A webkaparás hatékony eszköz lehet adatok kinyerésére a webhelyekről, de összetett és időigényes folyamat is lehet. Szerencsére a Google Táblázatok felhasználóbarát megoldást kínálnak a webhelyek adatainak összegyűjtésére anélkül, hogy bonyolult kódot kellene írnia. A Google Táblázatok erejének kihasználásával könnyedén kinyerhet adatokat a weboldalakról, és különféle módokon elemezheti azokat. Ebben a blogban végigvezetem Önt a Google Táblázatok használatával weboldalak kaparására, és segítek kibontakozni a webkaparásban rejlő lehetőségeket saját projektjeihez. Szóval, kezdjük!
A webkaparás időigényes, összetett lehet, és sok kódolást igényel. Nem kódolóknak. A Google Táblázatok kiváló alternatíva a webkaparáshoz. A Google-lapok webkaparása nem igényel kódolást, és számos módot kínál a webhelyadatok elemzésére.
Ebben a blogban látni fogjuk, hogyan használhatja a Google Táblázatokat weboldalak egyszerű kaparására. Tehát kezdjük!
Miért használja a Google Táblázatokat webkaparáshoz?
Számos oka lehet annak, hogy a Google Táblázatok nagyszerű eszköz a webkaparáshoz:
- A Google Táblázatok felhasználóbarát és ismerős felülettel rendelkezik.
- Nem igényel programozási nyelv ismereteket.
- A Google Táblázatok bárhonnan elérhető.
- A Google Táblázatok ingyenes, így magánszemélyek és kisvállalkozások számára megfizethető.
- A Google könnyen integrálható más Suite-eszközökkel.
- Makrók vagy szkriptek segítségével automatizálhatja a webkaparási feladatokat.
- Könnyedén elemezheti a kimásolt adatokat a Google Sheet képletekkel.
Szöveg kibontása bármely weboldalról egyetlen kattintással. Irány a Nanonets weboldal kaparó, Adja hozzá az URL-t, kattintson a „Scrape” gombra, és azonnal töltse le a weboldal szövegét fájlként. Próbáld ki most ingyen.
Milyen funkciókat kell használni a Google Táblázatok webkaparásához?
Íme néhány funkció, amelyeket akkor használhat, ha weboldalakat kell kimásolnia a Google Táblázatok használatával.
IMPORTHTML:
Táblázatok és listák kibontása HTML oldalakról.
=IMPORTHTML(url, query, index)- url: Ez a lemásolni kívánt weboldal linkje
- lekérdezés: Az adattípus – Táblázat, Lista
- index: Ha egy adott táblát szeretne kibontani, akkor ezt használhatja
Példa:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)","table",1)IMPORTXML:
Adatok kinyerése XML-oldalakról.
=IMPORTXML(url, xpath_query)- url: Ez a link a kimásolni kívánt weboldalra
- xpath_query: az XPath kifejezés, amely azonosítja a kinyerni kívánt adatokat
Példa:
=IMPORTXML("https://www.w3schools.com/xml/note.xml", "//note/to")IMPORTADATOK:
Adatok kibontása CSV- és TSV-fájlokból.
=IMPORTDATA(url)- url: annak a CSV- vagy TSV-fájlnak az URL-címe, amelyből adatokat szeretne kinyerni
Példa:
=IMPORTDATA("https://www.stats.govt.nz/assets/Uploads/Annual-enterprise-survey/Annual-enterprise-survey-2021-financial-year-provisional/Download-data/annual-enterprise-survey-2021-financial-year-provisional-size-bands.csv")REGEXTRACT:
Ez a függvény olyan adatokat tud kivonni, amelyek megfelelnek egy reguláris kifejezésmintának.
=REGEXEXTRACT(text, regular_expression)- szöveg: az a szöveg, amelyben a mintát keresni kívánja
- reguláris_kifejezés: a megfeleltetni kívánt minta
Példa:
=REGEXEXTRACT("1 pound = $1.40", "$d+.d+")Megjegyzés: Előfordulhat, hogy ezek a funkciók nem működnek minden egyes webhelyen. Ez a weboldal elrendezésétől függ. Ha több adatra van szüksége, akkor Python és Java használatával webkaparási oktatóanyagokat vehet igénybe, vagy használhat webhely-szöveg eszközt, például Nanoneteket.
