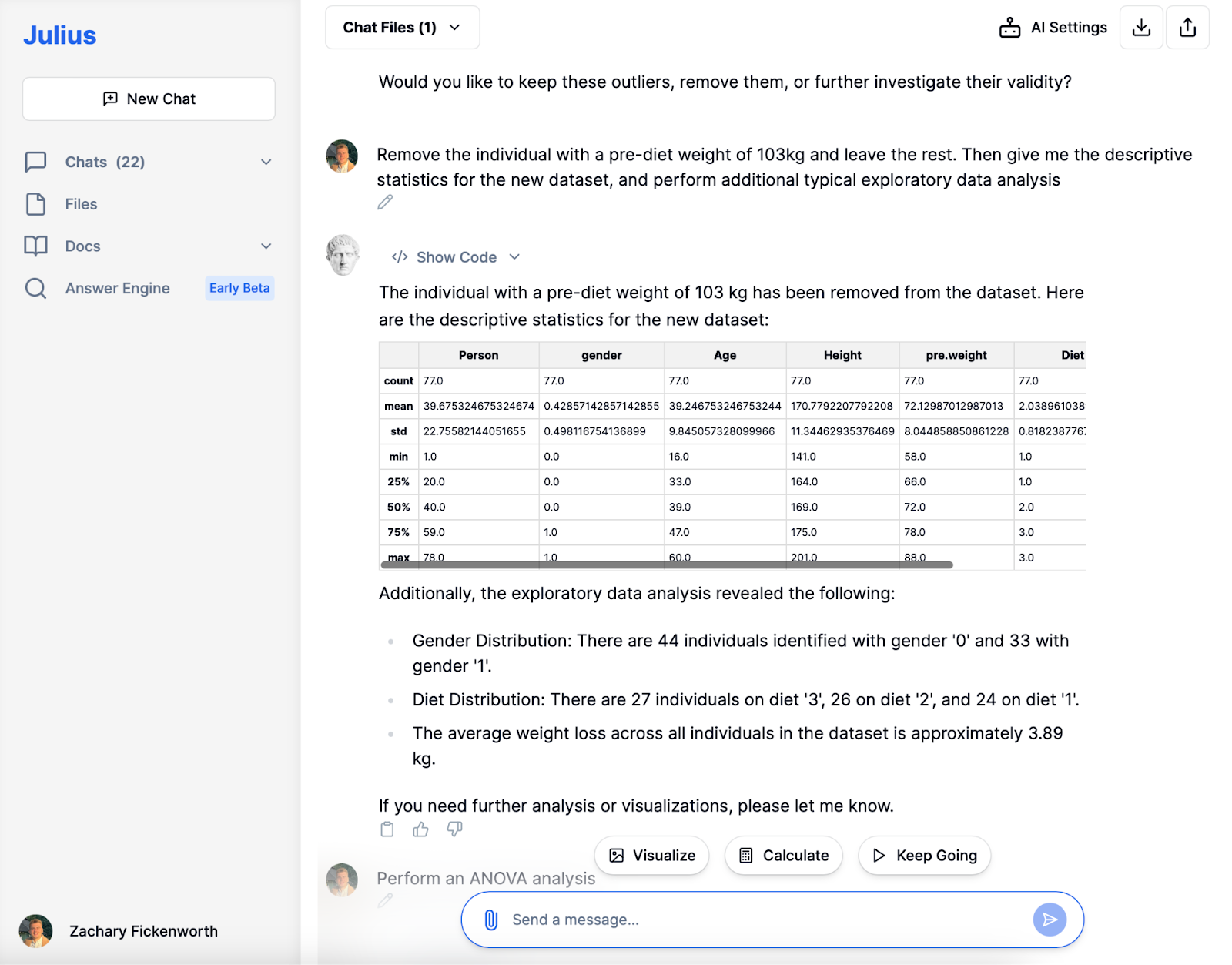
A szokatlanul magas diéta előtti súllyal járó kiugró érték eltávolítását követően a feltáró adatelemzés (EDA) fázisába ástunk bele. Julius gyorsan friss leíró statisztikákkal szolgált, így tisztább képet ad 77 résztvevőnkről. A körülbelül 72 kg-os átlagos diéta előtti súly és a körülbelül 3.89 kg-os átlagos fogyás felfedezése értékes betekintést nyújtott.
