यह पोस्ट एलएसईजी के लो लेटेंसी ग्रुप के प्रमोद नायक, लक्ष्मीकांत मन्नेम और विवेक अग्रवाल के साथ मिलकर लिखी गई है।
लेनदेन लागत विश्लेषण (टीसीए) का उपयोग व्यापारियों, पोर्टफोलियो प्रबंधकों और दलालों द्वारा व्यापार-पूर्व और व्यापार-पश्चात विश्लेषण के लिए व्यापक रूप से किया जाता है, और यह उन्हें लेनदेन लागत और उनकी व्यापारिक रणनीतियों की प्रभावशीलता को मापने और अनुकूलित करने में मदद करता है। इस पोस्ट में, हम विकल्प बिड-आस्क स्प्रेड का विश्लेषण करते हैं एलएसईजी टिक इतिहास - पीसीएपी डेटासेट का उपयोग करना अपाचे स्पार्क के लिए अमेज़न एथेना. हम आपको दिखाते हैं कि डेटा तक कैसे पहुंचें, डेटा पर लागू करने के लिए कस्टम फ़ंक्शन को कैसे परिभाषित करें, डेटासेट को क्वेरी और फ़िल्टर करें, और विश्लेषण के परिणामों की कल्पना करें, यह सब बुनियादी ढांचे की स्थापना या स्पार्क को कॉन्फ़िगर करने के बारे में चिंता किए बिना, यहां तक कि बड़े डेटासेट के लिए भी।
पृष्ठभूमि
ऑप्शंस प्राइस रिपोर्टिंग अथॉरिटी (ओपीआरए) एक महत्वपूर्ण प्रतिभूति सूचना प्रोसेसर के रूप में कार्य करता है, जो यूएस ऑप्शंस के लिए अंतिम बिक्री रिपोर्ट, उद्धरण और प्रासंगिक जानकारी एकत्रित, समेकित और प्रसारित करता है। 18 सक्रिय अमेरिकी विकल्प एक्सचेंजों और 1.5 मिलियन से अधिक योग्य अनुबंधों के साथ, ओपीआरए व्यापक बाजार डेटा प्रदान करने में महत्वपूर्ण भूमिका निभाता है।
5 फरवरी, 2024 को, सिक्योरिटीज इंडस्ट्री ऑटोमेशन कॉरपोरेशन (SIAC) OPRA फ़ीड को 48 से 96 मल्टीकास्ट चैनलों में अपग्रेड करने के लिए तैयार है। इस वृद्धि का उद्देश्य अमेरिकी विकल्प बाजार में बढ़ती व्यापारिक गतिविधि और अस्थिरता के जवाब में प्रतीक वितरण और लाइन क्षमता उपयोग को अनुकूलित करना है। एसआईएसी ने सिफारिश की है कि कंपनियां 37.3 जीबीआईटी प्रति सेकंड तक की चरम डेटा दरों के लिए तैयारी करें।
अपग्रेड के बावजूद प्रकाशित डेटा की कुल मात्रा में तुरंत बदलाव नहीं होने के बावजूद, यह ओपीआरए को काफी तेज दर से डेटा प्रसारित करने में सक्षम बनाता है। गतिशील विकल्प बाजार की मांगों को संबोधित करने के लिए यह परिवर्तन महत्वपूर्ण है।
150.4 की तीसरी तिमाही में एक दिन में अधिकतम 3 बिलियन संदेशों और एक ही दिन में 2023 बिलियन संदेशों की क्षमता की आवश्यकता के साथ, ओपीआरए सबसे अधिक मात्रा वाले फ़ीड के रूप में सामने आया है। लेनदेन लागत विश्लेषण, बाजार तरलता निगरानी, ट्रेडिंग रणनीति मूल्यांकन और बाजार अनुसंधान के लिए हर एक संदेश को कैप्चर करना महत्वपूर्ण है।
डेटा के बारे में
