चाबी छीन लेना
- विचार प्रसार (टीपी) एक नवीन पद्धति है जो बड़े भाषा मॉडल (एलएलएम) की जटिल तर्क क्षमताओं को बढ़ाती है।
- टीपी एलएलएम को शुरू से ही तर्कसंगत बनाने के बजाय, तर्क को बेहतर बनाने के लिए समान समस्याओं और उनके समाधानों का लाभ उठाता है।
- विभिन्न कार्यों में प्रयोगों से पता चलता है कि टीपी 12% से 15% तक के सुधार के साथ आधारभूत तरीकों से काफी बेहतर प्रदर्शन करता है।
टीपी पहले एलएलएम को इनपुट से संबंधित समान समस्याओं के एक सेट का प्रस्ताव करने और हल करने के लिए प्रेरित करता है। फिर, टीपी सीधे एक नया समाधान प्राप्त करने के लिए अनुरूप समस्याओं के परिणामों का पुन: उपयोग करता है या स्क्रैच से प्राप्त प्रारंभिक समाधान में संशोधन करने के लिए निष्पादन के लिए एक ज्ञान-गहन योजना प्राप्त करता है।
बड़े भाषा मॉडल (एलएलएम) की बहुमुखी प्रतिभा और कम्प्यूटेशनल शक्ति निर्विवाद है, फिर भी वे असीमित नहीं हैं। एलएलएम के लिए सबसे महत्वपूर्ण और लगातार चुनौतियों में से एक समस्या-समाधान के लिए उनका सामान्य दृष्टिकोण है, जिसमें सामने आने वाले प्रत्येक नए कार्य के लिए पहले सिद्धांतों से तर्क शामिल होता है। यह समस्याग्रस्त है, क्योंकि यह उच्च स्तर की अनुकूलनशीलता की अनुमति देता है, लेकिन त्रुटियों की संभावना भी बढ़ाता है, खासकर उन कार्यों में जिनमें बहु-चरणीय तर्क की आवश्यकता होती है।
"शून्य से तर्क" की चुनौती विशेष रूप से उन जटिल कार्यों में स्पष्ट होती है जिनमें तर्क और अनुमान के कई चरणों की आवश्यकता होती है। उदाहरण के लिए, यदि किसी एलएलएम को परस्पर जुड़े बिंदुओं के नेटवर्क में सबसे छोटा रास्ता खोजने के लिए कहा जाता है, तो यह आमतौर पर समाधान खोजने के लिए पूर्व ज्ञान या समान समस्याओं का लाभ नहीं उठाएगा। इसके बजाय, यह समस्या को अलग से हल करने का प्रयास करेगा, जिससे इष्टतम परिणाम नहीं मिल सकते हैं या यहां तक कि पूर्ण त्रुटियां भी हो सकती हैं। प्रवेश करना विचार प्रचार (टीपी), एलएलएम की तर्क क्षमताओं को बढ़ाने के लिए डिज़ाइन की गई एक विधि। टीपी का लक्ष्य एलएलएम को समान समस्याओं और उनके संबंधित समाधानों के भंडार से आकर्षित करने की अनुमति देकर उनकी अंतर्निहित सीमाओं को दूर करना है। यह अभिनव दृष्टिकोण न केवल एलएलएम-जनित समाधानों की सटीकता में सुधार करता है बल्कि बहु-चरणीय, जटिल तर्क कार्यों से निपटने की उनकी क्षमता को भी महत्वपूर्ण रूप से बढ़ाता है। सादृश्य की शक्ति का लाभ उठाकर, टीपी एक रूपरेखा प्रदान करता है जो एलएलएम की सहज तर्क क्षमताओं को बढ़ाता है, जो हमें वास्तव में बुद्धिमान कृत्रिम प्रणालियों की प्राप्ति के एक कदम करीब लाता है।
विचार प्रसार में दो मुख्य चरण शामिल हैं:
- सबसे पहले, एलएलएम को इनपुट समस्या से संबंधित अनुरूप समस्याओं का एक सेट प्रस्तावित करने और हल करने के लिए प्रेरित किया जाता है