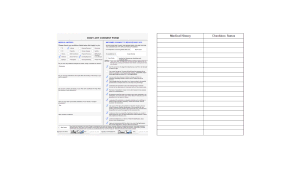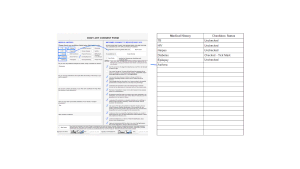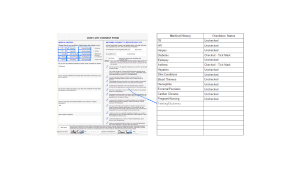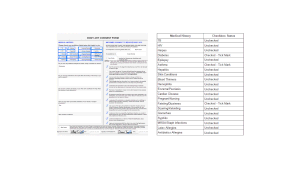
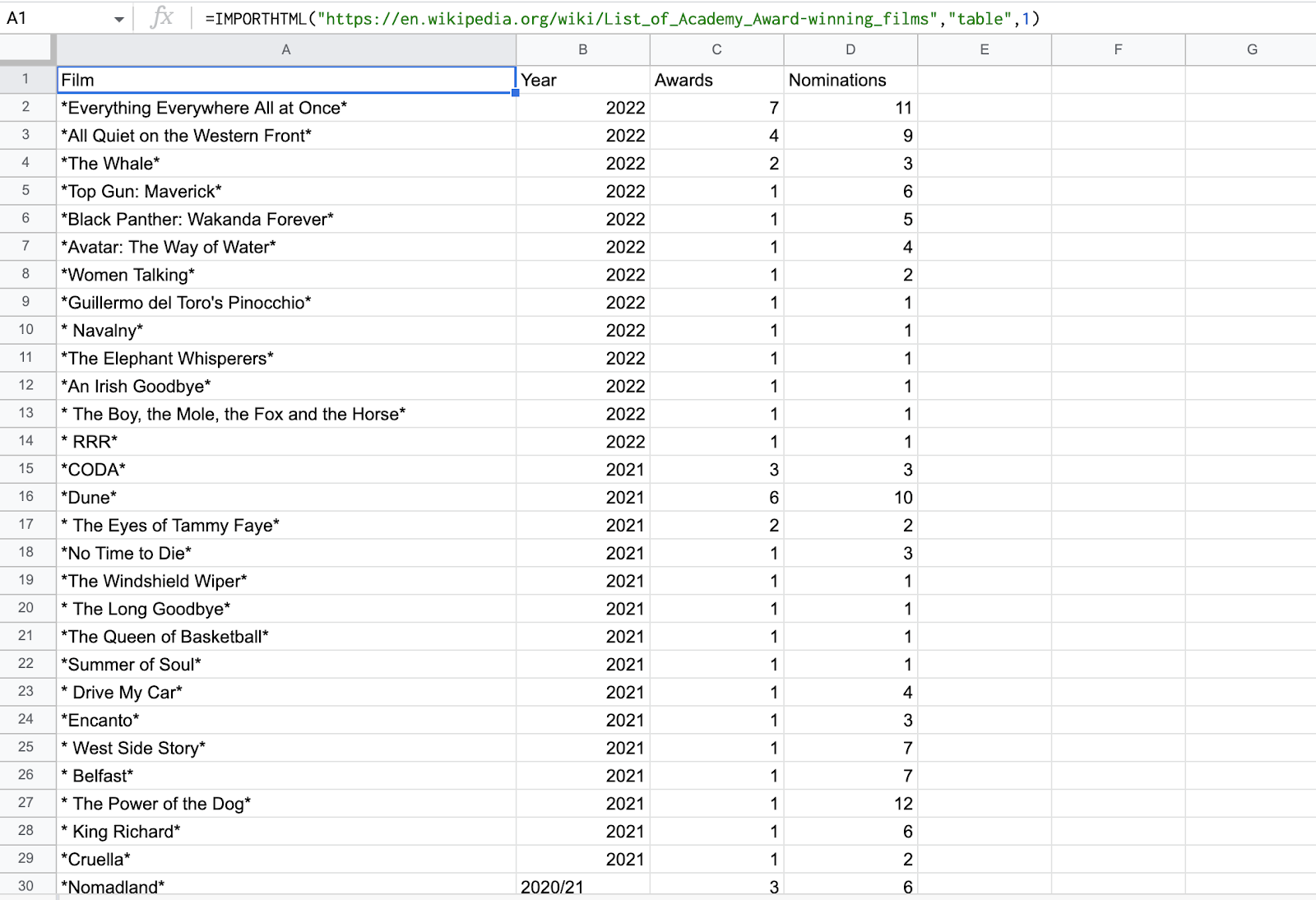
Próbáljunk kicsomagolni egy HTML-táblázatot a Google Táblázatokba. Megpróbáljuk lekaparni az asztalt a Az Akadémia-díjas filmek listája Wikipédia-oldal.