एलएसईजी टिक इतिहास - पीसीएपी एक क्लाउड-आधारित रिपॉजिटरी है, जो 30 पीबी से अधिक है, जिसमें अति-उच्च गुणवत्ता वाले वैश्विक बाजार डेटा शामिल है। यह डेटा सावधानीपूर्वक एक्सचेंज डेटा केंद्रों के भीतर सीधे कैप्चर किया जाता है, जो दुनिया भर के प्रमुख प्राथमिक और बैकअप एक्सचेंज डेटा केंद्रों में रणनीतिक रूप से तैनात अनावश्यक कैप्चर प्रक्रियाओं को नियोजित करता है। एलएसईजी की कैप्चर तकनीक दोषरहित डेटा कैप्चर सुनिश्चित करती है और नैनोसेकंड टाइमस्टैम्प परिशुद्धता के लिए जीपीएस टाइम-स्रोत का उपयोग करती है। इसके अतिरिक्त, किसी भी डेटा अंतराल को निर्बाध रूप से भरने के लिए परिष्कृत डेटा आर्बिट्रेज तकनीकों को नियोजित किया जाता है। कैप्चर करने के बाद, डेटा सावधानीपूर्वक प्रसंस्करण और मध्यस्थता से गुजरता है, और फिर इसका उपयोग करके Parquet प्रारूप में सामान्यीकृत किया जाता है एलएसईजी का रियल टाइम अल्ट्रा डायरेक्ट (आरटीयूडी) फ़ीड हैंडलर।
सामान्यीकरण प्रक्रिया, जो विश्लेषण के लिए डेटा तैयार करने का अभिन्न अंग है, प्रति दिन 6 टीबी तक संपीड़ित Parquet फ़ाइलें उत्पन्न करती है। डेटा की भारी मात्रा का श्रेय ओपीआरए की व्यापक प्रकृति को दिया जाता है, जिसमें कई एक्सचेंजों का विस्तार होता है, और विविध विशेषताओं वाले कई विकल्प अनुबंध शामिल होते हैं। बाजार में बढ़ती अस्थिरता और विकल्प एक्सचेंजों पर बाजार निर्माण गतिविधि ओपीआरए पर प्रकाशित डेटा की मात्रा में और योगदान देती है।
टिक हिस्ट्री - पीसीएपी की विशेषताएं कंपनियों को निम्नलिखित सहित विभिन्न विश्लेषण करने में सक्षम बनाती हैं:
- पूर्व-व्यापार विश्लेषण - संभावित व्यापार प्रभाव का मूल्यांकन करें और ऐतिहासिक डेटा के आधार पर विभिन्न निष्पादन रणनीतियों का पता लगाएं
- व्यापार पश्चात मूल्यांकन - निष्पादन रणनीतियों के प्रदर्शन का आकलन करने के लिए बेंचमार्क के विरुद्ध वास्तविक निष्पादन लागत को मापें
- अनुकूलित निष्पादन - बाजार के प्रभाव को कम करने और समग्र व्यापारिक लागत को कम करने के लिए ऐतिहासिक बाजार पैटर्न के आधार पर निष्पादन रणनीतियों को बेहतर बनाएं
- जोखिम प्रबंधन - स्लिपेज पैटर्न को पहचानें, आउटलेर्स की पहचान करें और व्यापारिक गतिविधियों से जुड़े जोखिमों का सक्रिय रूप से प्रबंधन करें
- प्रदर्शन एट्रिब्यूशन - पोर्टफोलियो प्रदर्शन का विश्लेषण करते समय व्यापारिक निर्णयों के प्रभाव को निवेश निर्णयों से अलग करें
एलएसईजी टिक हिस्ट्री - पीसीएपी डेटासेट उपलब्ध है AWS डेटा एक्सचेंज और इस पर पहुंचा जा सकता है एडब्ल्यूएस बाज़ार. साथ अमेज़न S3 के लिए AWS डेटा एक्सचेंज, आप सीधे एलएसईजी से पीसीएपी डेटा तक पहुंच सकते हैं अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3) बकेट, कंपनियों के लिए डेटा की अपनी प्रति संग्रहीत करने की आवश्यकता को समाप्त कर देता है। यह दृष्टिकोण डेटा प्रबंधन और भंडारण को सुव्यवस्थित करता है, जिससे ग्राहकों को उपयोग, एकीकरण और आसानी के साथ उच्च गुणवत्ता वाले पीसीएपी या सामान्यीकृत डेटा तक तत्काल पहुंच प्रदान होती है। पर्याप्त डेटा भंडारण बचत.
अपाचे स्पार्क के लिए एथेना
