
Kép a Bing Image Creatorból
A feltáró adatelemzés (EDA) az egyetlen legfontosabb feladat, amelyet minden adattudományi projekt elején végre kell hajtani.
Lényegében ez magában foglalja az adatok alapos vizsgálatát és jellemzését annak érdekében, hogy megtalálják az alapját jellemzők, lehetséges anomáliák, és rejtett minták és a kapcsolatok.
Az Ön adatainak ez a megértése az, ami végső soron lesz végigvezeti a következő lépéseket gépi tanulási folyamat, az adatok előfeldolgozásától a modellépítésig és az eredmények elemzéséig.
Az EDA folyamata alapvetően három fő feladatból áll:
- Lépés 1: Adatkészlet áttekintése és leíró statisztikák
- Lépés 2: Jellemzők értékelése és megjelenítéseés
- Lépés 3: Adatminőség értékelése
Amint azt már sejtette, ezek a feladatok mindegyike meglehetősen átfogó elemzést igényelhet, amely könnyen őrült módjára vágja, nyomtatja és ábrázolja a pandák adatkereteit.
Hacsak nem a megfelelő eszközt választja ki a munkához.
Ebben a cikkben, belemerülünk egy hatékony EDA folyamat minden egyes lépése, és beszéljétek meg, miért érdemes fordulnia ydata-profilozás az egyablakos ügyintézőbe, hogy elsajátítsa.
Nak nek bevált gyakorlatok bemutatása és a betekintések vizsgálata, azt fogjuk használni Felnőtt népszámlálási bevételi adatkészlet, szabadon elérhető a Kaggle vagy UCI Repository oldalon (licenc: CC0: Public Domain).
Amikor először kapunk kezünkbe egy ismeretlen adatkészletet, azonnal felbukkan egy automatikus gondolat: Mivel dolgozom?
Mélyen meg kell értenünk adatainkat, hogy hatékonyan kezelhessük azokat a jövőbeli gépi tanulási feladatok során
Alapszabály, hogy hagyományosan az adatok számához viszonyított jellemzésével kezdjük észrevételek, szám és jellemzők típusai, összességében hiányzó arány, és százaléka másolat megfigyelések.
Némi panda-manipulációval és megfelelő csalólappal végül kinyomtathatjuk a fenti információkat néhány rövid kódrészlettel:
Adatkészlet áttekintése: Felnőtt népszámlálási adatkészlet. Megfigyelések, jellemzők, jellemzőtípusok, duplikált sorok és hiányzó értékek száma. Részlet a szerzőtől.
Összességében a kimeneti formátum nem ideális… Ha ismeri a pandákat, akkor a szabványt is ismeri modus operandi az EDA folyamat elindítása – df.describe():
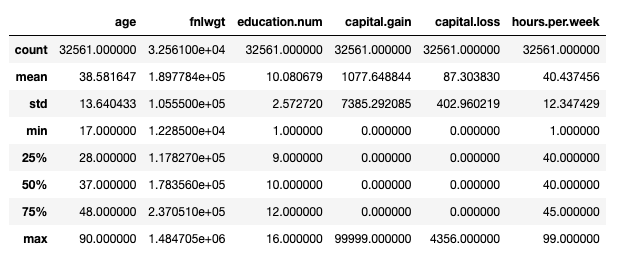
Felnőtt adatkészlet: A fő statisztika megjelenítése df.describe(). A kép szerzője.
Ez azonban csak figyelembe veszi numerikus jellemzők. Használhatnánk a df.describe(include='object') hogy kinyomtasson néhány további információt kategorikus jellemzők (számlálás, egyedi, mód, gyakoriság), de a meglévő kategóriák egyszerű ellenőrzése valamivel bőbeszédűbbet foglalna magában:
Adatkészlet áttekintése: Felnőtt népszámlálási adatkészlet. A meglévő kategóriák és a megfelelő gyakoriságok kinyomtatása minden egyes kategóriás jellemzőhöz az adatokban. Részlet a szerzőtől.
Ezt azonban megtehetjük - és találd ki, az összes ezt követő EDA-feladat! - egyetlen kódsorban, Felhasználva ydata-profilozás:
Profilozási jelentés a felnőtt népszámlálási adatkészletről ydata-profilozással. Részlet a szerzőtől.
A fenti kód teljes profilalkotási jelentést készít az adatokról, amellyel tovább mozgathatjuk az EDA folyamatunkat anélkül, hogy további kódot kellene írni!
A következő részekben a jelentés különböző részein fogunk átmenni. Amiben a az adatok általános jellemzőit, minden általunk keresett információ megtalálható a Áttekintés szakasz:
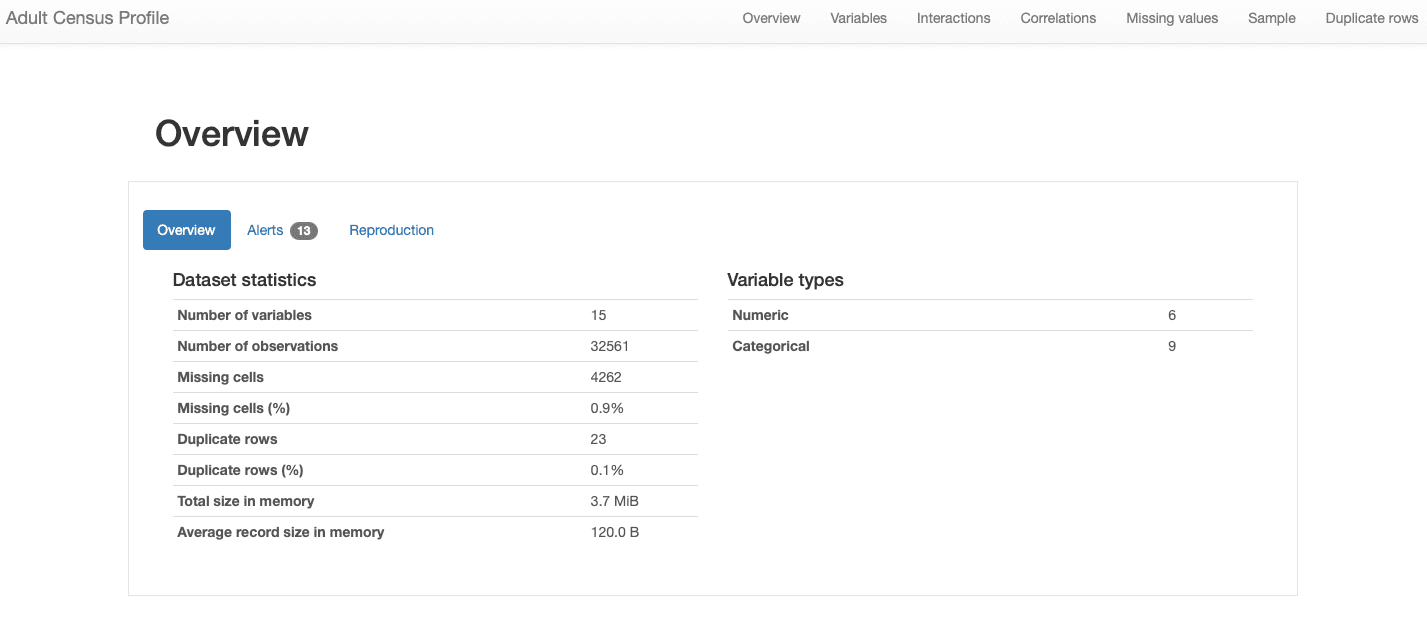
ydata-profiling: Adatprofilozási jelentés – Adatkészlet áttekintése. A kép szerzője.
