सभी उद्योगों के संगठनों के पास अलग-अलग एनालिटिक्स सिस्टम में उनके विश्लेषणात्मक उपयोग के मामलों के लिए जटिल डेटा प्रोसेसिंग आवश्यकताएं होती हैं, जैसे AWS पर डेटा झील, डेटा वेयरहाउस (अमेज़न रेडशिफ्ट), खोज (अमेज़न ओपन सर्च सर्विस), नोएसक्यूएल (अमेज़ॅन डायनेमोडीबी), मशीन लर्निंग (अमेज़न SageMaker), और अधिक। विश्लेषिकी पेशेवरों को अपने ग्राहकों के लिए बेहतर, सुरक्षित और लागत-अनुकूलित अनुभव बनाने के लिए इन वितरित प्रणालियों में संग्रहीत डेटा से मूल्य प्राप्त करने का काम सौंपा गया है। उदाहरण के लिए, डिजिटल मीडिया कंपनियां अपने ग्राहक प्रोफाइल के एकीकृत विचार बनाने, नवीन सुविधाओं के लिए विचारों को प्रोत्साहित करने और प्लेटफॉर्म जुड़ाव बढ़ाने के लिए आंतरिक और बाहरी डेटाबेस में डेटासेट को संयोजित और संसाधित करना चाहती हैं।
इन परिदृश्यों में, ग्राहक सर्वर रहित डेटा एकीकरण की पेशकश के उपयोग की तलाश कर रहे हैं एडब्ल्यूएस गोंद डेटा को संसाधित करने और सूचीबद्ध करने के लिए एक मुख्य घटक के रूप में। AWS Glue, AWS सेवाओं और भागीदार उत्पादों के साथ अच्छी तरह से एकीकृत है, और एनालिटिक्स, मशीन लर्निंग (ML), या एप्लिकेशन डेवलपमेंट वर्कफ्लो को सक्षम करने के लिए लो-कोड/नो-कोड एक्सट्रैक्ट, ट्रांसफ़ॉर्म और लोड (ETL) विकल्प प्रदान करता है। एडब्ल्यूएस गोंद ईटीएल नौकरियां अधिक जटिल पाइपलाइन में एक घटक हो सकती हैं। इन घटकों के बीच निर्भरता को चलाने और प्रबंधित करने की व्यवस्था करना डेटा रणनीति में एक महत्वपूर्ण क्षमता है। Apache Airflows के लिए Amazon प्रबंधित वर्कफ़्लोज़ (अमेज़ॅन MWAA) ऑन-प्रिमाइसेस संसाधनों, AWS सेवाओं और तृतीय-पक्ष घटकों सहित वितरित तकनीकों का उपयोग करके डेटा पाइपलाइनों को ऑर्केस्ट्रेट करता है।
इस पोस्ट में, हम दिखाते हैं कि Amazon MWAA की नवीनतम सुविधाओं का उपयोग करके Airflow द्वारा ऑर्केस्ट्रेटेड AWS Glue जॉब की निगरानी को कैसे सरल बनाया जाए।
समाधान का अवलोकन
यह पोस्ट निम्नलिखित पर चर्चा करता है:
- Amazon MWAA वातावरण को संस्करण 2.4.3 में कैसे अपग्रेड करें।
- एयरफ्लो से AWS ग्लू जॉब को ऑर्केस्ट्रेट कैसे करें निर्देशित अचक्रीय ग्राफ (डीएजी)।
- Amazon MWAA में Airflow Amazon प्रदाता पैकेज की अवलोकन क्षमता में वृद्धि। समस्या निवारण डेटा पाइपलाइनों को सरल बनाने के लिए अब आप Airflow कंसोल पर AWS Glue नौकरियों के रन लॉग को समेकित कर सकते हैं। Amazon MWAA कंसोल AWS Glue जॉब रन की निगरानी और विश्लेषण करने के लिए एक एकल संदर्भ बन जाता है। पहले, समर्थन टीमों को एक्सेस करने की आवश्यकता थी एडब्ल्यूएस प्रबंधन कंसोल और इस दृश्यता के लिए मैन्युअल कदम उठाएं. यह सुविधा Amazon MWAA संस्करण 2.4.3 से डिफ़ॉल्ट रूप से उपलब्ध है।
