Amazon RedShift egy teljesen felügyelt és petabájtos méretű felhőadattárház, amelyet ügyfelek tízezrei használnak napi exabájtnyi adat feldolgozására, hogy növeljék analitikai munkaterhelésüket. A dimenziós modell segítségével strukturálhatja adatait, mérheti az üzleti folyamatokat, és gyorsan értékes betekintést nyerhet. Az Amazon Redshift beépített funkciókat kínál a dimenziós modellek modellezésének, hangszerelésének és jelentésének felgyorsítására.
Ebben a bejegyzésben egy dimenziós modell megvalósításának módját tárgyaljuk, különösen a Kimball módszertana. Megbeszéljük a dimenziók és tények megvalósítását az Amazon Redshift-en belül. Megmutatjuk, hogyan kell végrehajtani a kibontást, átalakítást és betöltést (ELT), egy integrációs folyamatot, amely arra összpontosít, hogy a nyers adatokat egy Data Lake-ből egy állomásozó rétegbe helyezze a modellezés végrehajtásához. Összességében a bejegyzés világos megértést ad arról, hogyan kell használni a dimenziós modellezést az Amazon Redshiftben.
Megoldás áttekintése
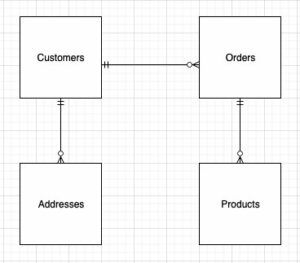
A következő ábra a megoldás architektúráját mutatja be.

A következő szakaszokban először a dimenziós modell legfontosabb szempontjait tárgyaljuk és mutatjuk be. Ezt követően az Amazon Redshift segítségével létrehozunk egy adatpiacot egy dimenziós adatmodellel, amely dimenzió- és ténytáblázatokat tartalmaz. Az adatok betöltése és szakaszolása a COPY paranccsal, a dimenziók adatai a következővel töltődnek be MERGE kijelentést, és a tények azokhoz a dimenziókhoz kapcsolódnak, amelyekből a betekintések származnak. A méretek és tények betöltését ütemezzük a Amazon Redshift Query Editor V2. Végül használjuk Amazon QuickSight hogy betekintést nyerjen a modellezett adatokba egy QuickSight műszerfal formájában.
Ehhez a megoldáshoz az Amazon Redshift által biztosított (normalizált) mintaadatkészletet használjuk az eseményjegyek értékesítéséhez. Ehhez a bejegyzéshez az egyszerűség és a szemléltetés érdekében leszűkítettük az adatkészletet. A következő táblázatok példákat mutatnak be a jegyeladásokra és a helyszínekre vonatkozó adatokra.


Szerint Kimball dimenziós modellezési módszertan, a dimenziós modell tervezésének négy fő lépése van:
- Azonosítsa az üzleti folyamatot.
- Nyilatkozzon az adatok szemcséjéről.
- Határozza meg és hajtsa végre a méreteket.
- A tények azonosítása és végrehajtása.
Ezenkívül bemutatás céljából hozzáadunk egy ötödik lépést is, amely az üzleti események jelentése és elemzése.
Előfeltételek
Ehhez az áttekintéshez a következő előfeltételekkel kell rendelkeznie:
Azonosítsa az üzleti folyamatot
Egyszerűen fogalmazva, az üzleti folyamat azonosítása egy mérhető esemény azonosítása, amely adatokat generál a szervezeten belül. Általában a vállalatoknak van valamilyen operatív forrásrendszerük, amely nyers formátumban állítja elő adataikat. Ez jó kiindulópont az üzleti folyamatok különböző forrásainak azonosításához.
Az üzleti folyamatot ezután a adatok mart dimenziók és tények formájában. A korábban említett mintaadatkészletünket tekintve jól látható, hogy az üzleti folyamat egy adott eseményre történő értékesítés.
Gyakori hiba, hogy egy vállalat részlegeit használják üzleti folyamatként. Az adatokat (üzleti folyamatot) integrálni kell a különböző részlegek között, ebben az esetben a marketing hozzáférhet az értékesítési adatokhoz. A megfelelő üzleti folyamat azonosítása kritikus fontosságú – ennek a lépésnek a tévedése kihatással lehet az egész adatpiacra (ez a szemcsék megkettőzését és helytelen mérőszámokat okozhat a végső jelentésekben).