Az alapvető statisztikákon túl Julius segítette a nemek és az étrendtípusok megoszlásának vizsgálatát. A tanulmány kiegyensúlyozott nemi megoszlást és egyenletes eloszlást mutatott ki a különböző étrendtípusok között. Ez az EDA nem pusztán összefoglalja az adatokat; mintákat és trendeket tár fel, amelyek elengedhetetlenek a mélyebb elemzéshez. Például az átlagos fogyás megértése megadja a terepet a leghatékonyabb étrend meghatározásához. Ez a mesterséges intelligencia által működtetett fázis megalapozza a későbbi részletes elemzést.
Módszer kiválasztása
Diétás vizsgálatunkban döntő lépés volt a megfelelő statisztikai módszerek kiválasztása. Fő célunk az volt, hogy összehasonlítsuk a fogyást a különböző diéták között, ami közvetlenül befolyásolta az elemzési technikák kiválasztását. Tekintettel arra, hogy kettőnél több csoportot (a különböző étrendtípusokat) kellett összehasonlítanunk, a varianciaanalízis (ANOVA) volt az ideális választás. Az ANOVA hatékony olyan helyzetekben, mint a miénk, ahol meg kell értenünk, hogy vannak-e szignifikáns különbségek egy folytonos változóban (fogyás) több független csoport (étrendtípus) között.