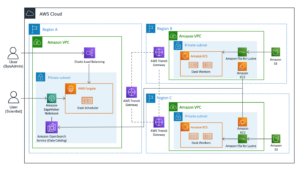
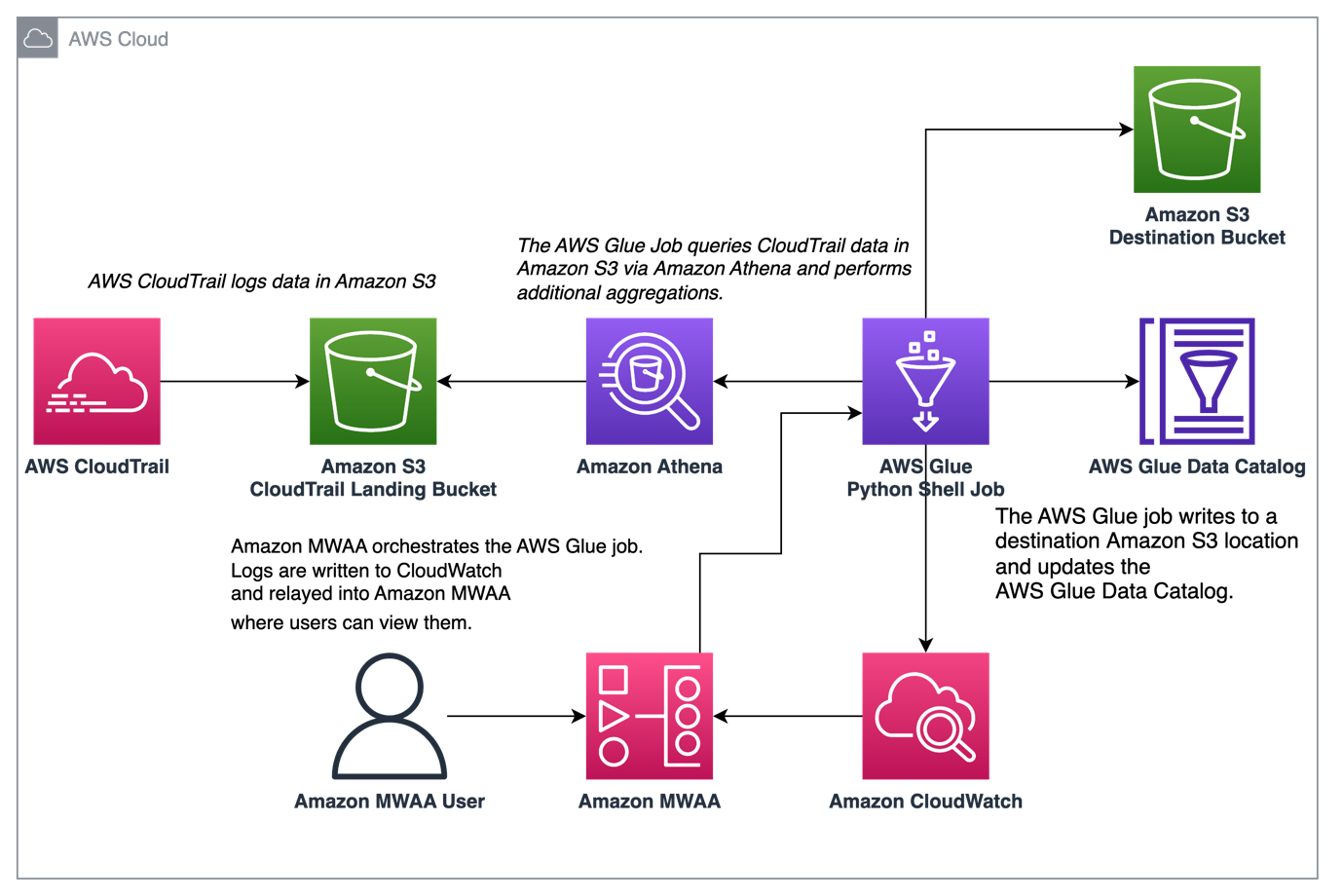
निम्नलिखित चित्र हमारे समाधान वास्तुकला को दर्शाता है।
.. पूर्वापेक्षाएँ
आपको निम्नलिखित पूर्वापेक्षाएँ चाहिए:
Amazon MWAA परिवेश सेट करें
अपना परिवेश बनाने के निर्देशों के लिए, देखें Amazon MWAA वातावरण बनाएं. मौजूदा उपयोगकर्ताओं के लिए, हम अनुशंसा करते हैं कि इस पोस्ट में विशेष रुप से देखे जाने योग्य संवर्द्धन का लाभ उठाने के लिए संस्करण 2.4.3 में अपग्रेड करें।
Amazon MWAA को 2.4.3 संस्करण में अपग्रेड करने के चरण इस बात पर निर्भर करते हैं कि वर्तमान संस्करण 1.10.12 है या 2.2.2। हम इस पोस्ट में दोनों विकल्पों पर चर्चा करते हैं।
Amazon MWAA परिवेश स्थापित करने के लिए पूर्वापेक्षाएँ
आपको निम्नलिखित पूर्वापेक्षाएँ पूरी करनी होंगी:
संस्करण 1.10.12 से 2.4.3 तक अपग्रेड करें
यदि आप Amazon MWAA संस्करण का उपयोग कर रहे हैं 1.10.12, को देखें नए Amazon MWAA परिवेश में माइग्रेट करना 2.4.3 में अपग्रेड करने के लिए।
संस्करण 2.0.2 या 2.2.2 से 2.4.3 में अपग्रेड करें
यदि आप Amazon MWAA पर्यावरण संस्करण 2.2.2 या निम्न का उपयोग कर रहे हैं, तो निम्न चरणों को पूरा करें:
- बनाओ किसी भी कस्टम निर्भरता के लिए आवश्यकताएँ। txt आपके DAGs के लिए आवश्यक विशिष्ट संस्करणों के साथ।
- फ़ाइल को Amazon S3 पर अपलोड करें उपयुक्त स्थान पर जहां Amazon MWAA वातावरण निर्भरताओं को स्थापित करने के लिए आवश्यकताएँ। txt की ओर इशारा करता है।
- में चरणों का पालन करें नए Amazon MWAA परिवेश में माइग्रेट करना और संस्करण 2.4.3 का चयन करें।
अपने डीएजी को अपडेट करें
पुराने Amazon MWAA परिवेश से अपग्रेड करने वाले ग्राहकों को मौजूदा DAG में अपडेट करने की आवश्यकता हो सकती है। Airflow संस्करण 2.4.3 में, Airflow वातावरण डिफ़ॉल्ट रूप से Amazon प्रदाता पैकेज संस्करण 6.0.0 का उपयोग करेगा। इस पैकेज में कुछ संभावित परिवर्तन शामिल हो सकते हैं, जैसे ऑपरेटर नामों में परिवर्तन। उदाहरण के लिए, एडब्ल्यूएस ग्लू जॉबऑपरेटर बहिष्कृत कर दिया गया है और इसके साथ बदल दिया गया है ग्लू जॉबऑपरेटर. संगतता बनाए रखने के लिए, पिछले संस्करणों के किसी भी बहिष्कृत या असमर्थित ऑपरेटरों को नए के साथ बदलकर अपने एयरफ्लो डीएजी को अपडेट करें। निम्नलिखित चरणों को पूरा करें:
- पर जाए अमेज़न एडब्ल्यूएस ऑपरेटरों.
- समर्थित Airflow ऑपरेटरों की सूची खोजने के लिए अपने Amazon MWAA उदाहरण (डिफ़ॉल्ट रूप से 6.0.0.) में स्थापित उपयुक्त संस्करण का चयन करें।
- मौजूदा DAG कोड में आवश्यक परिवर्तन करें और संशोधित फ़ाइलों को Amazon S3 में DAG स्थान पर अपलोड करें।