Nyilatkozzon az adatok szemcséjéről
A gabona deklarálása egy rekord egyedi azonosítása az adatforrásban. A szemcsét a ténytáblázatban használják fel az adatok pontos mérésére, és lehetővé teszik a további tekercselést. Példánkban ez lehet egy sor az értékesítési üzleti folyamatban.
A mi felhasználási esetünkben az eladás egyedileg azonosítható azáltal, hogy megnézzük a tranzakció időpontját, amikor az eladás megtörtént; ez lesz a legatomosabb szint.

Határozza meg és hajtsa végre a méreteket
A dimenziótáblázat leírja a ténytáblázatot és annak attribútumait. Az üzleti folyamat leíró kontextusának meghatározásakor a szöveget egy külön táblázatban tárolja, szem előtt tartva a ténytábla szemcsésségét. Amikor a mérettáblázatot a ténytáblához kapcsolja, csak egyetlen sor legyen társítva a ténytáblázathoz. Példánkban a következő táblázatot használjuk a mérettáblázatba való szétválasztáshoz; ezek a mezők leírják azokat a tényeket, amelyeket mérni fogunk.
A dimenziós modell (a séma) szerkezetének kialakításakor vagy létrehozhat a csillag or hópehely séma. A szerkezetnek szorosan illeszkednie kell az üzleti folyamathoz; ezért példánkhoz egy csillagséma felel meg a legjobban. A következő ábra az entitáskapcsolati diagramunkat (ERD) mutatja.

A következő szakaszokban részletezzük a méretek megvalósításának lépéseit.
Állítsa be a forrásadatokat
A mérettáblázat létrehozása és betöltése előtt forrásadatokra van szükségünk. Ezért a forrásadatokat egy átmeneti vagy ideiglenes táblába rendezzük. Ezt gyakran nevezik a színpadi réteg, amely a forrásadatok nyers másolata. Ehhez az Amazon Redshiftben a MÁSOLÁS parancsot az adatok betöltéséhez a dimenziós modellezés az amazon-redshiftben található nyilvános S3 gyűjtőből us-east-1 Vidék. Vegye figyelembe, hogy a COPY parancs egy AWS Identity and Access Management (IAM) szerepkörrel hozzáférés az Amazon S3-hoz. A szerepnek kell lennie kapcsolódik a klaszterhez. Hajtsa végre a következő lépéseket a forrásadatok rendezéséhez:
- Hozza létre a
venueforrás táblázat:
- A helyszín adatainak betöltése:
- Hozza létre a
salesforrás táblázat:
- Az értékesítési forrásadatok betöltése:
- Hozza létre a
calendarasztal:
- A naptár adatainak betöltése:
Hozza létre a mérettáblázatot
A dimenziótáblázat megtervezése az üzleti igényeitől függhet – például nyomon kell követnie az adatok időbeli változásait? Vannak hét különböző dimenziótípus. Példánkban használjuk írja 1 mert nem kell nyomon követnünk a történelmi változásokat. A 2-es típusról bővebben itt olvashat Egyszerűsítse az adatok betöltését a 2. típusú lassan változó dimenziókba az Amazon Redshiftben. A mérettáblázat denormalizálva lesz egy elsődleges kulccsal, helyettesítő kulccsal és néhány hozzáadott mezővel, amelyek jelzik a tábla változásait. Lásd a következő kódot:
Néhány megjegyzés a mérettáblázat létrehozásához:
- A mezőnevek vállalkozásbarát nevekké alakulnak
- Az elsődleges kulcsunk az
VenueID, amelyet arra használunk, hogy egyedileg azonosítsuk azt a helyszínt, ahol az értékesítés megtörtént - Két további sor kerül hozzáadásra, jelezve, hogy mikor szúrt be és frissített egy rekordot (a változások nyomon követéséhez)
- Mi egy AUTO terjesztési stílus hogy az Amazon Redshift felelősséget vállaljon a terjesztési stílus kiválasztásában és beállításában
Egy másik fontos tényező, amelyet figyelembe kell venni a dimenziós modellezés során, a használata pótkulcsok. A helyettesítő kulcsok mesterséges kulcsok, amelyeket a dimenziómodellezésben használnak a dimenziótáblázat minden rekordjának egyedi azonosítására. Általában szekvenciális egész számként jönnek létre, és az üzleti tartományban nincs jelentésük. Számos előnnyel járnak, mint például az egyediség biztosítása és az összekapcsolások teljesítményének javítása, mivel általában kisebbek, mint a természetes kulcsok, és helyettesítő kulcsként nem változnak az idő múlásával. Ez lehetővé teszi számunkra, hogy következetesek legyünk, és könnyebben egyesítsük a tényeket és a dimenziókat.