Bár az ANOVA megmondja, hogy vannak-e eltérések, nem határozza meg, hol vannak ezek a különbségek. Ahhoz, hogy meghatározzuk, melyik a leghatékonyabb étrend, célzottabb megközelítésre volt szükségünk. Itt jöttek be a Pairwise összehasonlítások. Miután szignifikáns eredményeket találtunk az ANOVA-val, Pairwise-összehasonlításokat alkalmaztunk az egyes étrendpárok közötti fogyásbeli különbségek vizsgálatára.
Ez a kétlépéses megközelítés – kezdve az ANOVA-val az általános különbségek kimutatására, majd a páronkénti összehasonlítással e különbségek részletezésére – stratégiai volt. Átfogó megértést nyújtott arról, hogy az egyes diéták hogyan teljesítenek a többihez képest, így biztosítva az étrendi adataink alapos és árnyalt elemzését.
Statisztikai elemzés
ANOVA
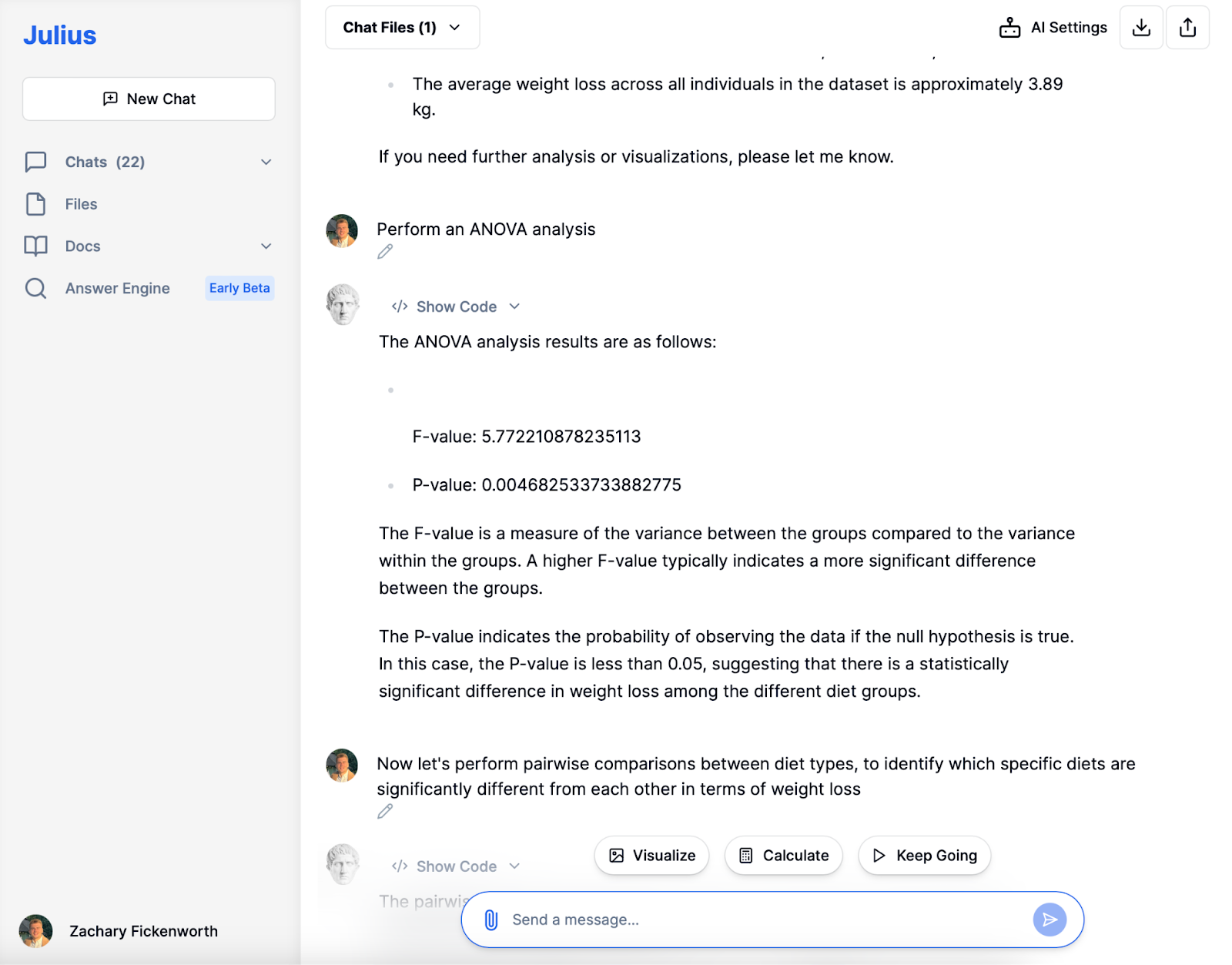
Statisztikai feltárásunk középpontjában egy ANOVA elemzést, hogy megértsük, statisztikailag szignifikáns-e a fogyás különbsége a különböző étrendtípusok között. Az eredmények eléggé leleplezőek voltak. Az 5.772-es F-értékkel az elemzés jelentős eltérést mutatott az étrendi csoportok között az egyes csoportokon belüli eltérésekhez képest. Ez az F-érték, mivel magasabb, szignifikáns különbségeket jelez a fogyásban a diéták között.
Ami még fontosabb, a P-érték, 0.00468, kiemelkedett. Ez az érték, amely jóval a hagyományos 0.05-ös küszöb alatt van, erősen arra utalt, hogy a diétás csoportok közötti súlycsökkenésben megfigyelt különbségek nem csak véletlenek voltak. Statisztikai