विश्लेषणात्मक प्रयासों के लिए, अपाचे स्पार्क के लिए एथेना एथेना कंसोल या एथेना एपीआई के माध्यम से सुलभ एक सरलीकृत नोटबुक अनुभव प्रदान करता है, जो आपको इंटरैक्टिव अपाचे स्पार्क एप्लिकेशन बनाने की अनुमति देता है। अनुकूलित स्पार्क रनटाइम के साथ, एथेना एक सेकंड से भी कम समय में स्पार्क इंजनों की संख्या को गतिशील रूप से स्केल करके डेटा के पेटाबाइट के विश्लेषण में मदद करता है। इसके अलावा, सामान्य पायथन लाइब्रेरी जैसे कि पांडा और न्यूमपी को मूल रूप से एकीकृत किया गया है, जिससे जटिल एप्लिकेशन लॉजिक के निर्माण की अनुमति मिलती है। लचीलापन नोटबुक में उपयोग के लिए कस्टम लाइब्रेरी के आयात तक विस्तारित है। स्पार्क के लिए एथेना अधिकांश ओपन-डेटा प्रारूपों को समायोजित करता है और इसके साथ सहजता से एकीकृत होता है एडब्ल्यूएस गोंद डेटा कैटलॉग।
डेटासेट
इस विश्लेषण के लिए, हमने 17 मई, 2023 से एलएसईजी टिक हिस्ट्री - पीसीएपी ओपीआरए डेटासेट का उपयोग किया। इस डेटासेट में निम्नलिखित घटक शामिल हैं:
- सर्वोत्तम बोली और प्रस्ताव (बीबीओ) - किसी दिए गए एक्सचेंज में सुरक्षा के लिए उच्चतम बोली और सबसे कम मांग की रिपोर्ट करता है
- राष्ट्रीय सर्वोत्तम बोली और प्रस्ताव (एनबीबीओ) - सभी एक्सचेंजों में सुरक्षा के लिए उच्चतम बोली और सबसे कम मांग की रिपोर्ट करता है
- ट्रेडों - सभी एक्सचेंजों में पूर्ण किए गए ट्रेडों का रिकॉर्ड
डेटासेट में निम्नलिखित डेटा वॉल्यूम शामिल हैं:
- ट्रेडों - 160 एमबी लगभग 60 संपीड़ित Parquet फ़ाइलों में वितरित
- BBO - 2.4 टीबी लगभग 300 संपीड़ित लकड़ी की फाइलों में वितरित
- एनबीबीओ - 2.8 टीबी लगभग 200 संपीड़ित लकड़ी की फाइलों में वितरित
विश्लेषण सिंहावलोकन
लेनदेन लागत विश्लेषण (टीसीए) के लिए ओपीआरए टिक इतिहास डेटा का विश्लेषण करने में एक विशिष्ट व्यापार घटना के आसपास बाजार उद्धरण और व्यापार की जांच करना शामिल है। हम इस अध्ययन के भाग के रूप में निम्नलिखित मैट्रिक्स का उपयोग करते हैं:
- उद्धृत प्रसार (क्यूएस) - बीबीओ पूछताछ और बीबीओ बोली के बीच अंतर के रूप में गणना की गई
- प्रभावी प्रसार (ईएस) - व्यापार मूल्य और बीबीओ के मध्य बिंदु के बीच अंतर के रूप में गणना की जाती है (बीबीओ बोली + (बीबीओ आस्क - बीबीओ बोली)/2)
- प्रभावी/उद्धृत प्रसार (ईक्यूएफ) - (ईएस/क्यूएस) * 100 के रूप में गणना की गई
हम इन स्प्रेड की गणना व्यापार से पहले और इसके अतिरिक्त व्यापार के बाद चार अंतरालों पर करते हैं (व्यापार के ठीक बाद, 1 सेकंड, 10 सेकंड और व्यापार के 60 सेकंड बाद)।
अपाचे स्पार्क के लिए एथेना कॉन्फ़िगर करें
अपाचे स्पार्क के लिए एथेना को कॉन्फ़िगर करने के लिए, निम्नलिखित चरणों को पूरा करें:
- एथेना कंसोल पर, नीचे शुरू हो, चुनते हैं PySpark और Spark SQL का उपयोग करके अपने डेटा का विश्लेषण करें.
- यदि आप पहली बार एथेना स्पार्क का उपयोग कर रहे हैं, तो चुनें कार्यसमूह बनाएं.

- के लिए कार्यसमूह का नाम¸ कार्यसमूह के लिए एक नाम दर्ज करें, जैसे
tca-analysis. - में विश्लेषिकी इंजन अनुभाग चुनें अपाचे स्पार्क.
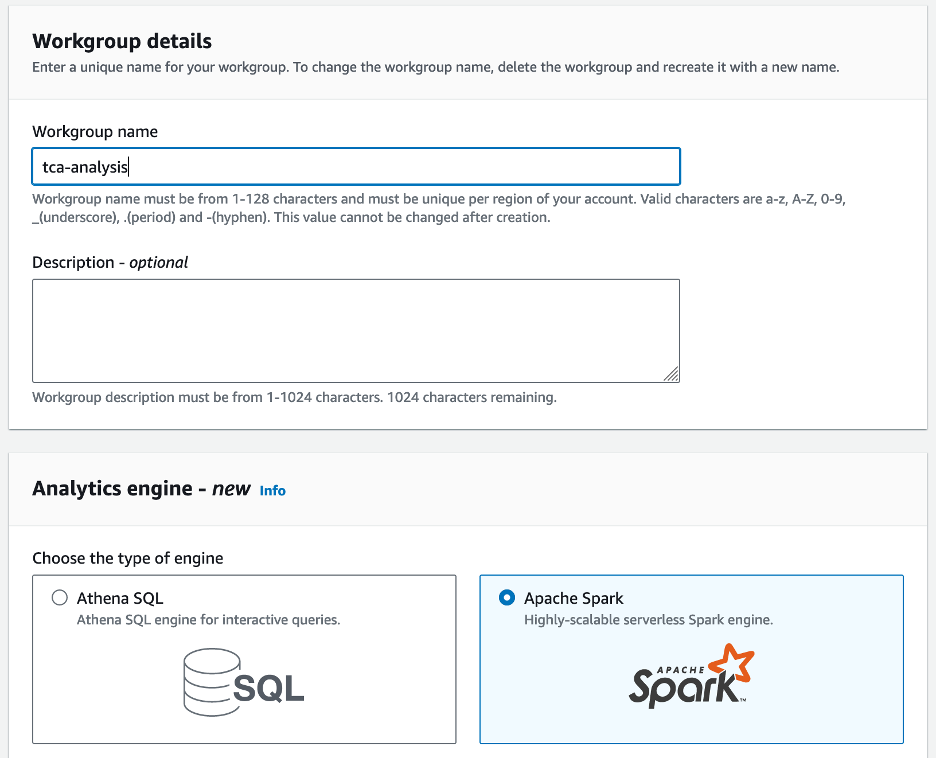
- में अतिरिक्त विन्यास अनुभाग, आप चुन सकते हैं डिफ़ॉल्ट का उपयोग करें या एक कस्टम प्रदान करें AWS पहचान और अभिगम प्रबंधन (IAM) भूमिका और गणना परिणामों के लिए Amazon S3 स्थान।
- चुनें कार्यसमूह बनाएं.
