
20. szeptember 2023.
Alapmodellek (FM-ek) egy új korszak kezdetét jelzik gépi tanulás (ML) és a mesterséges intelligencia (AI), ami a mesterséges intelligencia gyorsabb fejlesztéséhez vezet, amely sokféle downstream feladathoz igazítható, és számos alkalmazáshoz finomhangolható.
Az adatok feldolgozásának egyre fontosabbá válásával a munkavégzés helyén, a mesterséges intelligencia modellek vállalati élvonalbeli kiszolgálása közel valós idejű előrejelzéseket tesz lehetővé, miközben betartja az adatszuverenitási és adatvédelmi követelményeket. Kombinálva a IBM watsonx adat- és mesterséges intelligencia platform képességei az élszámítással rendelkező FM-ekhez, a vállalatok mesterséges intelligencia munkaterheléseket futtathatnak az FM finomhangolásához és a műveleti széleken történő következtetésekhez. Ez lehetővé teszi a vállalatok számára, hogy az AI-telepítéseket a széleken méretezzék, csökkentve a telepítés idejét és költségeit a gyorsabb válaszidővel.
Kérjük, feltétlenül nézze meg az éles számítástechnikával foglalkozó blogbejegyzések sorozatának összes részletét:
Mik azok az alapmodellek?
Az alapmodellek (FM-ek), amelyeket a címkézetlen adatok széles skáláján képeznek ki, a legkorszerűbb mesterséges intelligencia (AI) alkalmazásokat hajtják végre. A későbbi feladatok széles skálájához illeszthetők, és számos alkalmazáshoz finomhangolhatók. A modern AI-modellek, amelyek meghatározott feladatokat egyetlen tartományban hajtanak végre, átadják a helyét az FM-eknek, mert általánosabban tanulnak, és több tartományon és problémán keresztül dolgoznak. Ahogy a neve is sugallja, az FM az AI modell számos alkalmazásának alapja lehet.
Az FM-ek két olyan kulcsfontosságú kihívással foglalkoznak, amelyek visszatartották a vállalkozásokat attól, hogy az AI alkalmazását átlépjék. Először is, a vállalatok hatalmas mennyiségű címkézetlen adatot állítanak elő, amelyeknek csak a töredéke van címkézve az AI modellképzéshez. Másodszor, ez a címkézési és annotálási feladat rendkívül emberigényes, és gyakran több száz órát igényel a téma szakértőjének (KKV) munkájából. Ez költségkímélővé teszi a felhasználási esetek közötti skálázást, mivel ehhez KKV-k és adatszakértők serege lenne szükséges. Hatalmas mennyiségű címkézetlen adat befogadásával és önfelügyelt modellképzési technikák alkalmazásával az FM-ek megszüntették ezeket a szűk keresztmetszeteket, és utat nyitottak az AI széles körű elterjedéséhez a vállalaton belül. Ez a hatalmas mennyiségű adat, amely minden vállalkozásban megtalálható, arra vár, hogy szabadjára engedjék őket, hogy betekintést nyerjenek.
Mik azok a nagy nyelvi modellek?
A nagy nyelvi modellek (LLM) az alapmodellek (FM) egy osztálya, amelyek rétegekből állnak neurális hálózatok akiket erre a hatalmas mennyiségű címkézetlen adatra képeztek ki. Önfelügyelt tanulási algoritmusokat használnak különféle feladatok elvégzésére természetes nyelv feldolgozása (NLP) a feladatokat az emberek nyelvhasználatához hasonló módon (lásd 1. ábra).
