
एडोब जुगनू से छवि
“हममें से बहुत सारे लोग थे। हमारे पास बहुत अधिक धन, बहुत अधिक उपकरण थे और धीरे-धीरे हम पागल हो गए।”
फ्रांसिस फोर्ड कोपोला उन एआई कंपनियों के लिए रूपक नहीं बना रहे थे जो बहुत अधिक खर्च करती हैं और अपना रास्ता भटक जाती हैं, लेकिन वह ऐसा कर सकते थे। अब सर्वनाश यह महाकाव्य था लेकिन बनाने में एक लंबा, कठिन और महंगा प्रोजेक्ट भी था, GPT-4 की तरह। मेरा सुझाव है कि एलएलएम के विकास में बहुत अधिक पैसा और बहुत अधिक उपकरण लगे हैं। और कुछ "हमने अभी-अभी सामान्य बुद्धि का आविष्कार किया है" का प्रचार थोड़ा पागलपन भरा है। लेकिन अब ओपन सोर्स समुदायों की बारी है कि वे वह करें जो वे सबसे अच्छा करते हैं: बहुत कम पैसे और उपकरणों का उपयोग करके मुफ्त प्रतिस्पर्धी सॉफ़्टवेयर वितरित करना।
OpenAI ने $11Bn से अधिक की फंडिंग ली है और अनुमान है कि GPT-3.5 की लागत प्रति प्रशिक्षण $5-$6m है। हम GPT-4 के बारे में बहुत कम जानते हैं क्योंकि OpenAI नहीं बता रहा है, लेकिन मुझे लगता है कि यह मान लेना सुरक्षित है कि यह GPT-3.5 से छोटा नहीं है। वर्तमान में दुनिया भर में GPU की कमी है और - एक बदलाव के लिए - यह नवीनतम क्रिप्टोकॉइन के कारण नहीं है। जेनेरेटिव एआई स्टार्ट-अप $100 मिलियन+ सीरीज ए राउंड में भारी वैल्यूएशन पर उतर रहे हैं, जब उनके पास एलएलएम के लिए कोई भी आईपी नहीं है जिसका उपयोग वे अपने उत्पाद को पावर देने के लिए करते हैं। एलएलएम का चलन जोरों पर है और पैसा बह रहा है।
It had looked like the die was cast: only deep-pocketed companies like Microsoft/OpenAI, Amazon, and Google could afford to train hundred-billion parameter models. Bigger models were assumed to be better models. GPT-3 got something wrong? Just wait until there's a bigger version and it’ll all be fine! Smaller companies looking to compete had to raise far more capital or be left building commodity integrations in the ChatGPT marketplace. Academia, with even more constrained research budgets, was relegated to the sidelines.
सौभाग्य से, कुछ स्मार्ट लोगों और ओपन सोर्स प्रोजेक्ट्स ने इसे प्रतिबंध के बजाय एक चुनौती के रूप में लिया। स्टैनफोर्ड के शोधकर्ताओं ने 7-बिलियन पैरामीटर मॉडल अल्पाका जारी किया, जिसका प्रदर्शन जीपीटी-3.5 के 175-बिलियन पैरामीटर मॉडल के करीब आता है। OpenAI द्वारा उपयोग किए जाने वाले आकार का एक प्रशिक्षण सेट बनाने के लिए संसाधनों की कमी के कारण, उन्होंने चतुराई से एक प्रशिक्षित ओपन सोर्स LLM, LLaMA लेने का विकल्प चुना और इसके बजाय GPT-3.5 संकेतों और आउटपुट की एक श्रृंखला पर इसे ठीक किया। मूलतः मॉडल ने सीखा कि GPT-3.5 क्या करता है, जो उसके व्यवहार को दोहराने के लिए एक बहुत प्रभावी रणनीति बन गई है।