- कार्यसमूह बनाने के बाद, पर जाएँ नोटबुक टैब और चुनें नोटबुक बनाएं.
- अपनी नोटबुक के लिए एक नाम दर्ज करें, जैसे
tca-analysis-with-tick-history. - चुनें बनाएं अपनी नोटबुक बनाने के लिए.
अपनी नोटबुक लॉन्च करें
यदि आपने पहले ही स्पार्क कार्यसमूह बना लिया है, तो चयन करें नोटबुक संपादक लॉन्च करें के अंतर्गत शुरू हो.
![]()
आपकी नोटबुक बन जाने के बाद, आपको इंटरैक्टिव नोटबुक संपादक पर पुनः निर्देशित किया जाएगा।
![]()
अब हम निम्नलिखित कोड को अपनी नोटबुक में जोड़ और चला सकते हैं।
एक विश्लेषण बनाएं
विश्लेषण बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- सामान्य पुस्तकालय आयात करें:
- बीबीओ, एनबीबीओ और ट्रेडों के लिए हमारे डेटा फ़्रेम बनाएं:
- अब हम लेनदेन लागत विश्लेषण के लिए उपयोग करने के लिए एक व्यापार की पहचान कर सकते हैं:
हमें निम्नलिखित आउटपुट मिलता है:
हम व्यापार उत्पाद (टीपी), व्यापार मूल्य (टीपीआर), और व्यापार समय (टीटी) के लिए आगे बढ़ने वाली हाइलाइट की गई व्यापार जानकारी का उपयोग करते हैं।
- यहां हम अपने विश्लेषण के लिए कई सहायक फ़ंक्शन बनाते हैं
- निम्नलिखित फ़ंक्शन में, हम डेटासेट बनाते हैं जिसमें व्यापार से पहले और बाद के सभी उद्धरण शामिल होते हैं। एथेना स्पार्क स्वचालित रूप से निर्धारित करता है कि हमारे डेटासेट को संसाधित करने के लिए कितने डीपीयू लॉन्च करने हैं।
- आइए अब हमारे चयनित व्यापार की जानकारी के साथ टीसीए विश्लेषण फ़ंक्शन को कॉल करें:
विश्लेषण परिणामों की कल्पना करें
आइए अब वे डेटा फ़्रेम बनाएं जिनका उपयोग हम अपने विज़ुअलाइज़ेशन के लिए करते हैं। प्रत्येक डेटा फ़्रेम में प्रत्येक डेटा फ़ीड (बीबीओ, एनबीबीओ) के लिए पांच समय अंतरालों में से एक के लिए उद्धरण शामिल हैं:
निम्नलिखित अनुभागों में, हम विभिन्न विज़ुअलाइज़ेशन बनाने के लिए उदाहरण कोड प्रदान करते हैं।
व्यापार से पहले क्यूएस और एनबीबीओ प्लॉट करें
व्यापार से पहले उद्धृत स्प्रेड और एनबीबीओ को प्लॉट करने के लिए निम्नलिखित कोड का उपयोग करें:
![]()
प्रत्येक बाज़ार के लिए क्यूएस और व्यापार के बाद एनबीबीओ प्लॉट करें
व्यापार के तुरंत बाद प्रत्येक बाजार और एनबीबीओ के लिए उद्धृत प्रसार को प्लॉट करने के लिए निम्नलिखित कोड का उपयोग करें:
![]()
प्रत्येक समय अंतराल और बीबीओ के लिए प्रत्येक बाजार के लिए क्यूएस प्लॉट करें
बीबीओ के लिए प्रत्येक समय अंतराल और प्रत्येक बाजार के लिए उद्धृत प्रसार को प्लॉट करने के लिए निम्नलिखित कोड का उपयोग करें:
![]()
प्रत्येक समय अंतराल के लिए प्लॉट ES और BBO के लिए बाज़ार
बीबीओ के लिए प्रत्येक समय अंतराल और बाजार के लिए प्रभावी प्रसार की साजिश रचने के लिए निम्नलिखित कोड का उपयोग करें:
प्रत्येक समय अंतराल के लिए EQF प्लॉट करें और BBO के लिए बाज़ार बनाएं
बीबीओ के लिए प्रत्येक समय अंतराल और बाजार के लिए प्रभावी/उद्धृत प्रसार की साजिश रचने के लिए निम्नलिखित कोड का उपयोग करें:
एथेना स्पार्क गणना प्रदर्शन