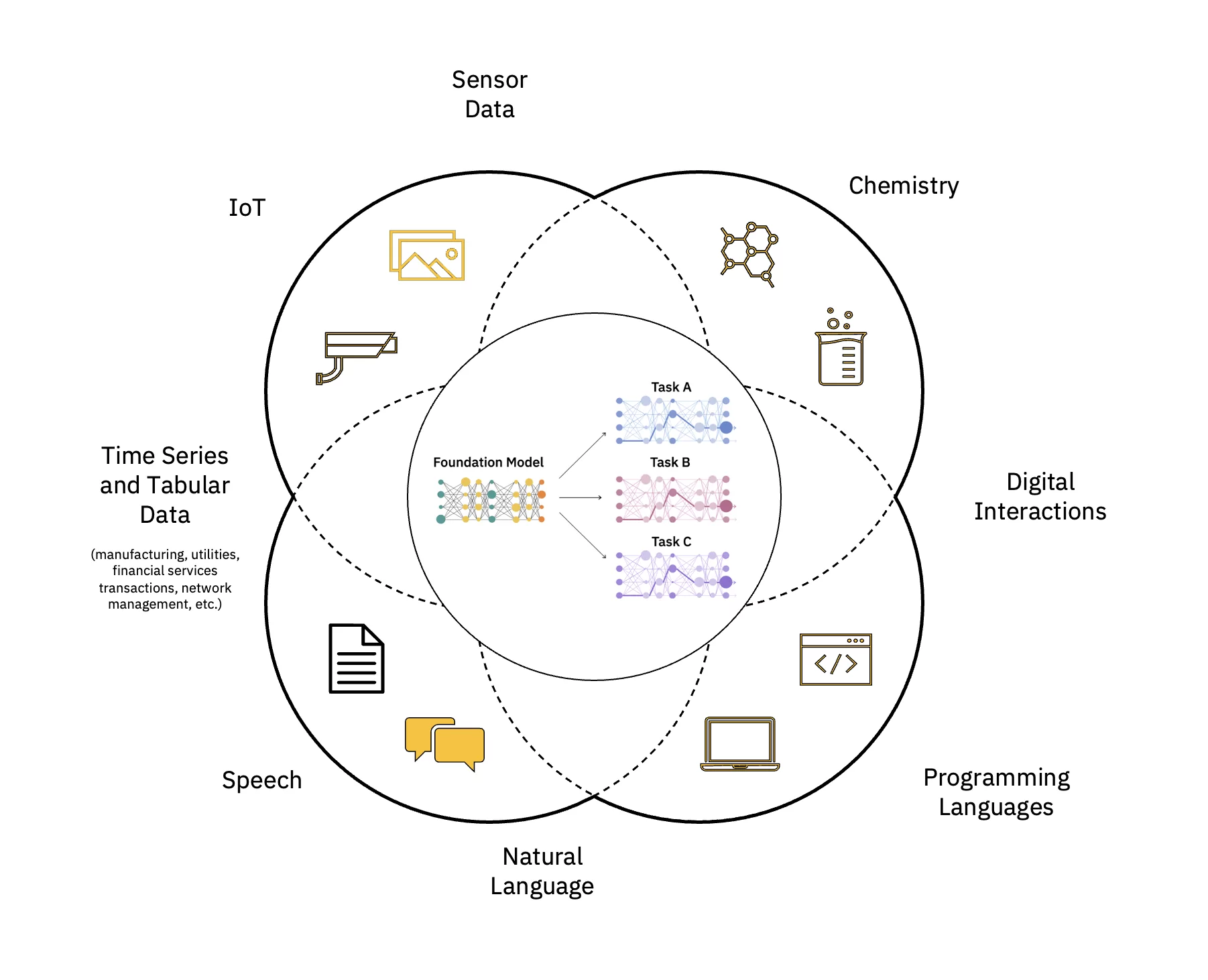
Méretezze és gyorsítsa fel az AI hatását
Az alapmodell (FM) felépítése és telepítése több lépésből áll. Ezek közé tartozik az adatfeldolgozás, az adatkiválasztás, az adatok előfeldolgozása, az FM előképzés, a modell hangolása egy vagy több downstream feladatra, a következtetések kiszolgálása, valamint az adat- és mesterségesintelligencia-modell irányítása és életciklus-kezelése – ezek mindegyike a következőképpen írható le: FMOps.
Hogy mindezt segítse, az IBM felajánlja a vállalatoknak a szükséges eszközöket és képességeket, hogy kiaknázhassák ezen FM-ek teljesítményét. IBM watsonx, egy vállalati használatra kész mesterséges intelligencia és adatplatform, amelyet arra terveztek, hogy megsokszorozza az AI hatását a vállalaton belül. Az IBM watsonx a következőkből áll:
- IBM watsonx.ai újat hoz generatív AI az FM-ek és a hagyományos gépi tanulás (ML) által meghajtott képességek egy nagy teljesítményű stúdióvá, amely az AI életciklusát felöleli.
- IBM watsonx.data egy nyílt lakehouse architektúrára épülő, célnak megfelelő adattár, amellyel bárhol méretezheti az AI-munkaterhelést az összes adatához.
- IBM watsonx.governance egy teljes körű automatizált AI-életciklus-irányítási eszköztár, amely felelős, átlátható és magyarázható AI-munkafolyamatokat tesz lehetővé.
