संपादक द्वारा छवि
यह 2023 है, जिसका अर्थ है कि अधिकांश उद्योगों में अधिकांश व्यवसाय बड़े डेटा की मदद से अंतर्दृष्टि एकत्र कर रहे हैं और बेहतर निर्णय ले रहे हैं। इन दिनों यह कोई आश्चर्य की बात नहीं है - जब बात आती है तो डेटा के बड़े सेट को इकट्ठा करने, वर्गीकृत करने और विश्लेषण करने की क्षमता बेहद उपयोगी होती है। डेटा-संचालित व्यावसायिक निर्णय लेना.
और, जैसे-जैसे संगठनों की बढ़ती संख्या डिजिटलीकरण को अपना रही है, डेटा एनालिटिक्स की उपयोगिता को समझने और उस पर भरोसा करने की क्षमता बढ़ती रहेगी।
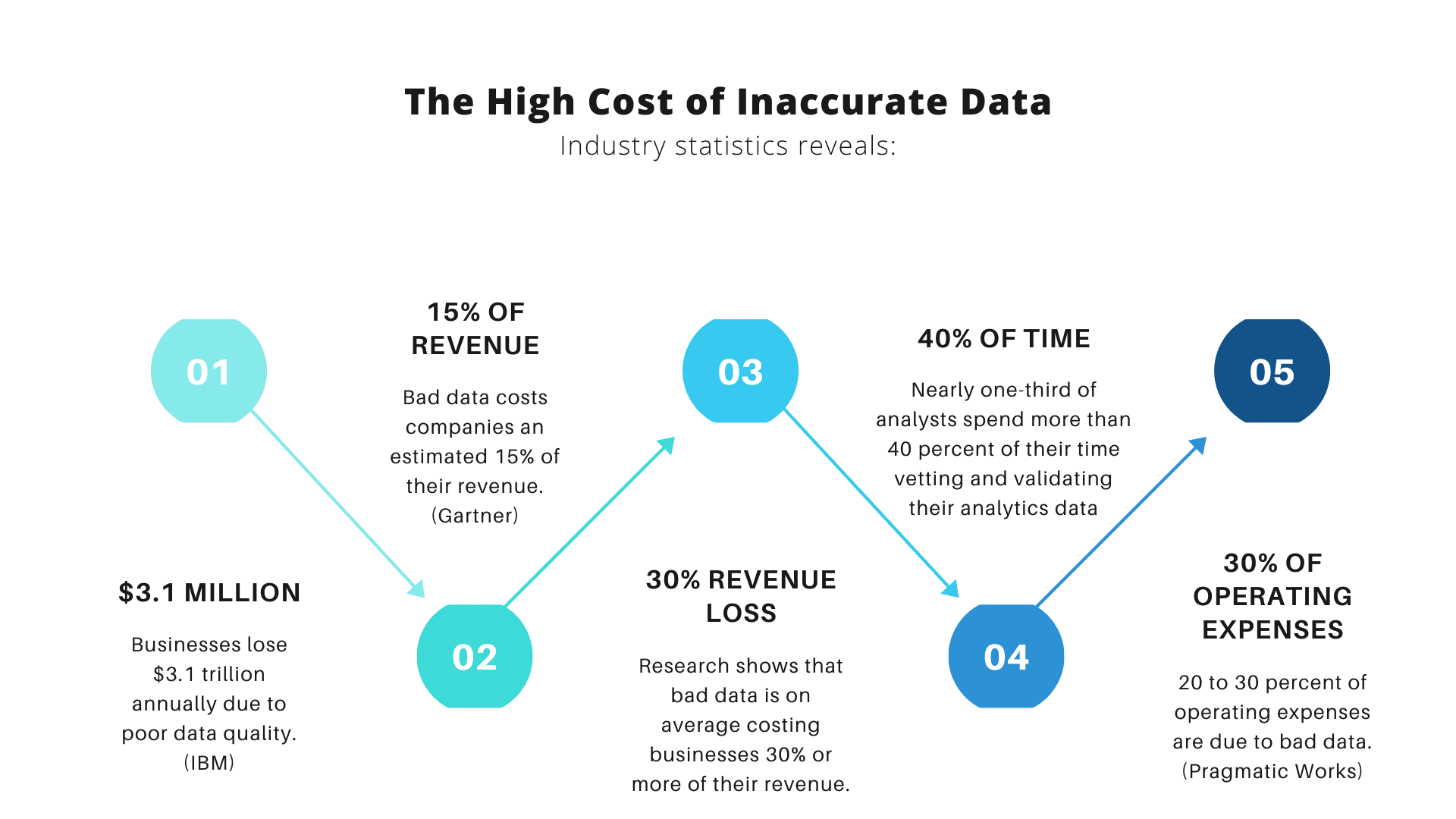
हालाँकि, यहाँ बड़े डेटा के बारे में बात है: जैसे-जैसे अधिक संगठन इस पर भरोसा करने लगते हैं, उतनी ही बड़ी संभावना बन जाती है कि उनमें से अधिक बड़े डेटा का गलत तरीके से उपयोग करेंगे। क्यों? क्योंकि बड़ा डेटा और उसके द्वारा प्रदान की जाने वाली अंतर्दृष्टि केवल तभी उपयोगी होती है जब संगठन अपने डेटा का सटीक विश्लेषण कर रहे हों।
से छवि डेटालाडर
अंत में, आइए सुनिश्चित करें कि आप कुछ सामान्य गलतियों से बच रहे हैं जो अक्सर डेटा विश्लेषण की सटीकता को प्रभावित करती हैं। इन मुद्दों के बारे में और आप इनसे कैसे बच सकते हैं, यह जानने के लिए आगे पढ़ें।
इससे पहले कि हम उंगलियां उठाएं, हमें यह स्वीकार करना होगा कि डेटा के अधिकांश सेटों में त्रुटियों की उचित हिस्सेदारी होती है, और जब डेटा का विश्लेषण करने का समय आता है तो ये त्रुटियां किसी का भी भला नहीं करती हैं। चाहे वे टाइपो त्रुटियाँ हों, अजीब नामकरण परंपराएँ हों, या अतिरेक हों, डेटा सेट में त्रुटियाँ डेटा विश्लेषण की सटीकता को बाधित करती हैं।
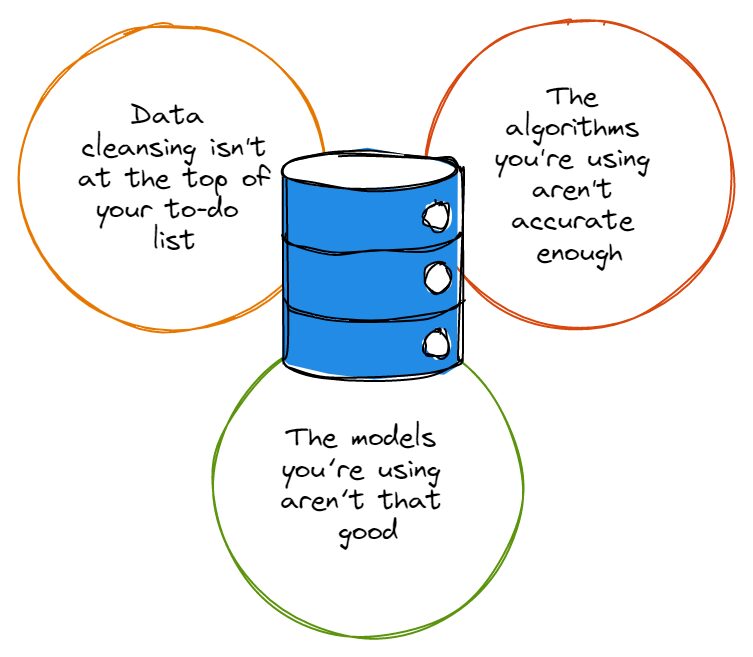
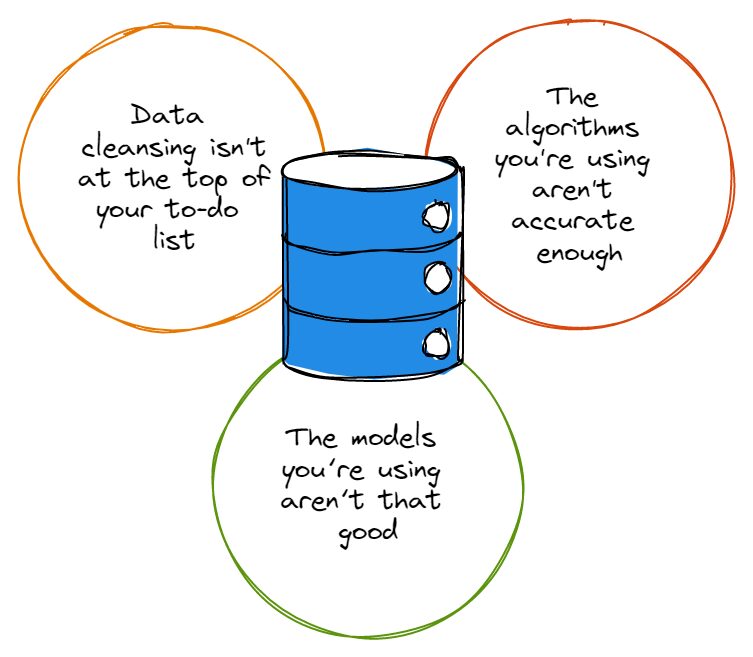