जब आप एक कोड ब्लॉक चलाते हैं, तो एथेना स्पार्क स्वचालित रूप से निर्धारित करता है कि गणना को पूरा करने के लिए कितने डीपीयू की आवश्यकता है। अंतिम कोड ब्लॉक में, जहां हम कॉल करते हैं tca_analysis फ़ंक्शन, हम वास्तव में स्पार्क को डेटा संसाधित करने का निर्देश दे रहे हैं, और फिर हम परिणामी स्पार्क डेटाफ़्रेम को पांडा डेटाफ़्रेम में परिवर्तित करते हैं। यह विश्लेषण का सबसे गहन प्रसंस्करण हिस्सा है, और जब एथेना स्पार्क इस ब्लॉक को चलाता है, तो यह प्रगति बार, बीता हुआ समय और कितने डीपीयू वर्तमान में डेटा संसाधित कर रहे हैं, दिखाता है। उदाहरण के लिए, निम्नलिखित गणना में, एथेना स्पार्क 18 डीपीयू का उपयोग कर रहा है।
![]()
जब आप अपने एथेना स्पार्क नोटबुक को कॉन्फ़िगर करते हैं, तो आपके पास डीपीयू की अधिकतम संख्या निर्धारित करने का विकल्प होता है जिसका वह उपयोग कर सकता है। डिफ़ॉल्ट 20 डीपीयू है, लेकिन हमने 10, 20 और 40 डीपीयू के साथ इस गणना का परीक्षण किया ताकि यह प्रदर्शित किया जा सके कि एथेना स्पार्क हमारे विश्लेषण को चलाने के लिए स्वचालित रूप से कैसे स्केल करता है। हमने देखा कि एथेना स्पार्क रैखिक रूप से स्केल करता है, जब नोटबुक को अधिकतम 15 डीपीयू के साथ कॉन्फ़िगर किया गया था तो 21 मिनट और 10 सेकंड, जब नोटबुक को 8 डीपीयू के साथ कॉन्फ़िगर किया गया था तो 23 मिनट और 20 सेकंड और जब नोटबुक को कॉन्फ़िगर किया गया था तो 4 मिनट और 44 सेकंड का समय लगा था। 40 डीपीयू के साथ कॉन्फ़िगर किया गया। क्योंकि एथेना स्पार्क प्रति सेकंड ग्रैन्युलैरिटी पर डीपीयू उपयोग के आधार पर शुल्क लेता है, इन गणनाओं की लागत समान है, लेकिन यदि आप उच्च अधिकतम डीपीयू मान सेट करते हैं, तो एथेना स्पार्क विश्लेषण के परिणाम को बहुत तेजी से वापस कर सकता है। एथेना स्पार्क मूल्य निर्धारण के बारे में अधिक जानकारी के लिए कृपया क्लिक करें यहाँ उत्पन्न करें.
निष्कर्ष
इस पोस्ट में, हमने दिखाया कि आप एथेना स्पार्क का उपयोग करके लेनदेन लागत विश्लेषण करने के लिए एलएसईजी के टिक हिस्ट्री-पीसीएपी से उच्च-निष्ठा ओपीआरए डेटा का उपयोग कैसे कर सकते हैं। समयबद्ध तरीके से ओपीआरए डेटा की उपलब्धता, अमेज़ॅन एस 3 के लिए एडब्ल्यूएस डेटा एक्सचेंज की पहुंच नवाचारों के साथ पूरक, महत्वपूर्ण व्यापारिक निर्णयों के लिए कार्रवाई योग्य अंतर्दृष्टि बनाने की चाहत रखने वाली कंपनियों के लिए विश्लेषण में लगने वाले समय को रणनीतिक रूप से कम कर देती है। ओपीआरए हर दिन लगभग 7 टीबी सामान्यीकृत परक्वेट डेटा उत्पन्न करता है, और ओपीआरए डेटा के आधार पर विश्लेषण प्रदान करने के लिए बुनियादी ढांचे का प्रबंधन करना चुनौतीपूर्ण है।
टिक हिस्ट्री के लिए बड़े पैमाने पर डेटा प्रोसेसिंग को संभालने में एथेना की स्केलेबिलिटी - ओपीआरए डेटा के लिए पीसीएपी इसे एडब्ल्यूएस में तेज और स्केलेबल एनालिटिक्स समाधान चाहने वाले संगठनों के लिए एक आकर्षक विकल्प बनाती है। यह पोस्ट एडब्ल्यूएस पारिस्थितिकी तंत्र और टिक हिस्ट्री-पीसीएपी डेटा के बीच सहज बातचीत को दिखाती है और कैसे वित्तीय संस्थान महत्वपूर्ण व्यापार और निवेश रणनीतियों के लिए डेटा-संचालित निर्णय लेने के लिए इस तालमेल का लाभ उठा सकते हैं।
लेखक के बारे में