Egy másik kulcsfontosságú vektor a számítástechnika növekvő jelentősége a vállalati széleken, például ipari helyszíneken, gyártási területeken, kiskereskedelmi üzletekben, telekommunikációs telephelyeken stb. Pontosabban, a vállalati széleken az AI lehetővé teszi az adatok feldolgozását ott, ahol a munka folyik. közel valós idejű elemzés. A vállalati előny az, ahol hatalmas mennyiségű vállalati adat keletkezik, és ahol az AI értékes, időszerű és hasznosítható üzleti betekintést nyújthat.
Az AI-modellek szélén való kiszolgálása közel valós idejű előrejelzéseket tesz lehetővé, miközben betartja az adatszuverenitási és adatvédelmi követelményeket. Ez jelentősen csökkenti az ellenőrzési adatok megszerzéséhez, továbbításához, átalakításához és feldolgozásához gyakran kapcsolódó késleltetést. Az élvonalbeli munka lehetővé teszi számunkra, hogy megóvjuk az érzékeny vállalati adatokat, és gyorsabb válaszidővel csökkentsük az adatátviteli költségeket.
Az AI-telepítések méretezése a széleken azonban nem könnyű feladat az adatokkal (heterogenitás, mennyiség és szabályozási) és korlátozott erőforrásokkal (számítási, hálózati kapcsolat, tárolási és még informatikai ismeretek) kapcsolatos kihívások közepette. Ezek nagyjából két kategóriába sorolhatók:
- Telepítési idő/költség: Minden egyes telepítés több hardver- és szoftverrétegből áll, amelyeket a telepítés előtt telepíteni, konfigurálni és tesztelni kell. Ma egy szerviz szakembernek akár egy-két hetet is igénybe vehet a telepítés minden helyszínen, súlyosan korlátozza, hogy a vállalatok milyen gyorsan és költséghatékonyan bővíthetik a telepítést szervezetükben.
- 2. nap kezelés: A telepített szegélyek nagy száma és az egyes telepítések földrajzi elhelyezkedése gyakran rendkívül költségessé teheti a helyi IT-támogatás biztosítását az egyes helyszíneken a telepítések figyeléséhez, karbantartásához és frissítéséhez.
Edge AI telepítések
Az IBM kifejlesztett egy éles architektúrát, amely megválaszolja ezeket a kihívásokat azáltal, hogy integrált hardver/szoftver (HW/SW) készülékmodellt hoz a szélsőséges AI-telepítésekbe. Számos kulcsfontosságú paradigmából áll, amelyek elősegítik az AI-telepítések méretezhetőségét:
- A teljes szoftvercsomag házirend-alapú, zéró érintés nélküli kiépítése.
- Az élrendszer állapotának folyamatos figyelése
- Lehetőségek a szoftver-/biztonsági/konfigurációs frissítések kezelésére és számos szélső helyre történő eljuttatására – mindezt egy központi felhőalapú helyről a 2. napos kezeléshez.
Az elosztott hub-and-spoke architektúra használható a vállalati mesterségesintelligencia-telepítések skálázására a széleken, ahol egy központi felhő vagy vállalati adatközpont hubként, az él a dobozban készülék pedig küllőként működik a széleken.. Ez a hibrid felhő- és szélkörnyezetekre kiterjedő hub- és küllőmodell szemlélteti legjobban az FM-műveletekhez szükséges erőforrások optimális kihasználásához szükséges egyensúlyt (lásd a 2. ábrát).