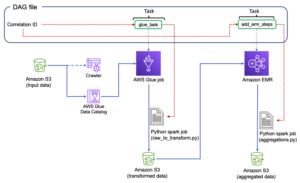
एयरफ्लो से AWS ग्लू जॉब को ऑर्केस्ट्रेट करें
यह खंड एयरफ्लो डीएजी के भीतर एडब्ल्यूएस ग्लू जॉब को ऑर्केस्ट्रेट करने के विवरण को कवर करता है। एयरफ्लो विषम प्रणालियों जैसे ऑन-प्रिमाइसेस प्रक्रियाओं, बाहरी निर्भरताओं, अन्य एडब्ल्यूएस सेवाओं, और अधिक के बीच निर्भरता के साथ डेटा पाइपलाइनों के विकास को आसान बनाता है।
AWS Glue और Amazon MWAA के साथ CloudTrail लॉग एकत्रीकरण की व्यवस्था करें
इस उदाहरण में, हम AWS Glue Python Shell जॉब को ऑर्केस्ट्रेट करने के लिए Amazon MWAA का उपयोग करने के उपयोग के मामले से गुजरते हैं जो CloudTrail लॉग के आधार पर एकत्रित मेट्रिक्स को बनाए रखता है।
CloudTrail आपके AWS खाते में किए जा रहे AWS API कॉल में दृश्यता सक्षम करता है। इस डेटा के साथ एक सामान्य उपयोग मामला ऑडिटिंग और विनियामक आवश्यकताओं के लिए आपके खाते के संसाधनों पर कार्य करने वाले प्रधानाचार्यों पर उपयोग मेट्रिक्स एकत्र करना होगा।
चूंकि CloudTrail ईवेंट लॉग किए जा रहे हैं, उन्हें Amazon S3 में JSON फ़ाइलों के रूप में डिलीवर किया जाता है, जो विश्लेषणात्मक प्रश्नों के लिए आदर्श नहीं हैं। इष्टतम क्वेरी प्रदर्शन की अनुमति देने के लिए हम इस डेटा को एकत्र करना चाहते हैं और इसे Parquet फ़ाइलों के रूप में बनाए रखना चाहते हैं। प्रारंभिक चरण के रूप में, हम अपने AWS Glue कार्य में अतिरिक्त एकत्रीकरण करने से पहले डेटा की प्रारंभिक क्वेरी करने के लिए एथेना का उपयोग कर सकते हैं। एडब्ल्यूएस ग्लू डेटा कैटलॉग तालिका बनाने के बारे में अधिक जानकारी के लिए देखें विभाजन प्रक्षेपण का उपयोग करके एथेना में CloudTrail लॉग के लिए तालिका बनाना आंकड़े। एथेना के माध्यम से डेटा की खोज करने और यह तय करने के बाद कि हम कुल तालिकाओं में कौन से मेट्रिक्स को बनाए रखना चाहते हैं, हम AWS ग्लू जॉब बना सकते हैं।
एथेना में क्लाउडट्रेल टेबल बनाएं
सबसे पहले, हमें अपने डेटा कैटलॉग में एक तालिका बनाने की आवश्यकता है जो क्लाउडट्रेल डेटा को एथेना के माध्यम से क्वेरी करने की अनुमति देती है। निम्न नमूना क्वेरी क्षेत्र और दिनांक पर दो विभाजनों के साथ एक तालिका बनाती है (जिसे स्नैपशॉट_डेट कहा जाता है)। अपने CloudTrail बकेट, AWS खाता ID और CloudTrail तालिका नाम के लिए प्लेसहोल्डर्स को बदलना सुनिश्चित करें:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')एथेना कंसोल पर पिछली क्वेरी चलाएँ, और तालिका का नाम और AWS ग्लू डेटा कैटलॉग डेटाबेस नोट करें जहाँ इसे बनाया गया था। हम इन मानों का उपयोग बाद में Airflow DAG कोड में करते हैं।