![]() प्रमोद नायक एलएसईजी में लो लेटेंसी ग्रुप के उत्पाद प्रबंधन के निदेशक हैं। प्रमोद के पास वित्तीय प्रौद्योगिकी उद्योग में सॉफ्टवेयर विकास, एनालिटिक्स और डेटा प्रबंधन पर ध्यान केंद्रित करने का 10 वर्षों से अधिक का अनुभव है। प्रमोद एक पूर्व सॉफ्टवेयर इंजीनियर हैं और बाजार डेटा और मात्रात्मक व्यापार के शौकीन हैं।
प्रमोद नायक एलएसईजी में लो लेटेंसी ग्रुप के उत्पाद प्रबंधन के निदेशक हैं। प्रमोद के पास वित्तीय प्रौद्योगिकी उद्योग में सॉफ्टवेयर विकास, एनालिटिक्स और डेटा प्रबंधन पर ध्यान केंद्रित करने का 10 वर्षों से अधिक का अनुभव है। प्रमोद एक पूर्व सॉफ्टवेयर इंजीनियर हैं और बाजार डेटा और मात्रात्मक व्यापार के शौकीन हैं।
![]() लक्ष्मीकांत मन्नम एलएसईजी के लो लेटेंसी ग्रुप में उत्पाद प्रबंधक हैं। वह कम-विलंबता बाज़ार डेटा उद्योग के लिए डेटा और प्लेटफ़ॉर्म उत्पादों पर ध्यान केंद्रित करते हैं। लक्ष्मीकांत ग्राहकों को उनकी बाज़ार डेटा आवश्यकताओं के लिए सबसे इष्टतम समाधान बनाने में मदद करता है।
लक्ष्मीकांत मन्नम एलएसईजी के लो लेटेंसी ग्रुप में उत्पाद प्रबंधक हैं। वह कम-विलंबता बाज़ार डेटा उद्योग के लिए डेटा और प्लेटफ़ॉर्म उत्पादों पर ध्यान केंद्रित करते हैं। लक्ष्मीकांत ग्राहकों को उनकी बाज़ार डेटा आवश्यकताओं के लिए सबसे इष्टतम समाधान बनाने में मदद करता है।
![]() विवेक अग्रवाल एलएसईजी के लो लेटेंसी ग्रुप में एक वरिष्ठ डेटा इंजीनियर हैं। विवेक कैप्चर किए गए बाज़ार डेटा फ़ीड और संदर्भ डेटा फ़ीड के प्रसंस्करण और वितरण के लिए डेटा पाइपलाइनों के विकास और रखरखाव पर काम करता है।
विवेक अग्रवाल एलएसईजी के लो लेटेंसी ग्रुप में एक वरिष्ठ डेटा इंजीनियर हैं। विवेक कैप्चर किए गए बाज़ार डेटा फ़ीड और संदर्भ डेटा फ़ीड के प्रसंस्करण और वितरण के लिए डेटा पाइपलाइनों के विकास और रखरखाव पर काम करता है।
![]() अल्केत मेमुशाज AWS में वित्तीय सेवा बाज़ार विकास टीम में एक प्रमुख वास्तुकार हैं। एल्केट तकनीकी रणनीति के लिए जिम्मेदार है, यहां तक कि सबसे अधिक मांग वाले पूंजी बाजार वर्कलोड को एडब्ल्यूएस क्लाउड पर तैनात करने के लिए भागीदारों और ग्राहकों के साथ काम करता है।
अल्केत मेमुशाज AWS में वित्तीय सेवा बाज़ार विकास टीम में एक प्रमुख वास्तुकार हैं। एल्केट तकनीकी रणनीति के लिए जिम्मेदार है, यहां तक कि सबसे अधिक मांग वाले पूंजी बाजार वर्कलोड को एडब्ल्यूएस क्लाउड पर तैनात करने के लिए भागीदारों और ग्राहकों के साथ काम करता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 12
- 15% तक
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- About
- पहुँच
- पहुँचा
- एक्सेसिबिलिटी
- सुलभ
- के पार
- सक्रिय
- गतिविधि
- वास्तविक
- वास्तव में
- जोड़ना
- इसके अतिरिक्त
- को संबोधित
- लाभ
- बाद
- के खिलाफ
- अग्रवाल
- करना
- सब
- की अनुमति दे
- पहले ही
- वीरांगना
- अमेज़न एथेना
- अमेज़ॅन वेब सेवा
- an
- विश्लेषण करती है
- विश्लेषण
- विश्लेषणात्मक
- विश्लेषिकी
- विश्लेषण करें
- का विश्लेषण
- और
- कोई
- अपाचे
- अपाचे स्पार्क
- एपीआई
- आवेदन
- अनुप्रयोगों
- लागू करें
- दृष्टिकोण
- लगभग
- अंतरपणन
- मध्यस्थता
- हैं
- चारों ओर
- AS
- पूछना
