छवि द्वारा Freepik
कन्वर्सेशनल एआई वर्चुअल एजेंटों और चैटबॉट्स को संदर्भित करता है जो मानवीय बातचीत की नकल करते हैं और मनुष्यों को बातचीत में शामिल कर सकते हैं। संवादी एआई का उपयोग तेजी से जीवन का एक तरीका बनता जा रहा है - एलेक्सा से पूछने से लेकर "निकटतम रेस्तरां ढूंढें" सिरी से पूछने के लिए "एक अनुस्मारक बनाएँ," वर्चुअल असिस्टेंट और चैटबॉट का उपयोग अक्सर उपभोक्ताओं के सवालों का जवाब देने, शिकायतों का समाधान करने, आरक्षण करने और बहुत कुछ करने के लिए किया जाता है।
इन आभासी सहायकों को विकसित करने के लिए पर्याप्त प्रयास की आवश्यकता है। हालाँकि, प्रमुख चुनौतियों को समझना और उनका समाधान करना विकास प्रक्रिया को सुव्यवस्थित कर सकता है। मैंने एक भर्ती मंच के लिए एक परिपक्व चैटबॉट बनाने में अपने प्रत्यक्ष अनुभव का उपयोग प्रमुख चुनौतियों और उनके संबंधित समाधानों को समझाने के लिए एक संदर्भ बिंदु के रूप में किया है।
संवादात्मक एआई चैटबॉट बनाने के लिए, डेवलपर्स चैटबॉट बनाने के लिए RASA, अमेज़ॅन के लेक्स, या Google के डायलॉगफ्लो जैसे फ्रेमवर्क का उपयोग कर सकते हैं। अधिकांश लोग RASA को तब पसंद करते हैं जब वे कस्टम परिवर्तन की योजना बनाते हैं या बॉट परिपक्व अवस्था में होता है क्योंकि यह एक ओपन-सोर्स फ्रेमवर्क है। अन्य ढाँचे भी शुरुआती बिंदु के रूप में उपयुक्त हैं।
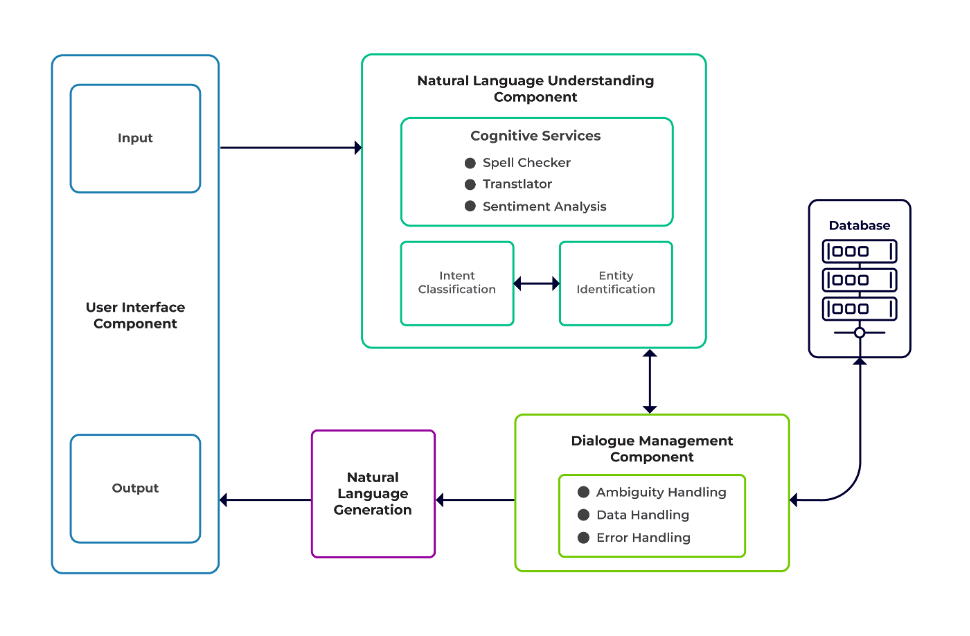
चुनौतियों को चैटबॉट के तीन प्रमुख घटकों के रूप में वर्गीकृत किया जा सकता है।
प्राकृतिक भाषा समझ (NLU) मानव संवाद को समझने की एक बॉट की क्षमता है। यह आशय वर्गीकरण, इकाई निष्कर्षण और प्रतिक्रियाएँ पुनर्प्राप्त करने का कार्य करता है।