Láthatjuk, hogy adatkészletünk tartalmaz 15 jellemző és 32561 megfigyelés, val vel 23 ismétlődő rekord, és az összesített hiányzási arány 0.9%.
Ezenkívül az adatkészletet helyesen azonosították a táblázatos adatkészlet, és meglehetősen heterogén, mindkettőt bemutatva numerikus és kategorikus jellemzők. Fórum idősoros adatok, amely időfüggő, és különböző típusú mintákat mutat be, ydata-profiling beépítené a jelentésben szereplő egyéb statisztikák és elemzések.
Tovább ellenőrizhetjük a nyers adatok és meglévő ismétlődő rekordok a funkciók általános megértéséhez, mielőtt bonyolultabb elemzésbe kezdene:
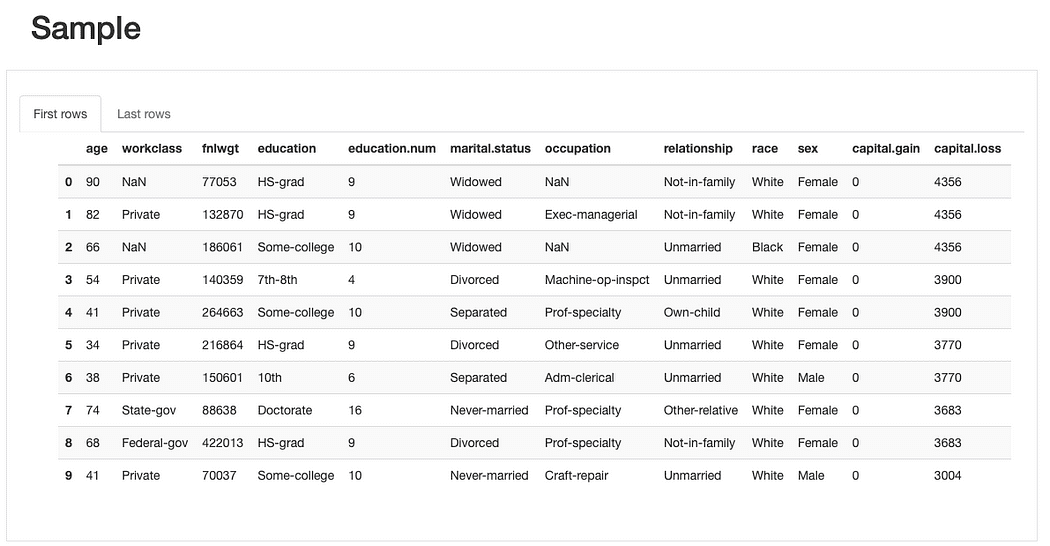
ydata-profiling: Adatprofilozási jelentés — Minta előnézet. A kép szerzője.
A rövid mintaelőzetesből Az adatmintából azonnal láthatjuk, hogy bár az adatkészletben összességében alacsony a hiányzó adatok aránya, egyes funkciókat érinthet több, mint mások. Azonosíthatunk egy inkább jelentős számú kategória egyes jellemzők és 0 értékű jellemzők esetében (vagy legalábbis jelentős számú 0 esetén).
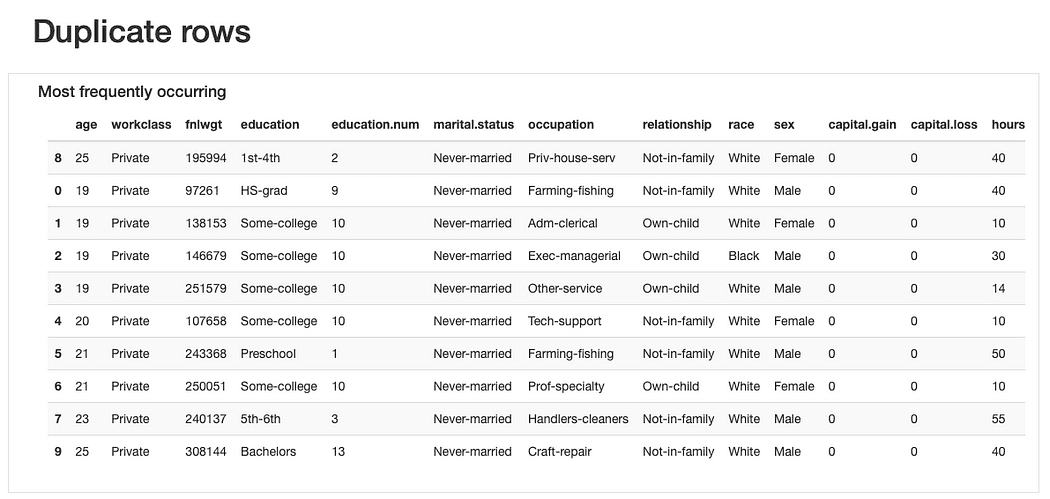
ydata-profiling: Adatprofilozási jelentés – Duplikált sorok előnézete. A kép szerzője.
Az ismétlődő sorokkal kapcsolatban, nem lenne furcsa „ismételt” megfigyeléseket találni, mivel a legtöbb jellemző olyan kategóriákat képvisel, amelyekben több ember is „beleférhet” egyszerre.
Mégis, talán a „adatszag” Lehetséges, hogy ezek a megfigyelések megegyeznek age értékek (ami valószínű), és pontosan ugyanaz fnlwgt ami a bemutatott értékeket tekintve nehezebben hihetőnek tűnik. Tehát további elemzésre lenne szükség, de meg kell tenni valószínűleg eldobja ezeket az ismétlődéseket később.
Összességében az adatok áttekintése egyszerű elemzés lehet, de egy rendkívül hatásos, mivel ez segít meghatározni a folyamatban lévő soron következő feladatokat.
Miután megnéztük az általános adatleírókat, meg kell tennünk nagyítson rá adatkészletünk funkcióira, annak érdekében, hogy betekintést nyerjünk az egyéni tulajdonságaikba – Egyváltozós elemzés – valamint interakcióik és kapcsolataik – Többváltozós elemzés.
Mindkét feladat nagymértékben függ megfelelő statisztikák és vizualizációk vizsgálata, amelyeknek meg kell lenniük a jellemző típusához igazítva kéznél (pl. numerikus, kategorikus), és a viselkedés boncolgatni szeretnénk (pl. interakciók, összefüggések).
Vessünk egy pillantást az egyes feladatok bevált gyakorlataira.
Egyváltozós elemzés
Az egyes jellemzők egyedi jellemzőinek elemzése kulcsfontosságú, mivel ez segít dönteni a jellemzőikről relevanciája az elemzés szempontjából és a adat-előkészítés típusa szükségük lehet az optimális eredmények eléréséhez.
Találhatunk például olyan értékeket, amelyek nagyon kívül esnek a tartományon, és utalhatnak rájuk következetlenségek or kiugró értékek. Lehet, hogy szükségünk lesz rá szabványosítása számszerű dátum vagy végezzen a a kategorikus egyhangú kódolása funkciókat, a meglévő kategóriák számától függően. Vagy további adat-előkészítést kell végeznünk a numerikus jellemzők kezeléséhez eltolódott vagy ferde, ha a használni kívánt gépi tanulási algoritmus egy adott eloszlást vár (általában Gauss-féle).