अल्पाका को केवल कोड और डेटा दोनों में गैर-व्यावसायिक उपयोग के लिए लाइसेंस प्राप्त है क्योंकि यह ओपन सोर्स गैर-व्यावसायिक एलएलएएमए मॉडल का उपयोग करता है, और ओपनएआई प्रतिस्पर्धी उत्पाद बनाने के लिए अपने एपीआई के किसी भी उपयोग की स्पष्ट रूप से अनुमति नहीं देता है। यह अल्पाका के संकेतों और आउटपुट पर एक अलग ओपन सोर्स एलएलएम को ठीक करने की आकर्षक संभावना पैदा करता है... विभिन्न लाइसेंसिंग संभावनाओं के साथ एक तीसरा जीपीटी-3.5-जैसा मॉडल तैयार करता है।
यहां विडंबना की एक और परत है, जिसमें सभी प्रमुख एलएलएम को इंटरनेट पर उपलब्ध कॉपीराइट पाठ और छवियों पर प्रशिक्षित किया गया था और उन्होंने अधिकार धारकों को एक पैसा भी नहीं दिया। कंपनियां अमेरिकी कॉपीराइट कानून के तहत "उचित उपयोग" छूट का दावा इस तर्क के साथ करती हैं कि इसका उपयोग "परिवर्तनकारी" है। हालाँकि, जब उन मॉडलों के आउटपुट की बात आती है जो वे मुफ़्त डेटा के साथ बनाते हैं, तो वे वास्तव में नहीं चाहते कि कोई भी उनके साथ वही काम करे। मुझे उम्मीद है कि अधिकार-धारकों के समझदार होने पर इसमें बदलाव आएगा और किसी बिंदु पर इसका अंत अदालत में हो सकता है।
यह प्रतिबंधात्मक-लाइसेंस प्राप्त ओपन सोर्स के लेखकों द्वारा उठाया गया एक अलग और विशिष्ट बिंदु है, जो कोपायलट जैसे कोड उत्पादों के लिए जेनरेटिव एआई के लिए, इस आधार पर प्रशिक्षण के लिए उपयोग किए जा रहे उनके कोड पर आपत्ति जताते हैं कि लाइसेंस का पालन नहीं किया जा रहा है। व्यक्तिगत ओपन-सोर्स लेखकों के लिए समस्या यह है कि उन्हें अपनी स्थिति दिखाने की ज़रूरत है - वास्तविक नकल - और इससे उन्हें नुकसान हुआ है। और चूंकि मॉडल आउटपुट कोड को इनपुट से लिंक करना कठिन बनाते हैं (लेखक द्वारा स्रोत कोड की पंक्तियाँ) और कोई आर्थिक नुकसान नहीं होता है (यह मुफ़्त माना जाता है), मामला बनाना बहुत कठिन है। यह फ़ायदेमंद रचनाकारों (उदाहरण के लिए, फ़ोटोग्राफ़र) के विपरीत है, जिनका पूरा व्यवसाय मॉडल अपने काम को लाइसेंस देने/बेचने में है, और जिनका प्रतिनिधित्व गेटी इमेजेज जैसे एग्रीगेटर्स द्वारा किया जाता है, जो वास्तविक नकल दिखा सकते हैं।