संवाद प्रबंधक उपयोगकर्ता इनपुट के वर्तमान और पिछले सेट के आधार पर की जाने वाली कार्रवाइयों के एक सेट के लिए जिम्मेदार है। यह इरादे और संस्थाओं को इनपुट के रूप में लेता है (पिछली बातचीत के हिस्से के रूप में) और अगली प्रतिक्रिया की पहचान करता है।
प्राकृतिक भाषा पीढ़ी (एनएलजी) दिए गए डेटा से लिखित या बोले गए वाक्य बनाने की प्रक्रिया है। यह प्रतिक्रिया को फ्रेम करता है, जिसे बाद में उपयोगकर्ता के सामने प्रस्तुत किया जाता है।
टैलेंटिका सॉफ्टवेयर से छवि
अपर्याप्त डेटा
जब डेवलपर्स अक्सर पूछे जाने वाले प्रश्न या अन्य सहायता प्रणालियों को चैटबॉट से बदलते हैं, तो उन्हें अच्छी मात्रा में प्रशिक्षण डेटा मिलता है। लेकिन ऐसा तब नहीं होता जब वे स्क्रैच से बॉट बनाते हैं। ऐसे मामलों में, डेवलपर्स प्रशिक्षण डेटा को कृत्रिम रूप से उत्पन्न करते हैं।
क्या करना है?
एक टेम्प्लेट-आधारित डेटा जनरेटर प्रशिक्षण के लिए अच्छी मात्रा में उपयोगकर्ता क्वेरी उत्पन्न कर सकता है। एक बार चैटबॉट तैयार हो जाने पर, प्रोजेक्ट मालिक प्रशिक्षण डेटा को बढ़ाने और एक अवधि में इसे अपग्रेड करने के लिए इसे सीमित संख्या में उपयोगकर्ताओं के सामने प्रदर्शित कर सकते हैं।
अनुपयुक्त मॉडल का चयन
सर्वोत्तम इरादे और इकाई निष्कर्षण परिणाम प्राप्त करने के लिए उपयुक्त मॉडल चयन और प्रशिक्षण डेटा महत्वपूर्ण हैं। डेवलपर्स आमतौर पर चैटबॉट्स को एक विशिष्ट भाषा और डोमेन में प्रशिक्षित करते हैं, और अधिकांश उपलब्ध पूर्व-प्रशिक्षित मॉडल अक्सर डोमेन-विशिष्ट होते हैं और एक ही भाषा में प्रशिक्षित होते हैं।
मिश्रित भाषाओं के मामले भी हो सकते हैं जहां लोग बहुभाषी होते हैं। वे मिश्रित भाषा में प्रश्न दर्ज कर सकते हैं। उदाहरण के लिए, फ्रांसीसी-प्रभुत्व वाले क्षेत्र में, लोग एक प्रकार की अंग्रेजी का उपयोग कर सकते हैं जो फ्रेंच और अंग्रेजी दोनों का मिश्रण है।
क्या करना है?