A legjobb gyakorlatok ezért megkövetelik az egyes tulajdonságok, például a leíró statisztikák és az adatelosztás alapos vizsgálatát.
Ezek rávilágítanak a külsőségek eltávolítására, szabványosításra, címkekódolásra, adatimputációra, adatkiegészítésre és más típusú előfeldolgozásra.
Vizsgáljuk meg race és a capital.gain részletesebben. Mit láthatunk azonnal?
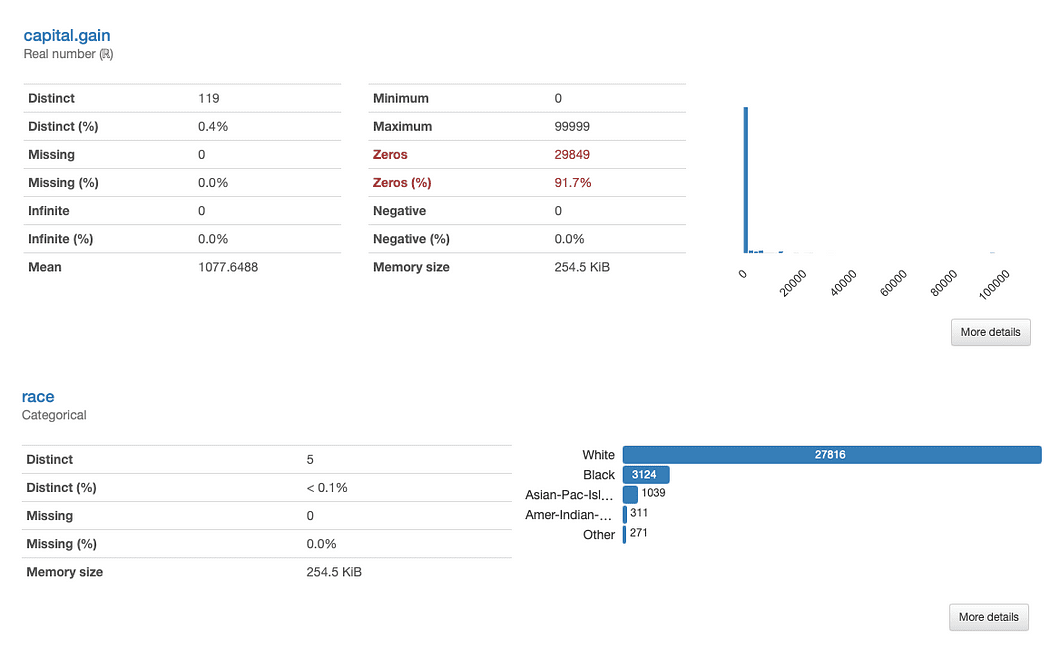
ydata-profiling: Profiling Report (faj és tőke.nyereség). A kép szerzője.
A) tőkenyereség magától érthetődő:
Tekintettel az adatok eloszlására, megkérdőjelezhetjük, hogy a funkció hozzáad-e értéket az elemzésünkhöz, mivel az értékek 91.7%-a „0”.
Elemzés verseny kicsit bonyolultabb:
Nyilvánvalóan alulreprezentáltak más fajok, mint White. Ez két fő problémát juttat eszünkbe:
- Az egyik a gépi tanulási algoritmusok általános tendenciája figyelmen kívül hagyja a kevésbé reprezentált fogalmakat, az úgynevezett probléma kis diszjunkciók, ami a tanulási teljesítmény csökkenéséhez vezet;
- A másik némileg ebből a témából származik: mivel egy érzékeny jellemzővel van dolgunk, ennek az „elnéző tendenciának” olyan következményei lehetnek, amelyek közvetlenül kapcsolódnak előítélet és a méltányosság kérdések. Valami olyasmit, amit semmiképpen nem akarunk bemászni a modelljeinkbe.
Ha ezt figyelembe vesszük, talán kellene fontolja meg az adatkiegészítés végrehajtását feltétele az alulreprezentált kategóriák, valamint figyelembe véve méltányosság-tudatos mérőszámok a modellértékeléshez, hogy ellenőrizze a teljesítménybeli eltéréseket race értékeket.
Az adatminőséggel kapcsolatos bevált gyakorlatok megvitatása során (3. lépés) további részleteket fogunk részletezni az adatok egyéb jellemzőiről, amelyekkel foglalkozni kell. Ez a példa csak azt mutatja be, mekkora betekintést nyerhetünk az egyes funkciók értékelésével ingatlanait.
Végül vegye figyelembe, hogy – amint azt korábban említettük – a különböző jellemzőtípusok eltérő statisztikákat és megjelenítési stratégiákat igényelnek:
- Numerikus jellemzők leggyakrabban az átlagra, a szórásra, a ferdeségre, a görbületre és más kvantilis statisztikákra vonatkozó információkat tartalmaznak, és legjobban a hisztogram diagramok segítségével ábrázolhatók;
- Kategorikus jellemzők általában a mód-, medián- és gyakoriságtáblázatok segítségével írják le, és oszlopdiagramok segítségével ábrázolják a kategóriaelemzéshez.
