
Kép a szerzőtől | Bing Image Creator
Dolly 2.0 egy nyílt forráskódú, utasításkövető, nagy nyelvi modell (LLM), amelyet egy ember által generált adatkészleten finomítottak. Kutatási és kereskedelmi célokra egyaránt használható.
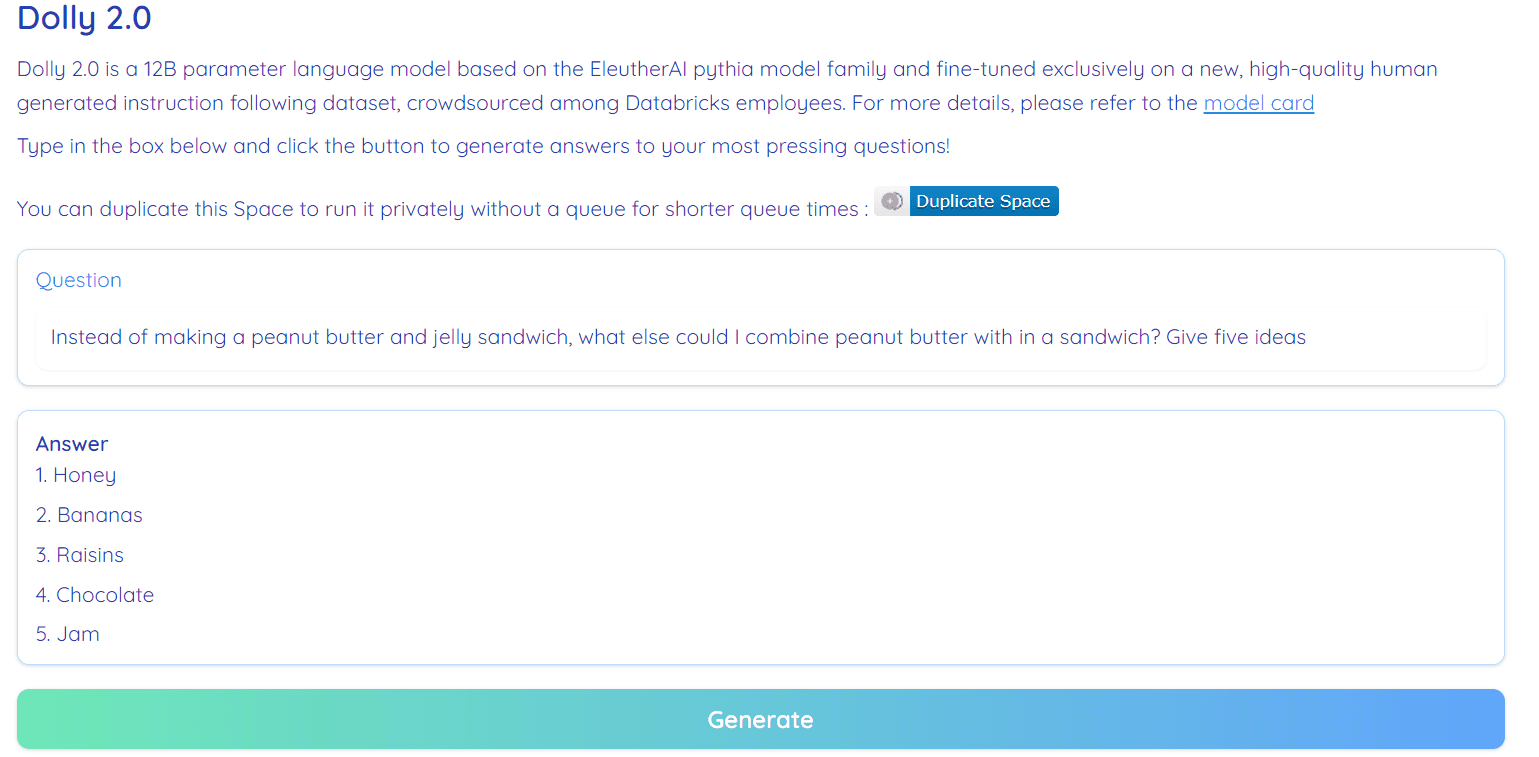
Kép Hugging Face Space – RamAnanth1
Korábban a Databricks csapata megjelent Dolly 1.0, LLM, amely a ChatGPT-hez hasonló utasításokat mutat be, és kevesebb, mint 30 dollárba kerül a képzés. A Stanford Alpaca csapat adatkészletét használta, amely korlátozott licenc alatt állt (csak kutatás).