értelemben ez azt jelentette, hogy el utasíthattuk a nullhipotézist – amely nem feltételezne különbséget a fogyásban a diéták között –, és arra a következtetésre jutottunk, hogy az étrend típusa valóban jelentős hatással volt a fogyásra. Ez az ANOVA-eredmény kritikus mérföldkő volt, ami arra késztetett bennünket, hogy tovább vizsgáljuk, hogy pontosan mely étrendek különböznek egymástól.
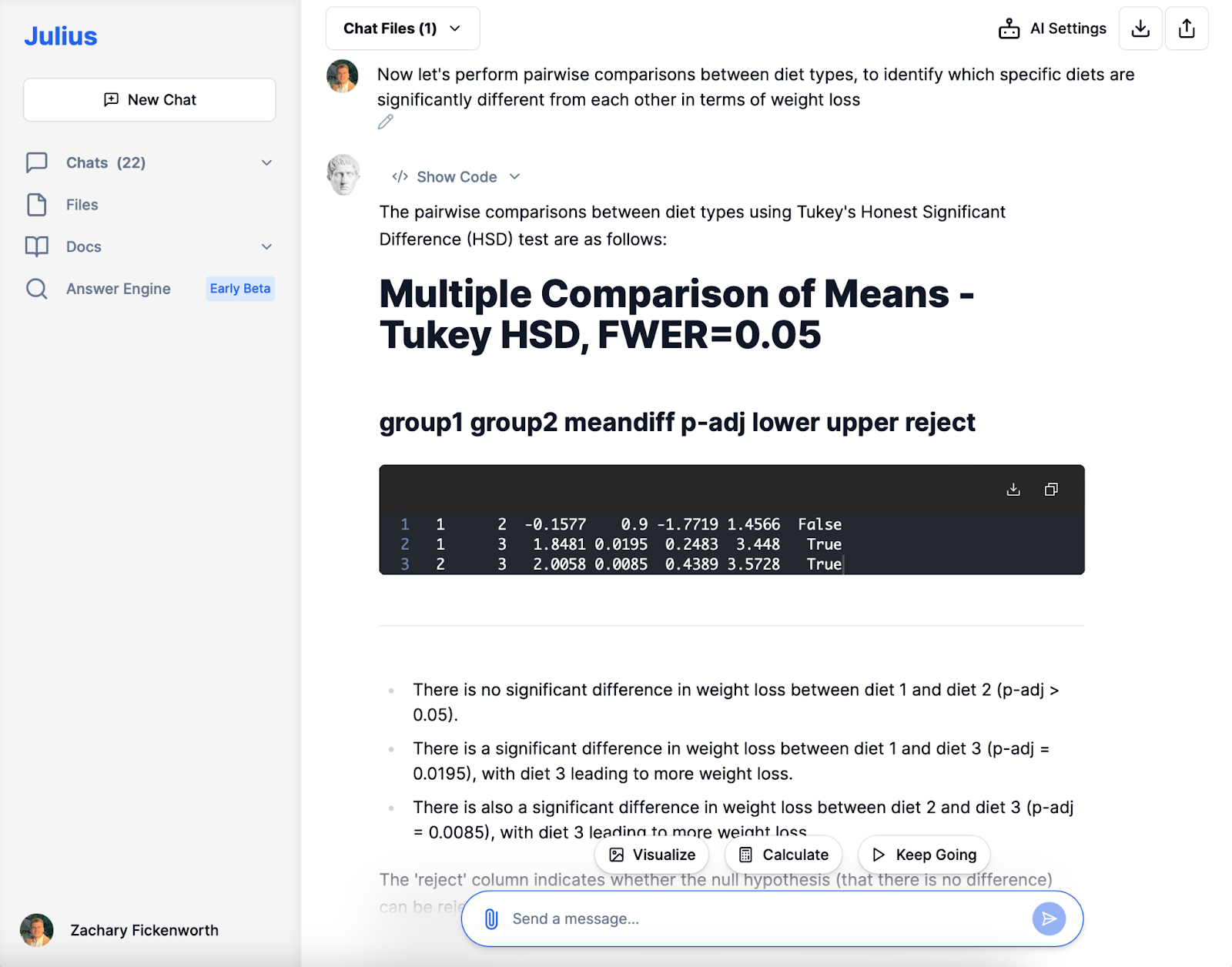
Páronként
A következő elemzési fázisban Juliusszal páronkénti összehasonlítást végeztünk az étrendtípusok között, hogy azonosítsuk a fogyásban mutatkozó specifikus különbségeket. A Tukey HSD teszt nem mutatott ki szignifikáns különbséget az 1. és a 2. diéta között. Azonban feltárta, hogy a 3. diéta szignifikánsan nagyobb súlycsökkenést eredményezett, mint az 1. és a 2. diéta, amit statisztikailag szignifikáns p-értékek is alátámasztanak. Juliusnak ez a tömör, de lényegre törő elemzése döntő szerepet játszott az egyes diéták relatív hatékonyságának megértésében.
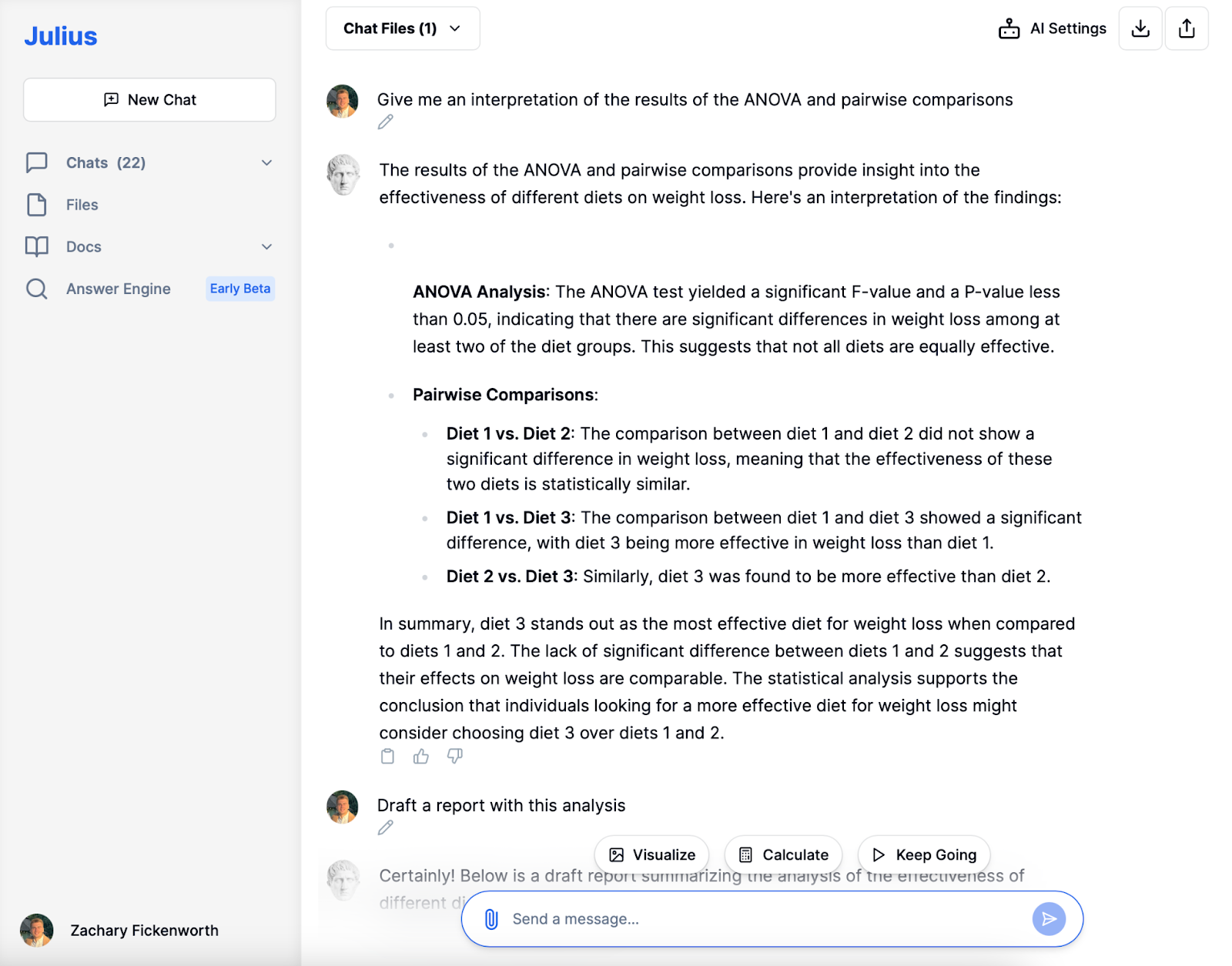
Értelmezés
Az étrend hatékonyságát vizsgáló tanulmányunkban Julius kulcsszerepet játszott az ANOVA és a páronkénti összehasonlítások eredményeinek értelmezésében és magyarázatában. Íme, hogyan segített nekünk megérteni a megállapításokat:
ANOVA értelmezés