- इसके बाद, इन समान समस्याओं के समाधान का उपयोग या तो सीधे तौर पर नया समाधान निकालने या प्रारंभिक समाधान में संशोधन करने के लिए किया जाता है
समान समस्याओं की पहचान करने की प्रक्रिया एलएलएम को समस्या-समाधान रणनीतियों और समाधानों का पुन: उपयोग करने की अनुमति देती है, जिससे उसकी तर्क क्षमताओं में सुधार होता है। टीपी मौजूदा संकेतन विधियों के साथ संगत है, एक सामान्य समाधान प्रदान करता है जिसे महत्वपूर्ण कार्य-विशिष्ट इंजीनियरिंग के बिना विभिन्न कार्यों में शामिल किया जा सकता है।
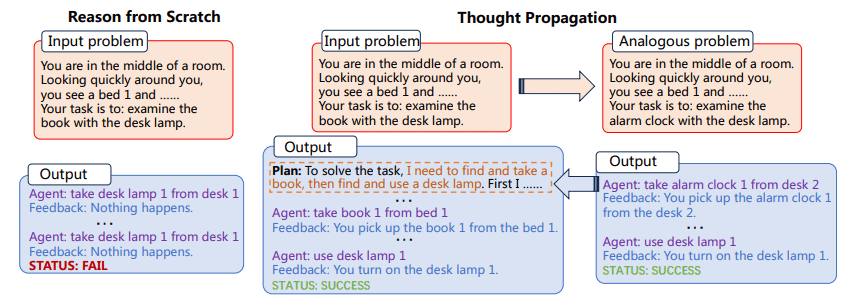
चित्रा 1: विचार प्रसार प्रक्रिया (कागज से छवि)
इसके अलावा, टीपी की अनुकूलनशीलता को कम करके नहीं आंका जाना चाहिए। मौजूदा संकेतन विधियों के साथ इसकी अनुकूलता इसे अत्यधिक बहुमुखी उपकरण बनाती है। इसका मतलब यह है कि टीपी किसी विशिष्ट प्रकार की समस्या-समाधान डोमेन तक सीमित नहीं है। यह कार्य-विशिष्ट फ़ाइन-ट्यूनिंग और अनुकूलन के लिए रोमांचक रास्ते खोलता है, जिससे अनुप्रयोगों के व्यापक स्पेक्ट्रम में एलएलएम की उपयोगिता और प्रभावकारिता बढ़ जाती है।
विचार प्रसार के कार्यान्वयन को मौजूदा एलएलएम के वर्कफ़्लो में एकीकृत किया जा सकता है। उदाहरण के लिए, शॉर्टेस्ट-पाथ रीजनिंग कार्य में, टीपी पहले विभिन्न संभावित रास्तों को समझने के लिए सरल, समान समस्याओं के एक सेट को हल कर सकता है। फिर यह जटिल समस्या को हल करने के लिए इन अंतर्दृष्टियों का उपयोग करेगा, जिससे इष्टतम समाधान खोजने की संभावना बढ़ जाएगी।
उदाहरण 1
- कार्य: सबसे छोटा रास्ता तर्क
- अनुरूप समस्याएँ: बिंदु A और B के बीच सबसे छोटा रास्ता, बिंदु B और C के बीच सबसे छोटा रास्ता
- अंतिम समाधान: समान समस्याओं के समाधान पर विचार करते हुए बिंदु A से C तक इष्टतम पथ
उदाहरण 2
- कार्य: रचनात्मक लेखन
- अनुरूप समस्याएँ: दोस्ती के बारे में एक छोटी कहानी लिखें, विश्वास के बारे में एक छोटी कहानी लिखें
- अंतिम समाधान: एक जटिल लघु कहानी लिखें जो दोस्ती और विश्वास के विषयों को एकीकृत करती हो
इस प्रक्रिया में पहले इन समान समस्याओं को हल करना और फिर हाथ में मौजूद जटिल कार्य से निपटने के लिए प्राप्त अंतर्दृष्टि का उपयोग करना शामिल है। इस पद्धति ने प्रदर्शन मेट्रिक्स में पर्याप्त सुधार दिखाते हुए कई कार्यों में अपनी प्रभावशीलता का प्रदर्शन किया है।