A Dolly 2.0 megoldotta ezt a problémát a 12B paraméteres nyelvi modell finomhangolásával (Pythia). Mind a modell, mind az adatkészlet kereskedelmi használatra elérhető.
A Dolly 1.0 egy Stanford Alpaca adatkészletre lett kiképezve, amelyet OpenAI API-val hoztak létre. Az adatkészlet tartalmazza a ChatGPT kimenetét, és megakadályozza, hogy bárki felhasználja azt az OpenAI-val való versenyre. Röviden, ezen adatkészlet alapján nem építhet kereskedelmi chatbotot vagy nyelvi alkalmazást.
Az elmúlt hetekben megjelent legújabb modellek többsége ugyanazoktól a problémáktól szenvedett, mint például a modellek alpaka, Koala, GPT4Allés vikunya. A megkerüléshez új, kiváló minőségű adatkészleteket kell létrehoznunk, amelyeket kereskedelmi használatra is fel lehet használni, és ezt tette a Databricks csapata a databricks-dolly-15k adatkészlettel.
Az új adatkészlet 15,000 XNUMX kiváló minőségű, emberi címkével ellátott prompt/válaszpárt tartalmaz, amelyek segítségével nagy nyelvi modelleket lehet hangolni. A databricks-dolly-15k adatkészlet jár hozzá Creative Commons Nevezd meg! – Nevezd meg! 3.0 Unported License, amellyel bárki használhatja, módosíthatja és kereskedelmi alkalmazást hozhat létre rajta.
Hogyan hozták létre a databricks-dolly-15k adatkészletet?
Az OpenAI kutatás papír kijelenti, hogy az eredeti InstructGPT modellt 13,000 13 felszólításra és válaszra tanították. Ezen információk felhasználásával a Databricks csapata elkezdett dolgozni rajta, és kiderült, hogy 5,000 ezer kérdés és válasz generálása nehéz feladat volt. Nem használhatnak szintetikus adatokat vagy mesterséges intelligencia generatív adatokat, és minden kérdésre eredeti választ kell generálniuk. Itt döntöttek úgy, hogy a Databricks XNUMX alkalmazottját felhasználják ember által generált adatok létrehozására.
A Databricks versenyt hirdetett, amelyen a legjobb 20 címkéző nagy díjat kap. Ezen a versenyen a Databricks 5,000 alkalmazottja vett részt, akik nagyon érdeklődtek az LLM-ek iránt
A dolly-v2-12b nem a legmodernebb modell. Egyes értékelési benchmarkokban alulmúlja a dolly-v1-6b teljesítményt. Ennek oka lehet a mögöttes finomhangoló adatkészletek összetétele és mérete. A Dolly modellcsalád aktív fejlesztés alatt áll, így előfordulhat, hogy a jövőben megjelenik egy frissített, jobb teljesítményű verzió.
Röviden: a dolly-v2-12b modell jobban teljesített, mint az EleutherAI/gpt-neox-20b és az EleutherAI/pythia-6.9b.

Kép Ingyenes Dolly
A Dolly 2.0 100%-ban nyílt forráskódú. Tanítási kóddal, adatkészlettel, modellsúlyokkal és következtetési folyamattal érkezik. Minden alkatrész kereskedelmi használatra alkalmas. A modellt a Hugging Face Spaces oldalon próbálhatod ki Dolly V2, RamAnanth1.