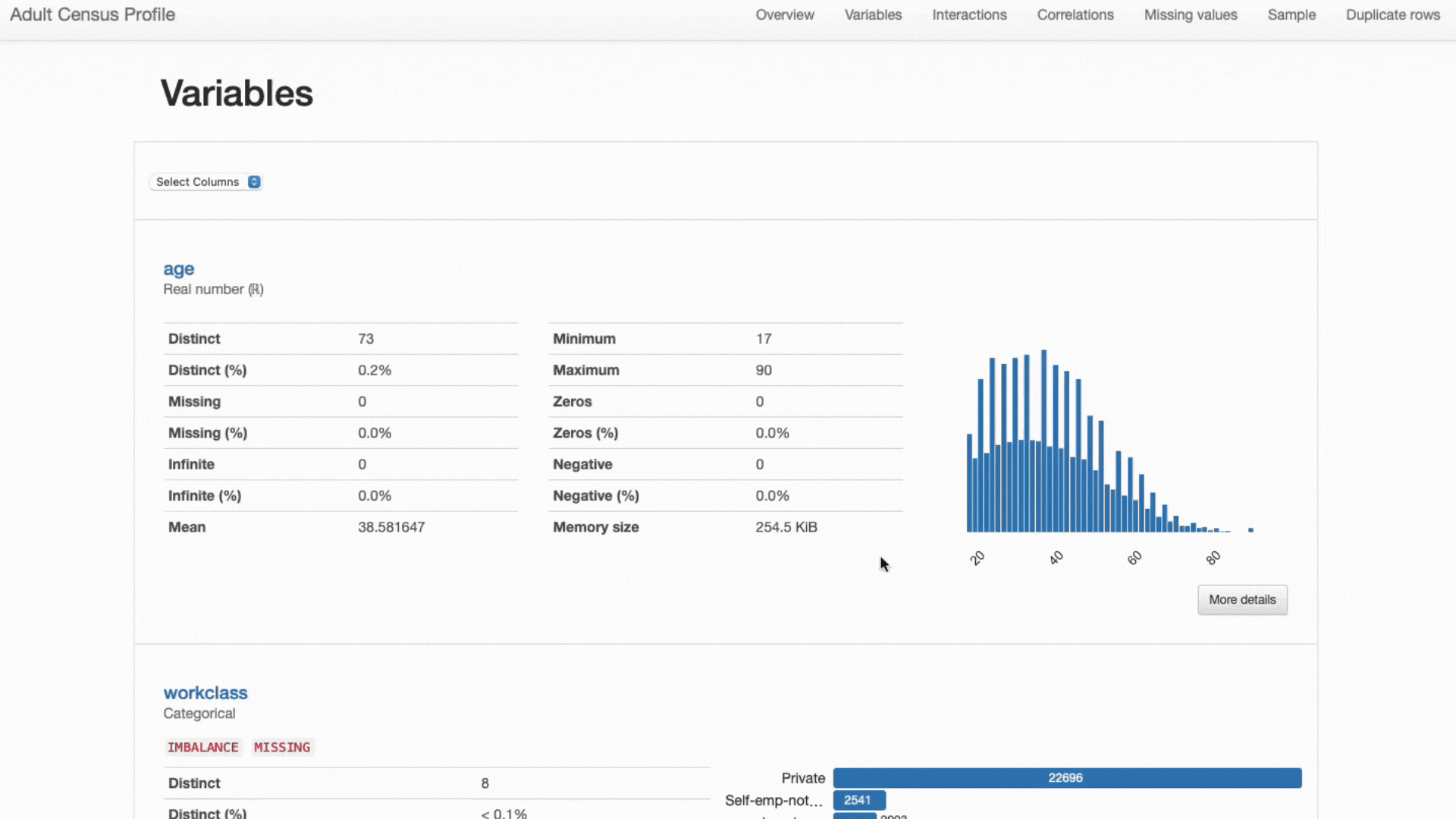
ydata-profiling: Profilozási jelentés. A bemutatott statisztikák és vizualizációk minden funkciótípushoz igazodnak. Forgatókönyv: Szerző.
Egy ilyen részletes elemzést nehézkes lenne elvégezni a pandák általános manipulációjával, de szerencsére ydata-profiling mindezen funkciók be vannak építve a ProfileReport a mi kényelmünk érdekében: nem adtak extra kódsorokat a részlethez!
Többváltozós elemzés
A többváltozós elemzés esetében a legjobb gyakorlatok főként két stratégiára összpontosítanak: a kölcsönhatások a jellemzők között, és elemezzük azokat összefüggések.
Interakciók elemzése
Az interakciók lehetővé teszik számunkra vizuálisan fedezze fel, hogyan viselkedik az egyes jellemzőpárok, azaz hogyan viszonyulnak az egyik jellemző értékei a másikhoz.
Például kiállíthatnak pozitív or negatív kapcsolatokat, attól függően, hogy az egyik érték növekedése a másik értékeinek növekedésével vagy csökkenésével jár-e, ill.
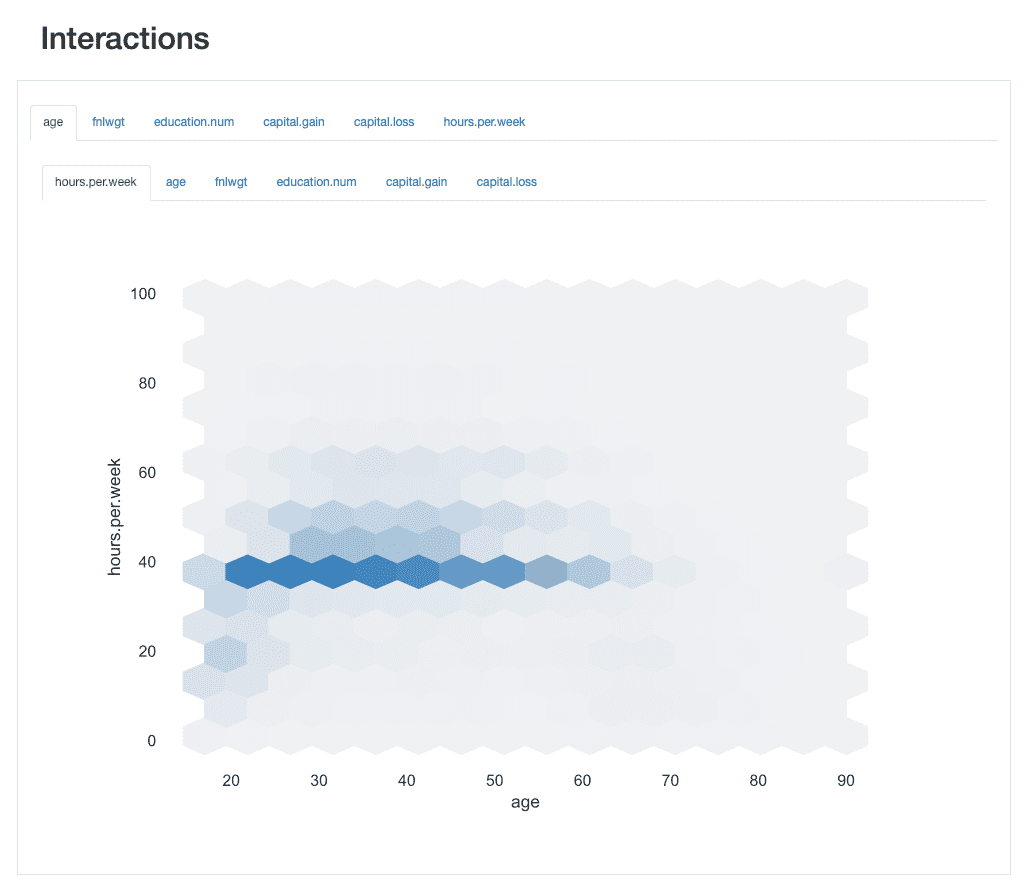
ydata-profiling: Profiling Report — Interactions. A kép szerzője.
Az interakciót figyelembe véve age és a hours.per.weekPéldaként láthatjuk, hogy a munkaerő nagy többsége 40 órát dolgozik. Vannak azonban olyan „foglalt méhek”, akik 60 és 65 éves koruk között dolgoznak ezen túl (30 vagy akár 45 óráig). A 20 év körüliek kevésbé hajlamosak túlhajszolni, és egyes esetekben könnyebb a munkabeosztásuk. hétig.
Összefüggések elemzése
Az interakciókhoz hasonlóan összefüggések engedik nekünk elemezni a kapcsolatot jellemzők között. Az összefüggések azonban „értéket adnak”, így könnyebben meghatározhatjuk a kapcsolat „erősségét”.