नमूना AWS गोंद जॉब कोड
निम्नलिखित कोड एक नमूना है एडब्ल्यूएस गोंद पायथन शेल जॉब जो निम्नलिखित करता है:
- किस दिन के डेटा को संसाधित करना है, इस पर तर्क लेता है (जो हम अपने Amazon MWAA DAG से पास करते हैं)।
- का उपयोग करता है पंडों के लिए एडब्ल्यूएस एसडीके AWS Glue के बाहर CloudTrail JSON डेटा की प्रारंभिक फ़िल्टरिंग करने के लिए एथेना क्वेरी चलाने के लिए
- फ़िल्टर किए गए डेटा पर सरल एकत्रीकरण करने के लिए पांडा का उपयोग करता है
- तालिका में एडब्ल्यूएस गोंद डेटा कैटलॉग के लिए एकत्रित डेटा को आउटपुट करता है
- प्रोसेसिंग के दौरान लॉगिंग का उपयोग करता है, जो Amazon MWAA में दिखाई देगा
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
इस AWS Glue जॉब के कुछ प्रमुख लाभ निम्नलिखित हैं:
- हम यह सुनिश्चित करने के लिए एथेना क्वेरी का उपयोग करते हैं कि हमारे AWS ग्लू जॉब के बाहर प्रारंभिक फ़िल्टरिंग की जाती है। जैसे, एक बड़े CloudTrail डेटासेट को एकत्र करने के लिए न्यूनतम गणना के साथ एक Python Shell जॉब अभी भी पर्याप्त है।
- हम सुनिश्चित करते हैं एनालिटिक्स लाइब्रेरी-सेट विकल्प पांडा लाइब्रेरी के लिए AWS SDK का उपयोग करने के लिए हमारी AWS Glue जॉब बनाते समय चालू है।
AWS ग्लू जॉब बनाएं
अपना AWS ग्लू जॉब बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- स्क्रिप्ट को पिछले अनुभाग में कॉपी करें और इसे एक स्थानीय फ़ाइल में सहेजें। इस पोस्ट के लिए फाइल कहा जाता है
script.py. - एडब्ल्यूएस गोंद कंसोल पर, चुनें ईटीएल नौकरियां नेविगेशन फलक में
- एक नया कार्य बनाएँ और चुनें पायथन शेल स्क्रिप्ट संपादक.
- चुनते हैं मौजूदा स्क्रिप्ट अपलोड और संपादित करें और आपके द्वारा स्थानीय रूप से सहेजी गई फ़ाइल को अपलोड करें।
- चुनें बनाएं.

- पर नौकरी विवरण टैब पर, अपने AWS Glue कार्य के लिए एक नाम दर्ज करें।
- के लिए IAM भूमिका, एक मौजूदा भूमिका चुनें या एक नई भूमिका बनाएं जिसमें Amazon S3, AWS Glue और Athena के लिए आवश्यक अनुमतियां हों। भूमिका को आपके द्वारा पहले बनाई गई CloudTrail तालिका को क्वेरी करने और आउटपुट स्थान पर लिखने की आवश्यकता है।
आप निम्न नमूना नीति कोड का उपयोग कर सकते हैं। प्लेसहोल्डर्स को अपने CloudTrail लॉग बकेट, आउटपुट टेबल नाम, आउटपुट AWS ग्लू डेटाबेस, आउटपुट S3 बकेट, CloudTrail टेबल नाम, AWS ग्लू डेटाबेस जिसमें CloudTrail टेबल है, और अपने AWS अकाउंट आईडी से बदलें।
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
के लिए पायथन संस्करण, चुनें अजगर 3.9.
- चुनते हैं सामान्य एनालिटिक्स लाइब्रेरी लोड करें.
- के लिए डाटा प्रोसेसिंग इकाइयां, चुनें 1 डीपीयू.