तो इससे पहले कि आप गहराई तक गोता लगाने के बारे में बहुत उत्साहित हों डेटा एनालिटिक्स खरगोश छेद में, आपको सबसे पहले यह सुनिश्चित करना होगा कि डेटा सफ़ाई आपकी कार्य सूची में सबसे ऊपर है और आप हमेशा अपने डेटा सेट को ठीक से साफ़ कर रहे हैं। आप शायद कह रहे होंगे, "अरे, डेटा सफ़ाई में मेरे लिए बहुत समय लगता है", जिस पर हम सहानुभूति में अपना सिर हिलाते हैं।
सौभाग्य से, आप संवर्धित विश्लेषण जैसे समाधानों में निवेश कर सकते हैं। यह आपके डेटा विश्लेषण करने की दर को तेज करने के लिए मशीन लर्निंग एल्गोरिदम का लाभ उठाता है (और यह आपके विश्लेषण की सटीकता में भी सुधार करता है)।
निचली पंक्ति: इससे कोई फर्क नहीं पड़ता कि आप अपने डेटा सफ़ाई को स्वचालित और बेहतर बनाने के लिए किस समाधान का उपयोग करते हैं, आपको अभी भी वास्तविक सफ़ाई करने की ज़रूरत है - यदि आप ऐसा नहीं करते हैं, तो आपके पास सटीक डेटा विश्लेषण को आधार बनाने के लिए उचित आधार कभी नहीं होगा।
जैसा कि डेटा सेट के मामले में होता है, अधिकांश एल्गोरिदम सौ प्रतिशत सही नहीं होते हैं; उनमें से अधिकांश में उचित मात्रा में खामियाँ होती हैं और हर बार जब आप उनका उपयोग करते हैं तो वे उस तरह से काम नहीं करते जैसा आप चाहते हैं। ढेर सारी खामियों वाले एल्गोरिदम आपके विश्लेषण के लिए आवश्यक डेटा को भी अनदेखा कर सकते हैं, या वे गलत प्रकार के डेटा पर ध्यान केंद्रित कर सकते हैं जो वास्तव में उतना महत्वपूर्ण नहीं है।
यह कोई रहस्य नहीं है कि टेक क्षेत्र में सबसे बड़े नाम हैं अपने एल्गोरिदम की लगातार जांच कर रहे हैं और उन्हें यथासंभव पूर्णता के करीब बदलना, और ऐसा इसलिए है क्योंकि बहुत कम एल्गोरिदम वास्तव में दोषरहित हैं। आपका एल्गोरिदम जितना अधिक सटीक होगा, इसकी गारंटी उतनी ही अधिक होगी कि आपके प्रोग्राम अपने लक्ष्यों को पूरा कर रहे हैं और वही कर रहे हैं जो आप उनसे कराना चाहते हैं।