Először az ANOVA eredményeket elemezte, amelyek szignifikáns F-értéket és 0.05-nél kisebb P-értéket mutattak. Ez azt jelezte, hogy jelentős különbségek voltak a fogyásban a különböző étrend-csoportok között. Segített megérteni, hogy ez azt jelenti, hogy a vizsgálatban szereplő diéták nem mindegyike volt egyformán hatékony a fogyás elősegítésében.
Páronkénti összehasonlítások értelmezése
- 1. diéta kontra 2. diéta: Összehasonlította ezt a két diétát, és nem talált jelentős különbséget a fogyásban. Ez az értelmezés azt jelentette, hogy statisztikailag ez a két diéta hasonlóan hatékony volt.
- 1. diéta kontra 3. diéta és 2. diéta 3. diéta ellen: Mindkét összehasonlítás során megállapítottam, hogy a 3. diéta lényegesen hatékonyabb volt a fogyás elősegítésében, mint akár az 1., akár a 2. diéta.
Julius értelmezése döntő fontosságú volt abban, hogy elemzésünkből konkrét következtetéseket vonjunk le. Egyértelművé tette, hogy míg az 1. és 2. diéta hasonló hatékonyságú, a 3. diéta a fogyás szempontjából a kiemelkedő lehetőség. Ez az értelmezés nemcsak a tanulmány egyértelmű eredményét adta számunkra, hanem megmutatta eredményeink gyakorlati vonatkozásait is. Ezen információk birtokában magabiztosan azt sugallhatjuk, hogy a 3. diéta lehet a jobb választás azok számára, akik hatékony fogyókúrás megoldásokat keresnek.