- अन्य विकल्पों को डिफ़ॉल्ट के रूप में छोड़ दें या आवश्यकतानुसार समायोजित करें।

- चुनें सहेजें अपने कार्य विन्यास को बचाने के लिए।
AWS Glue जॉब को ऑर्केस्ट्रेट करने के लिए Amazon MWAA DAG को कॉन्फ़िगर करें
निम्नलिखित कोड एक डीएजी के लिए है जो हमारे द्वारा बनाए गए एडब्ल्यूएस ग्लू जॉब को ऑर्केस्ट्रेट कर सकता है। हम इस डीएजी में निम्नलिखित प्रमुख विशेषताओं का लाभ उठाते हैं:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Amazon MWAA में AWS Glue नौकरियों की अवलोकन क्षमता बढ़ाएँ
AWS ग्लू जॉब्स को लॉग लिखते हैं अमेज़ॅन क्लाउडवॉच. एयरफ्लो के अमेज़ॅन प्रदाता पैकेज में हाल ही में अवलोकन क्षमता में वृद्धि के साथ, ये लॉग अब एयरफ्लो टास्क लॉग के साथ एकीकृत हैं। यह समेकन Airflow उपयोगकर्ताओं को सीधे Airflow UI में एंड-टू-एंड दृश्यता प्रदान करता है, जिससे CloudWatch या AWS Glue कंसोल में खोज करने की आवश्यकता समाप्त हो जाती है।
इस सुविधा का उपयोग करने के लिए, सुनिश्चित करें कि अमेज़ॅन MWAA पर्यावरण से जुड़ी IAM भूमिका में आवश्यक लॉग को पुनः प्राप्त करने और लिखने के लिए निम्नलिखित अनुमतियाँ हैं:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}यदि वर्बोज़ = सही है, तो AWS ग्लू जॉब रन लॉग एयरफ़्लो टास्क लॉग में दिखाई देते हैं। डिफॉल्ट गलत है। अधिक जानकारी के लिए, देखें पैरामीटर्स.
सक्षम होने पर, DAG AWS Glue जॉब के CloudWatch लॉग स्ट्रीम से पढ़ते हैं और उन्हें Airflow DAG AWS Glue जॉब स्टेप लॉग में रिले करते हैं। यह डीएजी लॉग के माध्यम से वास्तविक समय में एडब्ल्यूएस ग्लू जॉब के रन में विस्तृत अंतर्दृष्टि प्रदान करता है। ध्यान दें कि AWS ग्लू जॉब क्रमशः जॉब के STDOUT और STDERR के आधार पर एक आउटपुट और एरर CloudWatch लॉग ग्रुप उत्पन्न करता है। आउटपुट लॉग समूह में सभी लॉग और त्रुटि लॉग समूह से अपवाद या त्रुटि लॉग Amazon MWAA में रिले किए जाते हैं।
AWS एडमिन अब एक सपोर्ट टीम की एक्सेस को केवल एयरफ्लो तक सीमित कर सकते हैं, जिससे Amazon MWAA जॉब ऑर्केस्ट्रेशन और जॉब हेल्थ मैनेजमेंट पर ग्लास का सिंगल पेन बन जाता है। पहले, उपयोगकर्ताओं को एयरफ्लो डीएजी चरणों में एडब्ल्यूएस ग्लू जॉब रन स्थिति की जांच करने और जॉब रन आइडेंटिफायर को पुनः प्राप्त करने की आवश्यकता होती थी। फिर उन्हें जॉब चलाने के इतिहास को खोजने के लिए एडब्ल्यूएस ग्लू कंसोल तक पहुंचने की आवश्यकता थी, पहचानकर्ता का उपयोग करके रुचि की नौकरी की खोज करें, और अंत में समस्या निवारण के लिए जॉब के क्लाउडवॉच लॉग पर नेविगेट करें।
डीएजी बनाएं
DAG बनाने के लिए, निम्न चरणों को पूरा करें:
- संकेतित प्लेसहोल्डर्स को बदलकर पूर्ववर्ती DAG कोड को एक स्थानीय .py फ़ाइल में सहेजें।
आपके एडब्ल्यूएस अकाउंट आईडी, एडब्ल्यूएस ग्लू जॉब का नाम, क्लाउडट्रेल टेबल के साथ एडब्ल्यूएस ग्लू डेटाबेस और क्लाउडट्रेल टेबल नाम के मान पहले से ही ज्ञात होने चाहिए। आप आउटपुट S3 बकेट, आउटपुट AWS ग्लू डेटाबेस और आउटपुट टेबल नाम को आवश्यकतानुसार समायोजित कर सकते हैं, लेकिन सुनिश्चित करें कि AWS ग्लू जॉब की IAM भूमिका जो आपने पहले उपयोग की थी, उसी के अनुसार कॉन्फ़िगर की गई है।
- Amazon MWAA कंसोल पर, यह देखने के लिए अपने वातावरण में नेविगेट करें कि DAG कोड कहाँ संग्रहीत है।
DAGs फ़ोल्डर S3 बकेट के भीतर उपसर्ग है जहाँ आपकी DAG फ़ाइल रखी जानी चाहिए।
- अपनी संपादित फाइल को वहां अपलोड करें।

- तालिका में DAG दिखाई देने की पुष्टि करने के लिए Amazon MWAA कंसोल खोलें।

डीएजी चलाएं
DAG को चलाने के लिए, निम्न चरणों को पूरा करें:
- निम्नलिखित विकल्पों में से चुनें:
- ट्रिगर डीएजी - यह कल के डेटा को संसाधित करने के लिए डेटा के रूप में उपयोग करने का कारण बनता है
- ट्रिगर डीएजी w/config - इस विकल्प के साथ, आप संभावित रूप से बैकफ़िल के लिए एक अलग तिथि में पास कर सकते हैं, जिसे उपयोग करके पुनर्प्राप्त किया जाता है
dag_run.confDAG कोड में और फिर एक पैरामीटर के रूप में AWS Glue जॉब में पास हुआ

यदि आप चुनते हैं तो निम्न स्क्रीनशॉट अतिरिक्त कॉन्फ़िगरेशन विकल्प दिखाता है ट्रिगर डीएजी w/config.