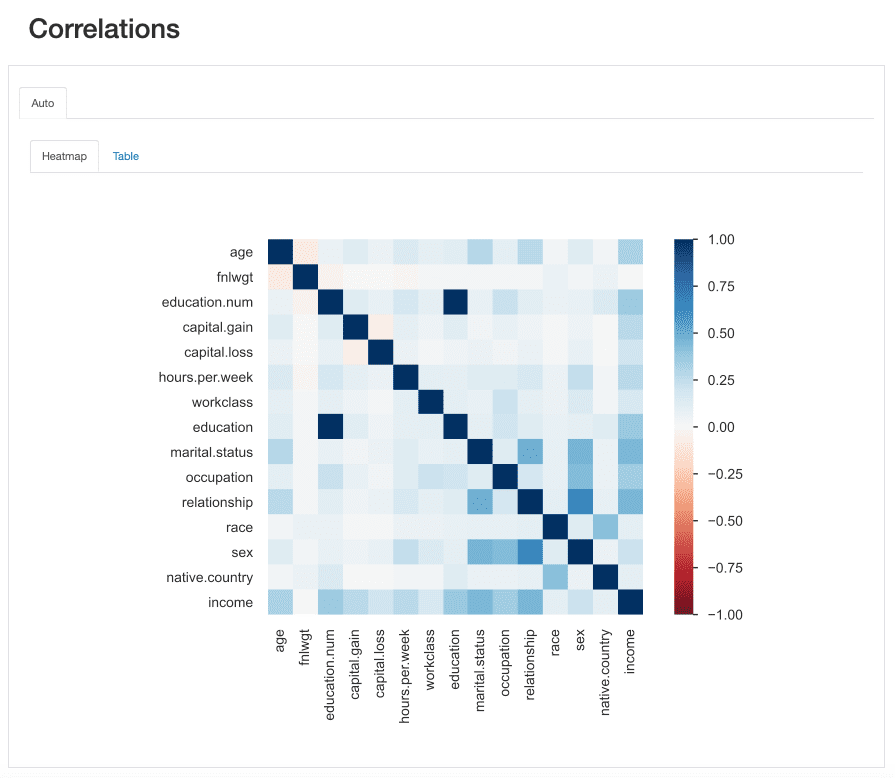
Ez az „erő” az korrelációs együtthatókkal mérjük és akár numerikusan is elemezhető (pl. megvizsgálva a korrelációs mátrix) vagy a hőtérkép, amely színt és árnyékolást használ az érdekes minták vizuális kiemelésére:
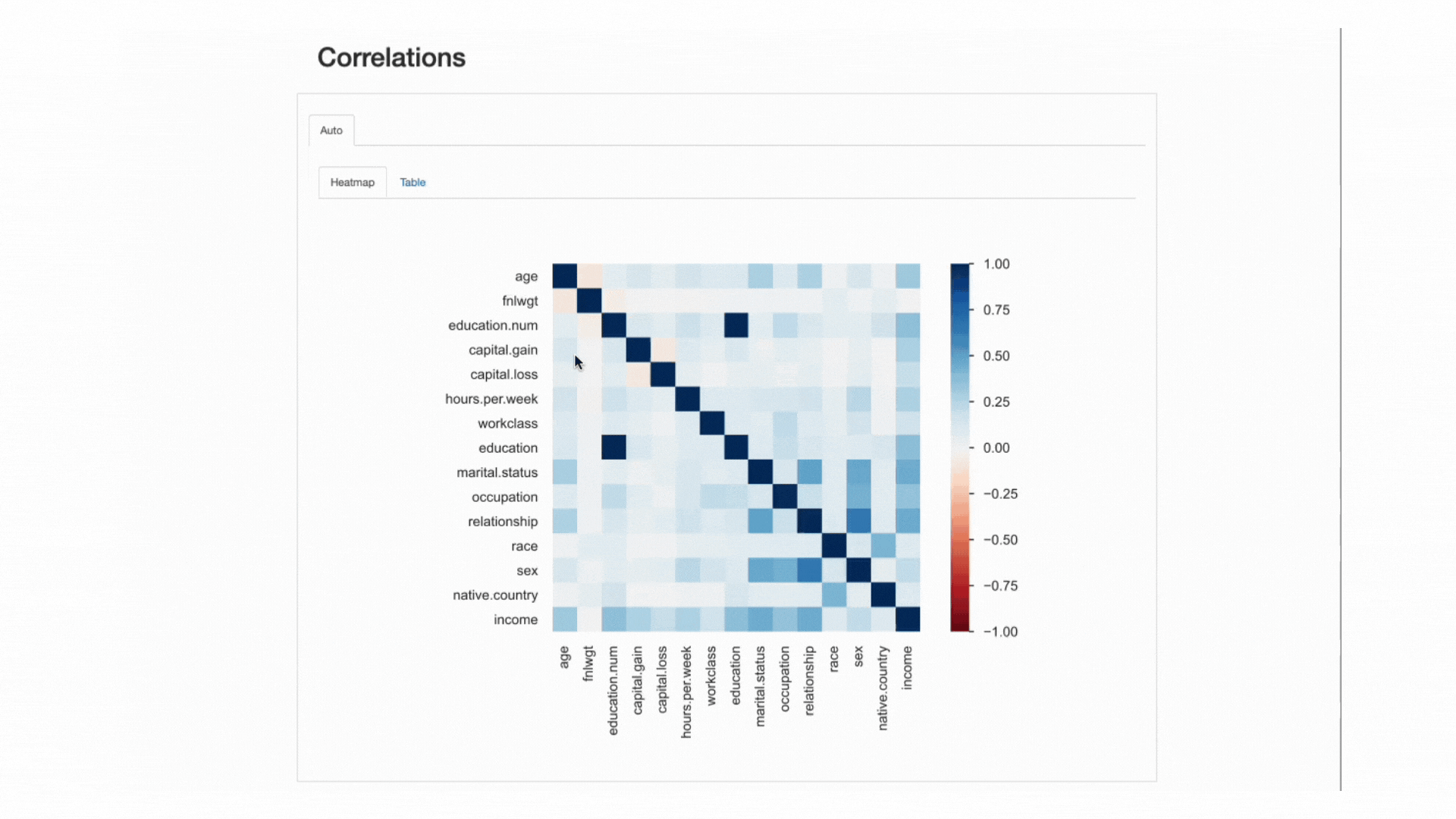
ydata-profiling: Profiling Report — Heatmap and Correlation Matrix. Forgatókönyv: Szerző.
Az adatkészletünkkel kapcsolatban figyelje meg, hogy milyen összefüggés van a kettő között education és a education.num kiemelkedik. Valójában, ugyanazt az információt birtokoljákés education.num csak egy binning a education értékeket.
Egy másik minta, amely megragadja a figyelmet, a közötti korreláció sex és a relationship bár ismét nem túl informatív: mindkét jellemző értékét megvizsgálva rájövünk, hogy ezek a jellemzők nagy valószínűséggel összefüggenek, mert male és a female megfelelni fog husband és a wife, Ill.
Az ilyen típusú redundanciákat ellenőrizni lehet, hogy eltávolítsuk-e ezeket a funkciókat az elemzésből (marital.status is kapcsolódik relationship és a sex; native.country és a race például többek között).
ydata-profiling: Profiling Report — Correlations. A kép szerzője.
Vannak azonban más összefüggések is, amelyek kiemelkednek, és érdekesek lehetnek elemzésünk szempontjából.
Például a közötti összefüggéssex és a occupationvagy sex és a hours.per.week.
Végül az összefüggések között income és a többi funkció valóban informatív, különösen abban az esetben, ha egy osztályozási problémát próbálunk feltérképezni. Tudva, mik azok leginkább korrelált célosztályunkhoz tartozó funkciók segítenek azonosítani a leginkább diszkriminatív funkciókat, és megtalálja a lehetséges adatszivárogtatásokat, amelyek hatással lehetnek a modellünkre.