अनेक भाषाओं में प्रशिक्षित मॉडलों का उपयोग करने से समस्या कम हो सकती है। ऐसे मामलों में लैबएसई (भाषा-अज्ञेयवादी बर्ट वाक्य एम्बेडिंग) जैसा पूर्व-प्रशिक्षित मॉडल सहायक हो सकता है। LaBSE को वाक्य समानता कार्य पर 109 से अधिक भाषाओं में प्रशिक्षित किया गया है। मॉडल पहले से ही एक अलग भाषा में समान शब्द जानता है। हमारे प्रोजेक्ट में, इसने वास्तव में अच्छा काम किया।
अनुचित इकाई निष्कर्षण
चैटबॉट्स को इकाइयों को यह पहचानने की आवश्यकता होती है कि उपयोगकर्ता किस प्रकार का डेटा खोज रहा है। इन संस्थाओं में समय, स्थान, व्यक्ति, वस्तु, तिथि आदि शामिल हैं। हालाँकि, बॉट प्राकृतिक भाषा से किसी इकाई की पहचान करने में विफल हो सकते हैं:
एक ही संदर्भ लेकिन अलग-अलग इकाइयाँ. उदाहरण के लिए, जब कोई उपयोगकर्ता "आईआईटी दिल्ली के छात्रों का नाम" और फिर "बेंगलुरु के छात्रों का नाम" टाइप करता है तो बॉट किसी स्थान को इकाई के रूप में भ्रमित कर सकते हैं।
ऐसे परिदृश्य जहां संस्थाओं के बारे में कम आत्मविश्वास के साथ गलत भविष्यवाणी की जाती है। उदाहरण के लिए, एक बॉट आईआईटी दिल्ली को कम आत्मविश्वास वाले शहर के रूप में पहचान सकता है।
मशीन लर्निंग मॉडल द्वारा आंशिक इकाई निष्कर्षण। यदि कोई उपयोगकर्ता "आईआईटी दिल्ली के छात्र" टाइप करता है, तो मॉडल "आईआईटी दिल्ली" के बजाय केवल "आईआईटी" को एक इकाई के रूप में पहचान सकता है।
बिना संदर्भ वाले एकल-शब्द इनपुट मशीन लर्निंग मॉडल को भ्रमित कर सकते हैं। उदाहरण के लिए, "ऋषिकेश" जैसे शब्द का अर्थ किसी व्यक्ति के नाम के साथ-साथ शहर दोनों से हो सकता है।
क्या करना है?
अधिक प्रशिक्षण उदाहरण जोड़ना एक समाधान हो सकता है। लेकिन एक सीमा है जिसके बाद अधिक जोड़ने से कोई मदद नहीं मिलेगी। इसके अलावा, यह एक अंतहीन प्रक्रिया है। एक अन्य समाधान शहर, देश आदि जैसे संभावित मूल्यों के ज्ञात सेट के साथ इकाइयों को निकालने में मदद करने के लिए पूर्व-परिभाषित शब्दों का उपयोग करके रेगेक्स पैटर्न को परिभाषित करना हो सकता है।
जब भी मॉडल इकाई भविष्यवाणी के बारे में निश्चित नहीं होते हैं तो उनका आत्मविश्वास कम हो जाता है। डेवलपर्स इसे एक कस्टम घटक को कॉल करने के लिए ट्रिगर के रूप में उपयोग कर सकते हैं जो कम-आत्मविश्वास वाली इकाई को सुधार सकता है। आइए उपरोक्त उदाहरण पर विचार करें। अगर आईआईटी दिल्ली कम आत्मविश्वास वाले शहर के रूप में भविष्यवाणी की जाती है, तो उपयोगकर्ता इसे हमेशा डेटाबेस में खोज सकता है। में पूर्वानुमानित इकाई को ढूंढने में असफल होने के बाद City तालिका, मॉडल अन्य तालिकाओं पर आगे बढ़ेगा और अंततः, इसे इसमें ढूंढेगा संस्थान तालिका, जिसके परिणामस्वरूप इकाई सुधार हुआ।
ग़लत इरादे का वर्गीकरण
प्रत्येक उपयोगकर्ता संदेश के साथ कुछ न कुछ आशय जुड़ा होता है। चूँकि इरादे किसी बॉट के कार्यों के अगले पाठ्यक्रम को प्राप्त करते हैं, इसलिए इरादे के साथ उपयोगकर्ता प्रश्नों को सही ढंग से वर्गीकृत करना महत्वपूर्ण है। हालाँकि, डेवलपर्स को इरादों में न्यूनतम भ्रम के साथ इरादों की पहचान करनी चाहिए। अन्यथा, भ्रम के कारण मामले उलझ सकते हैं। उदाहरण के लिए, "मुझे खुली स्थिति दिखाओ" बनाम "मुझे खुली स्थिति वाले उम्मीदवार दिखाओ”।
क्या करना है?