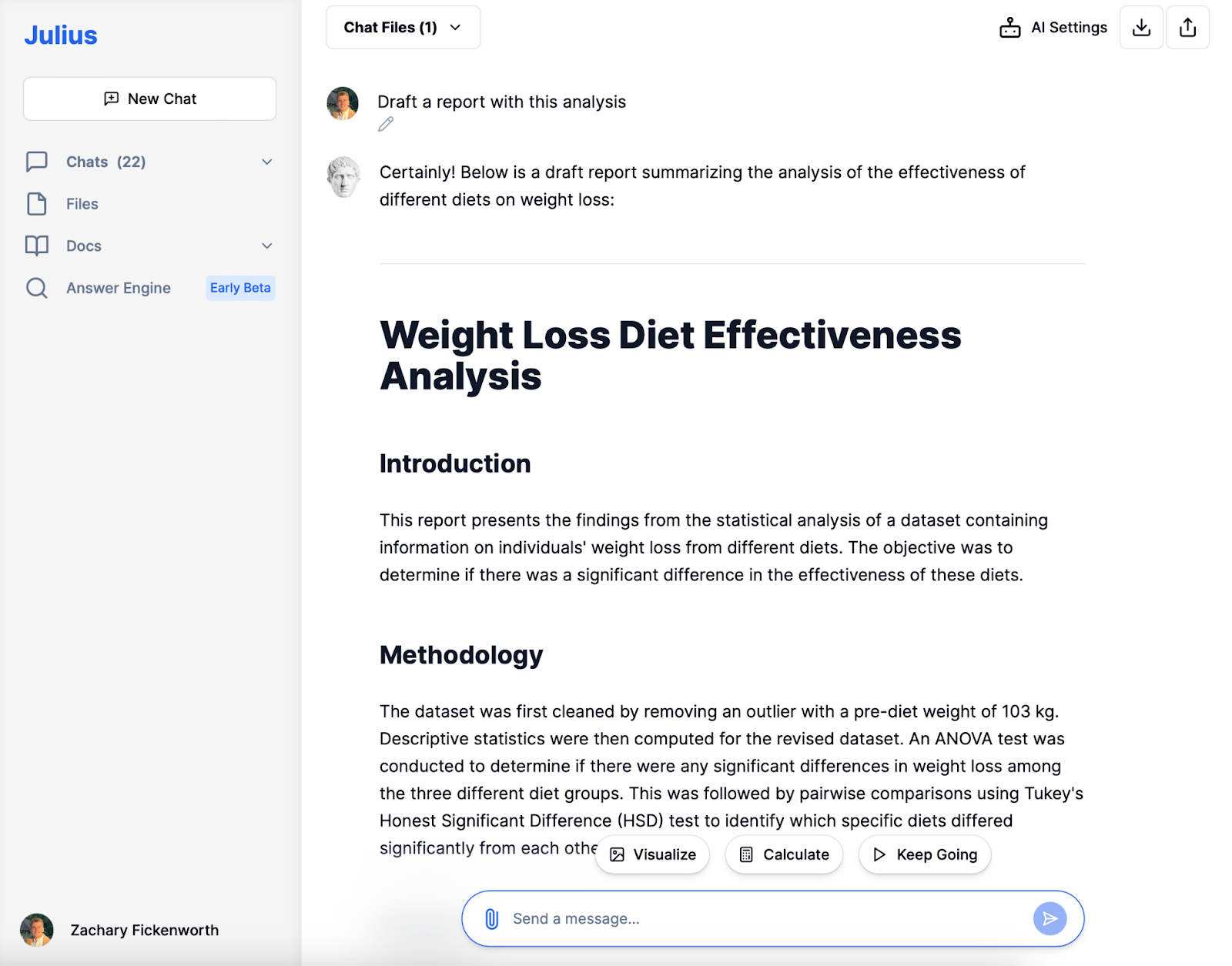
Jelentő
Diétás tanulmányunk utolsó szakaszában elkészítünk egy jelentést, amely szépen összefoglalja teljes kutatási folyamatunkat és eredményeinket. Ez a jelentés, amelyet a Juliussal végzett elemzés vezérel, a következőket tartalmazza:
- Bevezetés: A tanulmány céljának rövid magyarázata, amely a különböző diéták súlycsökkentésre gyakorolt hatékonyságának értékelése.
- Módszertan: Tömör leírás az adatok tisztításának módjáról, az alkalmazott statisztikai módszerekről (ANOVA és Tukey-féle HSD), és arról, hogy miért ezeket választottuk.
- Megállapítások és értelmezés: Az eredmények világos bemutatása, beleértve a diéták közötti jelentős különbségeket, különösen kiemelve a 3. diéta hatékonyságát.