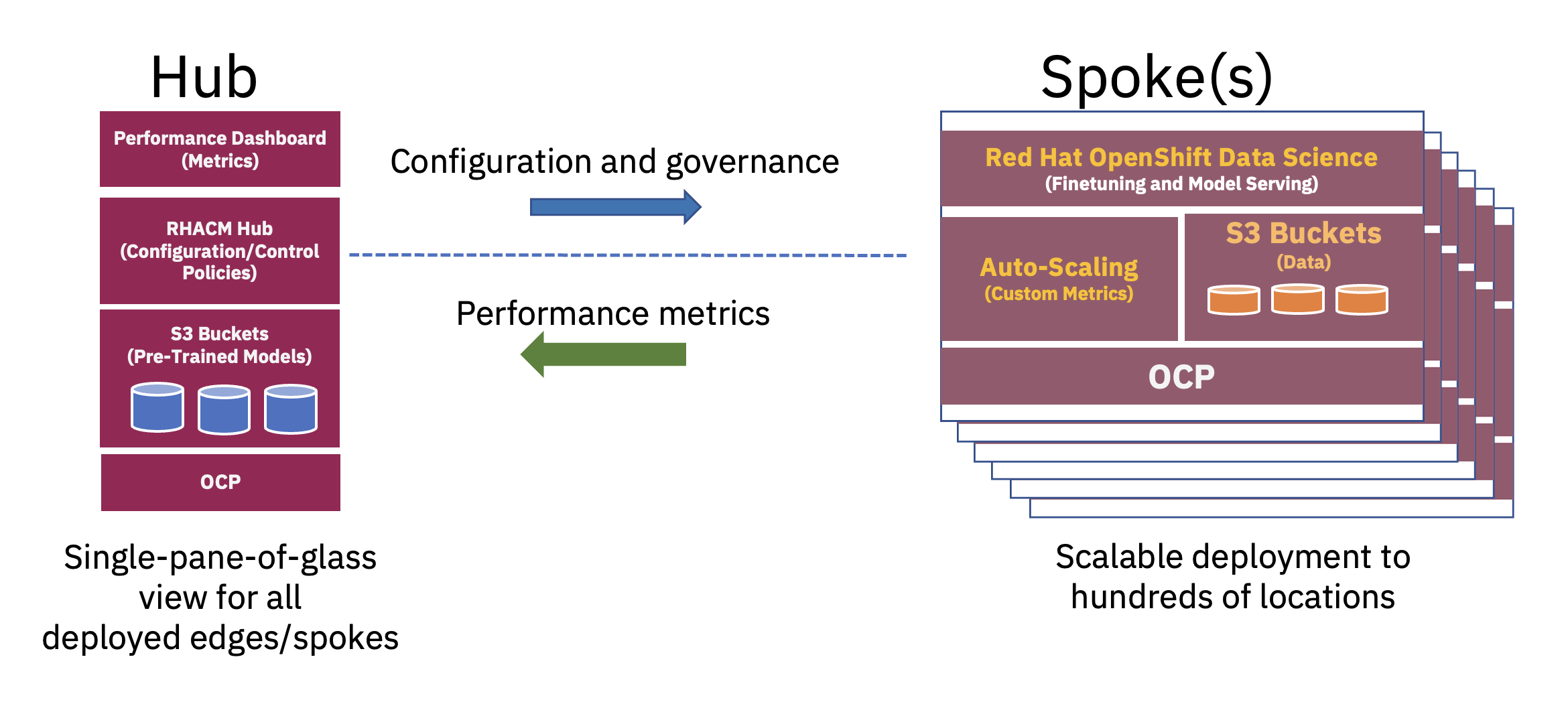
Ezeknek a nagy nyelvi alapmodelleknek (LLM-eknek) és más típusú alapmodelleknek az önfelügyelt technikákat használó, hatalmas, címkézetlen adatkészleteken történő előképzése gyakran jelentős számítási (GPU) erőforrásokat igényel, és a legjobb egy központban végrehajtani. A gyakorlatilag korlátlan számítási erőforrások és a gyakran felhőben tárolt nagy adathalmok lehetővé teszik a nagyparaméteres modellek előzetes betanítását és ezen alapmodellek pontosságának folyamatos javítását.
Másrészt ezeknek az alap FM-eknek a downstream feladatokhoz való hangolása – amelyekhez csak néhány tíz vagy száz címkézett adatminta és következtetési szolgáltatás szükséges – csak néhány GPU-val hajtható végre a vállalat szélén. Ez lehetővé teszi, hogy az érzékeny címkézett adatok (vagy vállalati koronaékszer adatok) biztonságosan maradjanak a vállalati működési környezetben, miközben csökkentik az adatátviteli költségeket.
Az alkalmazások szélsőséges üzembe helyezésére szolgáló full-stack megközelítést használó adattudósok elvégezhetik a modellek finomhangolását, tesztelését és üzembe helyezését. Ez egyetlen környezetben valósítható meg, miközben csökkenti az új AI-modellek végfelhasználók számára történő kiszolgálásának fejlesztési életciklusát. Az olyan platformok, mint a Red Hat OpenShift Data Science (RHODS) és a nemrégiben bejelentett Red Hat OpenShift AI eszközöket biztosítanak a gyártásra kész mesterséges intelligencia modellek gyors fejlesztéséhez és bevezetéséhez elosztott felhő és peremkörnyezetek.