भ्रमित करने वाले प्रश्नों में अंतर करने के दो तरीके हैं। सबसे पहले, एक डेवलपर उप-आशय पेश कर सकता है। दूसरे, मॉडल पहचानी गई संस्थाओं के आधार पर प्रश्नों को संभाल सकते हैं।
एक डोमेन-विशिष्ट चैटबॉट एक बंद प्रणाली होनी चाहिए जहां उसे स्पष्ट रूप से पहचानना चाहिए कि वह क्या करने में सक्षम है और क्या नहीं। डोमेन-विशिष्ट चैटबॉट की योजना बनाते समय डेवलपर्स को चरणों में विकास करना चाहिए। प्रत्येक चरण में, वे चैटबॉट की असमर्थित सुविधाओं (असमर्थित इरादे के माध्यम से) की पहचान कर सकते हैं।
वे यह भी पहचान सकते हैं कि चैटबॉट "दायरे से बाहर" इरादे से क्या संभाल नहीं सकता है। लेकिन ऐसे मामले भी हो सकते हैं जहां बॉट असमर्थित और दायरे से बाहर के इरादे से भ्रमित हो। ऐसे परिदृश्यों के लिए, एक फ़ॉलबैक तंत्र होना चाहिए, जहां, यदि इरादे का विश्वास एक सीमा से नीचे है, तो मॉडल भ्रम के मामलों को संभालने के लिए फ़ॉलबैक इरादे के साथ शानदार ढंग से काम कर सकता है।
एक बार जब बॉट उपयोगकर्ता के संदेश के इरादे की पहचान कर लेता है, तो उसे एक प्रतिक्रिया वापस भेजनी होगी। बॉट परिभाषित नियमों और कहानियों के एक निश्चित सेट के आधार पर प्रतिक्रिया तय करता है। उदाहरण के लिए, एक नियम बिल्कुल सरल हो सकता है "शुभ प्रभात" जब उपयोगकर्ता स्वागत करता है "नमस्ते"। हालाँकि, अक्सर, चैटबॉट्स के साथ बातचीत में अनुवर्ती बातचीत शामिल होती है, और उनकी प्रतिक्रियाएँ बातचीत के समग्र संदर्भ पर निर्भर करती हैं।
क्या करना है?
इसे संभालने के लिए, चैटबॉट्स को वास्तविक वार्तालाप उदाहरण दिए जाते हैं जिन्हें स्टोरीज़ कहा जाता है। हालाँकि, उपयोगकर्ता हमेशा इच्छित तरीके से इंटरैक्ट नहीं करते हैं। एक परिपक्व चैटबॉट को ऐसे सभी विचलनों को शालीनता से संभालना चाहिए। डिज़ाइनर और डेवलपर इसकी गारंटी दे सकते हैं यदि वे कहानियाँ लिखते समय न केवल खुशहाल रास्ते पर ध्यान केंद्रित करते हैं बल्कि दुखी रास्तों पर भी काम करते हैं।
चैटबॉट्स के साथ उपयोगकर्ता का जुड़ाव चैटबॉट प्रतिक्रियाओं पर बहुत अधिक निर्भर करता है। यदि प्रतिक्रियाएँ बहुत रोबोटिक या बहुत परिचित हैं तो उपयोगकर्ताओं की रुचि कम हो सकती है। उदाहरण के लिए, किसी उपयोगकर्ता को गलत इनपुट के लिए "आपने गलत क्वेरी टाइप की है" जैसा उत्तर पसंद नहीं आ सकता है, भले ही प्रतिक्रिया सही हो। यहां उत्तर किसी सहायक के व्यक्तित्व से मेल नहीं खाता।
क्या करना है?