- आकलन
- जुड़े
- At
- विशेषताओं
- अधिकार
- स्वतः
- स्वचालन
- उपलब्धता
- उपलब्ध
- एडब्ल्यूएस
- बैकअप
- बार
- आधारित
- BE
- क्योंकि
- से पहले
- मानक
- BEST
- के बीच
- बोली
- बिलियन
- खंड
- दलालों
- निर्माण
- लेकिन
- by
- गणना
- परिकलित
- हिसाब
- कॉल
- कर सकते हैं
- क्षमता
- राजधानी
- पूंजी बाजार
- कब्जा
- पर कब्जा कर लिया
- कैप्चरिंग
- सूची
- केंद्र
- चुनौतीपूर्ण
- चैनलों
- विशेषता
- प्रभार
- चुनाव
- चुनें
- ग्राहकों
- बादल
- कोड
- एकत्रित
- सामान्य
- सम्मोहक
- पूरा
- पूरा
- घटकों
- व्यापक
- शामिल
- आचरण
- कॉन्फ़िगर किया गया
- को विन्यस्त
- कंसोल
- मजबूत
- शामिल हैं
- ठेके
- योगदान
- बदलना
- निगम
- लागत
- लागत
- सहलिखित
- बनाना
- बनाया
- निर्माण
- महत्वपूर्ण
- महत्वपूर्ण
- वर्तमान में
- रिवाज
- ग्राहक
- पानी का छींटा
- तिथि
- डेटा केन्द्रों
- डेटा इंजीनियर
- आंकडों का आदान प्रदान
- आँकड़ा प्रबंधन
- डेटा संसाधन
- डेटा भंडारण
- डेटा पर ही आधारित
- डेटासेट
- दिन
- निर्णय
- निर्णय
- चूक
- परिभाषित
- प्रसव
- मांग
- मांग
- दिखाना
- साबित
- तैनात
- विवरण
- निर्धारित
- विकासशील
- विकास
- विकास दल
- अंतर
- विभिन्न
- सीधे
- निदेशक
- वितरित
- वितरण
- कई
- डबल
- ड्राइव
- गतिशील
- गतिशील
- गतिकी
- से प्रत्येक
- आराम
- उपयोग में आसानी
- पारिस्थितिकी तंत्र
- संपादक
- प्रभावी
- प्रभावशीलता
- पात्र
- नष्ट
- कार्यरत
- रोजगार
- सक्षम
- सक्षम बनाता है
- शामिल
- प्रयासों
- इंजन
- इंजीनियर
- इंजन
- वृद्धि
- सुनिश्चित
- दर्ज
- तीव्र
- ईथर (ईटीएच)
- मूल्यांकन करें
- मूल्यांकन
- और भी
- कार्यक्रम
- प्रत्येक
- उदाहरण
- एक्सचेंज
- एक्सचेंजों
- निष्पादन
- अनुभव
- का पता लगाने
- व्यक्त
- फैली
- और तेज
- की विशेषता
- फरवरी
- अंजीर
- फ़ाइलें
- भरना
- फ़िल्टर
- वित्तीय
- वित्तीय संस्थाए
- वित्तीय सेवाओं
- वित्तीय प्रौद्योगिकी
- फर्मों
- प्रथम
- पहली बार
- पांच
- लचीलापन
- केंद्रित
- ध्यान केंद्रित
- निम्नलिखित
- के लिए
- प्रारूप
- पूर्व
- आगे
- चार
- फ्रेम
- से
- समारोह
- कार्यों
- आगे
- अंतराल
- उत्पन्न करता है
- मिल
- दी
- वैश्विक
- वैश्विक बाज़ार
- Go
- जा
- जीपीएस
- समूह
- हैंडलिंग
- है
- होने
- he
- headroom
- मदद करता है
- उच्च गुणवत्ता
- उच्चतर
- उच्चतम
- हाइलाइट
- ऐतिहासिक
- इतिहास
- आवासन
- कैसे
- How To
- http
- HTTPS
- आई ए एम
- पहचान करना
- पहचान
- if
- तत्काल
- तुरंत
- प्रभाव
- आयात
- in
- सहित
- वृद्धि हुई
- उद्योग
- करें-
- इंफ्रास्ट्रक्चर
- नवाचारों
- अंतर्दृष्टि
- संस्थानों
- अभिन्न
- एकीकृत
- एकीकरण
- बातचीत
- इंटरैक्टिव
- में
- जटिल
- निवेश
- शामिल
- IT
- जेपीजी
- केवल
- बड़ा
- बड़े पैमाने पर
- पिछली बार
- विलंब
- लांच
- कम
- पुस्तकालयों
- लाइन
- चलनिधि
- स्थान
- तर्क
- देख
- निम्न
- सबसे कम
- को बनाए रखने
- प्रमुख
- बनाता है
- निर्माण
- प्रबंधन
- प्रबंध
- प्रबंधक
- प्रबंधक
- प्रबंध
- ढंग
- बहुत
- बाजार
- बाज़ार संबंधी आंकड़े
- बाजार प्रभाव
- बाजार अनुसंधान
- बाजार में अस्थिरता
- बाजार बनाने
- Markets
- विशाल
- माहिर
- अधिकतम
- मई..