विचार प्रसार के निहितार्थ केवल मौजूदा मेट्रिक्स में सुधार करने से परे हैं। यह संकेत देने वाली तकनीक हमारे एलएलएम को समझने और तैनात करने के तरीके को बदलने की क्षमता रखती है। यह कार्यप्रणाली पृथक, परमाणु समस्या-समाधान से अधिक समग्र, परस्पर जुड़े दृष्टिकोण की ओर बदलाव को रेखांकित करती है। यह हमें इस बात पर विचार करने के लिए प्रेरित करता है कि एलएलएम न केवल डेटा से, बल्कि समस्या-समाधान की प्रक्रिया से भी कैसे सीख सकते हैं। अनुरूप समस्याओं के समाधान के माध्यम से अपनी समझ को लगातार अद्यतन करके, टीपी से लैस एलएलएम अप्रत्याशित चुनौतियों से निपटने के लिए बेहतर ढंग से तैयार होते हैं, जिससे वे तेजी से विकसित हो रहे वातावरण में अधिक लचीला और अनुकूलनीय बन जाते हैं।
विचार प्रसार एलएलएम की क्षमताओं को बढ़ाने के उद्देश्य से प्रोत्साहन विधियों के टूलबॉक्स में एक आशाजनक अतिरिक्त है। एलएलएम को समान समस्याओं और उनके समाधानों का लाभ उठाने की अनुमति देकर, टीपी एक अधिक सूक्ष्म और प्रभावी तर्क पद्धति प्रदान करता है। प्रयोग इसकी प्रभावकारिता की पुष्टि करते हैं, जिससे यह विभिन्न कार्यों में एलएलएम के प्रदर्शन में सुधार के लिए एक उम्मीदवार रणनीति बन जाती है। टीपी अंततः अधिक सक्षम एआई सिस्टम की खोज में एक महत्वपूर्ण कदम का प्रतिनिधित्व कर सकता है।
मैथ्यू मेयो (@mattmayo13) के पास कंप्यूटर विज्ञान में मास्टर डिग्री और डेटा माइनिंग में स्नातक डिप्लोमा है। केडनगेट्स के प्रधान संपादक के रूप में, मैथ्यू का लक्ष्य जटिल डेटा विज्ञान अवधारणाओं को सुलभ बनाना है। उनकी व्यावसायिक रुचियों में प्राकृतिक भाषा प्रसंस्करण, मशीन लर्निंग एल्गोरिदम और उभरते एआई की खोज शामिल है। वह डेटा विज्ञान समुदाय में ज्ञान का लोकतंत्रीकरण करने के मिशन से प्रेरित है। मैथ्यू जब 6 साल का था तब से कोडिंग कर रहा है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models?utm_source=rss&utm_medium=rss&utm_campaign=thought-propagation-an-analogical-approach-to-complex-reasoning-with-large-language-models
- :हैस
- :है
- :नहीं
- $यूपी
- 15% तक
- 8
- a
- क्षमताओं
- क्षमता
- About
- सुलभ
- शुद्धता
- के पार
- इसके अलावा
- AI
- एआई सिस्टम
- उद्देश्य से
- करना
- एल्गोरिदम
- की अनुमति दे
- की अनुमति देता है
- भी
- amplifies
- an
- और
- कोई
- अनुप्रयोगों
- दृष्टिकोण
- हैं
- कृत्रिम
- AS
- At
- करने का प्रयास
- बढ़ाना
- रास्ते
- b
- आधारभूत
- BE
- किया गया
- बेहतर
- के बीच
- परे
- लाना
- विस्तृत
- लेकिन
- by
- कर सकते हैं
- उम्मीदवार
- क्षमताओं
- सक्षम
- चुनौती
- चुनौतियों
- करीब
- कोडन
- समुदाय
- अनुकूलता
- संगत
- जटिल
- कम्प्यूटेशनल
- कम्प्यूटेशनल शक्ति
- कंप्यूटर
- कम्प्यूटर साइंस
- अवधारणाओं
- पुष्टि करें
- विचार करना
- पर विचार
- संगत
- मिलकर
- लगातार
- इसी
- सका
- क्रिएटिव
- तिथि
- आँकड़ा खनन
- डेटा विज्ञान
- डिग्री
- मांग
- प्रजातंत्रीय बनाना
- साबित
- तैनात
- बनाया गया
- सीधे
- डोमेन
- खींचना
- संचालित
- मुख्या संपादक
- प्रभावी
- प्रभावशीलता
- प्रभावोत्पादकता
- भी
- ऊपर उठाने
- कस्र्न पत्थर
- अभियांत्रिकी