- Nyissa meg a Google Táblázatokat.
- Egy új cellába írja be: =IMPORTHTML(url, lekérdezés, index)
1. A kódunk a következő lesz:
=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1) =IMPORTHTML("https://en.wikipedia.org/wiki/List_of_Academy_Award-winning_films","table",1)
lekaparja az első táblázatot a Wikipédia oldalán
3. Ellenőrizze az eredményeket
Hogyan lehet adatokat kaparni a Google Táblázatok webkaparásával?
Nézzük meg, hogyan lehet címeket, leírásokat, H1-et és egyebeket kimásolni a Google Táblázatok segítségével. A Google Táblázatok H1-kaparásának megkezdéséhez az IMPORTXML függvényt használjuk erre a célra. Nanonets oldal. Íme a lépések:
- Nyisson meg egy új vagy meglévő Google-táblázatot.
- Egy cellába írja be a következő képletet:
=IMPORTXML(“https://nanonets.com/image-to-text”, “//h1/text()”)- A H1 címke kibontásához használja a következő XPath kifejezést: //h1/text()
- A title címke kibontásához használja a következő XPath kifejezést: //title/text()
- A meta description címke kibontásához használja a következő XPath kifejezést: //meta[@name='description']/@content
- Az összes oldalhivatkozás kibontásához használja a következő XPath kifejezést: //a/@href
Nyomja meg az Enter billentyűt, és a Google Táblázatok automatikusan kikaparja az adatokat, és megjeleníti azokat a kiválasztott cellában.
Ezután a képletet más cellákba másolhatja, hogy további adatokat kaparjon le ugyanarról vagy különböző weboldalról.
Szöveg kibontása bármely weboldalról egyetlen kattintással. Irány a Nanonets weboldal kaparó, Adja hozzá az URL-t, kattintson a „Scrape” gombra, és azonnal töltse le a weboldal szövegét fájlként. Próbáld ki most ingyen.
Milyen hátrányai vannak a Google Sheets Web Scraper használatának?
- A Google Táblázatok funkciói korlátozottak. Ha összetett elrendezésről van szó, nem tudja kezelni a dinamikus tartalmat.
- Adateltérések adódhatnak az adatoknak a Google Táblázatok internetes lekaparási képleteivel történő lemásolása során.
- Amikor adatokat másol le webhelyekről, véletlenül érzékeny vagy bizalmas információkat is lekaparhat. Ez adatvédelmi és biztonsági aggályokat vethet fel, különösen, ha a kimásolt adatokat megosztják vagy nem biztonságos helyen tárolják.
Tipp: A Google Sheets Web Scraping nagyszerű alternatíva az olyan nem bonyolult webes lemásolási feladatokhoz, mint a metacímek, listák vagy táblázatok kivonatolása. Összetett feladatokhoz webkaparó eszközöket kell használnia.
GYIK
Tudok webkaparni a Google Táblázatokkal?
