आज की दुनिया में, ग्राहक बड़ी मात्रा में डेटा का प्रबंधन करते हैं अमेज़न सरल भंडारण सेवा (अमेज़ॅन एस3) डेटा लेक, जिसके लिए डेटा लेआउट में परिवर्तनों को लगातार समझने और उन्हें उपभोक्ता प्रणालियों के लिए उपलब्ध कराने के लिए जटिल डेटा पाइपलाइनों की आवश्यकता होती है। एडब्ल्यूएस गोंद क्रॉलर AWS ग्लू डेटा कैटलॉग में डेटा को सूचीबद्ध करने का एक सीधा तरीका प्रदान करते हैं जो स्कीमा प्रबंधन और डेटा वर्गीकरण की बात आने पर भारी भार को हटा देता है। AWS ग्लू क्रॉलर मेटाडेटा को चालू रखते हुए डेटा कैटलॉग को स्वचालित रूप से पॉप्युलेट करने के लिए अमेज़ॅन S3 से डेटा स्कीमा और विभाजन निकालते हैं।
लेकिन समय के साथ डेटा तेजी से बढ़ने के साथ, किसी तालिका में विभाजन की संख्या काफी बढ़ सकती है। क्योंकि एनालिटिक्स सेवाएं पसंद हैं अमेज़न एथेना लाखों विभाजनों वाली तालिका को क्वेरी करने पर, विभाजन को पुनः प्राप्त करने के लिए आवश्यक समय बढ़ जाता है और इससे क्वेरी रनटाइम भी बढ़ सकता है।
आज, विभाजित डेटासेट पर क्वेरी प्रोसेसिंग को अनुकूलित करने के लिए नई खोजी गई तालिकाओं के लिए विभाजन अनुक्रमणिका को स्वचालित रूप से जोड़ने के लिए AWS ग्लू क्रॉलर समर्थन का विस्तार किया गया है। अब, जब क्रॉलर क्रॉलर रन के दौरान एक नई डेटा कैटलॉग तालिका बनाता है, तो यह डिफ़ॉल्ट रूप से एक विभाजन सूचकांक भी बनाता है, जिसमें कुंजी के रूप में सभी संख्यात्मक और स्ट्रिंग प्रकार विभाजन कॉलम का सबसे बड़ा क्रमपरिवर्तन होता है। डेटा कैटलॉग फिर इन कुंजियों के आधार पर एक खोजने योग्य सूचकांक बनाता है, जिससे लाखों विभाजनों वाली तालिकाओं पर विभाजन मेटाडेटा को पुनर्प्राप्त करने और फ़िल्टर करने के लिए आवश्यक समय कम हो जाता है। विभाजन अनुक्रमणिका के निर्माण से एथेना पर चल रहे विश्लेषणात्मक कार्यभार को लाभ मिलता है, अमेज़ॅन ईएमआर, अमेज़न रेडशिफ्ट स्पेक्ट्रम, और AWS गोंद।
इस पोस्ट में, हम वर्णन करते हैं कि एडब्ल्यूएस ग्लू क्रॉलर के साथ विभाजन इंडेक्स कैसे बनाएं और एथेना से विभाजन इंडेक्स के साथ और उसके बिना क्रॉल किए गए डेटा तक पहुंचने पर क्वेरी प्रदर्शन में सुधार की तुलना करें।
समाधान अवलोकन
हम एक का उपयोग करें एडब्ल्यूएस CloudFormation हमारे समाधान संसाधन बनाने के लिए टेम्पलेट। निम्नलिखित चरणों में, हम प्रदर्शित करते हैं कि AWS ग्लू कंसोल या AWS ग्लू कंसोल का उपयोग करके विभाजन सूचकांक बनाने के लिए AWS ग्लू क्रॉलर को कैसे कॉन्फ़िगर किया जाए AWS कमांड लाइन इंटरफ़ेस (एडब्ल्यूएस सीएलआई)। फिर हम एथेना का उपयोग करके क्वेरी प्रदर्शन सुधारों की तुलना करते हैं।
.. पूर्वापेक्षाएँ
इस पोस्ट का अनुसरण करने के लिए, आपके पास एक तक पहुंच होनी चाहिए AWS पहचान और अभिगम प्रबंधन (IAM) AWS CloudFormation का उपयोग करके संसाधन बनाने के लिए प्रशासक की भूमिका।
अपने समाधान संसाधनों को सेट करें
CloudFormation टेम्पलेट निम्नलिखित संसाधन उत्पन्न करता है:
- आईएएम भूमिकाएं और नीतियां
- स्कीमा को होल्ड करने के लिए एक AWS ग्लू डेटाबेस
- एक AWS ग्लू क्रॉलर अत्यधिक विभाजित डेटासेट की ओर इशारा करता है
- क्वेरी परिणामों को संग्रहीत करने के लिए एक एथेना कार्यसमूह और बाल्टी
समाधान संसाधन स्थापित करने के लिए निम्नलिखित चरणों को पूरा करें:
- में प्रवेश करें एडब्ल्यूएस प्रबंधन कंसोल एक IAM प्रशासक के रूप में.