इसके अतिरिक्त, यदि आपके संगठन में कुछ डेटा वैज्ञानिक भी कार्यरत हैं, तो उसे यह सुनिश्चित करना चाहिए कि वे डेटा वैज्ञानिक नियमित रूप से अपने डेटा विश्लेषण कार्यक्रमों के एल्गोरिदम को अपडेट कर रहे हैं - एक शेड्यूल स्थापित करना भी सार्थक हो सकता है जो टीमों को बनाए रखने के लिए जिम्मेदार रखता है और एक सहमत कार्यक्रम का पालन करते हुए अपने डेटा विश्लेषण एल्गोरिदम को अपडेट कर रहे हैं।
इससे भी बेहतर एक रणनीति स्थापित करना हो सकता है एआई/एमएल-आधारित एल्गोरिदम का लाभ उठाता है, जो स्वचालित रूप से खुद को अपडेट करने में सक्षम होना चाहिए।
अधिकतर समझने योग्य बात यह है कि, बहुत सारे बिजनेस लीडर जो अपनी डेटा एनालिटिक्स टीमों से सीधे तौर पर जुड़े नहीं हैं, उन्हें इस बात का एहसास नहीं है कि एल्गोरिदम और मॉडल समान चीज़ें नहीं हैं. यदि आप नहीं जानते हैं, तो याद रखें कि एल्गोरिदम वे तरीके हैं जिनका उपयोग हम डेटा का विश्लेषण करने के लिए करते हैं; मॉडल वे संगणनाएँ हैं जो किसी एल्गोरिथम के आउटपुट का लाभ उठाकर बनाई जाती हैं।
एल्गोरिदम पूरे दिन डेटा को क्रंच कर सकता है, लेकिन यदि उनका आउटपुट उन मॉडलों के माध्यम से नहीं जा रहा है जो बाद के विश्लेषण की जांच करने के लिए डिज़ाइन किए गए हैं, तो आपके पास कोई उपयोगी या उपयोगी अंतर्दृष्टि नहीं होगी।
इसे इस तरह से सोचें: यदि आपके पास डेटा क्रंच करने के लिए फैंसी एल्गोरिदम हैं, लेकिन आपके पास दिखाने के लिए कोई अंतर्दृष्टि नहीं है, तो आप उन एल्गोरिदम से पहले की तुलना में डेटा-संचालित निर्णय लेने में सक्षम नहीं होंगे; यह ऐसा होगा जैसे आप अपने उत्पाद रोडमैप में उपयोगकर्ता अनुसंधान का निर्माण करना चाहते हैं लेकिन इस तथ्य को नजरअंदाज कर रहे हैं कि, उदाहरण के लिए, बाजार अनुसंधान उद्योग $ 76.4 बिलियन उत्पन्न किया 2021 में राजस्व में, 100 के बाद से 2008% वृद्धि का प्रतिनिधित्व करता है।