Végül, a finomhangolt AI-modell vállalati élen történő kiszolgálása jelentősen csökkenti az adatok megszerzéséhez, továbbításához, átalakításához és feldolgozásához gyakran kapcsolódó késleltetést. A felhőben végzett előképzés szétválasztása a finomhangolástól és a szélső következtetések levonásától csökkenti a teljes működési költséget azáltal, hogy csökkenti a következtetési feladathoz kapcsolódó időigényt és adatmozgatási költségeket (lásd 3. ábra).
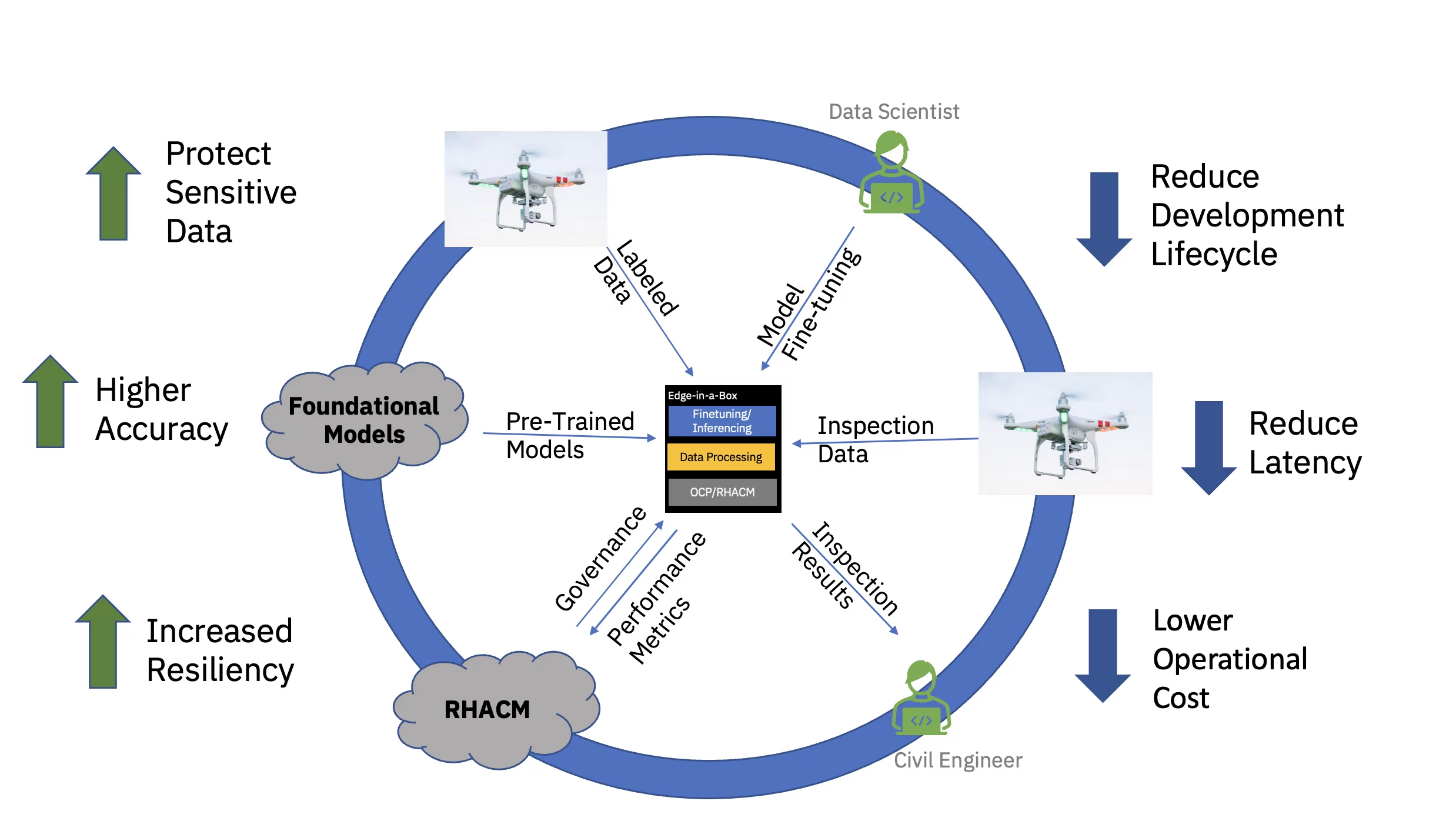
Ennek az értékajánlatnak a végpontokig történő demonstrálására egy példaértékű, látvány-transzformátor-alapú alapmodell a civil infrastruktúrához (előzetesen kiképzett nyilvános és egyéni iparág-specifikus adatkészletekkel) finomhangolásra került, és a következtetések levonására egy három csomópontos élen került sor. (küllő) fürt. A szoftvercsomag tartalmazta a Red Hat OpenShift Container Platformot és a Red Hat OpenShift Data Science-t. Ez az élfürt a Red Hat Advanced Cluster Management for Kubernetes (RHACM) hub egy felhőben futó példányához is csatlakozik.