- चुनें स्टैक लॉन्च करें क्लाउडफॉर्मेशन टेम्पलेट को तैनात करने के लिए:

- के लिए डेटाबेस का नाम, डिफ़ॉल्ट रखें
blog_partition_index_crawlerdb.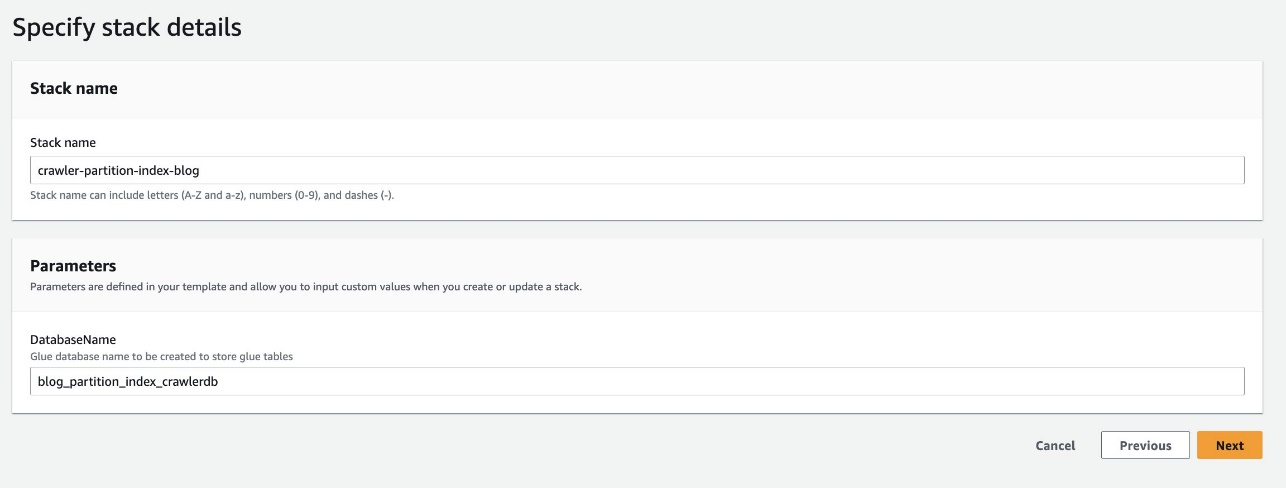
- चुनें अगला.
- अंतिम पृष्ठ पर विवरण की समीक्षा करें और चुनें मैं स्वीकार करता हूं कि AWS CloudFormation IAM संसाधन बना सकता है.
- चुनें स्टैक बनाएँ.
- जब स्टैक पूरा हो जाए, तो AWS CloudFormation कंसोल पर नेविगेट करें आउटपुट ढेर का टैब।
- के मान नोट करें
DatabaseNameऔरGlueCrawlerName.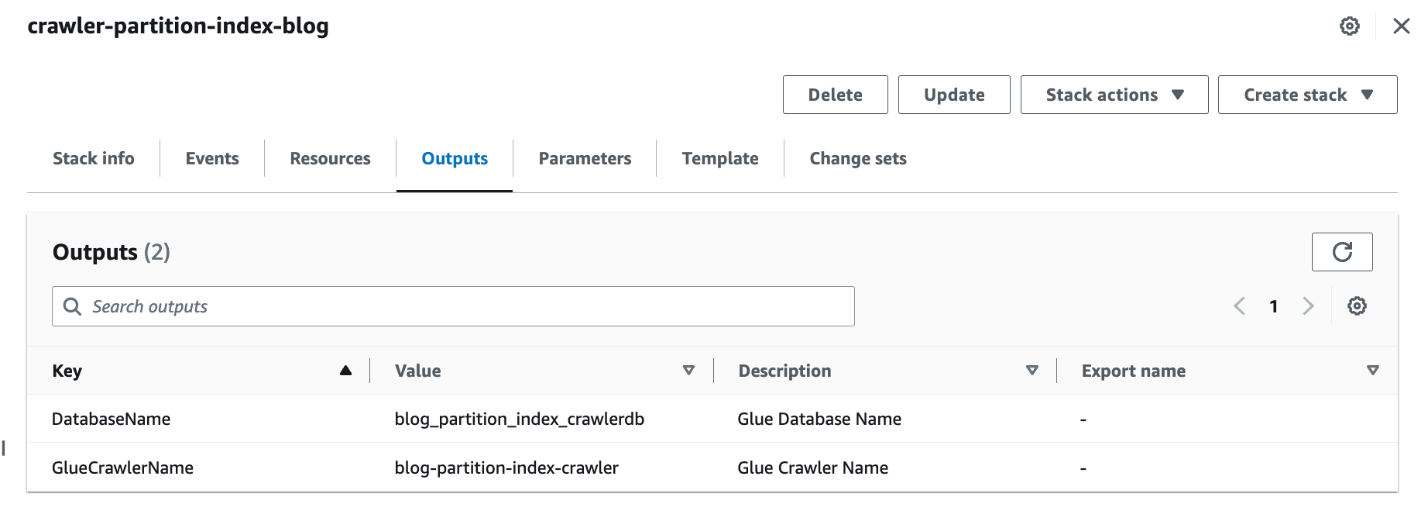
इस स्टैक द्वारा उपयोग किए जाने वाले कुछ संसाधनों पर उपयोग के दौरान लागत आती है।
एडब्ल्यूएस गोंद क्रॉलर को संपादित करें और चलाएं
एडब्ल्यूएस गोंद क्रॉलर को कॉन्फ़िगर करने और चलाने के लिए, निम्न चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर नेविगेशन फलक में
- पता लगाएँ
crawler blog-partition-index-crawlerऔर चुनें संपादित करें.