LLaMA के बारे में एक और दिलचस्प बात यह है कि यह मेटा से निकला है। इसे मूल रूप से केवल शोधकर्ताओं के लिए जारी किया गया था और फिर बिटटोरेंट के माध्यम से दुनिया भर में लीक कर दिया गया। मेटा, OpenAI, Microsoft, Google और Amazon से मौलिक रूप से अलग व्यवसाय में है, क्योंकि यह आपको क्लाउड सेवाएँ या सॉफ़्टवेयर बेचने की कोशिश नहीं कर रहा है, और इसलिए इसमें बहुत अलग प्रोत्साहन हैं। इसने अतीत में अपने कंप्यूट डिज़ाइन को ओपन-सोर्स किया है (ओपनकंप्यूट) और समुदाय को उनमें सुधार करते देखा है - यह ओपन सोर्स के मूल्य को समझता है।
मेटा सबसे महत्वपूर्ण ओपन-सोर्स एआई योगदानकर्ताओं में से एक बन सकता है। न केवल इसके पास बड़े पैमाने पर संसाधन हैं, बल्कि अगर महान जेनेरिक एआई तकनीक का प्रसार होता है तो इससे लाभ होता है: सोशल मीडिया पर मुद्रीकरण के लिए इसके लिए अधिक सामग्री होगी। मेटा ने तीन अन्य ओपन-सोर्स एआई मॉडल जारी किए हैं: इमेजबाइंड (बहु-आयामी डेटा इंडेक्सिंग), DINOv2 (कंप्यूटर विज़न) और सेगमेंट एनीथिंग। उत्तरार्द्ध छवियों में अद्वितीय वस्तुओं की पहचान करता है और अत्यधिक अनुमेय अपाचे लाइसेंस के तहत जारी किया जाता है।
अंतत: हमें एक आंतरिक Google दस्तावेज़ "वी हैव नो मोट, एंड न ही डूज़ ओपनएआई" के कथित रूप से लीक होने का पता चला, जो बंद मॉडल बनाम बहुत छोटे, सस्ते मॉडल बनाने वाले समुदायों के नवाचार के बारे में एक मंद दृष्टिकोण रखता है जो इसके करीब या उससे बेहतर प्रदर्शन करते हैं। उनके बंद स्रोत समकक्ष। मैं ऐसा कथित तौर पर इसलिए कह रहा हूं क्योंकि लेख के स्रोत को Google के आंतरिक होने के रूप में सत्यापित करने का कोई तरीका नहीं है। हालाँकि, इसमें यह सम्मोहक ग्राफ शामिल है:
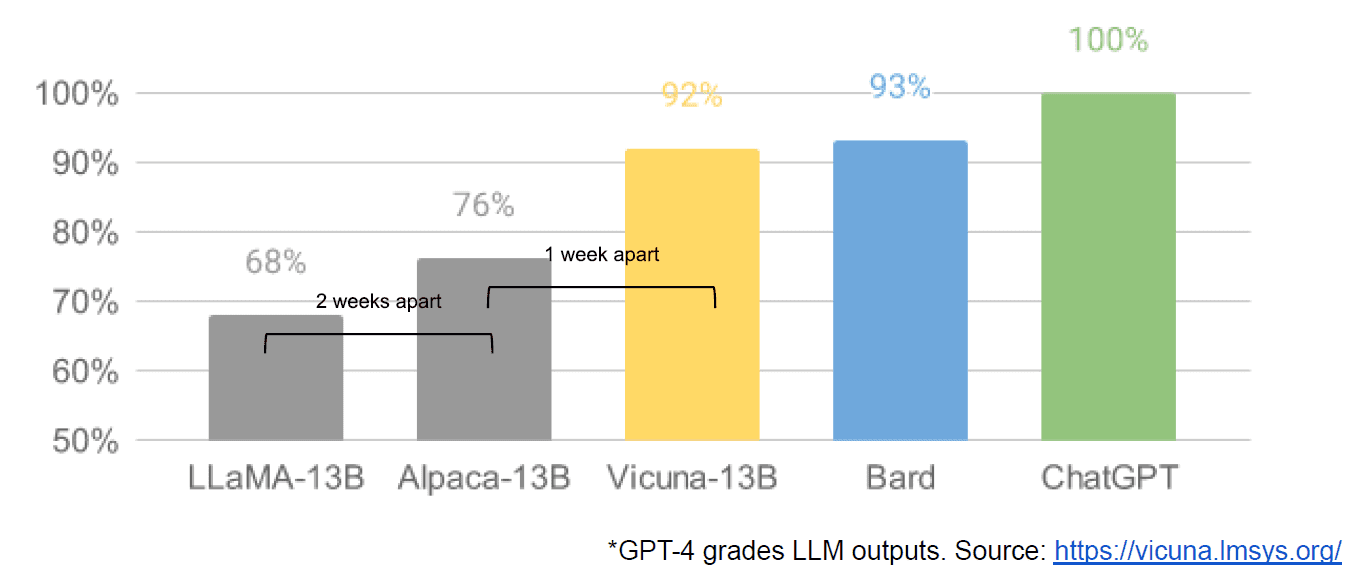
स्पष्ट होने के लिए, ऊर्ध्वाधर अक्ष GPT-4 द्वारा एलएलएम आउटपुट की ग्रेडिंग है।
स्टेबल डिफ्यूजन, जो पाठ से छवियों को संश्लेषित करता है, एक और उदाहरण है जहां ओपन सोर्स जेनरेटर एआई मालिकाना मॉडल की तुलना में तेजी से आगे बढ़ने में सक्षम है। उस प्रोजेक्ट (कंट्रोलनेट) के हालिया पुनरावृत्ति ने इसमें ऐसा सुधार किया है कि यह Dall-E2 की क्षमताओं से आगे निकल गया है। यह दुनिया भर में बहुत सारे बदलावों के परिणामस्वरूप हुआ, जिसके परिणामस्वरूप प्रगति की ऐसी गति आई जिसका मुकाबला करना किसी एक संस्थान के लिए कठिन है। उनमें से कुछ टिंकरर्स ने यह पता लगाया कि कैसे सस्ते हार्डवेयर पर प्रशिक्षित और चलाने के लिए स्थिर प्रसार को तेज़ बनाया जाए, जिससे अधिक लोगों द्वारा छोटे पुनरावृत्ति चक्र को सक्षम किया जा सके।
और इसलिए हम पूर्ण चक्र में आ गए हैं। बहुत अधिक पैसा और बहुत अधिक उपकरण न होने के कारण सामान्य लोगों के एक पूरे समुदाय ने नवाचार के एक चतुर स्तर को प्रेरित किया है। एआई डेवलपर बनने का क्या समय है।