आपके इरादे सराहनीय हो सकते हैं, लेकिन आपको उन अंतर्दृष्टियों को इकट्ठा करने या अपनी क्षमताओं के सर्वोत्तम तरीके से अपने रोडमैप में उपयोगकर्ता अनुसंधान का निर्माण करने के लिए आपके पास उपलब्ध आधुनिक उपकरणों और ज्ञान का उपयोग करने की आवश्यकता है।
यह दुर्भाग्यपूर्ण है कि उप-इष्टतम मॉडल आपके एल्गोरिदम के आउटपुट में गड़बड़ी करने का एक निश्चित तरीका है, चाहे वे एल्गोरिदम कितने भी परिष्कृत क्यों न हों। इसलिए यह आवश्यक है कि व्यावसायिक अधिकारी और तकनीकी नेता ऐसे मॉडल बनाने के लिए अपने डेटा विश्लेषण विशेषज्ञों को अधिक निकटता से शामिल करें जो न तो बहुत जटिल हों और न ही बहुत सरल हों।
और, इस पर निर्भर करते हुए कि वे कितने डेटा के साथ काम कर रहे हैं, बिजनेस लीडर कुछ अलग-अलग मॉडलों से गुजरना चुन सकते हैं, इससे पहले कि वे उस मॉडल पर निर्णय लें जो उनके लिए आवश्यक डेटा की मात्रा और प्रकार के लिए सबसे उपयुक्त हो।
दिन के अंत में, यदि आप यह सुनिश्चित करना चाहते हैं कि आपका डेटा विश्लेषण लगातार गलत नहीं है, तो आपको यह भी याद रखना होगा कभी भी पूर्वाग्रह का शिकार न बनें. जब डेटा एनालिटिक्स की सटीकता बनाए रखने की बात आती है तो पूर्वाग्रह दुर्भाग्य से सबसे बड़ी बाधाओं में से एक है जिसे दूर करने की आवश्यकता है।
चाहे वे एकत्र किए जा रहे डेटा के प्रकार को प्रभावित कर रहे हों या व्यवसायिक नेताओं द्वारा डेटा की व्याख्या करने के तरीके को प्रभावित कर रहे हों, पूर्वाग्रह विविध होते हैं और अक्सर उन्हें पहचानना मुश्किल होता है - अधिकारियों को लगातार लाभ पाने के लिए अपने पूर्वाग्रहों को पहचानने और उन्हें त्यागने के लिए अपना सर्वश्रेष्ठ प्रयास करने की आवश्यकता होती है। सटीक डेटा विश्लेषण.