- में आउटपुट और शेड्यूलिंग सेट करें अनुभाग के तहत, उन्नत विकल्प, चुनते हैं स्वचालित रूप से विभाजन अनुक्रमणिका बनाएँ.
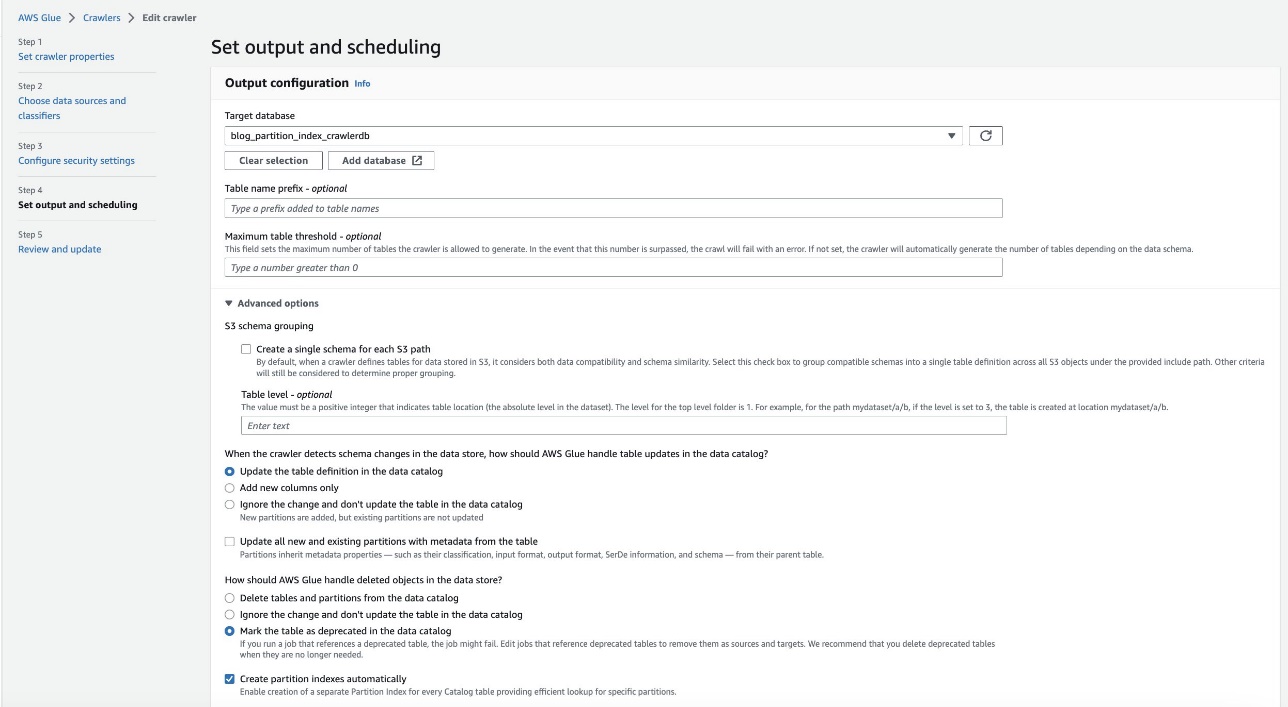
- क्रॉलर सेटिंग की समीक्षा करें और उसे अपडेट करें.