- बढ़ाता है
- बढ़ाने
- दर्ज
- वातावरण
- सुसज्जित
- त्रुटियाँ
- विशेष रूप से
- और भी
- प्रत्येक
- उद्विकासी
- उदाहरण
- उत्तेजक
- निष्पादन
- मौजूदा
- प्रयोगों
- तलाश
- खोज
- खोज
- प्रथम
- के लिए
- आगे
- ढांचा
- दोस्ती
- से
- प्राप्त की
- सामान्य जानकारी
- Go
- स्नातक
- हाथ
- he
- हाई
- अत्यधिक
- उसके
- रखती है
- समग्र
- कैसे
- HTTPS
- पहचान
- if
- की छवि
- कार्यान्वयन
- निहितार्थ
- में सुधार
- सुधार
- सुधार
- में सुधार लाने
- in
- शामिल
- निगमित
- बढ़ जाती है
- बढ़ती
- निहित
- प्रारंभिक
- जन्मजात
- अभिनव
- निवेश
- अंतर्दृष्टि
- बजाय
- एकीकृत
- एकीकृत
- बुद्धिमान
- परस्पर
- रुचियों
- में
- शामिल
- पृथक
- अलगाव
- IT
- आईटी इस
- खुद
- जेपीजी
- केवल
- केडनगेट्स
- बच्चा
- ज्ञान
- भाषा
- बड़ा
- नेतृत्व
- जानें
- सीख रहा हूँ
- लीवरेज
- leverages
- लाभ
- संभावना
- सीमा
- सीमाओं
- सीमित
- लिंक्डइन
- तर्क
- मशीन
- यंत्र अधिगम
- मुख्य
- बनाना
- बनाता है
- निर्माण
- मास्टर
- मैथ्यू
- मई..
- साधन
- केवल
- तरीका
- क्रियाविधि
- तरीकों
- मेट्रिक्स
- खनिज
- मिशन
- मॉडल
- अधिक
- अधिकांश
- विभिन्न
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- नेटवर्क
- नया
- नया समाधान
- उपन्यास
- प्राप्त
- of
- पुराना
- on
- ONE
- केवल
- खोलता है
- इष्टतम
- इष्टतमीकरण
- or
- Outperforms
- प्रत्यक्ष
- काबू
- काग़ज़
- विशेष रूप से
- पथ
- प्रदर्शन
- योजना
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- बिन्दु
- अंक
- संभव
- संभावित
- बिजली
- तैयार
- सिद्धांतों
- पूर्व
- मुसीबत
- समस्या को सुलझाना
- समस्याओं
- प्रक्रिया
- प्रसंस्करण
- पेशेवर
- होनहार
- स्पष्ट
- प्रचार
- प्रस्ताव
- प्रदान करता है
- प्रदान कर
- लेकर
- तेजी
- बल्कि
- वसूली
- कारण
- सम्बंधित
- प्रतिपादन
- प्रतिनिधित्व
- की आवश्यकता होती है
- लचीला
- परिणाम
- पुनः प्रयोग
- s
- विज्ञान
- खरोंच
- Search
- सेट
- पाली
- कम
- चाहिए
- दिखाना
- को दिखाने
- महत्वपूर्ण
- काफी
- के बाद से
- समाधान
- समाधान ढूंढे
- हल
- सुलझाने
- विशिष्ट
- स्पेक्ट्रम
- कदम
- कदम
- कहानी
- रणनीतियों
- स्ट्रेटेजी
- पर्याप्त
- काफी हद तक
- सिस्टम
- पकड़ना
- कार्य
- कार्य
- तकनीक
- से
- कि
- RSI
- लेकिन हाल ही
- उन
- विषयों
- फिर
- जिसके चलते
- इन
- वे
- इसका
- विचार
- यहाँ
- सेवा मेरे
- साधन
- टूलबॉक्स
- की ओर
- tp
- वास्तव में
- ट्रस्ट
- दो
- आम तौर पर
- अंत में
- निर्विवाद
- रेखांकित
- समझना
- समझ
- अदृष्ट
- अद्यतन
- us
- उपयोग
- प्रयुक्त
- का उपयोग
- उपयोगिता
- विविधता
- विभिन्न
- बहुमुखी
- चंचलता
- था
- we
- कौन कौन से
- साथ में
- बिना
- वर्कफ़्लो
- होगा
- लिखना
- लिख रहे हैं
- साल
- अभी तक
- प्राप्ति
- जेफिरनेट