A hőtérkép alapján úgy tűnik marital.status or relationship a legfontosabb előrejelzők közé tartoznak, míg fnlwgt például úgy tűnik, hogy nincs nagy hatása az eredményre.
Az adatleírókhoz és a vizualizációkhoz hasonlóan az interakcióknak és a korrelációknak is figyelembe kell venniük az adott jellemzőket.
Más szavakkal, a különböző kombinációkat különböző korrelációs együtthatókkal mérjük. Alapértelmezés szerint, ydata-profiling korrelációkat futtat auto, ami azt jelenti:
- Numerikus versus numerikus segítségével mérjük az összefüggéseket Spearman rangja korrelációs együttható;
- Kategorikus versus kategorikus segítségével mérjük az összefüggéseket Cramer V;
- Numerikus versus kategorikus a korrelációk is Cramer V-jét használják, ahol a numerikus jellemzőt először diszkretizálják;
És ha ellenőrizni akarod egyéb korrelációs együtthatók (pl. Pearson's, Kendall's, Phi) könnyen megteheti konfigurálja a jelentés paramétereit.
Ahogy a felé navigálunk adatközpontú paradigma A mesterséges intelligencia fejlesztése, hogy a csúcson lehetséges bonyolító tényezők amelyek az adatainkban felmerülnek, elengedhetetlenek.
A „bonyolító tényezőkkel” utalunk hibákat ami az adatfeldolgozás során előfordulhat, ill adatok belső jellemzői amelyek egyszerűen tükrözik a természet az adatok.
Ezek közé tartozik hiányzó adat, kiegyensúlyozatlan adat, állandó értékeket, ismétlődések, magasan korrelációs or fölösleges jellemzők, zajos adatok, többek között.
Adatminőségi problémák: hibák és az adatok belső jellemzői. A kép szerzője.
Ezeknek az adatminőségi problémáknak a felismerése a projekt elején (és a fejlesztés során folyamatosan figyelemmel kísérve) kritikus.
Ha ezeket nem azonosítják és nem kezelik a modellépítési szakasz előtt, veszélybe sodorhatják az egész ML-folyamatot, valamint az ebből származó későbbi elemzéseket és következtetéseket.
Automatizált folyamat nélkül e problémák azonosításának és kezelésének képessége teljes mértékben az EDA elemzést végző személy személyes tapasztalatára és szakértelmére lenne bízva, ami nyilvánvalóan nem ideális. Ráadásul mekkora súly nehezedik az ember vállára, különösen, ha figyelembe vesszük a nagy dimenziós adatkészleteket. Bejövő rémálom riasztás!
Ez az egyik legértékesebb tulajdonsága ydata-profiling, a adatminőségi riasztások automatikus generálása:
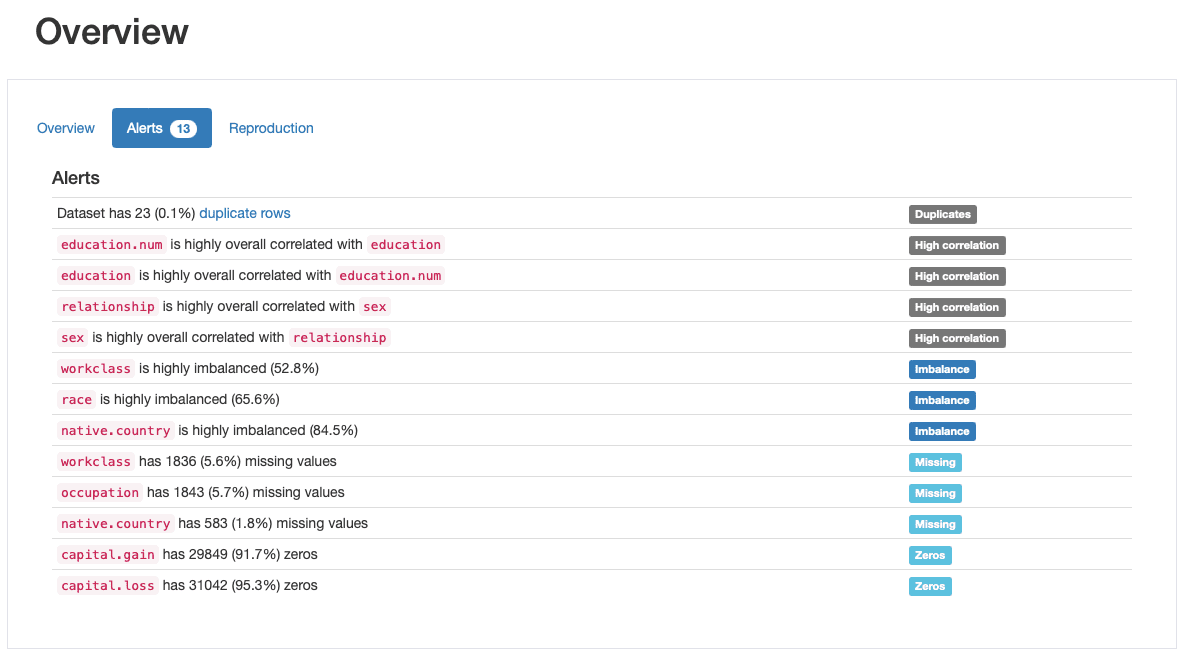
ydata-profiling: Profilalkotási jelentés – Adatminőségi figyelmeztetések. A kép szerzője.
A profil legalább 5 különböző típusú adatminőségi problémát ad kinevezetesen duplicates, high correlation, imbalance, missingés zeros.
Valójában ezek közül néhányat már korábban is azonosítottunk, amikor végigmentünk a 2. lépésen: race egy erősen kiegyensúlyozatlan tulajdonság és capital.gain túlnyomórészt 0-k lakják. Láttuk a szoros összefüggést is education és a education.numés relationship és a sex.
Hiányzó adatminták elemzése
A figyelembe vett riasztások átfogó köre között ydata-profiling különösen hasznos abban hiányzó adatminták elemzése.