Kép Átölelő arc
Forrás:
Dolly 2.0 demó: Dolly V2, RamAnanth1
Abid Ali Awan (@1abidaliawan) okleveles adattudós szakember, aki szereti a gépi tanulási modellek építését. Jelenleg tartalomkészítéssel foglalkozik, és technikai blogokat ír a gépi tanulásról és az adattudományi technológiákról. Abid mesterdiplomát szerzett technológiamenedzsmentből és alapdiplomát távközlési mérnökből. Elképzelése az, hogy egy MI-terméket hozzon létre egy gráf neurális hálózat segítségével a mentális betegséggel küzdő diákok számára.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- Platoblockchain. Web3 metaverzum intelligencia. Felerősített tudás. Hozzáférés itt.
- A jövő pénzverése – Adryenn Ashley. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :van
- :is
- :nem
- $ UP
- 000
- 1
- 20
- a
- képesség
- aktív
- AI
- Minden termék
- lehetővé teszi, hogy
- alternatív
- an
- és a
- válaszok
- bárki
- api
- Alkalmazás
- VANNAK
- körül
- szerző
- elérhető
- díj
- alapján
- BE
- referenciaértékek
- Berkeley
- Jobb
- Nagy
- Bing
- blogok
- mindkét
- épít
- Épület
- by
- TUD
- nem tud
- Vizsgázott
- chatbot
- ChatGPT
- kód
- kereskedelmi
- köznép
- versenyez
- alkatrészek
- tartalmaz
- tartalom
- tartalomalkotás
- verseny
- kiadások
- teremt
- készítette
- teremtés
- Jelenleg
- dátum
- adat-tudomány
- adattudós
- Adattárak
- adatkészletek
- határozott
- Fok
- Demó
- Design
- Fejlesztés
- DID
- nehéz
- Dolly
- munkavállaló
- alkalmazottak
- Mérnöki
- értékelés
- Minden
- kiállítási
- Arc
- család
- kevés
- összpontosítás
- következő
- A
- ból ből
- jövő
- generál
- generáló
- nemző
- kap
- grafikon
- Graph Neurális Hálózat
- Legyen
- he
- jó minőségű
- tart
- HTML
- HTTPS
- betegség
- kép
- in
- információ
- érdekelt
- kérdés
- kérdések
- IT
- jpg
- KDnuggets
- nyelv
- nagy
- keresztnév
- legutolsó
- tanulás
- Engedély
- mint
- gép
- gépi tanulás
- vezetés
- mester
- szellemi
- Mentális betegség
- esetleg
- modell
- modellek
- módosítása
- Szükség
- hálózat
- ideg-
- neurális hálózat
- Új
- of
- on
- csak
- nyitva
- nyílt forráskódú
- OpenAI
- or
- eredeti
- teljesítmény
- párok
- paraméter
- részt
- teljesítmény
- csővezeték
- Plató
- Platón adatintelligencia
- PlatoData
- Termékek
- szakmai
- célokra
- kérdés
- Kérdések
- felszabaduló
- kutatás
- megoldódott
- korlátozott
- s
- azonos
- Tudomány
- Tudós
- készlet
- rövid
- Méret
- So
- néhány
- forrás
- Hely
- terek
- Stanford
- kezdődött
- csúcs-
- Államok
- küzd
- Diákok
- megfelelő
- szintetikus
- szintetikus adatok
- Feladat
- csapat
- Műszaki
- Technologies
- Technológia
- távközlés
- mint
- hogy
- A
- A jövő
- ők
- ezt
- nak nek
- felső
- Vonat
- kiképzett
- Képzések
- alatt
- mögöttes
- frissítve
- használ
- használt
- segítségével
- változat
- látomás
- volt
- we
- Hetek
- voltak
- Mit
- ami
- WHO
- val vel
- Munka
- lenne
- írás
- te
- zephyrnet