- DAG के चलने पर उसकी निगरानी करें।
- जब DAG पूरा हो जाए, तो रन का विवरण खोलें।
दाएँ फलक पर, आप लॉग देख सकते हैं या चुन सकते हैं कार्य उदाहरण विवरण पूर्ण दृश्य के लिए।

- AWS Glue कंसोल का उपयोग किए बिना Amazon MWAA में AWS Glue जॉब आउटपुट लॉग देखें
GlueJobOperatorशब्दाडंबरपूर्ण झंडा।

AWS Glue जॉब में आपके द्वारा निर्दिष्ट आउटपुट तालिका में लिखित परिणाम होंगे।
- यह पुष्टि करने के लिए एथेना के माध्यम से इस तालिका को क्वेरी करें कि यह सफल रहा।
सारांश
Amazon MWAA अब AWS Glue जॉब की स्थिति को ट्रैक करने के लिए एक ही स्थान प्रदान करता है और आपको जॉब ऑर्केस्ट्रेशन और स्वास्थ्य प्रबंधन के लिए ग्लास के सिंगल पेन के रूप में Airflow कंसोल का उपयोग करने में सक्षम बनाता है। इस पोस्ट में, हमने एयरफ्लो का उपयोग करके एडब्ल्यूएस ग्लू नौकरियों को ऑर्केस्ट्रेट करने के लिए कदम उठाए GlueJobOperator. नए ऑब्जर्वेबिलिटी एन्हांसमेंट के साथ, आप एकीकृत अनुभव में एडब्ल्यूएस ग्लू जॉब्स का समस्या निवारण कर सकते हैं। हमने यह भी प्रदर्शित किया कि कैसे अपने Amazon MWAA वातावरण को एक संगत संस्करण में अपग्रेड किया जाए, निर्भरताओं को अपडेट किया जाए और तदनुसार IAM भूमिका नीति को बदला जाए।
सामान्य समस्या निवारण चरणों के बारे में अधिक जानकारी के लिए देखें समस्या निवारण: Amazon MWAA वातावरण बनाना और अद्यतन करना. Amazon MWAA परिवेश में माइग्रेट करने के गहन विवरण के लिए, देखें 1.10 से 2 में अपग्रेड करना. Airflow Amazon प्रदाता पैकेज में AWS Glue नौकरियों की बढ़ी हुई अवलोकन क्षमता के लिए ओपन-सोर्स कोड परिवर्तनों के बारे में जानने के लिए, देखें एडब्ल्यूएस गोंद नौकरियों से रिले लॉग.
अंत में, हम जाने की सलाह देते हैं एडब्ल्यूएस बिग डेटा ब्लॉग एडब्ल्यूएस पर एनालिटिक्स, एमएल और डेटा गवर्नेंस पर अन्य सामग्री के लिए।
लेखक के बारे में
 ऋषभ लोखंडे AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक डेटा और एमएल इंजीनियर है। वह ग्राहकों को बिग डेटा, मशीन लर्निंग और एनालिटिक्स सॉल्यूशंस को लागू करने में मदद करता है। काम से बाहर, उन्हें परिवार के साथ समय बिताना, पढ़ना, दौड़ना और गोल्फ खेलना अच्छा लगता है।
ऋषभ लोखंडे AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक डेटा और एमएल इंजीनियर है। वह ग्राहकों को बिग डेटा, मशीन लर्निंग और एनालिटिक्स सॉल्यूशंस को लागू करने में मदद करता है। काम से बाहर, उन्हें परिवार के साथ समय बिताना, पढ़ना, दौड़ना और गोल्फ खेलना अच्छा लगता है।
 रयान गोम्स AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक डेटा और एमएल इंजीनियर है। उन्हें क्लाउड में एनालिटिक्स और मशीन लर्निंग समाधानों के माध्यम से ग्राहकों को बेहतर परिणाम प्राप्त करने में मदद करने का जुनून है। काम से बाहर, वह फिटनेस, खाना बनाना और दोस्तों और परिवार के साथ अच्छा समय बिताना पसंद करते हैं।
रयान गोम्स AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक डेटा और एमएल इंजीनियर है। उन्हें क्लाउड में एनालिटिक्स और मशीन लर्निंग समाधानों के माध्यम से ग्राहकों को बेहतर परिणाम प्राप्त करने में मदद करने का जुनून है। काम से बाहर, वह फिटनेस, खाना बनाना और दोस्तों और परिवार के साथ अच्छा समय बिताना पसंद करते हैं।
 विश्व गुप्ता AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक वरिष्ठ डेटा आर्किटेक्ट हैं। वह ग्राहकों को बिग डेटा और एनालिटिक्स समाधान लागू करने में मदद करता है। काम से बाहर, उन्हें परिवार के साथ समय बिताना, यात्रा करना और नए भोजन की कोशिश करना अच्छा लगता है।