Nulla érintés nélküli kiépítés
A házirend-alapú, nulla érintés nélküli kiépítés a Red Hat Advanced Cluster Management for Kubernetes (RHACM) segítségével házirendeken és elhelyezési címkéken keresztül történt, amelyek meghatározott élfürtöket szoftverösszetevők és konfigurációk készletéhez kötik. Ezeket a szoftverkomponenseket – amelyek a teljes veremre kiterjednek, és lefedik a számításokat, a tárolást, a hálózatot és a mesterséges intelligencia munkaterhelését – különféle OpenShift-operátorok, a szükséges alkalmazásszolgáltatások és az S3 Bucket (tárhely) segítségével telepítették.
A polgári infrastruktúra előre betanított alapmodelljét (FM) a Red Hat OpenShift Data Science (RHODS) Jupyter Notebook segítségével finomhangolták címkézett adatok felhasználásával a betonhidakon talált hatféle hiba osztályozására. Ennek a finomhangolt FM-nek a következtetési kiszolgálását Triton szerverrel is demonstrálták. Ezen túlmenően az élrendszer állapotának nyomon követését a hardver- és szoftverkomponensek megfigyelhetőségi mutatóinak a Prometheuson keresztül a felhő központi RHACM irányítópultjáig történő összesítése tette lehetővé. A polgári infrastruktúrával foglalkozó vállalatok telepíthetik ezeket az FM-eket peremhelyeiken, és drónfelvételek segítségével közel valós időben észlelhetik a hibákat – így felgyorsul a betekintéshez szükséges idő, és csökkenthető a nagy mennyiségű nagyfelbontású adat felhőbe és onnan történő mozgatásának költségei.
Összegzésként
ötvözi IBM watsonx Az alapmodellek (FM) adat- és mesterséges intelligenciaplatform-képességei az él a dobozban készülékkel lehetővé teszik a vállalatok számára, hogy mesterséges intelligencia-munkaterheléseket futtassák az FM finomhangolása és a működési széleken történő következtetések levonására. Ez a készülék már a dobozból is képes kezelni az összetett használati eseteket, és kiépíti a központosított felügyelet, automatizálás és önkiszolgálás hub-and-spoke keretrendszerét. Az Edge FM telepítések hetekről órákra csökkenthetők megismételhető sikerrel, nagyobb rugalmassággal és biztonsággal.
Tudjon meg többet az alapmodellekről
Kérjük, feltétlenül nézze meg az éles számítástechnikával foglalkozó blogbejegyzések sorozatának összes részletét:
Továbbiak a Cloudból




- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://www.ibm.com/blog/foundational-models-at-the-edge/
- :van
- :is
- :nem
- :ahol
- $ UP
- 08
- 1
- 10
- 13
- 15%
- 20
- 2023
- 22
- 28
- 29
- 30
- 300
- 39
- 400
- 41
- 7
- 70
- 9
- a
- Rólunk
- gyorsul
- hozzáférés
- megvalósítható
- pontosság
- beszerzés
- át
- cselekmények
- igazítani
- Ezen kívül
- cím
- címek
- Örökbefogadás
- fejlett
- fejlesztések
- Hirdetés
- AI
- AI elfogadása
- AI modellek
- AI platform
- Támogatás
- algoritmusok
- Minden termék
- lehetővé
- lehetővé teszi, hogy
- Is
- Között
- összeg
- Összegek
- amp
- an
- elemzés
- analitika
- és a
- bejelentés
- bármilyen
- bárhol
- Alkalmazás
- alkalmazások
- megközelítés
- építészet
- VANNAK
- Sor
- cikkben
- mesterséges
- mesterséges intelligencia
- Mesterséges intelligencia (AI)
- AS
- társult
- At
- szerző
- Automatizált
- Automatizálás
- elérhető
- Sugárút
- vissza
- Egyenleg
- Bank
- Banks
- bázis
- BE
- mert
- válik
- egyre
- óta