- Következtetés: Végső következtetések levonása az adatokból, és gyakorlati következtetések vagy javaslatok megfogalmazása az eredményeink alapján.
- Referenciák: Idézve azokat az eszközöket és statisztikai módszereket, mint például Julius, amelyek alátámasztották elemzésünket.
Ez a jelentés világos, strukturált és átfogó feljegyzésként szolgálna kutatásunkról, hozzáférhetővé és informatívvá teszi olvasói számára.
Következtetés
Az akadémiai kutatásban tett utunk végéhez értünk, és az étrendekkel kapcsolatos adatkészletet értelmes betekintésekké alakítottuk. Ez a folyamat a kezdeti kérdéstől a zárójelentésig megmutatja, hogy a megfelelő eszközök és módszerek hogyan teszik elérhetővé az adatelemzést még a kezdők számára is.
<p></p> Julius, fejlett mesterséges intelligencia eszközünk, láthattuk, hogy az adatelemzés strukturált lépései hogyan tárhatnak fel fontos trendeket, és hogyan válaszolhatnak meg fontos kérdésekre. Diétákkal és fogyással foglalkozó tanulmányunk csak egy példa arra, hogy az adatok alapos elemzése során nemcsak történetet mesélnek el, hanem világos, megvalósítható következtetéseket is adnak. Reméljük, hogy ez az útmutató rávilágított az adatelemzési folyamatra, így kevésbé ijesztő és izgalmasabb mindazok számára, akik érdeklődnek az adataikban rejtőző történetek feltárása iránt.
Összefüggő
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/
- :van
- :is
- :nem
- :ahol
- 1
- 72
- 77
- a
- egyetemi
- tudományos kutatás
- hozzáférhető
- át
- fejlett
- Után
- kor
- AI
- AI-hajtású
- cél
- Igazítás
- Minden termék
- már
- Is
- között
- an
- elemzések
- elemzés
- elemez
- elemzett
- elemzése
- és a
- válasz
- válaszok
- bármilyen
- bárki
- megközelítés
- megközelíthető
- megfelelő
- körülbelül
- VANNAK
- TERÜLET
- körül
- AS
- feltételezni
- At
- átlagos
- Kiegyensúlyozott
- alapján
- alapvető
- BE
- előtt
- Kezdő
- Kezdők
- hogy
- lent
- Jobb
- között
- Nagy
- mindkét
- de
- by
- jött
- TUD
- gondosan
- eset
- esettanulmány
- esetek
- esély
- jellemzők
- választás
- választott
- tisztázni
- világosság
- Takarításra
- világos
- világosabb
- világosan
- gyűjt
- Gyűjtő
- gyűjtemény
- hogyan
- kommunikálni
- összehasonlítani
- képest
- összehasonlítva
- összehasonlítások
- bonyolult
- átfogó
- fogalmak
- tömör
- megállapítja,
- beton
- lefolytatott
- magabiztosan
- figyelembe véve
- kontextus
- folyamatos
- ellenőrzés
- hagyományos
- tudott
- teremt
- kritikai
- kritikus
- döntően
- dátum
- adatelemzés
- adatkészletek
- mélyebb
- meghatározó
- igazolták
- demisztifikálni
- leírás
- részlet
- részletes
- részletek
- kimutatására
- meghatározza
- meghatározó
- DID
- Diéta
- különbség
- különbségek
- különböző
- közvetlenül
- felfedezése
- terjesztés
- Sokféleség
- Nem
- csinált
- rajz
- ismétlődések
- e
- minden
- Hatékony
- hatékonyan
- hatékonyság
- hatások
- bármelyik
- végén
- biztosítása
- Egész
- egyaránt
- hibák
- különösen
- megállapítja
- stb.