विश्व गुप्ता AWS प्रोफेशनल सर्विसेज एनालिटिक्स प्रैक्टिस के साथ एक वरिष्ठ डेटा आर्किटेक्ट हैं। वह ग्राहकों को बिग डेटा और एनालिटिक्स समाधान लागू करने में मदद करता है। काम से बाहर, उन्हें परिवार के साथ समय बिताना, यात्रा करना और नए भोजन की कोशिश करना अच्छा लगता है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 12
- 8
- a
- About
- पहुँच
- तदनुसार
- लेखा
- पाना
- के पार
- कार्य
- अचक्रीय
- अतिरिक्त
- लाभ
- फायदे
- बाद
- एकत्रीकरण
- सब
- अनुमति देना
- की अनुमति देता है
- पहले ही
- भी
- वीरांगना
- अमेज़ॅन वेब सेवा
- an
- विश्लेषणात्मक
- विश्लेषिकी
- विश्लेषण करें
- और
- कोई
- अपाचे
- एपीआई
- आवेदन
- अनुप्रयोग विकास
- उपयुक्त
- स्थापत्य
- हैं
- तर्क
- तर्क
- AS
- At
- विशेषताओं
- लेखा परीक्षा
- उपलब्ध
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- AWS व्यावसायिक सेवाएँ
- आधारित
- BE
- हो जाता है
- किया गया
- से पहले
- जा रहा है
- बेहतर
- के बीच
- बड़ा
- बड़ा डेटा
- के छात्रों
- तोड़कर
- निर्माण
- लेकिन
- by
- बुलाया
- कॉल
- कर सकते हैं
- मामला
- मामलों
- सूची
- का कारण बनता है
- परिवर्तन
- परिवर्तन
- चेक
- चुनें
- बादल
- कोड
- COM
- गठबंधन
- टिप्पणी
- सामान्य
- कंपनियों
- अनुकूलता
- संगत
- पूरा
- जटिल
- अंग
- घटकों
- गणना करना
- विन्यास
- पुष्टि करें
- कंसोल
- को मजबूत
- समेकन
- खाना पकाने
- मूल
- शामिल किया गया
- बनाना
- बनाया
- बनाता है
- बनाना
- वर्तमान
- रिवाज
- ग्राहक
- ग्राहक
- डेग
- तिथि
- डेटा एकीकरण
- डेटा संसाधन
- डेटा रणनीति
- डेटा वेयरहाउस
- डाटाबेस
- डेटाबेस
- डेटासेट
- तारीख
- खजूर
- दिनांक और समय
- दिन
- का फैसला किया
- चूक
- दिया गया
- साबित
- निर्भर करता है
- पदावनत
- विस्तृत
- विवरण
- विकास
- अलग
- विभिन्न
- डिजिटल
- डिजिटल मीडिया
- सीधे
- चर्चा करना
- वितरित
- वितरित प्रणाली
- do
- कर देता है
- कर
- किया
- दौरान
- e
- पूर्व
- आसान बनाता है
- प्रभाव
- नष्ट
- अन्य
- सक्षम
- सक्षम
- सक्षम बनाता है
- शुरू से अंत तक
- सगाई
- इंजीनियर
- संवर्द्धन
- सुनिश्चित
- दर्ज
- वातावरण
- त्रुटि
- ईथर (ईटीएच)
- घटनाओं
- उदाहरण
- सिवाय
- अपवाद
- मौजूद
- मौजूदा
- मौजूद
- अनुभव
- अनुभव
- पता लगाया
- अभिव्यक्ति
- बाहरी
- उद्धरण
- विफल रहे
- असत्य
- परिवार
- Feature
- चित्रित किया
- विशेषताएं
- पट्टिका
- फ़ाइलें
- छानने
- अंत में
- खोज
- फिटनेस
- निम्नलिखित
- भोजन
- के लिए
- प्रारूप
- मित्रों
- से
- पूर्ण
- इकट्ठा
- उत्पन्न
- कांच
- Go
- गोल्फ
- शासन
- समूह
- Hadoop
- है
- he
- स्वास्थ्य
- मदद
- मदद करता है
- इतिहास
- करंड
- कैसे
- How To
- एचटीएमएल
- http
- HTTPS
- आई ए एम
- ID
- आदर्श
- विचारों
- पहचानकर्ता
- if
- दिखाता है
- लागू करने के
- आयात
- in
- में गहराई
- शामिल
- सहित
- बढ़ना
- वृद्धि हुई
- संकेत दिया
- उद्योगों
- पता
- करें-
- प्रारंभिक
- अभिनव
- अंतर्दृष्टि
- स्थापित कर रहा है
- उदाहरण
- निर्देश
- एकीकृत
- एकीकरण
- ब्याज
- आंतरिक
- में
- IT
- काम
- नौकरियां
- जेपीजी
- JSON
- कुंजी
- जानने वाला
- बड़ा
- बाद में
- ताज़ा
- जानें
- सीख रहा हूँ
- पुस्तकालय
- सीमा
- सूची
- भार
- स्थानीय
- स्थानीय स्तर पर
- स्थान
- लॉग इन
- लॉग इन
- लॉगिंग
- देख
- मशीन
- यंत्र अधिगम
- बनाया गया
- बनाए रखना
- बनाना
- निर्माण
- कामयाब
- प्रबंध
- प्रबंध
- गाइड
- सामग्री
- मई..