Az Amazon Redshiftben a helyettesítő kulcsok általában az IDENTITY kulcsszó használatával jönnek létre. Például az előző CREATE utasítás egy dimenziótáblát hoz létre a-val VenueSkey pótkulcs. A VenueSkey oszlop automatikusan feltöltődik egyedi értékekkel, amint új sorok kerülnek a táblázatba. Ez az oszlop használható a helyszín táblázat és a FactSaleTransactions táblázat.
Néhány tipp a helyettesítő kulcsok tervezéséhez:
- Használjon kicsi, rögzített szélességű adattípust a helyettesítő kulcshoz. Ez javítja a teljesítményt és csökkenti a tárhelyet.
- Használja az IDENTITY kulcsszót, vagy állítsa elő a helyettesítő kulcsot szekvenciális vagy GUID értékkel. Ez biztosítja, hogy a helyettesítő kulcs egyedi legyen, és nem módosítható.
Töltse be a dim táblázatot az MERGE segítségével
Számos módja van a dim táblázat betöltésének. Bizonyos tényezőket figyelembe kell venni – például a teljesítményt, az adatmennyiséget és esetleg az SLA betöltési idejét. A ... val MERGE utasítást, végrehajtunk egy upsert anélkül, hogy több beszúrási és frissítési parancsot kellene megadnunk. Beállíthatja a MERGE nyilatkozat a tárolt eljárás az adatok feltöltéséhez. Ezután ütemezheti a tárolt eljárás programozott futtatását a lekérdezésszerkesztőn keresztül, amelyet később bemutatunk a bejegyzésben. A következő kód létrehoz egy tárolt eljárást SalesMart.DimVenueLoad:
Néhány megjegyzés a méretbetöltésről:
- Amikor először szúr be egy rekordot, a beillesztés dátuma és a frissített dátum kerül kitöltésre. Ha bármely érték megváltozik, az adatok frissülnek, és a frissített dátum a módosítás dátumát tükrözi. A beillesztett dátum megmarad.
- Mivel az adatokat az üzleti felhasználók fogják használni, le kell cserélnünk a NULL értékeket, ha vannak, üzletileg megfelelőbb értékekkel.
A tények azonosítása és végrehajtása
Most, hogy a gabonánkat egy adott időpontban lezajlott értékesítés eseményének nyilvánítottuk, a ténytáblázatunk az üzleti folyamatunkhoz tartozó számszerű tényeket tárolja.
A méréshez a következő számszerű tényeket azonosítottuk:
- Eladott jegyek mennyisége eladásonként
- Jutalék az eladásért
A tény megvalósítása
Vannak háromféle ténytáblázat (tranzakciós ténytáblázat, időszakos pillanatkép-ténytábla és felhalmozódó pillanatkép-ténytábla). Mindegyik más-más képet ad az üzleti folyamatról. Példánkban egy tranzakciós ténytáblázatot használunk. Hajtsa végre a következő lépéseket:
- Készítse el a ténytáblázatot
A rendszer hozzáad egy beszúrt dátumot egy alapértelmezett értékkel, jelezve, hogy a rekord betöltődött-e, és mikor. Ezt a ténytábla újratöltésénél használhatja a már betöltött adatok eltávolításához, hogy elkerülje a duplikációkat.
A ténytábla betöltése egy egyszerű beszúrási utasításból áll, amely összekapcsolja a kapcsolódó dimenziókat. Csatlakozunk a DimVenue táblázat, amely leírja tényeinket. Ez a legjobb gyakorlat, de nem kötelező naptári dátum dimenziók, amelyek lehetővé teszik a végfelhasználó számára, hogy navigáljon a ténytáblázatban. Az adatok vagy új értékesítéskor tölthetők be, vagy naponta; itt jön jól a beszúrt dátum vagy betöltési dátum.
A ténytáblát egy tárolt eljárással töltjük be, és dátum paramétert használunk.