- Kezdet
- hogy
- Hisz
- BEST
- kötődik
- Blog
- Blogbejegyzések
- blogok
- mindkét
- Doboz
- hidak
- Bringing
- Bring
- széles
- nagyjából
- Épület
- épít
- épült
- üzleti
- by
- TUD
- képességek
- tőke
- Rögzítése
- szén
- kártya
- Kártyák
- esetek
- CAT
- kategóriák
- Okoz
- Központ
- központi
- Központi Bank
- a központi bank digitális valutái
- központosított
- lánc
- kihívások
- változik
- változó
- ellenőrizze
- választás
- körök
- CIS
- civil
- osztály
- osztályoz
- világos
- ügyfél részére
- szorosan
- felhő
- Fürt
- szín
- színes
- kombinálása
- versenyképes
- bonyolult
- bonyolultság
- teljesítés
- alkatrészek
- Kiszámít
- számítástechnika
- Configuration
- konfigurálva
- összefüggő
- Connectivity
- áll
- Konténer
- folytatódik
- ellenőrzés
- Költség
- kiadások
- tudott
- fedő
- cryptocurrency
- CSS
- pénznem
- szokás
- vevő
- Vásárlói élmény
- Ügyfelek
- műszerfal
- dátum
- Adatközpont
- Adatplatform
- adat-tudomány
- adattudós
- adatkészletek
- találka
- elszánt
- alapértelmezett
- definíciók
- szállít
- bizonyítani
- igazolták
- telepíteni
- telepített
- bevezetéséhez
- bevetés
- bevetések
- leírt
- leírás
- tervezett
- Fejleszt
- fejlett
- Fejlesztés
- digitális
- digitális valuták
- digitalizálás
- Zavar
- bomlasztó
- Zavarók
- megosztott
- kerület
- domain
- domainek
- csinált
- hajtás
- vezetés
- zümmög
- minden
- könnyű
- ökoszisztéma
- él
- szélsőséges számítástechnika
- ELEMELNI
- emelkedett
- lehetővé
- lehetővé teszi
- végén
- végtől végig
- mérnök
- Mérnöki
- belép
- Vállalkozás
- Vállalatok
- bejövő
- Környezet
- környezetek
- Ez volt
- különösen
- stb.
- Eter (ETH)
- Még
- események
- Minden
- alakult ki
- vizsgálva
- példák
- kivégez
- létezik
- Kilépés
- drága
- tapasztalat
- szakértők
- Megmagyarázható AI
- magyarázó
- kiterjedő
- rendkívüli módon
- tényezők
- GYORS
- gyorsabb
- kevés
- mező
- Ábra
- pénzügyi
- Pénzintézetek
- finanszírozás
- vezetéknév
- padló
- következik
- következő
- betűtípusok
- A
- Forefront
- talált
- Alapítvány
- töredék
- Keretrendszer
- ból ből
- Tele
- Teljes verem
- Továbbá
- általában
- generált
- generátor
- földrajzi
- Geopolitika
- Giving
- Globális
- globális kereskedelem
- kormányzás
- GPU
- GPU
- Rács
- kéz
- fogantyú
- hardver
- kalap
- Legyen
- Egészség
- magasság
- segít
- segít
- segít
- nagyfelbontású
- <p></p>
- nagyon
- történelem
- vendéglátó
- NYITVATARTÁS
- Hogyan
- How To
- azonban
- HTTPS
- Kerékagy
- Az emberek
- Több száz
- hibrid
- hibrid felhő
- IBM
- IBM Cloud
- ICO
- ICON
- illusztrálja
- kép
- Hatás
- fontosság
- javulás
- in
- tartalmaz
- beleértve
- növekvő
- egyre inkább
- index
- ipari
- iparágak
- ipar
- iparág-specifikus
- infláció
- ragozás
- Inflexiós pont
- befolyásolható
- Infrastruktúra
- Kezdeményezés
- Innováció
- újító
- bemenet
- meglátások
- példa
- intézmények
- integrált
- Intelligencia
- belső
- bevezetéséről
- IT
- IT Support
- Journeys
- jpg
- ugrás
- Jupyter Jegyzetfüzet
- éppen
- csak egy
- tartotta
- Kulcs
- Kubernetes
- címkézés
- nyelv
- nagy
- nagymértékben
- Késleltetés
- legutolsó
- tojók
- vezető
- TANUL
- tanulás
- Tőkeáttétel
- életciklus
- mint
- határtalan
- linux
- helyi
- helyszín
- elhelyezkedés
- helyszínek
- Hosszú
- néz
- gép
- gépi tanulás