वैकल्पिक रूप से, आप AWS CLI (अपनी IAM भूमिका और क्षेत्र प्रदान करें) का उपयोग करके अपने क्रॉलर को कॉन्फ़िगर कर सकते हैं:
- अब क्रॉलर चलाएं और सत्यापित करें कि क्रॉलर रन पूरा हो गया है।
यह अत्यधिक विभाजित डेटासेट है और इसे पूरा होने में लगभग 90 मिनट लगेंगे।
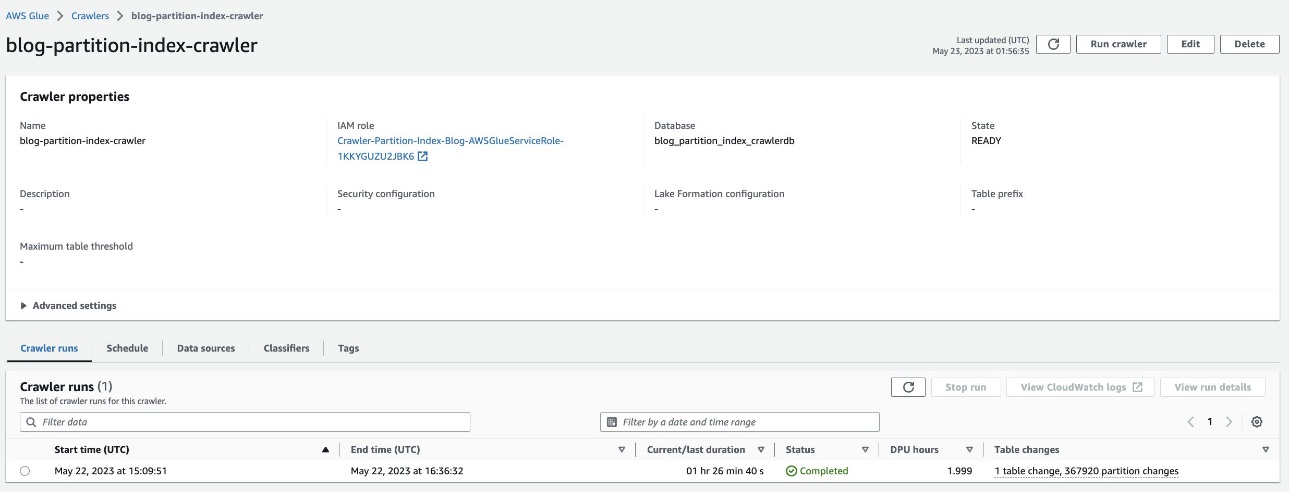
विभाजित तालिका को सत्यापित करें
एडब्ल्यूएस गोंद डेटाबेस में blog_partition_index_crawlerdb, सत्यापित करें कि तालिका highly_partitioned_table बनाया गया है।
डिफ़ॉल्ट रूप से, क्रॉलर विभाजन स्तंभों के समान क्रम में मान्य स्तंभ प्रकारों के विभाजन स्तंभों के सबसे बड़े क्रमपरिवर्तन के आधार पर एक सूचकांक निर्धारित करता है, जो या तो संख्यात्मक या स्ट्रिंग होते हैं। क्रॉलर द्वारा बनाई गई तालिका के लिए (highly_partitioned_table), हमारे पास विभाजन कॉलम हैं year (डोरी), month (डोरी), day (स्ट्रिंग), और hour (डोरी)।
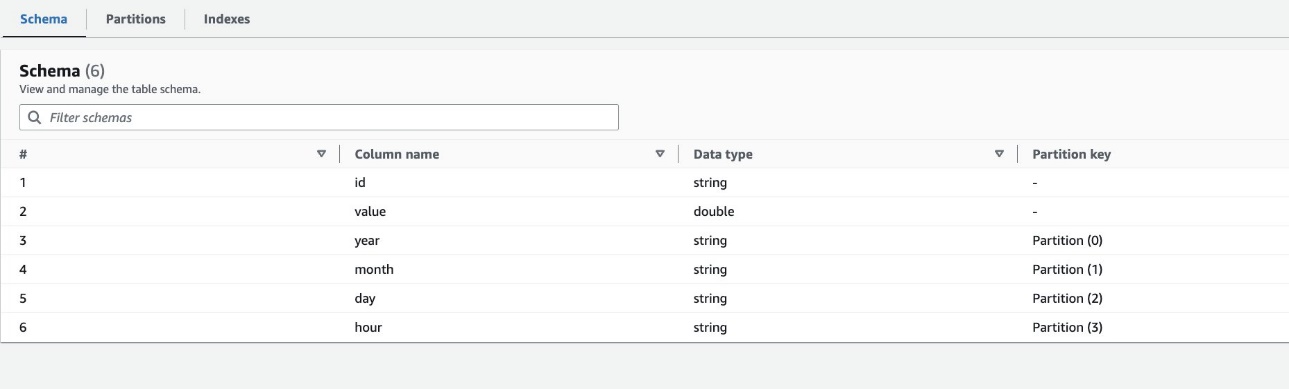
इस परिभाषा के आधार पर, क्रॉलर ने वर्ष, माह, दिन और घंटे के क्रमपरिवर्तन पर एक सूचकांक बनाया। क्रॉलर ने उपसर्ग वाले अनुक्रमणिकाएँ बनाईं crawler_ डिफ़ॉल्ट रूप से बनाए गए किसी भी विभाजन सूचकांक पर।
तालिका पर नेविगेट करके इसे सत्यापित करें highly_partitioned_table AWS ग्लू कंसोल पर और चुनें अनुक्रमित टैब.