Mivel az adatok hiánya nagyon gyakori probléma a valós világban, és egyes osztályozók alkalmazását teljesen veszélyeztetheti, vagy súlyosan torzíthatja előrejelzéseiket, egy másik bevált gyakorlat a hiányzó adatok alapos elemzése funkcióink által megjelenített százalékos arány és viselkedés:
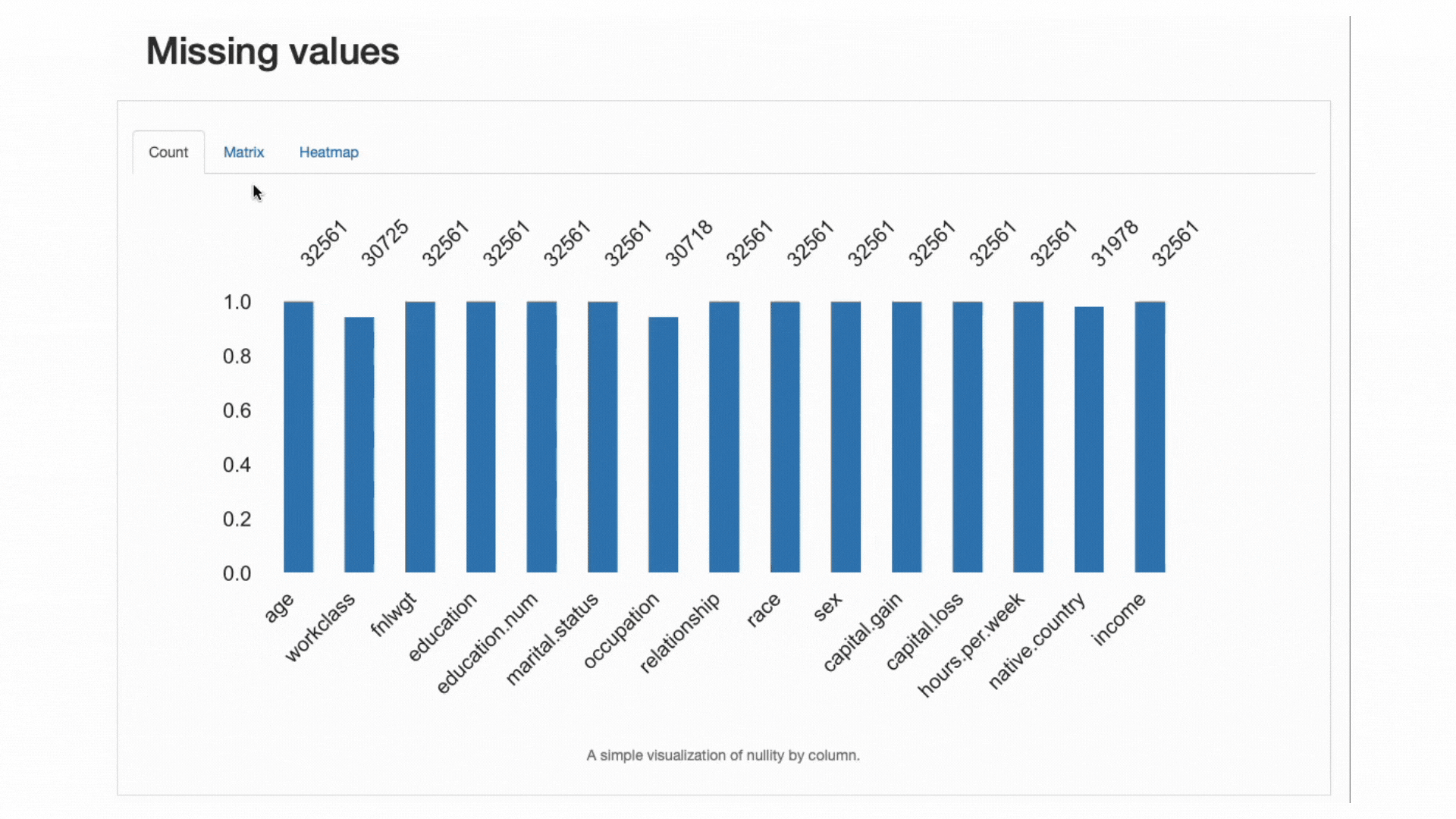
ydata-profiling: Profilozási jelentés – Hiányzó értékek elemzése. Forgatókönyv: Szerző.
Az adatriasztások részből ezt már tudtuk workclass, occupationés native.country hiányzó megfigyelések voltak. A hőtérkép továbbá azt mondja nekünk, hogy közvetlen kapcsolat van a hiányzó mintával in occupation és a workclass: ha az egyik jellemzőből hiányzik az érték, a másik is hiányozni fog.
Kulcsfontosságú betekintés: Az adatprofilozás túlmutat az EDA-n!
Eddig arról vitatkoztunk, hogy milyen feladatokat alkotnak egy alapos EDA folyamat és hogyan az adatminőséggel kapcsolatos kérdések és jellemzők értékelése - egy folyamat, amelyet adatprofilozásnak nevezhetünk – határozottan a legjobb gyakorlat.
Ennek ellenére fontos tisztázni ezt adatprofilozás túlmutat az EDA-n. Mivel az EDA-t általában feltáró, interaktív lépésként határozzuk meg, mielőtt bármilyen típusú adatfolyamot kifejlesztenénk, Az adatprofilalkotás egy iteratív folyamat, amely minden lépésnél meg kell történnie az adatok előfeldolgozása és modellépítése.
A hatékony EDA lefekteti a sikeres gépi tanulási folyamat alapjait.
Ez olyan, mintha egy diagnózist futtatna az adatain, és mindent megtanulna, amit tudnia kell arról, hogy mit is takar – az adatokat ingatlanait, kapcsolatok, kérdések – hogy később a lehető legjobban megszólítsa őket.
Ez egyben a mi inspirációs szakaszunk kezdete is: az EDA-tól kezdődően kérdések és hipotézisek kezdenek felmerülni, és a tervek szerint elemzéseket végeznek ezek megerősítésére vagy elutasítására.
A cikkben végig foglalkoztunk a 3 fő alapvető lépés, amely végigvezeti Önt egy hatékony EDA-n, és megvitatták egy csúcsminőségű eszköz hatását – ydata-profiling — hogy a helyes irányba mutasson, és rendkívül sok időt és lelki terhet takarít meg nekünk.
Remélem, ez az útmutató segít elsajátítani az „adatnyomozó” művészetét. és mint mindig, a visszajelzéseket, kérdéseket és javaslatokat nagyra értékeljük. Hadd tudjam meg, milyen témákról szeretnék még írni, vagy ami még jobb, jöjjön el hozzám Adatközpontú AI közösség és működjünk együtt!
Miriam Santos összpontosítson az adattudományi és gépi tanulási közösségek oktatására arról, hogyan lehet áttérni a nyers, piszkos, „rossz” vagy tökéletlen adatokról az intelligens, intelligens, jó minőségű adatokra, lehetővé téve a gépi tanulási osztályozók számára, hogy pontos és megbízható következtetéseket vonjanak le több iparágban (Fintech). , Healthcare & Pharma, Telecomm és Retail).
eredeti. Engedéllyel újra közzétéve.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- EVM Finance. Egységes felület a decentralizált pénzügyekhez. Hozzáférés itt.
- Quantum Media Group. IR/PR erősített. Hozzáférés itt.
- PlatoAiStream. Web3 adatintelligencia. Felerősített tudás. Hozzáférés itt.