- माप
- message
- संदेश
- सूक्ष्म
- पूरी बारीकी से
- मेट्रिक्स
- दस लाख
- कम से कम
- मिनट
- निगरानी
- अधिक
- और भी
- अधिकांश
- बहुत
- विभिन्न
- नाम
- प्रकृति
- नेविगेट करें
- आवश्यकता
- की जरूरत है
- कोई नहीं
- नोटबुक
- पुस्तिकाओं
- संख्या
- अनेक
- numpy
- मनाया
- of
- प्रस्ताव
- ऑफर
- on
- ONE
- इष्टतम
- ऑप्टिमाइज़ करें
- अनुकूलित
- विकल्प
- ऑप्शंस
- or
- संगठनों
- हमारी
- आउट
- उत्पादन
- के ऊपर
- कुल
- अपना
- पांडा
- भाग
- भागीदारों
- आवेशपूर्ण
- पैटर्न उपयोग करें
- शिखर
- प्रति
- निष्पादन
- प्रदर्शन
- केंद्रीय
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- निभाता
- कृप्या अ
- भूखंड
- संविभाग
- पोर्टफोलियो मैनेजर
- स्थिति में
- पद
- बाद व्यापार
- संभावित
- शुद्धता
- तैयार करना
- तैयारी
- मूल्य
- कीमत निर्धारण
- प्राथमिक
- प्रिंसिपल
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- प्रोसेसर
- एस्ट्रो मॉल
- उत्पाद प्रबंधन
- उत्पादन प्रबंधक
- उत्पाद
- प्रगति
- प्रदान करना
- प्रदान कर
- प्रकाशित
- अजगर
- Q3
- मात्रात्मक
- मात्रा
- सवाल
- उद्धरण
- मूल्यांकन करें
- दरें
- पढ़ना
- वास्तविक
- वास्तविक समय
- की सिफारिश की
- अभिलेख
- लाल
- को कम करने
- कम कर देता है
- संदर्भ
- refinitiv
- रिपोर्टिंग
- रिपोर्ट
- कोष
- आवश्यकता
- की आवश्यकता होती है
- अनुसंधान
- प्रतिक्रिया
- जिम्मेदार
- परिणाम
- जिसके परिणामस्वरूप
- परिणाम
- वापसी
- जोखिम
- भूमिका
- रन
- चलाता है
- बिक्री
- अनुमापकता
- स्केलेबल
- तराजू
- स्केलिंग
- निर्बाध
- मूल
- दूसरा
- सेकंड
- अनुभाग
- वर्गों
- प्रतिभूतियां
- सुरक्षा
- मांग
- चयन
- चयनित
- वरिष्ठ
- अलग
- कार्य करता है
- सेवाएँ
- सेट
- की स्थापना
- दिखाना
- दिखाता है
- काफी
- समान
- सरल
- सरलीकृत
- एक
- slippage
- सॉफ्टवेयर
- सॉफ्टवेयर विकास
- सॉफ्टवेयर इंजीनियर
- समाधान ढूंढे
- परिष्कृत
- तनाव
- स्पार्क
- विशिष्ट
- विस्तार
- स्प्रेड्स
- खड़ा
- कदम
- भंडारण
- की दुकान
- रणनीतिक
- रणनीतियों
- स्ट्रेटेजी
- सुव्यवस्थित
- अध्ययन
- आगामी
- ऐसा
- स्विफ्ट
- प्रतीक
- तालमेल
- लेना
- ले जा
- टीम
- तकनीकी
- तकनीक
- टेक्नोलॉजी
- परीक्षण किया
- से
- कि
- RSI
- जानकारी
- लेकिन हाल ही
- उन
- फिर
- इन
- इसका
- यहाँ
- टिकटिक
- पहर
- समयोचित
- टाइमस्टैम्प
- शीर्षक
- सेवा मेरे
- कुल
- tp
- TPR
- व्यापार
- व्यापारी
- ट्रेडों
- व्यापार
- ट्रेडिंग रणनीतियाँ
- व्यापार रणनीति
- ट्रांजेक्शन
- लेनदेन कीमत
- बदलने
- संक्रमण
- अति
- के अंतर्गत
- से होकर गुजरती है
- उन्नयन
- us
- प्रयोग
- उपयोग
- प्रयुक्त
- का उपयोग करता है
- का उपयोग
- उपयोग
- मूल्य
- विभिन्न
- दृश्य
- कल्पना
- अस्थिरता
- आयतन
- संस्करणों
- था
- we
- वेब
- वेब सेवाओं
- कब
- कौन कौन से
- व्यापक रूप से
- मर्जी
- साथ में
- अंदर
- बिना
- कार्यसमूह
- काम कर रहे
- कार्य
- दुनिया भर
- चिंता
- X
- साल
- इसलिए आप
- आपका
- जेफिरनेट