चैटबॉट एक सहायक के रूप में कार्य करता है और उसके पास एक विशिष्ट व्यक्तित्व और आवाज का लहजा होना चाहिए। उन्हें स्वागत करने वाला और विनम्र होना चाहिए और डेवलपर्स को तदनुसार बातचीत और कथन डिजाइन करना चाहिए। प्रतिक्रियाएँ रोबोटिक या यांत्रिक नहीं लगनी चाहिए। उदाहरण के लिए, बॉट कह सकता है, "क्षमा करें, ऐसा लगता है कि मेरे पास कोई विवरण नहीं है। क्या आप कृपया अपनी क्वेरी दोबारा टाइप कर सकते हैं?” गलत इनपुट को संबोधित करने के लिए।
चैटजीपीटी और बार्ड जैसे एलएलएम (बड़े भाषा मॉडल) आधारित चैटबॉट गेम-चेंजिंग इनोवेशन हैं और उन्होंने संवादी एआई की क्षमताओं में सुधार किया है। वे न केवल मानव-जैसी खुली बातचीत करने में अच्छे हैं, बल्कि पाठ सारांशीकरण, अनुच्छेद लेखन आदि जैसे विभिन्न कार्य भी कर सकते हैं, जिन्हें पहले केवल विशिष्ट मॉडलों द्वारा ही हासिल किया जा सकता था।
पारंपरिक चैटबॉट सिस्टम की चुनौतियों में से एक प्रत्येक वाक्य को इरादों में वर्गीकृत करना और उसके अनुसार प्रतिक्रिया तय करना है। यह दृष्टिकोण व्यावहारिक नहीं है. "क्षमा करें, मैं आपसे संपर्क नहीं कर सका" जैसी प्रतिक्रियाएँ अक्सर परेशान करने वाली होती हैं। इंटेंटलेस चैटबॉट सिस्टम आगे बढ़ने का रास्ता है, और एलएलएम इसे वास्तविकता बना सकते हैं।
एलएलएम कुछ डोमेन-विशिष्ट इकाई मान्यता को छोड़कर सामान्य नामित इकाई मान्यता में आसानी से अत्याधुनिक परिणाम प्राप्त कर सकते हैं। किसी भी चैटबॉट ढांचे के साथ एलएलएम का उपयोग करने के लिए एक मिश्रित दृष्टिकोण एक अधिक परिपक्व और मजबूत चैटबॉट प्रणाली को प्रेरित कर सकता है।
कन्वर्सेशनल एआई में नवीनतम प्रगति और निरंतर शोध के साथ, चैटबॉट हर दिन बेहतर होते जा रहे हैं। कई उद्देश्यों के साथ जटिल कार्यों को संभालना जैसे "मुंबई के लिए उड़ान बुक करना और दादर के लिए कैब की व्यवस्था करना" जैसे क्षेत्रों पर अधिक ध्यान दिया जा रहा है।
उपयोगकर्ता को व्यस्त रखने के लिए जल्द ही उपयोगकर्ता की विशेषताओं के आधार पर वैयक्तिकृत बातचीत होगी। उदाहरण के लिए, यदि कोई बॉट पाता है कि उपयोगकर्ता नाखुश है, तो यह बातचीत को वास्तविक एजेंट पर पुनर्निर्देशित करता है। इसके अतिरिक्त, लगातार बढ़ते चैटबॉट डेटा के साथ, चैटजीपीटी जैसी गहन शिक्षण तकनीकें ज्ञान आधार का उपयोग करके प्रश्नों के लिए स्वचालित रूप से प्रतिक्रियाएं उत्पन्न कर सकती हैं।
सुमन सौरव वह एक सॉफ्टवेयर उत्पाद विकास कंपनी टैलेंटिका सॉफ्टवेयर में डेटा वैज्ञानिक हैं। वह एनआईटी अगरतला के पूर्व छात्र हैं, जिनके पास एनएलपी, कन्वर्सेशनल एआई और जेनेरेटिव एआई का उपयोग करके क्रांतिकारी एआई समाधानों को डिजाइन करने और लागू करने का 8 वर्षों से अधिक का अनुभव है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- :हैस
- :है
- :नहीं
- :कहाँ
- 8
- a
- क्षमता
- About