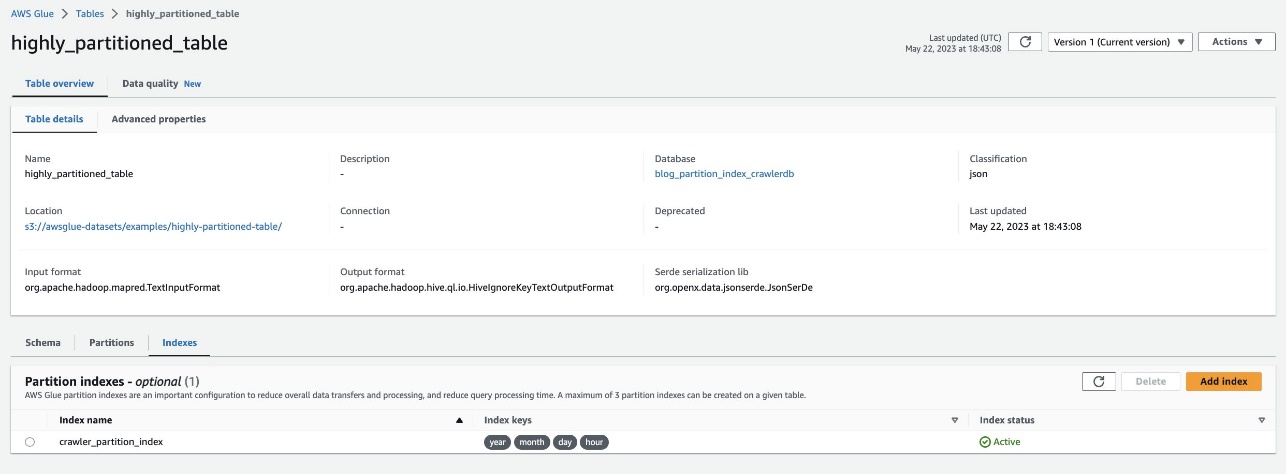
क्रॉलर S3 डेटा स्रोत को क्रॉल करने और तालिका के लिए विभाजन अनुक्रमणिका को सफलतापूर्वक पॉप्युलेट करने में सक्षम था।
एथेना का उपयोग करके क्वेरी प्रदर्शन सुधारों की तुलना करें
सबसे पहले, हम विभाजन सूचकांक का उपयोग किए बिना एथेना में तालिका को क्वेरी करते हैं। एथेना का उपयोग करके तालिकाओं को सत्यापित करने के लिए, निम्नलिखित चरणों को पूरा करें:
- एथेना कंसोल पर, चुनें
crawler-primary-workgroupएथेना कार्यसमूह के रूप में और चुनें स्वीकार करो.