डेटा शक्तिशाली है: जब सही तरीके से उपयोग किया जाता है, तो यह व्यापारिक नेताओं और उनके संगठनों को बेहद उपयोगी अंतर्दृष्टि प्रदान कर सकता है जो उनके उत्पादों को विकसित करने और अपने ग्राहकों तक पहुंचाने के तरीके को बदल सकता है। बस यह सुनिश्चित करें कि आप यह सुनिश्चित करने के लिए अपनी शक्ति में सब कुछ कर रहे हैं कि आपका डेटा विश्लेषण सटीक है और इस लेख में हमारे द्वारा बताई गई आसानी से टाली जा सकने वाली गलतियों से पीड़ित नहीं हैं।
नहाला डेविस एक सॉफ्टवेयर डेवलपर और तकनीकी लेखक हैं। तकनीकी लेखन के लिए अपना पूरा समय समर्पित करने से पहले, वह - अन्य दिलचस्प चीजों के साथ - एक इंक 5,000 अनुभवात्मक ब्रांडिंग संगठन में एक प्रमुख प्रोग्रामर के रूप में काम करने में कामयाब रही, जिसके ग्राहकों में सैमसंग, टाइम वार्नर, नेटफ्लिक्स और सोनी शामिल हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोब्लॉकचैन। Web3 मेटावर्स इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/03/3-mistakes-could-affecting-accuracy-data-analytics.html?utm_source=rss&utm_medium=rss&utm_campaign=3-mistakes-that-could-be-affecting-the-accuracy-of-your-data-analytics
- :है
- 000
- 2021
- 2023
- a
- क्षमताओं
- क्षमता
- योग्य
- About
- में तेजी लाने के
- पूरा
- शुद्धता
- सही
- सही रूप में
- वास्तव में
- प्रशंसनीय
- स्वीकार करना
- को प्रभावित
- प्रभावित करने वाले
- कलन विधि
- एल्गोरिदम
- सब
- हमेशा
- के बीच में
- विश्लेषण
- विश्लेषिकी
- विश्लेषण करें
- का विश्लेषण
- और
- किसी
- हैं
- लेख
- AS
- At
- संवर्धित
- को स्वचालित रूप से
- स्वतः
- उपलब्ध
- से बचने
- आधार
- BE
- क्योंकि
- हो जाता है
- से पहले
- जा रहा है
- लाभ
- BEST
- बेहतर
- पूर्वाग्रह
- बड़ा
- बड़ा डेटा
- बड़ा
- सबसे बड़ा
- तल
- ब्रांडिंग
- निर्माण
- गुच्छा
- व्यापार
- व्यवसायों
- by
- कर सकते हैं
- मामला
- संयोग
- चेक
- चुनें
- ग्राहकों
- समापन
- निकट से
- Codecademy
- एकत्रित
- कैसे
- सामान्य
- जटिल
- संगणना
- जारी रखने के
- कन्वेंशनों
- सका
- युगल
- बनाना
- बनाया
- संकट
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा विश्लेषण
- डेटा सेट
- डेटा पर ही आधारित
- दिन
- दिन
- निर्णय
- गहरा
- उद्धार
- निर्भर करता है
- बनाया गया
- विकसित करना
- डेवलपर
- विभिन्न
- मुश्किल
- डिजिटलीकरण
- सीधे
- कर
- नीचे
- ड्राइविंग
- आसानी