- ऊपर
- तदनुसार
- पाना
- हासिल
- के पार
- कार्रवाई
- जोड़ने
- इसके अतिरिक्त
- पता
- को संबोधित
- प्रगति
- बाद
- एजेंट
- एजेंटों
- AI
- ए चेट्बोट
- एलेक्सा
- सब
- पहले ही
- भी
- भूतपूर्व छात्र
- हमेशा
- राशि
- an
- और
- अन्य
- जवाब
- कोई
- दृष्टिकोण
- हैं
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- AS
- पूछ
- सहायक
- सहायकों
- जुड़े
- At
- ध्यान
- स्वतः
- उपलब्ध
- से बचने
- वापस
- आधार
- आधारित
- BE
- बनने
- प्राणियों
- नीचे
- BEST
- बेहतर
- बीओटी
- के छात्रों
- बॉट
- निर्माण
- लेकिन
- by
- कॉल
- बुलाया
- कर सकते हैं
- नही सकता
- क्षमताओं
- सक्षम
- मामलों
- वर्गीकरण
- कुछ
- चुनौतियों
- परिवर्तन
- विशेषताएँ
- chatbot
- chatbots
- ChatGPT
- City
- वर्गीकरण
- वर्गीकृत
- स्पष्ट रूप से
- बंद
- कंपनी
- शिकायतों
- जटिल
- अंग
- घटकों
- समझना
- आत्मविश्वास
- उलझन में
- भ्रमित
- भ्रम
- विचार करना
- प्रसंग
- निरंतर
- कन्वर्सेशन (Conversation)
- संवादी
- संवादी ऐ
- बातचीत
- सही
- ठीक प्रकार से
- इसी
- सका
- देश
- पाठ्यक्रम
- बनाना
- बनाना
- महत्वपूर्ण
- वर्तमान
- रिवाज
- तिथि
- आँकड़े वाला वैज्ञानिक
- डाटाबेस
- तारीख
- दिन
- सभ्य
- निर्णय लेने से
- गहरा
- ध्यान लगा के पढ़ना या सीखना
- परिभाषित
- परिभाषित
- दिल्ली
- निर्भर
- निकाले जाते हैं
- डिज़ाइन
- डिजाइनरों
- डिज़ाइन बनाना
- विवरण
- डेवलपर
- डेवलपर्स
- विकास
- संवाद
- बातचीत
- विभिन्न
- में अंतर
- do
- नहीं करता है
- डोमेन
- dont
- से प्रत्येक
- पूर्व
- आसानी
- प्रयास
- embedding
- अनंत
- लगाना
- लगे हुए
- सगाई
- अंग्रेज़ी
- बढ़ाना
- दर्ज
- संस्थाओं
- सत्ता
- आदि
- और भी
- अंत में
- बढ़ती
- प्रत्येक
- प्रतिदिन
- उदाहरण
- उदाहरण
- अनुभव
- समझाना
- उद्धरण
- निष्कर्षण
- असफल
- में नाकाम रहने
- परिचित
- फास्ट
- विशेषताएं
- फेड
- खोज
- पाता
- उड़ान
- फोकस
- के लिए
- आगे
- ढांचा
- चौखटे
- फ्रेंच
- से
- सामान्य जानकारी
- उत्पन्न
- सृजन
- पीढ़ी
- उत्पादक
- जनरेटिव एआई
- जनक
- मिल
- मिल रहा
- दी
- अच्छा
- गूगल की
- गारंटी
- संभालना
- हैंडलिंग
- होना
- खुश
- है
- होने
- he
- भारी
- मदद
- सहायक
- यहाँ उत्पन्न करें
- कैसे
- How To
- तथापि
- HTTPS
- मानव
- नम्र
- i
- पहचान
- पहचानती
- पहचान करना
- if
- कार्यान्वयन
- उन्नत
- in
- शामिल
- नवाचारों
- निवेश
- निविष्टियां
- प्रेरित
- उदाहरण
- बजाय
- इरादा
- इरादा
- बातचीत
- बातचीत
- बातचीत
- ब्याज
- में
- परिचय कराना
- IT
- जेपीजी
- केवल
- केडनगेट्स
- रखना
- कुंजी
- बच्चा
- ज्ञान
- जानने वाला
- जानता है
- भाषा
- भाषाऐं
- बड़ा
- ताज़ा
- सीख रहा हूँ
- जीवन
- पसंद
- सीमा
- सीमित
- लिंक्डइन
- खोना
- निम्न
- कम
- मशीन
- यंत्र अधिगम
- प्रमुख
- बनाना
- निर्माण
- मैच
- परिपक्व
- मई..