- निम्नलिखित क्वेरी चलाएँ:
निम्नलिखित स्क्रीनशॉट से पता चलता है कि विभाजन सूचकांक का उपयोग करके फ़िल्टरिंग सक्षम किए बिना क्वेरी में लगभग 32 सेकंड लग गए।
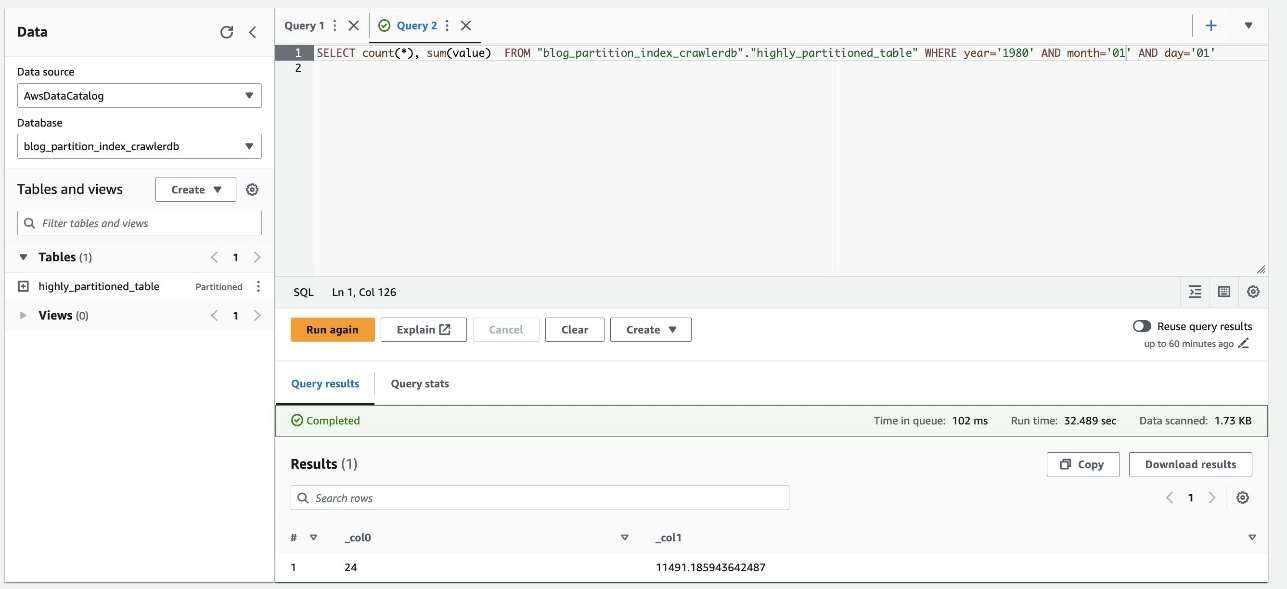
- अब हम एथेना क्वेरी पर विभाजन सूचकांक को सक्षम करते हैं:
- निम्नलिखित क्वेरी दोबारा चलाएँ और रनटाइम नोट करें:
निम्नलिखित स्क्रीनशॉट से पता चलता है कि क्वेरी में केवल 700 मिलीसेकंड लगे, जो कि विभाजन सूचकांक का उपयोग करके सक्षम फ़िल्टरिंग के साथ बहुत तेज़ है।
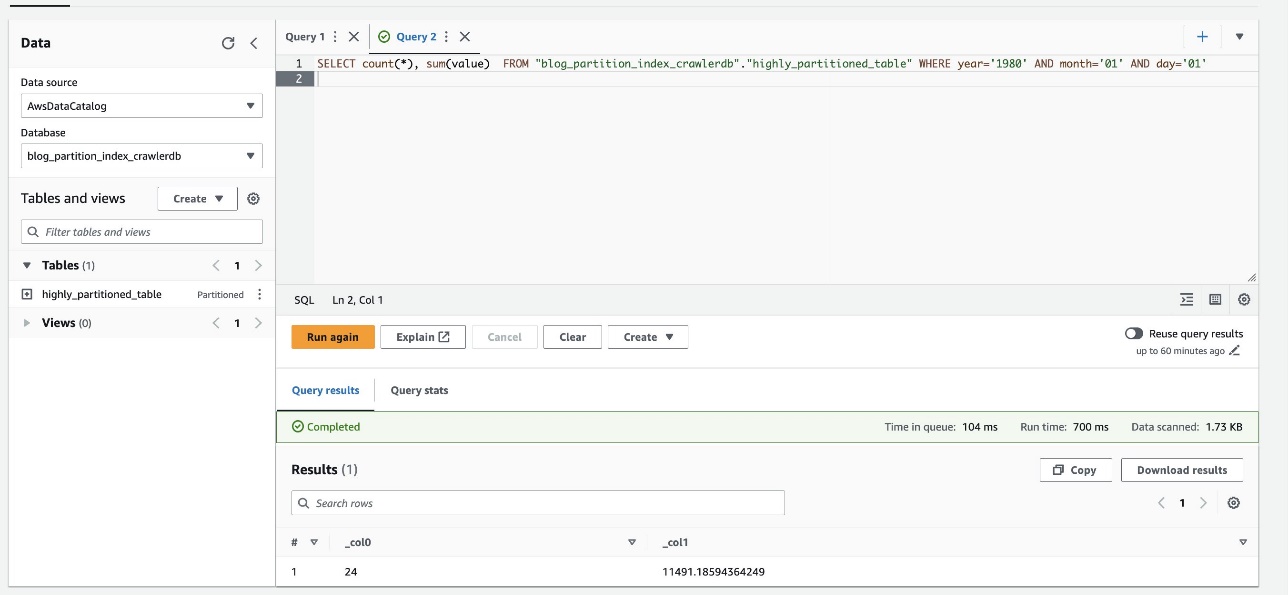
क्लीन अप
अपने AWS खाते में अवांछित शुल्क से बचने के लिए, आप AWS संसाधनों को हटा सकते हैं:
- CloudFormation कंसोल में साइन इन करें क्योंकि IAM व्यवस्थापक ने CloudFormation स्टैक बनाने के लिए उपयोग किया।
- आपके द्वारा बनाए गए क्लाउडफॉर्मेशन स्टैक को हटाएं।
निष्कर्ष
इस पोस्ट में, हमने बताया कि विभाजन इंडेक्स बनाने के लिए AWS क्रॉलर को कैसे कॉन्फ़िगर किया जाए और एथेना से इंडेक्स के साथ डेटा तक पहुंचते समय क्वेरी प्रदर्शन की तुलना की जाए।
यदि तालिका पर कोई विभाजन अनुक्रमणिका मौजूद नहीं है, तो AWS ग्लू तालिका के सभी विभाजनों को लोड करता है, और फिर लोड किए गए विभाजनों को फ़िल्टर करता है, जिसके परिणामस्वरूप मेटाडेटा की अक्षम पुनर्प्राप्ति होती है। रेडशिफ्ट स्पेक्ट्रम, अमेज़ॅन ईएमआर और एडब्ल्यूएस ग्लू ईटीएल स्पार्क डेटाफ्रेम जैसी एनालिटिक्स सेवाएं अब विभाजन लाने के लिए इंडेक्स का उपयोग कर सकती हैं, जिसके परिणामस्वरूप महत्वपूर्ण क्वेरी प्रदर्शन हो सकता है।
विभिन्न विश्लेषणात्मक इंजनों में विभाजन अनुक्रमणिका और क्वेरी प्रदर्शन पर अधिक जानकारी के लिए, देखें AWS ग्लू डेटा कैटलॉग विभाजन इंडेक्स का उपयोग करके अमेज़ॅन एथेना क्वेरी प्रदर्शन में सुधार करें और AWS ग्लू पार्टीशन इंडेक्स का उपयोग करके क्वेरी प्रदर्शन में सुधार करें.
इस क्रॉलर फीचर लॉन्च में योगदान देने वाले सभी लोगों को विशेष धन्यवाद: युहांग चेन, काइल डुओंग और मीता गावडे।
लेखक के बारे में
 श्रीविद्या पार्थसारथी AWS लेक फॉर्मेशन टीम में सीनियर बिग डेटा आर्किटेक्ट हैं। उन्हें डेटा मेश समाधान बनाने और उन्हें समुदाय के साथ साझा करने में आनंद आता है।