- Hozza létre a tárolt eljárást a következő kóddal. Annak érdekében, hogy megőrizzük ugyanazt az adatintegritást, amelyet a dimenzióbetöltésnél alkalmaztunk, lecseréljük a NULL értékeket, ha vannak, üzleti szempontból megfelelőbb értékekkel:
- Töltse be az adatokat az eljárás meghívásával a következő paranccsal:
Ütemezze be az adatbetöltést
Most már automatizálhatjuk a modellezési folyamatot a tárolt eljárások ütemezésével az Amazon Redshift Query Editor V2-ben. Hajtsa végre a következő lépéseket:
- Először meghívjuk a méretterhelést, és miután a méretbetöltés sikeresen lefut, megkezdődik a ténybetöltés:
Ha a méretbetöltés sikertelen, a ténybetöltés nem fut le. Ez biztosítja az adatok konzisztenciáját, mert nem akarjuk betölteni a ténytáblát elavult dimenziókkal.
- A betöltés ütemezéséhez válassza a lehetőséget menetrend a Lekérdezésszerkesztő V2-ben.

- A lekérdezést minden nap 5:00-ra ütemezzük.
- Opcionálisan hibaértesítéseket is hozzáadhat az engedélyezéssel Amazon Simple Notification Service (Amazon SNS) értesítései.

Jelentse és elemezze az adatokat az Amazon Quicksightban
A QuickSight egy üzleti intelligencia szolgáltatás, amely megkönnyíti a betekintést. Teljesen felügyelt szolgáltatásként a QuickSight segítségével egyszerűen hozhat létre és tehet közzé interaktív irányítópultokat, amelyek bármely eszközről elérhetők, és beágyazhatók alkalmazásaiba, portáljaiba és webhelyeibe.
Adatpiacunkat használjuk a tények vizuális bemutatására műszerfal formájában. A kezdéshez és a QuickSight beállításához lásd: Adatkészlet létrehozása nem automatikusan felfedezett adatbázis használatával.
Miután létrehozta az adatforrást a QuickSightban, a helyettesítő kulcsunk alapján egyesítjük a modellezett adatokat (data mart). skey. Ezt az adatkészletet használjuk az adatpiac megjelenítésére.

Végső irányítópultunk tartalmazza az adatpiaci betekintést, és megválaszolja a kritikus üzleti kérdéseket, például a helyszínenkénti teljes jutalékot és a legmagasabb értékesítési dátumokat. A következő képernyőkép az adatpiac végtermékét mutatja.

Tisztítsuk meg
A jövőbeni költségek elkerülése érdekében törölje a bejegyzés részeként létrehozott forrásokat.
Következtetés
Sikeresen megvalósítottunk egy adatpiacot a mi használatával DimVenue, DimCalendarés FactSaleTransactions táblázatok. Raktárunk nem teljes; mivel több ténnyel bővíthetjük az adatpiacot és több martot valósíthatunk meg, és ahogy az üzleti folyamat és a követelmények idővel nőnek, úgy fog növekedni az adattárház is. Ebben a bejegyzésben átfogó képet adtunk a dimenziómodellezés megértéséhez és megvalósításához az Amazon Redshiftben.
Kezdje el a sajátjával Amazon RedShift dimenziós modell ma.
A szerzőkről
 Bernard Verster egy tapasztalt felhőmérnök, aki több éves tapasztalattal rendelkezik a méretezhető és hatékony adatmodellek létrehozásában, az adatintegrációs stratégiák meghatározásában, valamint az adatkezelés és az adatbiztonság biztosításában. Szenvedélyesen használja az adatokat, hogy betekintést nyerjen, miközben igazodik az üzleti követelményekhez és célkitűzésekhez.
Bernard Verster egy tapasztalt felhőmérnök, aki több éves tapasztalattal rendelkezik a méretezhető és hatékony adatmodellek létrehozásában, az adatintegrációs stratégiák meghatározásában, valamint az adatkezelés és az adatbiztonság biztosításában. Szenvedélyesen használja az adatokat, hogy betekintést nyerjen, miközben igazodik az üzleti követelményekhez és célkitűzésekhez.