- me
- मतलब
- यांत्रिक
- तंत्र
- message
- हो सकता है
- कम से कम
- मिश्रण
- मिश्रित
- आदर्श
- मॉडल
- अधिक
- और भी
- अधिकांश
- बहुत
- विभिन्न
- मुंबई
- चाहिए
- my
- नाम
- नामांकित
- प्राकृतिक
- प्राकृतिक भाषा
- अगला
- NLG
- NLP
- एन एल यू
- नहीं
- संख्या
- of
- अक्सर
- on
- एक बार
- केवल
- खुला
- खुला स्रोत
- or
- अन्य
- अन्यथा
- हमारी
- के ऊपर
- कुल
- मालिकों
- भाग
- पथ
- पथ
- पैटर्न उपयोग करें
- स्टाफ़
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- अवधि
- व्यक्ति
- निजीकृत
- चरण
- चरणों
- जगह
- योजना
- की योजना बना
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- कृप्या अ
- बिन्दु
- स्थिति
- अधिकारी
- संभव
- व्यावहारिक
- भविष्यवाणी
- भविष्यवाणी
- पसंद करते हैं
- प्रस्तुत
- पिछला
- मुसीबत
- बढ़ना
- प्रक्रिया
- एस्ट्रो मॉल
- उत्पाद विकास
- परियोजना
- प्रश्नों
- प्रशन
- R
- रासा
- तैयार
- वास्तविक
- वास्तविकता
- वास्तव में
- मान्यता
- भर्ती
- को कम करने
- संदर्भ
- संदर्भित करता है
- क्षेत्र
- भरोसा करना
- अनुस्मारक
- की जगह
- की आवश्यकता होती है
- की आवश्यकता होती है
- अनुसंधान
- संकल्प
- प्रतिक्रिया
- प्रतिक्रियाएं
- जिम्मेदार
- जिसके परिणामस्वरूप
- परिणाम
- क्रान्तिकारी
- मजबूत
- नियम
- नियम
- वही
- कहना
- परिदृश्यों
- वैज्ञानिक
- खरोंच
- Search
- खोज
- लगता है
- चयन
- भेजें
- वाक्य
- कार्य करता है
- सेट
- Share
- चाहिए
- समान
- सरल
- के बाद से
- एक
- सिरी
- सॉफ्टवेयर
- समाधान
- समाधान ढूंढे
- कुछ
- ध्वनि
- विशिष्ट
- बात
- ट्रेनिंग
- शुरुआत में
- राज्य के-the-कला
- कहानियों
- सुवीही
- छात्र
- पर्याप्त
- ऐसा
- उपयुक्त
- समर्थन
- समर्थन प्रणाली
- निश्चित
- कृत्रिम
- प्रणाली
- सिस्टम
- T
- तालिका
- लेना
- लेता है
- कार्य
- कार्य
- तकनीक
- टेक्स्ट
- से
- कि
- RSI
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- इसका
- हालांकि?
- तीन
- द्वार
- पहर
- सेवा मेरे
- स्वर
- आवाज़ का लहज़ा
- भी
- परंपरागत
- रेलगाड़ी
- प्रशिक्षित
- प्रशिक्षण
- ट्रिगर
- दो
- टाइप
- प्रकार
- समझ
- उन्नयन
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- आमतौर पर
- मान
- के माध्यम से
- वास्तविक
- आवाज़
- vs
- W
- मार्ग..
- तरीके
- स्वागत करते हुए
- कुंआ
- क्या
- कब
- जब कभी
- कौन कौन से
- जब
- मर्जी
- साथ में
- शब्द
- शब्द
- काम
- काम किया
- होगा
- लिख रहे हैं
- लिखा हुआ
- गलत
- साल
- इसलिए आप
- आपका
- जेफिरनेट