श्रीविद्या पार्थसारथी AWS लेक फॉर्मेशन टीम में सीनियर बिग डेटा आर्किटेक्ट हैं। उन्हें डेटा मेश समाधान बनाने और उन्हें समुदाय के साथ साझा करने में आनंद आता है।
 संदीप अडवांकर AWS में वरिष्ठ तकनीकी उत्पाद प्रबंधक हैं। कैलिफ़ोर्निया बे एरिया में स्थित, वह दुनिया भर के ग्राहकों के साथ व्यापार और तकनीकी आवश्यकताओं को उत्पादों में अनुवाद करने के लिए काम करता है जो ग्राहकों को यह सुधारने में सक्षम बनाता है कि वे डेटा को कैसे प्रबंधित, सुरक्षित और एक्सेस करते हैं।
संदीप अडवांकर AWS में वरिष्ठ तकनीकी उत्पाद प्रबंधक हैं। कैलिफ़ोर्निया बे एरिया में स्थित, वह दुनिया भर के ग्राहकों के साथ व्यापार और तकनीकी आवश्यकताओं को उत्पादों में अनुवाद करने के लिए काम करता है जो ग्राहकों को यह सुधारने में सक्षम बनाता है कि वे डेटा को कैसे प्रबंधित, सुरक्षित और एक्सेस करते हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- ईवीएम वित्त। विकेंद्रीकृत वित्त के लिए एकीकृत इंटरफ़ेस। यहां पहुंचें।
- क्वांटम मीडिया समूह। आईआर/पीआर प्रवर्धित। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :हैस
- :है
- :कहाँ
- $यूपी
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- योग्य
- पहुँच
- तक पहुँचने
- लेखा
- स्वीकार करना
- के पार
- जोड़ना
- व्यवस्थापक
- फिर
- सब
- साथ में
- भी
- वीरांगना
- अमेज़न एथेना
- अमेज़ॅन ईएमआर
- अमेज़ॅन वेब सेवा
- राशियाँ
- an
- विश्लेषणात्मक
- विश्लेषिकी
- और
- कोई
- लगभग
- हैं
- क्षेत्र
- चारों ओर
- AS
- At
- स्वतः
- उपलब्ध
- से बचने
- एडब्ल्यूएस
- एडब्ल्यूएस CloudFormation
- एडब्ल्यूएस गोंद
- AWS झील निर्माण
- आधारित
- खाड़ी
- क्योंकि
- किया गया
- लाभ
- बड़ा
- बड़ा डेटा
- इमारत
- व्यापार
- by
- कैलिफ़ोर्निया
- कर सकते हैं
- सूची
- कारण
- परिवर्तन
- प्रभार
- चेन
- चुनें
- चुनने
- वर्गीकरण
- स्तंभ
- स्तंभ
- आता है
- समुदाय
- तुलना
- तुलना
- पूरा
- कंसोल
- लगातार
- योगदान
- लागत
- क्रॉलर
- बनाना
- बनाया
- बनाता है
- बनाना
- निर्माण
- वर्तमान
- ग्राहक
- तिथि
- डेटा प्राप्त करना
- डेटा लेक
- डाटाबेस
- दिन
- चूक
- दिखाना
- तैनात
- तैनात
- वर्णन
- विवरण
- निर्धारित
- की खोज
- नीचे
- दौरान
- कुशलता
- भी
- सक्षम
- सक्षम
- इंजन