- készült
- fenntartása
- csinál
- KÉSZÍT
- kezelése
- vezetés
- gyártási
- sok
- jelzés
- tömeges
- mester
- Anyag
- max-width
- mechanizmusok
- mód
- Metrics
- perc
- minimalizálása
- jegyzőkönyv
- ML
- Mobil
- modell
- modellek
- modern
- korszerűsítés
- korszerűsítésére
- monitor
- ellenőrzés
- több
- mozgalom
- mozgó
- név
- Navigáció
- Közel
- elengedhetetlen
- Szükség
- szükséges
- igények
- hálózat
- Új
- következő
- NLP
- jegyzetfüzet
- semmi
- Most
- szám
- számos
- of
- felajánlás
- gyakran
- on
- ONE
- csak
- nyitva
- nyitott
- operatív
- Művelet
- üzemeltetők
- optimalizált
- or
- szervezet
- Más
- mi
- ki
- átfogó
- csomagok
- oldal
- paraméter
- fizetés
- fizetési módok
- kifizetések
- teljesít
- teljesített
- PHP
- elhelyezés
- emelvény
- Platformok
- Plató
- Platón adatintelligencia
- PlatoData
- csatlakoztat
- pont
- Politikák
- politika
- pozíció
- lehetséges
- állás
- Hozzászólások
- potenciális
- hatalom
- erős
- Tippek
- Előzetes
- magánélet
- magán
- problémák
- feldolgozás
- gyárt
- szakmai
- ajánlat
- ad
- nyilvános
- Nyomja
- hatótávolság
- gyorsan
- Olvasás
- real-time
- nemrég
- rekord
- felvétel
- Piros
- Red Hat
- csökkenteni
- Csökkent
- csökkenti
- csökkentő
- előírások
- Szabályozók
- szabályozók
- összefüggő
- eltávolított
- megismételhető
- szükség
- kötelező
- követelmények
- szükséges
- kutatás
- Tudástár
- válasz
- felelős
- fogékony
- kiskereskedelem
- Emelkedik
- robotok
- futás
- futás
- biztosan
- azonos
- skálázhatóság
- Skála
- skála ai
- skálázás
- Tudomány
- Tudós
- Képernyő
- szkriptek
- Második
- biztosan
- biztonság
- lát
- látás
- kiválasztás
- Önkiszolgáló
- érzékeny
- SEO
- szeptember
- Series of
- szerver
- szolgáltatás
- Szolgáltatások
- szolgáló
- ülés
- ülések
- készlet
- számos
- Megosztás
- előadás
- jelentős
- jelentősen
- hasonló
- óta
- Szingapúr
- egyetlen
- egységes környezet
- weboldal
- Webhely (ek)
- SIX
- készségek
- kicsi
- EMS
- KKV-k
- szoftver
- szoftver komponensek
- megoldások
- szuverenitás
- Hely
- feszültség
- különleges
- kifejezetten
- Szponzorált
- verem
- kezdet
- csúcs-
- tartózkodás
- Lépései
- tárolás
- tárolni
- memorizált
- árnyékolók
- vihar
- stúdió
- tárgy
- siker
- ilyen
- javasolja,
- kínálat
- ellátási lánc
- támogatás
- biztos
- rendszer
- Vesz
- meghozott
- Feladat
- feladatok
- technikák
- Technológia
- Telco
- Temenos
- tíz
- Terraform
- kipróbált
- Tesztelés
- hogy
- A
- azok
- téma
- Ott.
- Ezek
- ők
- ezt
- Keresztül
- idő
- időszerű
- alkalommal
- Cím
- nak nek
- Ma
- együtt
- eszköztár
- szerszámok
- felső
- kereskedelem
- hagyományos
- Vonat
- kiképzett
- Képzések
- átruházás
- Átalakítás
- Átalakítás
- transzformációk
- átlátszó
- Triton
- kettő
- típus
- típusok
- elszabadult
- Frissítések
- Frissítés
- URL
- us
- használ
- használt
- Felhasználók
- segítségével
- hasznosít
- hasznosított
- Értékes
- érték
- értékajánlat
- fajta
- különféle
- Hatalmas
- keresztül
- Megnézem
- gyakorlatilag
- kötet
- kötetek
- W
- Várakozás
- pénztárca
- volt
- hullám
- Út..
- módon
- we
- hét
- Hetek
- Mit
- Mi
- amikor
- ami
- míg
- WHO
- miért
- széles
- Széleskörű
- val vel
- belül
- nő
- WordPress
- Munka
- munkafolyamatok
- dolgozó
- lenne
- írott
- A te
- zephyrnet