- Forrás: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :van
- :is
- :nem
- :ahol
- $ UP
- 1
- 30
- 40
- 60
- 65
- 91
- a
- képesség
- Rólunk
- felett
- hiányzó
- Fiók
- pontos
- Elérése
- át
- hozzáadott
- További
- további információ
- cím
- Hozzáteszi
- Beállított
- Felnőtt
- érint
- újra
- Korosztály
- AI
- figyelmeztetések
- algoritmus
- algoritmusok
- Minden termék
- mentén
- már
- Is
- Bár
- teljesen
- mindig
- am
- között
- között
- összeg
- an
- elemzés
- elemez
- elemzett
- elemzése
- és a
- bármilyen
- Alkalmazás
- VANNAK
- Művészet
- cikkben
- AS
- értékelése
- értékelés
- társult
- At
- részt vesz
- szerző
- Automatizált
- Automatikus
- elérhető
- el
- Rossz
- bár
- BE
- óta
- előtt
- Kezdet
- hogy
- Hisz
- BEST
- legjobb gyakorlatok
- Jobb
- között
- Túl
- előítélet
- Bing
- mindkét
- Bring
- Épület
- épült
- teher
- de
- by
- hívás
- TUD
- tőke
- gondosan
- visz
- eset
- kategóriák
- Kategória
- Népszámlálás
- jellemzők
- ellenőrizze
- ellenőrzött
- osztály
- besorolás
- világos
- kód
- gyűjtemény
- szín
- kombinációk
- hogyan
- Közös
- Közösségek
- teljes
- bonyolult
- átfogó
- tartalmaz
- kompromisszum
- aggodalmak
- Magatartás
- vezető
- Következmények
- figyelembe vett
- figyelembe véve
- folyamatosan
- kényelem
- Összefüggés
- korrelációs együttható
- tudott
- kritikai
- kritikus
- dátum
- adatelemzés
- Adatok előkészítése
- adatminőség
- adat-tudomány
- adatkészletek
- foglalkozó
- dönt
- csökkenés
- mély
- alapértelmezett
- minden bizonnyal
- Függőség
- attól
- derivált
- leírt
- részlet
- részletes
- Határozzuk meg
- fejlesztése
- Fejlesztés
- eltérés
- diagnózis
- különböző
- közvetlen
- irány
- közvetlenül
- megvitatni
- tárgyalt
- megbeszélése
- kijelző
- terjesztés
- do
- nem
- domainek
- ne
- húz
- Csepp
- alatt
- e
- minden
- könnyebb
- könnyen
- nevelése
- Hatékony
- hatékony
- eredményesen
- bármelyik
- lehetővé téve
- teljesen
- hibák
- különösen
- lényeg
- alapvető
- Eter (ETH)
- Még
- végül is
- Minden
- minden
- vizsgálva
- példa
- létező
- elvárja
- tapasztalat
- szakvélemény
- Feltáró adatelemzés
- feltárása
- külön-
- rendkívüli módon
- szem
- tény
- ismerős
- messze
- Funkció
- Jellemzők
- Visszacsatolás
- Találjon
- FINTECH
- vezetéknév
- Összpontosít
- következő
- A
- Kényszer
- formátum
- Alapítvány
- Frekvencia
- ból ből
- funkcionalitás
- alapvető
- alapvetően
- további
- jövő
- Nyereség
- általános
- általában
- generál
- generáció
- kap
- gif
- adott
- Go
- Goes
- megy
- nagy
- kitalálta
- útmutató
- kellett
- kéz
- fogantyú
- kezek
- Legyen
- tekintettel
- egészségügyi
- súlyosan
- segít
- hasznos
- segít
- jó minőségű
- Kiemel
- nagyon
- tart
- remény
- NYITVATARTÁS
- Hogyan
- How To
- azonban
- HTTPS
- i
- ideális
- azonosított
- azonosítani
- if
- kép
- azonnal
- Hatás
- fontos
- in
- beleértve
- Jövedelem
- Bejövő
- Növelje
- egyéni
- iparágak
- információ
- tájékoztató
- Insight
- meglátások
- Ihlet
- példa
- Intelligens
- szándékozik
- kölcsönhatás
- kölcsönhatások
- interaktív
- érdekes
- bele
- belső
- vizsgálja
- vizsgálat
- vonja
- kérdés
- kérdések
- IT
- ITS
- veszélyezteti
- Munka
- jpg
- éppen
- KDnuggets
- Kendall-é
- Ismer
- Ismerve
- ismert
- kurtosis
- Címke
- a későbbiekben
- Lays
- vezetékek
- tanulás
- legkevésbé
- balra
- kevesebb
- Engedély
- fény
- mint
- Valószínű
- vonal
- vonalak
- kis
- néz
- keres
- Elő/Utó
- gép
- gépi tanulás
- Fő
- főleg
- Többség
- csinál
- Manipuláció
- térkép
- mester
- Mátrix
- Lehet..
- me
- jelent
- eszközök
- megmért
- Találkozik
- szellemi
- említett
- Metrics
- esetleg
- bánja
- hiányzó
- ML
- Mód
- modell
- modellek
- ellenőrzés
- több
- a legtöbb
- mozog
- sok
- Keresse
- Szükség
- nem
- rendszerint
- Értesítés..
- szám
- tárgy
- Nyilvánvaló
- előfordul
- of
- gyakran
- on
- ONE
- csak
- optimálisan
- or
- érdekében
- Más
- Egyéb
- mi
- ki
- Eredmény
- teljesítmény
- átfogó
- áttekintés
- pár
- pandák
- különös
- múlt
- Mintás
- minták
- Emberek (People)
- százalék
- teljesít
- teljesítmény
- előadó
- talán
- engedély
- person
- személyes
- Pharma
- fázis
- vedd
- csővezeték
- tervezett
- Plató
- Platón adatintelligencia
- PlatoData
- valószínű
- pont
- Pops
- benépesített
- lehetséges
- gyakorlat
- gyakorlat
- Tippek
- Főleg
- előkészítés
- bemutatott
- ajándékot
- Preview
- korábban
- nyomtatás
- Előzetes
- Probléma
- folyamat
- feldolgozás
- profil
- profilalkotás
- program
- ingatlanait
- nyilvános
- cél
- világítás
- kérdés
- Kérdések
- Futam
- hatótávolság
- Arány
- Inkább
- Nyers
- való Világ
- észre
- nyilvántartások
- Csökkent
- visszaverődés
- tekintettel
- összefüggő
- kapcsolat
- Kapcsolatok
- viszonylag
- megbízható
- támaszkodnak
- megmaradó
- eltávolítás
- eltávolítása
- jelentést
- raktár
- képvisel
- képviselők
- szükség
- kötelező
- azok
- illetőleg
- Eredmények
- kiskereskedelem
- jobb
- Szabály
- futás
- azonos
- menetrend
- Tudomány
- hatálya
- Rész
- szakaszok
- lát
- látszik
- Úgy tűnik,
- látott
- érzékeny
- számos
- szigorúan
- Megosztás
- Webshop
- rövid
- kellene
- előadás
- jelentős
- Egyszerű
- egyszerűen
- egyszerre
- egyetlen
- okos
- So
- néhány
- valami
- némileg
- Spot
- Színpad
- állvány
- standard
- állványok
- kezdet
- Kezdve
- statisztika
- Lépés
- Lépései
- egyértelmű
- stratégiák
- későbbi
- sikeres
- ilyen
- Vesz
- cél
- Feladat
- feladatok
- megmondja
- mint
- hogy
- A
- az információ
- azok
- Őket
- Ott.
- ebből adódóan
- Ezek
- ők
- ezt
- alaposan
- gondoltam
- három
- Keresztül
- idő
- nak nek
- szerszám
- felső
- Témakörök
- felé
- hagyományosan
- borzasztó
- valóban
- kettő
- típus
- típusok
- alulreprezentált
- megértés
- egyedi
- ismeretlen
- -ig
- közelgő
- us
- használ
- használ
- segítségével
- rendszerint
- ÉRVÉNYESÍT
- érték
- Értékek
- különféle
- Ellen
- nagyon
- megjelenítés
- akar
- Út..
- we
- Hetek
- súly
- JÓL
- ment
- voltak
- Mit
- amikor
- vajon
- ami
- egész
- miért
- Wikipedia
- lesz
- val vel
- nélkül
- szavak
- Munka
- dolgozó
- művek
- lenne
- ír
- még
- te
- A te
- zephyrnet
- gyertya