मैथ्यू लॉज डिफ़ब्लू के सीईओ हैं, जो एक AI फ़ॉर कोड स्टार्टअप है। उनके पास एनाकोंडा और वीएमवेयर जैसी कंपनियों में उत्पाद नेतृत्व में 25+ वर्षों का विविध अनुभव है। लॉज वर्तमान में गुड लॉ प्रोजेक्ट के बोर्ड में कार्यरत है और रॉयल फोटोग्राफिक सोसाइटी के न्यासी बोर्ड का उपाध्यक्ष है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 9
- a
- योग्य
- About
- अकादमी
- पहुँच
- एडोब
- उन्नत
- एग्रीगेटर
- AI
- सब
- ने आरोप लगाया
- कथित तौर पर
- भी
- वीरांगना
- an
- और
- अन्य
- कोई
- किसी
- कुछ भी
- अपाचे
- एपीआई
- हैं
- तर्क
- लेख
- AS
- ग्रहण
- At
- लेखक
- लेखकों
- उपलब्ध
- अक्ष
- BE
- क्योंकि
- किया गया
- जा रहा है
- लाभ
- BEST
- बेहतर
- बड़ा
- BitTorrent
- मंडल
- के छात्रों
- बजट
- निर्माण
- इमारत
- गुच्छा
- व्यापार
- व्यापार मॉडल
- लेकिन
- by
- आया
- कर सकते हैं
- क्षमताओं
- राजधानी
- मामला
- मुख्य कार्यपालक अधिकारी
- कुर्सी
- चुनौती
- परिवर्तन
- ChatGPT
- सस्ता
- चुना
- चक्र
- दावा
- स्पष्ट
- समापन
- बंद
- बादल
- क्लाउड सेवाएं
- कोड
- कैसे
- आता है
- वस्तु
- समुदाय
- समुदाय
- कंपनियों
- सम्मोहक
- प्रतिस्पर्धा
- प्रतिस्पर्धा
- गणना करना
- कंप्यूटर
- Computer Vision
- सामग्री
- योगदानकर्ताओं
- नकल
- Copyright
- लागत
- सका
- कोर्ट
- बनाना
- बनाना
- रचनाकारों
- क्रिप्टोकरंसी
- वर्तमान में
- चक्र
- तिथि
- पहुंचाने
- डिप्टी
- डिजाइन
- डेवलपर
- विकास
- Умереть
- विभिन्न
- मुश्किल
- प्रसार
- अलग
- कई
- do
- दस्तावेज़
- कर देता है
- dont
- e
- आर्थिक
- प्रभावी
- समर्थकारी
- समाप्त
- संपूर्ण
- महाकाव्य
- उपकरण
- अनिवार्य
- अनुमानित
- और भी
- उदाहरण
- उम्मीद
- महंगा
- अनुभव
- दूर
- और तेज
- लगा
- बहता हुआ
- पीछा किया
- के लिए
- पायाब
- मुक्त
- से
- पूर्ण
- मूलरूप में
- निधिकरण
- गियर
- सामान्य जानकारी
- उत्पादक
- जनरेटिव एआई
- अच्छा
- गूगल
- GPU
- ग्राफ
- महान
- था
- कठिन
- हार्डवेयर
- है
- होने
- he
- यहाँ उत्पन्न करें
- हाई
- अत्यधिक
- धारकों
- कैसे
- How To
- तथापि
- HTTPS
- विशाल
- प्रचार
- i
- पहचानती
- if
- छवियों
- महत्वपूर्ण
- में सुधार
- उन्नत
- in
- प्रोत्साहन राशि
- व्यक्ति
- नवोन्मेष
- निवेश
- पागल
- प्रेरित
- बजाय
- संस्था
- एकीकरण
- दिलचस्प
- आंतरिक
- इंटरनेट
- आविष्कार
- IP
- व्यंग्य
- IT
- यात्रा
- आईटी इस
- केवल
- केडनगेट्स
- जानना
- अवतरण
- ताज़ा
- कानून
- परत
- नेतृत्व
- सीखा
- बाएं
- कम
- स्तर
- लाइसेंस
- लाइसेंस - प्राप्त
- लाइसेंसिंग
- पसंद
- पंक्तियां
- LINK
- लिंक्डइन
- थोड़ा
- लामा
- लंबा
- देखा
- देख
- खोना
- बंद
- लॉट
- प्रमुख
- बनाना
- निर्माण
- बहुत
- बाजार
- विशाल
- मैच
- मई..