- भी
- आलिंगन
- लगाना
- लगे हुए
- सुनिश्चित
- त्रुटियाँ
- आवश्यक
- स्थापित करना
- स्थापना
- और भी
- प्रत्येक
- सब कुछ
- उदाहरण
- उत्तेजित
- एक्जीक्यूटिव
- अनुभवात्मक
- विशेषज्ञों
- निष्पक्ष
- गिरना
- एहसान
- कुछ
- प्रथम
- खामियां
- फोकस
- निम्नलिखित
- के लिए
- बुनियाद
- से
- पूर्ण
- मिल
- Go
- लक्ष्यों
- जा
- अनुदान
- मुट्ठी
- अधिक से अधिक
- अधिकतम
- आगे बढ़ें
- बढ़ रहा है
- गारंटी
- संभालना
- है
- सिर
- मदद
- रखती है
- कैसे
- एचटीएमएल
- http
- HTTPS
- टट्टी कुदने की घुड़ौड़
- पहचान करना
- बेहद
- महत्वपूर्ण
- में सुधार
- सुधार
- in
- इंक
- शामिल
- गलत रूप से
- बढ़ना
- उद्योगों
- उद्योग
- को प्रभावित
- अंतर्दृष्टि
- इरादे
- निवेश करना
- मुद्दों
- IT
- जेपीजी
- केडनगेट्स
- बच्चा
- ज्ञान
- नेतृत्व
- नेताओं
- जानें
- सीख रहा हूँ
- leverages
- लाभ
- पसंद
- लाइन
- सूची
- लंबा
- लॉट
- मशीन
- यंत्र अधिगम
- बनाना
- निर्माण
- कामयाब
- बाजार
- बाजार अनुसंधान
- बात
- साधन
- तरीकों
- गलतियां
- मॉडल
- आधुनिक
- अधिक
- अधिकांश
- नामों
- नामकरण
- आवश्यकता
- न
- नेटफ्लिक्स
- संख्या
- of
- ऑफर
- on
- ONE
- आदेश
- संगठन
- संगठनों
- अन्य
- उल्लिखित
- उत्पादन
- काबू
- प्रतिशत
- उत्तम
- निष्पादन
- प्यूरिसर्च
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- संभव
- बिजली
- शक्तिशाली
- एस्ट्रो मॉल
- उत्पाद
- प्रोग्रामर
- प्रोग्राम्स
- उचित
- अच्छी तरह
- खरगोश
- मूल्यांकन करें
- RE
- पढ़ना
- महसूस करना
- नियमित तौर पर
- याद
- का प्रतिनिधित्व
- अनुसंधान
- राजस्व
- रोडमैप
- s
- वही
- सैमसंग
- अनुसूची
- वैज्ञानिकों
- गुप्त
- सेवा
- सेट
- बसना
- Share
- चाहिए
- दिखाना
- सरल
- केवल
- के बाद से
- होशियार
- So
- सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- कुछ
- सोनी
- परिष्कृत
- फिर भी
- स्ट्रेटेजी
- आगामी
- ऐसा
- पीड़ा
- आश्चर्य
- टीमों
- तकनीक
- तकनीकी
- कि
- RSI
- लेकिन हाल ही
- उन
- अपने
- इसलिये
- इन
- बात
- चीज़ें
- यहाँ
- पहर
- बहुत समय लगेगा
- सेवा मेरे
- भी
- उपकरण
- ऊपर का
- बदालना
- tweaking
- जाहिर है
- दुर्भाग्य
- अपडेट
- अपडेट
- अद्यतन
- प्रयोग करने योग्य
- उपयोग
- उपयोगकर्ता
- Ve
- शिकार
- आयतन
- चाहने
- वार्नर
- मार्ग..
- क्या
- या
- कौन कौन से
- कौन
- मर्जी
- साथ में
- काम
- काम कर रहे
- सार्थक
- लेखक
- लिख रहे हैं
- गलत
- आपका
- जेफिरनेट