Igen, a Google Táblázatok olyan beépített funkciókkal rendelkezik, mint az IMPORTHTML, IMPORTXML, IMPORTDATA,
és REGEXTRACT, amelyek lehetővé teszik, hogy adatokat rögzítsen webhelyekről közvetlenül a Google Táblázatokba. A funkcionalitás azonban korlátozott lehet, és az összetettebb webkaparási feladatokhoz külön webkaparó használatára vagy egyéni kód írására lehet szükség.
Hogyan kaparhatok adatokat egy Google-lapra?
A beépített függvények egyikével, például az IMPORTHTML, IMPORTXML, IMPORTDATA vagy REGEXTRACT használatával adatokat kaparhat a Google-táblázatba. Ezek a funkciók lehetővé teszik az adatok kinyerését webhelyekről, CSV- vagy TSV-fájlokból, és reguláris kifejezés-mintákkal való egyeztetést. Egyszerűen adja meg az URL-t, a lekérdezést, az indexet vagy a reguláris kifejezés-mintát, és az adatokat a rendszer kimásolja és feltölti a Google-táblázatába.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://nanonets.com/blog/scrape-websites-using-google-sheets-formulas/
- :is
- 1
- 11
- 2023
- 7
- a
- Akadémia
- hozzáférhető
- További
- megfizethető
- Minden termék
- alternatív
- elemez
- és a
- bárhol
- VANNAK
- AS
- automatizált
- automatikusan
- díjnyertes
- BE
- válik
- Blog
- beépített
- vállalkozások
- by
- TUD
- képességek
- elfog
- eset
- Cellák
- ellenőrizze
- kettyenés
- közel
- kód
- Kódolás
- bonyolult
- aggodalmak
- tartalom
- szokás
- dátum
- függ
- leírás
- különböző
- közvetlenül
- kijelző
- letöltés
- dinamikus
- minden
- könnyen
- belép
- különösen
- Eter (ETH)
- Minden
- kiváló
- létező
- kivonat
- kitermelés
- ismerős
- Jellemzők
- filé
- Fájlok
- filmek
- vezetéknév
- következő
- A
- képlet
- szerencsére
- Ingyenes
- ból ből
- funkció
- funkcionalitás
- funkciók
- kap
- Korm
- nagy
- útmutató
- fogantyú
- fej
- segít
- itt
- Hogyan
- How To
- azonban
- HTML
- HTTPS
- i
- azonosítja
- in
- index
- egyének
- információ
- integrál
- Felület
- vonja
- IT
- Jáva
- csak egy
- tudás
- nyelv
- elrendezés
- erőfölény
- mint
- Korlátozott
- LINK
- linkek
- listák
- elhelyezkedés
- Sok
- Makrók
- Gyártás
- sok
- Mérkőzés
- meta
- esetleg
- több
- Szükség
- igénylő
- Új
- of
- Ajánlatok
- on
- ONE
- érdekében
- Más
- saját
- oldal
- különös
- Mintás
- minták
- Plató
- Platón adatintelligencia
- PlatoData
- benépesített
- potenciális
- font
- hatalom
- erős
- magánélet
- Adatvédelem és biztonság
- folyamat
- Programozás
- projektek
- biztosít
- Piton
- emel
- miatt
- szabályos
- szükség
- megköveteli,
- Resort
- s
- azonos
- kaparás
- szkriptek
- Keresés
- biztonság
- kiválasztott
- érzékeny
- különálló
- számos
- megosztott
- kellene
- Egyszerű
- egyszerűen
- kicsi
- kisvállalkozások
- So
- megoldások
- néhány
- különleges
- kezdődött
- statisztika
- Lépései
- memorizált
- ilyen
- kíséret
- táblázat
- asztal kivonás
- TAG
- feladatok
- hogy
- A
- Ezek
- Keresztül
- időigényes
- Cím
- címei
- nak nek
- szerszám
- szerszámok
- oktatóanyagok
- kinyit
- fedezetlen
- URL
- használ
- barátságos felhasználói
- fajta
- módon
- háló
- webes kaparás
- weboldal
- honlapok
- Wikipedia
- lesz
- val vel
- nélkül
- Munka
- ír
- írás
- XML
- A te
- zephyrnet