- मीडिया
- मेटा
- माइक्रोसॉफ्ट
- आदर्श
- मॉडल
- धातु के सिक्के बनाना
- धन
- अधिक
- अधिकांश
- बहुत
- आवश्यकता
- न
- नहीं
- गैर वाणिज्यिक
- अभी
- वस्तु
- वस्तुओं
- of
- on
- ONE
- केवल
- खुला
- खुला स्रोत
- ओपन सोर्स प्रोजेक्ट्स
- OpenAI
- or
- साधारण
- मौलिक रूप से
- अन्य
- आउट
- उत्पादन
- के ऊपर
- अपना
- शांति
- प्राचल
- अतीत
- वेतन
- स्टाफ़
- निष्पादन
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- बिन्दु
- संभावनाओं
- बिजली
- मुसीबत
- एस्ट्रो मॉल
- उत्पाद
- परियोजना
- परियोजनाओं
- मालिकाना
- संभावना
- उठाना
- उठाया
- बल्कि
- वास्तव में
- हाल
- रिहा
- प्रतिनिधित्व
- अनुसंधान
- शोधकर्ताओं
- उपयुक्त संसाधन चुनें
- बंधन
- जिसके परिणामस्वरूप
- अधिकार
- राउंड
- शाही
- रन
- s
- सुरक्षित
- वही
- कहना
- देखा
- खंड
- बेचना
- अलग
- कई
- श्रृंखला ए
- कार्य करता है
- सेवाएँ
- सेट
- कमी
- दिखाना
- के बाद से
- एक
- आकार
- छोटे
- स्मार्ट
- So
- सोशल मीडिया
- सोशल मीडिया
- समाज
- सॉफ्टवेयर
- कुछ
- कुछ
- स्रोत
- स्रोत कोड
- बिताना
- स्थिर
- स्टैनफोर्ड
- स्टार्ट-अप
- स्टार्टअप
- स्ट्रेटेजी
- ऐसा
- सुझाव
- माना
- पार
- लेना
- लिया
- लेता है
- टेक्नोलॉजी
- से
- कि
- RSI
- स्रोत
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- वे
- बात
- सोचना
- तीसरा
- इसका
- उन
- तीन
- पहर
- सेवा मेरे
- भी
- ले गया
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- मोड़
- बदल जाता है
- के अंतर्गत
- समझता है
- अद्वितीय
- भिन्न
- जब तक
- us
- उपयोग
- प्रयुक्त
- का उपयोग करता है
- का उपयोग
- वैल्यूएशन
- मूल्य
- सत्यापित
- संस्करण
- ऊर्ध्वाधर
- बहुत
- के माध्यम से
- देखें
- दृष्टि
- vmware
- vs
- प्रतीक्षा
- करना चाहते हैं
- था
- मार्ग..
- we
- चला गया
- थे
- क्या
- कब
- कौन कौन से
- कौन
- पूरा का पूरा
- किसका
- मर्जी
- वार
- साथ में
- काम
- विश्व
- गलत
- इसलिए आप
- जेफिरनेट