- ईथर (ईटीएच)
- हर कोई
- विस्तारित
- समझाया
- तेजी
- उद्धरण
- डेटा निकालें
- और तेज
- Feature
- फ़िल्टर
- छानने
- फ़िल्टर
- अंतिम
- का पालन करें
- निम्नलिखित
- के लिए
- निर्माण
- से
- उत्पन्न करता है
- दी
- ग्लोब
- आगे बढ़ें
- बढ़ रहा है
- है
- he
- mmmmm
- भार उठाना
- अत्यधिक
- पकड़
- घंटा
- कैसे
- How To
- एचटीएमएल
- http
- HTTPS
- आई ए एम
- पहचान
- में सुधार
- सुधार
- सुधार
- in
- बढ़ना
- बढ़ जाती है
- अनुक्रमणिका
- अनुक्रमणिका
- अप्रभावी
- करें-
- में
- IT
- जेपीजी
- रखना
- रखना
- Instagram पर
- झील
- सबसे बड़ा
- लांच
- ख़ाका
- उत्तोलक
- पसंद
- लाइन
- भार
- बनाना
- प्रबंधन
- प्रबंध
- प्रबंधक
- जाल
- मेटाडाटा
- हो सकता है
- लाखों
- मिनट
- महीना
- अधिक
- बहुत
- चाहिए
- नेविगेट करें
- नेविगेट
- पथ प्रदर्शन
- जरूरत
- नया
- नए नए
- नहीं
- अभी
- संख्या
- of
- on
- केवल
- ऑप्टिमाइज़ करें
- or
- आदेश
- हमारी
- उत्पादन
- के ऊपर
- पृष्ठ
- फलक
- पथ
- प्रदर्शन
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- पद
- वर्तमान
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पादन प्रबंधक
- उत्पाद
- प्रदान करना
- को कम करने
- क्षेत्र
- अपेक्षित
- आवश्यकताएँ
- की आवश्यकता होती है
- उपयुक्त संसाधन चुनें
- जिसके परिणामस्वरूप
- परिणाम
- भूमिका
- भूमिकाओं
- रन
- दौड़ना
- वही
- सेकंड
- अनुभाग
- सुरक्षित
- वरिष्ठ
- सेवाएँ
- सेट
- सेटिंग्स
- बांटने
- वह
- दिखाता है
- महत्वपूर्ण
- काफी
- सरल
- समाधान
- समाधान ढूंढे
- स्रोत
- स्पार्क
- स्पेक्ट्रम
- धुआँरा
- कदम
- भंडारण
- की दुकान
- सरल
- तार
- सफलतापूर्वक
- समर्थन
- सिस्टम
- तालिका
- लेना
- टीम
- तकनीकी
- टेम्पलेट
- धन्यवाद
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- इन
- वे
- इसका
- पहर
- सेवा मेरे
- आज का दि
- ले गया
- अनुवाद करना
- <strong>उद्देश्य</strong>
- टाइप
- प्रकार
- के अंतर्गत
- समझना
- अवांछित
- अपडेट
- उपयोग
- प्रयुक्त
- का उपयोग
- उपयोग
- मूल्य
- मान
- विभिन्न
- व्यापक
- सत्यापित
- संस्करण
- था
- मार्ग..
- we
- वेब
- वेब सेवाओं
- कब
- कौन कौन से
- कौन
- मर्जी
- साथ में
- बिना
- कार्यसमूह
- कार्य
- विश्व
- यमलो
- वर्ष
- इसलिए आप
- आपका
- जेफिरनेट