- Eter (ETH)
- értékelni
- Még
- minden
- pontosan
- vizsgálat
- megvizsgálni
- vizsgálva
- példa
- kivételesen
- izgalmas
- létező
- tapasztalat
- magyarázó
- magyarázat
- kutatás
- Feltáró adatelemzés
- megkönnyítette
- elbűvölő
- utolsó
- Találjon
- megtalálása
- megállapítások
- vezetéknév
- görcsök
- Összpontosít
- követ
- következő
- A
- kiszerelés
- talált
- friss
- ból ből
- további
- összegyűjtött
- adott
- nem
- szerzés
- adott
- cél
- jó
- nagyobb
- alapozás
- Csoport
- Csoportok
- útmutató
- vezetett
- Útmutatók
- irányadó
- kellett
- fogantyú
- Kezelés
- Legyen
- Szív
- magasság
- segített
- itt
- Rejtett
- Magas
- <p></p>
- kiemelve
- remény
- Hogyan
- How To
- azonban
- HTTPS
- i
- ideális
- azonosított
- azonosítani
- azonosító
- if
- világít
- nagyon
- Hatás
- következményei
- fontos
- in
- tartalmaz
- magában foglalja a
- Beleértve
- független
- jelzett
- jelző
- egyéni
- egyének
- befolyásolható
- információ
- tájékoztató
- tájékoztatták
- kezdetben
- éleslátó
- meglátások
- sértetlenség
- érdekelt
- értelmezés
- bele
- vizsgálja
- vonja
- jár
- IT
- ITS
- utazás
- Julius
- éppen
- csak egy
- Kulcs
- Ismer
- tudás
- vezet
- vezető
- kevesebb
- fekszik
- fény
- mint
- korlátozások
- betöltés
- néz
- le
- Fő
- fenntartása
- csinál
- KÉSZÍT
- Gyártás
- max-width
- Lehet..
- jelent
- jelentőségteljes
- jelentett
- mérés
- csupán
- módszer
- Módszertan
- mód
- esetleg
- mérföldkő
- hiányzó
- modellek
- több
- a legtöbb
- Természet
- elengedhetetlen
- Szükség
- szükséges
- Új
- nem
- figyelemre méltó
- novícius
- árnyalt
- szám
- célkitűzés
- megfigyelt
- of
- felajánlás
- on
- ONE
- csak
- opció
- or
- Más
- Egyéb
- mi
- ki
- Eredmény
- eredmények
- kívülálló
- átfogó
- pár
- Papír
- rész
- résztvevők
- ösvény
- minták
- Emberek (People)
- teljesít
- teljesített
- fázis
- döntő
- Plató
- Platón adatintelligencia
- PlatoData
- játszott
- potenciális
- erős
- Gyakorlati
- előrejelzésére
- bemutatás
- megőrzése
- folyamat
- támogatása
- megfelelően
- ad
- feltéve,
- biztosít
- világítás
- kérdés
- Kérdések
- egészen
- Nyers
- nyers adatok
- olvasók
- Készenlét
- igazi
- új
- ajánlások
- rekord
- regresszió
- kapcsolat
- Kapcsolatok
- relatív
- eltávolítás
- jelentést
- képvisel
- kutatás
- kutatók
- eredményez
- eredményezett
- Eredmények
- mutatják
- Revealed
- felfedve
- jutalmazó
- jobb
- ütemterv
- Szerep
- Megtakarítás
- keres
- látott
- kiválasztása
- kiválasztás
- szolgál
- Szettek
- számos
- megosztás
- fészer
- kellene
- előadás
- kimutatta,
- mutató
- Műsorok
- jelentős
- jelentősen
- hasonló
- Hasonlóképpen
- helyzetek
- SIX
- Megoldások
- néhány
- különleges
- osztott
- Színpad
- állapota
- standard
- szabvány
- kiáll
- Kezdve
- statisztikai
- statisztikusan
- statisztika
- tartózkodás
- Lépés
- Lépései
- állt
- TÖRTÉNETEK
- Történet
- egyértelmű
- Stratégiai
- erősen
- szerkesztett
- Tanulmány
- Tanul
- későbbi
- javasol
- Támogatott
- biztos
- SVG
- gyorsan
- célzott
- technikák
- megmondja
- feltételek
- teszt
- tesztek
- mint
- hogy
- A
- A terület
- azok
- akkor
- Ott.
- Ezek
- ők
- dolgok
- ezt
- küszöb
- Keresztül
- egész
- idő
- nak nek
- szerszám
- szerszámok
- vágány
- transzformáló
- Trends
- megbízható
- FORDULAT
- Turning
- kettő
- típus
- típusok
- tipikus
- megért
- megértés
- egységek
- bemutatta
- bemutatta
- us
- használ
- használt
- segítségével
- Értékes
- érték
- Értékek
- változó
- különféle
- Megnézem
- vs
- séta
- sétál
- akar
- volt
- Út..
- we
- Hetek
- súly
- JÓL
- voltak
- Mit
- amikor
- vajon
- ami
- míg
- miért
- lesz
- val vel
- belül
- munkafolyamat
- lenne
- még
- te
- A te
- zach
- zephyrnet