 Abhishek Pan a WWSO SA-Analytics specialistája, amely az AWS India állami szektorbeli ügyfeleivel dolgozik. Az ügyfelekkel együttműködve adatvezérelt stratégiát határoz meg, mélyreható munkameneteket biztosít az analitikai felhasználási esetekről, valamint méretezhető és hatékony analitikai alkalmazásokat tervez. 12 éves tapasztalattal rendelkezik, és szenvedélyesen rajong az adatbázisokért, az elemzésekért és az AI/ML-ért. Lelkes utazó, és igyekszik megörökíteni a világot a fényképezőgépe lencséjén keresztül.
Abhishek Pan a WWSO SA-Analytics specialistája, amely az AWS India állami szektorbeli ügyfeleivel dolgozik. Az ügyfelekkel együttműködve adatvezérelt stratégiát határoz meg, mélyreható munkameneteket biztosít az analitikai felhasználási esetekről, valamint méretezhető és hatékony analitikai alkalmazásokat tervez. 12 éves tapasztalattal rendelkezik, és szenvedélyesen rajong az adatbázisokért, az elemzésekért és az AI/ML-ért. Lelkes utazó, és igyekszik megörökíteni a világot a fényképezőgépe lencséjén keresztül.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Autóipar / elektromos járművek, Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- BlockOffsets. A környezetvédelmi ellentételezési tulajdon korszerűsítése. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Rólunk
- gyorsul
- hozzáférés
- igénybe vett
- pontosan
- át
- törvény
- hozzá
- hozzáadott
- További
- Után
- AI / ML
- összehangolása
- igazítás
- lehetővé
- lehetővé teszi, hogy
- már
- am
- amazon
- Az Amazon Web Services
- an
- elemzés
- Analitikai
- analitika
- elemez
- és a
- válasz
- bármilyen
- alkalmazások
- alkalmazott
- megfelelő
- építészet
- VANNAK
- mesterséges
- AS
- szempontok
- társult
- At
- attribútumok
- auto
- automatizált
- automatikusan
- elkerülése érdekében
- AWS
- b
- alapján
- BE
- mert
- kezdődik
- Előnyök
- BEST
- beépített
- üzleti
- üzleti intelligencia
- Üzleti folyamat
- üzleti folyamatok
- de
- by
- Naptár
- hívás
- hívott
- hívás
- szoba
- TUD
- elfog
- eset
- esetek
- Okoz
- bizonyos
- változik
- megváltozott
- Változások
- változó
- karakter
- díjak
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a
- világos
- világosan
- szorosan
- felhő
- kód
- Oszlop
- jön
- jutalék
- Közös
- Companies
- vállalat
- teljes
- Fontolja
- következetes
- áll
- kontextus
- kijavítására
- tudott
- teremt
- készítette
- teremt
- létrehozása
- teremtés
- kritikai
- Ügyfelek
- napi
- műszerfal
- műszerfalak
- dátum
- adatintegráció
- adattó
- adattárház
- adatalapú
- Adatvezérelt stratégia
- adatbázis
- adatbázisok
- találka
- Időpontok
- dátum idő
- nap
- mély
- mély merülést
- alapértelmezett
- meghatározó
- szállít
- bizonyítani
- osztályok
- Származtatott
- leírni
- Design
- tervezés
- részlet
- eszköz
- különböző
- Dimenzió
- méretek
- megvitatni
- különböző
- terjesztés
- do
- domain
- csinált
- ne
- le-
- hajtás
- ismétlődések
- minden
- Korábban
- könnyen
- könnyű
- szerkesztő
- hatékony
- bármelyik
- beágyazott
- lehetővé
- lehetővé téve
- végén
- végtől végig
- elkötelezett
- mérnök
- biztosítására
- biztosítja
- biztosítása
- Egész
- egység
- Eter (ETH)
- esemény
- események
- Minden
- minden nap
- példa
- példák
- Bontsa
- tapasztalat
- tapasztalt
- Exponálás
- kivonat
- tény
- tényező
- tényezők
- tények
- nem sikerül
- Kudarc
- Jellemzők
- kevés
- mező
- Fields
- ötödik
- Ábra
- szűrő
- utolsó
- vezetéknév
- első