- मीडिया
- मिलना
- message
- मेट्रिक्स
- ओर पलायन
- कम से कम
- ML
- संशोधित
- मॉड्यूल
- मॉनिटर
- निगरानी
- अधिक
- चाहिए
- नाम
- नामों
- नेविगेट करें
- पथ प्रदर्शन
- आवश्यक
- आवश्यकता
- जरूरत
- की जरूरत है
- नया
- कुछ नहीं
- अभी
- of
- की पेशकश
- on
- ONE
- लोगों
- केवल
- खुला
- खुला स्रोत
- ओपन-सोर्स कोड
- ऑपरेटर
- ऑपरेटरों
- इष्टतम
- विकल्प
- ऑप्शंस
- or
- ऑर्केस्ट्रेटेड
- आर्केस्ट्रा
- अन्य
- हमारी
- परिणामों
- उत्पादन
- बाहर
- पैकेज
- पांडा
- फलक
- पैरामीटर
- साथी
- पास
- पारित कर दिया
- आवेशपूर्ण
- प्रदर्शन
- अनुमतियाँ
- बनी रहती है
- पाइपलाइन
- जगह
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- अंक
- नीति
- पद
- संभावित
- अभ्यास
- आवश्यक शर्तें
- पिछला
- पहले से
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- उत्पाद
- पेशेवर
- पेशेवरों
- प्रोफाइल
- प्रक्षेपण
- प्रदाता
- प्रदाताओं
- प्रदान करता है
- अजगर
- गुणवत्ता
- प्रश्नों
- उठाना
- रेंज
- पढ़ना
- पढ़ना
- वास्तविक
- वास्तविक समय
- हाल
- की सिफारिश
- क्षेत्र
- नियामक
- रिले
- की जगह
- प्रतिस्थापित
- अपेक्षित
- आवश्यकताएँ
- संसाधन
- उपयुक्त संसाधन चुनें
- क्रमश
- प्रतिक्रिया
- परिणाम
- बनाए रखने के
- सही
- भूमिका
- आरओडब्ल्यू
- रन
- दौड़ना
- s
- सहेजें
- परिदृश्यों
- एसडीके
- मूल
- Search
- अनुभाग
- सुरक्षित
- देखना
- शोध
- वरिष्ठ
- serverless
- सेवाएँ
- की स्थापना
- व्यवस्था
- खोल
- चाहिए
- दिखाना
- दिखाता है
- सरल
- को आसान बनाने में
- के बाद से
- एक
- आशुचित्र
- समाधान
- समाधान ढूंढे
- कुछ
- विशिष्ट
- विनिर्दिष्ट
- खर्च
- कथन
- स्थिति
- कदम
- कदम
- फिर भी
- भंडारण
- संग्रहित
- स्ट्रेटेजी
- धारा
- तार
- सफल
- ऐसा
- पर्याप्त
- समर्थन
- समर्थित
- सिस्टम
- तालिका
- लेना
- ले जा
- कार्य
- टीमों
- टेक्नोलॉजीज
- टेम्पलेट
- धन्यवाद
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- तीसरे दल
- इसका
- यहाँ
- पहर
- सेवा मेरे
- ट्रैक
- बदालना
- यात्रा का
- <strong>उद्देश्य</strong>
- कोशिश
- मंगलवार
- बदल गया
- दो
- टाइप
- ui
- एकीकृत
- इकाई
- अपडेट
- अपडेट
- अद्यतन
- उन्नयन
- उन्नत
- अपलोड हो रहा है
- प्रयोग
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ताओं
- का उपयोग
- मूल्य
- मान
- संस्करण
- के माध्यम से
- देखें
- विचारों
- दृश्यता
- दिखाई
- चला
- करना चाहते हैं
- था
- we
- वेब
- वेब सेवाओं
- कुंआ
- क्या
- कब
- या
- कौन कौन से
- कौन
- मर्जी
- साथ में
- अंदर
- बिना
- काम
- workflows
- होगा
- लिखना
- लिखा हुआ
- इसलिए आप
- आपका
- जेफिरनेट