- megfelelő
- összpontosított
- következő
- A
- forma
- formátum
- négy
- ból ből
- teljesen
- további
- jövő
- Nyereség
- generál
- generált
- generál
- kap
- szerzés
- Ad
- adott
- jó
- kormányzás
- Nő
- ügyes
- Legyen
- he
- legnagyobb
- övé
- történeti
- Ünnep
- Hogyan
- How To
- HTML
- http
- HTTPS
- IAM
- azonosított
- azonosítani
- azonosító
- Identitás
- if
- illusztrálja
- Hatás
- végre
- végre
- végrehajtási
- fontos
- javul
- javuló
- in
- Beleértve
- India
- jelez
- jelezve
- info
- meglátások
- integrált
- integráció
- sértetlenség
- Intelligencia
- interaktív
- bele
- IT
- ITS
- csatlakozik
- csatlakozott
- csatlakozott
- csatlakozik
- jpg
- Tart
- tartás
- Kulcs
- kulcsok
- tó
- nyelv
- a későbbiekben
- legutolsó
- réteg
- balra
- Lencsék
- Lets
- szint
- vonal
- kiszámításának
- betöltés
- terhelések
- található
- keres
- készült
- KÉSZÍT
- sikerült
- Marketing
- párosított
- jelenti
- intézkedés
- említett
- megy
- Metrics
- bánja
- hiba
- modell
- modellezés
- modellezés
- modellek
- Hónap
- több
- a legtöbb
- többszörös
- nevek
- Természetes
- Keresse
- Szükség
- igénylő
- igények
- Új
- Megjegyzések
- bejelentés
- értesítések
- Most
- számos
- célok
- of
- ajánlat
- gyakran
- on
- csak
- operatív
- or
- szervezet
- mi
- felett
- átfogó
- paraméter
- rész
- szenvedélyes
- mert
- teljesít
- teljesítmény
- talán
- időszakos
- Hely
- Plató
- Platón adatintelligencia
- PlatoData
- pont
- benépesített
- állás
- hatalom
- gyakorlat
- előfeltételek
- be
- elsődleges
- eljárás
- eljárások
- folyamat
- Folyamatok
- Termékek
- ad
- feltéve,
- biztosít
- nyilvános
- közzétesz
- célokra
- Kérdések
- gyorsan
- emel
- Nyers
- nyers adatok
- rekord
- nyilvántartások
- csökkenteni
- említett
- tükrözi
- vidék
- kapcsolat
- maradványok
- eltávolítása
- cserélni
- jelentést
- Jelentő
- Jelentések
- követelmények
- Tudástár
- felelősség
- Szerep
- Tekercs
- SOR
- futás
- fut
- eladás
- értékesítés
- azonos
- Minta adatkészlet
- skálázható
- menetrend
- ütemezés
- szakaszok
- szektor
- biztonság
- lát
- különálló
- szolgálja
- szolgáltatás
- Szolgáltatások
- ülések
- készlet
- számos
- kellene
- előadás
- Műsorok
- Egyszerű
- egyszerűség
- egyetlen
- Lassan
- kicsi
- kisebb
- Pillanatkép
- So
- eladott
- megoldások
- néhány
- forrás
- Források
- Hely
- szakember
- különleges
- kifejezetten
- Színpad
- színpadra állítás
- csillag
- kezdődött
- Kezdve
- nyilatkozat
- Lépés
- Lépései
- tárolás
- tárolni
- memorizált
- stratégiák
- Stratégia
- struktúra
- sikeres
- sikeresen
- ilyen
- rendszer
- táblázat
- ideiglenes
- tíz
- feltételek
- mint
- hogy
- A
- The Source
- a világ
- azok
- akkor
- Ott.
- ebből adódóan
- Ezek
- ők
- ezt
- ezer
- Keresztül
- jegy
- Jegyértékesítés
- jegyek
- idő
- alkalommal
- időbélyeg
- tippek
- nak nek
- Ma
- együtt
- vett
- Végösszeg
- vágány
- tranzakció
- Átalakítás
- át
- utazó
- típus
- típusok
- jellemzően
- megértés
- egyedi
- egyedileg
- egyediség
- ismeretlen
- Frissítések
- frissítve
- us
- Használat
- használ
- használati eset
- használt
- Felhasználók
- használ
- segítségével
- rendszerint
- Értékes
- érték
- Értékek
- különféle
- helyszín
- helyszínek
- keresztül
- Megnézem
- kötet
- végigjátszás
- akar
- Raktár
- volt
- módon
- we
- háló
- webes szolgáltatások
- honlapok
- hét
- amikor
- ami
- míg
- lesz
- val vel
- belül
- nélkül
- dolgozó
- világ
- Rossz
- év
- év
- te
- A te
- zephyrnet